
Осенью прошлого года мы рассказали читателям Хабра, как работает голосовой перевод видео в Яндекс Браузере. За первые десять месяцев пользователи посмотрели видеоролики с закадровым переводом 81 миллион раз. Механизм действует по запросу: нейросеть получает аудиодорожку целиком, а звук на понятном пользователю языке появляется с задержкой в пару минут.
Но такой способ не подходит для прямых трансляций, когда нужно переводить почти в режиме реального времени. Поэтому сегодня мы открываем для всех отдельный, более сложный механизм — потоковый перевод стримов.
Чтобы всё заработало, перезапустите Яндекс Браузер. Анонсы новых устройств, спортивные соревнования, вдохновляющие космические запуски — этот и другой контент теперь можно смотреть сразу на родном языке. Закадровый голосовой перевод сейчас доступен для некоторых каналов на YouTube, а в будущем, конечно, включить дубляж можно будет в любой YouTube-трансляции. Чтобы адаптировать механизм перевода для стримов, потребовалось переработать всю архитектуру.
ПРИЛОЖЕНИЕ ДЛЯ ПЕРЕВОДА СУБТИТРОВ ВИДЕО НА YOUTUBE + ОЗВУЧКА
Как работает потоковый перевод
Перевод потокового видео — очень сложная задача с инженерной точки зрения. Здесь сталкиваются два противоречивых требования. С одной стороны, нужно передать модели как можно больше текста за раз, чтобы нейросеть поняла контекст фразы. С другой стороны, необходимо свести задержку к минимуму, иначе «прямой эфир» перестанет быть таковым. Поэтому приходится начинать переводить как можно скорее — не в режиме синхронного перевода, но близко к нему.
Чтобы запустить быстрый и качественный перевод в потоковом режиме, мы, по сути, сделали новый сервис на основе существующих алгоритмов. Новая архитектура позволила сократить задержку, не сильно потеряв в качестве.
Если очень коротко описывать принцип работы потокового перевода, то в его основе лежат пять моделей. Одна нейросеть распознает аудиодорожку и превращает её в текст. Вторая определяет пол спикеров, третья нарезает текст на предложения — расставляет знаки препинания и выделяет из текста части, содержащие законченную мысль. Четвёртая нейросеть переводит полученные куски, а пятая синтезирует речь.
