
Разработчик INFORMATSIONNOE AGENTSTVO INTERFAX, AO указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Связанные с пользователем данные
- Контактные данные
- Идентификаторы
- Диагностика
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Информация
Провайдер INFORMATSIONNOE AGENTSTVO INTERFAX, AO
Размер 24,1 МБ
Совместимость iPhone Требуется iOS 13.0 или новее. iPad Требуется iPadOS 13.0 или новее. iPod touch Требуется iOS 13.0 или новее. Mac Требуется macOS 11.0 или новее и компьютер Mac с чипом Apple M1 или новее.
Возраст 12+ Малое/умеренное количество использования или упоминания алкогольной и табачной продукции или наркотических средств Малое/умеренное количество сквернословия или грубого юмора
Очень кратко про Hadoop и Spark
Цена Бесплатно
Встроенные покупки
- Сайт разработчика
- Поддержка приложения
Источник: apps.apple.com
Новая функция в 1СПАРК Риски – переход в веб-версию СПАРК из программ 1С
Система СПАРК является бесспорным лидером на рынке информационно-аналитических систем о компаниях по данным рейтингового агентства RAEX и используется для проверки благонадежности партнеров 71,5% компаний крупного и среднего бизнеса. В 2016 году фирма 1С и Интерфакс выпустили совместный продукт 1СПАРК Риски. Сервис 1СПАРК Риски использует данные из системы СПАРК, встроен в программы 1С и недорого стоит. Таким образом, возможности премиум-системы проверки благонадежности контрагентов для крупных компаний стали доступны абсолютному большинству пользователей программ 1С.
Уникальным преимуществом сервиса 1СПАРК Риски является то, что он помогает пользователям программ 1С «по месту», непосредственно в программе. Индексы отображаются в карточке контрагента, при формировании платежного поручения, в отчетах по дебиторской задолженности и т. д. Мониторинг помогает следить за важными изменениями у контрагентов: ликвидации, реорганизации, смене руководителя, адреса, учредителей и т. п. Бизнес-справку с электронной подписью Интерфакс также можно заказать прямо из программы и использовать для быстрой проверки контрагента по основным признакам хозяйственной деятельности за последние 12 месяцев.
С момента выпуска сервис постоянно развивался: совершенствовалась система расчета индексов и мониторинга, по пожеланиям пользователей менялся состав и вид бизнес-справки. В начале апреля 2021 года в сервис была добавлена информация об индивидуальных предпринимателях.
Что такое Apache Spark
С 4 июня у пользователей тарифа 1СПАРК Риски + появилась возможность получить еще больше информации по контрагентам. В программу 1С:Бухгалтерия предприятия начиная с версии 3.0.94.17 встроен переход в карточку организации в веб-версии СПАРК Интерфакс.
