
Краткое введение в Elasticsearch
Насколько замечательно Grafana, Graphite и Prometheus справляются с численными данными мониторинга, вроде загрузки процессора по времени, настолько же они бесполезны для работы с логами. А ведь с теми приходится работать даже чаще, чем с метриками.
Инструментов для работы с логами тоже навалом, но сегодня мы посмотрим в сторону ELK стека от Elastic. А именно: Elasticsearch, Logstash и Kibana — хранилище/поисковик, обработчик данных и тулза для их визуализации. А начнём, естественно, с первой буквы этого трёх-буквенного алфавита — «E».
Что такое Elasticsearch
Elasticsearch — это быстрый, горизонтально масштабируемый и очень бесплатный гибрид NoSQL базы данных и гугла для неё. С миром он общается через HTTP API и через него уже получает на вход JSON документы для индексации и хранения. Хранение, правда, можно отключить, и тогда останется только поисковик, возвращающий айдишки когда-то проиндексированных документов.
Установка
Так как Elasticsearch написан на Java, устанавливается он очень просто: качаем архив, распаковываем и запускаем bin/elasticsearch . Правда, запустить его через Docker будет еще проще: docker run -d -p9200:9200 elasticsearch . Всё общение будет проходить через порт 9200, так что самое время в него постучаться.
ElasticSearch что это такое — ElasticSearch уроки
Осматриваемся
Вэбинары и официальная документация обычно показывают демки, используя еще один продукт от Elastic — Kibana. Но так речь идёт об обычном HTTP и JSON, отправлять и получать запросы можно чем угодно. Наверное, самый простой готовый инструмент — консоль и curl .
Итак, у нас есть порт 9200. Попробуем его пнуть просто так:
$ curl 127.0.0.1 : 9200
# «name» : «e-wGdWV»,
# «cluster_name» : «elasticsearch»,
# «cluster_uuid» : «ZxPcxDlFTSu68zpY9foYiw»,
# «number» : «5.2.0»,
# «build_hash» : «24e05b9»,
# «build_date» : «2017-01-24T19:52:35.800Z»,
# «build_snapshot» : false,
# «lucene_version» : «6.4.0»
# «tagline» : «You Know, for Search»
Неплохо. Номер версии в середине ответа и шутка юмора внизу — запрос определенно того стоил.
Есть и другие полезные запросы, для которых в индексе не обязательно должны быть данные. Например, можно проверить статус узла:
$ curl 127.0.0.1 : 9200 / _cat / health ? v
#epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
#1486360312 05:51:52 elasticsearch yellow 1 1 5 5 0 0 5 0 — 50.0%
Или получить список индексов:
$ curl 127.00.1 : 9200 / _cat / indices ? v
#health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
Так как установка свежая, то, разумеется, индексов в ней никаких еще нет. Но мы как-то внезапно начали оперировать специфическими терминами, вроде узла и индекса, так что стоит сначала разобраться с терминологией.
ЧТО ТАКОЕ ELASTICSEARCH? ВВОДНЫЙ УРОК
Терминология Elasticsearch
Итак, мы уже упомянули узел (node), что на самом деле означает отдельно взятый процесс elasticsearch с его данными и настройками. Даже один узел образует кластер. Но если узлов в кластере несколько, то включённый по умолчанию шардинг (дробление) индексов и репликация шардов (shards) резко повысит и выживаемость индексов за счёт избыточности, и скорость запросов к ним за счёт параллелизации. Похожий подход, кстати, работает и в Kafka, только там шарды называются разделами.
Сам по себе индекс — это просто коллекция документов. В пределах кластера их может быть уйма. Внутри индекса документы можно организовать по типам — произвольным именам, описывающим похожие по структуре документы. Наконец, сам документ — это просто JSON. Обычный скучный JSON.
Создание, чтение, обновление и удаление
С двумя абзацами теории разобрались, самое время что-нибудь сделать.
Создание
Добавить документ в elasticsearch так же просто, как и сделать HTTP POST. Ну один в один:
Источник: dotsandbrackets.com
Elasticsearch — инструмент для сбора и анализа данных среднего объёма

