
Одним из самых популярных инструментов, используемых для этой цели, является Screaming Frog SEO Log File Analyser. Следует отметить, что программа не является бесплатной. Лицензия стоит 100 долларов США в год. Существует также бесплатная версия с ограниченной функциональностью:
Краулеры (поисковые роботы): зачем нужны, виды, как управлять и анализировать?
Краулер (поисковый робот, робот, паук) — это программа, являющаяся неотъемлемой частью поисковой системы и отвечающая за просмотр веб-сайтов и сканирование их содержимого, нажатие на страницы и ссылки для импорта собранной информации в базу данных поисковой системы.
Допустим, есть пользователь Иван Иванов, который каждый день посещает популярный книжный интернет-ресурс, который регулярно пополняется новыми наименованиями. Зайдя на сайт, Иван выполняет следующую последовательность действий:
- Заходит на главную страницу.
- Переходит в раздел «Новые книги».
- Просматривает список с недавно добавленными материалами.
- Открывает ссылки с заинтересовавшими его заголовками.
- Ознакомляется с аннотациями и скачивает интересующие его файлы.
Иванову потребовалось около 10 минут, чтобы найти подходящий материал. Если каждый день он будет тратить 10 минут на поиск нужной ему книги, то в общей сложности это займет у него 5 часов в месяц. И это только для одного сайта.
Узнай, кто такой скрапер, парсер и краулер! Почему Python актуален для фрилансера?
Чтобы избежать этих затрат времени, следует использовать программу, которая автоматически ищет новые книги.
Без роботов ни одна поисковая система не была бы эффективной, будь то Google или новая поисковая система. И чтобы избежать той же участи, что и Иван, они используют роботов, которые «ползают» по сайтам в поисках новой информации, которую поисковые системы предлагают пользователям. И чем лучше краулер сканирует, тем релевантнее контент в результатах.
Основные боты имеют следующие функции:
- Собирают новый или обновленный контент с веб-ресурсов. Сканированием свежих публикаций и ранее размещенных статей занимаются пауки первого порядка.
- Идентификация зеркал. Краулер отыскивает сайты, содержащие идентичный контент, но с разными доменами. Подобные боты имеет Яндекс.
- Сканирование графических файлов. Для поиска графики может быть привлечен отдельный робот.
Как сделать картинку уникальной для поисковиков. Как сделать так чтобы фото не нашли в яндексе.
И много других различных краулеров, имеющих свое собственное назначение, о которых мы поговорим ниже.
Виды краулеров
Каждая поисковая система имеет свои собственные веб-краулеры, которые выполняют различные задачи. Давайте поговорим о ботах двух самых популярных поисковых систем.
Роботы Яндекса
- YandexBot – основной краулер, занимающийся индексацией.
- YandexImages – вносит в индекс изображения ресурсов.
- YandexMobileBot – собирает страницы для их анализа и определения адаптации для смартфонов.
- YandexDirect – сканирует данные о материалах ресурсов-партнером РСЯ.
- YandexMetrika – поисковый паук сервиса Яндекс.Метрика.
- YandexMarket – бот Яндекс.Маркета.
- YandexCalenda – краулер Яндекс.Календаря.
- YandexNews – индексирует Яндекс.Новости.
- YandexScreenshotBot – делает скриншоты документов.
- YandexMedia – индексатор мультимедийных данных.
- YandexVideoParser – робот Яндекс.Видео.
- YandexPagechecker – отображает микроразметку.
- YandexOntoDBAPI – паук объектного ответа, который скачивает изменяющиеся данные.
- YandexAccessibilityBot – скачивает документы и проверяет, имеют ли к ним доступ пользователи.
- YandexSearchShop – скачивает файлы формата Yandex Market Language, которые относятся к каталогам товаров.
- YaDirectFetcher – собирает страницы, содержащие рекламу, с целью проверки их доступности для пользователей и анализа тематики.
- YandexirectDyn – создает динамические баннеры.
Боты Google
- Googlebot – главный индексатор контента страниц не только для ПК, но и адаптированных под мобильные устройства.
- AdsBot-Google – анализирует рекламу и оценивает ее качество на страницах, оптимизированных под ПК.
- AdsBot-Google-Mobile – выполняет аналогичные функции, что и предыдущий, только предназначен для мобильных страниц.
- AdsBot-Google-Mobile-Apps – работает также, как и стандартный AdsBot, но оценивает рекламу в приложениях, предназначенных для устройств на базе операционной системы Android.
- Mediaparnters-Google – краулер маркетинговой сети Google AdSense.
- APIs-Google – юзер-агент пользователя APIs-Google для отправки пуш-уведомлений.
- Googlebot-Video – вносит в индекс видеофайлы, содержащиеся на страницах ресурсов.
- Googlebot-Image – индексатор изображений.
- Googlebot-News – сканирует страницы с новостями и добавляет их в Google Новости.
Кции: что это такое, как добавить или убрать коллекции. Где находится моя коллекция в яндексе?
ТРОФИ И КРАУЛЕРЫ в «Арене-Пилотаж»
Другие поисковые роботы
Гусеницы есть не только у поисковых систем. В популярной социальной сети Facebook, например, есть боты, которые сканируют страницы, размещенные пользователями, и отображают ссылки с заголовками, описаниями и изображениями. Давайте подробнее рассмотрим веб-пауков за пределами Google и Yandex.
Ahrefs
Самый популярный инструмент для SEO-продвижения, который помогает анализировать массу ссылок. Что он делает:
- изучает обратные ссылки;
- проводит мониторинг конкурентов;
- анализирует ранжирование;
- проверяет сайты, недействительные ссылки;
- изучает ключевые слова, фразы и многое другое.
