
Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска.
Назначение и основные функциональные возможности
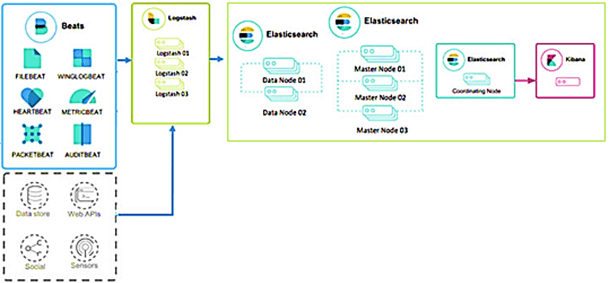
Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. ES является ядром ELK-стека (Elastic Stack), в состав которого, помимо Elasticsearch, входят следующие продукты [1]:
- Logstash– инструмент сбора, преобразования и сохранения в общем хранилище событий из различных источников (файлы, базы данных, логи и пр.) в реальном времени;
- Kibana– веб-интерфейс для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в его индексах ES через динамические панели мониторинга, таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени;
- FileBeat –агент на серверах для отправки различных типов оперативных данных в ES.
Из ключевых функциональных возможностей Elasticsearch стоит отметить следующие [2]:
Про Elastic Stack за 15 минут.
- автоматическая индексация новыхJSON-объектов, которые загружаются в базу и сразу становятся доступными для поиска, за счет отсутствия схемы согласно типичной NoSQL-концепции. Это позволяет ускорить прототипирование поисковых Big Data решений.
- поддержка восточных языков (китайский, японский, корейский);
- гибкостьпоисковых фильтров, включая нечеткий поиск и мультиарендность, когда в рамках одного объекта ES можно динамически организовать несколько различных поисковых систем;
- наличие встроенных анализаторов текста позволяет Elasticsearch автоматически выполнять токенизацию, лемматизацию, стемминг и прочие преобразования для решения NLP-задач, связанных с поиском данных.
Основные достоинства и недостатки Elasticsearch описаны здесь. Подчеркнем, что одним из главных недостатков ES считается склонность этой NoSQL-СУБД к утечкам данных из-за отсутствия встроенных средств обеспечения информационной безопасности, таких как система авторизации и ограничения прав доступа. Кроме того, после установки движок по умолчанию связывается с портом 9200 на все доступные интерфейсы, что открывает доступ к базе данных [2]. Подробнее об уязвимостях Elasticsearch читайте нашу отдельную статью.
История разработки и развития Elasticsearch
Основными ключевыми вехами в истории Elasticsearch считаются следующие:
- февраль 2010 года – Шай Бейнон (Shay Banon) выпустил первую версию системы под лицензией Apache0 [1];
- 2012 год – для коммерциализации проекта Бейнон основал нидерландскую компанию Elasticsearch BV [1];
- июнь 2014 года – стартап привлек внешнее финансирование в размере $104 миллионов [1];
- март 2015 года – компания Elasticsearch изменила название на Elastic [1];
- 2018 год – компания Elastic открыла исходный код своего коммерческого продукта X-Pack, который расширяет возможности Elasticsearch, включая обеспечение cybersecurity [3];
- 2019 год – компания Elastic сделала базовые функции обеспечения информационной безопасности ELK-стека бесплатными для всех пользователей, а не только тех, кто подписан на коммерческой основе [4].
Архитектура и принципы работы ES
ES обеспечивает горизонтально масштабируемый поиск с поддержкой многопоточности. Система основана на библиотеке Apache Lucene, которая предназначена для индексирования и поиска информации в любом типе документов. Все функции Lucene доступны через API-интерфейсы на JSON и Java. ES позволяет работать с GET- запросами в реальном времени, но не поддерживает распределённые транзакции. Бесшовная интеграция с Kibana гарантирует легкую управляемость по HTTP-интерфейсу с помощью JSON-запросов за счет REST API.
ЧТО ТАКОЕ ELASTICSEARCH? ВВОДНЫЙ УРОК
В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер. Поисковые индексы можно разделить на сегменты, реплицировав каждый из которых несколько раз. Это обеспечивает отказоустойчивость системы. На узле ES-кластера может размещаться несколько сегментов.
