
Эконометрика _лабор. раб
Министерство образования и науки Российской Федерации Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Челябинский государственный университет» ЭКОНОМЕТРИКА Модели и методы регрессионного анализа Лабораторные работы
Челябинск Издательство Челябинского государственного университета 2011
Одобрено на заседании кафедры математических методов в экономике. Лабораторные работы содержат практические задания и указания к их выполнению по дисциплине «Эконометрика» с использованием пакета прикладных программ Econometric Views (версия 5.1). В конце каждой работы приведены теоретические и практические вопросы, связанные с изучаемой темой.
Лабораторные работы предназначены для студентов экономического факультета. Составители: канд. физ.-мат. наук, доцент Т. Б. Бигильдеева; канд. экон. наук, доцент Е. А. Постников; преподаватель П. С. Кабанов. Рецензент д-р физ.-мат. наук, профессор, зав. кафедрой экономи- ко-математических методов и статистики ГОУ ВПО «ЮУрГУ» А. В. Панюков. 2
| ОГЛАВЛЕНИЕ | ||
| Лабораторная работа № 1. Основы работы с пакетом EViews … | 4 | |
| Лабораторная работа № 2. Анализ данных и их подготовка к | ||
| эконометрическому исследова- | 15 | |
| нию…. | ||
| Лабораторная работа № 3. | Парная регрессия………………….. | 25 |
| Лабораторная работа № 4. | Множественная линейная | |
| Лабораторная работа № 5. | регрессия | 37 |
| Нелинейные регрессионные | 53 | |
| модели | ||
| Лабораторная работа № 6. | Выбор регрессионной модели……. | 57 |
| Список рекомендуемой литературы ………………………….. | .60 | |
Лабораторная работа № 1. ОСНОВЫ РАБОТЫ С ПАКЕТОМ EVIEWS EViews ( Econometric Views ) — эконометрическое программное приложение, позволяющее вводить и обрабатывать статистические данные, проводить графический анализ, строить эконометрические модели. Запуск приложения осуществляется двойным щелчком мыши по иконке EViews на рабочем столе. В результате появится следующее окно (рис. 1.1). Рис.
1.1. Основные элементы окна EViews Основными элементами интерфейса окна EViews являются главное меню и строка ввода формул (рис. 1.1). В строке ввода формул пользователь вводит различные команды и формулы в процессе исследования.
1. Создание, открытие и сохранение рабочего файла Первым шагом при работе с приложением является создание нового или открытие существующего рабочего файла, в котором хранится вся информация. Для создания нового рабочего файла необходимо выбрать в главном меню File / New / Workfile… и заполнить открывшееся диалоговое окно Workfile Create (рис. 1.2).
Рис. 1.2. Окно создания рабочего файла Workfile Create В поле Workfile structure type выбирается тип данных [9]:
| пространственные данные | — Unstructured / Undated, |
| временные ряды | — Dated – regular frequency, |
| панельные данные | — Balanced Panel. |
При выборе Unstructured / Undated в поле Observations указывается размер выборки (число наблюдений), на которой будет проводиться исследование, например 100. В дальнейшем при работе с данным файлом размер выборки может быть уменьшен (часть наблюдений исключена из рассмотрения), но не может быть увеличен.
В полях WF и Page указываются имя создаваемого файла и страницы соответственно (необязательные поля). Таким образом, будет создан файл с максимальным размером выборки, равным 100. При выборе Dated — regular frequency в поле Frequency выбирается периодичность данных: Annual (годовые), Semiannual (полугодовые), Quarterly (квартальные), Monthly (месячные), Weekly (недельные) и т. д.; в полях Start date и End date ука- зываются первый и последний периоды соответственно. Например, для годовых данных — 1950 и 2008 соответст- венно, полугодовых — 1970 S 1 и 2007 S 2 (буква S указывает, что данные полугодовые, а цифра после нее — номер полугодия; далее аналогично характеризуются буквы Q , M , W ), квартальных — 1970 Q 1 и 2007 Q 4, месячных данных — 1991 M 1 и 2007 M 12; недельных данных — 1998 W 1 и 2007 W 52. 5
