
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
Что такое нейронные сети? ДЛЯ НОВИЧКОВ / Про IT / Geekbrains
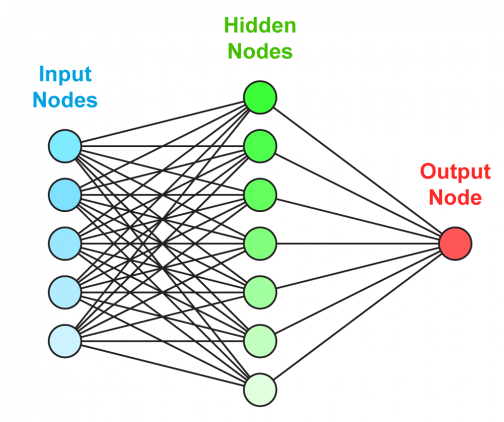
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
Прямое распространение ошибки
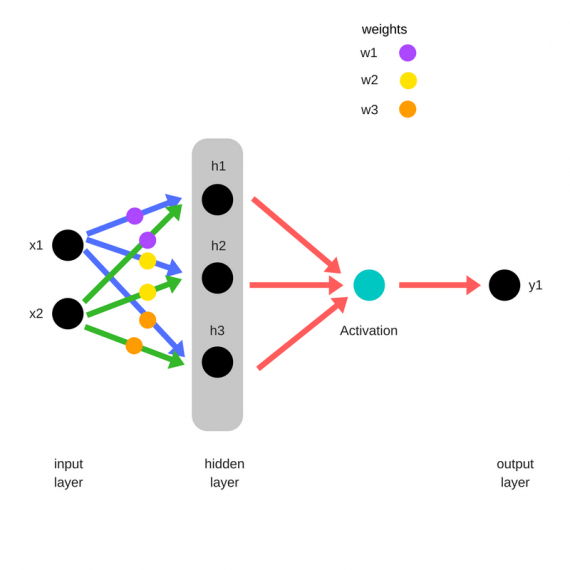
Зададим начальные веса случайным образом:
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение
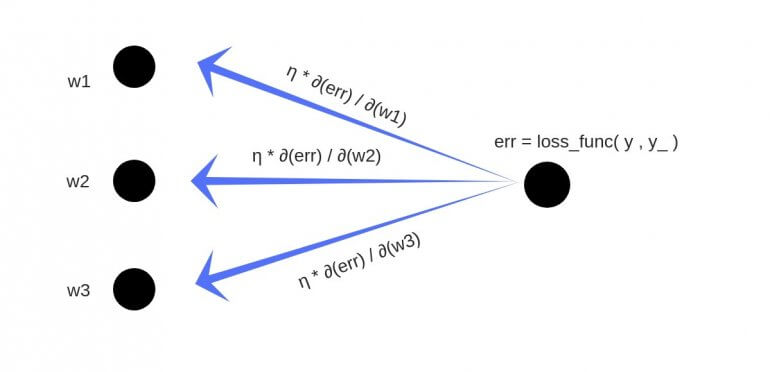
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.

Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
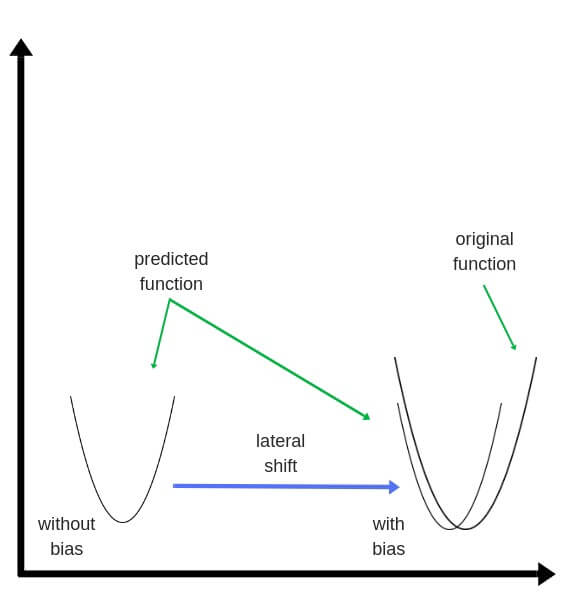
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль.
