
Logger getLogger () метод в Java с примерами
Метод getLogger () класса Logger использовал find или create logger. Если существует регистратор с переданным именем, метод вернет этот регистратор, иначе метод создаст новый регистратор с этим именем и вернет его.
Существует два типа метода getLogger (), в зависимости от того, какой параметр не передан.
-
getLogger (java.lang.String) : этот метод используется для поиска или создания регистратора с именем, переданным в качестве параметра. Он создаст новый регистратор, если регистратор не существует с переданным именем. Если этим способом создается новый регистратор, его уровень журнала будет настроен на основе конфигурации LogManager, и он также будет настроен на отправку выходных данных журнала обработчикам его родителя. Он будет зарегистрирован в глобальном пространстве имен LogManager. Синтаксис:
public static Logger getLogger(String name)
Параметры: Этот метод принимает одно имя параметра, которое представляет собой строку, представляющую имя для регистратора. Это должно быть имя, разделенное точкой, и обычно оно должно основываться на имени пакета или имени класса подсистемы, например, java.net или javax.swing.Возвращаемое значение: этот метод возвращает подходящий Logger. Исключение: этот метод генерируетисключениеNullPointerException, если переданное имя равно нулю. Ниже программы иллюстрируют метод getLogger (java.lang.String):
DEBUG ЧТО ЭТО И КАК ДЕБАЖИТЬ НА РЕАЛЬНЫХ ПРИМЕРАХ в JAVA | АВТОМАТИЗАЦИЯ НА ПАЛЬЦАХ
Программа 1:
| // Java-программа для демонстрации // Logger.getLogger (java.lang.String) метод import java.util.logging.*; public class GFG < public static void main(String[] args) < // Создать регистратор с именем класса GFG Logger logger = Logger.getLogger(GFG. class .getName()); // Вызов метода информации logger.info( «Message 1» ); logger.info( «Message 2» ); >> |
Вывод на консоль показан ниже.
Выход: Программа 2:
Программа 2:
| // Java-программа для демонстрации исключения, созданного // Logger.getLogger (java.lang.String) метод import java.util.logging.*; public class GFG < public static void main(String[] args) < String LoggerName = null ; // Создать регистратор с нулевым значением try < Logger logger = Logger.getLogger(LoggerName); >catch (NullPointerException e) < System.out.println( «Exception Thrown: » + e); >> > |
Вывод на консоль показан ниже.
Выход:
getLogger (String name, String resourceBundleName) : Этот метод используется для поиска или создания регистратора с переданным именем. Если регистратор уже был создан с заданным именем, он возвращается. В противном случае создается новый регистратор. Если регистратор с переданным именем уже существует и не имеет пакета ресурсов локализации, то данное имя пакета ресурсов используется в качестве пакета ресурсов локализации для этого регистратора. Если именованный регистратор имеет другое имя пакета ресурсов, этот метод создает исключение IllegalArgumentException. Синтаксис:
public static Logger getLogger(String name, String resourceBundleName)
- name : это имя для регистратора. Это имя должно быть именем, разделенным точкой, и обычно оно должно основываться на имени пакета или имени класса подсистемы, таких как java.net или javax.swing.
- resourceBundleName: имя ResourceBundle, которое будет использоваться для локализации сообщений для этого регистратора.
Возвращаемое значение: этот метод возвращает подходящий Logger.
Профессиональная отладка программ | Ведение логов | Сообщения об ошибках в программе | debug
Исключение: этот метод генерирует следующие исключения:
- NullPointerException: если переданное имя является нулем.
- MissingResourceException: если resourceBundleName не равно NULL и соответствующий ресурс не может быть найден.
- IllegalArgumentException: если Logger уже существует и использует другое имя пакета ресурсов; или если resourceBundleName имеет значение null, но у указанного регистратора установлен набор ресурсов.
Ниже программы иллюстрируют метод getLogger (String name, String resourceBundleName):
Программа 1:
// Java-программа для демонстрации
// getLogger (String name, String resourceBundleName) метод
public class GFG
public static void main(String[] args)
// Создать ResourceBundle с помощью getBundle
// myResource — это файл свойств
// с GFG.class и resourceBundle
GFG. class .getName(),
logger.info( «Message 1 for logger» );

Для вышеуказанной программы существует файл свойств с именем resourceBundle. мы должны добавить этот файл вместе с классом для выполнения программы.
