
Что такое стек
Постепенно осваиваем способы организации и хранения данных. Уже было про деревья, попробуем про стеки. Это для тех, кто хочет в будущем серьёзно работать в ИТ: одна из фундаментальных концепций, которая влияет на качество вашего кода, но не касается какого-то конкретного языка программирования.
Стек — это одна из структур данных. Структура данных — это то, как хранятся данные: например, связанные списки, деревья, очереди, множества, хеш-таблицы, карты и даже кучи (heap).
Как устроен стек
Стек хранит последовательность данных. Связаны данные так: каждый элемент указывает на тот, который нужно использовать следующим. Это линейная связь — данные идут друг за другом и нужно брать их по очереди. Из середины стека брать нельзя.
Главный принцип работы стека — данные, которые попали в стек недавно, используются первыми. Чем раньше попал — тем позже используется. После использования элемент стека исчезает, и верхним становится следующий элемент.
ElasticSearch что это такое — ElasticSearch уроки
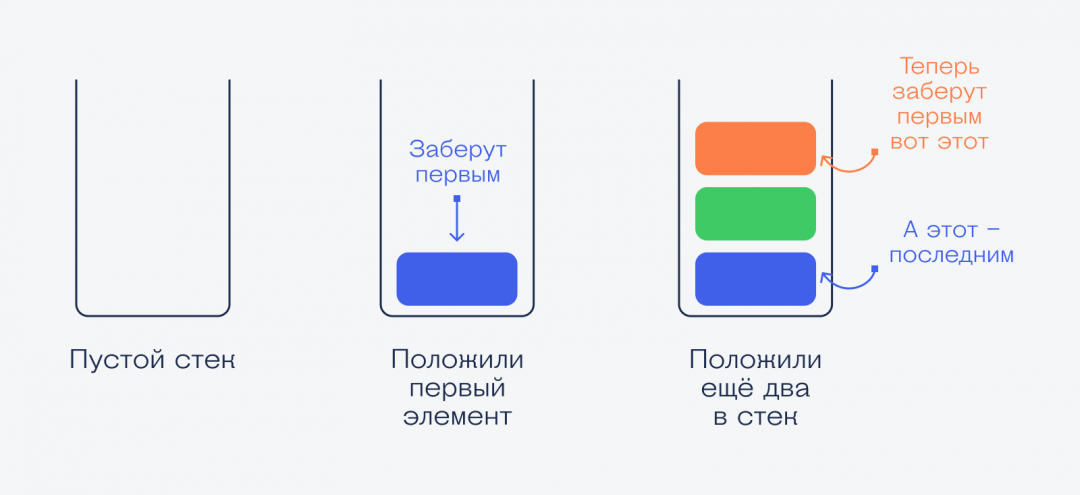
Классический способ объяснения принципов стека звучит так: представьте, что вы моете посуду и складываете одинаковые чистые тарелки стопкой друг на друга. Каждая новая тарелка — это элемент стека, а вы просто добавляете их по одной в стек.
Когда кому-то понадобится тарелка, он не будет брать её снизу или из середины — он возьмёт первую сверху, потом следующую и так далее.
Есть структура данных, похожая на стек, — называется очередь, или queue. Если в стеке кто последний пришёл, того первым заберут, то в очереди наоборот: кто раньше пришёл, тот раньше ушёл. Можно представить очередь в магазине: кто раньше её занял, тот первый дошёл до кассы. Очередь — это тоже линейный набор данных, но обрабатывается по-другому.
Стек вызовов
В программировании есть два вида стека — стек вызовов и стек данных.
Когда в программе есть подпрограммы — процедуры и функции, — то компьютеру нужно помнить, где он прервался в основном коде, чтобы выполнить подпрограмму. После выполнения он должен вернуться обратно и продолжить выполнять основной код. При этом если подпрограмма возвращает какие-то данные, то их тоже нужно запомнить и передать в основной код.
Чтобы это реализовать, компьютер использует стек вызовов — специальную область памяти, где хранит данные о точках перехода между фрагментами кода.
Допустим, у нас есть программа, внутри которой есть три функции, причём одна из них внутри вызывает другую. Нарисуем, чтобы было понятнее:
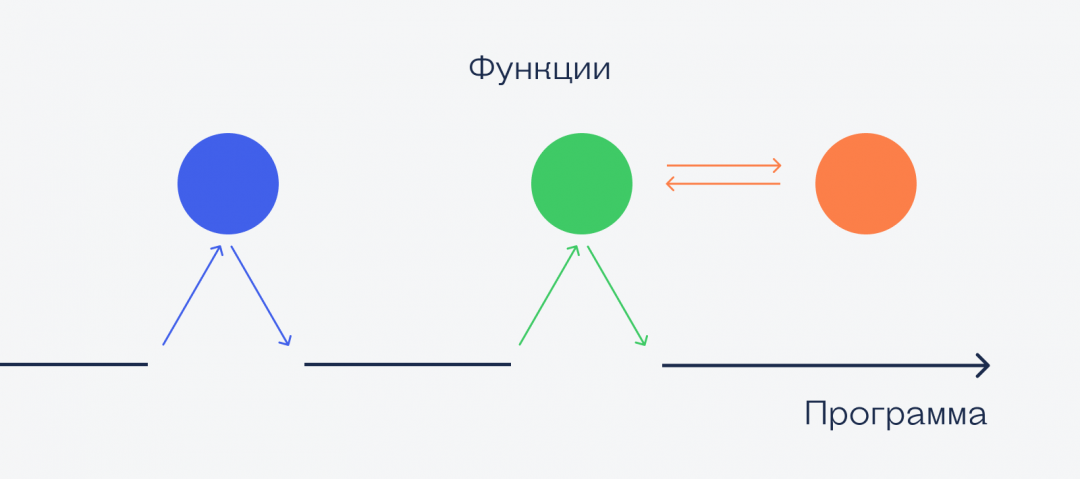
Программа запускается, потом идёт вызов синей функции. Она выполняется, и программа продолжает с того места, где остановилась. Потом выполняется зелёная функция, которая вызывает красную. Пока красная не закончит работу, все остальные ждут. Как только красная закончилась — продолжается зелёная, а после её окончания программа продолжает свою работу с того же места.
