
Использование программы SPSS в качестве ядра для современных маркетинговых исследований
Новая, 11-ая версия SPSS появилась в мае этого года, разумеется в английской локализации. Разработчики пакета сочли, что пользовательский интерфейс в последней версии уже является достаточно совершенным, поэтому подавляющее большинство изменений в новой версии связаны с усовершенствованием или добавлением статистических процедур, которые более полно обеспечивают потребности пользователей в современных методах обработки информации, возникающей в результате маркетинговых исследований, а также исследований в области социологии и психологии.
Основное внимание уделено расширению функциональных возможностей специальных модулей SPSS, таких как SPSS Categories, SPSS Advanced Models и другие. Собственно расширение программного наполнения специальных модулей и делает новую версию программы, которая уже успела стать стандартом в области обработки данных, еще более привлекательной для пользователей с весьма широким диапазоном деловых и научных интересов.
Что такое SPSS?
Если раньше данная программа широко использовалась в таких «классических» областях науки и бизнеса, как биология, социология, психология, управление качеством производства, общие маркетинговые исследования и экономическое прогнозирование, то сейчас новую версию можно с успехом применять в таких актуальных специализированных областях, как маркетинг, основанный на использовании баз данных, Data Mining, Data Warehousing и другие. Особенного внимания заслуживает тот факт, что изменения, внесенные в модуль SPSS Regression Models, позволяют использовать SPSS при решении задач управления лояльностью клиентов (CRM). Отметим, что данная тема представляет собой один из наиболее популярных разделов современного практического маркетинга.
Отдельного упоминания заслуживает то факт, что большинство наиболее популярных статистических методов прогнозирования, включенных в модуль SPSS Regression Models, позволяют работать с большим объемом недоступной информации. В математике в таком случае говорят о повышении робастности метода, то есть его устойчивости по отношению к неопределенностям и существенным отклонениям от диапазона параметров, для которого разрабатывался метод. Такое повышение робастности весьма желательно в маркетинговых исследованиях и в социологии, где всегда присутствует большой объем отсутствующих или недостоверных данных. Небесполезно данное улучшение и в области управления качеством, где всегда существует компромисс между подробностью информации о производственном процессе и его усложнением.
Изменения коснулись и техники вычислений. Подобные изменения не сказываются на интерфейсе и прочих видимых функциональных особенностях программы, но однако они затрагивают вычислительное ядро, которое используется в ходе проведения конкретных расчетов. Здесь основное внимание было сосредоточено на повышении эффективности статистических алгоритмов, в некоторых случаях эффективность повысилась до 50 раз.
Начало работы с SPSS: описательные статистики
Эффективность одной из наиболее часто используемых статистических процедур, общей линейной модели (GLM), возросла в 10 раз, что несомненно скажется на обшей производительности при выполнении статистических исследований, особенно в области обработки больших массивов экспериментальных данных, которые возникают, например, в решении задач управления качеством, социологии и медицины.
В два раза выросла скорость выполнения самых массовых статистических процедур, таких как расчет дисперсии и вычисление средних. Можно смело сказать, что пользователь, который нуждается только в самых простых статистических методах, заметит именно двукратное повышение эффективности работы программы.
Особенно повышение быстродействия чувствительно в случае, когда речь идет о методах кластерного анализа, широко используемого в маркетинге, социологии, психологии и медицине, которые иногда требовали многочасовых расчетов даже на мощных компьютерах, для чего в предыдущих версиях SPSS был предусмотрен пакетный режим выполнения задач.
Следует отметить, что только одно столь существенное повышение производительности уже может быть основанием для выпуска новой версии программы. Снижение затрат времени, которое обеспечивает новая версия SPSS, позволяет более интенсивно использовать эту программу в практических маркетинговых исследованиях, анализировать большее количество вариантов, обрабатывать более широкие и представительные выборки. В результате издержки, связанные с исследованиями падают, а степень достоверности информации повышается.
Изменения, которые были внесены в изобразительную и презентационную части программы в основном затрагивают гибкость отображения результатов статистической обработки данных и включают несколько более показательных видов графиков. Например, при выводе информации о приближении данных с помощью выбранного метода аппроксимации, на графике приводится информация о том насколько хорошо полученное приближение. Такая дополнительная возможность может оказаться весьма полезной для не слишком опытных пользователей или пользователей не имеющих и не нуждающихся в глубокой математической подготовке. В целом изменения, которым подверглась графическая и презентационная часть программы направлены на упрощение работы и облегчение интерпретации результатов вычислений неподготовленными пользователями.
Рассматривая изменения, внесенные в техническую часть программы, необходимо упомянуть, что новая версия SPSS способна конвертировать базовые и переносимые файлы программы SAS (www.sas.com), своего наиболее мощного конкурента в области статистической обработки данных. Очень многие массивы общедоступной информации, имеющие отношения к маркетинговым исследованиям и социальной статистике, например данные по исследованию уровня жизни США и других стран (в том числе и России — знаменитый RLMS, www.unc.edu), проводимые американскими исследователями имеют формат переносимых файлов SAS.
