
Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — это механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе. Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тесту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
Распознавание текста с картинки на Python | Оптическое распознавание символов Tesseract
В 1929 году Густав Таушек получил патент на метод оптического распознавания текста в Германии, после чего за ним последовал Гендель, получив патент на свой метод в США в 1933. В 1935 году Таушек также получил патент США на свой метод. Машина Таушека представляла собой механическое устройство, которое использовало шаблоны и фотодетектор.
В 1950 году Дэвид Х. Шепард, криптоаналитик из агентства безопасности вооружённых сил Соединённых Штатов, проанализировав задачу преобразования печатных сообщений в машинный язык для обработки компьютером, построил машину, решающую данную задачу. После того как он получил патент США, он сообщил об этом в «Вашингтон Дэйли Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26 декабря 1953). Затем Шепард основал компанию, разрабатывающую интеллектуальные машины, которая вскоре выпустила первые в мире коммерческие системы оптического распознавания символов.
Первая коммерческая система была установлена на «Ридерс Дайджест» в 1955 году. Вторая система была продана компании «Стэндарт Ойл» для чтения кредитных карт для работы с чеками. Другие системы, поставляемые компанией Шепарда, были проданы в конце 1950-х годов, в том числе сканер страниц для национальных воздушных сил США, предназначенный для чтения и передачи по телетайпу машинописных сообщений. IBM позже получила лицензию на использование патентов Шепарда.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений. Для печати на документах барабанным принтером «Ар-Си-Эй» был использован специальный шрифт OCR-A. Машина для чтения документов работала непосредственно с компьютером RCA 301 (один из первых массивных компьютеров). Скорость работы машины была 1500 документов в минуту: она проверяла каждый документ, исключая те, которые она не смогла обработать правильно.
Что такое Scan2x
Почтовая служба Соединённых Штатов с 1965 года для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым. В Европе первой организацией, использующей машины с оптическим распознаванием текста, был британский почтамт.
Почта Канады использует системы оптического распознавания символов с 1971 года. На первом этапе в центре сортировки системы оптического распознавания символов считывают имя и адрес получателя и печатают на конверте штрих-код. Он наносится специальными чернилами, которые отчётливо видимы в ультрафиолетовом свете. Это делается, чтобы избежать путаницы с полем адреса, заполненным человеком, которое может быть в любом месте на конверте.
В 1974 году Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом. Курцвейл считал, что лучшее применение этой технологии — создание машины чтения для слепых, которая позволила бы слепым людям иметь компьютер, умеющий читать текст вслух. Данное устройство требовало изобретения сразу двух технологий — ПЗС планшетного сканера и синтезатора, преобразующего текст в речь. Конечный продукт был представлен 13 января 1976 во время пресс-конференции, возглавляемой Курцвейлом и руководителями национальной федерации слепых.
В 1978 году компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов. Два года спустя Курцвейл продал свою компанию корпорации «Ксерокс», которая были заинтересована в дальнейшей коммерциализации систем распознавания текста. «Курцвейл Компьютер Продактс» стала дочерней компанией «Ксерокс», известной как «Скансофт».
1. Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Но работать с текстом невозможно по определённым причинам:
— страница с текстом представляет собой графический файл — обычную картинку;
— текст нельзя редактировать и форматировать;
— необходимо преобразовать элементы графического изображения в последовательности текстовых символов.
2. Основной метод
Основным методом перевода бумажных документов в электронную форму является сканирование:
— в результате сканирования получается графическое изображение, состоящее из точек;
— количество точек определяется размером изображения и разрешением сканера.
3. Преобразование документа
В электронный вид происходит в три основных этапа:
2. Сегментация и распознавание текста
3. Проверка орфографии и передача текстового документа в нужное приложение для дальнейшей работы или сохранение в файл.
Каждый из этих этапов может выполняться программами как автоматически, так и под контролем пользователя.
4. Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR).
Наиболее распространенные системы оптического распознавания символов:
a) BBYY FineReader
b) CuneiForm от Cognitive
а). ABBYY FineReader
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати.
OCR-технологии от компании ABBYY также поддерживают зональное распознавание (распознавание на уровне полей), необходимое во многих ключевых бизнес-процессах, таких как классификация по ключевым словам, индексирование по ключевым словам и ввод данных с форм. L, PDF/A, searchable PDF, CSV и текстовые (plain text) файлы.