Про Elastic Stack за 15 минут.
А вот как стек помогает это реализовать на практике:
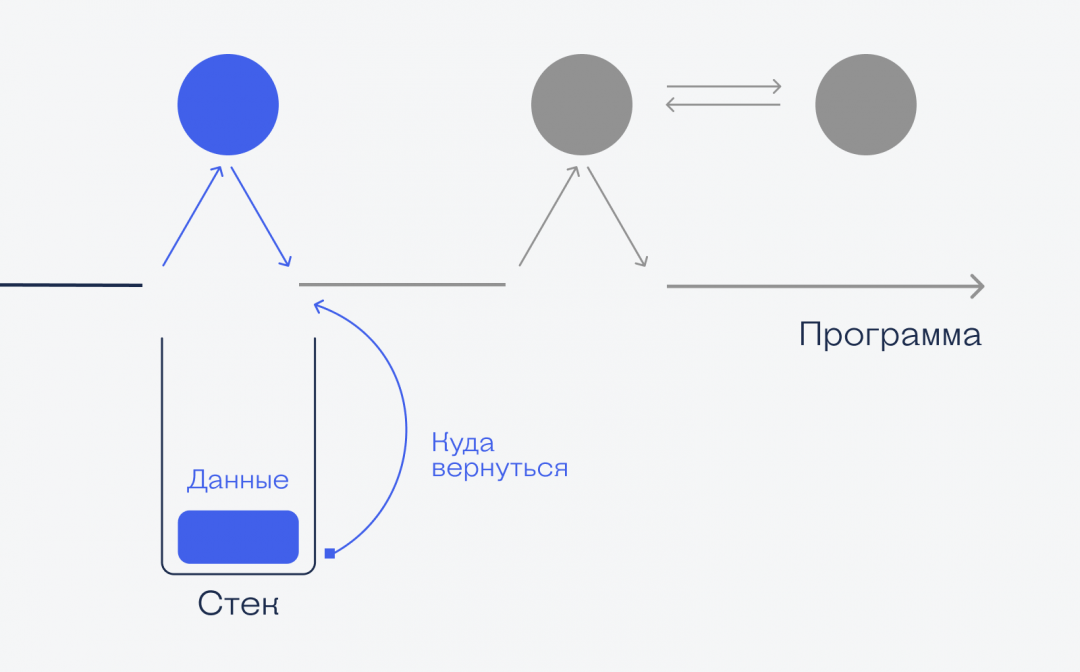
Программа дошла до синей функции, сохранила точку, куда ей вернуться после того, как закончится функция, и если функция вернёт какие-то данные, то программа тоже их получит. Когда синяя функция закончится и программа получит верхний элемент стека, он автоматически исчезнет. Стек снова пустой.
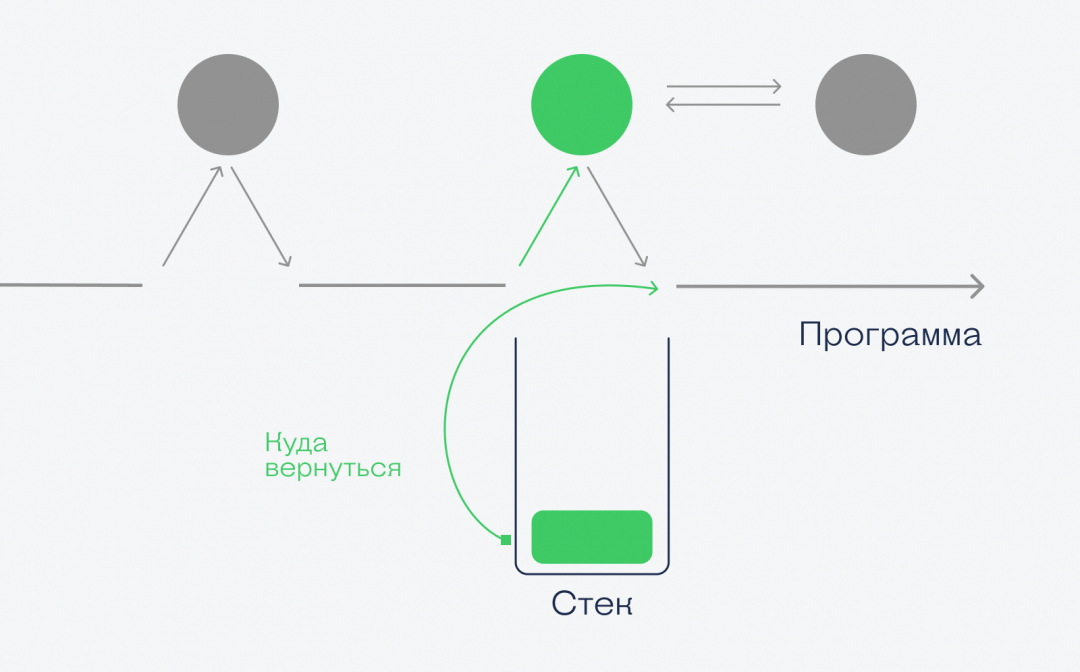
С зелёной функцией всё то же самое — в стек заносится точка возврата, и программа начинает выполнять зелёную функцию. Но внутри неё мы вызываем красную, и вот что происходит:
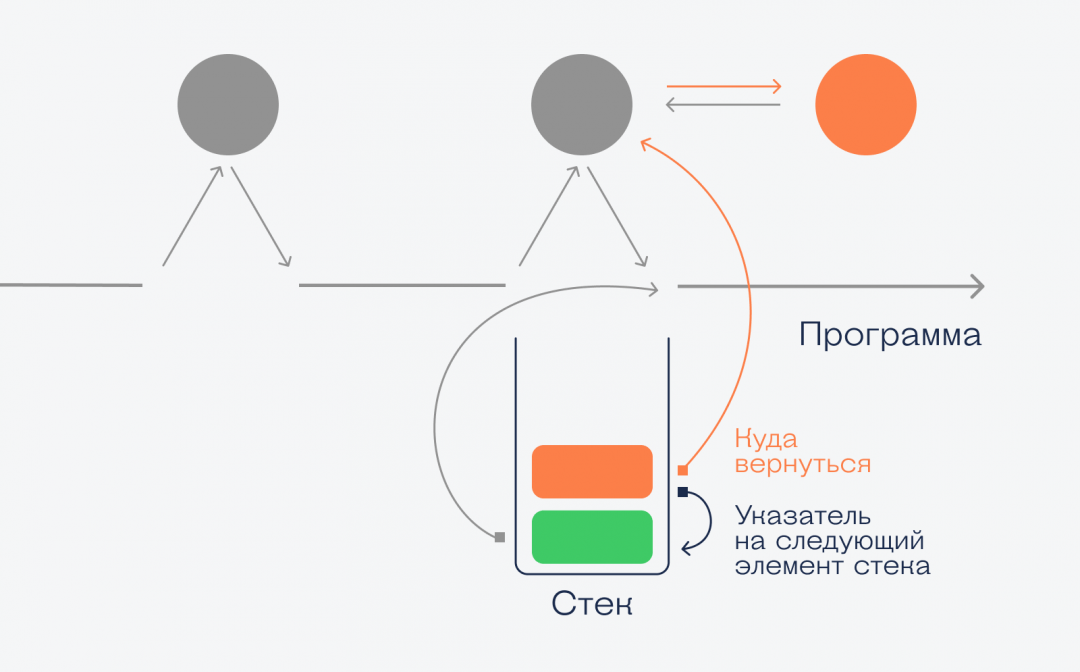
При вызове красной функции в стек помещается новый элемент с информацией о данных, точке возврата и указанием на следующий элемент. Это значит, что когда красная функция закончит работу, то компьютер возьмёт из стека адрес возврата и вернёт управление снова зелёной функции, а красный элемент исчезнет. Когда и зелёная закончит работу, то компьютер из стека возьмёт новый адрес возврата и продолжит работу со старого места.
Переполнение стека
Почти всегда стек вызовов хранится в оперативной памяти и имеет определённый размер. Если у вас будет много вложенных вызовов или рекурсия с очень большой глубиной вложенности, то может случиться такая ситуация:
- рекурсия всё работает и работает;
- при каждом новом витке рекурсии в стек добавляются новый элемент;
- когда элементов будет слишком много, память закончится, новые элементы некуда будет складывать и произойдёт переполнение стека.
Переполнение — это плохо: данные могут залезать в чужую область памяти и записывать себя вместо прежних данных. Это может привести к сбою в работе других программ или самого компьютера. Ещё таким образом можно внедрить в оперативную память вредоносный код: если программа плохо работает со стеком, можно специально вызвать переполнение и записать в память что-нибудь вредоносное.
Стек данных
Стек данных очень похож на стек вызовов: по сути, это одна большая переменная, похожая на список или массив. Его чаще всего используют для работы с другими сложными типами данных: например, быстрого обхода деревьев, поиска всех возможных маршрутов по графу, — и для анализа разветвлённых однотипных данных.
Стек данных работает по такому же принципу, как и стек вызовов — элемент, который добавили последним, должен использоваться первым.
Что дальше
А дальше поговорим про тип данных под названием «куча». Да, такой есть, и с ним тоже можно эффективно работать. Стей тюнед.
