
Программный стек ELK — связка из нескольких приложений (Elasticsearch, Logstash, Kibana, Filebeat), позволяющая быстро собирать и обрабатывать всю информацию об обслуживаемой системе.
Elasticsearch — это ядро программного стека ELK, поисковый движок для работы с большими объёмами данных. Он позволяет осуществлять быстрый и эффективный поиск по всему объёму собранных данных. Для сбора системных логов в данной конфигурации стека используется FileBeat, передающий данные в фильтрационную систему Logstash, а для визуализации представляемых данных используется Kibana.
В данной серии инструкций мы рассмотрим установку и настройку всего программного стека ELK на VPS под управлением CentOS или Ubuntu.
Начнём с установки и первичной настройки Elasticsearch. Устанавливать Elasticsearch будем из официальных репозиториев разработчиков на подготовленный к работе VPS с CentOS 8 stream или Ubuntu 20.04. Все необходимые зависимости и дополнительные приложения будут установлены в процессе.
ЧТО ТАКОЕ ELASTICSEARCH? ВВОДНЫЙ УРОК
# Установка Elasticsearch
# CentOS
Устанавливать Elasticsearch будем из официального репозитория Elastic. Для этого сначала добавим GPG-ключ на сервер:
sudo rpm —import https://artifacts.elastic.co/GPG-KEY-elasticsearch
После этого добавим репозиторий в список репозиториев, используемых dnf. Создадим в папке с репозиториями конфигурационный файл, содержащий все сведения о добавляемом источнике:
sudo vi /etc/yum.repos.d/elasticsearch.repo
В открывшемся текстовом файле укажем основные параметры устанавливаемого репозитория:
[elasticsearch] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md
Здесь мы указали имя, адрес, откуда устанавливать Elasticsearch, и gpg-ключ. В адресе установки мы указали 7.x — 7 версию. Если вы хотите установить более свежую версию, проверьте страницу доступных версий
(opens new window) и укажите номер версии, который хотите установить.
Теперь переходим к установке:
sudo dnf —enablerepo=elasticsearch install elasticsearch