Кроме того, следуя тенденции к превращению SPSS в мощное средство для проведения маркетинговых исследований и анализа разнородной информации, в 11-ой версии существенно расширено удобства доступа к различным форматам баз данных. В список поддерживаемых форматов теперь входят Sybase 11 и 12; Infomix 7.3+, 9.14: Infomix 2000 (9.20); UDB (DB2 6.1 и 7.1); SQL Server 2000; Oracle 8.06; Oracle! Releases 2 and 3 (8.1.6, 8.1.7).
Улучшена связь с Microsoft Data Access pack. Более мощным стал язык запросов, появилась возможность на уровне запроса формировать и имена переменных и метки, что облегчает интерпретацию результатов и повышает их наглядность. Повысилась гибкость и функциональные возможности мобильных таблиц — это изменение затрагивает модуль SPSS Tables.
Если подытожить все вышесказанное, то можно сделать вывод, что переход конкретного пользователя на новую версию SPSS оправдан в том случае, когда этот пользователь нуждается в расширении своего арсенала методов статистической обработки данных, реализации наиболее современных тенденций в маркетинговых исследованиях, испытывает проблемы с полнотой информации, на основании которой необходимо сделать надежные и достоверные выводы, а также сталкивается с жесткими временными ограничениями, накладываемыми на процесс проведения исследований. Кроме того, работа с 11-ой версией SPSS снимает часть проблем, с которыми сталкиваются пользователи на начальных этапах освоения сложных методов статистического анализа, применяемого в широком спектре областей деятельности.
Переход к новой версии желателен, если пользователь собирается более широко применять современные методы анализа данных в ходе своей деятельность и уже имеет опыт использования аппарата математической статистики.
И, наконец, переход к новой версии не столь необходим, если в ходе деятельности пользователя возникает потребность в применении только самых простых статистических методах, а интерпретация результатов не вызывает особенных проблем. Кроме того, необходимо отметить, что предыдущая версия SPSS 10.1 имеет русскую локализацию, а выход локализованной 11-ой версии может стать весьма отдаленной перспективой.
Источник: hr-portal.ru
Что такое SPSS и как оно работает? — Edu CBA

Что такое SPSS — SPSS — это программное обеспечение, которое широко используется в качестве инструмента статистического анализа в области социальных наук, таких как исследования рынка, опросы, анализ конкурентов и другие.
Это всеобъемлющий и гибкий инструмент статистического анализа и управления данными. Это один из самых популярных статистических пакетов, который может с легкостью выполнять очень сложные манипуляции и анализ данных. Он предназначен как для интерактивных, так и для неинтерактивных пользователей.
Функциональные возможности SPSS
Некоторые из функций SPSS включают в себя следующее
- Преобразования данных
- Проверка данных
- Описательная статистика
- Генеральная линейная модель
- Тесты на надежность
- корреляция
- T-тесты
- ANOVA
- MANOVA
- Регрессия
- Факторный анализ
- Кластерный анализ
- Пробит-анализ
- Временная последовательность
- Анализ выживания
- Графический и графический интерфейс
SPSS состоит из 2 листов: один — представление данных и представление переменных
Особенности SPSS
- Вам легко учиться и использовать
- SPSS включает в себя множество систем управления данными и инструментов для редактирования
- Он предлагает вам глубокие статистические возможности
- Он предлагает отличные возможности построения графиков, отчетов и презентаций.
Преимущества SPSS
Вот несколько ключевых моментов, почему SPSS считается лучшим инструментом для использования
Эффективное управление данными
SPSS в анализе данных проще и быстрее для вас, так как программа знает местоположение случаев и переменных. Это значительно уменьшает ручную работу пользователя
Широкий выбор опций
SPSS предлагает вам широкий спектр методов, графиков и диаграмм. Это также идет с лучшей возможностью просмотра и очистки информации как подготовка к дальнейшему анализу.
Широкий выбор опций
В SPSS выходные данные хранятся отдельно от самих данных. Хранит данные в отдельном файле.
Переменный вид
Это лист, где вы определяете переменную данных, которые у вас есть, представление переменной состоит из заголовка следующего столбца,
- Имя : введите уникальное имя идентифицируемой и сортируемой переменной, например: в данных учеников переменными могут быть идентификатор, пол, возраст, класс и т. Д., Примечание: это не позволит использовать какой-либо специальный символ или пробел при описании переменных Данные, и как только вы введете первую переменную, вы сразу увидите, как SPSS генерирует всю другую информацию о том, как вы хотите установить эту переменную, которую вы ввели,
- Тип: Вы можете изменить тип переменной, числовой, алфавитный или буквенно-цифровой, выбрав соответствующий тип в этом столбце, это ограничит использование любого другого типа, используемого в этом столбце переменной
- Ширина : определяет ширину символа, которую должна разрешить эта переменная, особенно полезно при вводе номера мобильного телефона, который допускает только 10 символов.