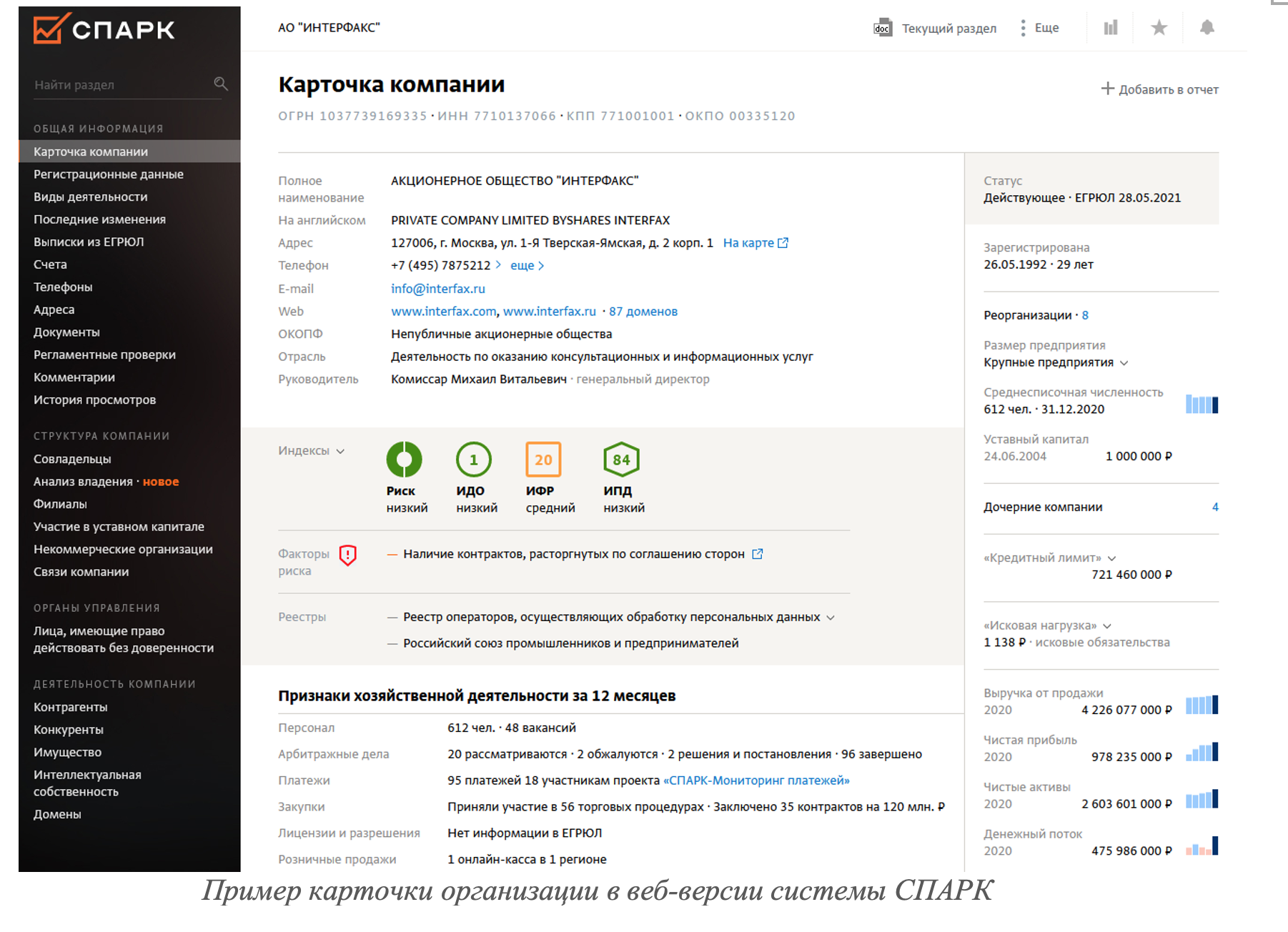
СПАРК анализирует доступные сведения по юридическим и физическим лицам более чем из 200 источников данных. На главной странице карточки юридического или физического лица в СПАРК пользователям 1С, при наличии данных в источнике, будет доступна ключевая информация по компании или персоне, а также показатели, требующие повышенного внимания:
- Основные реквизиты компании;
- Контактные сведения;
- Текущий статус (действующее, в стадии ликвидации, недействующее, в стадии банкротства и др.);
- Индексы СПАРК (Сводный риск, ИПД, ИДО, ИФР);
- Факторы риска и факторы, требующие внимания (Система анализирует всю доступную информацию о контрагенте и оповещает пользователя о наиболее значимых, рисковых событиях — более 50 готовых параметров);
- Вхождение компании/персоны в реестры, в том числе негативные;
- Признаки финансово-хозяйственной деятельности компании или ИП за 12 месяцев;
- Ключевые финансовые показатели и численность персонала.
Более подробная информация будет представлена в соответствующих разделах карточки:
Общая информация
- Регистрационные и контактные сведения (регистрационные коды, телефоны, сайты и домены, адрес);
- История изменений;
- Выписки из ЕГРЮЛ/ЕГРИП (актуальные или выписки на определенную дату);
- Виды деятельности.
Структура компании
- Структура собственников и дочерних компаний и анализ взаимосвязей;
- Сведения об обособленных подразделениях и представительствах.
Деятельность компании
- Сведения о наличии у компании или персоны залогов, лизинга, факторинга, исполнительных производств, гарантий и др.;
- Анализ судебной практики (Арбитражные суды и суды общей юрисдикции);
- Информация из узкоспециализированных отраслевых источников для оценки «признаков жизни» и легальности бизнеса;
- Новости и сообщения СМИ;
- Сведения об участии компании в качестве заказчика/поставщика государственных закупок.
Финансовая информация
- Ежегодная бухгалтерская отчетность организаций;
- Ежеквартальная отчетность эмитентов;
- Финансовая отчетность банков и страховых компаний.
Финансовый анализ
- Аналитические данные и оценка финансового состояния компании, рассчитанные на основе информации годовой бухгалтерской отчетности компании (динамика, графики, готовые выводы).
В карточках физических лиц реализован функционал автоматической проверки наличия персоны в реестре плательщиков налога на профессиональный доход (самозанятые).
В систему СПАРК можно перейти только из программы 1С. На примере «1С:Бухгалтерия предприятия», в карточке контрагента можно нажать кнопку «Веб-версия СПАРК» и карточка контрагента будет открыта в веб-браузере, который выбран по умолчанию в системе пользователя (Google Chrome, Mozilla Firefox и т.д.).