Интерфейс
Пользователь может настроить рабочее пространство по своему усмотрению:
— Изменить расположение и размер окон
— Настроить панель быстрого доступа, предназначенную для доступа к наиболее часто используемым командам
— Настроить горячие клавиши — можно как заменить предустановленные сочетания, так и добавить свои горячие клавиши для выполнения команд программы
— Выбрать нужный язык интерфейса и др.
Возможности:
— позволяет извлекать текстовые данные из цифровых изображений;
— полученное в результате распознавания может быть сохранено в различных форматах.
Дополнительные возможности:
-Распознавание с обучением;
-Создание новых языков и группы языков;
-Коллективная работа в сети.
b). CuneiForm
оптический символ текст интерфейс
CuneiForm — это программа для оптического распознавания текста документов в редактируемый вид. Результаты работы программы можно редактировать в офисных программах и текстовых редакторах и сохранять в популярных форматах, проводить по ним полнотекстовый поиск.
CuneiForm является предшественницей систем промышленного распознавания и понимания документов. Многие технологические ноу-хау, результаты научных исследований, положенные в основу CuneiForm, успешно применяются и совершенствуются по сей день в коммерческих продуктах Cognitive Technologies.
Возможности:
— при распознавании с помощью CuneiForm сохраняется структура документа и его форматирование;
— программа распознает таблицы любой структуры и сложности, в том числе и без отображения линий табличной сетки;
— распознаются любые печатные шрифты: книги, газеты, журналы, распечатки с лазерных и матричных принтеров, тексты с пишущих машинок;
— алгоритмы оптического распознавания (OCR, Optical Character Recognition), встроенные в программу позволяют распознавать текст с матричного принтера, плохих ксерокопий и факсов;
— распознавание документов более чем на 20 языках: на русском, английском, немецком, французском, испанском, итальянском, шведском, украинском и других;
— для повышения качества распознавания в программе используется словарная проверка. При этом стандартный словарь можно расширить за счет импорта новых слов из текстовых файлов.
Достоинства CuneiForm:
— практически единственная бесплатная OCR-программа профессионального уровня.
— большое количество языков распознавания.
— простой и понятный интерфейс.
— на русском языке.
5. Эксперты о CuneiForm и FineReader
CHIP Special 2/2002 «Наиболее сильным соперником FineReader является программа CuneiForm, которая долгие годы успешно с ним конкурировала. Следует отметить, что CuneiForm первой получила признание на Западе, будучи встроена в популярный CorelDraw, а также установлена во многих госструктурах США, например, в аппарате президента, ФБР, ЦРУ, Министерстве обороны и т.д.
Но постепенно, начиная с четвертой версии, лидерство FineReader становилось все более очевидным…»
6. Автоматический перевод текста
Программные средства автоматического перевода можно условно разделить на две основные категории:
1. Компьютерные словари. Назначение их — предоставить значения неизвестных слов быстро и удобно для пользователя.
2. Системы автоматического перевода — позволяют выполнять автоматический перевод связного текста. В ходе работы программа использует словари и наборы грамматических правил, обеспечивающих наилучшее качество перевода.
- Стратегические преимущества внедрения СЭД
- Технологии распознавания текста (Необходимость в системах распознавания символов.)
- Российское законодательство по информационной безопасности и безопасности сетей (Ограничение доступа к информации, конфиденциальность и защита информации)
- Технологии распознавания текста
- Способы активизации творческого мышления
- История развития мультимедиа (Гипертекстовые и мультимедийные информационные технологии)
- Этапы изготовления печатной формы для офсетной печати
- Аспекты рассмотрения знаков: синтактика, семантика, прагматика
- Регистрация и индексация документов (Факультет Управления)
- История развития торгового права России ( Коммерческое (торговое) право.)
- История развития торгового права России
- Технологии распознавания текста (по дисциплине Документооборот в управлении)
При копировании любых материалов с сайта evkova.org обязательна активная ссылка на сайт www.evkova.org
Сайт создан коллективом преподавателей на некоммерческой основе для дополнительного образования молодежи
Сайт пишется, поддерживается и управляется коллективом преподавателей
Telegram и логотип telegram являются товарными знаками корпорации Telegram FZ-LLC.
Cайт носит информационный характер и ни при каких условиях не является публичной офертой, которая определяется положениями статьи 437 Гражданского кодекса РФ. Анна Евкова не оказывает никаких услуг.
Источник: www.evkova.org
OCR-конвейер для обработки документов
Сегодня я расскажу о том, как создавалась система для переноса текста из бумажных документов в электронную форму. Мы рассмотрим два основных этапа: выделение областей с текстом на сканах документов и распознавание символов в них. Кроме того, я поделюсь сложностями, с которыми пришлось столкнуться, способами их решения, а также вариантами развития системы.

