
На стадии подготовки и обработки информации, особенно при компьютеризации предприятия, автоматизации бухучета, возникает задача ввода большого объема текстовой и графической информации в ПК. Основными устройствами для ввода графической информации являются: сканер, факс-модем и реже цифровая фотокамера.
Кроме того, используя программы оптического распознавания текстов, можно вводить в компьютер (оцифровывать) также и текстовую информацию. Современные программно-аппаратные системы позволяют автоматизировать ввод больших объемов информации в компьютер, используя, например, сетевой сканер и параллельное распознавание текстов на нескольких компьютерах одновременно.
Большинство программ оптического распознавания текста (OCR Optical Character Recognition) работают с растровым изображением, которое получено через факс-модем, сканер, цифровую фотокамеру или другое устройство. На первом этапе OCR должен разбить страницу на блоки текста, основываясь на особенностях правого и левого выравнивания и наличия нескольких колонок.
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
Затем распознанный блок разбивается на строки. Несмотря на кажущуюся простоту, это не такая очевидная задача, так как на практике неизбежны перекос изображения страницы или фрагментов страницы при сгибах. Даже небольшой наклон приводит к тому, что левый край одной строки становится ниже правого края следующей, особенно при маленьком межстрочном интервале.
Врезультате возникает проблема определения строки, к которой относится тот или иной фрагмент изображения. Например, для букв j, Й, ё при небольшом наклоне уже сложно определить, к какой строке относится верхняя (отдельная) часть символа (в некоторых случаях ее можно принять за запятую или точку).
Потом строки разбиваются на непрерывные области изображения, которые, как правило, соответствуют отдельным буквам; алгоритм распознавания делает предположения относительно соответствия этих областей символам; а затем делается выбор каждого символа, в результате чего страница восстанавливается в символах текста, причем, как правило, в соответствующем формате. OCR-системы могут достигать наилучшей точности распознавания свыше 99,9% для чистых изображений, составленных из обычных шрифтов.
На первый взгляд такая точность распознавания кажется идеальной, но уровень ошибок все же удручает, потому что, если имеется приблизительно 1500 символов на странице, то даже при коэффициенте успешного распознавания 99,9% получается одна или две ошибки на страницу. Втаких случаях на помощь приходит метод проверки по словарю.
То есть, если какого-то слова нет в словаре системы, то она по специальным правилам пытается найти похожее. Но это все равно не позволяет исправлять 100% ошибок, что требует человеческого контроля результатов. Встречающиеся в реальной жизни тексты обычно далеки от совершенства, и процент ошибок распознавания для нечистых текстов часто недопустимо велик.
Грязные изображения здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять определяющие части символа или преобразовывать один в другой. Еще одной проблемой является неаккуратное сканирование, связанное с человеческим фактором, так как оператор, сидящий за сканером, просто не в состоянии разглаживать каждую сканируемую страницу и точно выравнивать ее по краям сканера.
Программное обеспечение OCR обычно работает с большим растровым изображением страницы из сканера. Изображения со стандартной степенью разрешения получаются сканированием с точностью 9600 пикселей на дюйм. Изображение листа формата A4 при этом разрешении занимает около 1МБ памяти.
Основное назначение OCR-систем состоит в анализе растровой информации (отсканированного символа) и присвоении фрагменту изображения соответствующего символа. После завершения процесса распознавания OCR-системы должны уметь сохранять форматирование исходных документов, присваивать в нужном месте атрибут абзаца, сохранять таблицы, графику ит. д. Современные программы распознавания поддерживают все известные текстовые и графические форматы и форматы электронных таблиц, а некоторые поддерживают такие форматы, как HTML и PDF.
На данный момент существует огромное количество программ, поддерживающих распознавание текста как одну из возможностей. . Начнем обзор с лидера в этой области FineReader. Новая технология Intelligent Background Filtering (интеллектуальной фильтрации фона) позволяет отсеять информацию о текстуре документа и фоновом шуме изображения: иногда для выделения текста в документе используется серый или цветной фон.
ABBYY FormReader еще одна распознавалка от ABBYY. Эта программа предназначена для распознавания и обработки форм, которые могут быть заполнены вручную.