При выборе Balanced Panel поля Frequency, Start date и End date заполняются аналогично созданию временных рядов. В поле Number of cross sections указывается число единиц совокупности.
Для открытия существующего рабочего файла необходимо выбрать в главном меню File / Open / EVews Workfile… Для сохранения рабочего файла нужно в окне рабочего файла нажать кнопку Save или выбрать в меню File / Save или File / Save As… Имя файла пишется латинскими буквами. 2. Создание и сохранение группы Группа ( Group ) — объект рабочего файла, в котором ото- бражается содержимое одного или более рядов данных.
Группу можно создавать двумя способами. 1. Создание пустой группы . Для этого необходимо выбрать в меню Quick пункт Empty Group (Edit Series) . Появится окно группы, в котором можно создавать и работать с рядами (рис. 1.3). Создание рядов описано ниже в п. 3. Рис. 1.3. Окно группы при создании
Чтобы сохранить группу, нажмите кнопку Name в окне группы или при ее закрытии выберите пункт Name и введите название сохраняемой группы латинскими буквами. При сохранении группы в окне рабочего файла появится элемент группы со значком 
Также группу можно создать и сразу сохранить с помощью командной строки; для этого в строке ввода формул (см. рис. 1.1) необходимо ввести команду group имя_группы и нажать OK . На- пример, group gr1 . 2. Создание группы из существующих рядов.
Для этого необходимо выделить нужные ряды с помощью клавиши Ctrl и левой кнопки мыши, затем правой кнопкой мыши вызвать контекстное меню и выбрать Open / as Group . Либо ввести в командной строке group имя_группы имена_рядов и нажать OK . Например, group gr1 x1 x2 x3 . Примечание : группа не является хранилищем данных, а только дает возможность визуального отображения рядов с данными. 3. Создание, просмотр и редактирование ряда данных Ряды данных можно создавать двумя способами.
1. Создание пустого ряда в группе. Применяется для самостоятельного ввода данных или копи- рования данных из других приложений. В этом случае для создания ряда необходимо в открытой группе щелчком мыши активировать в самой верхней строке obs первую пустую ячейку и ввести название ряда, затем нажать Enter и OK (рис. 1.4).
В окне рабочего файла появится элемент ряда со значком  (см. рис. 1.4). Значения NA в ячейках созданного ряда означают отсутствие данных. Для ввода данных в ячейки необходимо выделить мышью соответствующую ячейку и ввести нужное значение. Примечание : при вводе числовых данных разделителем десятичной дроби является «.», а не «,» как в большинстве офисных приложений.
(см. рис. 1.4). Значения NA в ячейках созданного ряда означают отсутствие данных. Для ввода данных в ячейки необходимо выделить мышью соответствующую ячейку и ввести нужное значение. Примечание : при вводе числовых данных разделителем десятичной дроби является «.», а не «,» как в большинстве офисных приложений.
Рис. 1.4. Создание ряда в окне группы рабочего файла 2. Создание (генерирование) ряда с помощью командной строки. Для этого в строке ввода формул (см. рис. 1.1) необходимо ввести команду genr имя_ряда = команда и нажать OK . Например, genr y = nrnd (рис. 1.5) или genr y = x1 + 10 × x2 (при условии, что уже созданы ряды x 1 и x 2).
В первом случае будет создан ряд значений с именем y , каждое из которых есть значение некоторой случайной величины, имеющей стандартное нормальное распределение. Во втором случае каждое значение ряда y будет равно сумме соответствующих значений ряда x 1 и значений ряда x 2, умноженных на 10. 8
Рис. 1.5. Создание (генерирование) ряда через командную строку Просмотр ряда, как и любого элемента рабочего файла, осуществляется двойным щелчком мыши по этому элементу. При просмотре ряда в окне появляется также информация о времени последнего редактирования и история команд создания ряда (рис. 1.6).
Рис. 1.6. Просмотр ряда данных и его преобразования 9
