
Оптическое распознавание символов (англ. optical character recognition, OCR ) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко применяется для преобразования книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание символов позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
Источник: wiki2.org
OCR и OСV: распознавание и верификация символов для производств
Оптическое распознавание символов (англ. optical character recognition, OCR) – технология преобразования изображений, содержащих буквенно-цифровые надписи (рукописные или напечатанные), в машиночитаемые текстовые данные.
Необходимость в распознавании символов возникает перед промышленными предприятиями достаточно часто. В то же время задача осложняется сложными условиями производства: неровная поверхность, сложный способ нанесения, неподходящее освещение, пыль, блики и другие факторы затрудняют процесс распознавания.
Помимо считывания символов зачастую требуется их верификация (англ. optical character verification, OCV) – проверка соответствия символов в одной или нескольких символьных строках символам, которые должны содержаться в данных строках.
Уровень развития технологий сегодня таков, что уверенное распознавание и верификация большинства маркировок могут быть обеспечены применением систем машинного зрения «из коробки». Уже более 8 лет наша компания является официальным партнером-интегратором в России и СНГ мирового лидера в производстве систем машинного зрения – компании Cognex. Алгоритмы и оборудование Cognex позволяют быстро проектировать и разрабатывать высококачественные приложения на основе машинного зрения в широком спектре отраслей. Однако существуют задачи, с которыми типовое оборудование не справляется, и тогда требуется разработка индивидуального решения на основе собственных алгоритмов машинного зрения и глубокого обучения, в чем наша компания также специализируется. Цель статьи: поделиться практическим опытом применения машинного зрения для успешного распознавания и верификации символов в различных промышленных приложениях.
Учим программу распознавать текст на картинках, видео, играх ▲ Python + OpenCV + Tesseract
Оборудование для распознавания и верификации символов, и его возможности
Современные технологии OCR и OCV применяются на производстве для решения следующих задач:
- Контроль наличия маркировки
- Идентификация объектов контроля по маркировке
- Track а также возможность подключения до 8 камер на 1 ПК, что позволяет удешевить решение.
Решение производственных задач при помощи традиционных алгоритмов распознавания
В программном обеспечении распознавания символов могут использоваться различные алгоритмы: традиционные алгоритмы и алгоритмы глубокого обучения (Deep Learning), либо их комбинации.
До недавнего времени традиционные (детерминированные) алгоритмы были единственно возможным инструментом. В результате их работы выдается уникальный и предопределённый результат для заданных входящих данных. Традиционные алгоритмы используются в видеодатчиках, смарт-камерах и системах машинного зрения, поставляются «из коробки». Их основные преимущества: быстродействие, надежная работа в идеальных, воспроизводимых условиях, когда шрифт разборчив и представлен на контрастном фоне. Недостатки: работа преимущественно с типовыми шрифтами, ограниченные возможности распознавания поврежденных символов на сложном фоне.
В качестве примера рассмотрим все этапы работы традиционного алгоритма OCRMax™ — OCR и OCV инструмент, который используется как в системах InSight Vision, так и в программном обеспечении Cognex VisionPro. OCRMax™ выполняет не только распознавание, но и верификацию маркировки. Ключевые показатели: высокая производительность, предварительная обработка изображений, обучение новым шрифтам, возможность распознавания символов за миллисекунды, возможность достижения точности распознавания на уровне 99,99% или близкой к этому, простота программирования.
Возможности OCRMax™ достаточно широки и включают в себя:
- Обучение считыванию любого печатного шрифта
- Распознавание текста при небольшом контрасте между шрифтом и фоном
- Распознавание текста при значительных различиях в ширине и высоте символов
- Распознавание текста, когда символы соприкасаются, перекошены или искажены
- Определение похожих символов (буква «О» и число «0»)
- Обучение строки символов за один шаг
- Обучение отдельных символов – можно дополнительно обучить в ходе точечной настройки
- Обучение нескольким вариантам одного символа
- Загрузка или сохранение обученных шрифтов
Алгоритм OCRMax™ выполняется в несколько этапов: предварительная обработка и корректировка изображения, чтобы получить на выходе качественную картинку. На этом этапе алгоритм способен улучшить контрастность, скорректировать настройки под влиянием внешних факторов, фильтровать фоновые шумы на изображении. Использование предварительной обработки и коррекции изображения облегчает обучение алгоритма на новом шрифте, адаптирует систему под различные производственные линии и корректирует настройки системы при изменении условий освещения в течение дня.
