
Статья расскажет о работе с файлами в Python: о вводе и выводе, открытии, чтении, записи, закрытии и выполнении других не менее важных операций.
Файл представляет собой набор данных, сохраненных на компьютере, причем каждый файл имеет название — filename (имя файла, name of file).
В языке программирования Python выделяют 2 вида файлов:
Поговорим о каждом из типов подробнее.
Текстовые файлы. Формат .txt
Содержимое таких файлов вполне понятно человеку. То есть речь идет об обычных общепринятых символах, тексте, цифрах и т. п. Такие документы можно без проблем создавать, открывать, читать и редактировать Блокнотом и прочими простейшими редакторами.
Также важно отметить, что текст хранят не только в форме .txt, но и в формате.rtf (так называемом «формате обогащенного текста»).
Бинарные файлы. Формат .bin
В бинарных файлах отображение данных осуществляется в кодированной форме (применяются лишь нули и единицы). То есть речь идет уже о последовательности битов. Как следует из подзаголовка, для хранения используется формат .bin.
#51. Функция open. Чтение данных из файла | Python для начинающих
Основные операции
По сути, практически любую операцию с файлом мы можем разделить на 3 главных этапа:
- Открытие.
- Непосредственно выполнение операции (чтение, запись).
- Закрытие.
Открытие. Метод open
В «Питоне» существует встроенная функция open. Используя ее, вы сможете открыть файл на персональном компьютере. Технически, речь идет о создании на основе файла объекта.
Синтаксис относительно прост:
f = open(file_name, access_mode)
- file_name — это имя файла, который надо открыть;
- access_mode — это режим открытия файла. Это может быть чтение, запись и так далее. Если ничего не указать, будут справедливы настройки по умолчанию, те есть станет использоваться режим чтения (r).
Полный список режимов открытия смотрите в таблице ниже:

В качестве примера давайте выполним создание текстового файла test.txt с последующим сохранением его в рабочей директории.
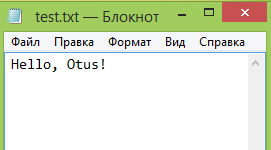
Открыть созданный документ можно в режиме чтения из рабочей директории:
Здесь f представляет собой переменную-указатель на файл test.txt.
Идем далее. Код ниже выведет содержимое файла и информацию об этом файле.
>>> print(*f) # вывод содержимого
>>> print(f) # вывод объекта
Учтите, что в операционной системе «Виндовс» стандартная кодировка — это cp1252, в то время как в Linux — utf-08.
Закрытие. Метод close
Раз открыли, надо и закрыть — это высвободит ресурсы. Язык программирования Python автоматически закроет файл в том случае, если объект будет присвоен другому файлу.
Для закрытия есть несколько вариантов действий.
Вариант №1
Один из наиболее простых способов. Открытый файл закрываем с помощью метода close.
Как устроен Python? ► Детальный разбор
# работаем с файлом
Все, документ закрыт (closed). Закрыв его таким образом, вы не сможете его использовать, пока не откроете по новой.
Вариант №2
Можно прописать try/finally. В результате файл закроется автоматически, если операции с ним приведут к исключениям. Закрытие произойдет до того, как остановится программа.
Синтаксис создания исключения следующий:
# работаем с файлом
Важно отметить, что файл следует открыть до срабатывания инструкции try.
Вариант №3
В третьем случае пригодится инструкция with, упрощающая обработку исключений посредством инкапсуляции начальных операций, а также задач по очистке и закрытию.
Тут уже инструкция close нужна не будет, так как with закроет файл автоматически.
Реализация в коде относительно проста:
with open(‘test.txt’) as f:
# работаем с документом
Чтение и запись в файл
Используя соответствующие режимы, можно выполнять чтение информации и ее сохранение (save) в буфер памяти.
Функция read
Применяется для чтения содержимого после открытия документа в режиме чтения (r).
Вот, как это выглядит:
- file — это объект файла;
- size — это число символов, которые необходимо прочесть. Если конкретное число не указывать, документ будет прочитан полностью.
>>> f.read(7) # читаем семь символов из test.txt
Функция readline
Это функция обеспечивает построчное чтение (считывание) содержимого. Ее используют для работы с большими файлами, так как она позволяет получать доступ к конкретной строке, причем любой.