Для редактирования ряда данных необходимо в режиме просмотра в окне этого ряда нажать кнопку  (рис. 1.7). По- вторное нажатие кнопки
(рис. 1.7). По- вторное нажатие кнопки  вернет ряд к режиму просмотра. Рис. 1.7.
вернет ряд к режиму просмотра. Рис. 1.7.
Режим редактирования ряда данных 4. Удаление элементов рабочего файла Для удаления ряда, группы или другого элемента рабочего файла нужно выделить его в окне рабочего файла и выполнить любое из следующих действий: − нажать кнопку Delete на клавиатуре; − нажать мышью кнопку Delete в этом окне; − нажать правой кнопкой мыши на элемент и выбрать в контекстном меню пункт Delete ; − выбрать в меню Objects / Delete и нажать клавишу Yes . Для удаления сразу нескольких элементов рабочего файла необходимо, используя клавишу Ctrl, выделить нужные элементы, а затем удалить их, применяя любой из перечисленных выше методов. 5. Генерирование рядов данных Для создания ряда X , представляющего собой равномерно распределенные на интервале ( a, b ) случайные числа, используют
Источник: studfile.net
EViews
![]()
This powerful utility allows you to analyze different types of data. In addition, you have the ability to visualize the distribution via detailed histograms.
Update date:
Windows version:
Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10, Windows 11
EViews is a program for Windows designed to help users work with time series, cross-section or longitudinal data. With the help of this tool, they can efficiently manage your information, perform econometric and statistical analysis, generate forecasts or model simulations, as well as produce high quality graphs and tables for publication or import in other third-party apps like WinMDI.
An object-based interface
At the core of the graphical user interface is the concept of an object. Each one has its own window, menus, procedures and its own view of its data. Since most statistical options are simply alternate perspectives of the object, a simple menu choice from a series window changes the display between a spreadsheet, various graph views, descriptive statistics, as well as tabulations, correlograms and independence tests.
Statistical analysis tools
The software solution supports a wide range of basic statistical analyses, including everything from simple descriptive statistics to parametric and nonparametric hypothesis tests. What is more, you have the ability to visualize the distribution of your data via histograms, theoretical distribution, kernel density, survivor and quantile plots. The latter may be used to compare the distribution of a pair of series or single series against a variety of theoretical distributions.
Features
- free to download and use;
- compatible with modern Windows versions;
- gives you the ability to visualize different types of data;
- it is possible to create and compare theoretical distributions;
- you can perform econometric and statistical analysis.
Источник: iowin.net
Русские Блоги
Машинное обучение (1) Руководство по загрузке и установке Eviews
Каталог статей
Введение в EViews
EViews — это всемирно известный эконометрический инструмент. Друзья могут позаимствовать этот эконометрический инструмент EViews для обработки данных или использовать его для построения графиков, анализа моделирования, программирования и т. Д. Можно сказать, что EViews представляет собой лучшую интеграцию передовых функций и современных программных технологий.Программное обеспечение представляет собой наиболее совершенную программу, которая обеспечивает беспрецедентные функции в гибком объектно-ориентированном интерфейсе.
EViews скачать
Ссылка: https://pan.baidu.com/s/1V92dI0a-ogmr_0b7TF0r7w Код извлечения:5xbp После копирования этого содержимого откройте мобильное приложение Baidu Netdisk, что удобнее.
После успешной загрузки разархивируйте и запустите программу формата .EXE из пакета.