Каждый узел кластера действует как координатор для делегирования операций правильному сегменту с автоматической перебалансировкой и маршрутизацией. Связанные данные часто хранятся в одном и том же индексе из одного или нескольких первичных сегментов и нескольких реплик. После создания индекса количество первичных сегментов нельзя изменить. Долгосрочное хранение индекса обеспечивает шлюз, позволяя восстанавливать индекс при сбое сервера [5].
Где используется Elasticsearch: компании и Big Data проекты
Благодаря широкому набору функциональных возможностей, особенно полнотекстовому поиску по множеству языков и аналитике в реальном времени, Elasticsearch активно применяется в различных Big Data системах крупных и средних компаний по всему миру. Из наиболее известных зарубежных пользователей стоит отметить корпорации Netflix, IBM, Facebook, Amazon, GitHub, Wikimedia, CERN, Mozilla, Adobe [2]. В России ES применяется в проектах Альфа-Банка, облачной платформе автоматизации рекрутмента Potok.io, сети лабораторий «Центр молекулярной диагностики» (CMD), ИТ-компании «Инфотех-Групп» и многих других предприятий, о чем мы писали здесь.
Источники
- https://ru.wikipedia.org/wiki/Elasticsearch
- https://ru.bmstu.wiki/Elastic_Elasticsearch
- https://habr.com/ru/post/443528/
- https://www.elastic.co/blog/security-for-elasticsearch-is-now-free
- https://ru.bmstu.wiki/Elastic_Stack
Источник: bigdataschool.ru
Что такое ELK-стек: установка и настройка Elasticsearch, Logstash и Kibana
Эта статья — введение в стек ELK. Будет полезна для начинающих специалистов, которые хотят работать с обилием информации: машинное обучение, информационная безопасность, БД, мониторинг и анализ служебной информации ИТ-ландшафта, отчетность, логирование, аналитика. С помощью ELK-стека можно создать мощный и, что важно, удобный инструмент, который позволит вести журналы и анализировать состояние любой информационной системы компании, чтобы оперативно реагировать на ошибки и инциденты в ней.
Что такое стек ELK
Название стека представляет собой аббревиатуру первых букв трех открытых проектов, разрабатываемых и поддерживаемых компанией Elastic:
E lasticsearch
Этот набор компонентов обеспечивает удобное централизованное логирование (ведение журналов) с разных серверов. ELK stack позволяет надежно и безопасно получать данные из любого источника во всех форматах и работать с этими данными: осуществлять поиск по ним, анализировать и визуализировать их в режиме real-time (NRT). В профессиональной среде ELK-стек также называют «эластичный стек», обыгрывая отсылку к названию компании-разработчика.
Что такое Elasticsearch
Elasticsearch (ES) — сердце стека ELK. Это распределенная RESTful-система на основе JSON, которая сочетает в себе функции NoSQL-базы данных (сохраняет все собранные данные), поисковой системы и аналитической системы. Изначально это была утилита полнотекстового поиска поверх поисковой системы Apache Lucene с некоторыми расширенными возможностями (например, легкой репликацией и масштабированием). Эти дополнительные возможности, а также простота использования и высокая работоспособность даже в изначальной конфигурации сделали Elasticsearch крайне удобной для высоконагруженных проектов с большими данными и сложными функциями поиска.
Со временем ES стали использовать не только для поиска, например, по товарам в интернет-магазинах, но и основывать на ней свои разработки по централизованному хранению логов и аналитике — настолько решение стало удобным. К тому же вокруг него сформировалось компетентное и отзывчивое сообщество, которое всегда подскажет, как настроить ваш ES-кластер под любые задачи.
Итак, Elasticsearch — это большое, быстрое и хорошо масштабируемое нереляционное хранилище данных, которое стало отличным инструментом для поиска и аналитики журналов благодаря мощности, простоте, документам JSON без схем, поддержке разных языков и геолокации. Система может быстро обрабатывать большие объемы журналов, индексировать системные логи по мере поступления и выполнять запросы к ним в режиме реального времени.