Что при этом ускоряется/замедляется? Производные скорости.
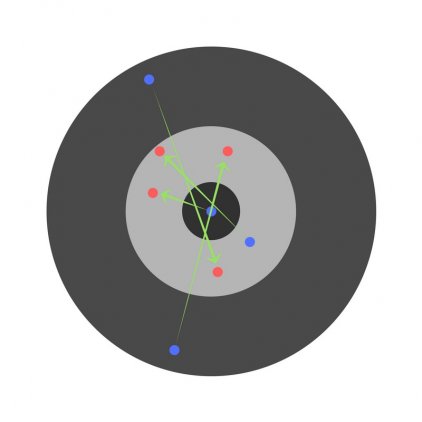
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
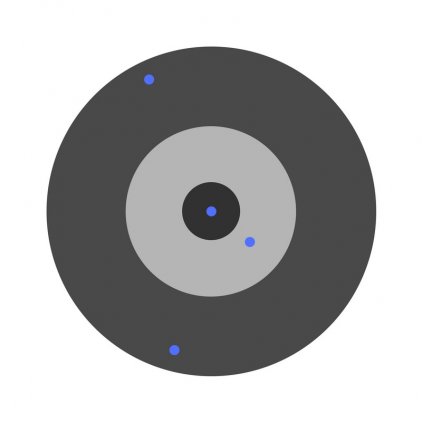
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
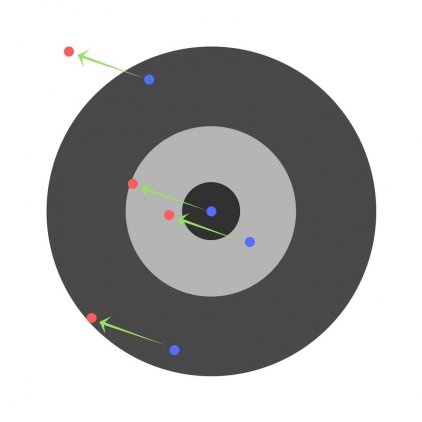
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
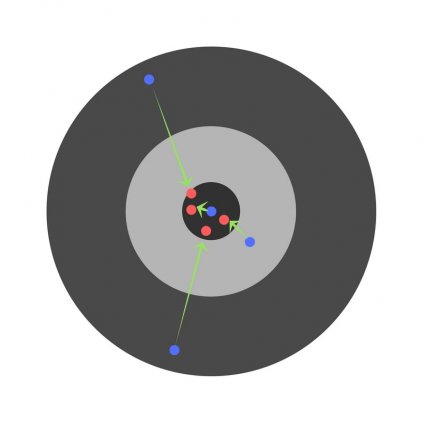
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
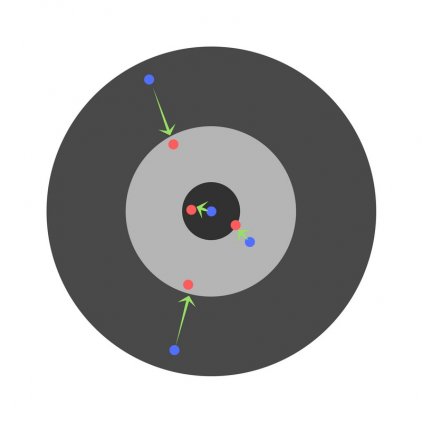
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
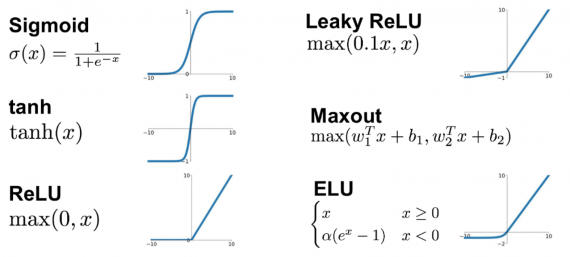
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
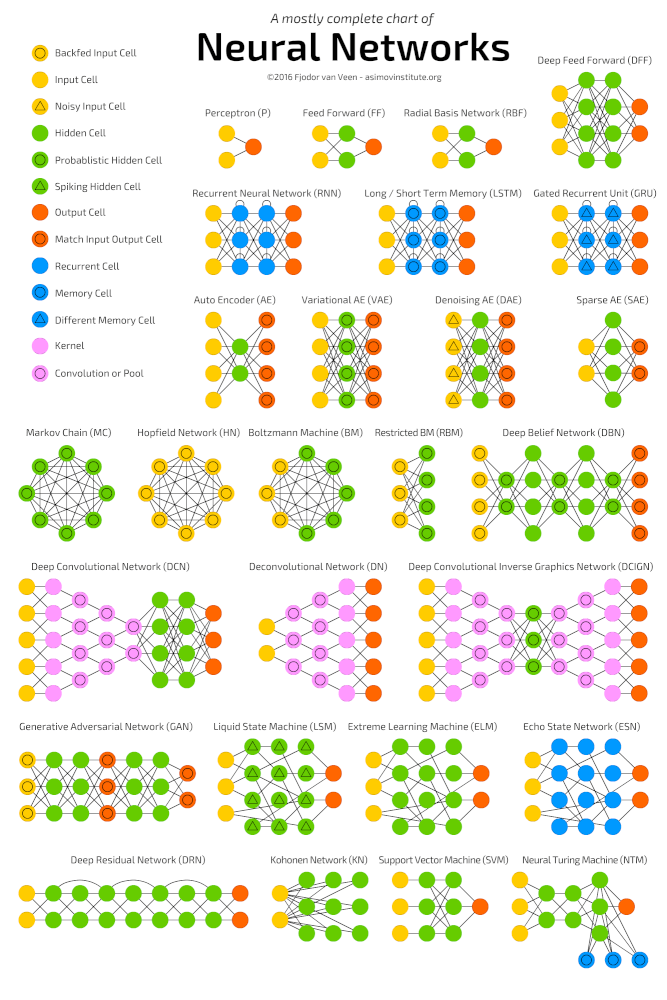
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:
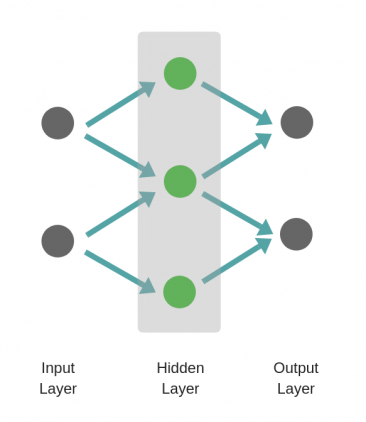
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
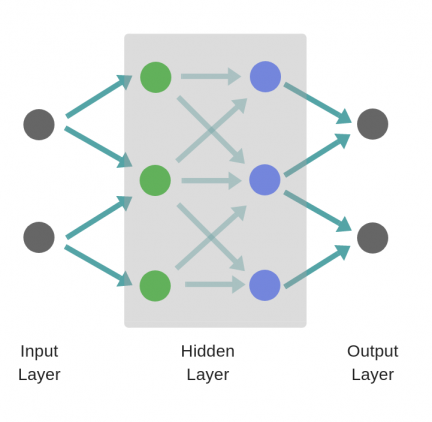
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
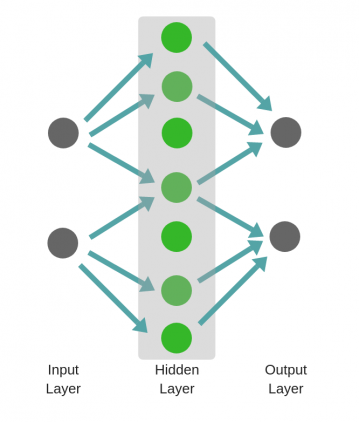
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
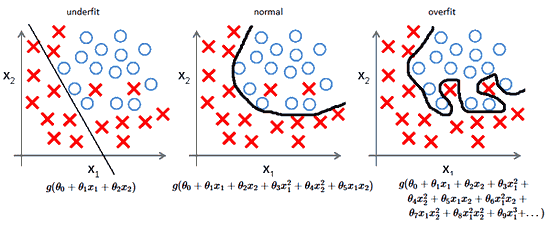
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Источник: neurohive.io
Как работают нейросети Простое объяснение в картинках

Принцип работы нейронной сети пришел в программирование из биологии. Пионерами нейросетей были не столько программисты, сколько нейрофизиологи и психологи. «Цифровой океан» разобрался, как работают нейросети — и в каком-то смысле человеческий мозг
Н ейросеть — это компьютерная программа, способная к обучению. Перед ней можно поставить практически любую задачу. И если сперва показать машине тысячу-другую верных решений, то затем она научится находить правильный ответ самостоятельно. За нейронными сетями стоит сложная математика, при этом модель компьютерной сети построена по принципу работы нервных клеток человека, то есть биологических нейронных сетей. В общем всю эту математику проще всего объяснить в картинках.