OCR CuneiForm выгодно отличается уровнем распознавания, особенно текстов низкого качества; удобным интерфейсом с наличием встроенных мастеров помощников в работе; встроенным текстовым редактором, не уступающим по своей функциональности популярным текстовым процессорам, и многими другими возможностями. способна распознавать любые полиграфические и машинописные гарнитуры всех начертаний и шрифтов, получаемые с принтеров, за исключением декоративных и рукописных. Также программа способна распознавать таблицы различной структуры, в том числе и без линий и границ; редактировать и сохранять результаты в распространенных табличных форматах.
Существенно облегчает работу и возможность прямого экспорта результатов в MS Word и MS Excel (для этого теперь не нужно сохранять результат в файл RTF, а затем открывать его с помощью MS Word). Также программа снабжена возможностями массового ввода возможностью пакетного сканирования, включая круглосуточное, сканирования с удаленных компьютеров локальной сети и организации распределенного параллельного сканирования в локальной сети.
Readiris Pro7 профессиональная программа распознавания текста. отличается от аналогов высочайшей точностью преобразования обычных (каждодневных) печатных документов, таких как письма, факсы, журнальные статьи, газетные вырезки, в объекты, доступные для редактирования (включая файлы PDF). Основными достоинствами программы являются: возможность более или менее точного распознавания картинок, сжатых по максимуму (с максимальной потерей качества) методом JPEG, поддержка цифровых камер и автоопределения ориентации страницы.
OmniPage11 продукт компании ScanSoft. . Разработчики утверждают, что их программа практически со 100% точностью распознает печатные документы, восстанавливая их форматирование, включая столбцы, таблицы, переносы (в том числе переносы частей слов), заголовки, названия глав, подписи, номера страниц, сноски, параграфы, нумерованные списки, красные строки, графики и картинки. Есть возможность сохранения в форматы Microsoft Office, PDF и в 20 других форматов, распознавания из файлов PDF, редактирование прямо в формате PDF.
Система искусственного интеллекта позволяет автоматически обнаруживать и исправлять ошибки после первого исправления вручную. Новый специально разработанный модуль Despeckle позволяет распознавать документы с ухудшенным качеством (факсы, копии, копии копий ит. д.). Преимуществами программы являются возможность распознавания цветного текста и возможность корректировки голосом. Теперь версия OmniPage существует и для компьютеров Macintosh.
Нравится 0
Понравилась работу? Лайкни ее и оставь свой комментарий!
Для автора это очень важно, это стимулирует его на новое творчество!
Посоветуйте статью друзьям!
Случайные работы
Другие работы автора
Параметры подпрограмм
Информационные технологии
Процедуры и функции в pascal
Информационные технологии
Способы адресации
Информационные технологии
Похожие работы
Раздел 3 ФУНКЦИОНАЛЬНЫЕ СТИЛИ СОВРЕМЕННОГО РУССКОГО ЯЗЫКА
Риторика
Статус государственного служащего: права, обязанности, ограничения и запреты.
Политология
Международные правовые акты, международные договоры РФ как источники государственного права.
Политология
Билеты на ГКК для матросов 2 класса.
Иностранные языки
Команды, поданные наруль, рулевой обязан повторить, а вахтенный офицер должен убедиться, что они выполняются немедленно и аккуратно.
Иностранные языки
Источник: lektsia.info
Оптическое распознавание символов (optical character recognition, OCR). Программы для оптического распознавания символов: ABBYY FineReader, CuneiForm
Технология OCR (Optical Character Recognition) может быть использована для преобразования печатной копии документа в электронную версию. Например, если сканируется многостраничный экземпляр в файл TIFF, то его загружают в OCR-программу, которая распознает текст, и далее переводят в редактируемый файл. Некоторые приложения позволяют сканировать страницы и преобразовывать содержимое в документ за один шаг.
Хотя технология изначально была разработана для оптического распознавания печатных символов, она также может использоваться для рукописных. Например, почтовые службы, такие как USPS, используют программное обеспечение OCR для автоматической обработки писем и посылок, считывая адрес.
Области применения OCR
Вам будет интересно: Замена Microsoft Office: альтернативные системы, рейтинг лучших, рекомендации и отзывы

OCR расшифровывается, как Оптическое Распознание Символов. Это широко распространенная технология распознавания текста внутри изображений в виде отсканированных документов и фотографий. Технология используется для преобразования практически любого типа изображений, содержащих письменный, рукописный или напечатанный текст в машиночитаемые текстовые данные.