После недолгого ожидания следующий


договор об установке после следующего
Нажмите «Обзор», чтобы изменить путь установки (если он вам не нужен, можете пропустить его), затем

Мой путь установки следующий (необходимо создать новую папку и нажать кнопку «Обзор»)


Откройте exe-файл по пути в каталоге загрузки


Проверить что заполнять серийник и имя

Вернитесь к интерфейсу установки и заполните следующий





Нажмите Да в обоих появившихся окнах.


Найдите . patch.exe, который вы только что использовали, и скопируйте его.

Вставьте его в каталог установки EViews

Каталог, установленный ранее, не обязательно такой же, как у меня
Дважды щелкните скопированный файл и щелкните патч

Появится следующий интерфейс, затем успех

Откройте интерфейс следующим образом
Источник: russianblogs.com
Сравнение скорости построения линейных моделей в R и Eviews
Если Вам необходимо оценить эконометрическую модель с небольшим количеством наблюдений, то софт, в котором это можно сделать определяется исключительно Вашими предпочтениями и финансовыми возможностями. Но если количество наблюдений большое? Регрессия не всегда оценивается в одно мгновение. В этом посте я сравниваю время оценки линейной регрессии в R и Eviews в зависимости от количества наблюдений.
Для проведения этого теста будем использовать простую линейную регрессию:
Количество наблюдений N в регрессии будем менять и сравнивать время оценки для каждого. Я взял N oт 100 000 до 10 000 000 с шагом в 100 000.
Что из этого получилось
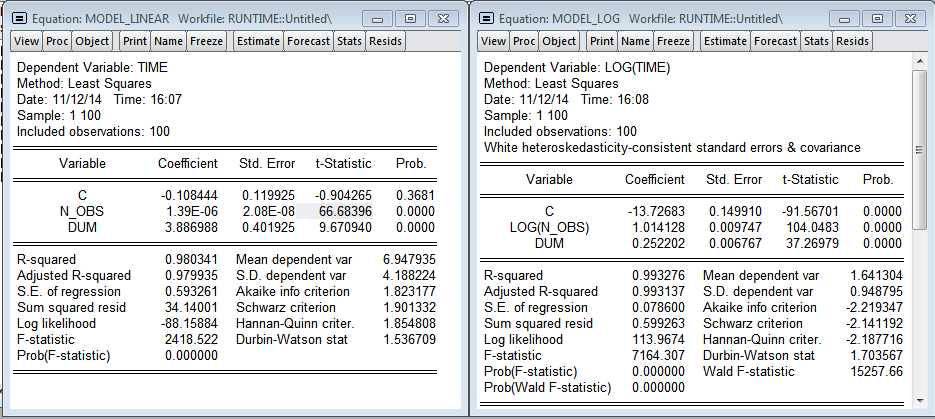
Результаты R (Линейная и логарифмическая модели)