Следующий крайне важный этап работы OCRMax™ – сегментация, то есть разделение надписи на отдельные символы. Этот инструмент находит каждый символ на основании: минимальной/максимальной высоты и ширины и соотношений сторон, углов/наклона, меж- и внутри символьного зазора и других характеристик шрифта. Каждая цифра обладает своими уникальными качествами, под них настраивается сегментация.
Для повышения скорости распознавания инструмент сегментации содержит фильтр шума, фильтр ширины штриха, инструмент компенсации изменения условий освещения и автоматического масштабирования символов – больше или меньше, если требуется.
Далее следует этап классификации, который заключается в отнесении каждого обнаруженного символа к определенному классу, например, к букве «А», букве «B», «С» и т.д. Классификация нужна для того, чтобы система отличала такие случаи как буква В и цифра 8, и другие похожие символы, которые могут вызвать сомнения в первоначальной обработке. Опциональный алгоритм программирования Fielding позволяет задать любую дополнительную информацию о строке символов, снижая тем самым вероятность ошибки. Например, можно установить, что символ 4 справа всегда является цифрой или буквой, или что в маркировке должен содержаться код производства. Если система его не найдет, то выдаст сигнал о браке.
Еще один этап работы алгоритма – автонастройка; он автоматизирует процессы получения изображения, установки оптимальных параметров сегментации, обучения алгоритма. Автонастройка значительно сокращает время настройки инструмента на чтение типовых шрифтов. Для сложных маркировок пользователь может вручную провести сегментацию, а также обучить символы, которые не будут распознаны автоматически.
Заключительный этап — оптическая проверка символов (OCV). Верификация нужна для анализа настройки маркировки на наличие в ней каких-либо ошибок.
Традиционные алгоритмы продолжают развиваться, несмотря на внедрение глубокого обучения, и до сих пор решают многие типовые задачи.
Таблица 1. Условия качественного распознавания традиционными алгоритмами
Фактор Условие Изображение Обеспечено выделение четких границ символов. Контраст Символы отличаются от фона как минимум на 30 уровней градации серого. Прописывается везде, в том числе и в ТЗ, совместно с заказчиками. Качество печати Символы печатаются без искажений. Шрифт Символы в строке состоят из предустановленного в ПО шрифта. Поверхность Строка нанесена на чистой плоской поверхности с незначительными или полностью отсутствующими факторами, которые могли бы повлиять на внешний вид конкретного символа. Таблица 2. Негативные условия распознавания традиционными алгоритмами
Фактор Условие Изображение Изображение не попало в фокус или плохо освещено. Шрифт Символы искажены либо выходят за рамки строки. Размер шрифта Не соответствует требованиям: минимальная площадь 20×15 пикселей или максимальная площадь 100×80 пикселей. Контраст Низкий. Символы не отличаются от фона как минимум на 30 уровней градации серого. Поверхность Качество поверхности, на которую нанесена строка, не позволяет осуществить надежное распознавание. Ржавая, бликующая. Примеры негативных факторов: недостаточный контраст – символы не видны, ложная поверхность нанесения, низкое качество изображения и шрифта.
Прочие факторы, влияющие на качество распознавания маркировки: наличие специальных маркеров, скорость линии в точке контроля, внешнее освещение, перекрытие маркировки объектами, фиксированное расстояние до маркировки, своевременная выдача сигнала о поступлении объекта в зону контроля.
Кроме того, для качественного распознавания важно правильно подобрать параметры конфигурации, которые позволяют осуществлять считывание и верификацию символов даже со сложных поверхностей. Например, большой интервал между символами усложняет работу алгоритма. Решение: увеличение параметра горизонтального интервала между символами.
Решение производственных задач алгоритмами глубокого обучения
По сравнению с традиционными алгоритмами, глубокое обучение дает более широкие возможности распознавания не только типовых маркировок, но и сложных, поврежденных шрифтов, символов на сложном текстурном фоне и т.д. Программное обеспечение Cognex VisionPro Deep Learning (ViDi) — лучшее в своем классе программное обеспечение для анализа изображений на базе технологий глубокого обучения, разработанное специально для автоматизации производства.
В конце апреля 2020 года Cognex выпустил на рынок также линейку смарт-камер с программным обеспечением глубокого обеспечения на борту. Это оборудование заточено именно под распознавание промышленных маркировок и предобучено на огромной базе шрифтов. Возможна работа «из коробки», так как дообучение может и не потребоваться. Кроме того, использование камеры не требует специальных знаний в области машинного зрения.