OCR стала популярной в начале 1990-х годов при попытке оцифровки исторических материалов. С тех пор метод претерпел значительные улучшения, и в настоящее время обеспечивает практически идеальную точность оптического распознавания символов. Расширенные методики, такие как Zonal OCR, используются для автоматизации сложных рабочих процессов на основе преобразования машинописных текстов в цифровые документы. После того как отсканированный материал прошел обработку, текст можно редактировать с помощью программ, таких как Microsoft Word или Google Docs, которые являются текстовыми редакторами.
Вам будет интересно: Lightshot: как пользоваться программой
До того как появилась эта технология, единственным вариантом оцифровки печатных документов был ручной набор текста. Это не только занимало много времени, но и приводило к неточностям и ошибкам при воспроизведении копии. OCR часто используется в качестве «скрытой» технологии во многих известных системах и службах, включающих автоматизацию ввода данных и индексацию для поисковых систем, автоматическое оптическое распознавание символов номерных знаков, а также помощь слепым и слабовидящим людям.
Процесс определения точности текста
Каждый шаг процесса OCR важен для определения точности окончательного текста. Он начинается с преобразования печатного документа. Если на нем есть следы, пятна и плохая контрастность, программное обеспечение при распознавании будет делать ошибки, а результат получится некорректным. Чтобы избежать этих проблем, можно сделать улучшенную ксерокопию печати.
Первый шаг работы — сканирование распечатанного текста. Программное обеспечение OCR работает с файлами изображений. Сканер или хорошая цифровая камера создают четкие фотокопии документов. Лучше преобразовать отсканированные файлы в черно-белом формате. Процесс является двоичным.
С помощью черного цвета на картинке происходит распознавание текста OCR, а белый, в свою очередь, выступает фоном.
Вам будет интересно: Программы для учебы: обзор. Обучающие программы для школьников
Вторым этапом является определение символов. Скорость этого процесса зависит от используемой программы OCR. Большинство из них анализируют каждый элемент один за другим. Целью приложения является определение знаков, но хорошие программы распознают не только текст, но и таблицы, и другие элементы макета.
Процесс не идеален, так как есть много факторов, которые влияют на точность. Какие программы предназначены для оптического распознавания символов, рассмотрим ниже. А пользователю самостоятельно выбирать, что лучше. OCR имеют встроенные средства проверки правописания и выделяют слова с ошибками. Некоторые из них настолько сложны, что отмечают несоответствие слов и грамматические ошибки, пользователю остается лишь выполнить необходимую корректировку.
Последний этап — сохранение готового документа в нужном формате. Если приложение не выдает необходимый, то можно воспользоваться многочисленными бесплатными конвекторами онлайн.
Оптическая технология для Брайля

Технология Optical Character Recognition (OCR) предоставляет слепым или слабовидящим людям возможность определить текст и произносить его вслух. При этом используется речевой вывод, а также отображается информация на дисплее Брайля.
Существует три основных элемента систем оптического распознавания символов: получение изображения, распознавание и чтение текста. Сначала распечатанный документ захватывается камерой, затем программное обеспечение OCR преобразует его в распознанные символы и слова, а после этого синтезатор в системе произносит определенный материал вслух или отображает на дисплее Брайля. Информация может быть сохранена в электронном формате на устройстве, на котором запущено ПО OCR, или в памяти автономного устройства.
Процесс учитывает логическую структуру языка. Система сделает вывод, что, например, союз «этом» в начале предложения является ошибкой и должен читаться, как «это». Она использует лексикон и применяет методы проверки правописания, аналогичные тем, которые используются во многих текстовых редакторах.
Все системы OCR создают временные файлы, содержащие символы и макет страницы. В некоторых системах они могут быть преобразованы в форматы, которые можно найти с помощью широко используемых компьютерных приложений, таких как текстовый редактор, электронная таблица и базы данных.
Выбор программ для распознавания текста

Рекомендуется осознано подойти к выбору программного обеспечения для распознавания текста. Лучше провести собственное тестирование или учесть мнение продвинутых пользователей.
Тестирование проводят с учетом следующих факторов:
Популярное ПО для мобильных устройств
Вам будет интересно: Что такое в «Фотошопе» смарт-объект? Его назначение
OCR отлично подходит для переноса текста из физических источников непосредственно в цифровой документ. Существуют различные типы программ и приложений для настольных и мобильных устройств. Они различны по цене и имеют свои ключевые отличительные функции.
