
CUDA — это модель, созданная Nvidia для платформы параллельных вычислений и интерфейса прикладного программирования. CUDA — это архитектура параллельных вычислений NVIDIA, которая позволяет резко повысить производительность вычислений за счет использования мощности графического процессора.
Google Colab — это бесплатная облачная служба, и самая важная особенность, которая отличает Colab от других бесплатных облачных служб, — это; Colab предлагает GPU и совершенно бесплатно! С Colab вы можете работать на графическом процессоре с CUDA C/C++ бесплатно!
Код CUDA не будет работать на процессоре AMD или графике Intel HD, если на вашем компьютере нет аппаратного обеспечения NVIDIA. В Colab вы можете воспользоваться преимуществами графического процессора Nvidia, а также полнофункциональным ноутбуком Jupyter с предустановленным Tensorflow и некоторыми другими ML / DL. инструменты.
Шаг 1: Перейдите на https://colab.research.google.com в браузере и нажмите Новый блокнот.
Технология CUDA от NVIDIA GEFORCE.Как включить в AFTER EFFECTS И PREMIER PRO
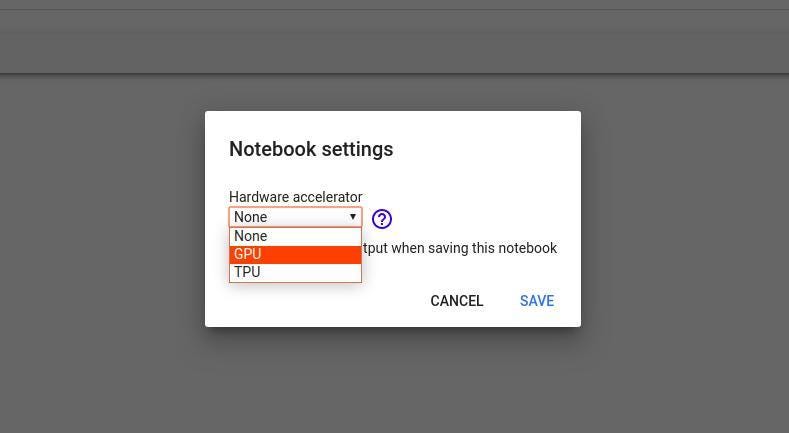
Шаг 2: Нам нужно переключить нашу среду выполнения с CPU на GPU. Нажмите Runtime › Change runtime type › Hardware Accelerator › GPU › Save.

Шаг 3: Полностью удалите все предыдущие версии CUDA. Нам нужно обновить облачный экземпляр CUDA.
!apt-get —purge remove cuda nvidia* libnvidia-* !dpkg -l | grep cuda- | awk » | xargs -n1 dpkg —purge !apt-get remove cuda-* !apt autoremove !apt-get update
Напишите код в отдельном блоке кода и запустите этот код. Каждая строка, начинающаяся с «!», будет выполняться как команда командной строки.
Шаг 4: Установите CUDA версии 9 (вы можете просто скопировать ее в отдельный блок кода).
!wget https://developer.nvidia.com/compute/cuda/9.2/Prod/local_installers/cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64 -O cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64.deb !dpkg -i cuda-repo-ubuntu1604-9-2-local_9.2.88-1_amd64.deb !apt-key add /var/cuda-repo-9-2-local/7fa2af80.pub !apt-get update !apt-get install cuda-9.2
Шаг 5: Теперь вы можете проверить установку CUDA, выполнив приведенную ниже команду:
!nvcc —version
Вывод будет примерно таким:
vcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Wed_Apr#include 23:16:29_CDT_2018 Cuda compilation tools, release 9.2, V9.2.88
Шаг 6: Запустите данную команду, чтобы установить небольшое расширение для запуска nvcc из ячеек ноутбука.
!pip install git+git://github.com/andreinechaev/nvcc4jupyter.git
Шаг 7: Загрузите расширение, используя приведенный ниже код:
%load_ext nvcc_plugin
Шаг 8: Выполните приведенный ниже код, чтобы проверить, работает ли CUDA.
Теперь мы готовы запускать код CUDA C/C++ прямо в вашем ноутбуке.