Первичным переводом документа в электронную форму является его сканирование или фотографирование, в результате которого получается графический файл в виде фотографии или скана. Однако такие файлы, особенно высокого разрешения, занимают много места на диске, и текст в них невозможно редактировать. В связи с этим, целесообразно извлекать текст из графических файлов, что успешно делается с применением OCR.
Про OCR и цели
Оптическое распознавание символов (OCR) — перевод изображений машинописного, рукописного или печатного текста в электронные текстовые данные. Обработка данных при помощи OCR может применяться для самых различных задач:
- извлечение данных и размещение в электронной базе банковских, бухгалтерских, юридических документов;
- сканирование печатных документов с последующей возможностью редактирования;
- перенос исторических документов и книг в архивы;
- распределение печатного материала по темам;
- индексирование и поиск отсканированного печатного материала.
В настоящее время все больше организаций переходят от бумажной формы документооборота к электронной. На одном из моих недавних проектов для компании с большими объемами бумажных документов, требовалось перенести информацию, накопившуюся в сканах (около нескольких петабайт), в электронную форму и добавить возможность обработки новых отсканированных документов.
Презентация на тему Системы оптического распознавания документов
Системы оптического распознавания символов При coздании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный
- Главная
- Шаблоны, картинки для презентаций
- Системы оптического распознавания документов
Слайды и текст этой презентации
Слайд 1Системы оптического распознавания документов