Если бизнес предполагает выполнение анализа статистических данных, которые поступают из разных источников, то вам в любом случае потребуется эти данные не только собирать и хранить, но и индексировать, анализировать и даже преобразовывать в другие данные. Какое решение подойдёт лучше, если речь идёт о данных среднего объёма? Об этом — наша статья.
На практике мы нередко сталкиваемся с тем, что масштаб проекта недостаточен для внедрения крупных платформ типа Hadoop. В таком случае следует обратить внимание на стандартные NoSQL-решения, позволяющие эффективно работать с данными среднего объёма. Именно к таковым решениям и относится Elasticsearch.
Elasticsearch — что это?
Elasticsearch представляет собой кластерную NoSQL с JSON REST API. Его можно назвать нереляционным хранилищем документов в JSON-формате и поисковой системой на базе полнотекстового Lucene-поиска. Аппаратной платформой является JVM — Java Virtual Machine. При этом официальные клиенты доступны на: • Python, • Groovy, • Java, • NET (C#), • PHP, • Perl, • JavaScript, • Ruby.
Elasticsearch разработан компанией Elastic одновременно со связанными проектами (их называют Elastic Stack) — Logstash, Elasticsearch, Beats, Kibana. Kibana осуществляет визуализацию данных через web-интерфейс. Beats — это отправители данных с разных устройств и легковесные агенты. Logstash обеспечивает сбор и обработку данных зарегистрированных событий. Что касается хранения и поиска данных, то за них отвечает Elasticsearch.
В настоящее время Elastic Stack широко используется такими компаниями, как eBay, Adobe, Uber, Volkswagen, Microsoft, Netflix, Amazon и пр. Так почему Elasticsearch так привлекателен?
Пару фактов о системе
Elasticsearch отлично подходит для работы в рамках определённого объёма данных (20–30 млрд документов в индексах, 2–10 терабайт в год), плюс прекрасно интегрируется с кластером Spark.
Агенты (Beats) помогают собирать интересующую информацию на конкретном сервере или устройстве. Посредством этих агентов мы можем собирать различного рода данные: логи ОС Linux, системную информацию Windows, данные устройства на Android. Также есть возможность самостоятельно выполнять анализ трафика с устройства, будь то HTTP, TCP и так далее.
При этом Logstash, локальный для инфраструктуры каждого здания, прекрасно справляется с отправкой данных, которые собирают агенты устройств в централизованный кластер Elasticsearch. Ну а Kibana предоставляет нам удобный способ построения web-отчётов.
О масштабируемости
Эта подсистема статистики способна работать с любой сферой деятельности, в которой нужен сбор и анализ статистических данных, имеющих средний объём. Как пример — обработка статистической информации с одной тысячи до 30 тысяч ноутбуков, мобильных устройств, интерактивных панелей, холодильников и т. п.
Если устройств меньше 1–3 тысячи, то система является избыточной, поэтому лучше обратить внимание на более простые решения. Оптимальный вариант — количество устройств в пределах 10–30 тысяч единиц. Если устройств будет 50 тысяч и более, мы столкнёмся с усложнением системы, поэтому тут тоже лучше искать другое решение. Впрочем, если воспринимать 50–100 тысяч устройств в качестве трёх сегментов по 15–30 тысяч, то мы можем просто запустить 3 подсистемы нашей статистики.
Главная идея — чем больше изолированы «сектора», тем проще использовать решение формата «3 по 30».
Что на базе собранных данных могут получить аналитики?
Наиболее часто встречающийся сценарий — сбор и хранение всей статистики (сырой) по всем сервисам и устройствам за последний месяц и с последующей агрегацией статистики по дням и группировкой по зданиям с «бессрочным» хранением результата. То есть Raw-индексы перезаписываются новыми данными ежемесячно, а Agg-индексы накапливаются «бесконечно» по дням, пока это позволяет дисковое пространство. Прочие пожелания по разбивке и группировке данных (например, по визуальному представлению, аналитическим срезам и т. п.) осуществляются аналитиками самостоятельно с помощью Kibana или Power BI.
Время от времени некоторые данные (обычно новые, получаемые из исходных), выделяют в отдельную задачу предварительного расчёта. Эта задача выполняется посредством вычислительной платформы Spark «по расписанию» с последующим сохранением в очередной Agg-индекс, из которого эти данные уже попадают в сложные отчёты.
Источник: otus.ru
ElasticSearch: что такое, как работать и где применять

