
Корпоративное хранилище данных (DWH): что это и зачем оно крупному бизнесу
Каждая компания за время своей работы обрастает данными. Чем больше этих данных, тем точнее бизнес-решения, принимаемые на их основе. Но большинство компаний в работе используют множество различных систем (1С, сайт, CRM, и т.д.), данные из которых хранятся разрозненно. Чтобы видеть точный результат работы, их нужно объединить в специальном хранилище Data Warehouse. Рассказываем, что это и зачем его использовать бизнесу.
Отличие хранилища данных (DWH) от обычных баз данных (БД)
Data Warehouse — это корпоративное хранилище, в котором хранятся все данные о работе компании, полученные из разных источников. Она нужна для того, чтобы руководство принимало верные решения на основе данных. Любая компания в работе использует несколько разных систем. Одни из них используются для контроля продаж, другие — для финансового или складского учета, третьи — для управления персоналом. Всю информацию они хранят внутри системы, а владельцу бизнеса приходится анализировать данные каждой из них по отдельности.
DWH, Data Lake и Data Mesh
Для получения общей картины можно подготовить сводный отчет в Excel, но это требует большого количества времени, в процессе создания могут возникнуть ошибки, и обновление данных нужно проводить вручную. DWH решает эту проблему и позволяет получать целостную и актуальную информацию, обновляемую автоматически.
Чем корпоративное хранилище отличается от обычных баз данных:
- Базы данных хранят информацию только из определенных информационных систем, а хранилище собирает информацию обо всех сторонах деятельности компании от разных отделов и из разных источников;
- в БД хранится только актуальная информация, а DWH содержит и архивные данные, благодаря чему можно получить динамику продаж за последние несколько лет или другую информацию;
- Базы данных собирают данные, а затем передают их в хранилище. В хранилище всегда находится последняя версия данных.
Структура хранилища данных (DWH)
Хранилище данных состоит из нескольких частей:
- область, собирающая первичные данные (здесь собирается информация из разных БД и от разных отделов компании);
- ядро хранилища (поступившая в хранилище информация обрабатывается и приводится к нужной структуре и ключам, благодаря чему обеспечивается целостность и полнота данных в хранилище);
- витрины аналитики (на этом уровне данные преобразовываются в тематические узконаправленные массивы, которые в будущем используются для построения отчетов и решения различных задач).
- сервисный уровень (управляет сбором данных, ядром хранилища и витринами аналитики. Обеспечивает бесперебойный мониторинг данных их сохранность и устранение ошибок).
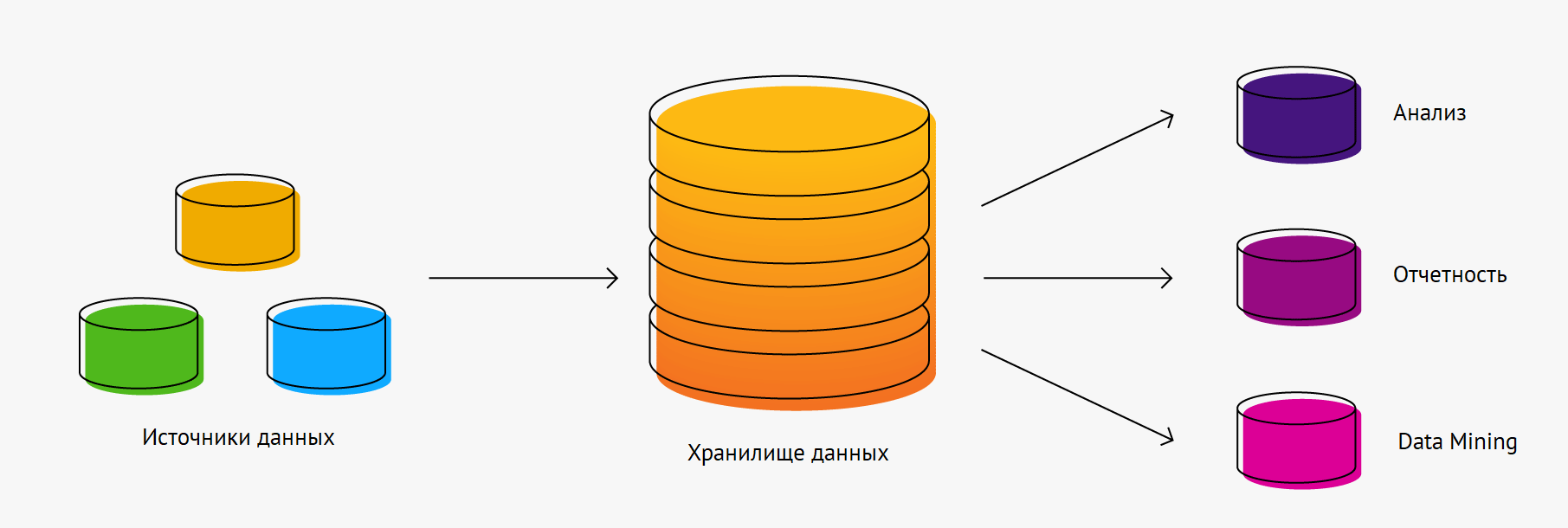
Как бизнес может использовать DWH
DWH нужен не только для того, чтобы хранить архив данных компании. Информация, содержащаяся внутри хранилища, используется для бизнес-аналитики. С помощью BI-системы и знаний в области бизнес-анализа руководство компании может принимать более взвешенные и обоснованные решения, которые помогут развитию бизнеса.
Что такое data warehouse со стороны аналитика?