Слайд 2Системы оптического распознавания символов
При coздании электронных библиотек
и архивов путем перевода книг и документов
в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.

Слайд 3Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character
recognition, OCR) — механический или электронный перевод
изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
С помощью сканера несложно получить изображение страницы текста в графическом файле.

Слайд 4Однако для получения документа в формате текстового
файла необходимо провести распознавание текста, т. е.
преобразовать элементы графического изображения в последовательности текстовых символов.

Слайд 5Сначала необходимо распознать структуру размещения текста на
странице: выделить колонки, таблицы, изображения и т.
д.
Далее выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст.

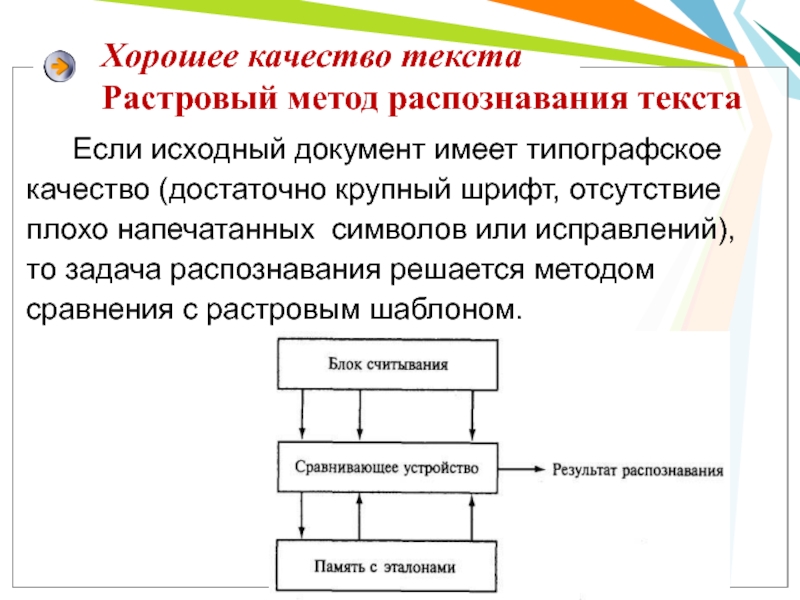
Слайд 6Хорошее качество текста Растровый метод распознавания текста
Если исходный
документ имеет типографское качество (достаточно крупный шрифт,
отсутствие плохо напечатанных символов или исправлений), то задача распознавания решается методом сравнения с растровым шаблоном.
Слайд 7Хорошее качество текста Растровый метод распознавания текста
Сначала растровое
изображение страницы разделяется на изображения отдельных символов.
Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством точек, отличных от входного изображения.

Слайд 8Хорошее качество текста Растровый метод распознавания текста
Растровое изображение
каждого символа последовательно накладывается на растровые шаблоны
символов, хранящиеся в памяти системы оптического распознавания. Результатом распознавания является символ, шаблон которого в наибольшей степени совпадает с изображением
Например, распознаваемый символ «Б» накладывается на растровые шаблоны символов (А, Б, В и т. д.)

Слайд 9Плохое качество текста Структурный метод распознавания
При распознавании документов
с низким качеством печати (машинописный текст, факс
и т.д.) используется метод распознавания структурных элементов (отрезков, колец, дуг и др.) символов. В искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов.
Любой символ можно описать через набор параметров, определяющих взаимное расположение eгo элементов. Например, буква «Н» и буква «И» состоят из трех отрезков, два из которых расположены параллельно друг другу, а третий соединяет эти отрезки. Различие между буквами в величине улов, которые составляет третий отрезок с двумя другими.

Слайд 10Плохое качество текста Структурный метод распознавания
При pacпознавании структурным
методом в искаженном символьном изображении выделяются характерные
детали и сравниваются со структурными шаблонами символов.
В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего coответствуют распознаваемому символу.
Например, распознаваемый символ «Б» накладывается на векторные шаблоны символов (А, Б, В и т. д.)

Слайд 11Системы оптического распознавания форм
При проведении Единого
государственного экзамена, при заполнении налоговых деклараций и
т. д. используются различного вида бланки с полями. Рукописные тексты (данные вводятся в поля печатными буквами от руки) распознаются с помощью систем оптического распознавания форм и вносятся в компьютерные базы данных.
Сложность состоит в том, что необходимо распознавать символы, написанные от руки, а они довольно сильно различаются у разных людей. Кроме того, система должна определить, к какому полю относится распознаваемый текст.

Слайд 12Бланком называется стандартный лист бумаги, на котором
размещается постоянная информация и отведено место для
переменной.
Сложность состоит в том, что необходимо распознать написанные от руки символы, довольно сильно различающиеся у разных людей.
Кроме того система должна определить, к какому полю относится распознаваемый текст.
Системы оптического распознавания форм

Слайд 13Для обработки бланков предназначено специальное приложение FineReader
Forms.
Для распознавания содержимого бланка необходимо предварительно создать
шаблон формы.
Сервис/ Шаблоны
Шаблон используют на этапе сегментации. Сегментация в данном случае состоит в наложении шаблона.
Положение шаблона корректируется в соответствии с тем, насколько ровно был размещён бланк при сканировании.
Заключительный этап состоит в распознавании содержимого бланка.
Системы оптического распознавания форм