- Десятичное число: определяет десятичную точку, которую необходимо отобразить, например: используется в процентах
- Метка: поскольку столбец имени не позволяет вам использовать какой-либо специальный символ или пробел, здесь вы можете указать любое имя в качестве метки для той переменной, которую вы хотите назначить
- Значение : это для определения / маркировки значения везде, где вы видите в данных, например: вы можете пометить «0» в данных как АБСЕНТ для экзамена, поэтому, когда вы найдете 0 в данных, оно будет помечено как АБСЕНТ для экзамена. Можно также пометить идентификационный номер сотрудника его именем, чтобы при помощи значения «Переключатель меток» можно было просматривать имя сотрудника, но в отчете имя не будет отображаться, будет отображаться только идентификационный номер EMP. чтение данных лучше в режиме просмотра данных
- Отсутствует: Вы можете упомянуть Данные, которые вы не хотите, чтобы SPSS учитывал при анализе. Например, значение «0» считается отсутствующим, поэтому при анализе оно будет игнорировать «0», если упомянуто в разделе «Отсутствует», что будет полезно при Имею ввиду, Mode Etc,
- Выровнять : Вы можете упомянуть выравнивание данных в листе данных, слева, справа от середины,
- Мера: Здесь вы будете определять меру введенной вами переменной, будь то шкала, порядковый или номинальный тип переменной
Примечание. Ярлык — вы можете скопировать тип переменной и вставить ее в следующую строку, если переменная почти такого же типа, как отметки субъектов — наука, математика, английский язык, история — все они будут иметь один и тот же тип, за исключением изменения имени и ярлык
После определения всех переменных данных, После того, как вы нажмете на Лист данных DATA, вы сможете увидеть метки, введенные вами в качестве метки столбцов,
Просмотр данных
Примечание: SPSS может читать файл данных лучше в числовом, чем в String (текст), поэтому всегда лучше преобразовать большую часть данных в числовые данные переменных, например: в случае опроса они используют больше Да / нет, Хорошее / Среднее / Плохо, Мужской / Женский, — Здесь во всех этих случаях вы можете использовать коды в файле данных, такие как 1 — Да, 2 — Нет; Также убедитесь, что данные Excel расположены таким образом, что строки всегда содержат ответы от разных людей, а столбцы содержат ответы на разные вопросы;
Импорт файла данных Excel в SPSS:
Анализ. После того, как данные импортированы или введены в таблицу представления данных, вы можете запускать отчеты и анализировать данные с помощью параметра «Анализ» на верхней панели инструментов. В этом параметре можно найти все инструменты «Аналитика». найти среднее значение, медиану, режим для вводимых данных,
- Перейти к варианту анализа
- Выберите описательную статистику
- Выберите частоты
- В диалоговом окне с левой стороны у вас будет список переменных, которые вы упомянули в данных, выберите переменные, для которых нужно найти среднее значение, медиану, режим и поместите их в поле справа, используя кнопка в центре,
- Нажмите на кнопку статистики,
- Вы найдете флажок «Среднее», «Медиана» и «Режим» в диалоговом окне центральной тенденции, отметьте их,
- Нажмите Продолжить,
- В диалоговом окне «Частоты» нажмите кнопку «Диаграмма» и выберите тип диаграммы, для которой необходимо отобразить данные.