Как работает бизнес-анализ на основе DWH:
- Компания замечает снижение выручки в 4 квартале, но не может понять причины этого явления.
- Для выявления проблемы привлекается сторонний бизнес-аналитик.
- Аналитик получает данные из DWH и изучает показатели по выручке, количеству продаж, сезонности и т.д.
- После этого он формирует отчет на основе данных, в котором указывается причина снижения продаж. Все выводы подкрепляются данными.
- Руководство компании принимает соответствующие меры и исправляет ситуацию.
Благодаря привлечению бизнес-аналитика компания не принимает решения вслепую, а выявляет, в чем именно проблема и вовремя устраняет ее. Возможностей обычных баз данных для этого недостаточно так как:
- они не сохраняют старые данные;
- данные в них хранятся разрозненно и нет общей картины;
- на сопоставление данных из разных источников уйдет много времени.
В чем преимущества DWH для бизнеса
Data Warehouse — это склад компании. Только хранит он не товары и оборудование, а информацию. Создание и поддержание работы такого склада дает следующие возможности для развития бизнеса:
- Оперативный доступ к любой нужной информации: у крупных компаний много департаментов и отделов, которые могут иметь свои базы данных. Стороннему аналитику придется запрашивать доступ к каждой БД, которая ему необходима для анализа проблемы. Он потратит больше времени на работу, а бизнес позже получит решение своей проблемы.
- Сохранность данных на протяжении многих лет: БД не хранят информацию за продолжительное время, а вот хранилища — да. Получить в DWH данные за 10 лет также легко, как и за прошедший месяц.
- Исключение влияния бизнес-аналитики на работу других отделов и систем компании: если BI-аналитикам понадобится выгрузить из хранилища большой объем данных, большая нагрузка на хранилище не повлияет на стабильность работы других систем и отделов компании.
Объединив возможности DWH-хранилищ и BI-аналитики можно улучшить качество принимаемых руководством решений и вывести бизнес на новый уровень развития.
Компания Денвик занимается внедрением систем бизнес-аналитики и интеграцией их с разными источниками данных. Для бизнес-аналитики мы предлагаем своим клиентам использовать Yandex Datalens. Это бесплатная BI-система с множеством возможностей и неограниченным числом пользователей. Так как Datalens является частью экосистемы Yandex.Cloud, в качестве DWH-хранилища система использует ее возможности.
Если вы хотите начать работать с BI-аналитикой, оставляйте заявку. Наши менеджеры свяжутся с вами и ответят на все вопросы.
Источник: denvic.ru
DWH как продукт: платформа, инструменты, масштабирование команды
Меня зовут Женя, в Авито я руковожу юнитом DWH. Мы отвечаем за работу с аналитическим хранилищем, которое помогает нашим сотрудникам принимать решения, основанные на данных.
В статье расскажу, как продуктовый взгляд помогает нам развивать DWH и быть полезнее для пользователей. Речь пойдёт про появление платформенных инструментов и рост проникновения аналитики в компании, а также про реорганизацию команды и перераспределение задач. Будет больше о процессах и практиках, чем о хардкорных технологиях. Но и технологии немного затрону.