Источник: thecode.media
Elastic stack что это за программа
Рано или поздно любой крупный бизнес сталкивается с проблемой сбора и хранения аналитики. Информация о бизнес-процессах стремительно растет и накапливается, все сложнее становится осуществлять поиск, хранение, индексацию и анализ критически важных данных.
В качестве примера рассмотрим веб-портал, собирающий информацию об активности пользователей, к примеру:
- — сколько пользователей просмотрели обучающие материалы,
- — какие материалы были просмотрены,
- — какова активность пользователей,
- — с каких устройств и браузеров пользователи заходят на сайт.
Допустим, на портале около зарегистрировано примерно 10 000 пользователей и хранить все данные в базе сайта не получается: во-первых ложится большая нагрузка на сам сайт и как следствие падает скорость работы и увеличивается время отклика, во-вторых накопленные данные крайне сложно проанализировать и выдать хоть какие-то отчеты и графики.
Отсюда получается вполне логичное решение – вынести весь сбор, хранение и анализ информации на отдельный сервер, на котором будет развернута система полнотекстового поиска.
Что нам дает ELK?
Итак, перечислим основные задачи, которые необходимо решить:
- 1. Добавление больших объемов информации без существенной нагрузки на БД.
- 2. Поиск и анализ по большому количеству критериев.
- 3. Сбор статистики и дальнейший ее показ в удобном виде.
Elasticsearch – популярная поисковая система в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска.
ES является ядром ELK-стека (Elastic Stack), в состав которого, помимо Elasticsearch, входят следующие продукты:
Logstash – инструмент сбора, преобразования и сохранения в общем хранилище событий из различных источников (файлы, базы данных, логи и пр.) в реальном времени;
Kibana – веб-интерфейс для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в его индексах ES через динамические панели мониторинга, таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени;
FileBeat – агент на серверах для отправки различных типов оперативных данных в ES.
В рамках нашей разрабатываемой системы компоненты ELK взаимодействуют следующим образом:
Elasticsearch — основное ядро всей системы, реализующий функции базы данных, поиск и анализ данных. Быстрый и гибкий поиск обеспечивается за счет анализаторов текста, нечеткого поиска. Немаловажно отметить, что наличие REST API позволяет модифицировать, добавлять, просматривать, удалять данные, а также осуществлять интеграцию со сторонними сервисами.
