
1 Комплексирование средств ВТ позволяет повысить эффективность систем об-работки информации за счет чего?
А. повышения надежности
Б. снижения затрат
В. производительности ЭВМ
Г. комплексного использования единых мощных вычислительных и информационных ресурсов
Д. все ,вместе взятые
2 Все интерфейсы, используемые с ВТ и сетях, разделяются на сколько типов?
А. 3
Б. 2
В. 4
Г. 5
Д. 6
3 Параллельный интерфейс состоит из числа больших линий, по которым передача данных осуществляется в параллельном коде в виде
А. 8-24 разрядных слов
Б. 8-64 разрядных слов
В. 8-128 разрядных слов
Г. 24-128 разрядных слов
Д. 8-16 разрядных слов
4 Метод коммутаций сообщений обеспечивает
А. Независимость работы отдельных участков связи
Б. Сглаживание несогласованности
В. Эффективно реализуется передача многоадресных сообщений
Г. Передача информаций производится в любое время
Д. Все, указанные вместе
Урок 42. Сегментация памяти
5 Сколько существует групп методов доступа к сети?
А. 5
Б. 3
В. 2
Г. 4
Д. 6
6 Эффективность применения компьютерной сети определяется чем?
А. Позволяет автоматизировать управление объектами
Б. Концентрацией больших объемов данных
В. Все, вместе взятые
Г. Обеспечением надежного и быстрого доступа пользователей к вычислительным и информационным ресурсам
Д. Концентрацией программных и аппаратных средств
7 Оптоволоконная оптика позволяет повысить пропускную способность , например система F6 M обеспечивает передачу информации, до 6,3 Мбит/c, заменяя до
А. 96 телефонных каналов
Б. 45 телефонных каналов
В. 64 телефонных каналов
Г. 128 телефонных каналов
Д. 140 телефонных каналов
8 Создание высокоэффективных крупных систем связано с
А. Объединением ЭВМ с помощью средств связи
Б. Обслуживанием отдельных предприятий
В. Обслуживанием подразделения предприятий
Г. Все вместе взятые
Д. Объединением средств вычислительной техники
9 Передача информации между удаленными компонентами осуществляется с по-мощью чего?
А. Телеграфных каналов
Б. Коаксиальных кабелей связи
В. Беспроводной связи
Г. Телефонных каналов
Д. Все, вместе взятые
10 Сколько видов компонентов имеет ПО вычисленных сетей?
А. 2
Б. 4
В. 5
Г. 3
Д. 6
11 Международная организация по стандартизации ISO подготовила проект эта-лонной модели взаимодействия открытых информационных сетей. Она была принята в качестве международного стандарта и имеет несколько уровней, сколько их?
А. 6 уровней
Б. 5 уровней
В. 3 уровня
Г. 4 уровня
Д. 7 уровней
12 Фиксированный набор информации, называемый пакетом, независимо от типа ЛВС включает в себя
А. адрес получателя
Б. адрес отправителя
В. контрольная сумма
Г. данные
Падарян В. А. — Архитектура ЭВМ и язык ассемблера — Лекция 24
Д. все перечисленное
13 Все множество видов ЛВС, разделяется
А. на 4 группы
Б. на 3 группы
В. на 2 группы
Г. на 5 групп
Д. на 6 групп
14 Для современных вычислительных сетей что характерно?
А. Объединение многих ЭВМ и сети вычислительных систем
Б. Все, вместе взятые
В. Объединение широкого спектра периферийного оборудования
Г. Применение средств связи
Д. Наличие операционной системы
15 Совокупность ЭВМ, программного обеспечения, периферийного оборудования, средств связи с коммуникационной подсетью вычислительной сети, выполняющих прикладные процессы – это
А. абонентская система
Б. коммуникационная подсеть
В. прикладной процесс
Г. телекоммуникационная система
Д. смешанная система
16 Метод доступа Token Ring рассчитан на какую топологию
А. На «общую шину»
Б. На многосвязную
В. Иерархическую
Г. На кольцевую
Д. На звездообразную
17 Базовая коммуникационная сеть?
А. Совокупность коммуникационных систем
Б. Магистраль каналов связи
В. Совокупность ЭВМ
Г. Совокупность шин
18 Побитная инверсия машинного слова…
А. NOT
Б. INV
В. COM
19 Вычислительные системы, с какой архитектурой наиболее дешевы?
А. кластерные системы;
Б. параллельная архитектура с векторным процессором;
В. массивно-параллельная архитектура.