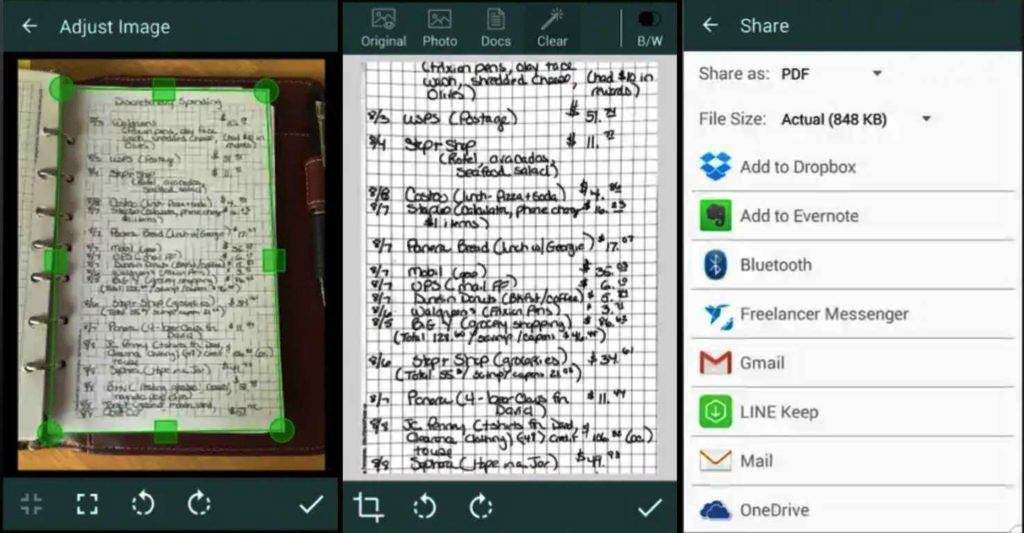
Наиболее популярные «Андроид»-сканеры:
Документы Google

Для тех, кто уже знаком с документами Google, можно использовать OCR, встроенный в Google Drive. Для достижения наилучших результатов шрифт должен быть установлен на Arial или Times New Roman. Можно улучшить результат, убедившись, что сканированное изображение имеет равномерное освещение и четкую контрастность. Фотоматериалы могут обрабатываться индивидуально в файлах: jpg, png, gif или в многостраничных документах PDF. Расширение поддерживает большинство языков.
У Google есть много обучающих программ и возможностей облачной обработки. Многие пользователи считают, что у сервиса нет достаточно продвинутых функций и опций. Тем не менее, если используется приложение Google Drive для Android, можно сканировать страницы прямо из приложения, используя камеру на смартфоне.
В противном случае загружают документы с помощью сканера, подключенного к компьютеру, или любым другим способом, чтобы начать обработку распознавания в Google Диске. Для физических лиц на Google Диске предлагается бесплатный уровень хранения около 19 ГБ с возможностью расширения до 100 ГБ через Google One за 1,99 долл. США.
Оптическое распознавание Abbyy

Abbyy FineReader работает с документами уже давно. Это комплексное решение, как для бизнеса, так и для обычных пользователей. В нем можно получить все необходимые функции для извлечения содержания текстов из сканера с полной читаемостью, аккуратно организованные оцифрованные материалы. Помимо распознавания текстов и преобразования в PDF, Microsoft Office или другие форматы, программа также может сравнивать их, добавлять аннотации и комментарии.
Abbyy FineReader может конвертировать материал в пакетном режиме и обрабатывать множество выходных форматов на 192-х различных языках. Есть сопутствующие мобильные приложения, когда нужно выполнить быстрое сканирование с телефона.
Программное обеспечение не самое современное, но оно простое, функциональное и отлично справляется со своей работой. Утилита имеет прочную репутацию одного из лучших вариантов в области оптического распознавания символов. Можно воспользоваться бесплатной пробной версией. ПО стоит от 199,99 долл. США за стандартную разовую бессрочную лицензию.