- Затем нажмите ОК,
- Выходные данные будут открыты в отдельном окне со списком средних значений, медианой, режимом и графическим представлением диаграммы, которую вы выбрали ранее;

Статистический тест с использованием SPSS
Быстрая проверка данных
Прежде чем использовать какой-либо статистический тест, всегда желательно выполнить проверку данных, чтобы узнать, как данные были распределены и четко определены, не учитываются ли пропущенные значения и т. Д. Проверка данных обычно выполняется с помощью диаграмм, чтобы можно было легко обнаружить любые отклонения. и данные могут быть исправлены,
Гистограмма — широко используется для проверки данных в случае тестов с одной переменной. Создание гистограммы уже объяснено;
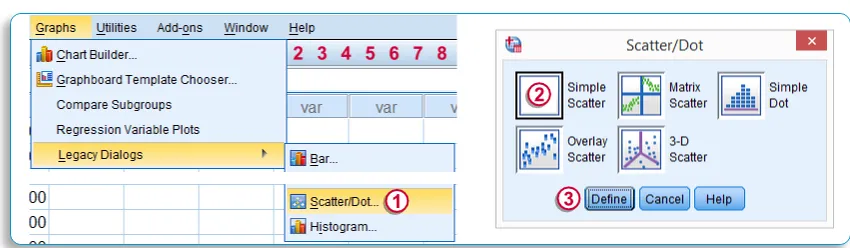
Точечная диаграмма — используется для двух переменных тестов:
- Нажмите Графики ………. Выберите Устаревшие Диалоги ……. Выберите Scatter / Dot
- Выберите простую диаграмму рассеяния
- Нажмите определить
- Вы найдете оси X и Y для сравнения
- Удалите переменную для оси X и оси Y соответственно
- Нажмите Ok
В основном тесты могут быть диверсифицированы в зависимости от цели, это может быть 2 типа — Сравнительные тесты и Ассоциативный тест, Сравнительный тест может быть далее разделен на 3 типа в зависимости от количества переменных, которые вы хотите сравнить, один тест переменных, два теста переменных и многовариантный тест;
Сравнительные тесты — одна переменная с использованием SPSS
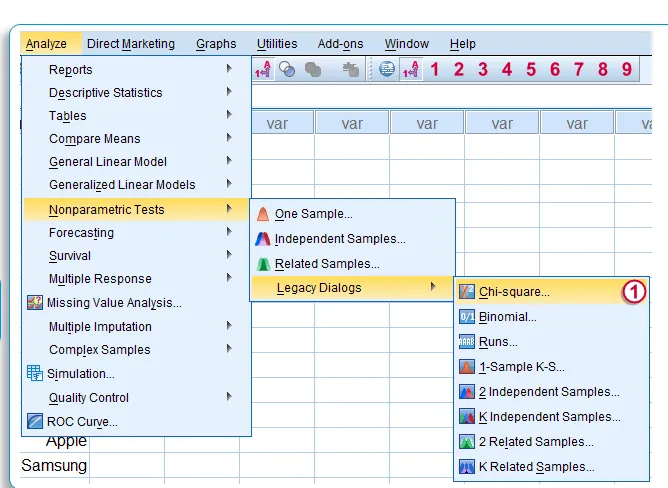
Тест А. Чи-Сквер
- Нажмите «Анализ». Выберите непараметрические тесты … Выберите устаревшие диалоги
- Выберите тест хи-квадрат
- В диалоговом окне «Хи-квадрат» опустите переменную, которую вы хотите запустить, в «Список переменных теста» с помощью кнопки «Пуск» в центре.
- В ожидаемом диапазоне отметьте «Получить из данных»
- В ожидаемых значениях отметьте «Все категории равны»
- Нажмите ОК
- Результат хи-квадрат появится в окне вывода
B. Один образец T-теста
- Нажмите «Анализ». Выберите Сравнить средства …
- Выберите один образец T — Test
- В диалоговом окне «Один образец T-теста», опустите переменную, которую вы хотите запустить, в «Список переменных теста», используя кнопку «Drop» в центре.
- В поле «Значение теста» введите значение «Население».
- Нажмите Вставить — появится синтаксис со всеми условиями
- Нажмите OK и запустите тест
- Один образец T — результат теста появится в окне вывода

Сравнительные тесты — две переменные с использованием SPSS
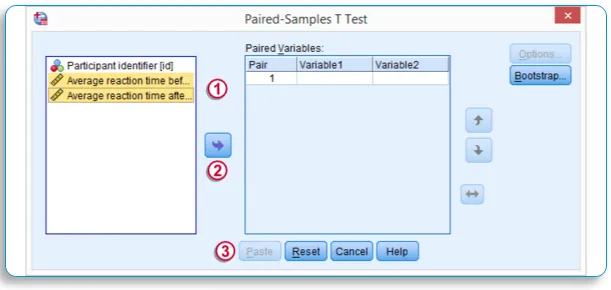
C. Парный образец T-теста:
- Нажмите «Анализ». Выберите Сравнить средства …
- Выберите один парный образец T-теста
- В диалоговом окне One Sample T Test отбросьте две переменные, которые вы хотите запустить, в «Список парных переменных», используя кнопку «Drop» в центре одну за другой.
- Нажмите Вставить — появится синтаксис со всеми условиями
- Нажмите OK и запустите тест
- Парный образец T — результат теста появится в окне вывода
Сравнительные тесты — больше переменных с использованием SPSS
D. Повторные меры ANOVA
- Нажмите «Анализ». Выберите общую линейную модель …
- Выберите повторные измерения
- В диалоговом окне «Фактор определения повторяющихся мер» мы собираемся определить несколько переменных, которые мы собираемся запустить,
- Присвойте имя набору переменных, которые вы собираетесь сравнивать (имя фактора) — как и курсы, в «Имя фактора внутри субъекта»
- Введите номер переменной под этим фактором в «Количество уровней»
- Нажмите ДОБАВИТЬ
- Дайте название меры, как рейтинг, рейтинг,
- Нажмите ДОБАВИТЬ
- Нажмите «Определить», чтобы определить переменные под именем упомянутого фактора — Курсы
- Перенесите все переменные, которые вы хотите включить, под именем фактора (курсы) в пределах — предметные переменные
- Нажмите Option и выберите описательную статистику
- Нажмите Вставить — появится синтаксис со всеми условиями
- Нажмите OK и запустите тест
- Повторные измерения ANOVA — результат теста появится в окне вывода


Ассоциированные тесты — две переменные
А. Корреляционные тесты
- Нажмите «Анализ». Выберите Коррелировать …
- Выберите Bivariate …
- В диалоговом окне Bivariate Correlation отбросьте две переменные, которые вы хотите запустить, в «Перечень переменных», используя кнопку «Drop» в центре одну за другой.