Зарождение аналитики в Авито
Аналитика в Авито начала активно развиваться в 2013 году. Мы хотели сделать расширяемую BI-платформу, чтобы растить бизнес на основе данных. Ключевым требованием к платформе стала практически неограниченная расширяемость — как по объёмам и скорости сбора, хранения и обработки данных, так и по их сложности.
Начали с сочетания Vertica и Tableau, чтобы осуществить быстрый старт. На тот момент у нас было порядка 50 Tb данных, 6 дата-инженеров и 25 пользователей-аналитиков. Подробнее почитать про задачи и выбор решения можно в кейсе Vertica.
Две типовые задачи, которые решала DWH-команда — это построение витрин и загрузка данных (ETL).
Витрины. Задачи на построение витрин выглядели как описание структуры отчёта, который хотелось получить. Нужно было разобраться с бизнес-логикой, закодить её на SQL и Python, и дальше внедрить это в прод. Такие задачи занимали достаточно много времени: заказчикам приходилось ждать спринтов разработки, а нам — заниматься рутиной.

ETL. Аналогичные тенденции прослеживались и в ETL-задачах, связанных с загрузкой данных. В них тоже описывалась бизнес-логика: что и куда загрузить. Команде DWH приходилось писать типовой код, чтобы реализовать требуемую раскладку данных в хранилище.

Платформизация
На первом этапе перед нами встали два вопроса:
- Как справиться с ростом задач, если Авито и его аналитика активно растут?
- Как не погрязнуть в рутине?
Ответить на эти вопросы нам помог такой подход как платформизация. Мы решили сфокусироваться на создании инструментов, с помощью которых пользователи смогли бы сами решать свои задачи. Мы при таком раскладе могли сосредоточиться на том, чтобы развивать единую платформу, следить за её стабильностью и помогать пользователям там, где что-то не получается.
Мы хотели сделать так, чтобы с помощью нашей инфраструктуры можно было решать любые аналитические задачи. Тогда пользователям не приходилось бы ждать спринтов разработки, а нам — тратить время на реализацию повторения бизнес-логики.
После внедрения платформенных инструментов, решения типовых задач стали выглядеть иначе.
Витрины. Задачи, связанные с витринами, стали представлять из себя пул-реквесты. Пользователь-аналитик может создать пул-реквест сам, написав код на SQL. Чтобы расчёт новой витрины не нарушил работоспособность всего хранилища, появились автотесты, которые проверяют стандарты кода, оптимальность запросов, потребление технических ресурсов и тому подобное. Если тесты прошли, то мы в команде DWH мёржим реквест, и он встаёт на регулярный расчёт.

Через механизм пул-реквестов удалось создать больше 800 ежедневных расчётов. Также мы создали инструмент оркестрации, который позволяет управлять зависимостями расчётов и считать их в оптимальном порядке.
ETL. Для решения ETL-задач мы сделали механизм, с помощью которого аналитики могут делать раскладку данных самостоятельно. В таске в Jira фиксируется наименование сервиса, бизнес-смысл данных и сценарии их использования. А сама бизнес-логика реализуется в пул-реквесте, он также проходит тесты и мёржится в прод.

В пул-реквесте нужно описать внешний источник, как экстрактить данные и как раскладывать их в хранилище. Все загрузки строятся в SQL, можно прозрачно видеть, что куда раскладывается и управлять версиями в Git.

Подход платформизации сработал и помог решить часть проблем. Чтобы улучшать созданные инструменты и масштабироваться дальше, мы решили применить продуктовый подход к DWH.
Продуктовый подход к DWH
Продукт — это то, у чего есть целевая аудитория и что приносит этой аудитории ценность. Основные пользователи DWH — это аналитики, инженеры и менеджеры продукта. Верхнеуровневая ценность нашей команды для них в том, что мы помогаем принимать решения на данных. Это важная задача, поскольку Авито — data-driven компания. Мы используем данные и метрики для решений в продукте и постановки целей всех команд.