Если кому-то покажется это дорогим вариантом, можно воспользоваться хорошей альтернативой ABBYY FineReader — онлайн версией. Она ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но поставляется со всеми другими функциями премиум-версии. Потребуется регистрация, чтобы получить доступ. Она поддерживает очень много форматов входных файлов, и можно выбрать выходные, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Облачный сервис Adobe Acrobat

Adobe Acrobat отвечает всем требованиям и предлагает впечатляющий список возможностей и опций, хотя цена немного круче, чем у конкурентов. Для всех функций оптического распознавания текста выбирают Pro версию Adobe Acrobat. DC означает «Облако документов», и довольно четко интегрируется с облачным решением Adobe, если нужно получить доступ к своим файлам с любого компьютера. Также есть простая и бесшовная интеграция со всем остальными сервисами Adobe, например, таким как Photoshop.
Если пользователь решит оплатить Pro версию Adobe Acrobat DC, он получит все инструменты распознавания текста, возможность добавлять комментарии и отзывы к содержанию, специализированный сервис для сканирования таблиц, возможность быстрого сравнения двух документов вместе. Материалы можно редактировать прямо на экране через несколько секунд после их сканирования.
Знак Adobe гарантирует определенный уровень качества, и пользователи впечатлены интуитивностью и возможностями Adobe Acrobat DC. Подписка на сервис начинается с 12,99 долл. США.
Лучшее бесплатное программное обеспечение
Free OCR to Word — это лучшее бесплатное программное обеспечение для оптического распознавания символов, использующее новейшие механизмы. Tesseract — самый мощный инструмент для данного типа ПО и считается одним из самых точных методов. Программа поддерживает несколько форматов изображений и TIFF нескольких страниц. Этот сервис может быть использован совершенно бесплатно для извлечения текста из предоставленного фотоматериала.
Вам будет интересно: VMware — что это? Описание, установка, применение
Двигатель Tesseract был первоначально разработан Hewlett Packard Labs в 1985-1994 годах. Некоторые изменения были внесены в него в 1996 году. В 1995 году он был включен в тройку лучших механизмов распознавания. Он работает с Windows, Linux и Mac OS X. FreeOCR может обрабатывать изображения, имеющие многоколонный и многоязычный текст. Он обрабатывает форматы PDF и поддерживает устройства TWAIN такие, как сканеры, имеет широко распространенный интерфейс с двойным окном, настройки которого легко понять.
Free OCR to Word может сэкономить много времени без необходимости повторного ввода уже написанного произведения. Программа берет документ, отсканированный объект или изображение и преобразует его в читаемый, редактируемый и точный материал. ПО можно бесплатно загрузить в Word. OCR to Word оптимизирован для работы со всеми типами сканеров и имеет рейтинг точности 98 %, современный интерфейс, который позволяет легко получить доступ ко всем задачам, имеются функции поворота на случай, если фото не помещается на экране правильно. ПО извлекает текст из захваченных снимков с помощью смартфонов или цифровых камер с высокой точностью и качеством.
Распознавание символов в Linux
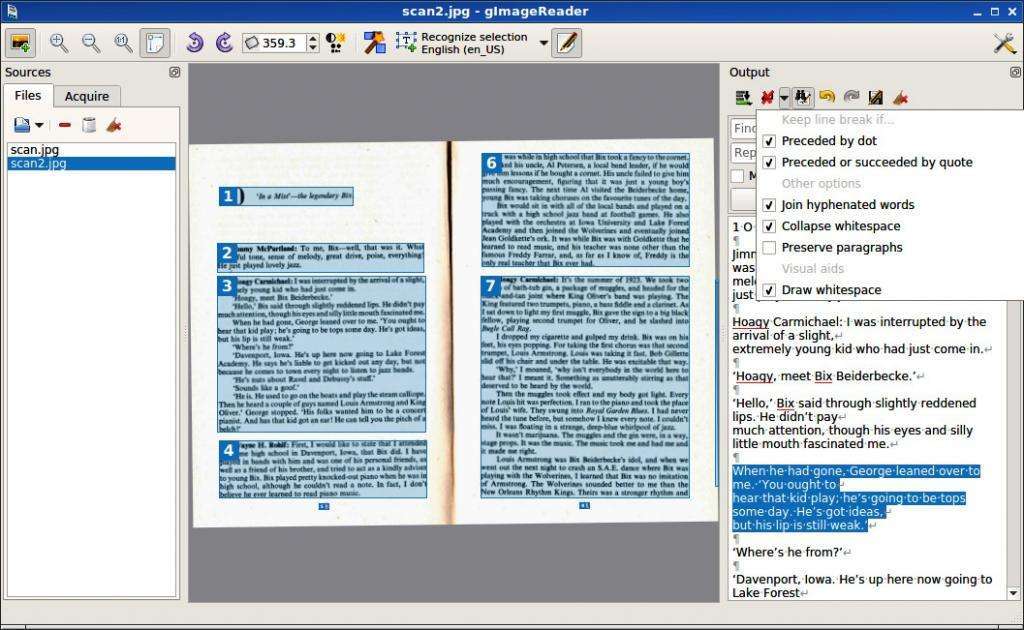
Набор OCRFeeder предоставляет удобный графический интерфейс Linux, который в основном является внешним интерфейсом для некоторых изображений, OCR и текстовых инструментов таких, как распечатка или проверка орфографии. Он не считывает символы сам по себе, но вместо этого использует другие приложения OCR через так называемые настройки «механизмов распознавания». Он имеет предопределенные параметры для Tesseract, CuneiForm, GOCR и Ocrad.