- Убедитесь, что вы отметили «корреляционные коэффициенты Пирсона»
- Тест на значимость галочки «Два хвостатых»
- Также отметьте флажки значимых корреляций
- Нажмите Вставить — появится синтаксис со всеми условиями
- Нажмите OK и запустите тест
- Двусторонняя корреляция — результат теста появится в окне вывода
B. Односторонний тест на анову
- Нажмите «Анализ». Выберите Сравнить средства …
- Выберите One Way Anova …
- В диалоговом окне «Односторонняя анова» опустите переменные в зависимом списке и список переменных в списке факторов, например: вес детей в зависимом списке и напитки здоровья в списке факторов.
- Выберите опцию и выберите описательный
- Нажмите Вставить — появится синтаксис со всеми условиями
- Нажмите OK и запустите тест
- One Way Anova — результат теста появится в окне вывода
Окно вывода SPSS
Это окно содержит все выходные данные, которые запускаются после статистических тестов. Выходные данные статистического теста будут отображаться в окне «Вывод» только в формате таблицы и диаграммы / графика;
Окно «Вывод» состоит из 2 сегментов — с левой стороны вы можете увидеть схему вывода, а справа — «Фактический вывод», «Схема вывода» покажет заголовки и субтитры «Вывод», организованные в иерархической древовидной структуре, щелкнув заголовок. или субтитры вы можете просмотреть фактический результат; Вы можете скрыть или удалить ветвь древовидной структуры,
Таблицу можно легко скопировать и вставить в лист Word или Excel. То же самое относится к графику или диаграмме, отображаемым в фактическом выводе, также можно скопировать и вставить
Окно редактора данных будет сохранено в формате (.sav) как файл данных SPSS, файл синтаксиса SPSS будет сохранено в формате (.spv) как файл синтаксиса SPSS, а окно просмотра выходных данных будет сохранено в (.spv) или ( .spo) формат в качестве выходного файла SPSS,
Как открыть сохраненный файл SPSS и снова запустить вывод
- Нажмите Файл…. Выберите Открыть…. Выберите Данные
- В диалоговом окне «Тип файлов» выберите «Файл (.sav)».
- Затем выберите файл данных SPSS, который вы сохранили в своей системе, и выберите Открыть
- Нажмите Ok
- Откроется редактор данных SPSS, и вы сможете найти в нем свой файл данных;
- Внесите необходимые изменения, если вы хотите отредактировать данные или переменные и запустить требуемый тест
Суть в том, что Excel предлагает хороший способ организации данных, а SPSS больше подходит для углубленного анализа данных.
Если вы хотите узнать больше о SPSS, попробуйте наш онлайн-тренинг по SPSS — Анализ данных для статистического анализа.
Рекомендуемые статьи
- Функции Excel диаграмм и графиков
- R против SPSS
- Знаете ли вы важность использования формата таблицы Excel
- Простая сортировка данных с помощью функции сортировки Excel — Полезное руководство
Источник: ru.education-wiki.com
Функциональные возможности системы SPSS
На сегодняшний день на указанном перекрестке установлены знаки главная дорога и пешеходный переход, находится остановка общественного транспорта. Рядом расположены торговые комплексы, жилые многоэтажные дома и строящийся жилой комплекс по улице Пархоменко. Также на данном перекрестке организовано движение маршрутных транспортных средств. Сейчас и в перспективе данный участок дороги будет осложнен из-за увеличения транспортного потока, т.к. отсутствие светофора приведёт к увеличению дорожно-транспортных происшествий и сложности проезда. Во избежание аварийности уже сегодня на данном перекрестке необходимо установить светофор.

Введение
Точная и своевременная информация о том, что может произойти в экономике и обществе в будущем, всегда имела значение для тех, кто принимал бизнес-решения. Прогнозирование стало важной частью процесса планирования любой компании. Развитие современных экономических теорий, а также сложных компьютерных программ повлияло на подъем новых методов прогнозирования.