Как управлять поисковым роботом?
Часто бывает так, что доступ к определенным страницам сайта должен быть ограничен для определенных краулеров. Для этого существуют специальные правила, которые веб-мастера предписывают паукам соблюдать. Они указываются в файле robots.txt.
Попав на сайт, роботы сначала сканируют информацию в файле со списком документов, которые не подлежат индексации, например, личные данные зарегистрированных пользователей. Прочитав правила, краулер либо покидает сайт, либо начинает индексировать ресурс.
- разделы сайта или фрагменты контента, закрытых/открытых для пауков;
- интервалы между запросами роботов.
Единственный выход из этой ситуации — написать собственный сценарий для сканирования, сбора, хранения и систематизации важной информации. Но как это сделать? Дочитайте до конца, и вы увидите, что все очень просто!
По сути, это робот, который работает по принципу роботов, индексирующих сайты для поисковых систем. Принцип работы очень прост: он ищет в коде страницы нужную информацию, извлекает ее и сохраняет в структурированном виде в виде списка, таблицы или базы данных.
Представьте, что Сергею Брину однажды помешали основать Google. Без поисковой системы вы никогда не смогли бы быстро найти в Интернете рецепт любимого блюда, информацию о написании курсовой работы или что-нибудь еще. Поэтому логический вывод таков: поисковые системы — те же краулеры, но разработанные в виде самого простого, понятного и удобного инструмента.
Автографические анализаторы, работающие по тому же принципу, позволяют:
- Страница about.html закрыта от всех краулеров.
- Роботам твиттера разрешено смотреть сайты, в адресе которых содержится /images .
- Остальным поисковым паукам разрешено посещать страницы, которые заканчиваются на /images, но глубже переходить нельзя ( Dissallow: /images/* ).
Что такое сниппет и как правильно его написать. Для чего нужен сниппет.
Как написать краулер? Туториал для новичков!
Главная>Блог>Business>И это лишь малая часть возможностей, которые открывает использование анализатора.
Существует два способа сканирования веб-сайтов для поиска и хранения нужной информации:
Один из вариантов для людей, знающих основы программирования. Самописный скрипт характеризуется тем, что его функциональность определяете вы. И вы можете настроить бота для любой задачи: от отслеживания цен до сбора базы данных поставщиков.

Что такое Web Crawler?
Чаще всего трекеры пишутся на языке Python. Сам сценарий состоит из трех частей:
Но почему именно Python? В конце концов, разве тот же JavaScript или PHP намного проще в изучении и может обеспечить такую же функциональность? Речь идет о библиотеках, которые гораздо эффективнее осуществляют поиск информации по заданным параметрам.
Однако из-за высокого входного порога написание первого парсера на Python может занять много времени. А если вы не хотите утруждать себя основами программирования, то обратите внимание на второй способ очистки данных.
- Собирать информацию по заданной теме из различных ресурсов с одного или нескольких сайтов;
- Анализировать настроения аудитории посредством сбора отзывов о различных товарах или услугах;
- Сформировать базу данных с адресами, контактами магазинов для выявления новых рынков сбыта продукции вашей компании.
Все дело в использовании преимуществ существующих инструментов парсинга. Вы также можете создать сканер для своих нужд. Для этого:
Создание веб-краулера
Вам не нужно исправлять ошибки или беспокоиться о настройке «правильной» скорости сканирования — все это включено «по умолчанию» в предварительно созданные анализаторы.
Парсинг с помощью языков программирования
- Направление запроса по URL-адресу страницы с последующим возвращением её содержимого;
- Генерирование древовидной структуры на основе полученного HTML-кода со сканированием по заданным веткам;
- Синтаксический анализ полученной информации через библиотеки Python для выделения нужных вам фрагментов.
Готовый парсер
- Переходим в режим «Расширенных настроек»;
- Создаем новую задачу, вводим адрес сайта;
- «Разбиваем» страницу, выделяя нужные нам пункты;
- Зацикливаем процесс, начинаем извлечение данных.
Источник: gbiznesblog.ru
Что такое поисковый робот: и как им управлять
Краулер (от английского crawler — «ползать») — это поисковый робот, используемы поисковой системой для обнаружения новых страниц в интернете. Простыми словами, краулер — это поисковый робот Google, «Яндекса» и других поисковых систем.
Принцип работы заключается в постоянном сканировании страниц и нахождении на них ссылок с дальнейшим переходом по ним. Всю собранную информацию робот заносит в специальную базу данных, которая называется индексом. Данные о новых страницах в интернете поисковая машина берет как раз из такого индекса.
Отдельно следует отметить большое количество синонимов, которыми могут называть поискового краулера. Среди них поисковый паук, робот, бот, ant, webspider, webrobot и т. д.

Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
Как поисковый робот видит страницу
Он видит веб-сайт совсем не так, как его видит пользователь. Вместо привычного нам визуального контента паук обращает внимание на заголовок, ответ и IP-адрес:
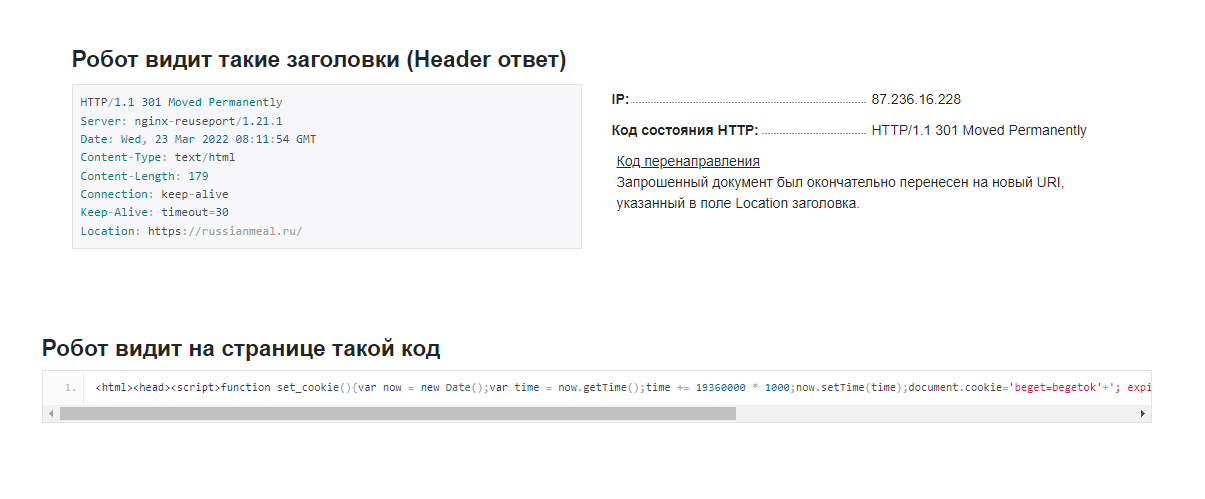
Поисковый робот анализирует следующие параметры:
- Ответ HTTP-заголовка страницы.
- Текущий веб-сервер.
- Текущую дату в GMT-формате.
- Тип контента.
- Объем контента.
- Наличие Keep-Alive (постоянное HTTP-соединение).
- Локейшн (URL сайта / страницы).
- Код перенаправления.
- IP-адрес.
- Установленные сайтом правила cookie.
- Внешние и внутренние ссылки на странице.
Как работает робот Google и «Яндекса»
Если представить алгоритм взаимодействия поискового робота со страницей обобщенно, оно выглядит следующим образом:
- Переход по URL.
- Сканирование контента страницы.
- Сохранение содержимого на сервере. На этом этапе может происходить конвертация формата данных в удобочитаемый для поисковой машины формат.
- Повторение указанной цепочки с переходом по новому URL.
У каждой поисковой машины свои роботы, и порядок сканирования может немного различаться. Например, по количеству посещений, максимальному количеству переходов, зацикливанию и т. д.
Все это регламентируется поисковой системой. Соответственно, нельзя вывести какие-то общие цифры, но можно посмотреть на поведение типичного, на примере паука Googlebot:

Апдейты в поисковых системах: что это, виды апдейтов и где отслеживать
Типы краулеров
Поисковые системы используют разные типы для сканирования разного контента. Например, у Google есть отдельные поисковые роботы для обработки изображений, видео, новостного контента, общего качества страницы. Кроме этого, у зарубежной ПС имеется собственный целевой робот для индексации мобильных страниц и проверки качества рекламы. Каждый из перечисленных поисковых роботов обладает собственным user-agent’ом, и при желании для любого из них можно создать директиву в стандарте исключения для роботов. Об этом мы расскажем в разделе «Как запретить обход сайта».
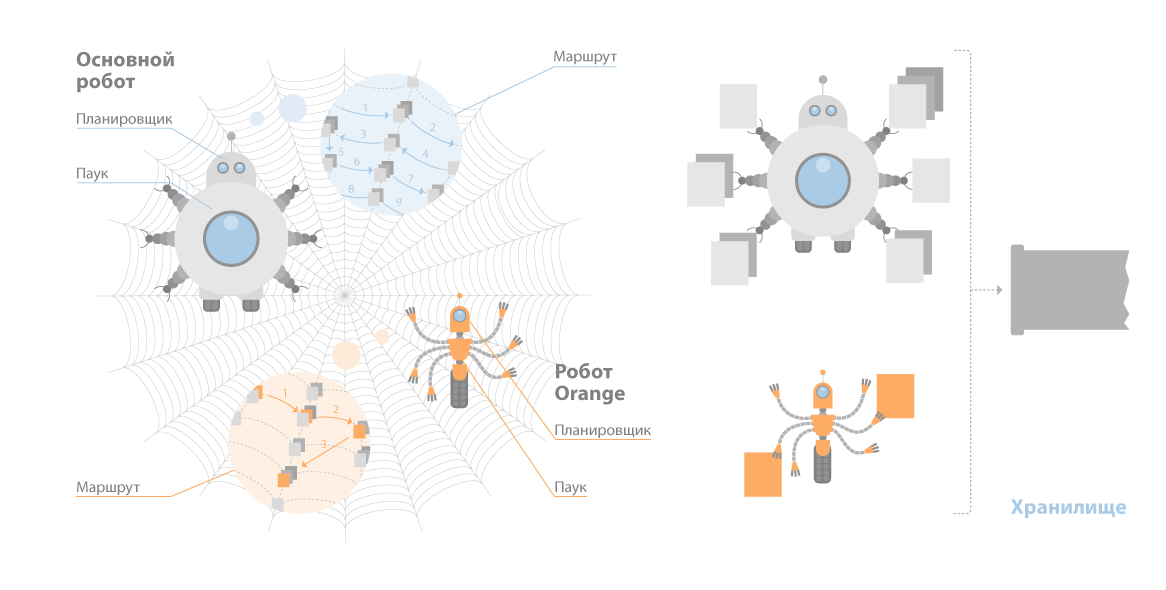
У «Яндекса» разноцелевых гораздо меньше: по разным оценкам — от четырех до пяти штук. Основных пауков у «Яндекса» два: стандартный бот и быстрый паук Orange.