Главная особенность Elasticsearch — отсутствие четкой структуры для хранения данных, в отличие от традиционной реляционной СУБД, где данные хранятся в строго структурированном виде с конкретными типами и размерами.
Kibana — система визуализации ES.
Filebeat — основная задача — сбор и хранение логов
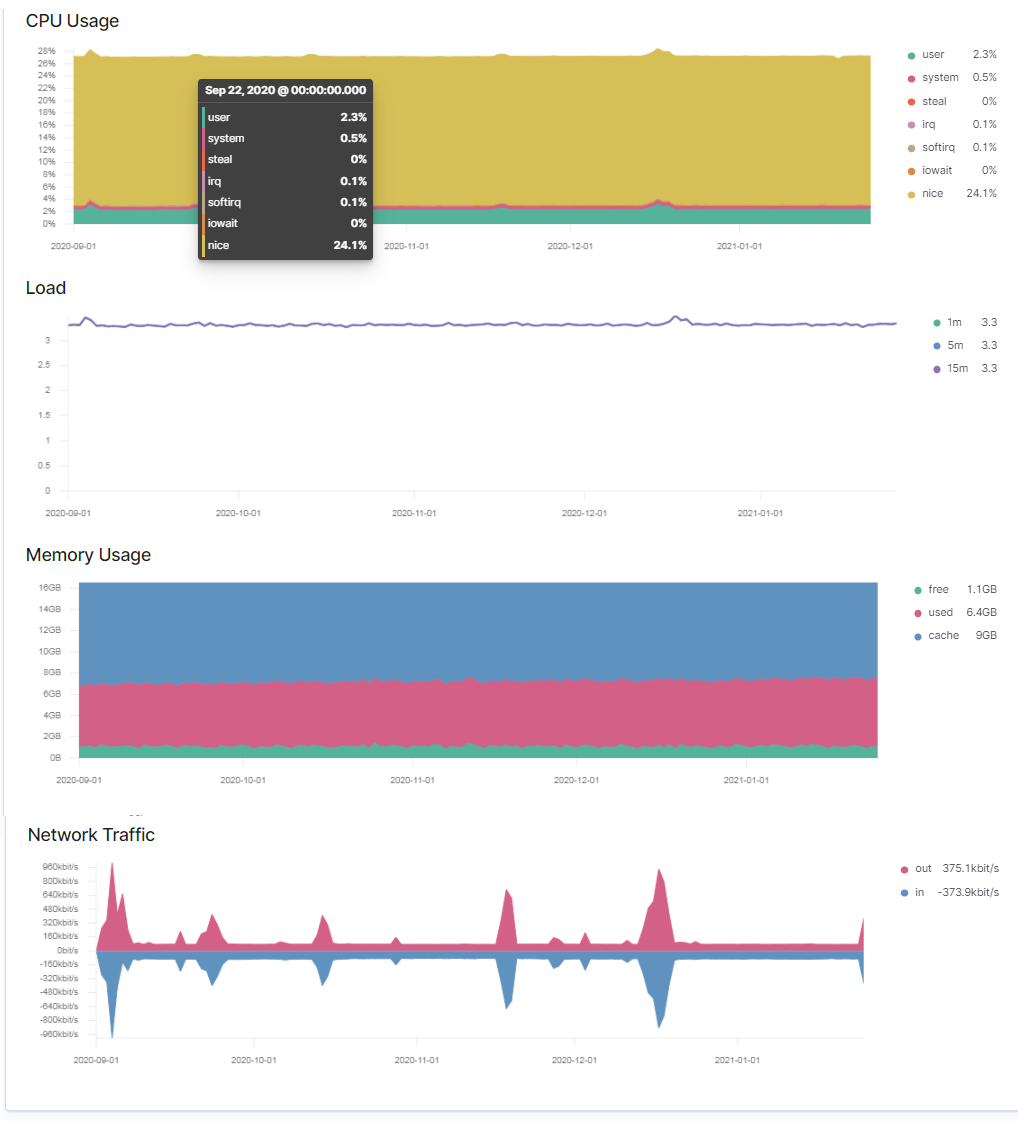
Metricbeat — осуществляет сбор статистики нагрузки CPU и памяти (глобально и по отдельным процессам), с дальнейшей передачей Elasticsearch
X-Pack — функционал, связанный с обеспечением безопасности ES и разграничением прав пользователей.
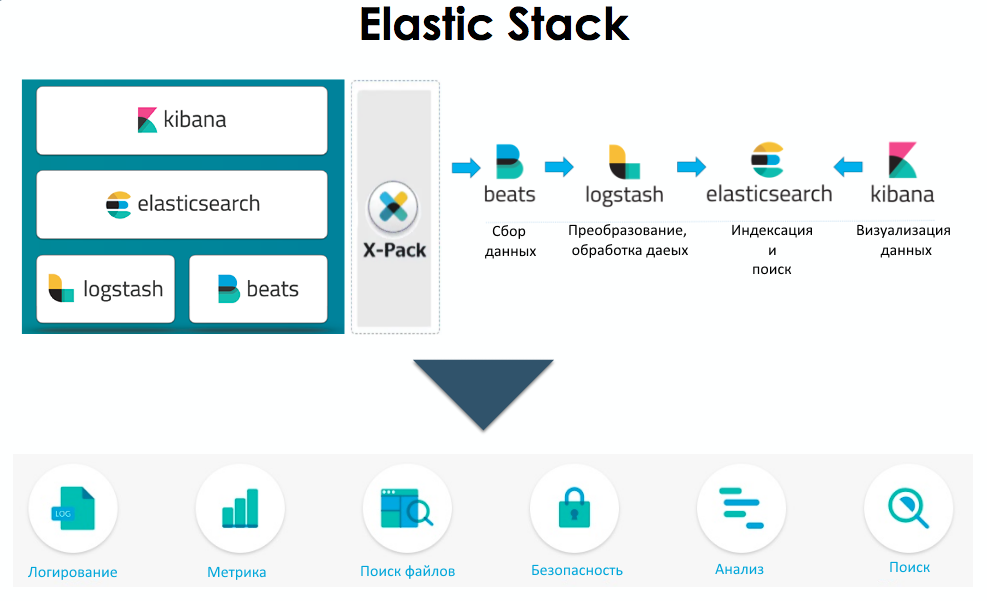
Elastic Stack — применение REST API
Elasticsearch имеет многофункциональный REST API, работающий на протоколе HTTP, что позволяет без проблем интегрировать ES с любым сторонним сервисом.