От чего зависит процент распознавания
Клиентов всегда волнует вопрос точности распознавания символов, которую может обеспечить система машинного зрения. Процент распознавания сильно зависит от условий в точке контроля. Предугадать его невозможно, так как он определяется только во время тестирования и работы (кроме отдельных типовых случаев).
Ошибки распознавания могут происходить как на этапе сегментации: пропуск символа, ложное срабатывание; так и при классификации: неправильное определение символа. В ходе тестирования, совместно с разработчиками, можно настроить систему под оптимальные параметры.
Достичь 70-80% распознавания – не проблема, это можно сделать на стандартных библиотеках, при отсутствии сложных условий. По опыту нашей работы, чтобы достичь распознавания 90-95% нужно поработать над алгоритмами: зачастую достаточно точечных настроек. А вот чтобы достичь уровня 99% и выше, требуется серьезная доработка алгоритмов.
Используются дополнительные факторы, повышающие качество распознавания маркировки: например, мы можем использовать несколько алгоритмов, один за одним, распознавание по серии кадров. Способы имеются, но для достижения результата нужно серьезно поработать над доработкой программы. Многое зависит от условий: если мы имеем дело с качественной печатью на хорошей поверхности, то серьезные доработки могут и не потребоваться.
Процент распознавания во многом зависит от задачи, однако 100% распознавание возможно лишь в жестко фиксированных идеальных условиях.
Примеры выполненных проектов
За свой почти десятилетний опыт работы компания «Малленом Системс» выполнила множество наукоемких IT-проектов в машиностроении, нефтегазовой, металлургической, пищевой, фармацевтической, алмазодобывающей, атомной и других отраслях промышленности. В том числе было реализовано множество проектов по считыванию маркировки, зачастую трудночитаемой или нанесенной на сложное поверхности. Рассмотрим два из них:
Проект 1: Чтение маркировки с капсюль-детонаторов
Негативные факторы, усложняющие считывание: металлическая бликующая и искривленная поверхность, а также малые размеры капсюль-детонатора и маркировки (диаметр детонатора — 8 мм, размер маркировки — 4 мм). Кроме того, необходимо было обеспечить 100%-ную точность распознавания.
Для решения задачи была разработана система на основе камер машинного зрения (взрывозащищенное исполнение), специализированного освещения и ПО на основе Cognex VisionPro. В результате удалось добиться параллельного и максимально точного распознавания маркировки на 6-ти объектах при использовании одного ПК. Заказчик остался доволен результатом и расширил систему на 4 производственные точки. По запросу заказчика были реализованы доработки интерфейса ПО для удобства работы оператора и визуализации процесса распознавания на русском языке.
Рис. 1. Маркировка капсюль-детонатора
Проект 2: Идентификация труб по маркировке
Негативные факторы, усложняющие считывание: низкое качество маркировки, большая зона контроля, бликующая поверхность и большой сортамент труб. Распознавание осуществляется в сложных условиях производственного цеха с труб большого диаметра в движении (при вращательном качении по наклонным направляющим).
Решение было построено на комбинации результатов распознавания, полученных в ПО Cognex VisionPro, и ПО собственной разработки «Малленом Системс», основанном на алгоритмах определения номера трубы по результатам распознавания на серии кадров. Объединение анализа изображений с 3-х камер дало возможность распознавания маркировки по всей длине трубы.
На текущий момент система обеспечивает считывание с точностью более 99%. На одном ПК может выполняться одновременная обработка видеоизображений, поступающих с нескольких камер (максимум 8).
«Малленом Системс» продолжает работать над увеличением точек распознавания в разных цехах предприятия, так как заказчик хочет получить на выходе полное прослеживание маркировки на всех этапах производства.

Рис. 2. Символьная маркировка труб
Если у вас возникли вопросы по теме статьи, мы всегда готовы поделиться опытом разработки и внедрения систем машинного зрения для решения самых сложных производственных задач.
Свои запросы направляйте:
ООО « Малленом Системс»
162610, Череповец ул. Металлургов, 21Б
8 800 700-35-17Старший менеджер ООО «Малленом Системс»
«Малленом Системс» — искусственный интеллект, системы машинного зрения и машинного обучения.
Источник: www.mallenom.ru
Алгоритмы распознавания символов
Койнова, Т. А. Алгоритмы распознавания символов / Т. А. Койнова. — Текст : непосредственный // Молодой ученый. — 2022. — № 18 (413). — С. 73-76. — URL: https://moluch.ru/archive/413/91060/ (дата обращения: 29.05.2023).