Для взгляда на DWH как продукт мы использовали две практики: user story mapping и customer development.
User story mapping. Эта практика помогла нам визуализировать и лучше представить продукт и задачи, которые мы решаем. Мы составили карту, где отразили всё, что делают наши пользователи. В Miro для этого есть классный плагин.
Сначала мы выписали верхнеуровневые задачи. Например, задача на проверку любой гипотезы. Дальше подумали, на что раскладывается данная задача и записали это в заголовки столбцов. Нужно:
- Найти данные.
- Провалидировать их.
- Понять, как ими пользоваться.
- Получить ответ на изначальный вопрос.
- Поделиться результатами.
По каждой части задачи мы накидывали идеи о том, как её сейчас решают пользователи и как можно её реализовать, если готового инструмента ещё нет.

Так мы получили список активностей. Например, чтобы провалидировать данные нужно понять, когда они корректно рассчитывались в последний раз. Если месяц назад, то пользоваться такими данными не очень корректно. Получившийся список активностей и хотелок можно ранжировать и выделять блоки, которые пойдут в MVP, спринт или квартал. Для этого нужно нарезать куски по важности.
Концепцию того, как можно это сделать, я подсмотрел у Джеффа Паттона. При нарезании возникают вопросы с тем, какого объёма должна быть каждая часть предстоящей работы. Мне понравилась аналогия с тем, чтобы вместо свадебного торта делать капкейки. Финальные задачи должны представлять собой ценные части продукта, которые сами по себе полезны, но изготовляются гораздо быстрее, чем весь продукт в целом. Используя такую аналогию, можно декомпозировать истории и структурировать продуктовый бэклог.
Customer development. Практику customer development мы использовали, чтобы понять, как люди пользуются DWH, лучше понять их потребности, проверить свои гипотезы и собрать обратную связь.
Идея состоит в том, что мы задаём пользователям определённые вопросы. Они помогают понять, в чём люди видят ценность продукта. Вот несколько примеров таких вопросов:
- В чём для вас главная ценность продукта?
- Что изменится, если продукта не будет?
- Какой продукт служит альтернативой?
- Есть ли факторы, которые мешают вам пользоваться текущим решением?
Несколько советов по проведению интервью с пользователями:
- Нужно заранее представлять, что мы хотим получить от встречи. В этом поможет предварительно написанный сценарий или хотя бы канва разговора.
- Все вопросы должны быть открытыми, ведь прежде всего мы хотим услышать развёрнутый ответ.
- Бывает полезно уточнить, правильно ли мы поняли респондента. Поможет формулировка «правильно ли я понимаю, что?»
- Важно задавать вопросы про прошлое, а не про будущее.
- Мы интересуемся фактами, а не мнениями и оценками.
- Полезная практика — «5 почему», чтобы докопаться до сути проблемы.
Про проведение интервью и корректное формулирование гипотез мы писали в статьях UX-лаборатории. Если вам интересна эта тема, можно почитать разбор тестовых заданий на стажировку 2020 года и похожий разбор 2021 года. На основе интервью с пользователями DWH мы сформулировали гипотезы о том, что можно сделать в следующей итерации.
Решение проблем пользователей
Во время общения с пользователями мы выявили ряд проблем, которые начали постепенно решать. Приведу пару примеров.
Проблема поиска данных. Наше хранилище росло в разы каждый год. Данных становилось всё больше, всё больше разных таблиц и источников. В какой-то момент стало очень сложно ориентироваться в данных и понимать, как тот или иной кусок продукта логируется. Пользователям DWH приходилось искать ответы в чатах в Слаке. Вот что говорили люди:
Данные искать сложно. Чаще всего приходится искать человека, который знает, где что лежит и как работает.
Регулярно приходится обращаться в чаты в Слаке, чтобы понять, есть ли та или иная информация в Вертике. Мне кажется, очень не хватает описания ДДС-таблиц.
Мы хотели упростить работу с хранилищем и упростить процесс валидации данных. Так появилась система поиска dwh-docs.