Выглядит просто, но внутри много подводных камней. Рассмотрим процесс подробнее.
Из чего состоит потоковый перевод в Браузере
На первом этапе нужно понять, что именно говорится в потоковом видео, а также определить, в какой момент произносятся слова. Дело в том, что мы не просто переводим речь, но и накладываем результат обратно на видео в нужные моменты.
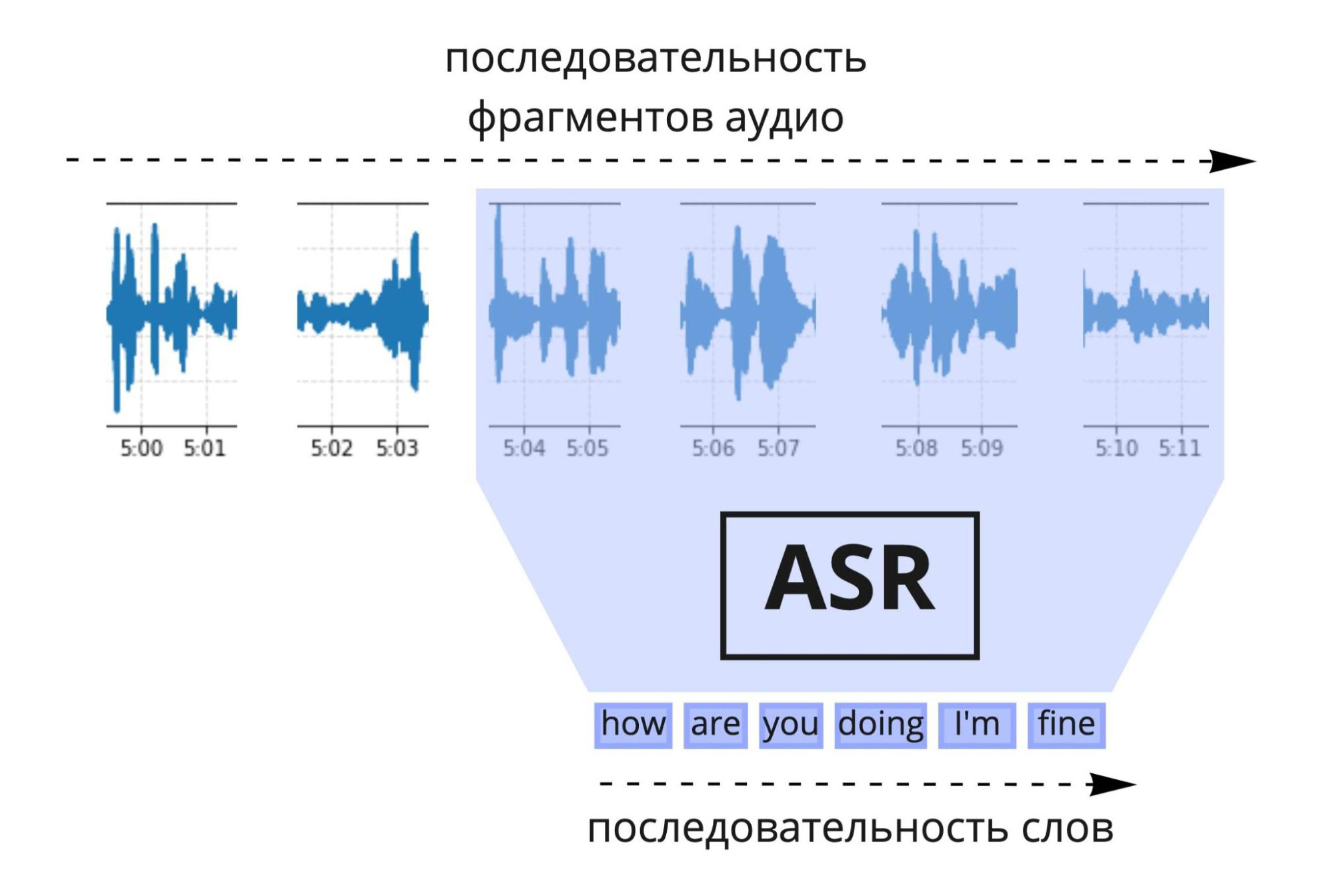
Задача распознавания речи (ASR, Automated Speech Recognition) отлично решается с использованием глубоких нейронных сетей. Архитектура нейросети должна допускать потоковый сценарий использования, то есть уметь обрабатывать аудио по мере поступления. Такое ограничение может сказаться на точности предсказания, но мы можем позволить модели смотреть на несколько секунд в будущее.
На видео могут присутствовать посторонние звуки, например, шумы и музыка, люди могут говорить с различным акцентом, скоростью и дикцией, спикеров может быть много, они могут кричать, а не говорить. Нужно помнить и про богатую лексику, поскольку тематик видео целое множество. Поэтому сбор данных для обучения играет ключевую роль.
На вход алгоритм получает последовательность кусочков аудио, берёт последние N из них, извлекает акустические признаки (мел-спектрограмму) и подает на вход нейросети. Она, в свою очередь, выдаёт множество последовательностей слов (так называемых гипотез), из которых языковая модель выбирает наиболее правдоподобную гипотезу. Когда приходит новый кусочек аудио, процесс повторяется.
Полученную последовательность слов нужно перевести. Если переводить пословно или по фразам, пострадает качество. Если ждать длительной паузы, которая гарантирует конец предложения, то появится большая задержка. Поэтому нужно группировать слова в предложения, не допуская потери смысла или слишком длинных предложений. Один из способов решить эту задачу — использовать модель восстановления пунктуации.

