
Простое руководство по дистилляции BERT
Если вы интересуетесь машинным обучением, то наверняка слышали про BERT и трансформеры.
BERT — это языковая модель от Google, показавшая state-of-the-art результаты с большим отрывом на целом ряде задач. BERT, и вообще трансформеры, стали совершенно новым шагом развития алгоритмов обработки естественного языка (NLP). Статью о них и «турнирную таблицу» по разным бенчмаркам можно найти на сайте Papers With Code.
С BERT есть одна проблема: её проблематично использовать в промышленных системах. BERT-base содержит 110М параметров, BERT-large — 340М. Из-за такого большого числа параметров эту модель сложно загружать на устройства с ограниченными ресурсами, например мобильные телефоны. К тому же, большое время инференса делает эту модель непригодной там, где скорость ответа критична. Поэтому поиск путей ускорения BERT является очень горячей темой.
Нам в Авито часто приходится решать задачи текстовой классификации. Это типичная задача прикладного машинного обучения, которая хорошо изучена. Но всегда есть соблазн попробовать что-то новое. Эта статья родилась из попытки применить BERT в повседневных задачах машинного обучения. В ней я покажу, как можно значительно улучшить качество существующей модели с помощью BERT, не добавляя новых данных и не усложняя модель.
Что такое дистилляция?

Knowledge distillation как метод ускорения нейронных сетей
Существует несколько способов ускорения/облегчения нейронных сетей. Самый подробный их обзор, который я встречал, опубликован в блоге Intento на Медиуме.
Способы можно грубо разделить на три группы:
- Изменение архитектуры сети.
- Сжатие модели (quantization, pruning).
- Knowledge distillation.
Если первые два способа сравнительно известны и понятны, то третий менее распространён. Впервые идею дистилляции предложил Рич Каруана в статье “Model Compression”. Её суть проста: можно обучить легковесную модель, которая будет имитировать поведение модели-учителя или даже ансамбля моделей. В нашем случае учителем будет BERT, учеником — любая легкая модель.
Задача
Давайте разберём дистилляцию на примере бинарной классификации. Возьмём открытый датасет SST-2 из стандартного набора задач, на которых тестируют модели для NLP.
Этот датасет представляет собой набор обзоров фильмов с IMDb с разбивкой на эмоциональный окрас — позитивный или негативный. В качестве метрики на этом датасете используют accuracy.
Обучение BERT-based модели или «учителя»
Прежде всего необходимо обучить «большую» BERT-based модель, которая станет учителем. Самый простой способ это сделать — взять эмбеддинги из BERT и обучить классификатор поверх них, добавив один слой в сеть.
Благодаря библиотеке tranformers сделать это довольно легко, потому что там есть готовый класс модели BertForSequenceClassification. На мой взгляд, самое подробное и понятное руководство по обучению этой модели опубликовал Thilina Rajapakse на Towards Data Science.
Теория алкоголя. Часть №2. Дистилляция. Mr.Tolmach на русском
Давайте представим, что мы получили обученную модель BertForSequenceClassification. В нашем случае num_labels=2, так как у нас бинарная классификация. Эту модель мы будем использовать в качестве «учителя».
Обучение «ученика»
В качестве ученика можно взять любую архитектуру: нейронную сеть, линейную модель, дерево решений. Давайте для большей наглядности попробуем обучить BiLSTM. Для начала обучим BiLSTM без BERT.
Чтобы подавать на вход нейронной сети текст, нужно представить его в виде вектора. Один из самых простых способов — это сопоставить каждому слову его индекс в словаре. Словарь будет состоять из топ-n самых популярных слов в нашем датасете плюс два служебных слова: “pad” — «слово-пустышка», чтобы все последовательности были одной длины, и “unk” — для слов за пределами словаря. Построим словарь с помощью стандартного набора инструментов из torchtext. Для простоты я не стал использовать предобученные эмбеддинги слов.
import torch from torchtext import data def get_vocab(X): X_split = [t.split() for t in X] text_field = data.Field() text_field.build_vocab(X_split, max_size=10000) return text_field def pad(seq, max_len): if len(seq) < max_len: seq = seq + [»] * (max_len — len(seq)) return seq[0:max_len] def to_indexes(vocab, words): return [vocab.stoi[w] for w in words] def to_dataset(x, y, y_real): torch_x = torch.tensor(x, dtype=torch.long) torch_y = torch.tensor(y, dtype=torch.float) torch_real_y = torch.tensor(y_real, dtype=torch.long) return TensorDataset(torch_x, torch_y, torch_real_y)
Модель BiLSTM
Код для модели будет выглядеть так:
Обучение
Для этой модели размерность выходного вектора будет (batch_size, output_dim). При обучении будем использовать обычный logloss. В PyTorch есть класс BCEWithLogitsLoss, который комбинирует сигмоиду и кросс-энтропию. То, что надо.
def loss(self, output, bert_prob, real_label): criterion = torch.nn.BCEWithLogitsLoss() return criterion(output, real_label.float())
Код для одной эпохи обучения:
def get_optimizer(model): optimizer = torch.optim.Adam(model.parameters()) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma=0.9) return optimizer, scheduler def epoch_train_func(model, dataset, loss_func, batch_size): train_loss = 0 train_sampler = RandomSampler(dataset) data_loader = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, drop_last=True) model.train() optimizer, scheduler = get_optimizer(model) for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc=’Train’)): text, bert_prob, real_label = to_device(text, bert_prob, real_label) model.zero_grad() output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) loss.backward() optimizer.step() train_loss += loss.item() scheduler.step() return train_loss / len(data_loader)
Код для проверки после эпохи:
def epoch_evaluate_func(model, eval_dataset, loss_func, batch_size): eval_sampler = SequentialSampler(eval_dataset) data_loader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size, drop_last=True) eval_loss = 0.0 model.eval() for i, (text, bert_prob, real_label) in enumerate(tqdm(data_loader, desc=’Val’)): text, bert_prob, real_label = to_device(text, bert_prob, real_label) output = model(text.t(), None).squeeze(1) loss = loss_func(output, bert_prob, real_label) eval_loss += loss.item() return eval_loss / len(data_loader)
Если это всё собрать воедино, то получится такой код для обучения модели:
import os import torch from torch.utils.data import (TensorDataset, random_split, RandomSampler, DataLoader, SequentialSampler) from torchtext import data from tqdm import tqdm def device(): return torch.device(«cuda» if torch.cuda.is_available() else «cpu») def to_device(text, bert_prob, real_label): text = text.to(device()) bert_prob = bert_prob.to(device()) real_label = real_label.to(device()) return text, bert_prob, real_label class LSTMBaseline(object): vocab_name = ‘text_vocab.pt’ weights_name = ‘simple_lstm.pt’ def __init__(self, settings): self.settings = settings self.criterion = torch.nn.BCEWithLogitsLoss().to(device()) def loss(self, output, bert_prob, real_label): return self.criterion(output, real_label.float()) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=1, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings[‘train_batch_size’]) return model def train(self, X, y, y_real, output_dir): max_len = self.settings[‘max_seq_length’] text_field = get_vocab(X) X_split = [t.split() for t in X] X_pad = [pad(s, max_len) for s in tqdm(X_split, desc=’pad’)] X_index = [to_indexes(text_field.vocab, s) for s in tqdm(X_pad, desc=’to index’)] dataset = to_dataset(X_index, y, y_real) val_len = int(len(dataset) * 0.1) train_dataset, val_dataset = random_split(dataset, (len(dataset) — val_len, val_len)) model = self.model(text_field) model.to(device()) self.full_train(model, train_dataset, val_dataset, output_dir) torch.save(text_field, os.path.join(output_dir, self.vocab_name)) def full_train(self, model, train_dataset, val_dataset, output_dir): train_settings = self.settings num_train_epochs = train_settings[‘num_train_epochs’] best_eval_loss = 100000 for epoch in range(num_train_epochs): train_loss = epoch_train_func(model, train_dataset, self.loss, self.settings[‘train_batch_size’]) eval_loss = epoch_evaluate_func(model, val_dataset, self.loss, self.settings[‘eval_batch_size’]) if eval_loss < best_eval_loss: best_eval_loss = eval_loss torch.save(model.state_dict(), os.path.join(output_dir, self.weights_name))
Дистилляция
Идея этого способа дистилляции взята из статьи исследователей из Университета Ватерлоо. Как я говорил выше, «ученик» должен научиться имитировать поведение «учителя». Что именно является поведением? В нашем случае это предсказания модели-учителя на обучающей выборке. Причём ключевая идея — использовать выход сети до применения функции активации.
Предполагается, что так модель сможет лучше выучить внутреннее представление, чем в случае с финальными вероятностями.
В оригинальной статье предлагается в функцию потерь добавить слагаемое, которое будет отвечать за ошибку «подражания» — MSE между логитами моделей.