Для примера создадим test.txt со следующими строками:
This is Otus for developers 1.
This is Otus for developers 2.
This is Otus for developers 3.
И воспользуемся readline:
x.readline() # читаем первую строку
This is Otus for developers 1.
>>> x.readline(2) # читаем 2-ю строку
This is Otus for developers 2.
>>> x.readlines() # читаем все строки сразу
[‘This is Otus for developers 1.’,’This is Otus for developers 2.’,’This is Otus for developers 3.’]
Функция write
Чтобы выполнить сохранение, нужно использовать функцию write. Сохранение в буфер памяти возможно только в те документы, которые открыты для записи (их можно сохранять, когда они находятся в соответствующем режиме).
Синтаксис несложен:
Если вы попытаетесь открыть в данном режиме файл, несуществующий в буфере, будет создан новый. Представим, что файла supertest.txt у нас нет. Однако при попытке его открыть в режиме чтения, он появится:
f = open(‘supertest.txt’,’w’) # открываем в режиме записи
f.write(‘Hello n Otus’) # пишем Hello Otus в документ
f.close() # закрываем документ
Переименование. Функция rename
Может возникнуть необходимость в переименовании имен файлов (filenames). Вопрос можно решить посредством функции rename. Но чтобы это сделать, сначала надо импортировать модуль os.
- src — это файловый документ, которому надо изменить name;
- dest — это новое имя.
Вот, как это выглядит в коде:
# переименовываем otus1.txt в otus2.txt
Основные методы
В таблице ниже вы увидите основные методы, которые используются при работе с файлами (files) в «Пайтон»:
Источник: otus.ru
Типы обрабатываемых данных и файлов в Python.
Существуют три типа файлов которые чаще всего обрабатываются на практике:
- Текстовые файлы.
- Буферизованные двоичные типы файлов.
- Необработанный тип файлов Raw.
Текстовый файл:
Текстовый файл — это самый распространенный тип файла, который чаще всего обрабатывается. При использовании этих типов файлов функция open() возвращает объект TextIOWrapper file . Вот некоторые примеры того, как эти файлы открываются:
>>> fp = open(‘foo.txt’) >>> fp = open(‘foo.txt’, ‘r’) >>> fp = open(‘foo.txt’, ‘w’) >>> type(fp) #
Буферизованные двоичные типы файлов:
Буферизованный двоичный тип файлов используется для чтения и записи двоичных файлов. С этими типами файлов функция open() вернет объект BufferedReader или объект BufferedWriter file . Вот некоторые примеры того, как эти файлы открываются:
>>> fp = open(‘foo.txt’, ‘rb’) >>> fp = open(‘foo.txt’, ‘wb’) >>> type(fp) #
Необработанный тип файлов Raw:
Необработанный тип файла обычно используется как низкоуровневый строительный блок для двоичных и текстовых потоков. Поэтому он обычно не используется. При использовании этих типов файлов функция open() возвращает объект FileIO file . Вот пример того, как открываются эти файлы:
>>> fp = open(‘abc.txt’, ‘rb’, buffering=0) >>> type(fp) #
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Составление пути к файлу в Unix и Windows.
- Открытие/закрытие файла для чтения/записи.
- Типы обрабатываемых данных и файлов.
- Способы чтения открытого файла.
- Способы записи в открытый файл.
- Одновременное чтение из одного и запись в другой файл.
- Добавление данных в открытый файл..
- Управление указателем чтения/записи в файле.
- Создание менеджера для обработки файла.
- Сохранение словарей в формат JSON.
- Встроенные модули для работы с разными форматами.
Источник: docs-python.ru
Шпаргалка по форматам файлов с данными в python
Python понимает все популярные форматы файлов. Кроме того, у каждой библиотеки есть свой, «теплый ламповый», формат. Синтаксис, разумеется, у каждого формата сугубо индивидуален. Я собрал все функции для работы с файлами разных форматов на один лист A4, с приложением в виде примера использования в jupyter notebook.