Выход:
Ссылки:
- https://docs.oracle.com/javase/10/docs/api/java/util/logging/Logger.html#getLogger(java.lang.String, java.lang.String)
- https://docs.oracle.com/javase/10/docs/api/java/util/logging/Logger.html#getLogger(java.lang.String)
- Метод getMogger () LogManager в Java с примерами
- Logger log () метод в Java с примерами
- Метод getAnonymousLogger () в Java с примерами
- Метод logger setFilter () в Java с примерами
- Логгер addHandler () метод в Java с примерами
- Метод logger finest () в Java с примерами
- Метод getResourceBundleName () в Java с примерами
- Logger warning () метод в Java с примерами
- Logger getUseParentHandlers () метод в Java с примерами
- Метод logger isLoggable () в Java с примерами
- Метод входа () в Java с примерами
- Метод logger exiting () в Java с примерами
- Метод logger config () в Java с примерами
- Метод логгера fine () в Java с примерами
- Метод logger setLevel () в Java с примерами
Источник: espressocode.top
Debug logger ui что это за программа и нужна ли она
Все что вы делаете вы делаете на свой страх и риск. Я могу только рекомендовать и не претендую на 100% решение, многое зависит от вашего окружения и прочих настроек. О которых я могу и не догадываться. Дополнение материалов и исправление ошибок приветствуется.
(Решено) Непонятный файл aria-debug размером в несколько Гб
Также доступны: EN
Как всегда Microsoft «радует». Сегодня смотрел проблему почему съедается всё место на жестком диске. Причем съедается в момент, ты успеваешь освободить и через короткий промежуток система просто взрывается от сообщения об отсутствие свободного места на диске С. При пристальном рассмотрении выяснилось, на диске появляется серия файлов с именем aria-debug-xxxx.log один из которых занимает несколько Гб, у всех по разному зависит от вашего размера системного диска (как правило это диск C ). Изначально первой мыслью было вирус, но антивирус молчит и не подает сигналов опасности.
Внимание!! Есть решение проблемы.
Недолго поискав, выяснил что всему виной OneDrive от Microsoft, даже если вы им не пользуете, он все равно что-то логирует. Причем делает настолько интенсивно, что забивается место на жестком диске почти мгновенно.
Так как я не пользуюсь им и человек который ко мне обратился также не использует его. Пришлось просто удалить проблемную версию. Если он вам нужен и вы его используете. Следите за обновлениями, как минимум установите предыдущую версию. Как только появятся у меня сведения об патче или настройках я добавлю к заметке. Если у вас есть такие сведения поделитесь и вместе сделаем мир лучше 🙂 .
Возможно вы спросите: «Как удалить этот файл aria-debug-xxxx.log ?» Все очень просто, выгружаем OneDrive и после этого запускаем «Очистку диска» и она вам высвободит все занимаемое пространство этим log файлом. Но это временная мера, до следующего запуска OneDrive.
Наткнулся на решение, пробуйте может поможет:
Вот, наверно, наиболее грамотные советы от сегодня:
Все пути и знаки сохранил из первоисточника.
***Если вы не пользуетесь One Drive и он вам не нужен***
- Удаляем все файлы aria-debug-****.log в папке C:\Users\Имя пользователя\AppData\Local
- В диспетчере задач (win+R команда taskmgr)отключаем все процессы Microsoft OneDriveSetup и OneDrive
- Удаляем все файлы в папке C:\Users\Имя пользователя\AppData\Local\Microsoft\OneDrive\setup\logs
- Запускаем редактор реестра windows (win+R команда regedit) и меняем атрибут по адресу HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Group Policy Objects\Machine\Software\Policies\Microsoft\Windows\OneDrive на 1 (если его нет можно создать с типом dword)
———————————————————————————————
***Если вы пользуетесь One Drive и он вам нужен***
- Удаляем все файлы aria-debug-****.log в папке C:\Users\Имя пользователя\AppData\Local
- В диспетчере задач (win+R команда taskmgr)отключаем все процессы Microsoft OneDriveSetup и OneDrive
- Удаляем все файлы в папке C:\Users\Имя пользователя\AppData\Local\Microsoft\OneDrive\setup\logs
- Если компьютер обновлялся идем в C:\Users\Имя пользователя\AppData\Local\Microsoft\OneDrive и запускаем OneDriveStandaloneUpdater.exe
Если компьютер не обновлялся или искомого файла нет то скачиваем установщик по адресу https://go.microsoft.com/fwlink/p/?LinkId=248256
«АлексейТелятников ответил: 10 октября, 2017
Помогло обновление OneDrive, без всяких перезагрузок и прочего. Файл просто перестал расти.