Для этих целей сделаем два небольших изменения: изменим количество выходов сети с 1 до 2 и поправим функцию потерь.
def loss(self, output, bert_prob, real_label): a = 0.5 criterion_mse = torch.nn.MSELoss() criterion_ce = torch.nn.CrossEntropyLoss() return a*criterion_ce(output, real_label) + (1-a)*criterion_mse(output, bert_prob)
Можно переиспользовать весь код, который мы написали, переопределив только модель и loss:
class LSTMDistilled(LSTMBaseline): vocab_name = ‘distil_text_vocab.pt’ weights_name = ‘distil_lstm.pt’ def __init__(self, settings): super(LSTMDistilled, self).__init__(settings) self.criterion_mse = torch.nn.MSELoss() self.criterion_ce = torch.nn.CrossEntropyLoss() self.a = 0.5 def loss(self, output, bert_prob, real_label): return self.a * self.criterion_ce(output, real_label) + (1 — self.a) * self.criterion_mse(output, bert_prob) def model(self, text_field): model = SimpleLSTM( input_dim=len(text_field.vocab), embedding_dim=64, hidden_dim=128, output_dim=2, n_layers=1, bidirectional=True, dropout=0.5, batch_size=self.settings[‘train_batch_size’]) return model
Вот и всё, теперь наша модель учится «подражать».
Сравнение моделей
В оригинальной статье наилучшие результаты классификации на SST-2 получаются при a=0, когда модель учится только подражать, не учитывая реальные лейблы. Accuracy всё ещё меньше, чем у BERT, но значительно лучше обычной BiLSTM.

