
Все сталкивались с пересылкой по электронной почте текстовых и прочих документов. При этом некоторые из них необходимо переводить в электронный вид. Иногда полученные файлы требуют редактирования. На помощь приходит функция распознавания текста со скана или картинки. Этим пользуются студенты, которые предпочитают справочники и литературу иметь в электронном виде.
Принцип работы
Сейчас в интернете можно найти научную, справочную, учебную, методическую и прочую литературу. Книги и статьи, выпущенные в прошлом, оцифрованы и представляют собой фотографии, сканы в различных форматах.
Для работы в текстовом редакторе понадобится программа, считывающая текст с картинки. Последние версии позволяют распознавать на изображении не только текст, но и таблицы.
Любой графический файл (растровый рисунок) состоит из точек. Оптическое распознавание букв основано на выделении точек, их анализе и преобразовании в текст. А процесс выглядит следующим образом:
Как распознать текст с фото. Как перевести фото в формат Word.
- Выделяются блоки, содержащие текст.
- Приложение блок выстраивает в линии.
- Линия делится на слова.
- Слова делятся на символы.
- Символ анализируется с шаблонами шрифтов.
- Программное обеспечение перебирает множество вариантов.
- В итоге распознавалка выдает текст, готовый к изменению в редакторе.
Все многообразие программного обеспечения делится на:
- бесплатные программы;
- платные программы;
- онлайн-сервисы.
Распознаватели предоставляют широкие возможности. После процедуры полученный файл можно сохранить в различных форматах: Word, Excel, PowerPoint, Jpeg, PDF. К тому же можно сделать перевод текста, сжатие файла, применить эффекты, отсканировать и даже проверить на антиплагиат.
Используемые программы
Среди платных и бесплатных программ встречаются как хорошо зарекомендовавшие себя продукты, так и не нашедшие широкого применения. По составленному рейтингу в сети большей популярностью пользуются следующие.
ПрограммаПоддерживаемые языкиФормат сохраненияДостоинстваAbbyy Fine Reader179DOC, DOCX, XLS, XLSX, PPT, PPTX, PDFСохраняет структуру, высокая скоростьCunei Form20RTF, TXT, HTMLПрисутствует редактор, обработка пакетами, сохраняется структура документаWin Scan 2PDF3PDFОтсутствие дополнительных инструментов, пакетная обработкаSimple OCR3DOC, TXT, TIFFТекстовый редакторVue Scan32PDF, JPG, TIFFСохранение шаблонов, всплывающие подсказкиRi Doc4DOC, DOCX, XLS, XLSX, PDF, JPG, TIFFРедактор, конвертерTop OCR11HTML, RTF, PDF, MP3Создание аудиофайловCapture TextНа кириллице и латиницеDOC, TXT, RTFИзвлечение текста и картинок и анимацииInformatik Scan3JPG, BMP, PNG, TIFF, PDFУдаление однотонных блоков, редактор текстаReadiris130DOC, XLS, RTF, TXT, PDF, JPG, TIFFОпределение рукописного текста
Abbyy Fine Reader
Программа для распознавания текста с картинки от разработчика ABBYY считается одной из лучших. В своем функционале имеет множество инструментов. В зависимости от версии она работает и с djvu-файлами.
Источник сканов
Сканирование. Перед началом работы с растровыми изображениями необходимо настроить сканер текста с фото. В настройках указывается максимальное количество точек на дюйм (DPI). Рекомендуемое значение не ниже DPI 300. Чем больше этот показатель, тем выше качество и меньше вероятность возникновения ошибок.
Цветность. От цветности зависит скорость сканирования. Среди основных ее настроек три варианта:
- Черно-белый — подходит для сплошного текста.
- Оттенками серого можно воспользоваться, если нужно сканировать документ, содержащий картинки, таблицы и текст.
- Цветным режимом пользуются, когда идет оцифровка журналов и периодики, для которых цветопередача важнее содержания.
Фотография. Программа для считывания текста с картинки работает не только со сканами, но и с фотографиями, снятыми на фотоаппарат или на смартфон в хорошем разрешении. Но как показывает практика, снимки со смартфона имеют искажения, которые влияют на распознавание.