Качественный поиск на вашем сайте — это не самая тривиальная вещь, которую можно придумать. Если ранее вы имели задачу по реализации поиска по базе данных, то должны понимать, что действительно, качественный поисковый алгоритм не так просто разработать. Ввиду того, что эта задача стоит перед разработчиками очень часто, а так же, эта задача не самая простая, существует много продвинутых решений, помогающих нам с решением этой проблемы. Благодаря качественно разработанному поиску вы улучшите опыт времяпровождения пользователей на вашем сайте. И в этом нам поможет Elasticseach. Поисковый алгоритм должен соответствовать 2 условиям:
- хорошая релевантность запросов
- высокая скорость поиска
Как раз, ElasticSeach удовлетворяет нас по этим 2 показателям, плюс, он имеет ещё много дополнительных функций и возможностей для того, чтобы сделать нашу жизнь ещё проще.
Что такое Elasticsearch и как он работает
Вот как сами разработчики говорят о своём продукте на сайте:
Elasticsearch — это распределённый поисковой и аналитический движок с REST-api, имеющий широкое применение и помогающий решить большой количество нетривиальных бизнес-задач.
Elasticsearch использует документо-ориентированную модель хранения данных, сохраняя всё в JSON-формате. Распределение и хранение информации основано на, так называемых индексах и типах. Их может быть большое множество. Вы можете думать о индексах как о базе данных в реляционных СУБД, а типы — как таблица этой БД. На просто примере сравнения, можете увидеть аналогии, построенные между базой данных и структурой хранения в Elasticsearch:
| MySQL | Базы дынных | Таблицы | Строки/Колонки |
| Elasticsearch | Индексы | Типы | Документы со свойствами |
Весомым преимуществом его является то, что этот поиск быстрый, масштабируемый и возвращает более релевантные запросы, чем, Mysql LIKE , например. Внедрение его в свой проект позволяет выполнять запросы действительно быстро, а благодаря легкой масштабируемости, такой поиск может быть расположен сразу на нескольких серверах, и хранить большое количество данных, выполняя параллельный поиск. Elasticsearch очень полезен при работе с большими данными, и делает работу при поиске по миллионным данным практически в реальном времени. Такова магия Elasticsearch.
Для того, чтобы установить Elasticsearch, рекомендую просмотреть эту статью, в которой были рассмотрены примеры установки на все операционные системы (в том числе, Docker и Homestead Vagrant).
Базовые понятия
Перед началом, хотелось бы рассмотреть подробнее, важные определения.
Для изучения Elasticsearch нужно ознакомиться с такими его базовыми понятиями:
Кластер
Кластер — это набор одного или более узлов, которые объединены под одним уникальным именем. Он поддерживает индексирование и поиск по всем узлам, которые ему пренадлежат. Кластер должен иметь уникальное имя (по умолчанию это elasticsearch ). То есть, кластер полезен при масштабировании. Кластер объединяет в себе несколько независимо работающих серверов с Elasticsearch.
Узел (Node)
Узел — это единичный сервер, который является частью кластера. Узел хранит данные и учавствеет в индексировании и поиске данных.
Индекс
Индекс — это набор документов с похожими свойствами и структурой, который идентифицируется по уникальному имени (как и таблица в реляционной БД). Это имя используется для обращения к конкретному индексу, при добавлении в индекс, поиске, обновлении и удалении документов из него. В одном кластере может находится столько индексов, сколько пожелаете.
Документ
Документ это базовая единица информации, находящаяся в индексе. Информация документа хранится в формате JSON. Документ — как одна конкретная запись из реляционной БД.
Фрагмент (Shard)
Elasticsearch поддерживает возможность разделять индексы на фрагменты ( shards ). Каждый из них является полнофункциональным и независимым «индексом», который может быть частью узла внутри кластера. Это полезно, в случаях, когда индекс добавляется в один узел, который не будет занимать больше места, чем ему доступно. Индекс тогда разделяется между несколькими различными узлами. Кроме того, shards позволяют распределять и выполнять параллельные операции между этими фрагментами, повышая при этом производительность.
Replica
Elasticsearch позволяет вам сделать один или более копий ваших индексов, называемые копией фрагмента ( replica shard ), или просто replica . Это позволяет обеспечить высокую отказоустойчивость в случае сбоя узла и позволяет легко масштабировать поиск, поскольку поиск может выполняться параллельно на нескольких фрагментах.
Грубо говоря, реплика — это бекап данных, который сохранён на другом сервере. И в случае, если текущий сервер по каким-либо причинам отваливается, то данные берутся с запасного сервера.
Какие способы внедрения Elasticsearch в свой проект
При внедрении Elasticsearch в свой проект, существует несколько способов:
- Запустить его на локальной машине, на которой расположен ваш проект/вебсайт.
- Запустить его на отдельном сервере, например, на Amazon AWS Elasticsearch, или DigitalOcean. Там вам нужно выбрать характеристики железа и тариф, в зависимости от того, какие размеры и нагрузки ожидаются.
Как говорится на их сайте, чем больше ОЗУ, тем лучше работает Elasticsearch.
Добавление документа
Перед тем, как мы разработаем простое PHP-приложение, которое будет взаимодействовать с Elasticsearch, я покажу как добавлять документы в индекс, просто используя REST API, выполняя запросы из обычного HTTP-клиента:
curl -H «Content-Type: application/json» -XPOST «http://127.0.0.1:9200/users/user» -d «< «firstname»:»Alexander», «nickname»:»truehero», «site»:»badcode.ru» >»
В текущем случае, экранирование кавычек в теле запроса » должно быть, чтобы на сервер отправился валидный JSON.
В этой команде я использовал curl , чтобы отправить POST запрос к серверу Elasticsearch.