Сегодня рынок статистического программного обеспечения впечатляет своим многообразием. Существует более тысячи разнообразных программ решающих задачи статистического анализа данных. Зарекомендовавшими себя представителями этого класса программ являются SAS, STATISTICA, Statgraphics, а также отечественная разработка пакет STADIA. Однако бесспорным лидером является статистический пакет SPSS.
Целью данной курсовой работы является описание функциональных возможностей системы SPSS и решение средствами этой системы задачи прогнозирования.
Функциональные возможности системы SPSS
Пакет SPSS для Windows является в настоящее время одним из лидеров среди универсальных статистических пакетов. SPSS предлагает полный набор инструментов, обеспечивающих эффективную работу на всех этапах аналитического процесса — от планирования до управления данными, анализа данных и представления результатов.
Программное обеспечение SPSS позволяет:
§ Эффективно осуществлять сбор и ввод данных;
§ Организовывать простой доступ к данным;
§ Эффективно управлять данными;
§ Использовать различные статистические процедуры для анализа данных и строить более точные модели;
§ Наглядно представлять результаты тем;
§ Публиковать результаты в Интернете.
Для прогнозирования числовых переменных в системе SPSS можно использовать такие процедуры как:
§ Линейная регрессия — исследование взаимосвязей между предикторами и прогнозируемой переменной. Например, прогнозирование продаж на основе данных о ценах и доходе покупателей.
§ Линейная регрессия доступна в SPSS Base
§ Регрессия на основе взвешенного метода наименьших квадратов
§ — используется, когда дисперсия независимой переменной в генеральной совокупности непостоянна.
§ Регрессия на основе взвешенного метода наименьших квадратов доступна в SPSS Regression Models
§ Двухэтапный метод наименьших квадратов — применяется, когда предиктор и прогнозируемая переменная оказывают взаимное влияние друг на друга.
§ Двухэтапный метод наименьших квадратов доступен в SPSS Regression Models
§ Анализ выживаемости — оценка распределения временных интервалов между двумя событиями, например, временных интервалов от момента привлечения клиента до момента ухода клиента к конкурентам, даже если второе событие не регистрируется (например, клиенты остаются лояльными).
Анализ выживаемости доступен в SPSS Advanced Models
— Регрессия Кокса с ковариатами, зависящими от времени
Процедуры доступны в SPSS Advanced Models.
Мощным инструментом анализа временных рядов и прогнозирования является модуль SPSS Trends. SPSS Trends позволяет анализировать информацию о прошлом и предсказывать будущее.
SPSS Trends позволяет воспользоваться следующими процедурами оценивания:
§ Анализ Бокса-Дженкинса для несезонных и одномерных моделей
§ Процедуры для обработки сезонных составляющих
§ Оценка до четырех параметров в 12 различных моделях экспоненциального сглаживания
§ Различные регрессионные методы: регрессия тренда, регрессионные модели с авторегрессионными ошибками первого порядка
§ Разложение временных рядов на гармонические составляющие
На каждом этапе построения модели в SPSS Trends можно воспользоваться альтернативными методами. Для оценки степени адекватности модели в SPSS Trends выводятся статистики и нормальные вероятностные графики. Адекватность моделей можно оценивать при помощи автоматически вычисляемых стандартных ошибок и других статистик.
SPSS для Windows обладает целым рядом графических возможностей позволяющих визуально оценить полученные числовые результаты анализа и прогноза данных. Многочисленные типы диаграмм позволяют представлять результаты в наглядной форме.
§ Категориальные диаграммы (включая несколько типов столбиков, линий, областей, кругов и ящиков).
§ Диаграммы для контроля качества (включая диаграммы Парето, Х-среднего и Сигма).
§ Гистограммы и диаграммы рассеяния (включая перекрывающиеся, матричные и трехмерные).
§ Диагностические и исследовательские графики (включая графики по наблюдениям и графики временных рядов).
§ Вероятностные графики (включая графики наблюденных и ожидаемых значений).
§ Графики автокорреляционной и частной автокорреляционной функции (включая преобразование натурального логарифма и сезонное и несезонное дифференцирование).
§ Графики кросс-корреляционной функции (включая преобразование при помощи натурального логарифмирования, сезонное и несезонное дифференцирование).
Система презентационной графики SPSS для Windows позволяет без лишних усилий создавать диаграммы, наилучшим образом описывающие результаты анализа, а также редактировать созданные диаграммы для их более тонкой настройки. Системой презентационной графики также легко пользоваться в случае работы в производственном режиме. SPSS создавать диаграммы и применять параметры созданной диаграммы к новым диаграммам.