С приходом трансформеров нейросетям стало проще понимать смысл текста, взаимосвязи между словами и закономерности языковых конструкций. Нужно только большое количество данных. Для задачи восстановления пунктуации достаточно взять текстовый корпус, подавать на вход нейросети текст без пунктуации и обучить нейросеть её восстанавливать.
На вход нейросети текст поступает в токенизированном виде, как правило, это BPE-токены. Такое разбиение не слишком мелкое, чтобы длина последовательности не сильно увеличилась, но и не слишком крупное, чтобы избежать проблемы out-of-vocabulary — когда токена нет в словаре. На выходе модели после каждого слова метка: ставить ли тот или иной символ пунктуации.
Чтобы обеспечить работу в потоке, нужно задать некоторый ограниченный контекст. Его размер — компромисс между качеством и задержкой. Если мы не уверены, нужно ли разбивать на предложения в данном месте, то можем подождать чуть дольше, пока не придут новые слова. Тогда мы либо лучше определимся с разбиением, либо превысим ограничение по контексту и будем вынуждены разбивать там, где почти уверены.

Для корректного перевода и озвучки нужно определить пол говорящего. Если использовать классификатор пола на уровне предложений, то никаких отличий в потоковом сценарии не будет. Но мы заметили, что биометрическая информация снижает ошибку классификации пола в полтора раза: то есть мы можем не просто определять пол человека по реплике, а ещё и учитывать результат классификации пола на предыдущих репликах. Для этого нам нужно «на лету» определять, кому принадлежит реплика, тем самым уточняя пол спикера.

С точки зрения машинного перевода ничего не изменилось в сравнении с переводом уже готовых роликов, поэтому на этом этапе останавливаться не будем. Подробнее о том, как работает перевод, мы писали в этом хабрапосте.

В прошлом году мы также рассказывали, как устроен речевой синтез Яндекса. Базовая технология синтеза в Алисе и переводе видео одна и та же. Разница в том, как осуществляется применение (inference) этих нейросетей. Спикер на видео может произнести реплику очень быстро или перевод предложения может оказаться в два раза длиннее оригинала.
В таком случае придётся сжать синтезированное аудио, чтобы успеть в тайминг. Это можно сделать двумя способами: на уровне звуковой волны, например, при помощи PSOLA (Pitch Synchronous Overlap and Add) или внутри нейросети. При втором способе речь звучит натуральнее, но для этого нужна возможность редактирования скрытых параметров.
Важно не только привести длительности синтезированных фраз к нужной длине, но и разложить их по нужным моментам времени. Идеально получится не всегда, придётся либо ускорить запись, либо сдвинуть тайминги. За это у нас отвечает алгоритм укладки. В переводе стримов нельзя менять прошлое, поэтому может получиться ситуация, когда нужно озвучить фразу в два раза быстрее, чем она произносится в оригинальном видео. Для справки: ускорение более чем на 30% существенно влияет на восприятие.
Решение следующее: делаем некоторый запас по времени, то есть не спешим укладывать реплики, а ждём, когда придут новые, чтобы учесть их длительность, а так же позволяем немного накапливать сдвиг по времени, так как рано или поздно на видео все замолчат и сдвиг обнулится.
Результирующую аудиодорожку нарезаем на фрагменты и оборачиваем в аудиострим, который будет микшироваться на клиенте браузера.
Как архитектурно устроен сервис потокового перевода

Когда вы смотрите трансляцию, браузер опрашивает сервис стриминга (например, YouTube) на предмет новых фрагментов видео и аудио; если такие есть, он их скачивает, а затем последовательно воспроизводит.
Когда пользователь нажимает на кнопку перевода стрима, Яндекс Браузер запрашивает у своего бэкенда ссылку на стрим с переведенной аудиодорожкой. Эту дорожку Браузер накладывает по таймингам поверх основной.
В отличие от video-on-demand (то есть перевода уже готовых роликов), стрим обрабатывается переводом всё время своего существования. Stream Downloader читает аудиопоток и отправляет его в ML-pipeline обработки, компоненты которого мы разобрали выше.
Есть несколько способов организовать взаимодействие между компонентами. Мы остановились на варианте с очередями сообщений, где каждый компонент оформлен в виде отдельного сервиса:
- Запустить все модели в рамках одной машины проблематично — они просто не уместятся по памяти или потребуют очень специфичную конфигурацию железа.
- Требуется балансировать нагрузку и иметь возможность горизонтально масштабироваться. Например, у сервисов перевода и синтеза различные пропускные способности, поэтому количество реплик может быть разное.
- Сервисы иногда падают (out-of-memory на GPU, утечка памяти или просто отключили питание в дата-центре), и очереди предоставляют механизм retry.
Полученный аудиопоток нужно доставить пользователю. Здесь за дело берётся Stream Sender — он оборачивает фрагменты аудио в стриминговый протокол, и клиент читает этот стрим по ссылке.
Что дальше
Сейчас мы отдаём потоковый перевод со средней задержкой 30-50 секунд. Иногда вылетаем за этот диапазон, но не сильно: стандартное отклонение — примерно 5 секунд.
Основная сложность в переводе стримов — гарантировать стабильность задержки. Простой пример: вы запустили стрим и через 15 секунд начали получать перевод. Если продолжать просмотр, то рано или поздно одна из моделей захочет большего контекста — скажем, если спикер произносит длинное предложение без пауз, нейросеть попробует получить его целиком. Тогда задержка увеличится, возможно, на десять дополнительных секунд. Чтобы такого не происходило, лучше на старте дать чуть большую задержку.
Наша глобальная задача — уменьшить задержку примерно до 15 секунд. Это чуть больше, чем при синхронном переводе, но достаточно для стримов, где ведущие общаются с аудиторией — например, в Twitch.
- машинный перевод
- перевод видео
- трансляции
- видеотрансляции
- дубляж
- яндекс браузер
- Блог компании Яндекс
- Браузеры
- Машинное обучение
- Софт
- Искусственный интеллект
Источник: habr.com
Переводим видео с английского на русский онлайн