Пользователю нужно только установить в Ubuntu выбранные им движки — один или несколько и затем обнаружить их в настройках Feeder. Можно добавить другие движки и изменить эти параметры вручную. В одном приложении может быть несколько разных движков. Главное окно Feeder позволяет на лету выбрать, какой их них использовать для конкретной области, также есть настройка для выбора одного по умолчанию. Для выбора языка прочитанного текста, в случае с Tesseract и CuneiForm, необходимо добавить переключатель «-l» с соответствующим кодом языка / скрипта, например, «-l pol» для польского или «-l dan-frak» для датского к настройкам данного движка
Технология оптического распознавания печатных символов «Тессеракт» в начале могла распознавать текст только на английском языке, версия 2.x сделала ее многоязычной. При необходимости можно установить более одного словаря. Новые версии оцифровывают текст на основе ISO 963-2.
После успешной установки используют команду «tesseract>путь к изображению>базовое имя выходного файла». Tesseract автоматически придаст выходному документу расширение «.txt», можно указать опцию «-l», за которой следует код языка. Для версий Tesseract более ранних, чем третья, очень важно, чтобы изображение было в формате файла тегового значения и имело расширение «.tif», а не «.tiff». Командная строка должна выглядеть следующим образом:»$ tesseract ~ / input.tif output».
Где «input.tif» — это документ для преобразования, расположенный в домашней папке, а «output» — материал, который Tesseract создаст, как «output.txt». Часто отсканированные тексты хранятся в виде растрового рисунка в большом документе PDF. Используя ImageMagick, отдельные страницы могут быть извлечены в виде файлов TIFF для обработки с Tesseract. Следующий скрипт может помочь автоматизировать этот процесс.
Программа CuneiForm — это еще одна система оптического распознавания текста, которая была первоначально разработана и основана на открытых источниках Cognitive Technologies. Версия Windows, которая имеет собственный графический интерфейс, может быть запущена с некоторыми результатами в Wine. Его порт Linux разрабатывается на Launchpad и хотя в настоящее время у него нет собственного графического интерфейса, CuneiForm может быть успешно запущен из графического интерфейса OCRFeeder.
Ниже приведен пример, как успешно преобразовать некоторые скриншоты изображений .jpeg доски объявлений в Интернете в полезные текстовые файлы.

Технология OCR не стоит на месте, в перспективе признание интеллектуальной системы оптического распознавания символов — ICR. Этот стандарт является передовым. Большая часть ICR имеет самообучающуюся систему, называемую нейронной сетью, которая автоматически обновляет базу данных для новых образцов почерка. Она расширяет полезность сканирующих устройств для целей обработки документов от распознавания печатного текста (функция OCR) до рукописных материалов и могут достигать более 97 % степени точности при чтении рукописного материала в структурированных формах.
Источник: abc-import.ru
Что такое OCR? Зачем нужно оптическое распознавание символов в современном мире мобильных технологий?
Говоря простым языком, OCR (optical character recognition, оптическое распознавание символов) – это процесс перевода текста на изображениях в текстовый формат. Основное применение технологии OCR находят в различных задачах, связанных с оцифровкой данных. Для отдельных подзадач OCR иногда используют названия наподобие “умное распознавание символов” (intelligent character recognition, ICR) или “распознавание визитных карточек” (business card recognition, BCR).