Какие бизнес-задачи может решать Elasticsearch:
- агрегировать большие объемы любых данных с разных площадок (например, товары со множества интернет-магазинов), осуществлять фильтрацию и поиск по различным свойствам продукции;
- автоматически обрабатывать огромные объемы опросников и анкет;
- быстро вычислять нужные показатели в данных, собранных из различных систем, для комплексной аналитики бизнес-процессов;
- анализировать большие объемы неструктурированной статистической информации;
- хранить данные без схемы или создать схему для данных;
- управлять записью данных через многодокументные API;
Что такое Logstash
Logstash в стеке ELK представляет собой конвейер по парсингу данных (логов событий) одновременно из множества источников ввода и их обработки для дальнейшего использования в Elasticsearch. С помощью этой утилиты в сообщениях системных событий можно выделять поля и их значения, фильтровать и редактировать данные. Настраивается она через конфигурационные файлы.
В Logstash все события с использованием внутренних очередей последовательно проходят через три фазы:
- Input — передача журналов для их обработки в машинно-понятный вид. Здесь можно настроить: из какой папки читать новые или постоянно дозаписываемые файлы; на какой порт и по какому протоколу будут приходить логи.
- Filter — это поле для управления сообщением, приходящим на Logstash, с набором условий для выполнения определенного действия или события. Здесь можно настроить парсер логов: редактирование значений, добавление и удаление новых параметров, разбор полей.
- Output — здесь можно настроить, куда отправлять разобранный лог. Если в Elasticsearch, то нужен JSON-запрос, в котором отправляются поля со значениями. Если это дебаг, то можно выводить в stdout или просто записывать в файл.
Logstash позволяет централизовать обработку большого объема структурированных и неструктурированных данных и событий. Для подключения к различным типам источников ввода и платформ утилита поддерживает более 200 подключаемых плагинов, благодаря которым упрощается доступ к разным данным.
Источник: dzen.ru
Elasticsearch: что это такое и зачем он вам нужен?

Я использовал Elasticsearch, когда это был проект одного человека от Шэя Бэннона, первоначального создателя. В то время, примерно в 2010 году, я искал технологию поиска, которая была бы масштабируемой и простой в использовании, предпочтительно с открытым исходным кодом. Меня не устраивали коммерческие и некоммерческие продукты — пока я не нашел Elasticsearch. Какой ветерок!
Его было легко использовать, потому что это был весь JSON; он очень хорошо масштабировался; это было невероятно быстро и с открытым исходным кодом! С тех пор я использую Elasticsearch во всех ситуациях и в самых разных продуктах и до сих пор очень люблю его.
Для начала давайте посмотрим, что Elastic, компания, стоящая за Elasticsearch, сначала скажет об этом продукте:
Elasticsearch — это распределенная система поиска и аналитики с открытым исходным кодом для всех типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные. . Elasticsearch построен на Apache Lucene и впервые был выпущен в 2010 году компанией Elasticsearch N.V. (теперь известной как Elastic). Elasticsearch, известный своими простыми API-интерфейсами REST, распределенным характером, скоростью и масштабируемостью, является центральным компонентом Elastic Stack, набора инструментов с открытым исходным кодом для приема, обогащения, хранения, анализа и визуализации данных. («источник»)
Вот это да. Несколько лаконичных и длинных предложений. Давай разберемся!
Система поиска и аналитики

Elasticsearch позволяет хранить все виды данных. Вы можете подумать, что поиск — это только текст. И да, Elasticsearch отлично справляется с индексированием и запросами текста. Но это не все. Вы также можете хранить числовые данные и геопространственные данные, такие как координаты и геометрические формы.
Elasticsearch позволяет запрашивать данные, обобщать их, рассчитывать средние значения и многое другое!
Открытый исходный код
Elasticsearch бесплатен и имеет открытый исходный код. Компания Elastic за последние годы превратилась в очень прибыльную и коммерческую компанию. К счастью, вам не нужно ничего тратить, чтобы использовать Elasticsearch в производственной среде. Elastic повышает ценность продукта с точки зрения поддержки и дополнительных функций, когда вы им платите.
Например, вам может понравиться их полностью управляемый облачный хостинг. Они также предлагают X-Pack. Некоторые функции в X-Pack бесплатны, но для других требуется лицензия, например расширенные параметры авторизации и аутентификации, искусственный интеллект и анализ графиков.
Целая экосистема
Elasticsearch — это центральный компонент растущего стека продуктов, производимого Elastic, который называется «Elastic Stack». Эти инструменты помогают визуализировать (Kibana), принимать (Beats, Logstash) и управлять данными, хранящимися в Elasticsearch. Помимо официальных инструментов, доступно множество бесплатных и коммерческих инструментов и библиотек.