Эта команда добавит репозиторий Elasticsearch в список репозиториев, из которых возможна установка, и проверит доступность пакета Elasticsearch, после чего предложит установить его.
В процессе установки Elasticsearch установит дополнительные необходимые зависимости, в том числе необходимые для работы версии Open JDK и JVM.
После завершения установки можно добавить Elasticsearch в автозагрузку и запустить:
sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service sudo systemctl start elasticsearch.service
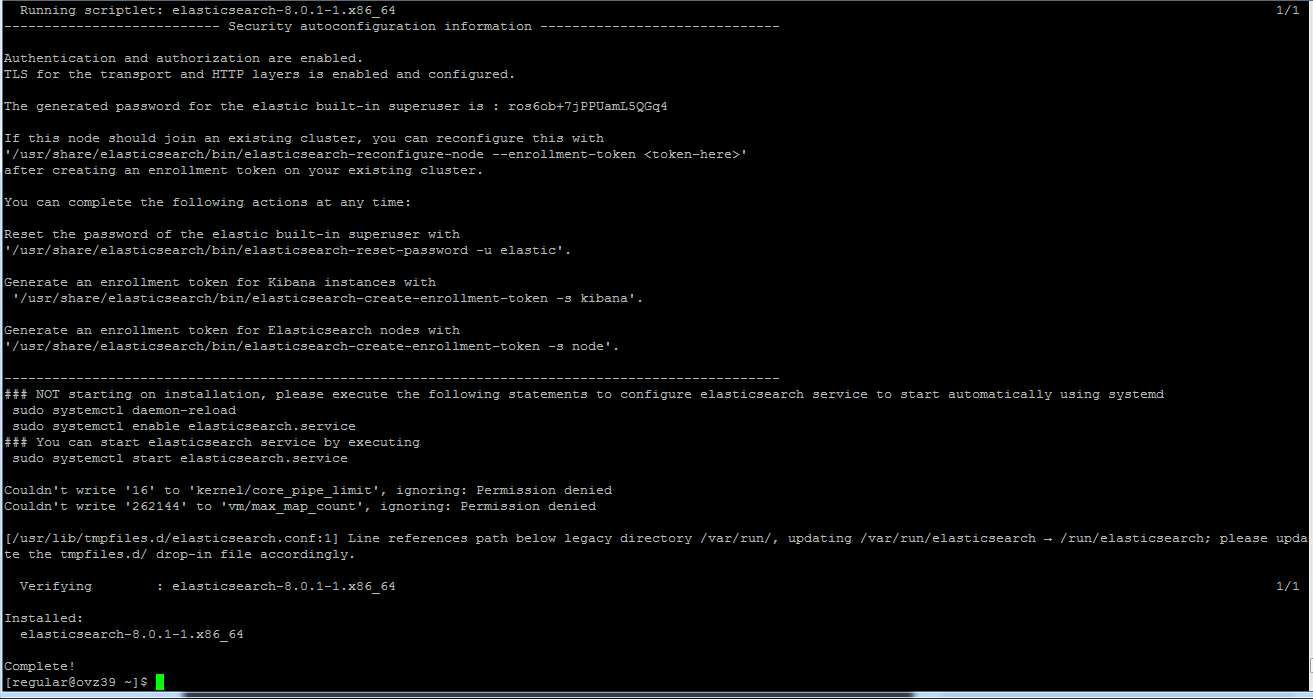
После этого проверим статус программы:
sudo systemctl status elasticsearch.service
Вывод должен быть примерно таким:
# Ubuntu
Последовательность действий при установке Elasticsearch на Ubuntu будет примерно такой же, как и при установке на CentOS. Основное отличие — способ добавления репозитория.
Про Elastic Stack за 15 минут.
Начнём с добавления gpg-ключа:
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add —
После этого добавим репозиторий в список репозиториев apt. Для этого можно воспользоваться любым текстовым редактором. Мы используем команду echo :
echo «deb https://artifacts.elastic.co/packages/7.x/apt stable main» | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Обратите внимание, что в данном случае мы тоже устанавливаем 7 версию Elasticsearch.
После добавления репозитория в список источников apt обновим его и запустим установку:
sudo apt update sudo apt install elasticsearch
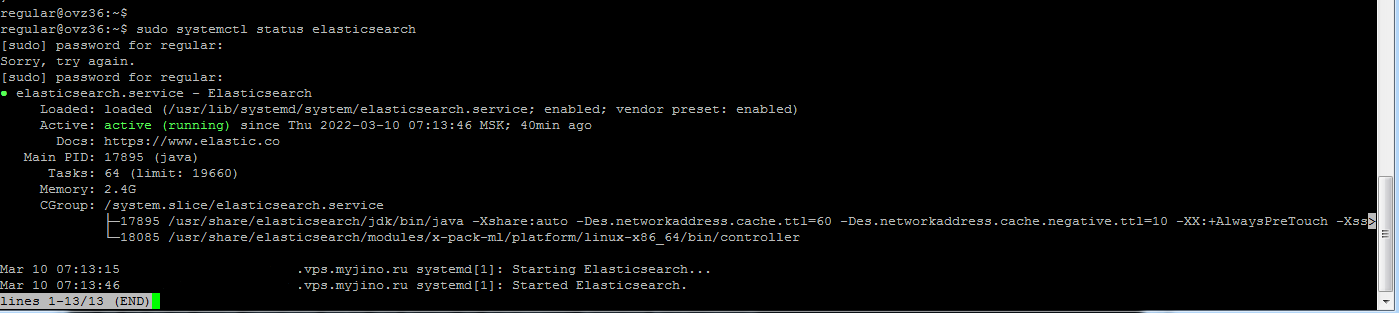
После завершения установки запустим Elasticsearch и проверим его статус, чтобы убедиться, что всё работает верно:
sudo systemctl enable elasticsearch sudo systemctl start elasticsearch sudo systemctl status elasticsearch
Если установка прошла как положено, правильные зависимости установились и запустились, и сам Elasticsearch запустился без ошибок, то на экране появится примерно такое сообщение:
# Настройка Elasticsearch
Основные настройки Elasticsearch производятся через конфигурационный файл elasticsearch.yml , файл конфигурации виртуальной машины Java jvm.options и файл журнала Elasticsearch log4j2.properties .