Сегодня Вы узнаете один из лучших способов, как переводить видео с английского на русский, т. е., как получить русский перевод с видео. Для этого, мы воспользуемся сервисом «Speechpad» и программой «Virtual Audio Cable».
Перед тем, как писать эту статью, я решил узнать, какие в Интернете существуют еще метода, кроме тех, что предлагаю я. И вот на YouTube я нашел один ролик, где парень предлагает получать готовый перевод через субтитры. Говорит – это классная штука, и дает хороший перевод.
Работает это следующим образом: нажимаем в плеере значок «Субтитры», выбираем нужный для перевода язык, а затем читаем готовый перевод на своем мониторе. Так у него все просто – тяп-ляп и готово.
Этот метод действительно работает, но применить его можно только на YouTube, да и перевод получается настолько искаженным, что и не разобрать ничего. Судя по ролику того парня, то ему это как-то по барабану. Главное, что он поделился этой фишкой бесплатно, и за такую щедрость, ролик получил более восьмисот лайков, плюс около 70 тысяч просмотров.
Как перевести видео на русский язык
В одной из своих статей я писал, как можно переводить видео на YouTube в текст. Но переводить видео можно не только с Ютуб, а с любого другого сайта, и даже с компьютера. Перевод такой называется транскрибацией, и с помощью тех же манипуляция, можно получать готовый текст с аудио файлов.
С помощью блокнота «Speechpad» можно получить перевод видео в текст на семи языках:
- Украинский
- Русский
- Английский
- Немецкий
- Итальянский
- Испанский
- Французский
Для транскрибации, нужно выполнить следующие действия: в одной вкладке браузера включаем видео (это может быть любой сайт), а в другой вкладке заходим на сервис « speechpad » и жмем на «запись». Таким образом, мы получаем готовый текстовый перевод.
Напомню, что нам для этого понадобиться:
- Программа «Virtual Audio Cable» (платная)
- Сервис «Speechpad»
Устанавливаем и настраиваем программу Virtual Audio Cable
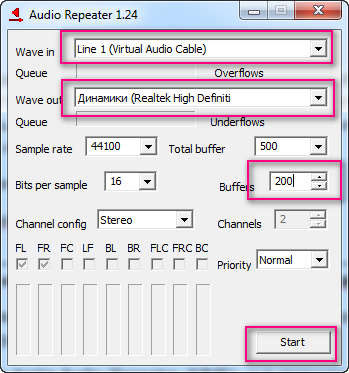
Как установить программу, смотрите видео в конце этой статьи, а о настройках я Вам расскажу сейчас. После установки программы, у Вас должно появиться два ярлыка на рабочем столе. Если их нет, ищите тогда в программах. Запустите ярлык Audio Repeater (MME), а затем сделайте следующие настройки:
- Wave in: Line 1 (Virtual Audio Cable)
- Динамики
- Buffers: 200
- Нажать кнопку «Start»
[lazy_load_box effect=”slidefromleft” speed=”1900″ delay=”5″][/lazy_load_box]
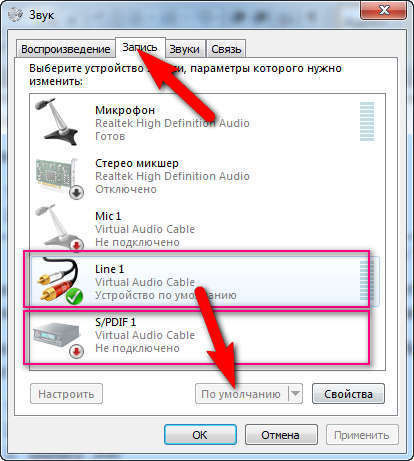
Так, молодцы! Теперь переходим в настройки звука Windows (Устройства воспроизведения), и жмем вкладку «Запись».