Адрес, по которому обращаемся, состоит из таких параметров:
где users — указывает, под каким индексом (о котором вы можете думать, как о базе данных) мы хотим добавить документ. В случае, если такого индекса не существует, он будет создан автоматически.
user — это тип (о нём можете думать, как о таблице в базе данных), куда сохраняется документ. Этот документ хранится в виде JSON-а, который мы и передали в теле запроса < «firstname»:»Alexander», «nickname»:»truehero», «site»:»badcode.ru» >, который состоит из 3 полей: firstname , nickname и site , и их переданных значений.
Для демонстрации процесса поиска ниже, добавим ещё несколько записей:
curl -H «Content-Type: application/json» -XPOST «http://127.0.0.1:9200/users/user» -d «< «firstname»:»Ivan», «nickname»:»vanya007″, «site»:»badcode.ru» >» curl -H «Content-Type: application/json» -XPOST «http://127.0.0.1:9200/users/user» -d «< «firstname»:»Valya», «nickname»:»vasya007″, «site»:»badcode.ru» >»
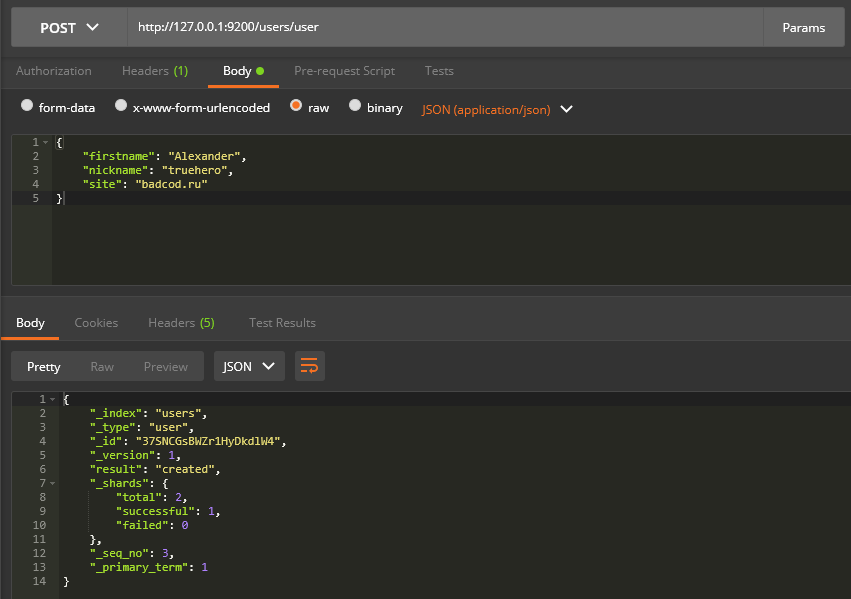
Если вы не используете CURL, а хотите для этого использовать программу Postman, то для этого, нужно настоить удалённый доступ для Elasticsearch и после чего, сможете воспользоваться этим клиентом, указав ему нужные параметры
Поиск документов
Перед тем, как создавать более сложные запросы, удостоверимся, что предыдущие данные были успешно сохранены:
curl -XGET «http://127.0.0.1:9200/users/user/_search/?pretty=true»
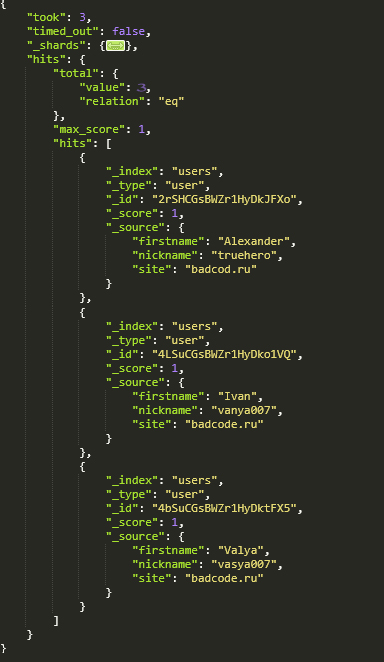
Этот запрос вернёт все документы, типа user , индекса users . А указание параметра pretty=true означает, что ответ от сервера должен вернуться в отформатированном виде (с читабельными отступами):
Как можете увидеть, все 3 пользователя были успешно добавлены. И, помимо указанных нами полей, Elasticsearch предоставляет информацию о том, сколько времени занял этот запрос (в миллисекундах), и какое количество результатов было получено, и дополнительные поля документа: индекс, тип и идентификатор.
Подключение и настройка ElasticSearch с PHP
Во второй части той статьи мы рассмотрим пример работы с Elasticsearch из PHP. В результате чего, напишем простой скрипт по добавлению данных в индекс из PHP, и их поиск.