Статья посвящена рассмотрению существующих на сегодняшний день вариантов решения проблемы распознавания символов печатного текста. В процессе исследования отдельное внимание уделено системе оптического распознавания символов, а именно специализированным алгоритмам. В частности, рассмотрен алгоритм на основе грамматик, алгоритм линейного распределения, алгоритм контурного анализа, алгоритм на основе нейронных сетей. Также выделены возможности этих алгоритмов, особенности их работы, достоинства и недостатки.
Ключевые слова : алгоритм, текст, символ, распознавание, грамматика, контур, анализ, обработка, нейронная сеть.
The article is devoted to the consideration of the currently existing options for solving the problem of recognizing characters in printed text. In the process of research, special attention is paid to the system of optical character recognition, namely, specialized algorithms. In particular, an algorithm based on grammars, a linear distribution algorithm, and a contour analysis algorithm are considered. The possibilities of these algorithms, the features of their work, advantages and disadvantages are also highlighted.
Keywords: algorithm, text, symbol, recognition, grammar, contour, analysis, processing, neural network.
Сегодня существует большой спрос на хранение в цифровом виде текстовой информации, размещенной в печатных, графических или рукописных документах, с целью дальнейшей ее обработки, редактирования и анализа. Кроме того, обширное распространение инструментов сканирования и оцифровки способствовало стремительному развитию методов и способов детектирования текста, которые в целом получили название системы оптического распознавания символов (OCR). Эти системы дают возможность в автоматическом режиме проводить анализ различных документов, подготавливать текстовые данные в редактируемых форматах для их дальнейшей обработки [3].
Необходимо отметить, что в последние годы системы распознавания печатного текста стали достаточно эффективными. В тоже время, текущие технологии все еще имеют ряд ограничений, чтобы распознавать текстовые изображения разных стилей и языков ввода. Также актуальной остается проблема обеспечения качества обработки в зависимости от таких факторов как: цвет, шрифт, расстояние между символами.
Обозначенные обстоятельства обуславливают необходимость проведения дальнейших исследования в данной предметной области, что и предопределило выбор темы этой статьи.
Описанию технологии оптического распознавания символов уделяется большое внимание в работах отечественных и зарубежных авторов. Так, в трудах Коноваленко И. А., Полевого Д. В., Николаева Д. П., Qamar, Faizan; Al-Sheikh, Idris исследуются этапы и методы распознавания текста.
Однако, несмотря на активные разработки и внимание к исследуемым вопросам, появление новых цифровых технологий и возможностей предопределяет необходимость актуализации имеющихся наработок и их регулярного пересмотра.
Таким образом, с учетом вышеизложенного, цель статьи заключается в проведении анализа современных алгоритмов распознавания символов печатного текста.
На сегодняшний день создан уже достаточно широкий спектр разнообразных алгоритмов (шаблонные, структурные, признаковые, статистические), которые незначительно отличаются по функционалу, но могут существенно различаться по качеству обработки текста. Некоторые допускают довольно много ошибок в распознавании, тогда как другие идентифицируют символы практически идеально.
Рассмотрим некоторые алгоритмы более подробно.
Алгоритм на основе грамматик . Грамматики представляют собой набор определенных правил распознавания символов.
Можно выделить следующие методы создания грамматик:
– использование теории графов. Текст представлен в виде размеченного графа. Задачи распознавания символов ставятся как задачи нахождения изоморфизма эталонного и входного графов, или изоморфизма их подграфов;
– методы теории формальных языков и грамматик. Символ рассматривается в некотором формальном языке, который задается с помощью конструкций, являющихся обобщениями грамматик Хомского. Распознавание заключается в отыскании лучшего в определенном смысле вывода изображения в заданной грамматике [1].
Особую популярность сегодня получили двумерные контекстно-свободные грамматики. В тоже время заложенная в них постановка задачи на точное совпадение, очевидно, имеет ряд недостатков, существенно ограничивающих их практическое применение для распознавания символов:
– с точки зрения распознавания символов формализм двумерных контекстно-свободных грамматик не всегда позволяет найти реальное изображение, которое можно разделить на прямоугольные фрагменты;
– чрезмерная детализация правил грамматики: для каждого символа следует указывать, каким образом он состоит из меньших частей вплоть до уровня отдельных пикселей.
Алгоритм линейного распределения . Процедура линейного разделения текста разбивает строки на слова, а слова — на отдельные буквы. После этого, по принципу IPA (integrity, purposefulness, adaptability) формируется набор гипотез (т. е. возможных вариантов идентификации каждого символа) и, обеспечив оценку вероятности, результат передается на вход системы распознавания [2].