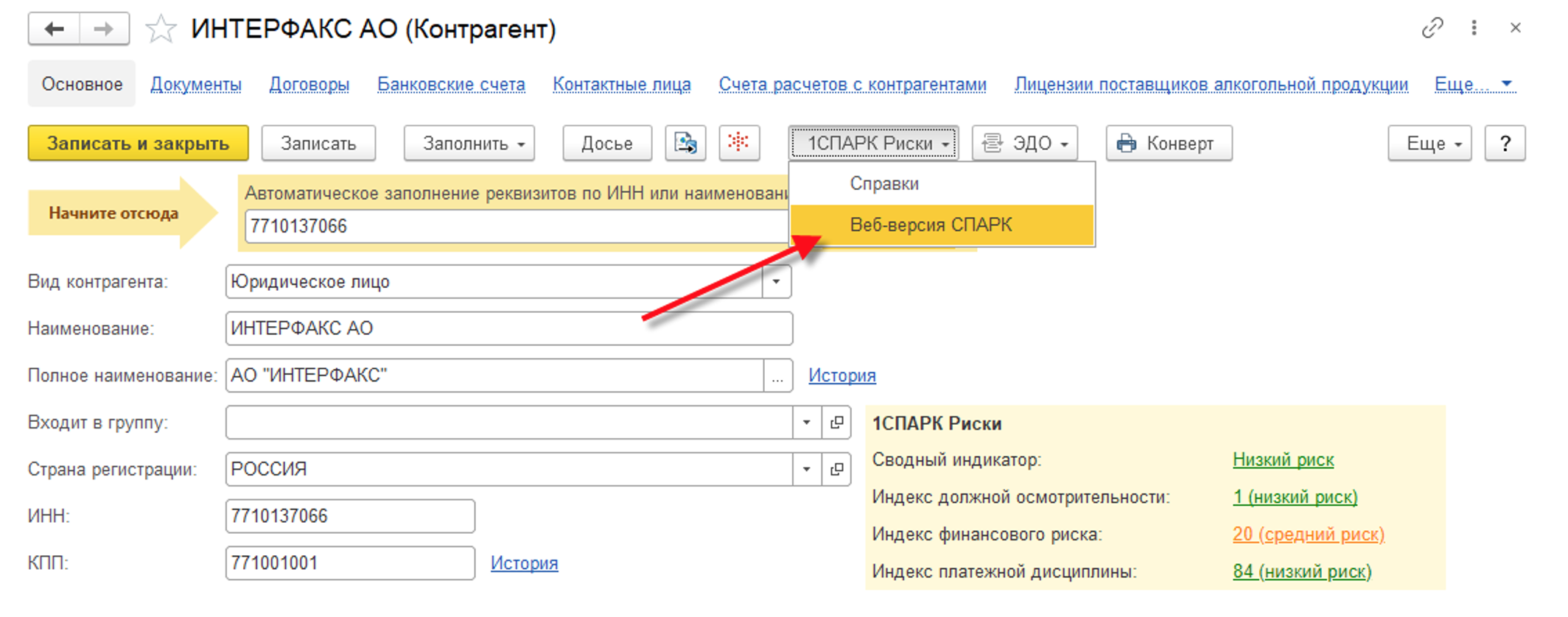
Список компаний, по которым были ранее открыты карточки СПАРК из программы 1С, можно просмотреть в личном кабинете на Портале 1С:ИТС: https://portal.1c.ru/application/list/1C-Spark-risks/received-cards-info. Также из этого списка в личном кабинете на Портале 1С:ИТС на можно перейти в карточку компании в СПАРК.
Возможность перехода в веб-версию СПАРК реализована в Библиотеке интернет-поддержки с версии 2.5.1.41 и в ближайшее время будет встроена в программы 1С. Список программ, которые поддерживают переход в веб-версию СПАРК, можно узнать на Портале 1С:ИТС: https://portal.1c.ru/applications/47#termsOfUse.
Тарифы и цены
Тариф «1СПАРК Риски +» был расширен, теперь в него включены:
- Индексы по всем компаниям в программах 1С;
- Мониторинг событий по всем компаниям в программах 1С;
- Бизнес-справки по 150 компаниям;
- Карточки в веб-версии СПАРК по 150 компаниям.
Возможность перехода в карточку организации в СПАРКе по 150 контрагентам включена во все тарифы «1СПАРК Риски +», в том числе и в тарифы, которые уже действуют.
Использование бизнес-справок не зависит от использования карточек контрагентов, как и наоборот. То есть бизнес-справки можно получать по одному списку компаний, при этом открывать карточки в веб-версии СПАРК можно по другим компаниям из программы 1С.