Первые системы оптического распознавания символов появились практически одновременно с первыми компьютерами. В 50-х годах прошлого столетия с помощью коммерческих OCR системы начали обрабатывать отчеты о продажах, набранные на печатной машинке, и переводили их в перфокарты. С тех пор OCR пережил много изменений, главным из которых стала замена применяемых в алгоритмах распознавания разнообразных классификаторов символов искусственными нейронными сетями (ИНС, ANN).
Вызовы современных OCR технологий
Сейчас технологиям распознавания брошен серьезный вызов, когда все чаще речь идет о распознавании изображений с камер мобильных устройств или обычных веб-камер. Это могут фотографии или кадры из видеопотока. Чтобы лучше понять сложность поставленной задачи, давайте начнем с примера. Изображение документа для распознавания можно получить разными способами, и мы выбрали три из них:
1) взяли Canon CanoScan LiDE 300, отсканировали документ с разрешением 300dpi и бинаризовали результат;
2) сфотографировали документ на iPhone 11 при комнатном освещении;
3) сняли видео веб-камерой и взяли из него один кадр.
Как видно на картинке, системы распознавания в наши дни должны быть устойчивы к самым разнообразным условиям съемки. Очевидно, качество изображений может существенно различаться.
| Binarized scan | 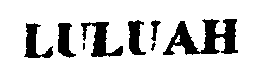 |
| Photo with iPhone 11 | 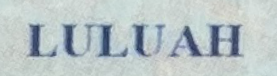 |
| Web camera video frame |  |
Вот так может выглядеть рабочий процесс системы оптического распознавания.

Большинство подходов начинаются с предобработки изображения, которая, как правило, включает бинаризацию изображение для упрощения последующей сегментации на символы. Алгоритм сегментации делит изображение строки на изображения отдельных символов, которые подаются классификатору. Иногда, для улучшения качества распознавания к результату классификации могут применяться алгоритмы постобработки.
В случае mobile optical character recognition или мобильного OCR (на Android, iOS или иных системах), или же распознавания на мобильном устройстве, возникают две трудности: ограничения на вычислительные мощности и неконтролируемые условия съемки. При работе с персональными документами, банковскими бумагами или, например, результатами теста на COVID-19 важно обеспечить максимум конфиденциальности и минимизировать риск утечки данных, так что распознавание “в облаке” сразу отпадает.
Распознавание непосредственно на устройстве накладывает ограничения на вычислительную сложность алгоритмов, ведь система должна работать быстро и энергоэффективно. С другой стороны, меньшие ограничения на условия съемки значительно расширяют диапазон возможных искажений. Появляются проективные искажения, смазывание, перепады яркости, блики и многое другое. Все это существенно влияет на этап предобработки.
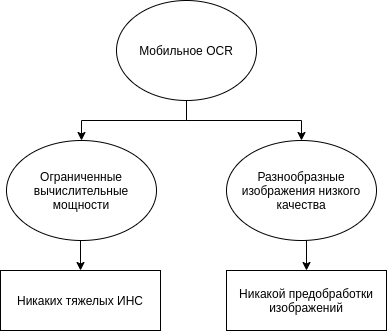
В результате при мобильном распознавании, с одной стороны, возникает множество ошибок у стандартных подходов к сегментации, а с другой – из-за ограничения на вычислительные ресурсы многие современные нейросетевые модели, например, рекуррентные сети (RNN) или LSTM-сети становятся неэффективными или же излишне ресурсозатратными. Таким образом, для успешного распознавания изображений, снятых на камеры мобильных устройств (работающих на Android или iOS), необходимо придумывать абсолютно новые алгоритмы и переосмысливать уже известные подходы.
Примером переосмысления старых подходов можно считать замену алгоритмов сегментации, основанных на обработке изображений, на сегментирующие нейронные сети, как это уже когда-то произошло с классификаторами. Наиболее многообещающей моделью для такие подходов представляется полносверточная сеть (fully convolutional network, FCN).

Замена отдельного изображения на видеопоток приводит к появлению концепции 4D OCR и новым возможностям распознавания, прежде всего, к алгоритмам межкадровой интеграции результатов распознавания. Более того, при обработке видео можно рассматривать процесс распознавания как anytime алгоритм, готовый в любой момент дать ответ. Выбор оптимального числа кадров можно осуществлять, решая задачу останова.
В каких процессах применяются системы оптического распознавания (OCR)
Давайте приведем несколько примеров. Все ниже перечисленные процессы можно улучшить и ускорить с помощью OCR системы.