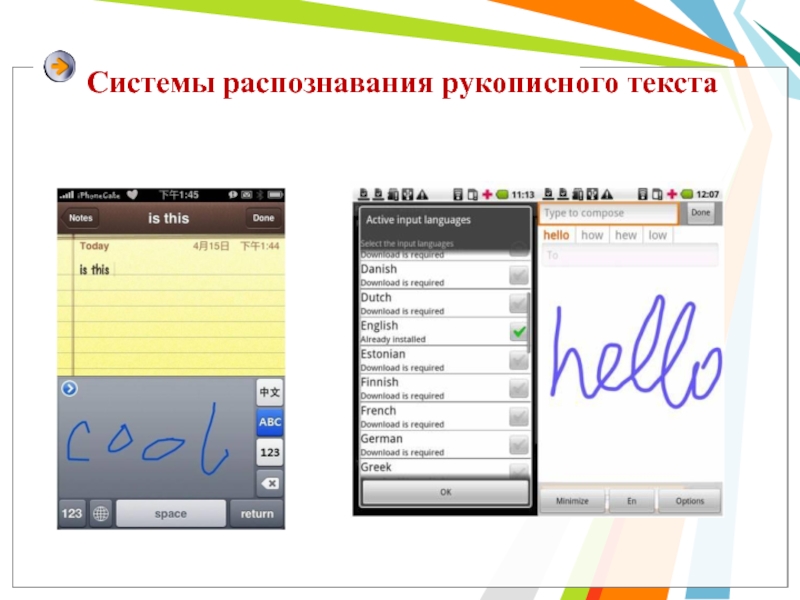
Слайд 14Системы распознавания рукописного текста
С появлением первого
карманного компьютера Newton фирмы Apple в 1990
году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.

Слайд 15Системы распознавания рукописного текста
Слайд 16
Программы оптического распознавания текста