При продлении лицензии «1СПАРК Риски +» и после окончания предыдущей, пользователю начисляется бонус в 150 компаний, по которым он может переходить в карточки СПАРК. Для получения бонуса необходимо продлить лицензию в течение месяца, после окончания предыдущей лицензии «1СПАРК Риски +». При своевременном продлении бонус в 150 компаний, по которым можно получать карточки СПАРК, начисляется за каждую предыдущую закончившуюся лицензию «1СПАРК Риски +».
Всем пользователям, у которых уже есть бонусы за своевременное продление «1СПАРК Риски +», начислено дополнительное количество карточек СПАРК, равное количеству начисленных ранее бонусных бизнес-справок за продление.
В составе тарифа «1СПАРК Риски» не произошло изменений и пользователям доступны:
- Индексы по всем компаниям в программах 1С;
- Мониторинг событий по всем компаниям в программах 1С.
Чтобы оценить новые возможности сервиса 1СПАРК Риски, все пользователи 1С могут получить тестовый доступ к сервису, даже если раньше им уже воспользовались. Тестовый период предоставляется на 7 дней и в него входит:
- Индексы СПАРК по всем контрагентам;
- Мониторинг всех контрагентов;
- Неограниченное количество справок по 5 контрагентам;
- Карточки в веб-версии СПАРК по 5 контрагентам.
Стоимость лицензий 1СПАРК Риски не изменилась:
Артикул
Наименование
Рекоменд. розничная цена, руб.
«1СПАРК Риски на 12 месяцев»
«1СПАРК Риски Плюс на 12 месяцев»
Техническая поддержка
Статья относится к тематикам: Автоматизация на 1С
Поделиться публикацией:
Подписывайтесь на наши новостные рассылки, а также на каналы Telegram , Vkontakte , Яндекс.Дзен чтобы первым быть в курсе главных новостей Retail.ru.
Добавьте «Retail.ru» в свои источники в Яндекс.Новости
Новая функция в 1СПАРК Риски – переход в веб-версию СПАРК из программ 1С https://www.retail.ru
Система СПАРК является бесспорным лидером на рынке информационно-аналитических систем о компаниях по данным рейтингового агентства RAEX и используется для проверки благонадежности партнеров 71,5% компаний крупного и среднего бизнеса. В 2016 году фирма 1С и Интерфакс выпустили совместный продукт 1СПАРК Риски. Сервис 1СПАРК Риски использует данные из системы СПАРК, встроен в программы 1С и недорого стоит. Таким образом, возможности премиум-системы проверки благонадежности контрагентов для крупных компаний стали доступны абсолютному большинству пользователей программ 1С.
Уникальным преимуществом сервиса 1СПАРК Риски является то, что он помогает пользователям программ 1С «по месту», непосредственно в программе. Индексы отображаются в карточке контрагента, при формировании платежного поручения, в отчетах по дебиторской задолженности и т. д. Мониторинг помогает следить за важными изменениями у контрагентов: ликвидации, реорганизации, смене руководителя, адреса, учредителей и т. п. Бизнес-справку с электронной подписью Интерфакс также можно заказать прямо из программы и использовать для быстрой проверки контрагента по основным признакам хозяйственной деятельности за последние 12 месяцев.
С момента выпуска сервис постоянно развивался: совершенствовалась система расчета индексов и мониторинга, по пожеланиям пользователей менялся состав и вид бизнес-справки. В начале апреля 2021 года в сервис была добавлена информация об индивидуальных предпринимателях.
С 4 июня у пользователей тарифа 1СПАРК Риски + появилась возможность получить еще больше информации по контрагентам. В программу 1С:Бухгалтерия предприятия начиная с версии 3.0.94.17 встроен переход в карточку организации в веб-версии СПАРК Интерфакс.
СПАРК анализирует доступные сведения по юридическим и физическим лицам более чем из 200 источников данных. На главной странице карточки юридического или физического лица в СПАРК пользователям 1С, при наличии данных в источнике, будет доступна ключевая информация по компании или персоне, а также показатели, требующие повышенного внимания:
- Основные реквизиты компании;
- Контактные сведения;
- Текущий статус (действующее, в стадии ликвидации, недействующее, в стадии банкротства и др.);
- Индексы СПАРК (Сводный риск, ИПД, ИДО, ИФР);
- Факторы риска и факторы, требующие внимания (Система анализирует всю доступную информацию о контрагенте и оповещает пользователя о наиболее значимых, рисковых событиях — более 50 готовых параметров);
- Вхождение компании/персоны в реестры, в том числе негативные;
- Признаки финансово-хозяйственной деятельности компании или ИП за 12 месяцев;
- Ключевые финансовые показатели и численность персонала.