Платежи и переводы могут стать гораздо быстрее с добавлением распознавания банковской карты . Замена ручного ввода данных на сканирование QR, AZTEC, PDF 417 или другого типа штрихкода вместе с распознаванием карты поможет избежать раздражающих ошибок во введенных данных и улучшить впечатление конечного пользователя от банковского приложения, онлайн-магазина или даже оффлайн магазина.
При продаже билетов и регистрации на рейс пассажирам требуется вводить свои личные данные. Автоматическое сканирование МЧЗ (машиночитаемой зоны) или паспорта позволит сделать эти процессы более удобными для пользователей и минимизировать число ошибок в данных.
Удаленная идентификация клиента – популярная и крайне важная опция для многих задач, включая проверку возраста, онлайн-регистрацию, активацию сим-карты, бронирование номеров в отелях и предварительную запись на медицинские услуги. С ее помощью можно упростить жизнь пользователю, а также оптимизировать работу персонала и в результате избежать очередей в офисах, магазинах, фойе отелей и других местах скопления людей.
Отдельно стоит выделить банковские услуги, где применение OCR для распознавания документов и удостоверений личности является must-have функцией. В этой сфере любые ошибки в данных приводят к проблемам для клиентов, оставляя у них плохое впечатление от банка и влияя на решение о дальнейшем обслуживании. Встроенное распознавание ID карт, паспортов, водительских прав и других документов ускоряет процесс открытия счета новым клиентам, упрощает аутентификацию текущих клиентов и предоставляет возможности развития кросс-продаж.
А что об общедоступных OCR решениях?
В наше время существует много общедоступных open-source распознавателей текста. Такие решения могут быть очень полезны в образовательных целях или для учебного демонстрационного приложения. Однако они могут быть не просто бесполезны, а опасны для настоящих “боевых” коммерческих систем. При этом, их существенным недостатком окажется не только точность и скорость распознавания, но и уязвимость для внешних атак.
Атаки на нейронные сети – это популярная тема для научных исследований. Главные типы атак – отравление данных и атака уклонением с помощью состязательных примеров. При отравлении данных ошибки вводятся в сеть на этапе обучения. А при применении сети распознаватель может совершить специфические серьезные ошибки.
Единственный способ избежать такой атаки – быть уверенными в своих данных. А как можно быть уверенным в данных, которых вы никогда не видели? При атаке уклонением злоумышленник пытается заставить сеть дать неверный ответ. Иногда он даже может предопределить этот ответ.
Для открытых систем оптического распознавания текста и символов (OCR) такие примеры можно посчитать, так как эти системы общедоступны. Можно просто скачать модель и подобрать нужные примеры.
Теперь чуть больше об OCR сервисах Smart Engines
В Smart Engines мы разрабатываем OCR решения, которые могут работать с изображениям, фотографиями, сканами или видеопотоком в реальном времени. Условия съемки могут быть самыми разными – не нужно специально фокусировать камеру или же искать хорошо освещенное место. Наше ПО работает автономно на конечном устройстве, никуда не передает данные клиента, не хранит их и не требует интернет-соединения. При разработке нашего OCR модуля мы активно пользуемся генерацией искусственных данных и не используем предобученные модели. Таким образом, наше решение оказывается гораздо более устойчивым для внешних атак.
Программные продукты Smart Engines, в которых мы применяем собственные технологии OCR
– Smart ID Engine – SDK для сканирования более чем 2427 типов удостоверяющих личность документов со всего мира, напечатанных с использованием латиницы, кириллицы, арабицы и других письменностей;
– Smart Code Engine – решение для распознавания банковских карт, одномерных и двумерных штрихкодов, МЧЗ и других кодированных объектов;
– Smart Document Engine – система автоматического анализа и распознавания деловых документов, форм и анкет.
– Сканеры Smart Engines – программно-аппаратные комплексы для распознавания и проверки подлинности паспортов и дргуих удостоверений личности
Как работают наши OCR технологии в мобильных приложениях Android и iOS
Чтобы бесплатно попробовать наши продукты в действии, вы можете скачать демо приложение из App Store или Google Play.
Если же вы хотите узнать больше о научных разработках, стоящих за нашими продуктами, можете почитать разделы Наука и Блог на нашем сайте, наш блог на хабре или просто поискать нас в Google Scholar.
Источник: smartengines.ru