Win+R и %localappdata%\Microsoft\OneDrive\Update\onedrivesetup.exe»
Если вам помогла статья или информация была полезной. Благодарность, не должна знать границ.
- Две стрелки на ярлыках windows 10
- Установка и исправления CiscoVpn Client в Windows 10 (x32_x64)
- Борьба за место, очищаем папку WinSxS
- Отключение Fast Startup(быстрый запуск) в Windows 10
- Ошибки активации MS Windows и Office
Источник: www.bobr.pw
Средства мониторинга Linux системы (часть 1?)
Короче, продолжаем. Теперь я для вас подготовил некую уже не маленькую статью, на тему мониторинга Linux систем. В некотором роде эта статья мне будет служить в качестве мини-справочника по необходимым командам, для того, чтобы можно было понимать, все ли нормально с системой. Поговорим об основных командах типа top/htop/uptime/ps, о том где какие логи лежат и что они означают и так далее. Короче, начнем..
Log-файлы (журналы)
Все логи по умолчанию хоронятся в директории /var/log/ (ну так принято по стандарту иерархии файловой системы) и эти файлы — сведения о происходящих процессах в системе. Кстати, если вы поддерживайте систему, которая может быть интересна взломщикам, то настоятельно рекомендуется обзавестись системой дублирования логов, например, на туже почту. Взломщик будет думать, что все «зачистил» за собой, но доказательства его пребывания в системе останутся. Но речь не об этом..
Рассмотрим пример стандартных файлов в директории /var/log/, на примере ОС Debian Linux 7:
- /var/log/syslog — syslog является основным системным журналом и в нем сохраняются сообщения демонов и других программ, работающих в системе, например, dhclient, cron, init, xscreensaver, а также некоторые сообщения ядра. Этот журнал — первое место, откуда надо начинать просмотр при попытке отследить типичные системные ошибки
- /var/log/auth.log — содержит информацию системы авторизации, в том числе логины и механизм проверки подлинности, которые были использованы
- /var/log/daemon.log — содержит информацию о различных демонах/сервисах запущенных в системе. С помощью него можно находить проблемы во время падения системы
- /var/log/dmesg — в файле содержаться все сообщения ядра, начиная с этапа загрузки системы, а просмотреть содержимое этого файла можно используя команду dmesg
- /var/log/kern.log — файл журнала ядра, предоставляет подробный лог сообщений от ядра Linux, которые могут быть полезны при анализе и устранении неисправностей
- /var/log/messages — файл содержит глобальные настройки, в том числе сообщения, которые регистрируются при запуске системы
- /var/log/debug — журнал отладки, предоставляющий подробную отладочную информацию системы и приложений, которые используют syslogd для отладки
- /var/log/user.log — содержит информацию о всех журналах на уровне пользователя
- /var/log/btmp — файл содержит записи обо всех неудавшихся попытках регистрации пользователей в системе. Посмотреть неудачные попытки входа в систему можно с помощью команды lastb
- /var/log/faillog — в этом файле хранится число неудачных попыток входа в систему и их предельное число для каждой учётной записи. А если в консоли ввести команду faillog, то можно увидеть содержимое этого файла
- /var/log/mail.log, /var/log/mail.err, /var/log/mail.info, /var/log/mail.warn — файлы журналирующие почтовые события
- /var/log/lastlog — файл содержащий записи о предыдущих входах в систему
- var/log/apt — директория содержит информацию, которая пишется при установки/удалении пакета с помощью программы apt
- /var/log/alternatives.log — файл программы update-alternatives, которая является механизмом выбора предпочтительного ПО среди нескольких вариантов в таких дистрибутивах Linux, как Debian и Ubuntu
- /var/log/aptitude — файл программы aptitude содержащий информацию об установке/удалении пакетов
- /var/log/dbconfig-common — в случае использования утилиты dbconfig все действия будут журналироваться в файлах, в этой лиректории
- /var/log/dpkg.log — файл содержит информацию, которая пишется при установки/удалении пакета с помощью программы dpkg
- /var/log/fsck — если в вашей системе запускалась проверка файловой системы то она будет журналироваться в файлы находящиеся в этой директории
- /var/log/wtmp — файл содержит двоичные данные о времени регистрации и продолжительность работы всех пользователей системы. Он пользуется командой last для вывода списка регистрировавшихся пользователей
- /var/log/apache2 — если в вашей системе установлен apache, то в данной директории будут находиться журналы access_log и error_log
- /var/log/mysql.err и /var/log/mail.info — если у вас установлена СУБД MySQL, то в этих файлах будут журналироваться сведения о работе и об ошибках СУБД
Теперь приведем пример, что когда нам понадобится..