Я старался повторить результаты из статьи, но в моих экспериментах лучший результат получался при a=0,5.
Так выглядят графики loss и accuracy при обучении LSTM обычным способом. Судя по поведению loss, модель быстро обучилась, а где-то после шестой эпохи пошло переобучение.
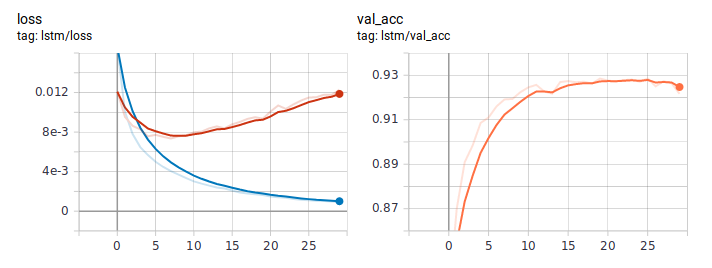
Графики при дистилляции:
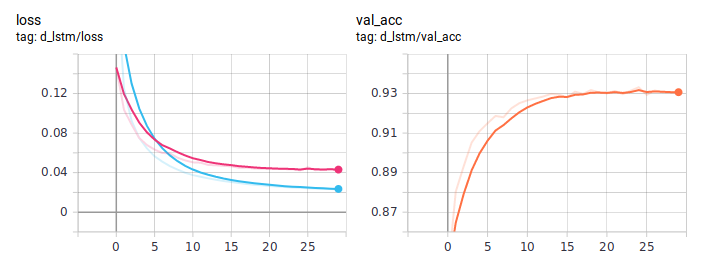
Дистиллированная BiLSTM стабильно лучше обычной. Важно, что по архитектуре они абсолютно идентичны, разница только в способе обучения. Полный код обучения я выложил на ГитХаб.
Заключение
В этом руководстве я постарался объяснить базовую идею подхода дистилляции. Конкретная архитектура ученика будет зависеть от решаемой задачи. Но в целом этот подход применим в любой практической задаче. За счёт усложнения на этапе обучения модели, можно получить значительный прирост её качества, сохранив изначальную простоту архитектуры.
- neural networks
- deep learning
- bert
- nlp (natural language processing)
- машинное обучение
- Блог компании AvitoTech
- Python
- Машинное обучение
- Natural Language Processing
Источник: habr.com
Дистилляция знаний

Наша главная цель — подготовить модель, которая может дать хорошие результаты на тестовом наборе данных. Для этого мы обучаем громоздкую модель, которая может представлять собой множество различных обученных моделей или просто очень большую модель, обученную с помощью регуляризатора, такого каквыбывать, Когда-то громоздкая модель(Учитель)готов мы используем технику под названиемдистилляцияперенести сложное знание, усвоенное громоздкой моделью, на маленькую модель(ученик)это больше подходит для развертывания в устройствах с ограниченным объемом памяти и большими вычислительными возможностями.
Под комплексным знанием я подразумеваю то, что громоздкая модель может различать большое количество классов. При этом он присваивает вероятности всем неправильным классам. Однако эти вероятности очень малы, они многое говорят о том, как обобщается громоздкая модель. Например, изображение собаки с меньшей вероятностью будет принято за кошку, но эта ошибка все еще во много раз больше, чем за голубя.
Громоздкая модель должна хорошо обобщать, поэтому, когда мы переносим знания на меньшую модель, она должна иметь возможность обобщать так же, как и большая модель. Например, если большая модель представляет собой совокупность множества различных моделей, то небольшая модель, изученная с использованием знаний дистилляции, сможет лучше обобщать тестовые наборы данных по сравнению с небольшой моделью, которая обучается обычным образом на том же тренировочном наборе, что и был использован для обучения ансамбля.
Очевидный способ перенести обобщающую способность громоздкой модели на маленькую модель состоит в использовании вероятностей классов.(генерируется с помощью техники, называемой перегонкой)производится громоздкой моделью как «мягкие цели» для обучения маленькой модели. Для этапа передачи мы можем использовать тот же тренировочный набор или отдельный набор(состоят исключительно из немаркированных данных),

Для мягкой цели мы можем взять среднее геометрическое значение всех отдельных предсказательных распределений. Когда мягкая цель имеет высокую энтропию (вы можете прочитать больше об энтропии Вот), они предоставляют гораздо больше информации по каждому обучающему случаю, чем жесткие цели, и гораздо меньшую разницу в градиенте между обучающими случаями, поэтому небольшая модель часто может быть обучена на гораздо меньшем количестве данных, чем исходная громоздкая модель, и использует гораздо более высокую скорость обучения.
дистилляция
Дистилляция — это общее решение для получения вероятностных распределений мягких целей. В этом мы создаем вероятности класса, используя функцию активации softmax, которая преобразует логитыz_iрассчитывается для каждого класса в вероятности,q_i:

Здесь T — это температура, которая обычно устанавливается на 1. Использование более высокого распределения вероятности приводит к более мягкому распределению вероятности.
z_i — это логиты, вычисленные для каждого класса для каждой точки данных в наборе данных.
В простейшем варианте дистилляции знания переносятся в маленькую модель путем обучения громоздкой модели на передаточном наборе и использования мягкого целевого распределения для каждого случая в передаточном наборе, созданного высокой температурой в его функции softmax Такая же высокая температура используется при обучении маленькой или дистиллированной модели, но после того, как она была обучена, температура устанавливается на 1.
Эта техника может быть значительно улучшена, если у нас есть правильные метки для набора передачи. Один из способов сделать это — взять средневзвешенное значение двух целевых функций. Первой целевой функцией является кросс-энтропия с мягкими мишенями, и эта кросс-энтропия вычисляется с использованием той же высокой температуры в softmax дистиллированной модели, которая использовалась для генерации мягких мишеней из громоздкой модели. Вторая целевая функция — это кросс-энтропия с правильными метками. Это вычисляется с использованием точно таких же логарифмов в softmax дистиллированной модели, но при температуре 1. Сохранение веса второй целевой функции значительно маленьким дает лучшие результаты.
Поскольку величины градиентов, создаваемых мягкими целями, масштабируются как 1 / T², важно умножить их на T² при использовании как твердых, так и мягких целей. Это гарантирует, что относительные вклады твердых и мягких мишеней остаются примерно неизменными, если температура, используемая для дистилляции, изменяется при экспериментировании с мета-параметрами.
Запуск через пример