Распознавание графических документов
Утилита работает почти со всеми популярными файлами с расширением jpeg, bmp, png, tiff. Рабочая область имеет два экрана. На левом находится исходник, на правом — результат. После загрузки фото в программу производится его распознавание, но не всегда процедура происходит корректно. Часто приходится прибегать к ручному режиму.
Если есть выход в интернет, то полученный результат можно проверить на орфографические ошибки.
Текст. На панели инструментов есть иконка «Т», которая при выделении области исключает работу с таблицами и изображениями. При наличии на странице нескольких таблиц, выделять текст придется несколькими блоками. После чего нажимается иконка «Распознать».
Изображения. При необходимости копирования изображений со сканированного листа они просто выделяются, копируются и вставляются. Не нужно пользоваться графическим редактором для обрезки. Word обладает рядом инструментов для редактирования изображений.
Ненужные области. На отсканированных страницах встречаются области, мешающие работе, такие как реклама и колонтитулы. Перед работой с документами эти области следует удалить. В Fine Reader есть функция «ластик». С ее помощью ненужная область удаляется полностью до белого листа.
Работа с DJVU и PDF
Документы этих форматов не что иное, как графические изображения, преобразованные в формат меньшего объема. И хранить таких документов можно значительно больше на ограниченном объеме памяти.
Распознавание и чтение файлов djvu и pdf идет по всей странице, включая номера страниц и колонтитулы. Это затрудняет дальнейшее редактирование. Чтобы исключить лишнюю информацию в программе устанавливаются дополнительные настройки, ограничивающие рабочую область. Делается это следующим образом:
- Редактирование → работа с изображениями.
- Активировать опцию «Обрезка».
- Установить границы обработки.
- Сохранить настройки кнопкой «Применить ко всем страницам».
Работа онлайн
Если на компьютере или ноутбуке мало места и нет желания возиться с установкой специального программного обеспечения, можно бесплатно воспользоваться онлайн-сервисами. Хороший и известный Img2txt. Сервис бесплатный, функционирует с 2014 года.
Войдя, через вкладку «Открыть» загружается необходимый файл. Далее, нажимается кнопка «Начать распознавание», запускается процедура сканирования текста с фотографии онлайн и его распознавание.
В качестве вывода специалистами отмечается, что широким функционалом обладают платные версии программ. Но если нужно просто распознавание текста для работы с текстовым редактором, то достаточно онлайн-сервисов.
Источник: dzen.ru
5 бесплатных программ для сканирования и распознавания текста
Программы для распознавания текста позволяют конвертировать сфотографированные или отсканированные документы непосредственно в предложения.
Дело в том, что текст на изображении представлен в виде растра, набора точек.
Упомянутый софт осуществляет превращение набора точек в полноценный текст, доступный для редактирования и сохранения.

Содержание:
- ABBYY FineReader 10
- OCR CuneiForm
- WinScan2PDF
- SimpleOCR
- Freemore OCR
Распознавание букв призвано оптимизировать процесс оцифровки бумажных печатных или рукописных книг, документов.
Такой метод оцифровки на порядки превосходит скорость ручного набора с изображения. Широко применяется при оцифровке библиотек и архивов.
Далее рассмотрим пятерку лучших представителей семейства подобных программ.
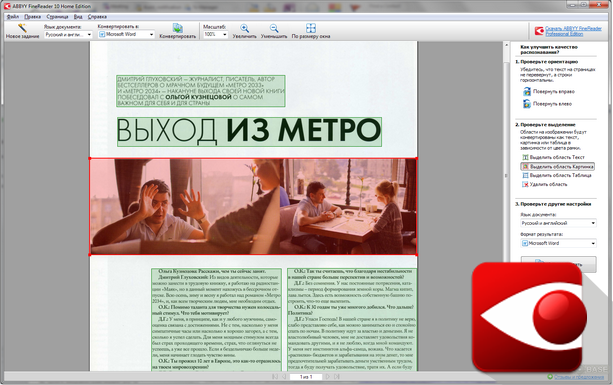
ABBYY FineReader 10
FineReader безоговорочный лидер среди всех программ, распознающих текст на изображении. В частности, софта, более четко обрабатывающего кириллицу нет.