-
Если у нас не запускается какая то служба, то имеет смысл посмотреть файл /var/log/syslog, хотя скажу сразу, туда логируется почти все, даже bind9, если таковой стоит, поэтому лучше смотреть этот файл при помощи «tail -f»:
tail -f /var/log/syslog
На этом про логи, я думаю, достаточно..
Правки в файлах
Иногда бывает полезно выявлять факты изменения файлов в такой директории, как /etc, особенно, если администрированием сервера занимайтесь не только вы. Сделать это все можно при помощи команды find с параметром -mtime. Например, следующая команда покажет файлы, которые были изменение в течении последних двух суток:
find /etc -mtime 2
Более подробно поиск по различным временам описан тут.
Какова загрузка системы?(LoadAverage)
Вы наверное часто обращали внимание на такую строчку, как LoadAverage, которая показывает числа. Собственно эти числа отображают число блокирующих процессов на исполнение в определенный интервал времени, а именно 1 минута, 5 минут и 15 минут. Под блокирующим процессом подразумевается процесс, который ждет ресурсы для того, чтобы продолжить свою работу, а под ресурсами подразумевается ЦП, дисковая подсистема ввода вывода и сетевая подсистема ввода/вывода.
Не обязательно быть специалистом, чтобы понимать, что высокие показатели LA говорят о том, что система не справляется, например эти цифры могут говорить об аппаратных проблемах.
Чтобы посмотреть эти показания, достаточно воспользоваться командой top или uptime (о top мы поговорим несколько позднее)
[email protected]:~$ uptime 16:54:50 up 5 days, 18:54, 3 users, load average: 0,59, 0,77, 0,84
Большинство (как и я ) будут думать, что чем меньше эти числа, тем лучше, но нужно понимать, когда бить тревогу, если значения этих цифр начнет расти.
Отличная аналогия «на машинках» о том, что эти цифры обозначают приведена в статье на хабре, поэтому приведу краткую выдержку от туда: представим, что одноядерный процессор это однополосный мост, а мы управляем движением на этом мосту. Если мост перегружен, то машины ждут (ну или стоят в пробке). Собственно количество машин в очереди это и есть то число, которое вы видите. Пример можно увидеть на этих картинках из этой прекрасной статьи:
![]()
![]()
![]()
Исходя из того, что мы видим, можно понять, что Load Average равный 1,00 — идеальное значение, но это не так. Идеальным значением для меня можно считать 0,50 ну или на худой конец 0,70, так как должен сохраняться какой-то запас на случай внезапной нагрузки или нештатного поведения той или иной программы.
И имейте в виду, пример выше это пример для одноядерного процессора. Если у вас четырехядерный процессор или два двухядерных процессора, то идеальным LA для вас будет 2,00 или 2,80.
Теперь подытожим эту тему,
- Какое значение лучше смотреть? За минуту, 5 минут или 15 минут?
Если на одноядерном процессоре LA за 5 или 15 минут, то следует на это обратить внимание - Как понять сколько процессоров в системе?