Важное примечание. Чтобы проверить, работает следующий код или нет, напишите этот код в отдельном блоке кода и запустите его снова только после обновления кода и его повторного запуска.
Чтобы запустить код в блокноте, добавьте расширение %%cu в начало кода.
Как установить CUDA How to install CUDA
int
return 0;
Welcome To GeeksforGeeks
Я предлагаю вам попробовать программу поиска максимального элемента из вектора, чтобы убедиться, что все работает правильно.
using namespace std;
__global__ void maxi(int* a, int* b, int n)
int block = 256 * blockIdx.x;
int max = 0;
for (int i = block; i < min(256 + block, n); i++)
if (max < a[i])
int main()
int n;
int a[n];
for (int i = 0; i < n; i++)
a[i] = rand() % n;
cudaEvent_t start, end;
int *ad, *bd;
int size = n * sizeof(int);
cudaMemcpy(ad, a, size, cudaMemcpyHostToDevice);
int grids = ceil(n * 1.0f / 256.0f);
dim3 grid(grids, 1);
while (n > 1)
n = ceil(n * 1.0f / 256.0f);
cudaMemcpy(ad, bd, n * sizeof(int), cudaMemcpyDeviceToDevice);
float time = 0;
int ans[2];
cudaMemcpy(ans, ad, 4, cudaMemcpyDeviceToHost);
The maximum element is : 1338278816 The time required : 0.003392
Источник: skine.ru
CUDA: Начало

Это первая публикация из цикла статей об использовании GPGPU и nVidia CUDA. Планирую писать не очень объемно, чтобы не слишком утомлять читателей, но достаточно часто.
Я предполагаю, что читатель осведомлен, что такое CUDA, если нет, то вводную статью можно найти на Хабре.
Что потребуется для работы:
1. Видеокарта из серии nVidia GeForce 8xxx/9xxx или более современная
2. CUDA Toolkit v.2.1 (скачать можно здесь: www.nvidia.ru/object/cuda_get_ru.html)
3. CUDA SDK v.2.1 (скачать можно там же где Toolkit)
4. Visual Studio 2008
5. CUDA Visual Studio Wizard (скачать можно здесь: sourceforge.net/projects/cudavswizard)
Создание CUDA проекта:
После установки всего необходимого в VS появиться новый вид проекта для С++ с названием CU-DA WinApp, это именно то, что нам надо. В данном типе проекта доступны дополнительные на-стройки для CUDA, позволяющие настроить параметры компиляции под GPU, например версию Compute Capability в зависимости от типа GPU и т.д.
Обычно я создаю чистый проект (Empty Project), так как Precompiled Headers навряд ли пригодиться для CUDA.
Важно отметить, как собирается CUDA приложение. Файлы с расширением *.cpp обрабатываются компилятором MS C++ (cl.exe), а файлы c расширением *.cu компилятором CUDA (nvcc.exe), который в свою очередь определяет, какой код будет работать на GPU, а какой на CPU. Код из *.cu, работающий на CPU, передается на компиляцию MS C++, эту особенность удобно использовать для написания динамических библиотек, которые будут экспортировать функции, использующие для расчетов GPU.
Далее привожу листинг простой программы на CUDA, который выводит на экран информацию об аппаратных возможностях GPU.
Листинг. Программа CudaInfo.
int main()
int deviceCount;
cudaDeviceProp deviceProp;
//Сколько устройств CUDA установлено на PC.
cudaGetDeviceCount(
return 0;
>
* This source code was highlighted with Source Code Highlighter .
В программе я подключаю библиотеку “cuda_runtime_api.h”. Хотя это делать не обязательно, так она инклюдится автоматически, но без неё не будет работать IntelliSence (хотя все равно периодически косячит).
Заключение
Я думаю, что это самый простой способ для написания CUDA-программ, так как требуется минимум усилий для конфигурирования и настройки среды, единственная проблема только с использованием IntelliSence.
В следующий раз будет рассмотрено использование CUDA для математических вычислений и вопросы работы с память видеокарты.
P.S. Задавайте вопросы.