- Искать таблицы и отчёты по поисковому запросу. Dwh-docs ищет по данным из документации, Jira-задачам, коду витрин, названиям таблиц и колонок.
- Документировать свои таблицы и отчёты.
- Видеть некоторые аномалии в данных. Это помогает пользователям понять, что теми или иными данными сейчас, возможно, не стоит пользоваться, потому что в них есть известная проблема.
- Подписываться на объекты. Подписка позволяет получить пуш-уведомление, если что-то произошло с твоими данными.
Проблема DBeaver. Другая проблема, с которой сталкивались наши пользователи, была связана с созданием запросов и вообще порогом входа в хранилище. Мы использовали бесплатный SQL-клиент DBeaver, который стал неудобен с появлением высокоуровневых бизнес-пользователей.
Интерфейс неудобный, сложные настройки, после обновления периодически ломается, например, работа с параметрами. Трудно настраивать клиент самому, аналитик помогал выбрать драйвер и ещё что-то. Не так много документации в интернете.
DBeaver достаточно сложно настраивать. Мы ставили себе вызов демократизировать аналитику и делать её доступной всё более широкому кругу пользователей. Решить этот вызов с использованием готового инструмента было проблематично. Мы решили создать свой SQL-клиент в браузере и поддержать в нём все нужные базы данных: Vertica, ClickHouse, PostgreSQL. За основу взяли sqlpad.io и кастомизировали под себя.
Новый клиент позволяет нам шарить запросы. Приведу пример. Менеджер продукта, у которого возникает вопрос по данным, обычно идёт к аналитику. Аналитик пишет запрос и отправляет ссылку на этот запрос продакту. По ссылке тот может увидеть и сам запрос, и его результаты.
В будущем менеджер продукта может поменять какие-то параметры (например, дату) и ответить на вопрос уже самостоятельно. Эта штука действительно сработала, и нам удалось понизить порог входа к данным.
Помимо этого мы добавили ещё несколько фич, которые позволяют удобнее работать с отчётами: строить витрины и интегрироваться с Tableau. Например, по нажатию кнопки можно создать источник данных в Tableau, либо перейти в веб-версию.
Аналогично тестам на витрины, в sqlpad мы добавили проверки планов adhoc-запросов. Таким образом мы страхуемся от того, что пользователь обрушит работу хранилища плохим запросом. Также мы можем делать подсказки, как улучшить производительность запроса.
Внедрив SQL-клиент мы заметили, что доля пользователей DWH среди авитовцев выросла. А новые сотрудники теперь пользуются только sqlpad и забыли про DBeaver.
Проблемы структуры
На этапе, когда мы перешли к созданию единых платформенных инструментов для пользователей аналитики, DWH развивали две команды: dwh-growth и dwh-infra.
Люди в dwh-growth фокусировались на том, чтобы наращивать скорость решения аналитических задач. Они помогали искать данные, строить отчёты, проверять гипотезы, развивали фреймворки и придумывали, что делать, если фреймворка для конкретной задачи ещё нет.
Команда dwh-infra отвечала за развитие инфраструктуры. Для работы высокоуровневых инструментов важно, чтобы платформа корректно функционировала, базы быстро отвечали на запросы, а сами данные были качественными и очищенными от ботов. Другая активность инфраструктурной команды была связана с уходом в realtime.
До какого-то момента всё было неплохо, но затем вскрылись проблемы такой структуры. У первой команды было множество пользовательских контекстов, и ей было очень сложно параллельно развивать ещё и инструменты. При этом у второй команды наоборот было мало взаимодействия, и ей сложно было фокусироваться на потребностях пользователя.
При этом инфраструктура всё усложнялась, а пользователей становилось всё больше: как я говорил, мы вовлекали в работу с данными не только аналитиков, но и инженеров и менеджеров продукта. Юнит DWH рос, и нам нужно было как-то масштабироваться, декомпозировать текущие команды, выбирать верную стратегию и цели. Здесь мы решили применить идею DWH как продукта не только к развитию хранилища, но и юнита.
Разделение команды
За основу для декомпозиции команд мы взяли высокоуровневые задачи пользователей из user story map. В теории получилась такая организация:
Название команды
Главная задача
Источник: habr.com
Что такое Data Warehouse (DWH) и зачем нужно корпоративное хранилище данных?