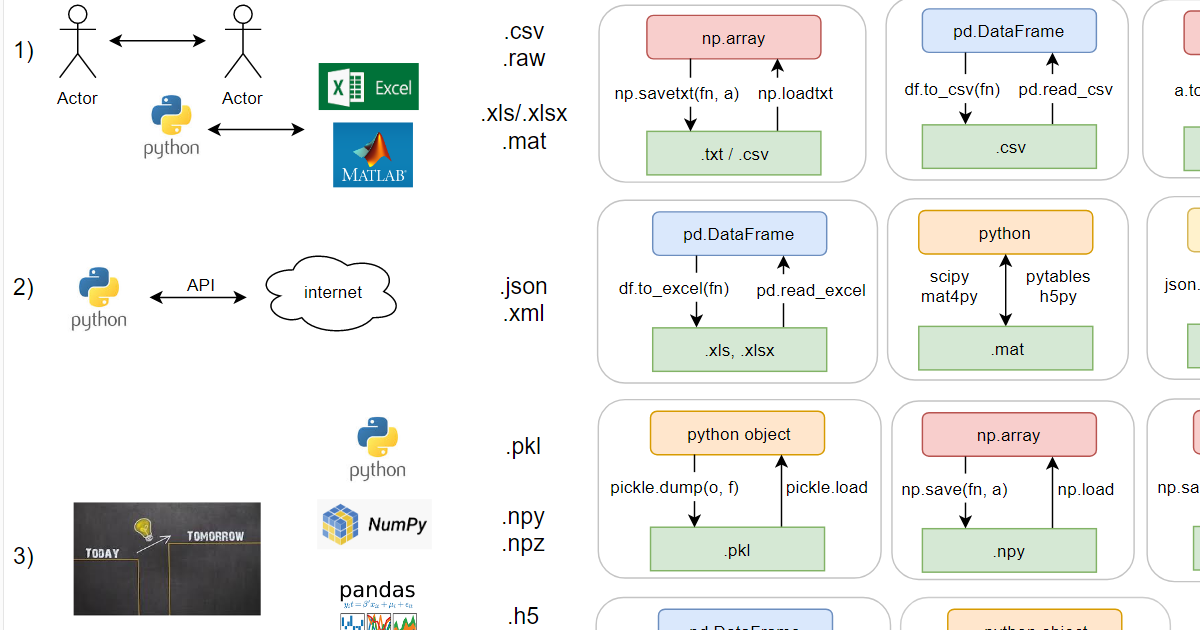
Я условно разделил форматы на три блока по способу использования. Как известно, файлы нужны для обмена информацией: между людьми, между программами (первый блок), между компьютером и сетью (второй) и «save game» – между одной и той же программой в разные моменты времени (третий блок).
Вкратце о каждом блоке:
1) Универсальные форматы:
- .json – текстовый, выглядит как словарь в питоне, но кавычки можно использовать только двойные;
- .xml – текстовый, похож на html.
- .pkl – бинарный формат, в него умеют сохраняться все встроенные питоновские объекты. Пользовательские классы тоже умеют, а если питон сохраняет как-то не так, можно ему помочь через магические методы. Поддерживает дописывание в конец существующего файла (appending).
- .npy и .npz – в numpy аж целых два своих формата (оба бинарные). Появились как реакция на потерю обратной совместимости у pkl в момент перехода python v2->v3. Накладные расходы минимальные (~ на 100 байт больше, чем соответствующий raw; pkl, впрочем, немногим больше: на ~150 байт больше raw). В .npy можно сохранить только один массив, а в npz – сразу несколько, причём достать их оттуда впоследствии можно по имени.
- .h5 – бинарный формат hdf5. Примечателен тем, что в нем можно хранить целую иерархическую структуру данных, это практически файловая система в одном файле. Кроме того, его можно открыть в matlab без конвертации. Минусы:
a) небольшие файлы занимают неоправданно много места (например, 300 байт pkl vs 3.1 Мb у h5),
b) много багов,
c) есть дописывание в существующий файл, но если при этом случится ошибка (а так бывает), данные из него достать будет проблематично.

– в формате pdf
– в формате png:
Пример использования всех функций с диаграммы: html с оглавлением и ipynb-исходником
Источник: habr.com