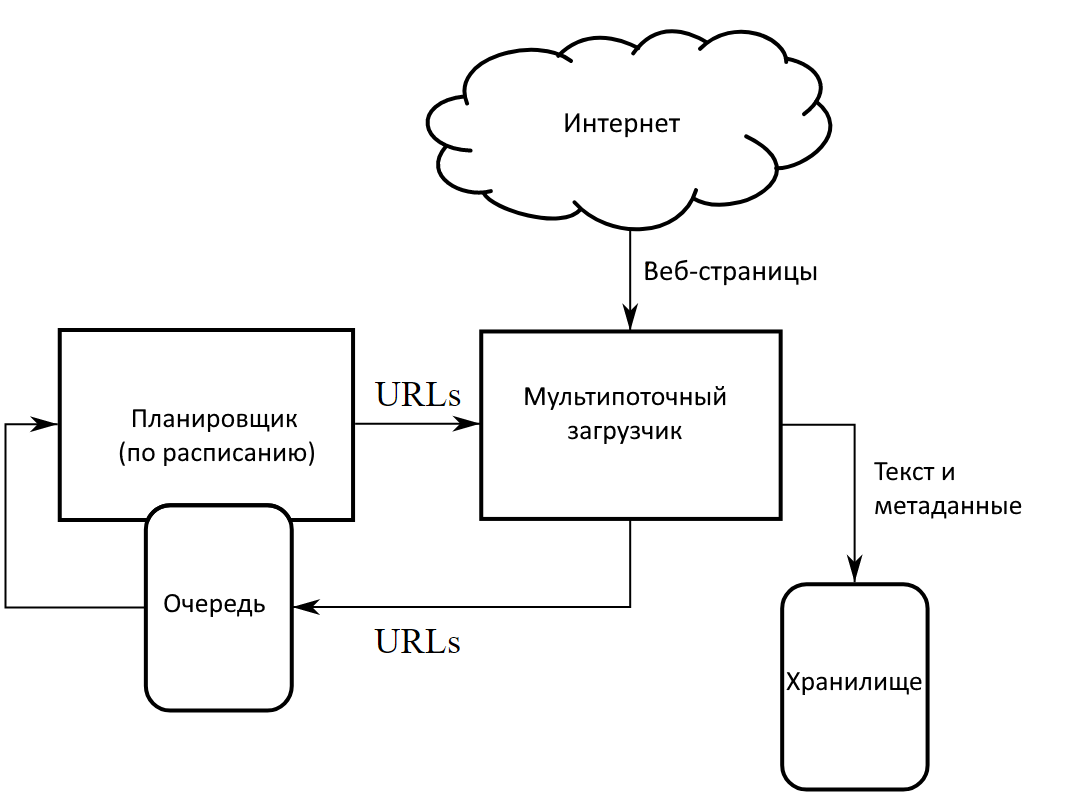
Работа краулера на примере поискового робота «Яндекса» выглядит так:
- Планировщик строит очередность сканирования.
- Этот маршрут отправляется роботу.
- Он обходит документы.
- Если сайт отдает корректный ответ, он скачивает данные.
- Самостоятельно идентифицирует параметры документа, включая язык.
- Затем он отправляет полученные сведения в кэш «Яндекса» или иное хранилище.
Вот примерная визуализация этих процессов:
Как часто обновляется индекс Google и «Яндекса»
Информация о найденных ссылках попадает в базы данных поисковых машин не сразу, а через определенный период времени. Обновление индекса — базы данных, содержащей ссылки на вновь найденные URL — у «Яндекса» может занимать от нескольких дней до 1–2 недель. Google же обновляет индекс гораздо чаще — несколько раз за сутки.
Это, пожалуй, одно из самых принципиальных отличий между двумя поисковыми системами именно с точки зрения процессов обработки новых страниц.

Отличия SEO под Яндекс и Google
Почему краулер не индексирует все страницы сайта сразу
Учитываются и повторные запросы сканирования одного и того же URL. Кроме того, у каждой поисковой машины существуют ограничения по уровням доступа, а также по размеру текстового контента.
По всем вышеуказанным причинам сайт, особенно если он имеет сложную структуру и большое количество страниц, не может быть проиндексирован за один раз (и даже за 2-3-4).
Индексация в поисковых системах: что это простыми словами
Зачем поисковые роботы притворяются реальными пользователями
Краулеры поисковых систем почти всегда «играют по правилам». Они никогда не представляются пользовательским клиентом — например, браузером. Однако пауки различных сервисов сканируют огромные массивы данных. Если они будут соблюдать все ограничения для краулеров (бюджеты обращений, интервалы между обращениями), скорость сканирования будет оставаться очень низкой.
Чтобы решить эту проблему, разработчики веб-сервисов в частном порядке создают пауков, которые представляются пользовательским клиентом, чаще всего — браузером.