На данном этапе нужно проверить сетевые настройки работы Elasticsearch. Для этого откроем основной конфигурационный файл:
sudo vi /etc/elasticsearch/elasticsearch.yml
Найдём здесь блок Network , отвечающий за сетевое соединение Elasticsearch. В качестве хоста указан localhost с номером порта 9200. Оставим именно эти значения, потому что в нашем случае Elastcisearch будет работать только на внутренней машине, доступ к нему будет осуществляться из локальной сети сервера.
В этом же файле в разделе Paths указаны директории хранения логов работы программы и основных данных, с которыми будет работать Elasticsearch. Программный стек будет работать с большими объёмами данных, поэтому размещать их хранилище нужно там, где будет достаточно дискового пространства.
# Проверка работы Elasticsearch
После проверки сетевых настроек и статуса Elasticsearch (active, enabled) проверим непосредственный доступ к приложению.
Сначала проверим правильность его размещения на сервере. Посмотрим, какое приложение занимает порт 9200, указанный в качестве рабочего порта Elasticsearch:
sudo netstat -tulpn | grep 9200 # Output tcp6 0 0 127.0.0.1:9200 . * LISTEN 17895/java
Как видим, порт 9200 локального адреса занят java — это виртуальная машина, на которой запущен Elasticsearch.
Теперь отправим к Elasticsearch curl-запрос:
curl -X GET ‘http://localhost:9200’
Результат выдачи должен быть примерно следующим:
# Output «name» : «localhost_name», «cluster_name» : «elasticsearch», «cluster_uuid» : «-JKGBFLLS5itNHDokWrPzQ», «version» : «number» : «7.17.1», «build_flavor» : «default», «build_type» : «deb», «build_hash» : «e5acb99f822233d62d6444ce45a4543dc1c8059a», «build_date» : «2022-02-23T22:20:54.153567231Z», «build_snapshot» : false, «lucene_version» : «8.11.1», «minimum_wire_compatibility_version» : «6.8.0», «minimum_index_compatibility_version» : «6.0.0-beta1» >, «tagline» : «You Know, for Search» >
Это означает, что Elasticsearch запущен и правильно функционирует, возвращая по запросу свои основные данные.
Теперь можно переходить к следующей части нашей инструкции, в которой мы будем устанавливать компонент для визуализации получаемых данных — Kibana.
Источник: jino.ru
Что такое Elasticsearch, зачем он нужен на сайте? Наш пример из практики
В ответе на вопрос ”Что такое Elasticsearch?” можно услышать такие фразы: “система поиска”, “умный поисковик”, “решение для работы с большими данными”, “работает как Гугл”, “решение для поиска в режиме реального времени” и т.д. И каждый ваш ответ будет правильный. Все это про Elasticsearch. Чем же он отличается от обычного поиска и как он работает? Разберем в этой статье.
Что такое Elasticsearch?
Это движок, который помогает быстро найти информацию в большом массиве данных, от документа в корпоративной системе, до нужного товара на маркетплейсе. Он представляет собой открытую, распределенную и бесплатную аналитическую систему для любых типов данных (текстовые, числовые, структурированные, неструктурированные и т.д.).
Решение появилось после того, как создатель Шей Банон решил сделать масштабируемое поисковое решение для обработки больших объемов данных. Продукт из решения для поиска вырос в экосистему — Elastic Stack, которая на данный момент представляет из себя:
- Beats — программа для сбора системных журналов и файлов;
- Logstash — механизм сбора данных и регистрации данных, предобработка данных;
- Elasticsearch — ядро всей системы, где индексируются и хранятся данные;
- Kibana — веб-интерфейс для визуализации данных.
Последний релиз Elasticsearch, на момент написания статьи, вышел в июле 2022 года, версия 8.3.3.
У вас есть идея? У нас есть решение!
Разработаем интеграции с любыми сервисами
Узнать больше
Как работает Elasticsearch?
Попробуем описать логику работы по основным терминам:
Документ
Основная единица обмена данными в Интернете, индексируется в Elasticsearch, представлена и закодирована в формате JSON. Это не просто текстовый документ, это то, что вы ищите. Документ может выражаться любыми данными: числа, строки, даты. У каждого документа есть свой ID и тип. Например, документ может представлять собой статью в блоге или номер заказа в интернет-магазине.