ну тут все просто, нужно отфильтровать grep-ом вывод cpuinfo:
[email protected]:~$ cat /proc/cpuinfo | grep ‘cpu cores’ cpu cores : 2 cpu cores : 2 cpu cores : 2 cpu cores : 2
Что происходит в системе (процессы)
Собственно. чтобы увидеть эти показатели, понять, где у нас есть проблемы, и вообще получить информацию о процессах воспользуемся утилитой top:
Рассмотрим по порядку, что есть что:
- Общая информация:
- текущем времени
- uptime времени (сколько система работает)
- количество пользовательских сессий (3 users)
- LoadAverage (ну о нем написан целый раздел)
- Статистика процессов:
- общее количество процессов в системе
- количество работающих в данный момент процессов
- количество спящих процессов (они работающие, просто «ждут» события)
- количество остановленных событий (я их останавливаю с помощью команды ctrl+z)
- количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie)
- Статистика использования CPU:
- 6,8 us — процент использования центрального процессора пользовательскими процессам
- 1.1 sy — процент использования центрального процессора системными процессами
- 0.0 ni — процент использования центрального процессора процессами с приоритетом, повышенным при помощи вызова nice
- 92.1 id (id это idle cpu time, т.е. время простоя CPU) — процент простоя процессора
- 0.0 wa — процент использования центрального процессора процессами, ожидающими завершения операций ввода-вывода (например чтение/запись на диск)
- 0.0 hi (hi это Hardware IRQ, т.е. аппаратные прерывания) — процент использования центрального процессора обработчиками аппаратных прерываний
- 0.0 si (si это Software Interrupts, т.е. программные прерывания) — процент использования центрального процессора обработчиками программных прерываний
- 0.0 st (st это Steal Time , т.е. заимствованное время) — количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины); это значение будет равно нулю на не использующих виртуальные машины
- Статистика использования физической и swap памяти:
- общее количество памяти (total)
- количество используемой памяти (used)
- количество свободной памяти (free)
- количество памяти в кэше буферов (buffers)
- Список процессов, отсортированный по степени использования центрального процессора (по умолчанию), опишем столбцы:
- PID — идентификатор процесса
- USER — имя пользователя, который является владельцем процесса
- PR — приоритет процесса
- NI — значение «NICE», влияющие на приоритет процесса
- VIRT — объем виртуальной памяти, используемый процессом
- RES — объем физической памяти, используемый процессом
- SHR — объем разделяемой памяти процесса
- S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс)
- %CPU — процент использования центрального процессора данным процессом (0.3)
- %MEM — процент использования оперативной памяти данным процессом (0.7)
- TIME+ — общее время активности процесса (0:17.75)
- COMMAND — имя процесса (bb_monitor.pl)
Что нам тут интересно? Да интересно почти все :). Например, статистика CPU: высокие значения (более 80%) параметра wa говорят о простое из-за ввода вывода, что может говорить о проблемах с HDD. Кстати, если сложить все эти значения, то у вас получится 100%.
Что мы там можем делать в утилите top?
- Нажав на клавишу k мы можем убить процесс, достаточно будет ввести его PID
- нажав на клавишу u и введя имя пользователя мы можем увидеть все процессы определенного пользователя
- нажав на клавишу b или z и работающие процессы будут выделены цветом
Более подробнее о ключах top можно почитать в страницах man. Кстати, есть еще и отличный аналог утилиты top — htop:
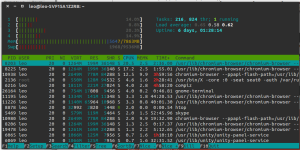
ps — process status
Существует еще генератор снимков процессов ps. Подробнее о нем можно почитать его man, а ниже я приведу примеры использования этой команды:
-
при помощи следующей команды мы можем выяснить, выполняется ли в данный момент программа apache:
ps -aux | grep apache
ps aux
ps -ef
ps axjf
ps -f -u www-data
[email protected]:~$ ps -f -p 11947,11950,11957 UID PID PPID C STIME TTY TIME CMD www-data 11947 11943 0 июля30 ? 00:00:00 /usr/sbin/apache2 -k start www-data 11950 11943 0 июля30 ? 00:00:00 /usr/sbin/apache2 -k start www-data 11957 11943 0 июля30 ? 00:00:00 /usr/sbin/apache2 -k start
Этого я думаю достаточно.
Есть еще масса интересных примеров на просторах интернета, например тут.
В заключение…
начиная писать эту статью, я не думал что все получится на столько громоздко, поэтому еще будет как минимум вторая или третья часть средств мониторинга linux систем.
- http://cyberforby.blogspot.ru/2012/04/varlog.html
- http://rus-linux.net/nlib.php?name=/MyLDP/BOOKS/ubuntu_hacks_ru/ubuntuhack82.html
- http://www.thegeekstuff.com/2011/08/linux-var-log-files/
- https://help.ubuntu.com/community/LinuxLogFiles
- http://www.softpanorama.org/Tools/Find/selecting_files_by_age.shtml
- http://habrahabr.ru/post/216827/
- http://habrahabr.ru/post/71020/
- http://habrahabr.ru/post/49204/
- http://rus-linux.net/MyLDP/consol/komanda-top-v-linux.html
- http://linux.die.net/man/1/top
- http://linuxopen.ru/2010/01/21/15-primerov-ispolzovanija-v-linux.html
Источник: maxidrom.net