Рассмотрим реализацию задачи по интеграции веб-сервиса на Битриксе:
- Имеется образовательный портал с большим количеством пользователей (от 10 000).
- Необходимо собирать статистику поведения пользователей для дальнейшего анализа: количество посещений, с каких устройств и браузеров заходят пользователи, сколько было просмотрено видеоматериалов, сколько в среднем по времени просматривается материалы, какие ресурсы сайта пользуются популярностью и т. д.
Схема интеграции портала показана на рисунке ниже:
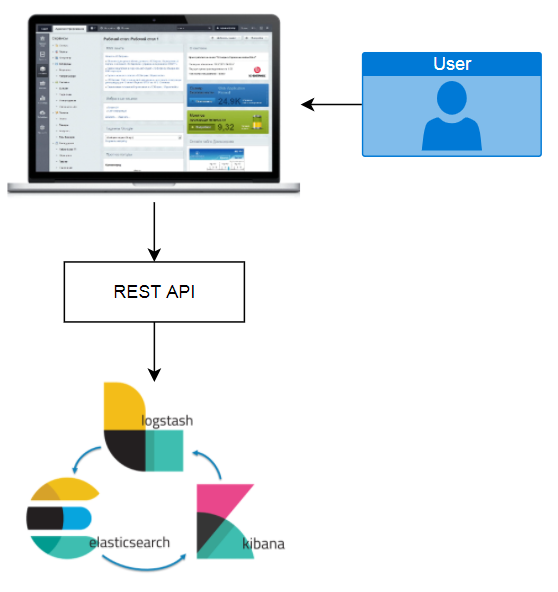
Как видно на рисунке, интеграция ES Stack с сторонним веб-ресурсом достаточно проста: необходимо всего лишь организовать сбор статистики на самом сайте и дальше просто обычными HTTP запросами отправляем наши данные на сервер с Elasticsearch, который принимает входящие данные для дальнейшего анализа.
Установка и настройка ES
- Elastic Stack достаточно прост в установке и включает в себя следующие шаги:
- Установка и настройка Elasticsearch.
- Установка и настройка Kibana.
- Установка и настройка Logstash.
- Установка и настройка Metricbeat.
- Установка и настройка X-Pack.
Пример внедрения Elastic Stack
Итак, после установки Elastic Stack мы можем работать с системой (главный экран):
На рисунке ниже приведены основные параметры, по которым собирается статистика:
- Запрос контроля присутствия;
- Статистика по нажатым кнопкам;
- Количество пользователей, посетивших трансляцию с обучающим материалом;
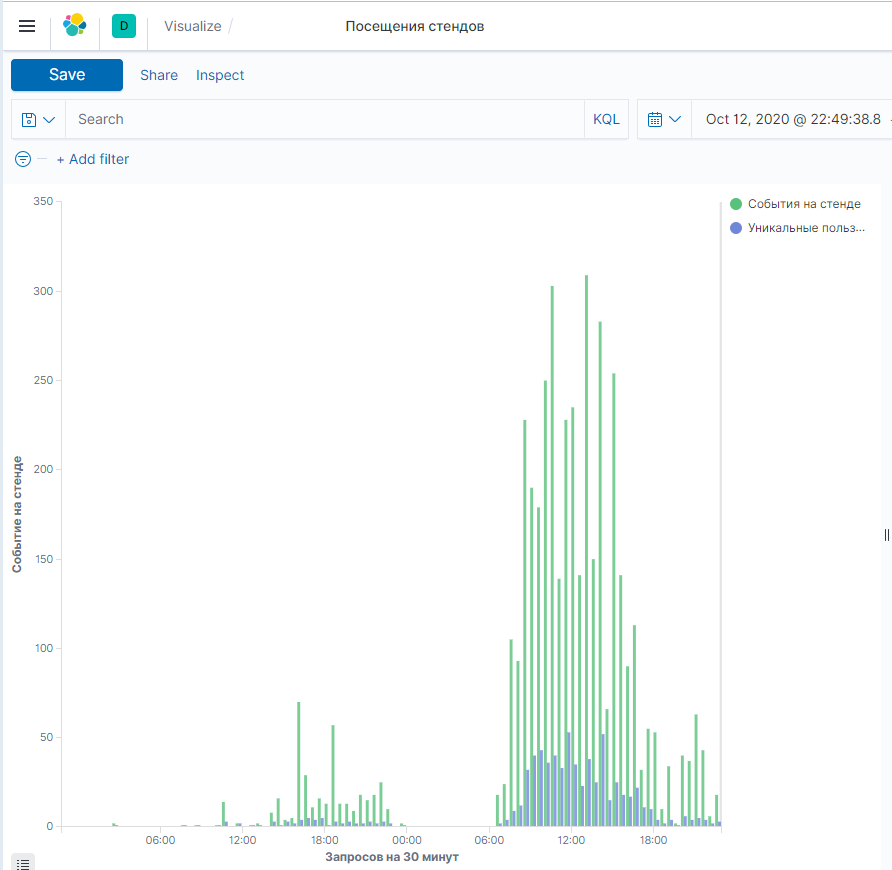
- Посещение пользователями страниц сайта.
Ниже, на рисунках приведен пример визуализации основных отслеживаемых параметров.