Хранилище данных – единая зона хранения данных, в которой в детальном или агрегированном виде сохраняются данные как единая версия правды для последующей отчётности или ad-hoc аналитики. Отчётность, которая строится на данных из хранилища, бывает управленческая, финансовая, регуляторная или аналитическая. Корпоративное хранилище данных специально строится в т.н. оффлайн-режиме (то есть опаздывает на один день по отношению к сформированным данным), чтобы иметь возможность делать агрегаты и предоставлять показатели, которые демонстрируют, каким образом изменяются параметры бизнеса, на основании каких продуктов бизнес получает прибыль или несёт убытки, каким образом формируются затраты и т.д. Всё это делается специально для того, чтобы можно было получить дневной срез или более серьёзный исторический взгляд на данные, не обращаясь напрямую к источникам данных. Основная задача хранилищ изначально и состояла в том, чтобы:
- отделить источники данных и не нагружать их дополнительной аналитикой и отчётностью;
- структурировать информацию таким образом, чтобы бизнес-пользователь мог быстро и легко пользоваться своими отчётами;
- объединить разноформатные данные из различных систем в единую структуру для удобства работы и возможности аналитики с использованием данных из разных систем.
Чем отличается DWH от обычной базы данных?
Классическое применение баз данных обычно раскладывается на базы, которые находятся в рамках каких-либо OLTP-систем, т.е. систем, которые используются в качестве репозиториев, или для хранилищ данных. То есть хранилища всегда используют базы данных для своей работы, однако эти данные структурированы таким образом, чтобы их можно было максимально быстро предоставить в качестве отчётности или для построения агрегатов.
Такая часть хранилища называется витриной данных. Она позволяет получить отчёт в течение 2-3 секунд, даже если дневной объём данных содержит в себе миллионы или миллиарды записей. Поэтому хранилище – это структурированная база данных, и структурирование – это отдельная часть проекта по внедрению хранилища, поскольку оно должно быть построено так, чтобы работа была быстрой, но при этом была учтена вся историчность изменений данных. Сама применимость базы данных под хранилище отличается от применимости любой другой базы данных.
Как бизнес использует DWH?
Хранилище данных – единая версия правды, которая может быть использована и другими системами, и бизнес-пользователями, и аналитиками. Наличие лишний записей в хранилище или отсутствие нужной информации может привести к тому, что хранилище фактически потеряет свою функцию именно по той причине, что оно не валидно. Основными бизнес-пользователями хранилища выступают:
- различные финансовые структуры. Они используют хранилище для обработки управленческой отчётности, на основании которой принимают свои решения о дальнейшем развитии бизнеса;
- все виды подразделений, которые работают с продажами, маркетингом и производством;
- все подразделения, деятельность которых связана с регуляторной отчётностью.
Вторым видом использования является ad-hoc аналитика. Она представляет собой возможность использования ранее рассчитанных показателей для аналитических исследований. Однако сейчас всё больше эта функция перекладывается на уровень озёр данных именно за счёт того, что озёра более эффективны для бизнес-пользователей за счёт возможности подтягивать дополнительную информацию.
В хранилище же сложно подтянуть себе для дальнейших исследований дополнительную информацию, которой ещё нет в системных источниках. Т.е. в хранилище бизнес-пользователь ограничен тем набором данных, который в хранилище уже загружен, а озеро снимает эту проблему. Таким образом, применение хранилища для ad-hoc аналитики характерно скорее для среднего бизнеса, либо крупного бизнеса, который пока не готов к использованию озёр.
DWH и бизнес-аналитика
Хранилище данных предназначено в первую очередь для анализа оттока и для предиктивной аналитики. Для этого было создано много аналитических решений, в том числе весьма мощных, использующих модели на основе данных, чаще всего – детальных данных. Однако сейчас в бизнес-аналитике фокус постепенно смещается в сторону использования озёр данных.
Структура DWH
О структуре хранилища данных можно рассуждать с классической точки зрения, а можно взглянуть более широко. Если мы говорим о классической схеме, то хранилище обычно содержит в себе детальный слой информации и слой витрин данных. Есть отдельное направление развития хранилищ данных, при котором витрины заменяются на OLAP-кубы. В этом случае средства, которые работают с кубами, также пользуются детальной информацией, но витрины, заполняемые данными в жёстком режиме, при этом не строятся.
Однако для наполнения хранилища данных чаще всего вводятся дополнительные зоны хранения данных при их перемещении для того, чтобы данные приобрели свою ценность и единую версию:
- ODS (Operational Data Store) – зона реплики системы-источника. Это зона данных, в которой в первую очередь перегружаются копии системы-источника, той части, которая нужна для формирования хранилища, чтобы быстро отпустить систему-источник и не влиять на неё своими запросами. Как правило, эта зона наполняется раз в сутки, после полуночи. Иногда это происходит чаще: например, в том случае, если на данных из этой зоны формируется оперативная отчётность, допустим, отчёт о продажах за последний час. Эта зона обычно обладает неконсолидированным набором данных, фактически копирующим структуру системы-источника.
- Набор стейджингов, или дополнительных зон хранения данных, которые используются, во-первых, для приведения данных в состояние требуемого качества, а также для консолидации данных разного формата. Подобные перемещения данных между зонами обычно решаются с помощью средств класса ETL (Extract, Transform, Load). Чтобы использовать данные хранилища, обычно применяются решения класса BI (Business Intelligence), средства построения отчётности и ad-hoc аналитики, средства дата-майнинга, т.е. предиктивной аналитики, или любые системы компании, которые уже должны пользоваться чистыми данными, собранными в компании.
Источник: dis-group.ru
Не Hadoop’ом единым: что такое КХД и как его связать с Big Data