Для представления данных в табличном виде в системе SPSS имеется дополнительный модуль SPSS Tables. Интерактивный интерфейс построения таблиц обновляется в режиме реального времени, так что Вы можете видеть, как будет выглядеть таблица, и изменять ее в процессе построения. Такие возможности, как объединение несколько категорий в одну, вставка итогов и подитогов сверху, снизу, справа или слева в таблице, добавление подкатегорий, изменение типов переменных и исключение категорий позволяют быстро и эффективно управлять внешним видом таблиц. Кроме того, вместе с таблицами можно рассчитывать статистические критерии, что позволяет устанавливать и подчеркивать достоверность полученных результатов. Например, можно показать значимость связи между временем, уделяемым домашним животным, и временем восстановления после сердечного приступа, построив таблицу по переменной времени восстановления после сердечного приступа и переменным повседневной деятельности.
Скорость работы и производственные возможности SPSS Tables позволяют создавать большие отчеты, и обеспечивают быстрое и эффективное представление информации, заложенной в огромных массивах данных, в удобной и понятной форме. SPSS Tables обладает целым рядом возможностей, обеспечивающих удобную и быструю доставку получаемых табличных отчетов. Интерактивные мобильные таблицы, создаваемые в SPSS Tables, можно экспортировать в Word и Excel. Дополнительного форматирования таблиц не требуется, однако, при необходимости в таблицы можно вставлять содержательную и описательную информацию. Результаты также можно распечатывать и публиковать в Интернете.
Основные понятия и методы эконометрического прогнозирования
Прогнозирование — это научное, основанное на системе установленных причинно-следственных связей и закономерностей, выявление состояния и вероятностных путей развития явлений и процессов.
Статистические методы прогнозирования опираются на анализ временных рядов.
Временным рядом называется (рядом динамики) называется последовательность значений статистического показателя-признака, упорядоченная в хронологическом порядке, т.е. в порядке возрастания временного параметра. Отдельные наблюдения временного ряда называются уровнями этого ряда.
Каждый временной ряд содержит два элемента:
1. значения времени;
2. соответствующие им значения уровней ряда.
В качестве показателей времени во временных рядах могут указываться либо определенные моменты времени, либо отдельные периоды (сутки, месяцы, кварталы, полугодия, годы и т.д.). в зависимости от характера временного параметра ряды делятся на моментные и интервальные.
В моментных рядах уровни характеризуют значения показателей по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значения показателя за определенные интервалы времени.
Уровни рядов динамики могут представлять собой абсолютные, относительные и средние величины. Если уровни ряда представляют собой непосредственно не наблюдаемые значения, а производные величины: средние или относительные, то такие ряды называются производными. Уровни этих рядов получаются с помощью некоторых вычислений на основе абсолютных показателей.
Моментные ряды в отличие от интервальных не обладают свойством аддитивности. При исследовании моментных рядов смысл имеет расчет разностей уровней, характеризующих изменение показателя за некоторый период времени.
Успешность статистического анализа развития процесса во времени во многом зависит от правильного построения рядов динамики.
Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно разделить на 3 группы:
факторы, формирующие тенденции ряда;
факторы, формирующие циклические колебания ряда;
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы.
Если во временном ряду проявляется длительная тенденция изменения экономического показателя, то говорят, что имеет место тренд.
Если модель является временным рядом, представленным как сумма трендовой, циклической и случайной компонент, то такая модель называется аддитивной моделью временного ряда.
Если в модели временный ряд представлен как произведение перечисленных компонент, то такая модель называется мультипликативной моделью временного ряда.
Для статического анализа одномерных временных рядов экономических показателей вида: y1, у2,… уn вычисляют ряд величин:
— абсолютный прирост, который показывает величину изменения показателя за определенный интервал времени;
— средний абсолютный прирост:, т.е. прирост в единицу времени;
— коэффициент роста для t-го периода,
На практике часто применяют показатель темпа роста и темпа прироста:
, где Т- темп роста для t-го периода;
, где Т- темп прироста для t-го периода.
Предварительный анализ временных рядов экономических показателей заключается в основном в выявлении и устранении аномальных значений уровней ряда, а также в определении наличия тренда в исходном временном ряде. Под аномальным уровнем понимается отдельное значение уровня временного ряда, которое не отвечает потенциальным возможностям исследуемой экономической системы и оказывает существенное влияние на значения основных характеристик временного ряда.
Для выявления аномальных уровней временных рядов используются методы, рассчитанные для статистических совокупностей, например, метод Ирвина предполагает использование следующей формулы:
Расчетные значения, и т.д. сравниваются с табличными значениями критерия Ирвина, и если какое-то значение оказывается больше табличного, то соответствующее значение у уровня ряда считается аномальным.
Для определения наличия тренда в исходном временном ряду применяют ряд методов, в частности метод проверки разностей средних уровней.
Чтобы более четко выявить тенденцию развития исследуемого процесса производят сглаживание (выравнивание) временных рядов.
Сглаживания временных рядов можно осуществлять аналитическими или механическими методами.
Суть аналитических методов заключается в построении кривой, проходящей между конкретными уровнями ряда так, чтобы она отображала тенденцию, присущую ряду, и одновременно освобождала его от незначительных колебаний.