Статистика активности пользователей:
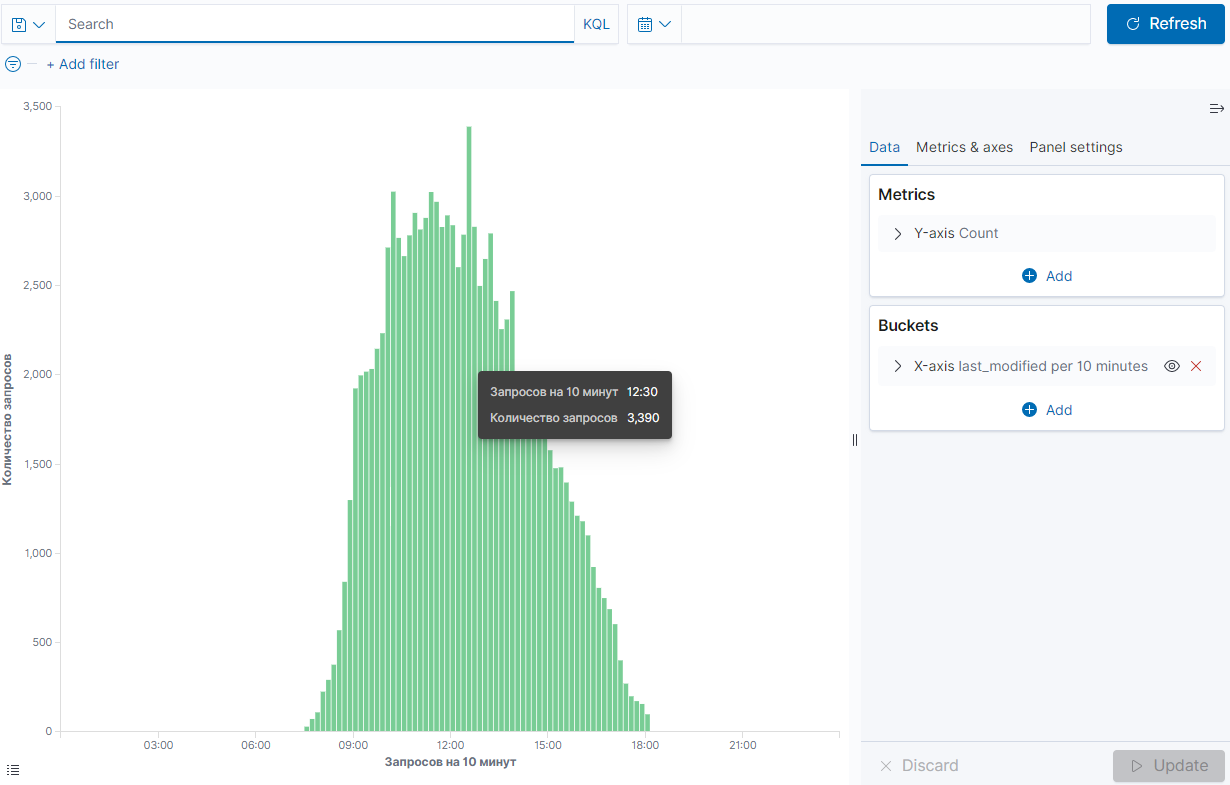
Статистика по нажатым кнопкам на трансляциях с обучающим материалом:
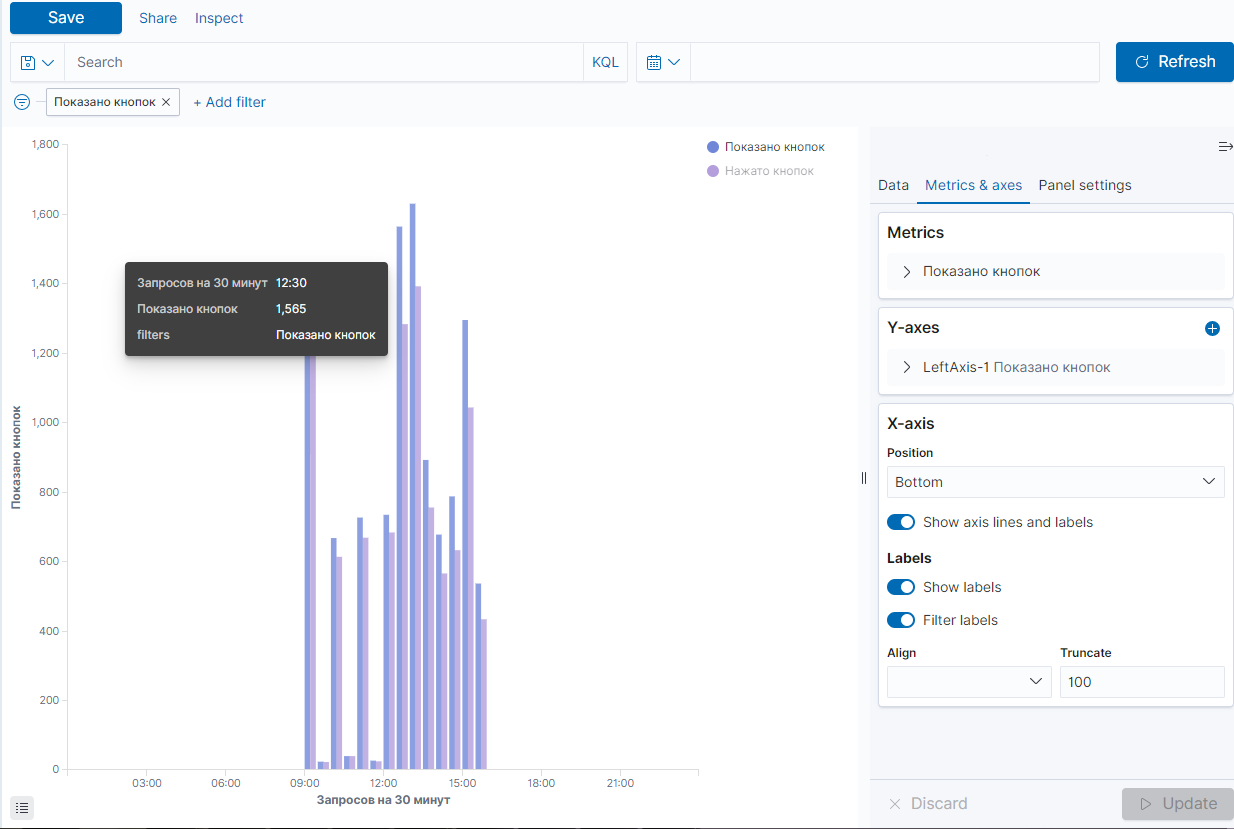
Количество зарегистрированных и активных пользователей:
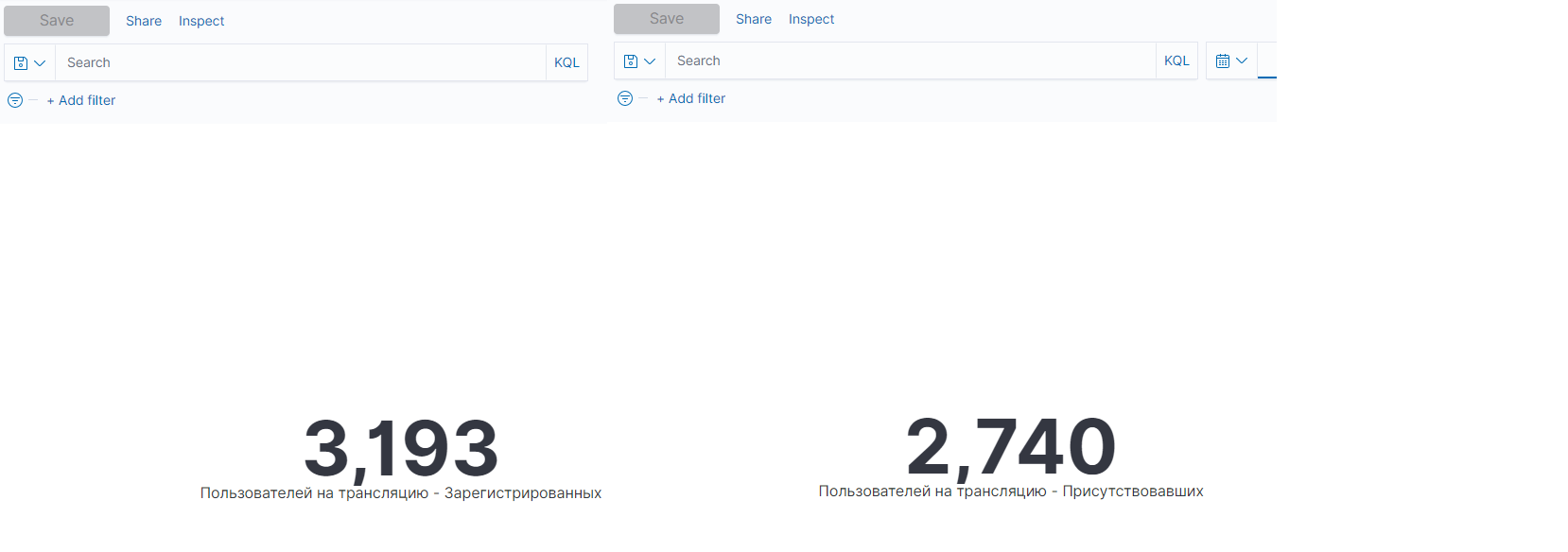