В этом примере мы будем рассматривать, что мы работаем над очень сложным набором данных(ИКС)и получить хорошую точность на нем с помощью мелкой сети(может быть развернуто на мобильных устройствах)почти невозможно, с традиционными методами построения моделей. Поэтому, чтобы получить хорошую точность, мы будем использовать метод дистилляции знаний:
- Во-первых, мы будем обучать набор данных X в центре обработки данных, используя большую модель(Учитель), который может разбить сложность набора данных X для получения хорошей точности.
- Теперь мы будем использовать оригинальный набор данных X или набор передачи(уменьшенная версия набора данных X)создать мягкие цели из большой модели, а затем использовать их, чтобы получить распределения вероятностей для каждого случая в наборе данных с использованием метода дистилляции.
- Следующий шаг — построить мелкую сеть.(ученик)на основе памяти и вычислительных ограничений мобильного устройства.
- Эта мелкая сеть будет обучаться на распределениях вероятностей, полученных на втором этапе, и обобщать их.
- Как только эта модель обучена, она готова к развертыванию на мобильных устройствах.
Чтобы оценить, насколько хороши результаты дистиллированной модели, мы посмотрим на числа, которые авторы статьи Дистилляция знаний в нейронной сети были в состоянии достичь на наборе данных MNIST, используя перегонку знаний.
Полученные результаты
Чтобы увидеть, насколько хорошо работает дистилляция, набор данных MNIST был обучен с использованием очень большой нейронной сети.(Учитель)состоящий из 2 скрытых слоев, каждый из которых имеет 1200 выпрямленных линейных скрытых единиц. Следующая модель обучила более 60 000 учебных случаев. Сеть достигла 67 тестовых ошибок, тогда как меньшая сеть(ученик)с двумя скрытыми единицами, каждая из которых имеет 800 исправленных скрытых единиц, 146 ошибок теста.
Но если меньшая сеть была упорядочена исключительно путем добавления дополнительной задачи по сопоставлению мягких целей, создаваемых большой сетью при температуре 20, она достигла 74 ошибок тестирования. Это показывает, что мягкие цели могут передавать большой объем знаний в дистиллированную модель, в том числе знания о том, как обобщать это на основе переведенных обучающих данных, даже если набор передачи не содержит никаких переводов.
Если вы хотите сравнить результаты с другими наборами данных, вы можете проверить оригинал бумага за дополнительной информацией.
Вывод
- Возможность простых моделей не в полной мере используется при жестком обучении: совершенствуется путем дистилляции знаний.
- Мягкие метки легче сопоставить, поскольку более богатые и плавные знания доступны.
- Основы дистилляции знаний в основном сосредоточены на точности и коэффициентах сжатия, но игнорируют надежность сети изученных студентов, что существенно для практического использования.
- Модель студента может использоваться во встроенных устройствах, дающих сопоставимые результаты, а в некоторых случаях ее можно даже сделать способной воспроизводить результаты сложной сети.
Чтобы получить более глубокое представление о дистилляции знаний, я бы порекомендовал вам прочитать оригинальную статью: Перегонка знаний в нейронной сети,
Если вам нравится этот пост и вы хотите оставаться на связи, вы можете найти меня на LinkedIn Вот,
Источник: machinelearningmastery.ru
Что такое дистилляция, где применяется, описание процесса
Что такое дистилляция? Это процесс, заключающийся в превращении жидкости в пар, который затем снова конденсируется в жидкую форму. Простейшим примером может служить дистилляция воды, когда пар из чайника осаждается в виде капель на холодной поверхности.
Применение и история
Дистилляция используется для отделения жидкостей от нелетучих твердых веществ, как при перегонке спиртных напитков из сброженных материалов, или для разделения двух или более жидкостей с различной температурой кипения, как при производстве бензина, керосина и смазочных масел из нефти. Другие промышленные применения включают переработку таких химических продуктов, как формальдегид и фенол, опреснение морской воды.
Процесс дистилляции, вероятно, использовался еще древними экспериментаторами. Аристотель (384-322 гг. до н. э.) упоминал, что чистую воду можно получить путем испарения морской. Плиний Старший (23-79 гг. н. э.) описал примитивный способ конденсации, при котором масло, получаемое путем нагревания канифоли, собирается на шерсти, помещенной в верхней части перегонного куба.
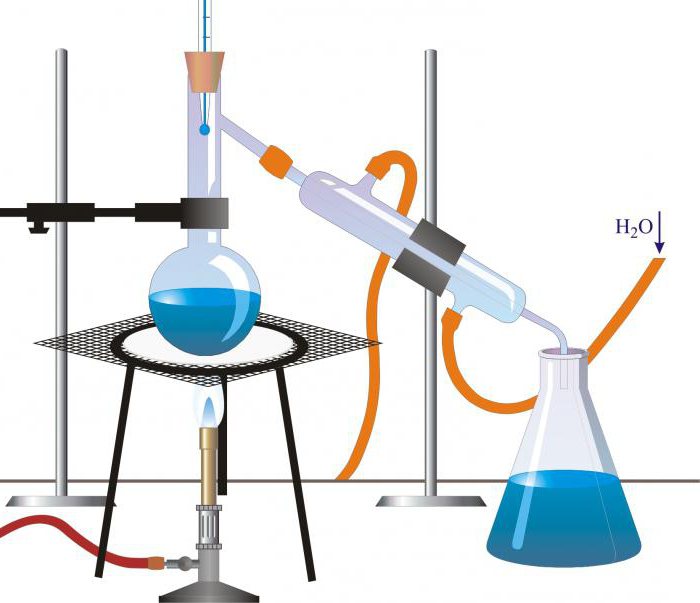
Простая дистилляция
Большинство методов дистилляции, применяемых в промышленности и лабораторных исследованиях, являются вариациями простой перегонки. В этой базовой технологии используется куб или реторта, в которых жидкость нагревается, конденсатор для охлаждения пара и емкость для сбора дистиллята.
При нагреве смеси веществ в первую очередь перегоняется наиболее летучее из них или то, у которого температура кипения минимальна, а затем дистиллируются другие, или не дистиллируются совсем. Такой простой аппарат прекрасно подходит для очистки жидкости, содержащей нелетучие компоненты, и достаточно эффективен для разделения веществ с разной точкой кипения. Для лабораторного использования части аппарата обычно делают из стекла и соединяют их пробками, резиновыми шлангами или стеклянными трубками. В промышленных масштабах оборудование делают из металла или керамики.