Индекс
Индекс объединяет документы со схожими характеристиками. Индекс — это своего рода база данных документов в схеме реляционных данных. У каждого индекса есть свое имя, по которому происходит обработка, обновление, удаление данных.
К примеру, на сайте отдельный индекс может быть для клиентов, для продуктов, для заказов.
Инвертированный индекс
То, как представлен на самом деле индекс в любой поисковой системе. Он разделяет и сопоставляет слова с документами, в которых они содержаться. Представляют собой что-то вроде карты, он разбивает каждый документ на условия поиска. И выдает совпадающие по значениям и условиям документы, на основе запроса.

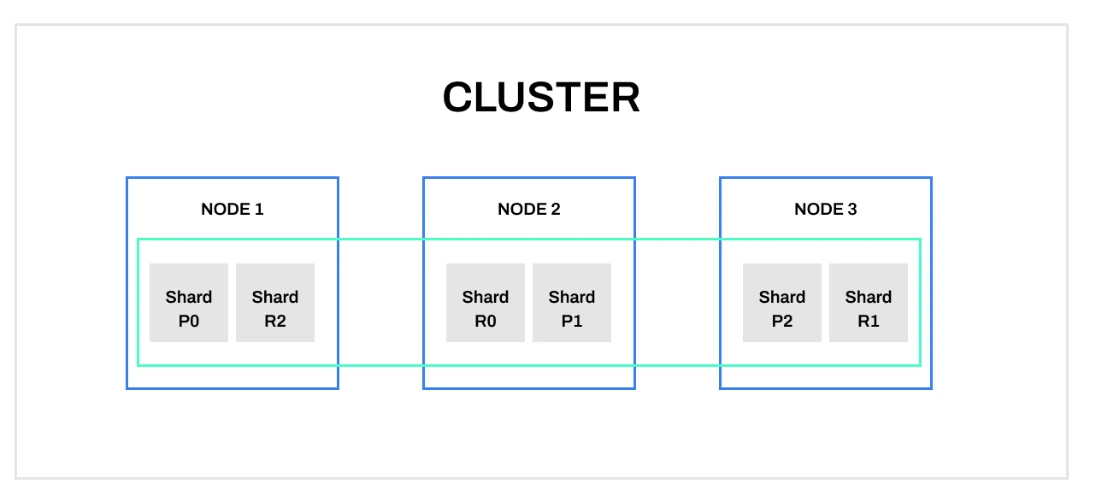
Узел и кластер (Node and Cluster)
Узел — это отдельный сервер, который хранит данные, является частью кластера и участвует в поиске кластера. В кластер входит один или несколько узлов, и содержит все данные для поиска и индексирования.
Шарды (Shard)
В Elasticsearch индекс можно разделить на несколько частей, шардов. Каждый шард будет являться независимым “индексом”, который может размещаться в любом узле кластера. Благодаря им объем данных распределяется горизонтально на несколько узлов, что позволяет выполнять параллельные операции и ускорить процесс поиска.
Как можно использовать Elasticsearch
Elasticsearch отлично подходит для хранения неструктурированных данных. И при необходимости данные могут быть молниеносно извлечены. Таким образом Elasticsearch отлично подходит и может использоваться как:
Востребованность и популярность Elasticsearch по всему миру поддерживается высоким качеством и скоростью обработки данных, не только среди высоконагруженных проектов, но и небольших сервисов. Elasticsearch поддерживает различные языки программирования: Java, Go, PHP, Python, Ruby и другие. Поддерживает 34 текстовых языка, а при необходимости можно добавить еще больше через плагины.
Какие же основные преимущества использования Elasticsearch?
- Разные функциональности поиска. Он предлагает разные варианты работы с поиском на сайте: полнотекстовый, настраиваемый по параметрам, с автозаполнением, с нечетким запросом.
- Масштабируемость. Так как это распределенная система, она легко масштабируется по горизонтали. Не важно сколько новых элементов для поиска вы добавите, система балансирует нагрузку между узлами в кластере.