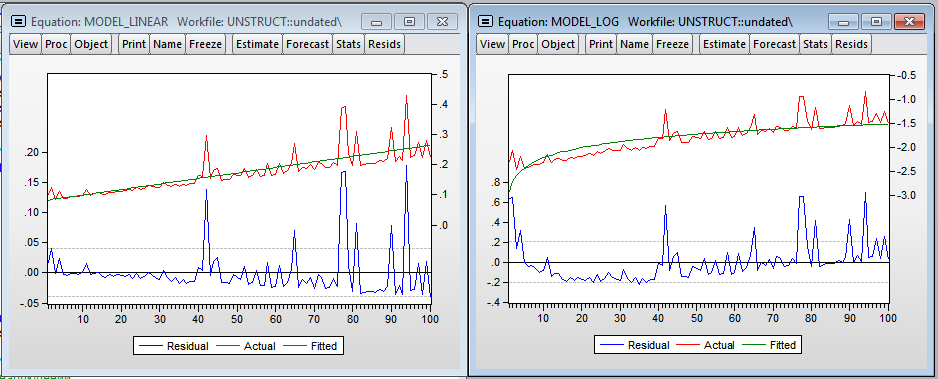
Я добавил переменную dum — дамми на одно из наблюдений (видно выброс на графике, в этот момент мне нужно было открыть браузер). Как и ожидалось, количество наблюдений значимо влияет на время построения регрессии. Мультипликативная модель дает более красивые результаты. Даже есть намёк на нормальность остатков в регрессии. По линейной модели получаем, что каждый дополнительный миллион наблюдений увеличивает время построения на 1.39 секунды, а модель в логарифмах показывает эластичность количества наблюдений по времени 1.014 (т.е. если количество наблюдений увеличится на 1%, то время расчета регрессии увеличится на 1.014%).
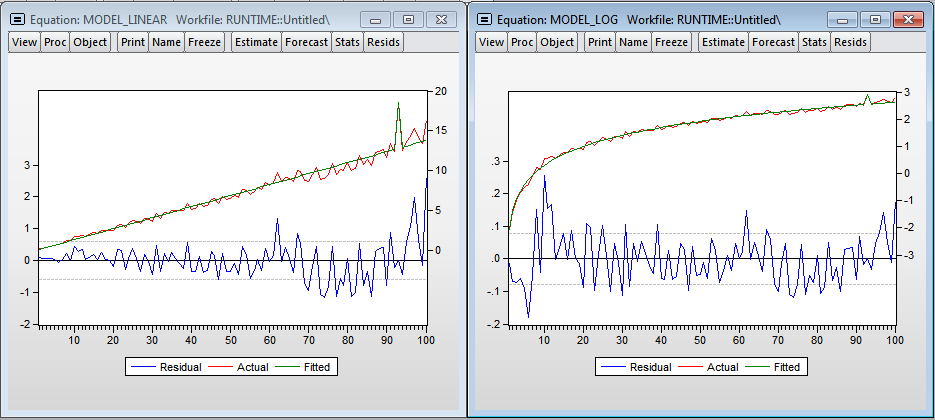
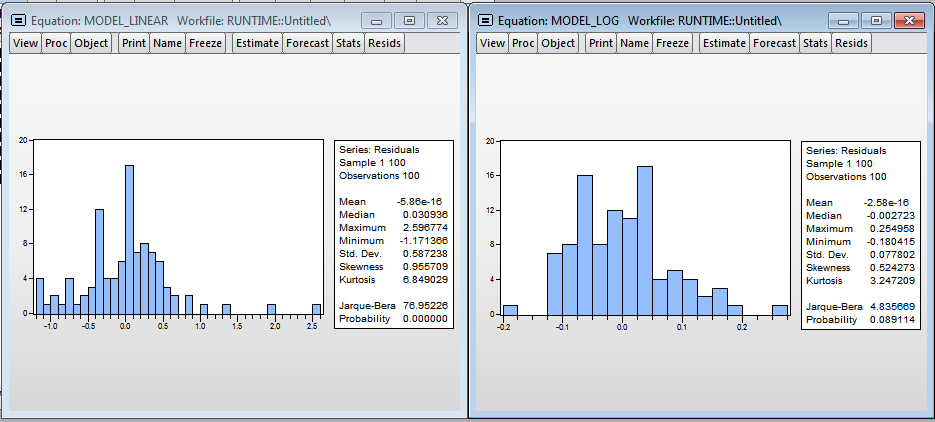
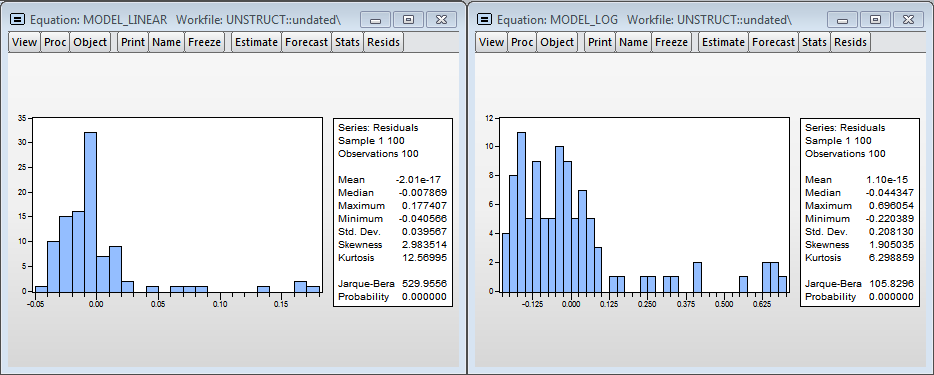
Гистограммы остатков
Визуально гистограммы остатков моделей не похожи на нормальное распределение, а значит оценки, полученные в моделях смещенные, т.к., скорее всего, не учитываем значимую переменную — уровень загрузки процессора. Тем не менее в логарифмической модели можно принять гипотезу о нормальности (т.к. критическое значение тестовой статистики Харки-Бера 8.9% и превышает стандартный критический уровень значимости в 5%).
Результаты Eviews (Линейная и логарифмическая модели)
Модели, полученные в Eviews не так качественно описывают зависимость времени построения от количества наблюдений. Линейная модель предсказывает, что дополнительный миллион наблюдений увеличит время оценивания модели на 0.018 секунд (в 75.8 раз меньше, чем в R). В логарифмической модели эластичность — 0.306 (в 3.3 раза меньше чем в R)