Вообще в активе FineReader 179 языков, текст на которых распознается чрезвычайно успешно.
Единственное обстоятельство, которое может разочаровать пользователей, состоит в том, что программа платная.
Бесплатно распространяется только пробная версия на 15 дней. За этот период разрешено сканирование 50-ти страниц.
Дальше за пользование программой придется платить. FineReader легко «кушает» любое более-менее качественное изображение.
Источник при этом совершенно неважен. Будь то фотография, скан страницы или любая картинка с буквами.
Достоинства:
- точное распознавание;
- огромное количество языков чтения;
- толерантность к качеству изображения-источника.
Недостаток:
- пробная версия на 30 дней.
Вам это может быть интересно:
OCR CuneiForm
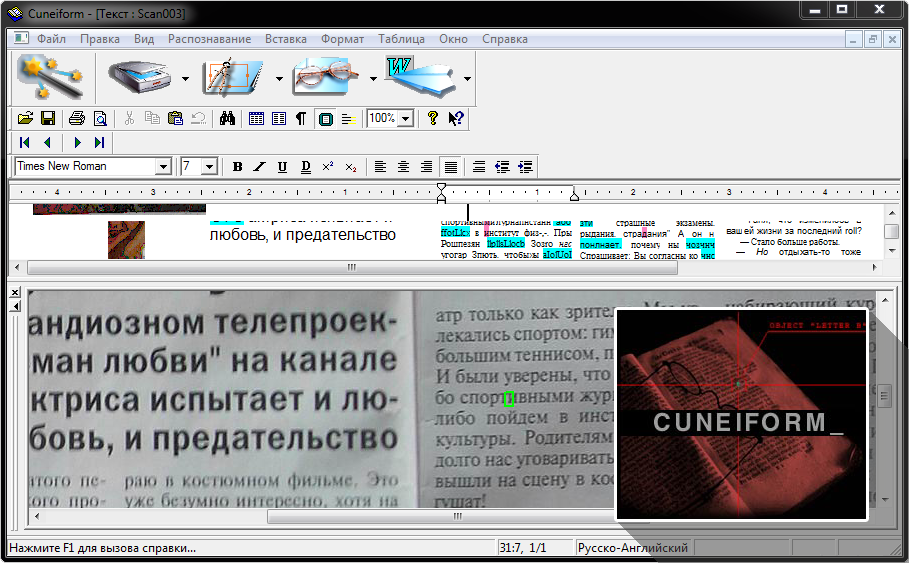
Бесплатная программа для считывания текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей рассматриваемой программы.
Но как для бесплатной утилиты, функционал все-таки на высоте.
Интересно! CuneiForm распознает блоки текста, графические изображения и даже различные таблицы. Более того, считыванию поддаются даже неразлинованные таблицы.
Программа может прочитать и сохранять шрифт и кегль распознаваемого текста. В базе шрифтов содержится большинство используемых печатных шрифтов.
Поддерживается даже распознавание текста вышедшего из печатной машинки.
Для обеспечения точности к процессу распознавания подключаются специальные словари, которые пополняют словарный запас из сканируемых документов.
Достоинства:
- бесплатное распространение;
- использование словарей для проверки правильности текста;
- сканирование текста с ксерокопий плохого качества.
Недостатки:
- относительно небольшая точность;
- небольшое количество поддерживаемых языков.