Для выполнения запросов к серверу Elasticsearch из PHP, мы могли бы использовать обычный curl для всех запросов, как мы делали в первом секции перед этим. Однако более удобным вариантом будет использовать PHP библиотеку elasticsearch/elasticsearch , которую установим через composer.
composer require elasticsearch/elasticsearch
После того, как composer установит библиотеку, в папке vendor появится папка elasticsearch .
Теперь, создадим файл idnex.php , чтобы проверить работу этой библиотеки:
setHosts([‘localhost:9200’]) // указываем, в виде массива, хост и порт сервера elasticsearch ->build(); $data = $client->search([ ‘index’ => ‘users’, ‘type’ => ‘user’, ‘body’ => [ ‘query’ => [ ‘match’ => [ ‘site’ => ‘badcode.ru’ ] ] ] ]); echo », print_r($data, true), »;
В строке . ->setHosts([‘localhost:9200’]) указываем, по какому адресу находится сервер Elasticsearch. Ввиду того, что он установлен локально на 9200 порту, то мы и указали localhost:9200 .
Дальше, вызываем метод поиска, передав нужные параметры:
$data = $client->search([ ‘index’ => ‘users’, // имя индекса ‘type’ => ‘user’, // тип ‘body’ => [ ‘query’ => [ ‘match’ => [ ‘site’ => ‘badcode.ru’ ] ] ] ]);
Для текущего примера мы указали параметры для поиска, означающие, что нужно получить все документы, из индекса users , типа user , и которые имеют значение поля site равно badcode.ru (по прямому соответствию).
А строкой echo », print_r($data, true), »; мы просто печатаем ответ от сервера на страницу. Благодаря тегам ответ от сервера становится более читаемым и удобным для восприятия. 
И здесь вы можете увидеть, что мы получили 2 результата, которые соответствуют истине.
Создание списка найденных результатов
Для завершения этой статьи, я обработаю полученные результаты от Elasticsearch, и сделаю удобный вывод полученных данных в HTML шаблоне.
Для начала, удалим строку, которая печатала полный ответ: echo », print_r($data, true), »; .
После чего, пройдёмся по полученному массиву данных, и создадим на его основе свой, содержащий только нужные нам данные:
$results = array_map(function($item) < return $item[‘_source’]; >, $data[‘hits’][‘hits’]);
Я использовал функцию array_map для того, чтобы преобразовать массив с множеством ненужных мне данных, в удобный, содержащий только данные о найденных пользователях [firstname, nickname, site] .
И, после, можем распечатать результаты в HTML-шаблоне:
foreach($results as $result) < echo «User: () —
«; >