Более подробная информация будет представлена в соответствующих разделах карточки:
Общая информация
- Регистрационные и контактные сведения (регистрационные коды, телефоны, сайты и домены, адрес);
- История изменений;
- Выписки из ЕГРЮЛ/ЕГРИП (актуальные или выписки на определенную дату);
- Виды деятельности.
Структура компании
- Структура собственников и дочерних компаний и анализ взаимосвязей;
- Сведения об обособленных подразделениях и представительствах.
Деятельность компании
- Сведения о наличии у компании или персоны залогов, лизинга, факторинга, исполнительных производств, гарантий и др.;
- Анализ судебной практики (Арбитражные суды и суды общей юрисдикции);
- Информация из узкоспециализированных отраслевых источников для оценки «признаков жизни» и легальности бизнеса;
- Новости и сообщения СМИ;
- Сведения об участии компании в качестве заказчика/поставщика государственных закупок.
Финансовая информация
- Ежегодная бухгалтерская отчетность организаций;
- Ежеквартальная отчетность эмитентов;
- Финансовая отчетность банков и страховых компаний.
Финансовый анализ
- Аналитические данные и оценка финансового состояния компании, рассчитанные на основе информации годовой бухгалтерской отчетности компании (динамика, графики, готовые выводы).
В карточках физических лиц реализован функционал автоматической проверки наличия персоны в реестре плательщиков налога на профессиональный доход (самозанятые).
В систему СПАРК можно перейти только из программы 1С. На примере «1С:Бухгалтерия предприятия», в карточке контрагента можно нажать кнопку «Веб-версия СПАРК» и карточка контрагента будет открыта в веб-браузере, который выбран по умолчанию в системе пользователя (Google Chrome, Mozilla Firefox и т.д.).
Список компаний, по которым были ранее открыты карточки СПАРК из программы 1С, можно просмотреть в личном кабинете на Портале 1С:ИТС: https://portal.1c.ru/application/list/1C-Spark-risks/received-cards-info. Также из этого списка в личном кабинете на Портале 1С:ИТС на можно перейти в карточку компании в СПАРК.
Возможность перехода в веб-версию СПАРК реализована в Библиотеке интернет-поддержки с версии 2.5.1.41 и в ближайшее время будет встроена в программы 1С. Список программ, которые поддерживают переход в веб-версию СПАРК, можно узнать на Портале 1С:ИТС: https://portal.1c.ru/applications/47#termsOfUse.
Тарифы и цены
Тариф «1СПАРК Риски +» был расширен, теперь в него включены:
- Индексы по всем компаниям в программах 1С;
- Мониторинг событий по всем компаниям в программах 1С;
- Бизнес-справки по 150 компаниям;
- Карточки в веб-версии СПАРК по 150 компаниям.
Возможность перехода в карточку организации в СПАРКе по 150 контрагентам включена во все тарифы «1СПАРК Риски +», в том числе и в тарифы, которые уже действуют.
Использование бизнес-справок не зависит от использования карточек контрагентов, как и наоборот. То есть бизнес-справки можно получать по одному списку компаний, при этом открывать карточки в веб-версии СПАРК можно по другим компаниям из программы 1С.
При продлении лицензии «1СПАРК Риски +» и после окончания предыдущей, пользователю начисляется бонус в 150 компаний, по которым он может переходить в карточки СПАРК. Для получения бонуса необходимо продлить лицензию в течение месяца, после окончания предыдущей лицензии «1СПАРК Риски +». При своевременном продлении бонус в 150 компаний, по которым можно получать карточки СПАРК, начисляется за каждую предыдущую закончившуюся лицензию «1СПАРК Риски +».
Всем пользователям, у которых уже есть бонусы за своевременное продление «1СПАРК Риски +», начислено дополнительное количество карточек СПАРК, равное количеству начисленных ранее бонусных бизнес-справок за продление.
В составе тарифа «1СПАРК Риски» не произошло изменений и пользователям доступны:
- Индексы по всем компаниям в программах 1С;
- Мониторинг событий по всем компаниям в программах 1С.
Чтобы оценить новые возможности сервиса 1СПАРК Риски, все пользователи 1С могут получить тестовый доступ к сервису, даже если раньше им уже воспользовались. Тестовый период предоставляется на 7 дней и в него входит:
- Индексы СПАРК по всем контрагентам;
- Мониторинг всех контрагентов;
- Неограниченное количество справок по 5 контрагентам;
- Карточки в веб-версии СПАРК по 5 контрагентам.
Стоимость лицензий 1СПАРК Риски не изменилась:
Артикул
Наименование
Рекоменд. розничная цена, руб.