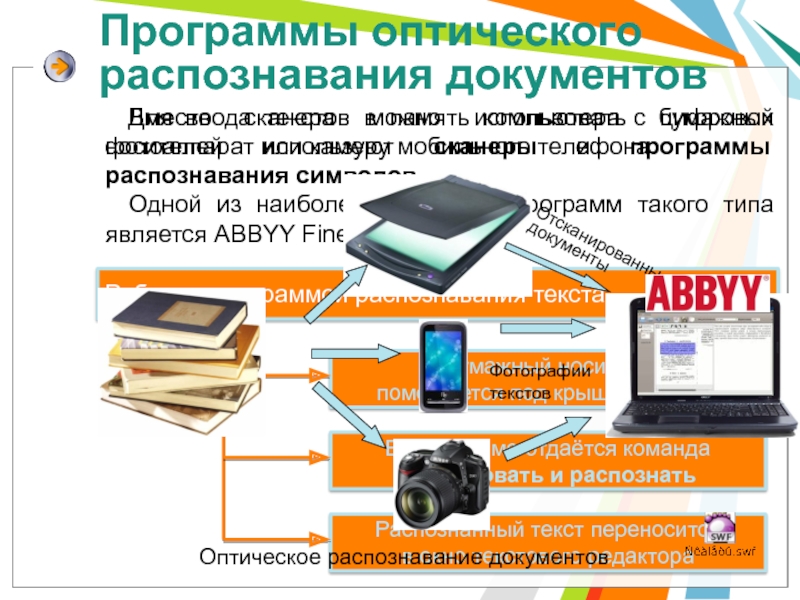
Слайд 17Программы оптического распознавания документов
Для ввода текстов в
память компьютера с бумажных носителей используют сканеры
и программы распознавания символов.
Одной из наиболее известных программ такого типа является ABBYY FineReader.
Бумажный носитель
помещается под крышку сканера
В программе отдаётся команда
Сканировать и распознать
Распознанный текст переносится
в окно текстового редактора
Работа с программой распознавания текста
Вместо сканера можно использовать цифровой фотоаппарат или камеру мобильного телефона.
Оптическое распознавание документов
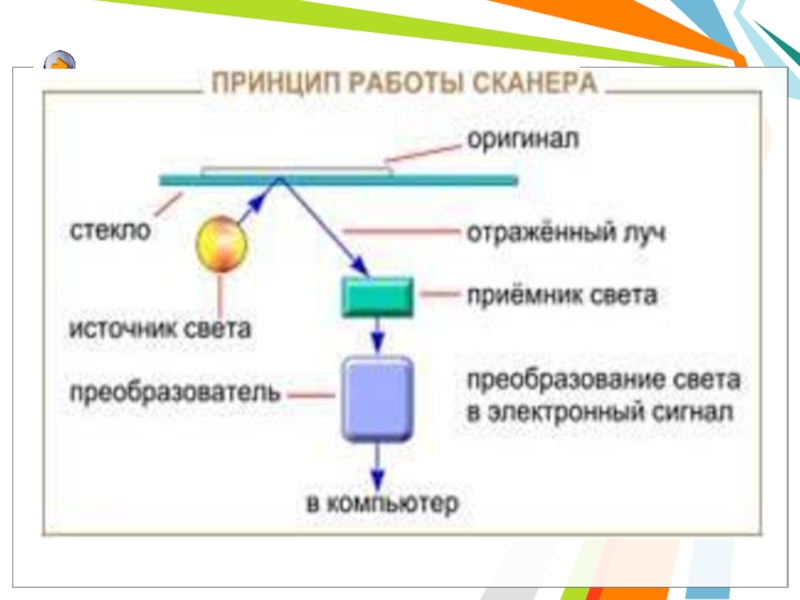
Слайд 18 Принцип работы сканера
состоит в следующем: в результате преобразования света
получается электрический сигнал, содержащий информацию об активности цвета в исходной точке сканируемого изображения. После оцифровки аналогового сигнала в АЦП цифровой сигнал через аппаратный интерфейс сканера идет в компьютер, где его получает и анализирует программа для работы со сканером. После окончания одного такого цикла (освещение оригинала — получение сигнала — преобразование сигнала — получение его программой) источник света и приемник светового отражения перемещается относительно оригинала.
Принцип работы сканера

Слайд 19
Слайд 20Программы распознавания текста
Преобразованием графического изображения в текст
занимаются специальные программы распознавания текста (Optical Character
Recognition — OCR).
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами, но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы.
И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word.

Слайд 21OCR CUNEIFORM
Это бесплатная программа сканирования и
распознавания текста российского разработчика Cognitive Technologies.
OCR CuneiForm
обеспечивает быстрое, удобное и качественное распознавание текста с сохранением исходного вида документа. Поддерживается распознавание с более 20 языков, среди них русский, украинский, английский, немецкий, французский, испанский, итальянский, португальский, шведский, финский, сербский, хорватский, польский, а также распознавание смешанного русско-английского текста.

Слайд 22ABBYY FineReader
Популярная проприетарная программа распознавания текста компании
ABBYY
Программа производит распознавание текста с более 180
языков, для 38 из них предусмотрена встроенная проверка орфографии. Начиная с версии Professional, распознаются иврит, японский, тайский, китайский языки. Finereader открывает файлы графических форматов (TIFF, JPG, PFD, PNG и др.) в том числе DjVu – компактный формат для хранения отсканированных документов, книг.