- Line 1 оставляем по умолчанию (жмем кнопку «по умолчанию»)
- Щелкаем правой клавишей мышки по S/PDIF, а затем в появившемся контекстном меню надо выбрать «включить»
[lazy_load_box effect=”slidefromleft” speed=”1900″ delay=”5″][/lazy_load_box]
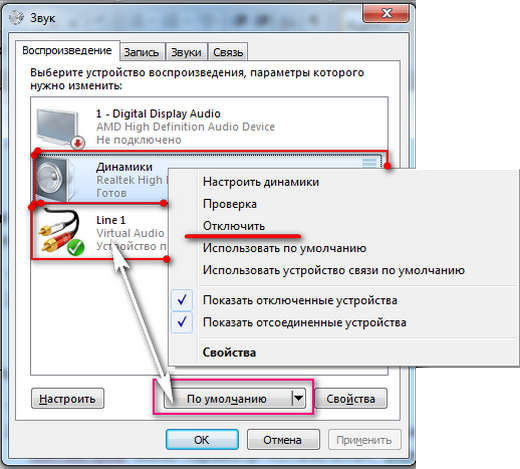
Теперь выбираем вкладку «Воспроизведение» а потом:
- Line 1 остается по умолчанию, т. е., надо выбрать Line 1, а потом нажать кнопку «По умолчанию», как показано на скриншоте.
- Включаем динамики. Правый клик мышки, а затем выбрать «включить». Но, если в контекстном меню, которое должно появиться, Вы увидите параметр «Отключить», значит, звук динамиков уже включен, и трогать ничего не надо.
- Жмем «ОК»
[lazy_load_box effect=”slidefromleft” speed=”1900″ delay=”5″][/lazy_load_box]
Перевод видео с Английского на Русский
Итак, переходим непосредственно к переводу видео. Откройте в одной вкладке браузера сайт с видео, которое нужно перевести, а в другой вкладке нужно зайти на сервис speechpad.ru (речевой блокнот). Далее выполняем следующие действия: внизу нажимаем кнопку «+Транскрибацию», а потом «+Перевод».
Должно появиться два окна:
- окно для перевода текста,
- и окно для транскрибации.
Далее выполняем следующие настройки:
- поставьте галочку «YouTube video», если перевод видео будет осуществляться с сайта YouTube.
- Вставляем ID видео, и жмем «Обновить». ID видео берем после знака «=» в ссылке к видео.
Должен появиться первый кадр видеоролика. Теперь выберите язык перевода и язык голосового ввода

[lazy_load_box effect=”slidefromleft” speed=”1900″ delay=”5″][/lazy_load_box]
На этом этапе настройки завершены, и можно переходить к переводу.
Поставьте видео на воспроизведение прямо на самом сервисе, а затем нажмите кнопку «включить запись». После этого, в одном окошке должен начать выводиться текст на английском языке, а в другом на русском. Вот в принципе и все.
Аналогичным образом, можно переводить видео и с других сайтов, но в этом случае, его не нужно вставлять на сервис, как было описано выше, а включить его в другой вкладке браузера. Также можно делать перевод видео и на своем компьютере. Для этого включите его, а затем жмите «Запись» на сервисе «Блокнот».
Вы также можете посмотреть видео, чтобы иметь представление, как это все работает. Вы увидите, как в реальном времени происходить перевод видео с Английского языка на русский.
Если изучив эту статью, у Вас не получается настроить программу «Virtual Audio Cable», то не стоит обращаться ко мне за помощью, а поищите информацию в Интернете, как это делал я. Но для многих ноутбуков должны подойти настройки, о которых я рассказываю в этой статье.
Источник: dvpress.ru
Автоматический закадровый перевод иностранных видео в браузере онлайн

Закадровый перевод необходимая вещь в нашем время, так как не каждый знает иностранные языки. Да, есть субтитры, но гораздо удобнее смотреть видео с озвучкой на вашем языке. Вы сможете смотреть зарубежные мануалы и прямые трансляции каких-либо компаний и слушать их уже на своем языке. Этот метод сейчас доступен в любых браузерах, мы покажем на примере Chrome.
Как сделать закадровую озвучку в браузере:
1. Открываем сайт. Открылась страница с нужным нам расширением. Нажимаем «Установить».

2. Чтобы расширение работало, нам необходимо установить скрипт. Переходим по ссылке на страницу с скриптом. Нажимаем «Установить»

3. Убедитесь что расширение включено и перезагружаем браузер.

4. Открываем любое зарубежное видео. Например на YouTube. У вас появится новая функция «Перевести видео». Нажимаем на нее и наслаждаемся закадровым переводом.
Если в видео говорит мужчина, то озвучивается мужским голосом. Если в видео говорит женщина, озвучка идет женским голосом.
В Яндекс Браузере эта функция уже встроена.
Также, если будут какие-то дополнения и обновления ссылок на скрипт, вы всегда можете посмотреть их здесь, в вкладке Установка расширения
Источник: mipped.com