- Ориентированность на документы. Elasticsearch может хранить сложные объекты, например технические инструкции, в виде структурированных документов JSON и индексов, которые значительно проще обрабатывать.
- Скорость. Elasticsearch легко и быстро обрабатывает сложные запросы. Благодаря кэшированию всех структурированных запросов, которые используются в качестве фильтра для поиска результатов, делает это один раз и не нагружает сервер.
Из недостатков, что мы нашли по опыту реальных пользователей, можно отметить:
- Производительность в облаке ниже, чем при локальной установке.
- Установка и настройка не подойдут для простого пользователя, лучше обратится к разработчикам.
- Установку обновлений для сервиса, также лучше доверить профессионалам. В частности обновление ролей узлов кластера и репликации данных, индексов, может стать непростой задачей и потребовать кропотливой работы, чтобы не потерять данные.
- Стоимость всей системы продуктов Elastic Stack может не подойти для небольших бизнесов.
Примеры из практики
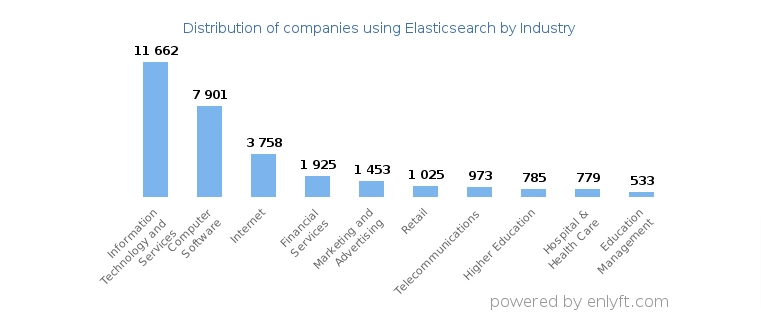
По данным исследования компании Enlyft больше всего Elasticsearch применяется в индустриях: информационные технологии и услуги (24%), компьютерное программное обеспечение (17%) и интернет (8%).
Netflix

На Elasticsearch построена система сообщений в Netflix. Она разделена на следующие категории:
- Сообщение, которые вы получаете, присоединяясь к сервису;
- После регистрации, вы получаете сообщения с контентом, который вам может быть интересен;
- На основе алгоритмов машинного обучения система получает о вас больше данных и предлагает более персонализированный контент в сообщениях;
- Сообщения на удержание клиентов, если вы решите покинуть сервис.
Все это осуществляется через email рассылку, push уведомления, текстовые сообщения. Для анализа эффективности этих уведомлений, жизненный цикл сообщений проходит через Elasticsearch. Например, вышел новый фильм, сообщение об этом должно быть отправлено всем пользователям.
Kibana позволит в режиме реального времени посмотреть сколько людей было уведомлено, а также успешно доставленные сообщения. По каким причинам сообщения не были отправлены. Благодаря Elasticsearch в режиме реального времени Netflix отслеживает все сбои в сообщениях и оперативно решает проблемы.
Airbus
Производит и поставляет самолеты во все континенты мира, выпускает около 11 моделей самолетов, а на конец 2021 года всего выпущено более 13 тысяч самолетов. Документация должна быть доступна для всех пользователей, на разных языках и для каждой модели и типа самолета.
Airbus развернули в своей базе систему Elastic Stack, в базе хранятся технические документы на 6ТБ для каждого самолета. Менее чем за 2 секунды можно найти нужный документ. Система позволяет обрабатывать 3000 запросов авторизированных пользователей в минуту, а также следить за работоспособностью платформы.
Leroy Merlin

Сделали поиск по каталогу продуктов, их доступности и цене, адаптированный для русского рынка. Данные собираются и хранятся в индексе Elasticsearch. При поиске товаров на сайте, запрос обращается к индексу ES, затем ранжируются и выдаются на странице.
Сервис продолжает масштабироваться, добавляются все новые товары в индексе, при этом пользователи совершают до 300 поисковых запросов в секунду в мобильном приложении и на сайте.
Как и зачем мы внедрили Elasticsearch?