Фракционная дистилляция
Метод, называемый фракционной, или дифференциальной, дистилляцией, был разработан для нефтепереработки, потому что простая перегонка для разделения жидкостей, температура кипения которых мало отличается, неэффективна. При этом пары многократно конденсируются и испаряются в изолированной вертикальной емкости. Особую роль здесь играют сухопарники, фракционные колонны и конденсаторы, позволяющие вернуть некоторую часть конденсата назад в куб. Цель состоит в том, чтобы добиться тесного контакта между поднимающимися разными фазами смеси, чтобы только самые летучие фракции в форме пара достигали приемника, а остальное возвращалось в виде жидкости в сторону куба. Очищение летучих компонентов в результате контакта между такими противотоками называется ректификацией, или обогащением.
Многократная дистилляция
Данный метод еще называют многостадийным мгновенным испарением. Это еще один вид простой перегонки. С его помощью производится, например, дистилляция воды на крупных коммерческих опреснительных установках. Преобразование жидкости в пар не требует нагрева. Она просто попадает из емкости с высоким атмосферным давлением в емкость с более низким.
Это приводит к быстрому испарению, сопровождающемуся конденсацией пара в жидкость.

Вакуумная перегонка
В одной из разновидностей процесса с пониженным давлением для создания вакуума используется вакуумный насос. Этот метод, называемый «вакуумная дистилляция», иногда применяется при работе с веществами, которые обычно кипят при высоких температурах или разлагаются при кипении в нормальных условиях.
Вакуумные насосы создают в колонне давление, которое значительно ниже атмосферного. В дополнение к ним используются вакуумные регуляторы. Тщательный контроль параметров очень важен, поскольку эффективность разделения зависит от различия в относительной летучести при данной температуре и давлении. Изменение этого параметра может негативно повлиять на ход процесса.
Что такое дистилляция в вакууме, хорошо знают на нефтеперерабатывающих заводах. Обычные методы перегонки отделяют легкие углеводороды и примеси от тяжелых углеводородов. Остаточный продукт подвергают вакуумной дистилляции. Это позволяет отделить высококипящие углеводороды, такие как масла и воски, при невысоких температурах. Метод также применяется при разделении чувствительных к нагреву органических химических соединений и для восстановления органических растворителей.
Что такое дистилляция паром?
Паровая перегонка является альтернативным методом перегонки при температурах ниже нормальной точки кипения. Она применяется, когда дистиллируемое вещество не смешивается и химически не реагирует с водой. Примерами таких материалов являются жирные кислоты и соевое масло. В ходе перегонки в жидкость подается пар, который нагревает ее и вызывает испарение.
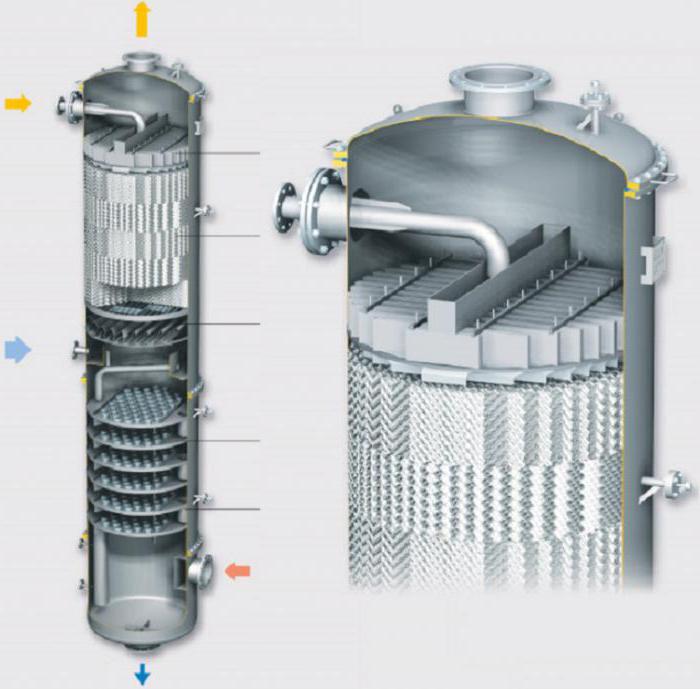
Дистилляция в насадочной колонне
Хотя насадочные колонны чаще всего применяются для абсорбции, они также используются для перегонки парожидкостных смесей. Такая конструкция обеспечивает большую площадь контактной поверхности, что повышает эффективность системы. Другое название такой конструкции – ректификационная колонна.
Принцип работы заключается в следующем. Сырьевая смесь компонентов с разной волатильностью подается в центр колонны. Жидкость стекает вниз через насадку, а пар движется вверх. Смесь в нижней части резервуара попадает в подогреватель и выходит из него вместе с паром.
Газ устремляется вверх через насадку, подхватывая наиболее летучие компоненты жидкости, выходит из колонны и попадает в конденсатор. После сжижения продукт поступает в сборник флегмы, где он разделяется на дистиллят и фракцию, используемую для орошения.
Различная концентрация приводит к тому, что менее летучие компоненты переходят из паровой фазы в жидкую. Насадка увеличивает продолжительность и площадь контакта, что повышает эффективность разделения. На выходе пар содержит максимальное количество летучих компонентов, в то время как в жидкости их концентрация минимальна.