«1СПАРК Риски на 12 месяцев»
«1СПАРК Риски Плюс на 12 месяцев»
Техническая поддержка
1С, автоматизация, аналитика, рейтинги, контрагент Новая функция в 1СПАРК Риски – переход в веб-версию СПАРК из программ 1С
Источник: www.retail.ru
Apache Spark: гайд для новичков

Специалисты компании Databricks, основанной создателями Spark, собрали лучшее о функционале Apache Spark в своей книге Gentle Intro to Apache Spark (очень рекомендую прочитать):

“Apache Spark — это целостная вычислительная система с набором библиотек для параллельной обработки данных на кластерах компьютеров. На данный момент Spark считается самым активно разрабатываемым средством с открытым кодом для решения подобных задач, что позволяет ему быть полезным инструментом для любого разработчика или исследователя-специалиста, заинтересованного в больших данных. Spark поддерживает множество широко используемых языков программирования (Python, Java, Scala и R), а также библиотеки для различных задач, начиная от SQL и заканчивая стримингом и машинным обучением, а запустить его можно как с ноутбука, так и с кластера, состоящего из тысячи серверов. Благодаря этому Apache Spark и является удобной системой для начала самостоятельной работы, перетекающей в обработку больших данных в невероятно огромных масштабах.”
Что такое большие данные?
Посмотрим-ка на популярное определение больших данных по Гартнеру. Это поможет разобраться в том, как Spark способен решить множество интересных задач, которые связаны с работой с большими данными в реальном времени:
“Большие данные — это информационные активы, которые характеризуются большим объёмом, высокой скоростью и/или многообразием, а также требуют экономически эффективных инновационных форм обработки информации, что приводит к усиленному пониманию, улучшению принятия решений и автоматизации процессов.”
Заметка: Ключевой вывод — слово “большие” в больших данных относится не только к объёму. Вы не просто получаете много данных, они поступают в реальном времени очень быстро и в различных комплексных форматах, а ещё — из большого многообразия источников. Вот откуда появились 3-V больших данных: Volume (Объём), Velocity (Скорость), Variety (Многообразие).
Причины использовать Spark
Основываясь на самостоятельном предварительном исследовании этого вопроса, я пришёл к выводу, что у Apache Spark есть три главных компонента, которые делают его лидером в эффективной работе с большими данными, а это мотивирует многие крупные компании работать с большими наборами неструктурированных данных, чтобы Apache Spark входил в их технологический стек.
- Spark — всё-в-одном для работы с большими данными. “Spark создан для того, чтобы помогать решать широкий круг задач по анализу данных, начиная с простой загрузки данных и SQL-запросов и заканчивая машинным обучением и потоковыми вычислениями, при помощи одного и того же вычислительного инструмента с неизменным набором API. Главный инсайт этой программной многозадачности в том, что задачи по анализу данных в реальном мире — будь они интерактивной аналитикой в таком инструменте, как Jupyter Notebook, или же обычным программированием для выпуска приложений — имеют тенденцию требовать сочетания множества разных типов обработки и библиотек. Целостная природа Spark делает решение этих заданий проще и эффективнее.” (Из книги Databricks). Например, если вы загружаете данные при помощи SQL-запроса и потом оцениваете модель машинного обучения при помощи библиотеки Spark ML, движок может объединить все эти шаги в один проход по данным. Более того, для исследователей данных может быть выгодно применять объединённый набор библиотек (например, Python или R) при моделировании, а веб-разработчикам пригодятся унифицированные фреймворки, такие как Node.js или Django.
- Spark оптимизирует своё машинное ядро для эффективных вычислений — “то есть Spark только управляет загрузкой данных из систем хранения и производит вычисления над ними, но сам не является конечным постоянным хранилищем. Со Spark можно работать, когда имеешь дело с широким разнообразием постоянных систем хранения, включая системы облачного типа по примеру Azure Storage и Amazon S3, распределенные файловые системы, такие как Apache Hadoop, пространства для хранения ключей, как Apache Cassandra, и последовательностей сообщений, как Apache Kafka. И всё же, Spark не сохраняет данные сам по себе надолго и не поддерживает ни одну из этих систем. Главная причина здесь в том, что большинство данных уже находится в нескольких системах хранения. Перемещать данные дорого, поэтому Spark только обрабатывает данные при помощи вычислительных операций, не важно, где они при этом находятся.” (из книги Databricks). Сфокусированность Sparks на вычислениях отличает его от более ранних программных платформ по обработке больших данных, например от Apache Hadoop. Это ПО включает в себя и систему хранения (HFS, сделанную для недорогих хранилищ на кластерах продуктовых серверов Defining Spark 4) и вычислительную систему (MapReduce). Между собой они интегрируются достаточно хорошо. И всё же это тяжело реализовать с участием только одной части без применения второй или, что важнее, написать приложения, которые имеют доступ к данным, хранящимся где-то еще. Spark также широко применяется сейчас в средах, где в архитектуре Hadoop нет смысла. Например, на публичном облаке (где хранение можно купить отдельно от обработки) или в потоковых приложениях.