Источник: habr.com
Аппаратная часть
Архитектура GPU построена несколько иначе, нежели CPU. Поскольку графические процессоры сперва использовались только для графических расчетов, которые допускают независимую параллельную обработку данных, то GPU и предназначены именно для параллельных вычислений. Он спроектирован таким образом, чтобы выполнять огромное количество потоков (элементарных параллельных процессов).
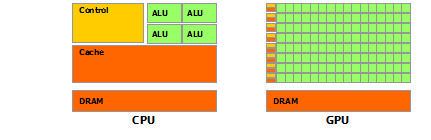
Как видно из картинки – в GPU есть много простых арифметически-логических устройств (АЛП), которые объединены в несколько групп и обладают общей памятью. Это помогает повысить продуктивность в вычислительных заданиях, но немного усложняет программирование.
«Для достижения лучшего ускорения необходимо продумывать стратегии доступа к памяти и учитывать аппаратные особенности.»
GPU ориентирован на выполнение программ с большим объемом данных и расчетов и представляет собой массив потоковых процессоров (Streaming Processor Array), что состоит из кластеров текстурных процессоров (Texture Processor Clusters, TPC). TPC в свою очередь состоит из набора мультипроцессоров (SM – Streaming Multi-processor), в каждом из которых несколько потоковых процессоров (SP – Streaming Processors) или ядер (в современных процессорах количество ядер превышает 1024).
Набор ядер каждого мультипроцессора работает по принципу SIMD (но с некоторым отличием) – реализация, которая позволяет группе процессоров, работающих параллельно, работать с различными данными, но при этом все они в любой момент времени должны выполнять одинаковую команду. Говоря проще, несколько потоков выполняют одно и то же задание.
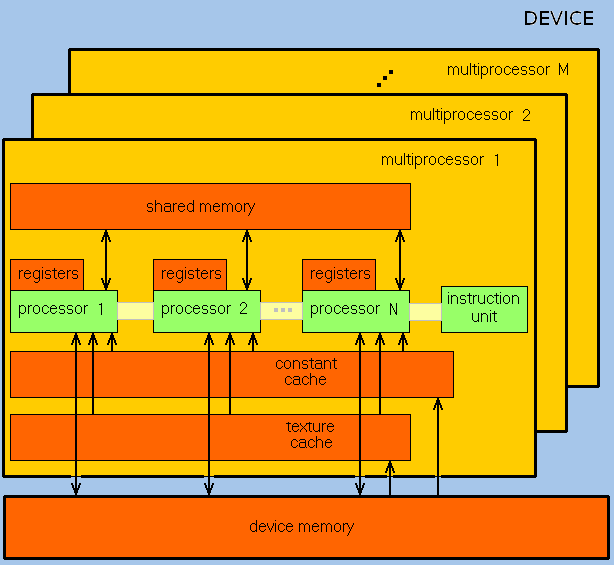
В результате GPU фактически стал устройством, которое реализует потоковую вычислительную модель (stream computing model): есть потоки входящих и исходящих данных, что состоят из одинаковых элементов, которые могут быть обработаны независимо друг от друга.
Вычислительные возможности
Продолжаем разбираться с CUDA. Каждая видеокарта обладает так называемыми compute capabilities – количественными характеристиками скорости выполнения определенных операций на графическом процессоре. Данное число показывает, насколько быстро видеокарта будет выполнять свою работу.
В NVIDIA эту характеристику обозначают Compute Capability Version. В таблице приведены некоторые видеокарты и соответствующие им вычислительные возможности:

Полный перечень можно посмотреть здесь. Compute Capability Version описывает множество параметров, среди которых: количество потоков на блок, максимальное количество блоков и потоков, размер warp, а также многое другое.
Потоки, блоки и сетки
CUDA использует большое количество отдельных потоков для расчетов. Все они группируются в иерархию – grid / block / thread.
Верхний уровень – grid – отвечает ядру и объединяет все потоки, которые выполняет данное ядро. Grid – одномерный или двумерный массив блоков (block). Каждый блок (block) представляет собой полностью независимый набор скоординированных между собой потоков. Потоки из разных блоков не могут взаимодействовать.