Суть методов механического сглаживания заключается в следующем: берется несколько первых уровней временного ряда, образующих интервал сглаживания, и для них подбирается полином, степень которого должна быть меньше числа уровней, входящих в интервал сглаживания; с помощью полинома определяются новые, выровненные значения уровней в середине интервала сглаживания. Далее интервал сглаживания сдвигается на один уровень ряда вправо, вычисляется следующее сглаженное значение и т.д.
Простейшим методом механического сглаживания является метод простой скользящей средней.
При наличии во временном ряду тенденции и циклических изменений значения последующего уровня ряда зависят от предыдущих. Зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда.
Количественно ее можно измерить с помощью индекса корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени.
Последовательность коэффициентов автокорреляции уровней первого, второго и т.д. порядков называют автокорреляционной функцией временного ряда (АКФ).
График зависимости ее значений от величины лага называется коррелограмой.
АКФ и коррелограмма позволяют определить лаг, при котором автокорреляция наиболее высокая, а, следовательно, и лаг, при котором связь между текущим и предыдущим уровнями ряда наиболее тесная, т.е. с их помощью можно выявить структуру ряда.
Коэффициент автокорреляции и АКФ целесообразно использовать для выявления во временном ряде наличия или отсутствия трендовой компоненты и циклической компоненты:
если наиболее высоким оказался коэффициент автокорреляции 1-го порядка, то исследуемый ряд содержит только тенденцию;
если наиболее высоким оказался коэффициент автокорреляции к-го порядка, то ряд содержит циклические колебания с периодичностью в к-моментов времени;
если, ни один из коэффициентов не является значимым, то можно сделать одно из двух предположений, относительно структуры этого ряда: либо ряд не содержит тенденции и циклических изменений и имеет структуру, сходную со структурой ряда, изображенного на рис. 5.1в, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
При моделировании временных рядов нередко встречается ситуация, когда остатки содержат тенденцию или циклические колебания, когда в соответствии с предпосылками МНК остатки должны быть случайными.
В том случае, когда каждое следующее значение зависит от, говорят о наличии автокорреляции остатков. Причинами автокорреляции могут быть: исходные данные с ошибками в измерениях результативного признака; формулировка модели (модель может не включать фактор, оказывающий существенное воздействие на результат). Очень часто этим фактором является фактор времени t).
Если причина автокорреляции — в неправильной спецификации функциональной формы модели, то следует изменить форму связи факторных и результативных признаков.
Существуют два наиболее распространенных метода определения автокорреляции остатков: 1) путем построения графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции; 2) использование критерия Дарбина-Уотсона и расчет величины
Одним из наиболее распространенных способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Для построения трендов чаще всего применяются следующие функции:
· экспоненциальный тренд: или;
· — полином 2-й степени;
· — полином 3-й степени.
Расчет оценок параметров трендовых моделей с помощью метода наименьших квадратов в рамках регрессионных моделей, в которых в качестве значений зависимой переменной выступают фактические уровни ряда, а в роли независимой переменной — время t. Для нелинейных трендовых моделей применяется процедуры линеаризации. В том случаи, если уравнение тренда преобразовать к линейному виду невозможно, применяют нелинейные методы оценивания коэффициентов.
При наличии неявной нелинейной тенденции следует дополнять описанные выше методы качественным анализом динамики изучаемого показателя, с тем, чтобы избежать ошибок спецификации при выборе вида тренда.
Качественный анализ предполагает изучение проблем возможного наличия в исследуемом временном ряде поворотных точек и изменения темпов прироста, начиная с определенного момента. В случае если уравнение тренда выбрано неверно при больших значениях t, результаты прогноза на основе выбранного вида тренда будут недостоверными.
Существует несколько подходов к анализу структуры временных рядов, содержащих сезонные или циклические колебания. Простейший подход — построение аддитивной или мультипликативной модели временного ряда методом скользящей средней.
При краткосрочном прогнозировании, а также при прогнозировании в ситуации изменения внешних условий, когда более важными являются последние реализации исследуемого процесса, более эффективными оказываются адаптивные методы, учитывающие неравноценность уровней временного ряда.
Адаптивные модели прогнозирования — это модели дисконтирования данных, способные быстро приспосабливать свою структуру и параметры к изменению условий. Инструментом прогноза в адаптивной модели является математическая модель, аргументом которой выступает — время.
При оценке параметров адаптивных моделей, в отличии от «кривых роста», наблюдениям (уровням ряда) присваиваются различные веса, в зависимости от того, насколько сильным признается их влияние на текущий уровень. Это позволяет учитывать изменения в тенденции, а также любые колебания, в которых прослеживается закономерность. В качестве примера можно назвать модель экспоненциального сглаживания Брауна.
Источник: studopedia.info