- Библиотеки Spark дарят очень широкую функциональность — сегодня стандартные библиотеки Spark являются главной частью этого проекта с открытым кодом. Ядро Spark само по себе не слишком сильно изменялось с тех пор, как было выпущено, а вот библиотеки росли, чтобы добавлять ещё больше функциональности. И так Spark превратился в мультифункциональный инструмент анализа данных. В Spark есть библиотеки для SQL и структурированных данных (Spark SQL), машинного обучения (MLlib), потоковой обработки (Spark Streaming и более новый Structured Streaming) и аналитики графов (GraphX). Кроме этих библиотек есть сотни открытых сторонних библиотек, начиная от тех, что работают с коннекторами и до вариантов для различных систем хранения и алгоритмов машинного обучения.
Apache Spark или Hadoop MapReduce…Что вам подходит больше?
Если отвечать коротко, то выбор зависит от конкретных потребностей вашего бизнеса, естественно. Подытоживая свои исследования, скажу, что Spark выбирают в 7-ми из 10-ти случаев. Линейная обработка огромных датасетов — преимущество Hadoop MapReduce. Ну а Spark знаменит своей быстрой производительностью, итеративной обработкой, аналитикой в режиме реального времени, обработкой графов, машинным обучением и это ещё не всё.
Хорошие новости в том, что Spark полностью совместим с экосистемой Hadoop и работает замечательно с Hadoop Distributed File System (HDFS — Распределённая файловая система Hadoop), а также с Apache Hive и другими похожими системами. Так что, когда объёмы данных слишком огромные для того, чтобы Spark мог удержать их в памяти, Hadoop может помочь преодолеть это затруднение при помощи возможностей его файловой системы. Привожу ниже пример того, как эти две системы могут работать вместе:
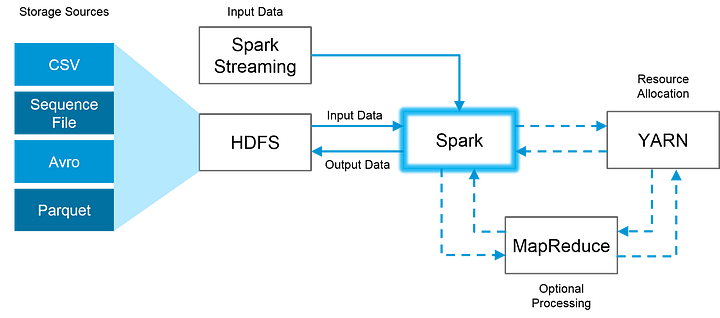
Это изображение наглядно показывает, как Spark использует в работе лучшее от Hadoop: HDFS для чтения и хранения данных, MapReduce — для дополнительной обработки и YARN — для распределения ресурсов.
Дальше я пробую сосредоточиться на множестве преимуществ Spark перед Hadoop MapReduce. Для этого я сделаю краткое поверхностное сравнение.

Скорость
- Apache Spark —это вычислительный инструмент, работающий со скоростью света. Благодаря уменьшению количества чтения-записи на диск и хранения промежуточных данных в памяти, Spark запускает приложения в 100 раз быстрее в памяти и в 10 раз быстрее на диске, чем Hadoop.
- Hadoop MapReduce— MapReduce читает и записывает на диск, а это снижает скорость обработки и эффективность в целом.
Просто пользоваться
- Apache Spark— многие библиотеки Spark облегчают выполнение большого количества основных высокоуровневых операций при помощи RDD (Resilient Distributed Dataset/эластичный распределённый набор данных).
- Hadoop — в MapReduce разработчикам нужно написать вручную каждую операцию, что только усложняет процесс при масштабировании сложных проектов.
Обработка больших наборов данных
- Apache Spark— так как, Spark оптимизирован относительно скорости и вычислительной эффективности при помощи хранения основного объёма данных в памяти, а не на диске, он может показывать более низкую производительность относительно Hadoop MapReduce в случаях, когда размеры данных становятся такими огромными, что недостаточность RAM становится проблемой.
- Hadoop —Hadoop MapReduce позволяет обрабатывать огромные наборы данных параллельно. Он разбивает большую цепочку на небольшие отрезки, чтобы обрабатывать каждый отдельно на разных узлах данных. Если итоговому датасету необходимо больше, чем имеется в доступе RAM, Hadoop MapReduce может сработать лучше, чем Spark. Поэтому Hadoop стоит выбрать в том случае, когда скорость обработки не критична и решению задач можно отвести ночное время, чтобы утром результаты были готовы.