Эластичный
Так что с названием? Что такого гибкого в этой поисковой технологии? Я думаю, это сводится к двум ключевым моментам. Во-первых, Elasticsearch легко масштабируется от одного узла до большего количества узлов, чем вам когда-либо понадобится.
Elasticsearch также отличается гибкостью в том, насколько легко вы можете начать с ним работать. Начать работу совсем несложно. Помимо этого, он предлагает множество способов помочь вам успешно использовать его в производственной среде. Он может быть очень гибким и прощающим, если вы этого хотите, но он также может быть строгим и устойчивым, как камень, когда вы идете в производство.
Распространено
Я считаю, что одна из самых сильных сторон Elasticsearch — это легкость, с которой он масштабируется по мере необходимости. Обратите внимание, что, как и в случае с традиционными базами данных, большинству пользователей достаточно одного узла. Но как только ваш бизнес будет расти, Elasticsearch будет рядом с вами, легко расширяя его. Физически это просто вопрос добавления машин и их перечисления в файле конфигурации. Ваши индексы автоматически распределяются по другим узлам после их добавления!
Есть много профессиональных советов по расширению Elasticsearch, но я сохраню их для следующих статей.
Для чего это используется?
Многие используют Elasticsearch в качестве основного хранилища данных. Преимущество здесь в том, что вы можете очень хорошо хранить и запрашивать свои документы. Таким образом он используется для поиска приложений, поисковой системы предприятия и поиска на веб-сайтах.
Еще один широко распространенный вариант использования — хранение и индексирование журналов. Благодаря стеку ELK можно легко загрузить все данные журнала в Elasticsearch для анализа. Аналогичным вариантом использования является хранение данных журнала безопасности для создания платформы анализа угроз.
Более того, стек ELK часто используется для мониторинга инфраструктуры и производительности приложений и использования. Он также используется для анализа угроз, например в Cisco Talos. Его можно использовать для хранения и анализа геопространственных данных. И наконец, что не менее важно, его можно использовать в качестве платформы бизнес-аналитики.
Из этих примеров вы можете извлечь два типа данных, которые хорошо подходят для Elasticsearch:
- Статические данные — где Elasticsearch используется в качестве поисковой системы.
- Данные временных рядов — данные с привязкой ко времени отправляются в Elasticsearch, а механизм используется для получения аналитических данных, составления отчетов, обнаружения аномалий и т. Д.
Альтернативы Elasticsearch

Я считаю, что нельзя полностью оценить продукт, не зная его конкурентов. И, на мой взгляд, у Elasticsearch есть только один реальный конкурент, предлагающий аналогичный набор функций. Этот продукт называется Apache Solr. Когда я начал использовать Elasticsearch в 2010 году, способ работы Solr был более «неуклюжим», чем Elasticsearch.
Например, Solr не мог даже приблизиться к той легкости, с которой Elasticsearch масштабируется, когда вам нужно. Также требовалось много XML. Я полностью ненавижу XML. Я уверен, что с тех пор Solr значительно улучшился, но я не нашел веской причины для перехода на Solr за последние 9 лет.
Популярность
Чтобы дать вам представление о популярности этих двух продуктов, вот сравнение, которое я провел с помощью Google Trends:

Это поисковые запросы Google в США с 2004 года. Он показывает огромный рост популярности Elasticsearch, который начался после его запуска в 2010 году. В середине 2014 года он превзошел Solr. С тех пор популярность Solr постепенно снижалась.
Упаковать
Вот и все. Теперь у вас есть базовые знания о том, что такое Elasticsearch, для чего он используется и как позиционируется на рынке. Я планирую написать больше статей о Elasticsearch. Если у вас есть что-то конкретное, о чем вы хотите, чтобы я написал, оставьте, пожалуйста, комментарий.
дальнейшее чтение
Если вы хотите начать использовать Elasticsearch, вам также может понравиться моя статья о настройке тестовой среды:
Или нырните прямо в:
Если вам понравилась эта статья и вы хотите получать уведомления, когда я публикую новые материалы, подпишитесь на мой список рассылки.
Источник: questu.ru