В соответствии с первым принципом целостности (integrity) объект (символ) рассматривается как единое целое, которое состоит из нескольких взаимосвязанных частей. Принцип целеполагания (purposefulness): любая интерпретация данных должна иметь некую цель. Т. е. распознавание представляет собой процесс формулировки гипотез об объекте и их подтверждение или опровержение. Третий принцип — адаптивность (adaptability) — предполагает способность системы самостоятельно обучаться и использовать в дальнейшем ранее собранную информацию. Полученные в ходе распознавания данные упорядочиваются, хранятся и используются впоследствии для решения аналогичных задач.
Алгоритм контурного анализа . Основным преимуществом алгоритмов данной группы является их простота и скорость работы, а также минимальное влияние внешних факторов на результаты работы программных систем с элементами контурного анализа. Суть алгоритма контурного анализа при распознавании символов сводится к точному представлению границ для чего используется четыре модели кривых и методы подгонки моделей к краевым точкам. Модели включают: отрезки линий; круговые дуги; конические сечения; кубические сплайны. Алгоритм в процессе распознавания решает два вопроса: какой метод применяется для подгонки кривой к краям и как измеряется точность передачи контура.
Алгоритм на основе нейронной сети . Алгоритм распознавания текста с использованием нейронной сети заключается в следующем: на вход нейронной сети подается растровое изображение текста. В начале по входному тексту рассчитываются определенные признаки. Результатом расчетов является некоторый вектор значений признаков. Каждый выход нейронной сети соответствует определенной букве алфавита, а получаемое в итоге значение представляет собой уровень принадлежности буквы конкретному нечеткому множеству.
Задачей алгоритма является обобщение информации, поступающей в виде нечетких входных множеств и вычисление на их основе исходного нечеткого подмножества множественного числа распознавания символов. На последнем этапе принимается решение о выборе наиболее правдоподобного варианта прочтения слова.
Проанализируем на конкретном примере особенности работы нейронной сети для распознавания печатного текста.
Рассмотрим сверточную нейронную сеть, которая обучается по методу обратного распространения ошибки (back propagation) см. рис. 1.
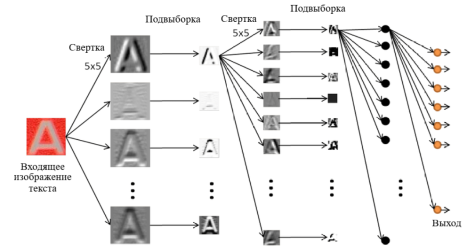
Рис. 1. Архитектура сверточной нейронной сети для распознавания текста
Такая архитектура предполагает прохождение трех взаимосвязанных этапов распознавания текста.
- Обработка изображения и распознавание текста в целом. Этот этап необходим для обнаружения границ текста. Данная процедура происходит с помощью фильтров изображения для обнаружения того, где находится текст, а где изображены обычные «шумовые» предметы (ручка, карандаш, точки на изображении и др.).
Каждый фрагмент изображения текста поэлементно умножается на матрицу весов (ядро), после чего результат суммируется. Эта сумма является пикселем исходного изображения, называемого картой признаков. После этого взвешенная сумма входов пропускается через функцию активации:
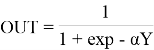
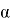
— параметр наклона сигмоидальной функции активации. Изменяя этот параметр, можно построить функции с разной крутизной.
- Обработка каждого отдельного слова посредством определения отступлений между словами. Главной проблемой этого этапа может быть перепутывание буквы в слове с отдельным словом. Для решения этой проблемы нейронная сеть должна научиться приспосабливаться к отдельным шрифтам и языкам.
- Выявление отдельных букв в слове и определения, на какие из алфавита они больше всего похожи (см. рис. 2).

Рис. 2. Пример распознанных текстов
Зеленые дуги обозначают символы, расположенные между последовательными «точными» сегментациями, а красные дуги представляют различные возможные конфигурации, связанные с «рискованными сегментациями», синие — кадрированные символы.
Таким образом, в процессе исследования рассмотрены различные алгоритмы распознавания символов в печатном тексте. Для распознавания текстовых документов с высоким качеством (низкий процент шумов, четкий шрифт и т. д.) целесообразно использовать алгоритмы на основе грамматик, линейного распределения. Структурные алгоритмы (алгоритмы контурного анализа, алгоритмы на основе нейронной сети) будут эффективны при распознавании сложных символов.
- Text analytics: an introduction to the science and applications of unstructured information analysis / John Atkinson-Abutridy. Boca Raton: Chapman https://moluch.ru/archive/413/91060/» target=»_blank»]moluch.ru[/mask_link]