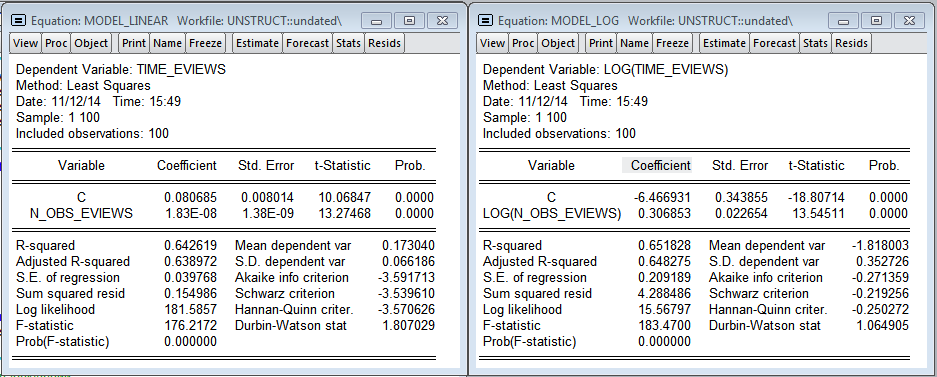
На графиках видно значительное количество выбросов, что, скорее всего, говорит о намного более значимом влиянии загрузки процессора на время вычисления в Eviews. Присутствует гетероскедастичность в ошибках, что свидетельствует в пользу включения переменной — уровня загрузки процессора в модель. Нужно отметить, что Eviews практически не потребляет оперативную память, в то время как R кумулятивно увеличивает объем потребляемой памяти для своих нужд и не освобождает ее до закрытия программы.
Опять же, остатки в моделях не нормальные, нужно добавлять ещё переменных.
В конце хочу сказать, что не стоит сразу записывать это в R как минус. Возможно, такое разное время вычисления получилось потому, что функция lm(), которую я использовал в R создает большой объект типа lm в котором содержится много информации об оцененной модели и для 100 000 наблюдений уже весит около 23 Mb, который опять же, хранится в оперативной памяти. Если вам будет интересно можно повторить похожий тест, используя какие-либо другие функции из R или, например, реализовать алгоритм gradient descent, о котором можно посмотреть здесь.
Код в R
library(ggplot2) #Создаем векторы, которые будут содержать кол-во наблюдений и время выполнения N #Рисуем картинку и записываем данные в файл times
Код в Eviews
Источник: habr.com
Построение и анализ модели в среде EViews
Данная работа осуществляется в пакете Econometric Views. Начальным этапом является ввод данных.
Создаем новый рабочий файл. В строке главного меню выбираем File/New/Workfile, после чего откроется диалоговое окно (рис.1):