20 Что в большей мере определяет производительность кластерной системы?
А. способ соединения процессоров друг с другом;
Б. тип используемых в ней процессоров;
В. операционная система.
21 Доступны ли сегментные регистры прикладной программе в защищенном ре-жиме?
А. Да
Б. Только в реальном режиме
В. Нет
22 Какой модели организации памяти из перечисленных не существует?
А. сегментированная модель памяти реального режима
Б. сегментированная модель памяти защищённого режима
В. сплошная модель памяти защищённого режима
Г. сплошная модель памяти реального режима
23 Удастся ли в 32-х битном защищённом режиме получить доступ к памяти выше 4 ГиБ, если создать сегмент с базой большей нуля и пределом в 4 ГиБ?
А. Да, но только при включенном PAE.
Б. Да, это сработает всегда.
В. Да, но только при выключенном PAE.
Г. Нет, даже при включенной 36-битной адресации (PAE) все процессы по прежнему смогут адресовать только 4 ГиБ.
24 Какой уровень привилегий в защищенном режиме предназначен для выполнения кода ядра ОС?
А. Ring 3
Б. Ring 0
В. Ring 2
Г. Ring 1
25 Возможна ли прямая передача данных между ячейками памяти?
А. Да.
Б. Нет.
В. Только с использованием вспомогательного регистра-посредника.
26 Обязательно ли включать линию A20 для использования защищённого режима?
А. Да, иначе при переходе в режим произойдёт внутреннее исключение ЦПУ и компьютер будет перезагружен.
Б. Нет, линия A20 ни на что не влияет.
В. Нет, но без её включения не будет доступна оперативная память, расположенная выше 1 МиБ.
27 Какие утверждения верны для модели памяти Compact ?
А. адресация данных ближняя, адресация кода дальняя
Б. адресация данных ближняя, адресация кода ближняя
В. адресация данных дальняя, адресация кода ближняя
Г. ничего из приведенного
28 Какой способ адресации имеет наиболее компактный код?
А. регистровый
Б. регистровый относительный
В. непосредственный
Г. прямой
29 Что делает невозможным подключение компьютера к глобальной сети:
А. Тип компьютера,
Б. Состав периферийных устройств,
В. Отсутствие дисковода,
Г. Отсутствие сетевой карты.
30 В компьютерных сетях используются обычно каналы связи:
А. Провода;
Б. Кабели;
В. Радио связь,
Г. Все вышеперечисленное.
31 Эффективность компьютерной связи зависит обычно от:
А. Пропускной способности;
Б. Производительности процессора;
В. Емкости памяти,
Г. Все вышеперечисленное.
Источник: mebik.su
Какие утверждения верны для модели памяти Compact ? 1. адресация данных ближняя, адресация кода дальняя
Как быстро выучить стихотворение наизусть? Запоминание стихов является стандартным заданием во многих школах.
Как научится читать по диагонали? Скорость чтения зависит от скорости восприятия каждого отдельного слова в тексте.
Как быстро и эффективно исправить почерк? Люди часто предполагают, что каллиграфия и почерк являются синонимами, но это не так.
Как научится говорить грамотно и правильно? Общение на хорошем, уверенном и естественном русском языке является достижимой целью.
- Обратная связь
- Правила сайта
Источник: www.soloby.ru
Сегментная организация памяти в защищенном режиме
В основе сегментной модели памяти лежит разделение ее на независимые адресные пространства переменной длины — сегменты. Для программы адресное пространство разделено на блоки смежных адресов, называемых сегментами, а программа может обращаться только к данным, находящимся в этих сегментах.
Внутри сегментов применяется линейная адресация, то есть программа может обращаться к байту 0, байту 1 и т. д. Такая адресация осуществляется относительно начала сегмента, и физический адрес, ассоциируемый, например, с программным адресом 0, по существу, скрыт от программиста. Этот подход к управлению памятью опирается на тот факт, что программы обычно логически разделяются на области (сегменты) кода, данных и стека.
При этом упрощается изоляция программ друг от друга в мультипрограммном режиме работы. Каждый сегмент имеет свое целевое назначение. Каждая задача имеет непосредственный доступ к трем основным сегментам: кода, данных и стека, определяемых сегментными регистрами CS, DS SS соответственно, и к трем дополнительным сегментам данных, определяемых сегментными регистрами ES, FS, GS. Описания этих сегментов содержатся в их дескрипторах. Любая программа, независимо от уровня ее привилегий, не может обращаться к сегменту до тех пор, пока он не описан с помощью дескриптора, а сам дескриптор не помещен в таблицу дескрипторов.