Насадки заполняются в навал и пакетами. Форма наполнителя может быть либо случайной, либо геометрически структурированной. Его делают из инертного материала, такого как глина, фарфор, пластик, керамика, металл или графит. Наполнитель, как правило, имеет размеры от 3 до 75 мм и отличается большой площадью поверхности, контактирующей с парожидкостной смесью. Преимущество заполнения в навал заключается в большой пропускной способности, стойкости к большим давлениям и низкой стоимости.
Металлические наполнители имеют высокую прочность и хорошую смачиваемость. Керамические обладают еще более высокой смачиваемостью, но они не такие прочные. Пластиковые достаточно прочны, но плохо смачиваются при низкой скорости потока. Поскольку керамические наполнители устойчивы к коррозии, они используются при повышенных температурах, которые пластик не выдерживает.
Пакетные насадки представляют собой структурированную сетку, размеры которой соответствуют диаметру колонны. Обеспечивают наличие длинных каналов для потоков жидкости и пара. Они дороже, но позволяют снизить перепады давления. Пакетным насадкам отдается предпочтение при невысокой скорости потока и в условиях низкого давления. Обычно их делают из древесины, листового металла или тканой сетки.
Применяются для восстановления растворителей и в нефтехимической промышленности.
Дистилляция в ректификационной колонне
Наиболее широкое распространение получили колонны тарельчатого типа. Количество тарелок зависит от желаемой чистоты и сложности разделения. Оно влияет на то, какой высоты будет ректификационная колонна.
Принцип работы ее следующий. Смесь подается посредине высоты колонны. Разница в концентрации приводит к тому, что менее летучие компоненты переходят из потока пара в поток жидкости. Газ, выходящий из конденсатора, содержит наиболее летучие вещества, а менее испаряемые выходят через нагреватель в поток жидкости.
Геометрия тарелок в колонне влияет на степень и тип контакта между разными фазовыми состояниями смеси. Конструктивно они выполняются ситчатыми, клапанными, колпачковыми, решетчатыми, каскадными и т. д. Ситчатые тарелки, в которых имеются отверстия для пара, используются для обеспечения высокой производительности при низких затратах.
Более дешевые клапанные тарелки, в которых отверстия снабжены открывающими и закрывающими клапанами, склонны к засорению из-за скопления на них материала. Колпачковые снабжены колпачками, позволяющими пару проходить через жидкость сквозь крошечные отверстия. Это самая передовая и дорогая технология, эффективная при низких скоростях потока. Жидкость течет от одной тарелки к другой вниз по сливным вертикальным трубам.
Тарельчатые колонны часто используются для восстановления растворителей из технологических отходов. Также они применяются для восстановления метанола при операции сушки. В качестве жидкого продукта выходит вода, а летучие органические отходы переходят в паровую фазу. Вот что такое дистилляция в ректификационной колонне.

Криогенная перегонка
Криогенная дистилляция заключается в применении общих методов перегонки к газам, охлажденным до жидкого состояния. Система функционирует при температурах ниже -150 °С. Для этого используются теплообменники и змеевики. Вся конструкция называется криогенным блоком. Сжиженные газы поступают в блок и перегоняются при очень низких температурах.
Колонны криогенной дистилляции могут быть насадочными и пакетными. Пакетный дизайн более предпочтителен, поскольку насыпной материал менее эффективен при низких температурах.
Одним из основных применений криогенной дистилляции является разделение воздуха на составляющие его газы.
Экстрактивная перегонка
В экстрактивной ректификации используются дополнительные соединения, которые действуют как растворитель для изменения относительной летучести одного из компонентов смеси. В экстрактивную колонну к разделяемым веществам добавляется растворитель. Компонент сырьевого потока, который требуется извлечь, соединяется с растворителем и выходит в жидкой фазе. Другой компонент испаряется и выходит в дистиллят. Вторая перегонка в другой колонне позволяет отделить вещество от растворителя, который затем возвращается на предыдущий этап, чтобы повторить цикл.
Экстрактивная ректификация применяется для разделения соединений с близкими температурами кипения и азеотропных смесей. Экстрактивная ректификация не так широко распространена в промышленности, как обычная дистилляция, из-за сложности конструкции. Примером является процесс получения целлюлозы. Органический растворитель отделяет целлюлозу от лигнина, а вторая перегонка позволяет получить чистое вещество.
Источник: fb.ru
Русские Блоги
Методы глубокого обучения (пятнадцать): дистилляция знаний (дистилляция знаний в нейронной сети), онлайн дистилляция