В итоге, получился такой результат:
Резюме
В этой статье я рассказал, что такое Elasticsearch, написал небольшой гайд по работе с ним, для чего он нужен, как делать индексы в elasticsearch, описал его базовые понятия и термины для чайников. Так же, показал, как работать с Elasticsearch из PHP, как добавлять документы, искать их, продемонстрировав примеры запросов, и как они строятся. А так, же, как обрабатывать ответ от Elasticsearch в PHP, как делать поиск.
Дальше будут более продвинутые примеры, агрегации, настройка анализаторов, работа с Laravel, массивами, связями и т.д.
А пока что, советую детальнее изучить документация.

В серці. Назавжди.
Вчора у мене помер однокласник. А сьогодні бабуся. І хто б міг уявити, що цей рік принесе війну, смерть товариша, та смерть члена сім’ї? Це боляче. Проте це добре нагадування про те, як швидко тече час. І як його ціна збільшується кожної марно витраченої секунди. І я не скажу щось
20 мая 2022 г. 1 min read

Ось такий він, руський мир
«Руський мир» — звучить дуже сильно та виправдовуюче. Гарна обгортка виправдання слабкості, аморальності та нікчемності своїх дійсних намірів. Руський мир, який дуже солодко звучить для всіх, хто хоче закрити очі на факт повномасштабної війни. Дуже добре виправдання вбивства для купки звірів. Втім, це ж росія, в якій все виглядає логічно
16 апр. 2022 г. 3 min read

Перехват запросов и ответов JavaScript Fetch API
Перехватчики — это блоки кода, которые вы можете использовать для предварительной или последующей обработки HTTP-вызовов, помогая в обработке глобальных ошибок, аутентификации, логирования, изменения тела запроса и многом другом. В этой статье вы узнаете, как перехватывать вызовы JavaScript Fetch API. Есть два типа событий, для которых вы можете захотеть перехватить HTTP-вызовы:
Источник: badtry.net
Elasticsearch что это за программа
В этом разделе помещены уроки по PHP скриптам, которые Вы сможете использовать на своих ресурсах.

Фильтрация данных с помощью zend-filter
Когда речь идёт о безопасности веб-сайта, то фраза «фильтруйте всё, экранируйте всё» всегда будет актуальна. Сегодня поговорим о фильтрации данных.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 10 Июня 2017 Просмотров: 22973 Комментариев: 0

Контекстное экранирование с помощью zend-escaper
Обеспечение безопасности веб-сайта — это не только защита от SQL инъекций, но и протекция от межсайтового скриптинга (XSS), межсайтовой подделки запросов (CSRF) и от других видов атак. В частности, вам нужно очень осторожно подходить к формированию HTML, CSS и JavaScript кода.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 9 Июня 2017 Просмотров: 18254 Комментариев: 0

Подключение Zend модулей к Expressive
Expressive 2 поддерживает возможность подключения других ZF компонент по специальной схеме. Не всем нравится данное решение. В этой статье мы расскажем как улучшили процесс подключение нескольких модулей.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 7 Июня 2017 Просмотров: 12097 Комментариев: 0

Совет: отправка информации в Google Analytics через API
Предположим, что вам необходимо отправить какую-то информацию в Google Analytics из серверного скрипта. Как это сделать. Ответ в этой заметке.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 6 Июня 2017 Просмотров: 20149 Комментариев: 0

Подборка PHP песочниц
Подборка из нескольких видов PHP песочниц. На некоторых вы в режиме online сможете потестить свой код, но есть так же решения, которые можно внедрить на свой сайт.
Автор/переводчик: Станислав Протасевич
Сложность:
Создан: 4 Июня 2017 Просмотров: 28896 Комментариев: 0

Совет: активация отображения всех ошибок в PHP
При поднятии PHP проекта на новом рабочем окружении могут возникнуть ошибки отображение которых изначально скрыто базовыми настройками. Это можно исправить, прописав несколько команд.
Источник: ruseller.com