WinScan2PDF
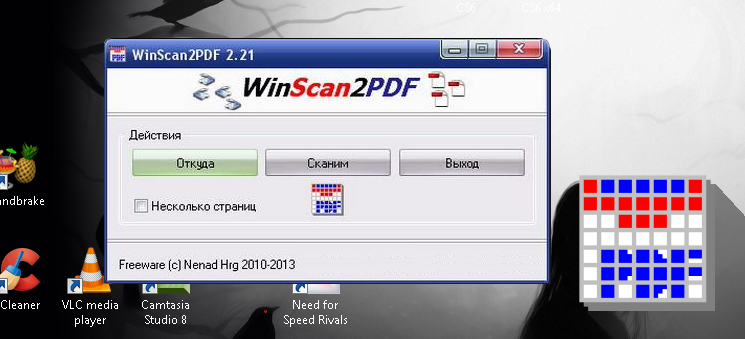
Winscan2pdf — это даже не полноценная программа, а утилита. Установка не потребуется, а исполнительный файл весит всего в несколько килобайт.
Процесс распознавания происходит предельно быстро, правда, полученные в его результате документы сохраняются исключительно в формате PDF.
Фактически весь процесс выполняется при нажатии трех кнопок: выбор источника, места назначения и, собственно, запуска программы.
Утилита предназначена для быстрой пакетной обработки множества файлов. Для удобства пользователей предусмотрен большой языковой пакет интерфейса.
Достоинства:
- портативность;
- быстрая работа;
- простота в использовании.
Недостатки:
- минимальный размер;
- единственный формат файлов на выходе.
SimpleOCR
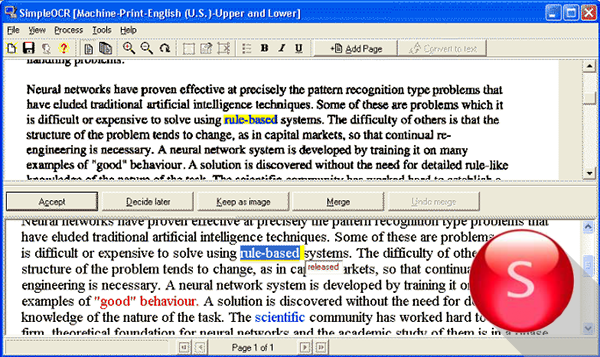
Отличная небольшая программа для распознавания текстов с изображений. Поддерживает даже чтение рукописей.
Беда в том, что русский не входит ни в языковой пакет интерфейса, ни в список поддерживаемых для распознавания языков.
Однако если необходимо отсканировать английский, датский или французский, то лучшего бесплатного варианта не найти.
В своей области программа обеспечивает точную расшифровку шрифтов, удаление шума и извлечение графических изображений.
К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
Достоинства:
- точное распознавание текста;
- удобный текстовый редактор;
- удаление шума с изображения.
Недостатки:
- полное отсутствие русского языка.
Freemore OCR
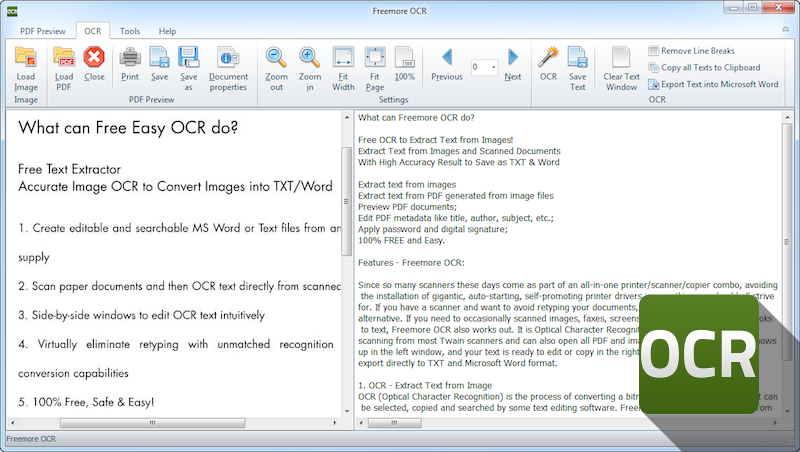
Программа позволяет оперативно извлекать текст и графику с изображений. Софт поддерживает работу с несколькими сканерами без потери производительности.
Извлеченный текст может быть сохранен в формате текстового документа или документа MS Office.
Кроме того предусмотрена функция многостраничного распознавания.