Я понимаю: не обязательно правильно
Сделайте небольшое значение ближе к нулю. Распределение предыдущего примера перейдет к жесткой цели. Если распределение более среднее, возьмите мягкую цель
1. Сначала используйте оригинальную метку для обучения модели, зарезервированные параметры — это каждое слово, прогнозируется вероятность всех категорий.
2. Дистилляция. Возьмите среднее количество меток с высокой вероятностью перед распределением. Если распределение неравномерно, просто возьмите вероятность?
Distilling the Knowledge in a Neural Network
В этой статье рассказывается о черной технологии, созданной Хинтоном за 15 лет, в некоторых докладах Хинтон называл ее «Темное знание», а эта технология обычно называется «Распространение знаний». Основная идея заключается в передаче знаний, чтобы получить небольшую модель, более подходящую для вывода, через обученную большую модель. Эта концепция была впервые введена в документе «Сжатие модели» в 2006 году. Каруана предложил метод сжатия функций, изученных большой моделью, в меньшую и более быструю модель и получения метода, который может соответствовать результатам большой модели.
Основная идея состоит в том, чтобы использовать мягкие цели, чтобы помочь жестким целям в совместном обучении, и мягкие цели получаются из результатов прогнозирования большой модели. Кто-то здесь спросит, так как истинный ярлык (жесткая цель) полностью верен, зачем нам мягкая цель?
Жесткая цель содержит очень небольшое количество информации (информационная энтропия), мягкая цель содержит большое количество информации и имеет информацию о взаимоотношениях между различными классами (например, при одновременной классификации ослов и лошадей, хотя изображение — это лошадь, но мягкая цель — В отличие от жесткой цели, только значение индекса лошади равно 1, а остальное равно 0, но в части осла также будет вероятность.) [5]
Преимущество этого состоит в том, что это изображение может больше походить на осла, чем на машину или собаку, и такая мягкая информация существует в вероятности, а высокое и низкое сходство между метками существует в мягкой цели. Но если мягкая цель — это информация, подобная этой [0,98 0,01 0,01], это не имеет особого смысла, поэтому вам нужно увеличить температурный параметр T в softmax (эта настройка не нужна в рассуждениях после финальной тренировки)
q i = e x p ( z i / T ) Σ j e x p ( z j / T ) q i = e x p ( z i / T ) Σ j e x p ( z j / T ) q i = e x p ( z i / T ) Σ j e x p ( z j / T ) qi=exp(zi/T)Σjexp(zj/T)qi=exp(zi/T)Σjexp(zj/T) q_i=frac <Sigma_jexp(z_j/T)>q i = e x p ( z i / T ) Σ j e x p ( z j / T ) q i = e x p ( z i / T ) Σ j e x p ( z j / T ) q i = Σ j e x p ( z j / T ) e x p ( z i / T ) L = α L ( s o f t ) + ( 1 − α ) L ( h a r d )

Принципиальная схема алгоритма выглядит следующим образом [5]:
1. Обучение больших моделей: сначала используйте жесткие цели, то есть обычные метки, чтобы обучать большие модели.
2. Рассчитайте мягкую цель: используйте обученную большую модель для расчета мягкой цели. То есть большая модель «размягчается» и затем проходит через выход softmax.
3. Обучите маленькую модель, добавьте дополнительную мягкую целевую функцию потерь на основе маленькой модели и отрегулируйте пропорцию двух функций потерь с помощью лямбды.
4. При прогнозировании используйте обученную маленькую модель обычным способом (справа).
Онлайн дистилляция кодистилляция
В рамках задачи распределенного обучения метод замены стандартной модели NN обучения SGD, кодистилляция, является несинхронизированным алгоритмом. На самом деле, существует много копий Wieght в независимом обучении, он может эффективно «решить» увеличение машины. Для проблемы, что линейность не увеличивается, есть некоторые поверхности данных в эксперименте, которые могут сходиться быстрее, чем стандартная SGD.
Это также идея дистиллята, но, поскольку это тяжелое обучение, какова модель учителя? Автор предлагает использовать прогнозируемое среднее всех моделей в качестве модели учителя, а затем в качестве мягкой цели для обучения каждой модели.
В этой статье кодистилляция используется для обозначения выполненной дистилляции:
- Все модели используют одинаковую архитектуру;
- Используйте один и тот же набор данных для обучения всех моделей;
- Прежде чем любая модель полностью сходится, используйте потери дистилляции во время тренировки.

Принцип работы алгоритма заключается в следующем:

Автор потерь на дистилляцию отметил, что это может быть квадратное расстояние или KL-дивергенция, но автор использовал перекрестную энтропию.
Разделенный на два этапа, первый этап независимого обновления SGD, этот этап не нужно синхронизировать, поэтому он очень эффективен. Второй этап — это этап кодистилля, который заключается в использовании среднего результата прогнозирования каждой модели в качестве мягкой цели для обучения каждой независимой модели. Интересно, что автор сказал, что это будет обучать кучу разных моделей (требуется только, чтобы они выполнялись близко, и не может Вынудите их вес быть тем же), но эти модели не имеют никакого значения в потере. ,

Авторы также показывают, что на самом деле его можно комбинировать со стандартной синхронной SGD, то есть группировать — использовать синхронную SGD внутри группы для обучения копии модели, а затем использовать codistill для обучения между группами (только результаты прогнозирования обмена, очень малые). Кроме того, автор сказал, что, хотя они и передали все копии модели всем узлам в реализации моделирования, для получения результатов мягкого прогнозирования фактически они могут передавать только результаты прогнозирования (я полагаю, это может быть неудобно для поддержки инфраструктуры?)

Сосредоточив внимание на Imagenet, 16K Batchsize использует двустороннее обучение, чтобы сходиться быстрее, чем одностороннее обучение.
Источник: russianblogs.com
Дистилляция данных (Data Distillation)
Расскажем об одном DL-подходе к задаче сокращения размера выборки, а на самом деле, даже более амбициозной задаче — создания синтетических данных, хранящих всю полезную информацию о выборке.