Фактор роботности

Google Analytics для начинающих: самое полное руководство. Часть 1. Universal Analytics
В любом отчете «Яндекс.Метрики» можно ограничить отображение визитов, создаваемых роботами. Для этого откройте любой интересующий вас отчет, кликните по строке «Данные с роботами» и выберите необходимый сценарий фильтрации:
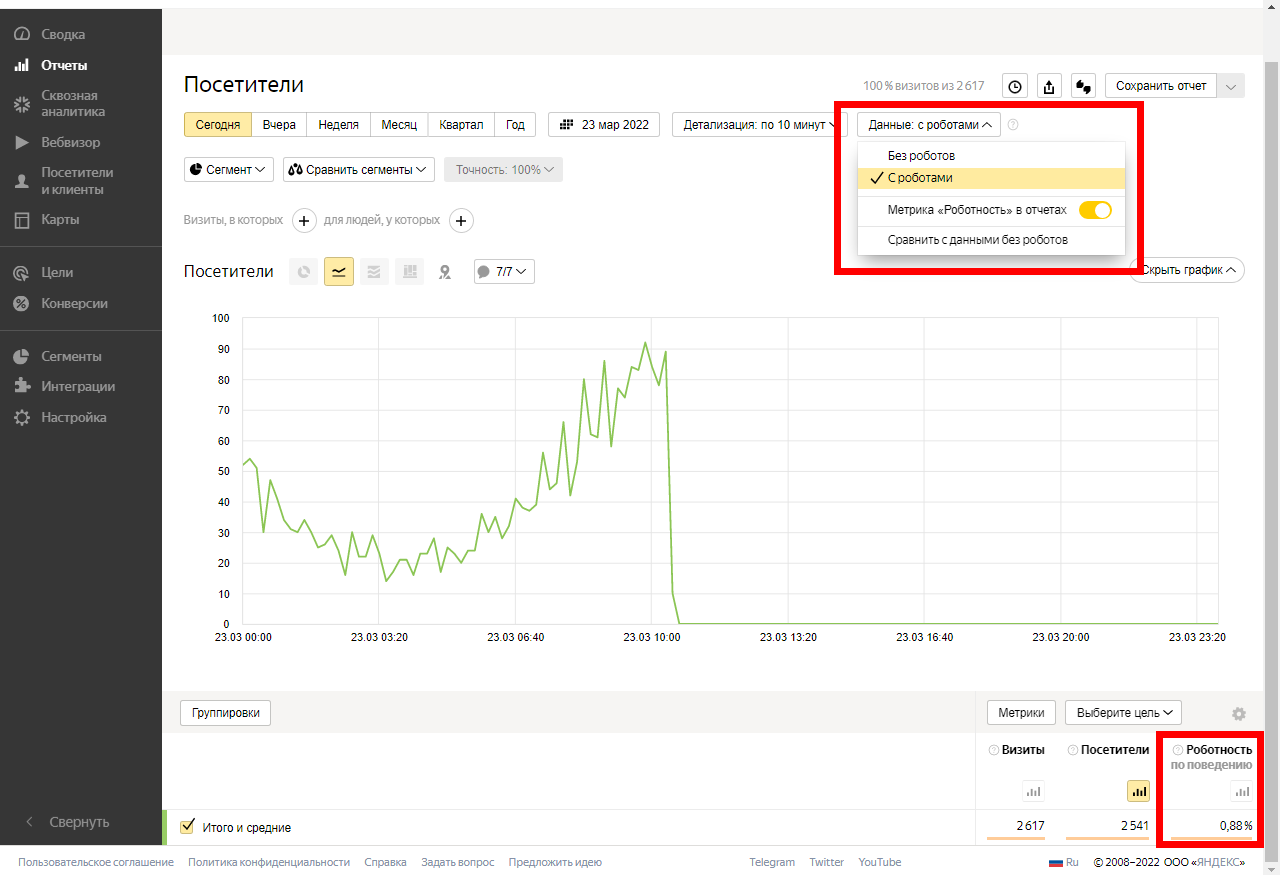
Роботность по поведению — это доля визитов роботов, определенных по поведенческим факторам. Роботы по поведению маскируются под реальных посетителей
В Google Analytics также можно фильтровать роботов. Для этого откройте настройки администратора и перейдите в параметры представления:
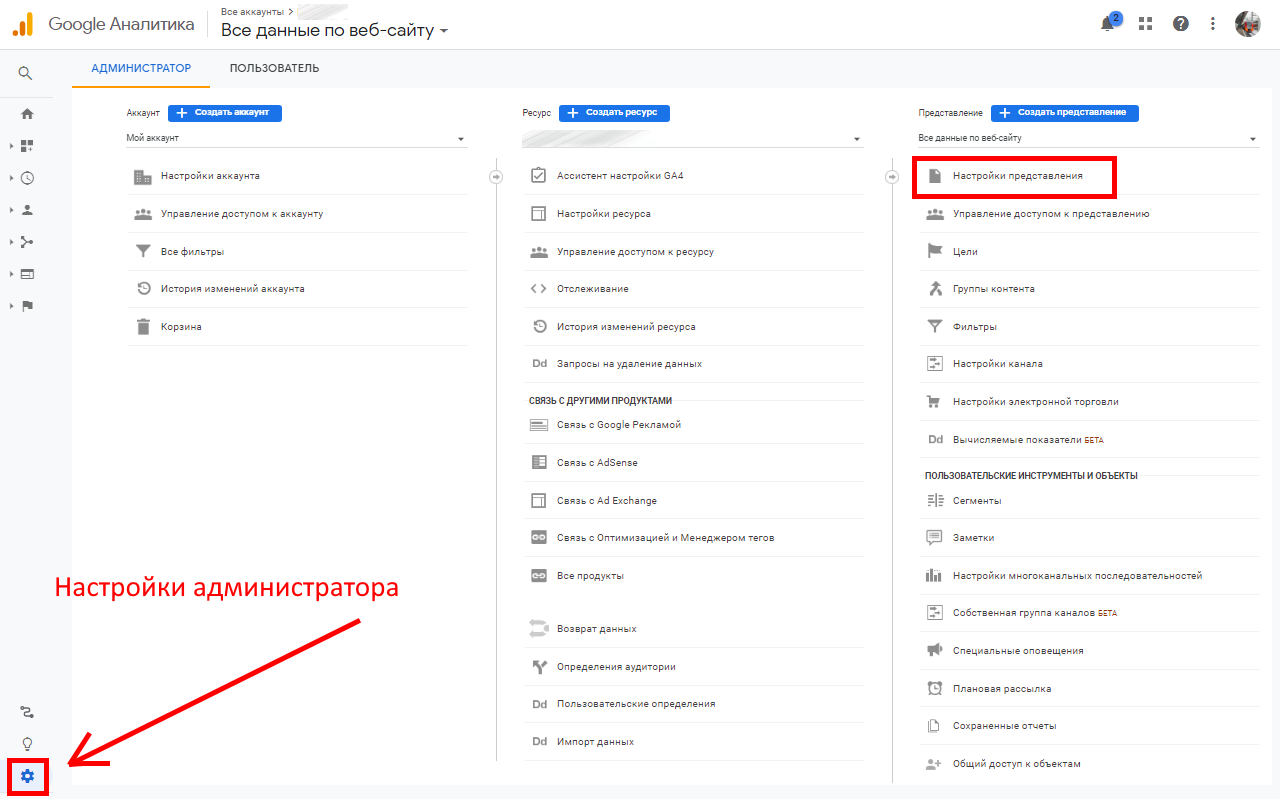
Сделайте активным чекбокс «Исключить обращения роботов и пауков»:
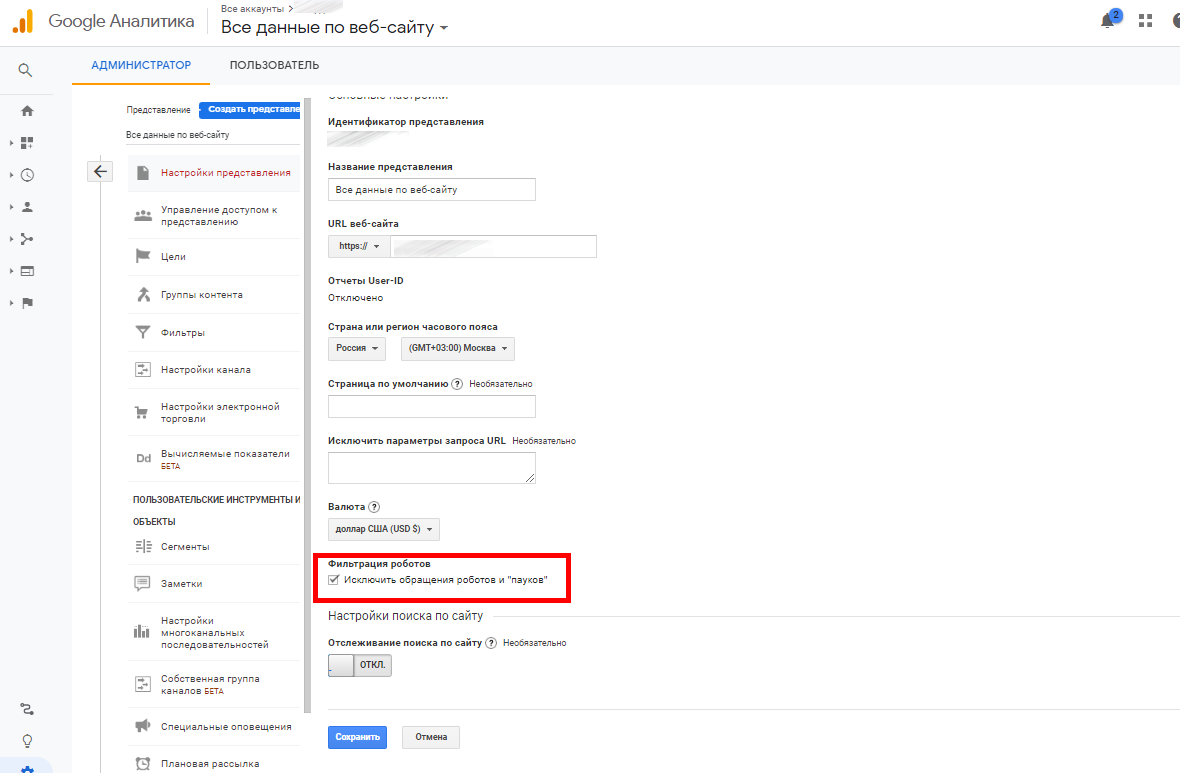
Всё. Теперь GA не будет учитывать их своих отчетах.
Комплексная веб-аналитика
- Позволяет видеть каждый источник трафика, его качество — процент конверсии по каждой кампании, группе объявлений, объявлению, ключевому слову.
- Даст понимание насколько качественный трафик дает каждый канал, стоит ли в него вкладываться или стоит ограничить.
Вежливые и вредные роботы
Классификация не официальная, но вполне подходящая в данном случае.
Вежливые роботы — те, которые представляются. Вредные роботы — маскируются под пользователя.
Не стоит думать, что объем трафика, генерируемого роботами, ничтожен: поисковые роботы есть не только у Google и «Яндекса», а также других поисковых систем, но и у огромного количества аналитических сервисов, сервисов статистики, SEO-инструментов. Например, существуют: Alexa, Amazon, Xenu, NetPeak, SEranking.