Распространяется Freemore OCR бесплатно, однако, интерфейс только на английском.
Но это обстоятельство никак не влияет на удобство пользования, потому как организованы элементы управления интуитивно понятным образом.
Достоинства:
- бесплатное распространение;
- возможность работы с несколькими сканерами;
- достойна точность распознавания.
Недостатки
- Отсутствие русского языка в интерфейсе;
- Необходимость загрузки русского языкового пакета для распознавания.
Программа для распознавания текста. Как распознать текст с картинки
5 бесплатных программ для сканирования и распознавания текста
Источник: geek-nose.com
Для распознавания текста в формате графического изображения используют какую программу

Популярное
- Сканирование документов от 1,5 руб./страница
- Сканирование книг от 4 руб./страница
- Сканирование фотографий от 10 руб./фото
- Распознавание текста от 2 руб./стр
- Сканирование чертежей формата А1 от 60 руб./стр
- Обработка анкет от 2 руб./анкета

3 руб. за страницу за автоматическое распознавание.
Подробнее на странице Распознавание текста.
Этапы сканирования и распознавание текста
Опуская процесс подготовки оригиналов, сам процесс сканирования и распознавания можно разделить на следующие этапы.
1. Выбор режима сканирования. Для успешного распознавания и минимизации ошибок, специалист сканирования должен, прежде всего, правильно подготовить документ для распознавания, настроить оборудование для получения максимально качественной цифровой копии оригинала. Свежеотпечатанный на принтере текст и старая газета с выцветшим шрифтом и пожелтевшей бумаге требуют к себе разного подхода на всех этапах сканирования и распознавания. Однако профессиональные опытные специалисты с помощью новейших программно-аппаратных средств отлично справляются с любыми задачами такого рода.
Также на этом этапе важно определиться с режимом сканирования. Для текстового черно-белого документа, не содержащего картинок и иллюстраций (или же эти элементы так же черно-белые), достаточно выбрать режим черно-белого сканирования или режим градации серого. Однако если текст не черно-белый, присутствуют цветные элементы, картинки, графики, схемы, и нам нужно получить точную копию, режим сканирования должен быть соответствующим, то есть цветным. Если цветность не принципиальна, то можно ограничиться режимом сканирования в градациях серого.

2. Далее приступаем к распознаванию текста. Для начала с помощью специализированных программ анализируется структура документов. На этом этапе важен контроль специалиста, так как возможные ошибки на этом этапе потребуют серьезных усилий по их устранению в последствии.
Следующий этап — непосредственное распознавание текста. Этот процесс так же доверяем компьютерной программе распознавания текста.
3. Проверка результата и устранение ошибок. После окончания процесса распознавания, не смотря на постоянно совершенствующееся программное обеспечение, получившийся результат необходимо проверить и откорректировать вручную. Чем хуже состояние оригинала, тем больше возникает ошибок и только человек может провести коррекцию и исправить все недочеты.
Далее происходит проверка на предмет синтаксических и орфографических ошибок, расставляются, по необходимости, знаки препинания и специальные символы.

4. И последний этап это форматирование документа. Проверяется и если нужно корректируется размер шрифта, стили заголовков и текста, разбивается на абзацы, главы, проверяется нумерация страниц и оглавление документа. Также проверяется общая структура документа и верстка. Графические элементы, картинки, графики, схемы и другие иллюстрации так же проходят проверку на предмет соответствия.
После проведения всех вышеописанных процедур, мы получаем точную и самое главное редактируемую копию оригинала. Теперь мы с легкостью можем вносить изменения, копировать и делится этим документом, получить необходимое количество твердых копий. На основании этого документа можно создавать свои собственные документы. При этом документ будет храниться, без риска быть испорченным, потерянным или украденным.

Доверьте работу профессионалам
Наша компания на рынке с 2006 года. Профессиональное оборудование и опытный персонал. Сотни тысяч обработанных документов и книг. Всё это позволяет нам предложить вам оптимальные по соотношению цена/качество услуги.
Страница сгенерирована за 0.01 секунд !
Источник: redocs.ru