На маркетплейсе нашего клиента представлено более 300+К товаров, где вендоры — это производители и оптовики, а покупатели — розничные магазины. Высокие нагрузки на сервер, широкий ассортимент товаров – проблемы с поиском неизбежны.
Чтобы клиентам не приходилось долго ждать результатов поиска, необходимо максимально быстрое решение, поэтому мы решили использовать в качестве хранилища каталога Elasticsearch.
Но из-за множества модификаций на маркетплейсе (в том числе и наших) решение которое мы нашли на маркетплейсе CS-Cart от стороннего разработчика, показывало некорректную товарную выдачу. Не учитывались сделанные модификации. Изучив модуль и пообщавшись с его разработчикам, мы пришли к выводу, что он нам не подходит, так как не предусматривает необходимые возможности расширения выборки товаров, поэтому результаты поисковой выдачи были некорректными. Тогда мы решили сделать собственную интеграцию с Elasticsearch.
Вся интеграция Elasticsearch в НЕдефолтный магазин прошла в 3 этапа:
1. Изучение и анализ модификаций товарной выдачи магазина. Анализ допустимых сортировок и фильтров товаров.
2. Установка базового модуля Elasticsearch от Cart-Power.
3. Создание вспомогательного модуля непосредственно для магазина клиента, который будет расширять базовый модуль с учетом новых доработок, из пункта 1.
Подробнее и по порядку:
Разработав с нуля интеграцию для базовой версии CS-Cart, мы проверили интеграцию 300к товаров на дефолтном CS-Cart.
С точки зрения подхода к поиску ничего не изменилось. И для пользователя он выглядит также:
Источник: cart-power.ru
Elasticsearch – поиск для самых больших

Чем крупнее компания, тем большим количеством данных она владеет. Но все эти петабайты ценной для бизнеса и его клиентов информации не должны лежать без дела – они должны работать, постоянно и эффективно.
Требования к современным системам быстрого внутреннего поиска постоянно меняются и растут. Меняется и сама структура данных. Если раньше это были единообразные записи в таблицах БД, то теперь чаще речь идет об «озерах данных», содержащих неструктурированную информацию, объектных хранилищах S3 и т.д.
Не так уж много существует поисковых решений, способных хорошо показать себя в подобной среде, особенно если дело касается поиска среди многих и многих петабайт. Одной из самых популярных в области Big Data поисковых систем такого рода является, безусловно, Elasticsearch.
Первая версия поискового движка увидела свет в 2010 году. В 2012 году создатель Elasticsearch Шай Бейнон (Shay Banon) зарегистрировал одноименную компанию, задачей которой стала коммерциализация изначально открытого решения. Позднее она была переименована в Elastic.
В настоящее время возможностями Elasticsearch пользуются множество всемирно известных компаний, среди которых GitHub, Netflix, Uber, Slack, Microsoft и пр. Так, к примеру, для организации поиска по своим бездонным хранилищам Netflix постоянно использует 700-800 узлов Elasticsearch, объединенных в 100 кластеров. Uber обрабатывает по тысяче поисковых запросов в секунду и более, а GitHub индексирует более 8 млн репозиториев, обслуживая более 4 млн пользователей.
Принципы работы Elasticsearch
В основе Elasticsearch лежит написанный на Java поисковый движок, использующий свободную библиотеку скоростного полнотекстового поиска Lucene и поддерживающий JSON REST API. К ключевым достоинствам Elasticsearch, помимо высочайшей производительности и возможности практически безграничного горизонтального масштабирования, можно отнести автоматическую индексацию новых объектов, которые становятся доступными сразу после загрузки в БД в соответствии с концепцией NoSQL.
Кроме того, поисковая система оснащена широким набором настраиваемых фильтров, позволяющим реализовать мультиарендность и использовать нечеткий поиск. Также Elasticsearch снабжен анализаторами, в автоматическом режиме выполняющими токенизацию текста (разбиение на элементарные элементы – слова, знаки препинания и пр.), лемматизацию, стемминг и другие преобразования.
Elasticsearch можно назвать документно-ориентированной базой данных с поддержкой многопоточности. Поиск в реальном времени может осуществляться по документам любого типа при помощи API-интерфейсов библиотеки Lucene и запросов GET.