Количество пользователей, просматривающих обучающие материалы:
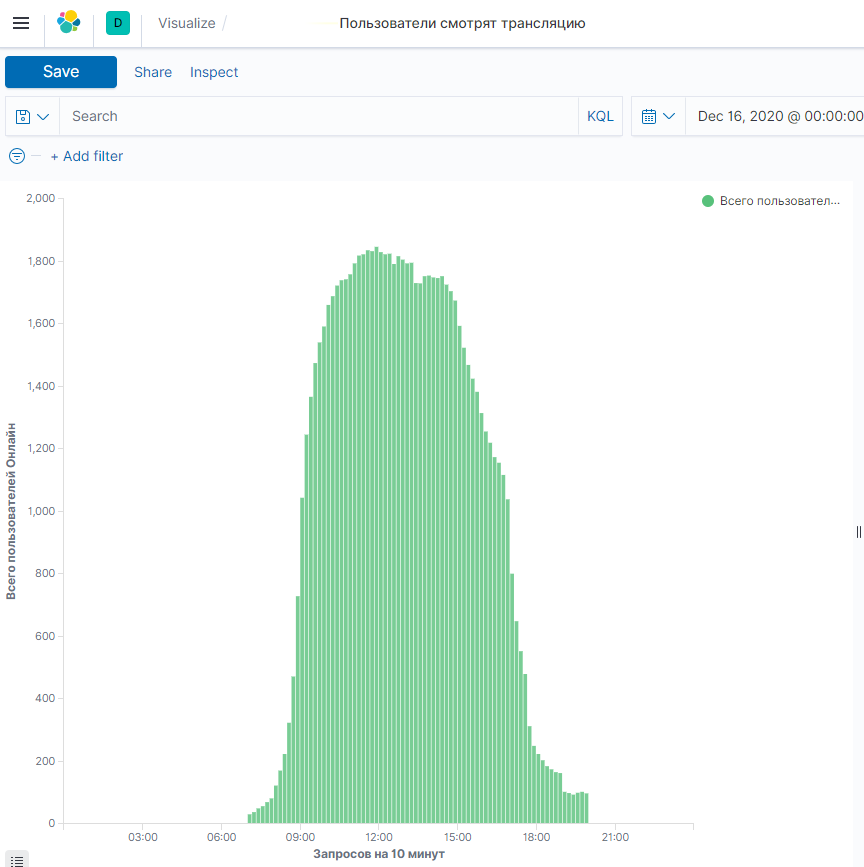
Статистика по пользователям, посещавших страницу с обучающим материалом:
При помощи модуля Metricbeat можно посмотреть статистику нагрузки CPU и памяти.