В пакете допускается восемь типов данных:
Годовые (Annual) — годы 20 века идентифицируются по последним двум цифрам (97 эквивалентно 1997), для данных, относящихся к 21 веку необходима полная идентификация (например, 2020);
Полугодовые (Semi-annual) — 1999:1, 2001:2 (формат — год и номер полугодия);
Квартальные (Quarterly) — 1992:1, 2005:3 (формат — год и номер квартала);
Ежемесячные (Monthly) — 1956:1, 1990:11 (формат — год и номер месяца);
Недельные (Weekly);
Дневные (5 day weeks);
Дневные (7 day weeks);
Недатированные или нерегулярные (Undated or irregular) — допускают работу с данными, строго не привязанными к определенным временным периодам;
Воспользуемся типом (Annual). В окнах Start date и End date вводим соответственно начальную (1997) и конечную (2006) даты наблюдения. Нажав кнопку ОК, создастся рабочий файл, содержащий вектор коэффициентов C и серию Resid (рис.2):

Ввод данных может осуществляться двумя способами:
Первый заключается в импорте данных из файла. Осуществляется это следующим образом. В строке главного меню выберем File/ Import/Read Text-Lotus-Excel. Появится окно (рис. 3):

В окне Names for series or Number of series if names in file можно сразу же задать имена переменных либо поставить цифру 7, т.е. общее количество факторов. Нажимаем кнопку OK:

В этом окне С — вектор, который будет содержать коэффициенты уравнения, построенного в процессе работы с Eviews, Resid — вектор остатков.
Для того чтобы просмотреть итоговую таблицу, необходимо, выделив переменные, выбрать опцию Open->as Group

Второй способ заключается в создании пустой таблицы и простом переносе данных из Excel. Для этого необходимо выбрать в меню Quick/Empty Group (Edit Series). Появится таблица (рис. 6):

Для того чтобы ввести имена переменных необходимо указать ячейку и нажать Edit+/-. Затем набрать название переменной.
Далее вставляем данные из Excel:

Построение регрессионной модели.
Просмотр числовых характеристик переменных.
Для просмотра числовых характеристик отмеченных переменных необходимо выбрать в рабочем файле View/Descriptive Stats/Common Sample. В результате появится окно (рис.8):

Данное окно содержит:
- · Mean — среднее значение.
- · Median — медиана. В случае симметричного модального распределения медиана совпадает со средним значением.
- · Maximum, Minimum — минимальное и максимальное значения ряда.
- · Std. Dev. — стандартное среднеквадратическое отклонение. Используется для характеристики степени рассеивания случайной величины.
- · Skewness — асимметрия. Для симметричного распределения, в частности для нормального распределения, асимметрия равна нулю.
- · Kurtosis — эксцесс
- · Статистика Jarque-Bera — используется для проверки гипотезы о нормальности распределения исследуемого ряда. Статистика основана на проверке того, насколько отличается эксцесс и асимметрия ряда от соответствующих характеристик нормального распределения.
Нулевая гипотеза: распределение не отличается от нормального.
Альтернативная гипотеза: распределение существенно отличается от нормального. Probability — это вероятность того, что статистика Jarque-Bera превышает (по абсолютному значению) наблюдаемое значение для нулевой гипотезы.
· Observations — количество проведенных наблюдений (в нашем случае их 10, т.к. наблюдения проводились за 10 лет).
Регрессионный анализ модели
Построим и рассчитаем модель множественной регрессии для всей совокупности независимых факторов (для этого воспользуемся схемой пошагового исследования назад). Выбрать Procs/Make Equation.
В строке Method есть методы:

- · LS — метод наименьших квадратов, минимизируется сумма квадратов отклонения для каждого уравнения.
- · TSLS — двустадийный метод наименьших квадратов, применяется, когда присутствует корреляция между переменными, стоящими в правой части уравнения регрессии.
- · ARCH — метод авторегрессии с условием гетероскедастичности, используется для моделирования и прогнозирования условных колебаний и изменений.
- · GMM — общий метод моментов, принадлежит к классу оценочных методов, известных как М-оценка, определяемых минимизацией некоторой функции критерия.
- · Binary — двоичный отбор (логит-преобразование, метод пробитов, экстремальное значение) используется для тех моделей, в которых зависимая переменная Y может принимать два значения.
- · Ordered — упорядоченный отбор, применяется когда присутствует многообразие скрытых ошибок распределения. Наблюдаемая переменная Y представляется на выходе в виде упорядоченной или ранжированной категории.
- · Cencored — модель для цензурированной зависимой переменной, наблюдения над которой проводились только частично (например, наблюдаемые отрицательные значения записывались как 0). С наблюдениями над нашей эндогенной переменной такие действия не проводились.
- · Count — целые, натуральные числовые данные. Применяется, когда Y принимает целые значения, представляющие число событий.
Для оценки параметров уравнения множественной регрессии применим метод наименьших квадратов (Least Squares), так как он позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака от расчетных (теоретических) минимальна.

- · Coefficient — в колонке указаны оценки параметров модели.
- · Standart error — указаны стандартные ошибки коэффициентов уравнения. Стандартные ошибки показывают статистическую надежность коэффициента. Значение стандартных ошибок используется для построения доверительных интервалов.
- · t — statistics — дает наблюдаемое значение t — статистики. Ее значение используется для проверки значимости соответствующей оценки параметра регрессии. Имеются две гипотезы: Гипотеза Н0 о равенстве нулю соответствующего коэффициента (фактор X не влияет на Y). И гипотеза Н1 о неравенстве нулю соответствующего коэффициента.
- · Probability — показывает вероятность принять или отвергнуть гипотезу о равенстве нулю соответствующего коэффициента. При этом предполагается, что ошибки имеют нормальное или асимптотически нормальное распределение. Значения вероятности, указанные в таблице, известны в статистике как уровни значимости б. Если значение вероятности ниже уровня значимости б, то гипотеза Н0 отвергается и соответствующий коэффициент не равен нулю.
- · R — Squared- коэффициент детерминации — одна из наиболее эффективных оценок адекватности регрессионной модели, мера качества уравнения регрессии, характеристика прогностической силы анализируемой регрессионной модели. В общем случае показывает, какая часть зависимой переменной — может быть объяснена с помощью независимых переменных включенных в модель. Если значение R 2 равно 1, то между переменными существует точная линейная связь. Если R 2 равно нулю, то статистическая линейная связь отсутствует
- · Adjusted R — Squared — скорректированный коэффициент детерминации. Важным свойством коэффициента детерминации является то, что R 2 — неубывающая функция от количества факторов, входящих в модель. Поэтому для сравнения коэффициентов детерминации разных моделей надо уравнивать количество факторов. Для сравнения моделей по коэффициенту детерминации корректируют коэффициент детерминации так, чтобы он как можно меньше зависел от количества факторов. Скорректированный коэффициент детерминации может быть использован для выбора лучшей модели при небольшом объеме выборки. Он учитывает число степеней свободы. Т.к. в моем случае объем наблюдений равен 10 годам, то я не могу говорить о небольшом объеме выборки, поэтому буду рассматривать не скорректированный коэффициент детерминации, а простой коэффициент детерминации
- · S.E. of regression- стандартная ошибка регрессии в результате решения уравнения. Прогнозы производятся с ошибками, где ошибки — это разность между фактическим и прогнозируемым значением yt- yt.
- · Sum Squared Resid- сумма квадратов остатков.
- · Log likelihood- показывает значение функции максимального правдоподобия
- · Durbin-Watson Stat- Статистика Дарбина-Уотсона. Используется для выявления автокорреляции. Нулевая гипотеза состоит в отсутствии автокорреляции. В качестве альтернативной гипотезы — гипотеза о наличии автокорреляции. Далее, по приведенной ниже таблице можно сделать более точные выводы о наличии или отсутствии автокорреляции:
Значение статистики DW
Гипотеза Н0 отвергается, есть отрицательная корреляция
Источник: vuzlit.com