Дескрипторы хранятся либо в глобальной таблице дескрипторов (Global Descriptor Table — GDT), либо в локальных таблицах дескрипторов (Local Descriptor Table — LDT). В GDT содержатся дескрипторы сегментов, которые доступны всем активным задачам, имеющимся в системе на данный момент. GDT может содержать любые дескрипторы сегментов, за исключением дескрипторов прерываний и ловушек. Обычно GDT включает дескрипторы сегментов кодов и данных операционной системы, сегментов состояния задач и дескрипторы сегментов, содержащих локальные таблицы дескрипторов. Микропроцессорная система имеет единственную глобальную таблицу дескрипторов.
Локальная таблица дескрипторов LDT используется для хранения дескрипторов, доступных только данной задаче. Их количество определяется количеством активных задач в системе.
С точки зрения расположения в памяти, локальные таблицы дескрипторов представляют собой обычные сегменты. Они могут накладываться друг на друга, частично пересекаться. Это приводит к тому, что отдельные сегменты, описанные дескрипторами в своих LDT, могут разделяться несколькими задачами (рис. 3.8).
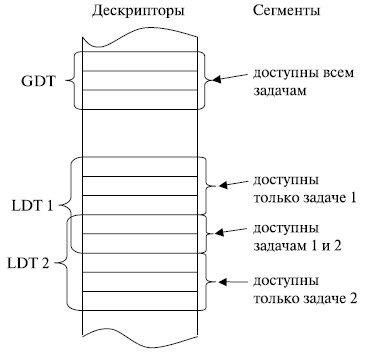
Рис. 3.8. Описание сегментов в таблицах дескрипторов
Для нахождения дескриптора в таблице дескрипторов используется селектор, который содержится в одном из сегментных регистров. Селектор представляет собой 16-разрядое слово, которое разбито на 3 поля (рис. 3.9):
- TI (Table Indicator — индикатор таблицы) показывает, к какой таблице идет обращение: TI = 0 — дескриптор находится в глобальной таблице дескрипторов GDT, TI = 1 — в локальной таблице LDT;
- Index: поле индекса — номер дескриптора в соответствующей таблице дескрипторов;
- RPL (Request privilege level — уровень привилегий запроса). При обращении сравнивается с полем DPL в байте доступа дескриптора.
Обращение разрешается, если уровень привилегий запроса не ниже, чем уровень привилегий дескриптора. 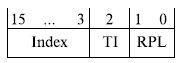 Рис. 3.9. Формат селектора Максимальное количество дескрипторов, находящихся в таблице дескрипторов, определяется длиной поля Index селектора и равно 2 13 . Так как каждый дескриптор имеет длину 8 байт, максимальный объем любой таблицы дескрипторов составляет 2 16 байт. Каждая из таблиц дескрипторов имеет регистр (GDTR для глобальной таблицы и LDTR для локальной), определяющий ее положение в памяти. Регистр GDTR содержит 48 разрядов, из которых 32 задают базовый адрес глобальной таблицы дескрипторов, а 16 указывают ее объем в байтах (границу таблицы). Для определения положения дескриптора относительно начала таблицы его номер (поле Index селектора) умножается на 8, то есть реально сдвигается на три разряда влево, так как длина дескриптора составляет 8 байт. Если селектор обращается к дескриптору, содержащемуся в таблице GDT (при TI = 0 в селекторе), то полученное смещение сравнивается с хранящейся в GDTR границей таблицы. Если нарушения границы нет, то смещение прибавляется к содержащемуся в GDTR базовому адресу, в результате чего образуется физический адрес выбираемого дескриптора (рис. 3.10). Нулевой дескриптор в GDT является пустым, не используемым. Селектор с нулевым значением разрядов 2….15 называется нуль-индикатором. Он обеспечивает обращение к нулевому дескриптору GDT. Так как этот дескриптор не используется, то при обращении к нему происходит прерывание. Одно из возможных применений пустых селекторов заключается в следующем. Перед инициированием задачи операционная система может загрузить в регистры DS и ES пустые селекторы. Если в последующем не инициализировать эти регистры, то адресация памяти через них вызовет особый случай (прерывание). Загрузка в LDTR пустого селектора, для которого поле Index = 0, допустима. Такая операция сообщает процессору о том, что в задаче не будет использоваться локальная дескрипторная таблица. Это характерно для небольших однопользовательских систем. Для обращения к локальной таблице дескрипторов предназначен 16-разрядный регистр LDTR. Он содержит селектор, определяющий размещениев GDT дескриптора используемой локальной таблицы дескрипторов.