Вывод
Как мы видим Elasticsearch — это мощная поисковая система, способная решать самые разные задачи. Немаловажно отметить, что внедрение ELK Stack не требует как больших финансовых так и временных затрат.
Система легко устанавливается, легко настраивается и при необходимости масштабируется.
Источник: vis.center
Elastic stack что это за программа
Toggle navigation
- Главная
- Главная
- Вопросы и ответы
- Хранение и управление
- Поделиться файлами
- Быстрая загрузка
- Безопасный и надежный
- Регистрация
Threat Hunting with Elastic Stack.rar
Идет проверка файла. sec.
| HTML-ссылка | Постоянная ссылка для скачивания на этот файл: https://wdfiles.ru/6c4332 |
| HTML Code: | Скачать Threat Hunting with Elastic Stack.rar — загрузить файл |
| Длинная ссылка на этот файл: | https://wdfiles.ru/6c4332/Threat Hunting with Elastic Stack.rar |
| Forum Code | [url]https://wdfiles.ru/6c4332[/url] |
| QR-код: | QR-код это ссылка для мобильных устройств
подойдёт для вставки в документы или презентации. Приветствуем Вас на файлообменнике WdFiles.ru! Ресурс WDfiles.RU был задуман как бесплатный файлообменник. Согласитесь, удобно с его помощью делиться файлами, или перемещать их с одного устройства на другое!
Всем спасибо за использование нашего ресурса! Источник: wdfiles.ru Elastic stack что это за программаЯ использую клиент Python elasticsearch для подключения к elasticsearch. При попытке добавить сопоставление в индекс я получаю следующее предупреждение: es.indices.put_mapping (index = index, body = mappings) / usr / local / . спросил 1 час назад
1,041 1 1 золотой значок 10 10 серебряных значков 24 24 бронзовых знака У Elasticsearch внезапная высокая загрузка ЦП с сборщиком мусораМы используем ELS v 7.5.2 на узлах (кластер из 7 узлов) с общим объемом ОЗУ 32 ГБ, 16 ГБ выделено для ES. Узлы Elasticsearch время от времени испытывают высокие скачки ЦП из-за GC. Любое предложение или идея .
спросил 2 часа назад Обновить значение поля в индексе на основе его значения в другом индексеЕсть index_A, который содержит, скажем, около 10K документов. У него много полей, таких как field_1, field_2, . field_n, и одно из полей — product_name. Затем есть еще один index_B, содержащий около 10 . спросил 13 часов назад
1,024 13 13 серебряных значков 29 29 бронзовых знаков Подсчитать количество внутренних элементов свойства массива (включая повторяющиеся значения)
Учитывая, что у меня есть следующие записи. [ <«profile»: «123», «inner»: [<«name»: «John»>. 17 просмотров Поиск определенной строки в поле сообщения в Kibana
спросил 2 дня назад Elasticsearch SIEM не работает, но запрос EQL в порядкеУ меня проблемы с работой моего ELK на докере. Я сделал ssl для tls и http и попытался сделать простой EQL-запрос: последовательность по winlog.computer_name [iam where event.code == «4720»] [iam .
задан 25 окт в 12:49 Сохранение контейнера Docker для мониторинга файлов журнала [дубликат]Я пытаюсь запустить Filebeat в контейнере для отправки журналов в кластер ELK. Это автономный контейнер, в котором работает только Filebeat. Основное приложение работает отдельно, а Filebeat отслеживает .
задан 25 окт в 9:49 Имя индекса в Kibana может быть другим или должно быть таким же, как inddex, созданное logstash, когда он предоставляет данные для эластичного поиска?Я использую стек ELK в своей организации. я хотел понять конвейер через стек ELK вместе с filebeat. Я мог видеть названное имя индекса (возьмем его как XYZ), присутствующее в моем пользовательском интерфейсе кибаны .
задан 23 окт в 13:41 Обнаружение службы мониторинга работоспособности (в Elastic Stack)возможно ли в Elastic Uptime иметь какое-то обнаружение / саморегистрацию для приложений и сервисов? Чтобы приложения могли регистрировать необходимые проверки работоспособности и предупреждения без .
задан 22 окт в 8:16 Как применить учетные данные OAuth2 к Fluentd для эластичного приема?Я привык периодически принимать HTTP-запросы, а также проверять связь с моим экземпляром для приема данных. Оба полезны. Одна вещь, о которой я думал, это идея автоматизации приема http . задан 22 окт в 5:14
8 906 12 12 золотых значков 54 54 серебряных знака 111 111 бронзовых знаков Добавление нового поля в метрических битах при отправке данных в Elastic CloudТекущая ситуация: все журналы из разных кластеров смешаны в одном индексе. Я использую метрические биты, которые выполняются как наборы демонов в кластере. Нам нужны те же дашборды, где мы могли бы перечислить .
задан 21 окт в 17:39 Как получить пространство имен kubernetes в полезной нагрузке предупреждения веб-перехватчика?Кто-нибудь знает, как получить пространство имен Kubernetes в полезной нагрузке предупреждения веб-перехватчика из модуля metricbeat k8s? Или, в более общем смысле, как получить доступ к данным события для включения в полезную нагрузку? Я установил . задан 21 окт в 13:05
55 7 7 бронзовых знаков Ошибка при загрузке документов с нулевыми значениями долготы и широты (geo_point) в Elastic 7.15.Я использую опцию «Загрузить файл» для загрузки файла CSV, в котором некоторые значения долготы и широты равны нулю в Elastic 7.15. Сопоставления и конвейер загрузки приведены ниже Сопоставление . «.
задан 20 окт в 23:40 Запрос подсчета Elasticsearch уникальных значений, которые имеют более n вхождений другого значенияВ моем документе у меня есть поле eventName: sessionStart, и у меня есть поле, которое представляет идентификатор пользователя. Я пытаюсь получить число, которое будет представлять количество вернувшихся пользователей, то есть количество идентификаторов пользователей, которые . Источник: www.stackfinder.ru |