Слайд 23Окно программы FineReader
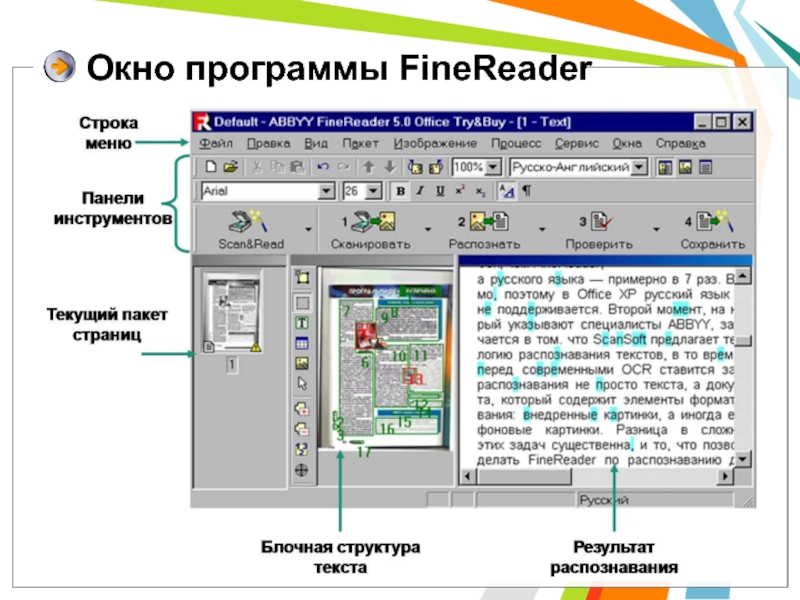
Слайд 24Процесс обработки FineReader
Сканирование (сканер, цифровой фотоаппарат, цифровая
видеокамера).
Сегментация — выделение блоков на изображении.
Распознавание –
неоднозначно опознанные символы выделяются цветом.
Проверка ошибок- можно провести проверку грамматики.
Сохранение результатов в виде отформатированного или неотформатированного документа, или прямой передачи в другое приложение — WORD, Excel в буфер обмена Windows.

Слайд 25OmniPage
Популярная программа распознавания текста российской компании ABBYY
Программа
отличается высокой скоростью и точностью распознавания. Распознаются
более 120 языков с различными алфавитами: латинский, греческий алфавиты, кириллица, китайский, японский и корейский языки. Как и FineReader, OmniPage уверенно распознает документы, полученные с помощью цифровых камер с помощью технологии коррекции изображения «3D Correction».

Слайд 26OmniPage
В программе присутствуют удобные инструменты обработки изображений,
повышенное качество сканирования без повторного сканирования; функция
преобразования бумажных форм в электронные документы, заполняемые на экране; механизм Google Desktop Search для поиска отсканированного файла (и других файлов) по содержащимся в нем словам. В комплекте с OmniPage Professional поставляется несколько полезных утилит. В частности, PDF Converter — позволяет преобразовывать файлы формата PDF в редактируемые форматы: doc, rtf, wpd, xls. Упрощенный вариант утилиты PDF Create!, которая выполняет обратное преобразование: превращает практически любой текстовый или графический файл в формат PDF.
Слайд 27Readiris
Программа сканирования и распознавания текста компании
I.R.I.S.
Поддерживается распознавание текста с более 120 языков
распознавания, включая русский, а также ближневосточные языки — арабский, иврит, фарси (в версии Middle-East) и японский, китайский, корейский (в версии Asian). Есть версия Readiris для Macintosh.
Вместе с поддержкой распознавания популярных форматов картинок, распознаются файлы PDF и DjVu.

Слайд 28Readiris
Содержит региональные пакеты для
распознавания азиатских языков и языков среднего востока.

Слайд 29Kirtas Technologies Arabic OCR
Может
распознавать арабские и английские символы на одной

Слайд 30Zonal OCR
Помогает автоматизировать извлечение
данных из компьютерных изображений.

Слайд 31Brainware
Извлечение данных из документов
и их обработка — например, счета, извещения,
накладные и платёжки

Слайд 32Microsoft Office Document Imaging
Программа распознавания текста компании
Microsoft
Программа Document Imaging способна работать только с
двумя языками: английским и языком локализации самого MS Office. Для поддержки других языков необходимо дополнительно устанавливать пакет Multilingual User Interface (MUI). OCR настроек в программе практически нет, программа в автоматическом режиме поддерживает распознавание типа и размера шрифтов, картинок и простых таблиц.
Источник: thepresentation.ru