Рис. 3.9. Формат селектора Максимальное количество дескрипторов, находящихся в таблице дескрипторов, определяется длиной поля Index селектора и равно 2 13 . Так как каждый дескриптор имеет длину 8 байт, максимальный объем любой таблицы дескрипторов составляет 2 16 байт. Каждая из таблиц дескрипторов имеет регистр (GDTR для глобальной таблицы и LDTR для локальной), определяющий ее положение в памяти. Регистр GDTR содержит 48 разрядов, из которых 32 задают базовый адрес глобальной таблицы дескрипторов, а 16 указывают ее объем в байтах (границу таблицы). Для определения положения дескриптора относительно начала таблицы его номер (поле Index селектора) умножается на 8, то есть реально сдвигается на три разряда влево, так как длина дескриптора составляет 8 байт. Если селектор обращается к дескриптору, содержащемуся в таблице GDT (при TI = 0 в селекторе), то полученное смещение сравнивается с хранящейся в GDTR границей таблицы. Если нарушения границы нет, то смещение прибавляется к содержащемуся в GDTR базовому адресу, в результате чего образуется физический адрес выбираемого дескриптора (рис. 3.10). Нулевой дескриптор в GDT является пустым, не используемым. Селектор с нулевым значением разрядов 2….15 называется нуль-индикатором. Он обеспечивает обращение к нулевому дескриптору GDT. Так как этот дескриптор не используется, то при обращении к нему происходит прерывание. Одно из возможных применений пустых селекторов заключается в следующем. Перед инициированием задачи операционная система может загрузить в регистры DS и ES пустые селекторы. Если в последующем не инициализировать эти регистры, то адресация памяти через них вызовет особый случай (прерывание). Загрузка в LDTR пустого селектора, для которого поле Index = 0, допустима. Такая операция сообщает процессору о том, что в задаче не будет использоваться локальная дескрипторная таблица. Это характерно для небольших однопользовательских систем. Для обращения к локальной таблице дескрипторов предназначен 16-разрядный регистр LDTR. Он содержит селектор, определяющий размещениев GDT дескриптора используемой локальной таблицы дескрипторов. 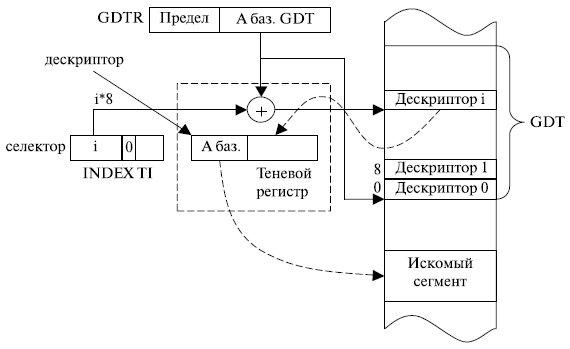 Рис. 3.10. Получение дескриптора, находящегося в глобальной таблице дескрипторов GDT Такая структура упрощает работу с таблицами LDT. Благодаря описанию LDT с помощью селектора эти таблицы превращаются в обычные сегменты памяти и, в частности, могут размещаться в любых областях памяти, участвовать в свопинге и т. п. Внутри процессора с регистром LDTR ассоциируется так называемый «теневой регистр», в котором и хранится дескриптор LDT текущей задачи. Это ускоряет в последующем обращение к локальной таблице дескрипторов текущей задачи. При переключении с одной задачи на другую для замены используемой LDT достаточно загрузить в регистр LDTR селектор новой LDT, а процессор уже автоматически загрузит в теневой регистр дескриптор новой LDT при первом обращении к нему. Если в селекторе индикатор таблицы TI = 1, то дескриптор сегмента выбирается из локальной таблицы дескрипторов. Процесс определения адреса сегмента в этом случае представлен на рис. 3.11. Он более сложен по сравнению с получением дескриптора из глобальной таблицы дескрипторов и проходит следующие этапы:
Рис. 3.10. Получение дескриптора, находящегося в глобальной таблице дескрипторов GDT Такая структура упрощает работу с таблицами LDT. Благодаря описанию LDT с помощью селектора эти таблицы превращаются в обычные сегменты памяти и, в частности, могут размещаться в любых областях памяти, участвовать в свопинге и т. п. Внутри процессора с регистром LDTR ассоциируется так называемый «теневой регистр», в котором и хранится дескриптор LDT текущей задачи. Это ускоряет в последующем обращение к локальной таблице дескрипторов текущей задачи. При переключении с одной задачи на другую для замены используемой LDT достаточно загрузить в регистр LDTR селектор новой LDT, а процессор уже автоматически загрузит в теневой регистр дескриптор новой LDT при первом обращении к нему. Если в селекторе индикатор таблицы TI = 1, то дескриптор сегмента выбирается из локальной таблицы дескрипторов. Процесс определения адреса сегмента в этом случае представлен на рис. 3.11. Он более сложен по сравнению с получением дескриптора из глобальной таблицы дескрипторов и проходит следующие этапы:
- Анализируем, к какой из двух возможных таблиц дескрипторов идет обращение. Если в селекторе TI = 1, то обращение идет к локальной таблице дескрипторов.