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data).
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины [1].
Принцип слоеного пирога или архитектура КХД
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа [2].
Классически LSA реализуется в виде следующих уровней [3]:

- операционный слой первичных данных(Primary Data Layer или стейджинг), на котором выполняется загрузка информации из систем-источников в исходном качестве и сохранением полной истории изменений. Здесь происходит абстрагирование следующих слоев хранилища от физического устройства источников данных, способов их сбора и методов выделения изменений.
- ядро хранилища (Core Data Layer) – центральный компонент, который выполняет консолидацию данныхиз разных источников, приводя их к единым структурам и ключам. Именно здесь происходит основная работа с качеством данных и общие трансформации, чтобы абстрагировать потребителей от особенностей логического устройства источников данных и необходимости их взаимного сопоставления. Так решается задача обеспечения целостности и качества данных.
- аналитические витрины (Data Mart Layer), где данные преобразуются к структурам, удобным для анализа и использования в BI-дэшбордах или других системах-потребителях. Когда витрины берут данные из ядра, они называются регулярными. Если же для быстрого решения локальных задач не нужна консолидация данных, витрина может брать первичные данные из операционного слоя и называется соответственно операционной. Также бывают вторичные витрины, которые используются для представления результатов сложных расчетов и нетипичных трансформаций. Таким образом, витрины обеспечивают разные представления единых данных под конкретную бизнес-специфику.
- Наконец, сервисный слой (Service Layer) обеспечивает управление всеми вышеописанными уровнями. Он не содержит бизнес-данных, но оперирует метаданными и другими структурами для работы с качеством данных, позволяя выполнять сквозной аудит данных (data lineage), использовать общие подходы к выделению дельты изменений и управления загрузкой. Также здесь доступны средства мониторинга и диагностики ошибок, что ускоряет решение проблем.
Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами) [3]. Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW) [2].
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД [4] не совсем корректно по следующим причинам:
- разное целевое назначение – DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения [5];
- разные подходы к проектированию. Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями [1]. При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3 [5];
- наконец, цена – обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке [6]:
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- наконец, уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum [6].
От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка [6].

В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Источники
- https://ru.wikipedia.org/wiki/Хранилище_данных
- https://habr.com/ru/post/269727/
- https://habr.com/ru/post/281553/
- https://habr.com/ru/post/495670/
- https://chernobrovov.ru/articles/kuda-slit-big-data-ili-zachem-vam-ozero-dannyh.html
- https://habr.com/ru/company/tinkoff/blog/259173/
Источник: www.bigdataschool.ru