Поисковые роботы указанных сервисов в некоторых случаях — например, при сверхограниченных ресурсах сервера — могут становиться настоящей проблемой. Часто вебмастеры сталкиваются и с откровенно вредоносными краулерами, которые постоянно добывают определенный тип данных: например, электронные адреса для создания баз данных для организации дальнейших почтовых рассылок.
Способов борьбы предостаточно. Например, для многих CMS сегодня доступны разнообразные инструменты, ограничивающие воздействие вредных пауков на сайт. Часто они сделаны в виде плагинов или расширений. Например, в WordPress разработан плагин Blackhole for Bad Bots.
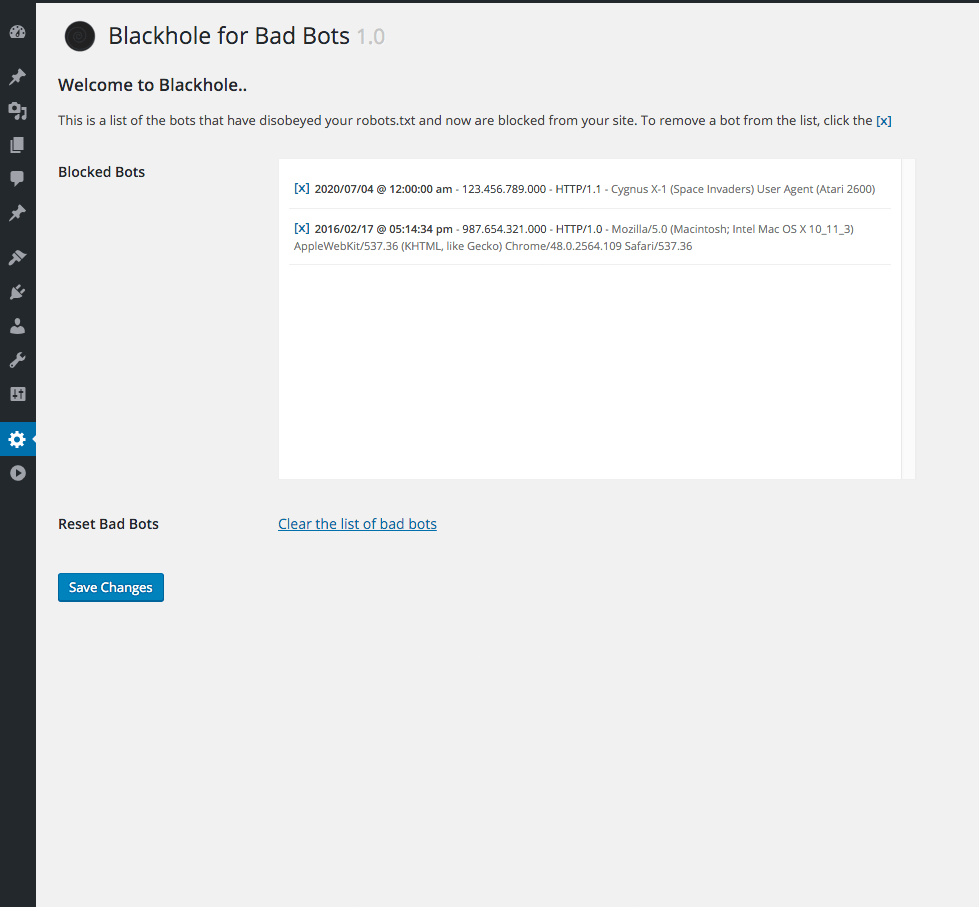
Этот плагин работает так: сначала плагин добавляет скрытую триггерную ссылку в нижний коллонтитул страниц. Вебмастер добавляет в robots.txt строку, запрещающую всем паукам переходить по скрытой ссылке. Те, которые игнорируют или не подчиняются правилам, сканируют ссылку и автоматически попадают в ловушку.
Плохие краулеры вредны для сайта в первую очередь тем, что создают высокую нагрузку на сервер. В особо тяжелых случаях сайт даже может стать недоступным.
Источник: kokoc.com
Что такое веб-краулер?

Веб-краулеры (поисковые роботы) – важная часть инфраструктуры Интернета. В этой статье мы рассмотрим:
- Определение веб-краулера
- Как работают поисковые роботы?
- Примеры веб-краулеров
- Почему веб-краулеры важны для SEO
- Проблемы, с которыми сталкиваются поисковые роботы
Определение веб-краулера
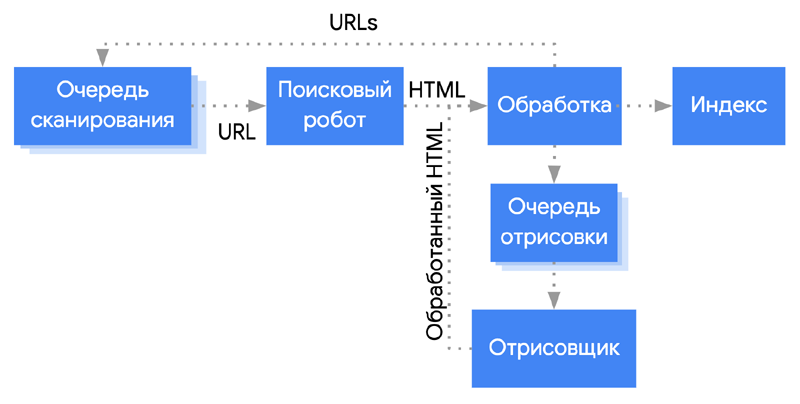
Веб-краулер — это программный робот, который сканирует Интернет и загружает найденные данные. Большинство краулеров работают под управлением поисковых систем, таких как Google, Bing, Baidu и DuckDuckGo. Поисковые системы применяют свои алгоритмы поиска к собранным данным, чтобы сформировать индекс своей поисковой системы. Индексы позволяют им предоставлять релевантные ссылки пользователям на основе их поисковых запросов.