В случае необходимости, которая в крупных проектах возникает почти всегда, несколько копий Elasticsearch могут быть объединены в кластер. Группа таких кластеров может хранить реплицированные копии сегментов индекса, за счет чего достигается высокая отказоустойчивость решения.
В достаточно большом хранилище данных число развернутых кластеров Elasticsearch может измеряться сотнями. При этом каждый из узлов кластера умеет делегировать операции поиска правильному сегменту индекса, попутно осуществляя маршрутизацию и перебалансировку данных.
Также по теме
Elastic Stack
Важно отметить, что в своем типичном воплощении Elasticsearch не используется в отрыве от других продуктов Elastic – Logstash, Kibana и FileBeat. Вместе они образуют комплексное решение, получившее общее название Elastic Stack.
Logstash – инструмент сбора, обработки и отправки в хранилище всевозможных событий из разных источников – журналы, пакеты, события, транзакции, временные метки и т.д. Logstash написан на JRuby и работает на JVM, что позволяет запускать его на разных платформах.
В качестве источников данных для этого инструмента могут служить социальные сети, новостные агрегаторы, внутренние данные систем электронной коммерции, CRM, финансовые показатели, телеметрия мобильных устройств, сенсорные сети IoT, HTTP-запросы и ответы на них, журналы Apache или Windows, а также многое другое.
Широкий ассортимент фильтров Logstash помогает извлекать ценные выводы из данных при помощи преобразований и анализа. Построенные на основе регулярных выражений шаблоны фильтров могут быть объединены в последовательности. Также анализ данных облегчает набор плагинов для Logstash, позволяющих преобразовать содержимое журналов в любой удобный формат.
Kibana – веб-инструмент визуализации, позволяющий привести поток событий от Logstash в человекочитаемый вид для анализа. При этом Kibana не взаимодействует с Logstash напрямую, а использует в качестве источника данных уже обработанные индексы Elasticsearch. С помощью Kibana можно создавать разнообразные динамические панели мониторинга, таблицы, графики и диаграммы, демонстрирующие обстановку во входящих источниках событий в реальном времени.
FileBeat – легковесный серверный агент, с помощью которого можно организовать отправку логов серверов в Logstash. Этот элемент стека не является обязательным, однако зачастую оказывается весьма полезен в инфраструктурах определенных типов.
Особенности лицензирования
Все элементы Elastic Stack доступны для изучения и использования в виде исходных кодов в репозитории GitHub. До недавнего времени они распространялись по лицензии Apache 2.0, однако в январе 2021 года Elastic объявила о переходе на лицензию SSPL (Server Side Public License), накладывающую некоторые ограничения на коммерческое использование.
Теперь эксплуатанты Elastic Stack могут продолжать пользоваться им безвозмездно только в том случае, если все остальные компоненты, вовлеченные в работу сервиса, также будут публиковаться в виде открытого исходного кода.
Изменения коснулись главным образом облачных провайдеров, которые физически не в состоянии выполнить требования SSPL и будут вынуждены перейти на коммерческую лицензию.
В то же время, основное коммерческое предложение Elastic состоит вовсе не в этом. Различные варианты лицензий, такие как Gold, Platinum и Enterprise, включают в себя многочисленные дополнительные инструменты, направленные на расширение функциональности Elastic Stack.
· Gold включает в себя механизмы авторизации через Active Directory/LDAP, дополнительные инструменты внутреннего аудита, расширенные возможности службы оповещений и, разумеется, техническую поддержку в рабочие часы.
· Platinum в дополнение к вышеперечисленному предлагает встроенные инструменты машинного обучения, поддержку ODBC/JDBC, настройки гранулярного доступа вплоть до отдельных документов, кросс-кластерную репликацию и ряд других возможностей, включая круглосуточную техподдержку. На сегодняшний день это самый востребованный тип лицензий на Elastic Stack.
· Enterprise, помимо возможностей Platinum, включает в себя решение Elastic Cloud Enterprise, оркестратор Elastic Cloud on Kubernetes, инструмент киберзащиты конечных устройств Endgame, а также поддержку неограниченного количества проектов на базе Elastic.
Источник: www.syssoft.ru