История и термины
Дистилляция данных (Data Distillation) – это существенное уменьшение выборки, путём создания искусственных объектов (синтетических данных), которые агрегируют полезную информацию, хранящуюся в данных, и позволяют настраивать алгоритмы машинного обучения не менее эффективно, чем на всех данных.
Изначально термин «дистилляция» появился в работе [1] Хинтона, потом утвердился термин «дистилляция модели / знаний» (Knowledge Distillation) – это построение простой модели на основе сложной / нескольких моделей, но эта заметка, как Вы поняли, совсем про другую задачу, хотя и со схожим названием.
Есть много классических методов по выбору объектов (Instance Selection), начиная от выбора т.н. эталонов в метрических алгоритмах, заканчивая выбором опорных объектов в SVM. Но дистилляция это не выбор, а синтез объектов (разница примерно такая же как между селекцией признаков и снижением размерности признакового пространства, только речь в данном случае не о признаках, а о объектах). В эпоху глубокого обучения появилась возможность делать синтетические данные с помощью единой оптимизационной техники, именно синтезируя объекты (а не переборно). Ниже расскажем о некоторых работах в этом направлении. Заметим, что дистилляция данных нужна для
• ускорения обучения / тестирования (желательно для целого класса моделей),
• сокращения объёма данных для хранения (замена старому выбору объектов),
• ответа на научный вопрос: сколько информации содержится в данных (насколько сможем их «сжать»).
Метод дистилляции
Идея DL-дистилляции данных предложена в работе [2], в которой MNIST-датасет из 60 000 изображений сокращён до 10, т.е. в синтетическом обучении находилось по одному изображению-представителю для каждого класса! При этом сеть архитектуры LeNet обучалась на синтетических данных примерно до такого же качества, что и на всей выборке (естественно, существенно быстрее) и сходилась за несколько шагов. Однако обучение по-другому инициализированной сети уже ухудшало качество решения. На рис. 1 из работы [2] показан основной результат и полученные синтетические данные в задачах MNIST и CIFAR10, можно обратить внимание, что для датасета MNIST они совсем не похожи на реальные числа, хотя логично ожидать, что синтетический представитель класса «ноль» это что-то похожее на ноль, см. также рис. 2.


Опишем базовую идею предложенного в [2] метода, мы хотим, чтобы синтетические данные были такими, чтобы при использовании градиентного спуска на них мы попали в минимум функции ошибки, т.е. надо решить такую задачу оптимизации

здесь θt – вектор параметров сети на t-й итерации, на нулевой итерации они берутся из распределения p(•), x «с волной» – синтетические данные, x (без волны) – обучающая выборка, l(x, θ) – функция ошибки нейронной сети на всей обучающей выборке. Заметим, что в формуле используется лишь один шаг градиентной настройки исходной нейросети, дальше мы обобщим это. Здесь же возникает центральная проблема: если предложенную задачу оптимизации решать градиентным методом ,то мы должны брать градиент от градиента.
В более общем случае мы отказываемся от надежды свалиться в минимум за один шаг градиентного спуска и используем несколько шагов. Более того, можно задаваться несколькими наборами параметров из распределения p(.) и, таким образом, синтетические данные будут подходить для нескольких нейронных сетей с разными параметрами. Ниже показан алгоритм для поиска синтетических данных в общем случае. Кстати, это обобщение позволяет получить синтетические данные, которые больше похожи на исходные, см. рис. 3.




Развитие метода
Статья [2] дала толчок новому направлению исследований, например в [3] показали, как улучшить сжатие данных при дистилляции, используя «нечётко (мягко) размеченные» данные, т.е. в задаче MNIST представитель искусственных данных мог принадлежать сразу нескольким классам с разными вероятностями. Неформально говоря, дистиллировались не только данные, но и метки. В результате обучаясь на выборке только из 5 дистиллированных изображений, можно получить точность около 92% (это, правда, хуже 96%, полученных в предыдущей работе). Конечно, чем больше синтетических данных, тем качество на них лучше, см. рис. 5. Более того, в [3] дистилляцию данных применили для текстов (правда, немного искусственно – обрезав или дополнив тексты до фиксированной длины).


Авторские эксперименты
Когда автор откопал статью [2], показалось, что она сильно недооценена. Конечно, у неё близкая к нулю практическая важность, но
1) предложен «регулярный» и очень логичный метод агрегации данных, заточенный «под модель»,
2) есть много открытых проблем, например, получение синтетических данных, похожих на оригинальные,
3) любопытно, как это всё работает для табличных данных (удивительно, что это сразу не сделали),
4) есть чисто инженерный вызов создания «более эффективного синтеза» искусственных данных.
Магистр автора на факультете ВМК МГУ Дмитрий Медведев заинтересовался дистилляцией данных и сделал часть напрашивающихся экспериментов (другую часть мы пока не доделали, ибо описанная двухуровневая оптимизация производится очень медленно, а сверхмощностей гугла у нас сейчас нет). Мы решили посмотреть, как метод работает на табличных данных. Ниже приведены картинки для классической модельной задачи «два полумесяца» и нескольких простых нейросетей: однослойной, 2-слойной и 4-слойной. Заметим, что даже для такой простой задачи и простых моделей общее время дистилляции достигает 4 часов.
Мы исследовали, как качество на тесте зависит от числа эпох при решении задачи минимизации для построения синтетических данных (это не эпохи обучения НС), числа шагов в этой же задаче, числа нейронных сетей для которых синтезируются данных (число начальных параметров), см. рис. 6.

На рис. 7 показана синтетическая выборка (крупным), получаемая на разных шагах метода для разных архитектур. Проблемы, которые были для данных другой природы, здесь, конечно, остались: синтетические объекты не похожи на объекты выборки. И с этой проблемой нам предстоит ещё побороться.

На рис. 8 показано, как работают модели, настроенные на синтетических данных.

Мы также посмотрели, насколько синтетические данные, построенные для одной архитектуры, годятся для других архитектур нейронных сетей (см. табл), также был предложен метод дистилляции данных сразу для нескольких архитектур. Кстати, удалось продемонстрировать эффект, что сеть, обученная на дистиллированных данных, может быть по качеству лучше сети, обученной на всей выборке.

Наши исследования дистилляции продолжаются, пока подготовлена работа [4], её откорректированная версия представлена на недавней конференции AIST-2020, а также выложен код [5]. Параллельно ещё несколько научных групп делают что-то подобное (если будет интерес, то автор представит обзор их исследований в этом блоге).
Ссылки
[2] Wang, T., Zhu, J., Torralba, A. and Efros, A. Dataset Distillation, 2018.
Источник: alexanderdyakonov.wordpress.com