Функциональность
Apache Spark — неизменный победитель в этой категории.Ниже я даю список основных задач по анализу больших данных, в которых Spark опережает Hadoop по производительности:
- Итеративная обработка. Если по условию задачи нужно обрабатывать данные снова и снова, Spark разгромит Hadoop MapReduce. Spark RDD активирует многие операции в памяти, в то время как Hadoop MapReduce должен записать промежуточные результаты на диск.
- Обработка в почти что реальном времени. Если бизнесу нужны немедленные инсайты, тогда стоит использовать Spark и его обработку прямо в памяти.
- Обработка графов. Вычислительная модель Spark хороша для итеративных вычислений, которые часто нужны при обработке графов. И в Apache Spark есть GraphX — API для расчёта графов.
Машинное обучение. В Spark есть MLlib — встроенная библиотека машинного обучения, а вот Hadoop нужна третья сторона для такого же функционала. MLlib имеет алгоритмы “out-of-the-box” (возможность подключения устройства сразу после того, как его достали из коробки, без необходимости устанавливать дополнительное ПО, драйверы и т.д.), которые также реализуются в памяти.
- Объединение датасетов. Благодаря скорости Spark может создавать все комбинации быстрее, а вот Hadoop показывает себя лучше в объединении очень больших наборов данных, которым нужно много перемешивания и сортировки.
А вот и визуальный итог множества возможностей Spark и его совместимости с другими инструментами обработки больших данных и языками программирования:
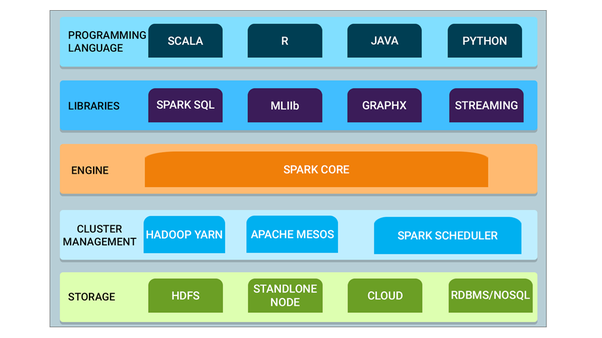
- Spark Core — это базовый инструмент для крупномасштабной параллельной и распределённой обработки данных. Кроме того, есть дополнительные библиотеки, встроенные поверх ядра. Они позволяют разделить рабочие нагрузки для стриминга, SQL и машинного обучения. Отвечают за управление памятью и восстановление после ошибок, планирование, распределение и мониторинг задач в кластере, а также взаимодействие с системами хранения.
- Cluster management (управление кластером) — контроль кластера используется для получения кластерных ресурсов, необходимых для решения задач. Spark Core работает на разных кластерных контроллерах, включая Hadoop YARN, Apache Mesos, Amazon EC2 и встроенный кластерный менеджер Spark. Такая служба контролирует распределение ресурсов между приложениями Spark. Кроме того, Spark может получать доступ к данным в HDFS, Cassandra, HBase, Hive, Alluxio и любом хранилище данных Hadoop.
- Spark Streaming — это компонент Spark, который нужен для обработки потоковых данных в реальном времени.
- Spark SQL — это новый модуль в Spark. Он интегрирует реляционную обработку с API функционального программирования в Spark. Поддерживает извлечение данных, как через SQL, так и через Hive Query Language. API DataFrame и Dataset в Spark SQL обеспечивают самый высокий уровень абстракции для структурированных данных.
- GraphX — API Spark для графов и параллельных вычислений с графами. Так что он является расширением Spark RDD с графом устойчивого распределения свойств (Resilient Distributed Property Graph).
- MLlib (Машинное обучение): MLlib расшифровывается как библиотека машинного обучения. Нужна для реализации машинного обучения в Apache Spark.
Заключение
Вместе со всем этим массовым распространением больших данных и экспоненциально растущей скоростью вычислительных мощностей инструменты вроде Apache Spark и других программ, анализирующих большие данные, скоро будут незаменимы в работе исследователей данных и быстро станут стандартом в индустрии реализации аналитики больших данных и решении сложных бизнес-задач в реальном времени.
Для тех, кому интересно погрузиться глубоко в технологию, которая стоит за всеми этими внешними функциями, почитайте книгу Databricks — “A Gentle Intro to Apache Spark” или “Big Data Analytics on Apache Spark”.
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
- Почему за способностью объяснения модели стоит будущее Data Science
Источник: nuancesprog.ru