- Находим дескриптор локальной таблицы дескрипторов в глобальной таблице дескрипторов.
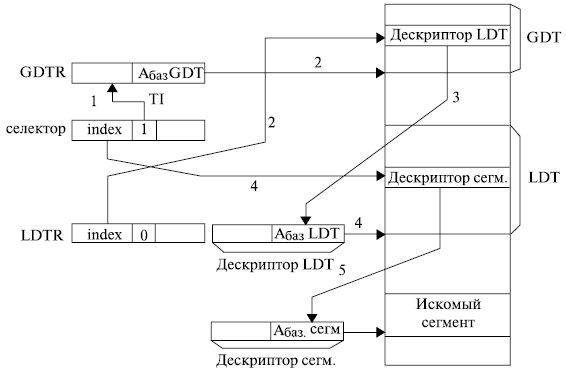 Рис. 3.11. Получение дескриптора, находящегося в локальной таблице дескрипторов LDT
Рис. 3.11. Получение дескриптора, находящегося в локальной таблице дескрипторов LDT
- Считываем дескриптор LDT в «теневой» регистр регистра LDTR микропроцессора. После считывания дескриптора в «теневой» регистр дальнейшее обращение к сегменту аналогично обращению к GDT, где вместо GDTR используются поля базового адреса и предела из дескриптора LDTR, находящегося в «теневом» регистре.
- По адресу локальной таблицы дескрипторов, находящемуся в ее дескрипторе, и номеру дескриптора из обрабатываемого селектора находим дескриптор сегмента в локальной таблице дескрипторов.
- Записываем дескриптор сегмента в «теневой» регистр сегментного регистра микропроцессора для ускорения последующих обращений к искомому сегменту.
Таким образом, при обращении к сегменту через таблицу LDT появляется дополнительный уровень вложенности, снижающий быстродействие микропроцессора. «Теневые» регистры микропроцессора частично обеспечивают решение этой проблемы. Поле адреса дескриптора, полученного из локальной или глобальной таблицы дескрипторов, определяет начало искомого сегмента. При суммировании полученного базового адреса сегмента и смещения в сегменте получается линейный адрес искомой ячейки памяти. В случае если режим страничной адресации выключен (в регистре CR0 бит PG = 0), полученный линейный адрес равен физическому адресу искомого операнда или команды. Рассмотрим подробнее процесс получения адреса операнда на примере команды MOV EAX, [ECX+ESI+20h]. В этой команде нет специальных указаний об использовании сегмента, поэтому она обращается к текущему сегменту данных, селектор которого по умолчанию находится в сегментном регистре DS. Пусть (DS) = 0000000000011.0.XXb. Формирование физического адреса операнда включает следующие действия (для сегментированного ЛАП):
- Образовать эффективный адрес (вычислить смещение в сегменте):
EA = (ECX)+(ESI)+20h.
- Выбрать 3-й дескриптор (Index = 3) из GDT (TI = 0).
Для этого:
- считать базовый адрес глобальной таблицы дескрипторов (
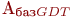 ) из GDTR;
) из GDTR; - вычислить
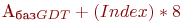 ;
; - обратиться по полученному адресу в память и считать нужный дескриптор.
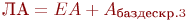 , где
, где  -базовый адрес сегмента из считанного дескриптора с номером 3.
-базовый адрес сегмента из считанного дескриптора с номером 3.Источник: studfile.net