Существуют поисковые роботы, которые служат не только поисковым системам, но и другим интересам, например The Way Back Machine из Интернет-архива, который предоставляет снимки сайтов в определенный момент времени в прошлом.
Как работают поисковые роботы?
Поисковые роботы, такие как Googlebot, начинают каждый день со списка сайтов, которые они хотят просканировать. Это называется краулинговым бюджетом. Он отражает потребность в индексировании страниц. На краулинговый бюджет влияют два основных фактора: популярность и устаревание.
URL-адреса, которые более популярны в Интернете, обычно сканируются чаще, чтобы они оставались свежими в индексе. Поисковые роботы также пытаются предотвратить устаревание URL-адресов в индексе.
Когда краулер подключается к сайту, он начинает с загрузки и чтения файла robots.txt. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям.
Владельцы сайтов могут определить, какие пользовательские агенты могут и не могут получать доступ к сайту. В robots.txt также можно определить директиву задержки сканирования, чтобы ограничить скорость запросов, которые сканер делает на сайте. В Robots.txt также перечисляются связанные с сайтом карты сайта, так что краулер может найти каждую страницу и время ее последнего обновления. Если страница не изменилась с момента последнего посещения краулером, он ее пропустит.
Когда поисковый робот, наконец, достигает страницы для сканирования, он отображает ее в браузере, загружая весь HTML, сторонний код, JavaScript и CSS. Эта информация хранится в базе данных поисковой системы, а затем используется для индексации и ранжирования страницы. Он также загружает все ссылки на странице. Ссылки, которых еще нет в индексе поисковой системы, добавляются в список для последующего сканирования.
Соблюдение директив в файле robots.txt является добровольным. Большинство основных поисковых систем следуют директивам robots.txt, но некоторые этого не делают. Злоумышленники, такие как спамеры и ботнеты, игнорируют директивы robots.txt. Даже некоторые законные поисковые роботы, такие как Архив Интернета, игнорируют файл robots.txt.
Примеры веб-краулеров
Поисковые системы имеют несколько типов поисковых роботов. Например, у Google есть 17 типов ботов:
- APIs-Google
- AdSense
- AdsBot Mobile Web Android
- AdsBot Mobile Web
- Googlebot Image
- Googlebot News
- Googlebot Video
- Googlebot Desktop
- Googlebot Smartphone
- Mobile Apps Android
- Mobile AdSense
- Feedfetcher
- Google Read Aloud
- Duplex on the web
- Google Favicon
- Web Light
- Google StoreBot
Почему веб-краулеры важны для SEO
Цель SEO заключается в том, чтобы ваш контент можно было легко найти, когда пользователь выполняет поиск по определенному поисковому запросу. Google не может знать, куда ранжировать ваш контент, если он не проиндексирован.
Поисковые роботы также могут помочь и в других областях. Сайты эл. коммерции часто сканируют сайты конкурентов для анализа выбора продукции и ценообразования. Этот тип сбора данных обычно известен как «веб-скрапинг вместо сканирования». Веб-скрапинг фокусируется на определенных элементах данных HTML.
Веб-скраперы очень целенаправленны, тогда как веб-краулеры расставляют широкую сеть и собирают весь контент. На стороне пользователя также есть инструменты SERP API, которые помогают сканировать и собирать данные поисковой выдачи.
Проблемы, с которыми сталкиваются поисковые роботы
Есть ряд проблем, с которыми могут столкнуться поисковые роботы.
| Проблема | Описание |
| Ограничения robots.txt | Если поисковый робот соблюдает ограничения robots.txt, он не сможет получить доступ к определенным страницам или отправить запросы, превышающие произвольное ограничение. |
| Баны IP | Поскольку некоторые поисковые роботы не соблюдают ограничения robots.txt, они могут использовать ряд других инструментов для ограничения сканирования. Сайты могут блокировать IP-адреса, которые считаются вредоносными, например, бесплатные прокси данных, используемые мошенниками, или определенные IP ЦОД. |
| Ограничения геолокации | Некоторые сайты требуют, чтобы посетитель находился в определенной локации для доступа к содержимому сайта. Хорошим примером является попытка доступа к контенту Netflix USA за пределами США. Большинство гео-ограничений можно преодолеть с помощью резидентных прокси-сетей. |
| CAPTCHA | Некоторые веб-сайты, обнаружив большое количество активности из подозрительных источников, выставляют CAPTCHA, чтобы проверить, настоящий ли человек стоит за запросом. CAPTCHA могут нарушить деятельность веб-краулеров. Многие решения для веб-скрапинга имеют инструменты и технологии для преодоления подобных блокировок. Эти инструменты часто используют решение для разблокировки CAPTCHA. |
Подведем итоги
Поисковые роботы являются важной частью инфраструктуры Интернета. Они позволяют поисковым системам собирать данные, необходимые для создания поисковых индексов и предоставления результатов поиска по запросам пользователей. Многие компании обращаются к краулерам, чтобы помочь им в своих исследованиях. Зачастую они сосредоточены только на одном или двух сайтах, таких как Amazon, Adidas или Airbnb. В таких случаях для их нужд лучше подходят такие инструменты, как веб-парсеры IDE от Bright Data.
Источник: ru-brightdata.com