Непростое человеческое
Контекст и опыт
Перед вами десять картинок. Человек без труда узнает на всех десяти цифру 6. Для машины же это набор совершенно разных изображений, никак не связанных между собой. Что помогает человеку узнать «шестерку»? Контекст и опыт.
Контекст помогает нам разобрать даже почерк врача: если на месте буквы появляется странный крестик, мы понимаем, что это, видимо, «т» или «к». К сожалению, компьютеры на сегодняшний день мало что смыслят в контексте. Зато опыта они набираются гораздо быстрее людей. Покажите нейронной сети тысячу рукописных цифр, и она научится их различать.

На месте цифр может быть что угодно: кошки, лица, раковые опухоли. Речь идет не обязательно об изображениях: обучить программу можно на биржевых сводках, художественных текстах, аудиозаписях — любых оцифрованных данных. Но прежде, чем обучать, давайте разберемся с матчастью — какие виды структур нейронных сетей существуют.

Виды структур нейросетей
Нейронные сети прямого распространения или FFNN (от английского Feed Forward Neural Networks) имеют две входные клетки и всего одну выходную. Обучение осуществляется по принципу обратного распространения ошибки между вводом и выводом, что предполагает способность сети моделировать связь между входными и выходными слоями, генерируя определенный результат. FFNN применяются для распознавания речи, письменных символов, изображений и компьютерного зрения.
Сети радиально-базисныx функций (RBFN, radial basis function network) обладают такой же структурой, что и предыдущие с той лишь разницей, что для активации применяется радиально-базисная функция. Эта ИНС (искусственная нейронная сеть) находит применение для решения задач аппроксимации, а также классификации и прогноза временных рядов.
Нейронная сеть Хопфилда (HN, Hopfield network) характеризуется симметрией матрицы образующихся связей. Это означает, что смещение, вернее вход и выход данных осуществляется в рамках одного и того же узла. Эта нейронная сеть также имеет название сеть с ассоциативной памятью — в процессе обучения она запоминает определенные шаблоны и впоследствии возвращается к одному из них.
Автоэнкодер (Autoencoder) — сеть прямого распространения, которая умеет восстанавливать входные данные на узле выхода. Подобная структура применяется для классификации данных, сжатия и восстановления информации.
Свёрточные нейронные сети (CNN, convolutional neural networks) основное применение нашли в области распознания изображений. Технология их работы заключается в том, что она считывает изображения небольшими квадратами, потом передает информацию через сверточные слои. Логичным продолжением операции становится подключение FFNN, которые выдают определенный результат на основе полученных данных (так сверточные нейронные сети становятся глубинными). Если на обрабатываемых картинках изображена мышь, то сети констатируют этот факт.
Развёртывающие нейронные сети (DN, deconvolutional networks), как следует из их названия, обладают обратным к CNN действием. Для примера обратимся к помощи уже взятой выше мыши. Если нужно, наоборот, создать или найти картинки с изображением грызуна, для запуска функции активации DN достаточно одного этого слова, вернее, определённого бинарного вектора.
Генеративно-состязательные сети (GAN, Generative Adversarial Network) используются для досконального копирования цифровых данных, например, изображений. Применение GAN нашли в области кибербезопасности. А еще с их помощью можно наложить на фото эффект старения.

Квадратно-гнездовое
Сенсорный слой
Приступим к строительству и обучению нейронных сетей. Разделим изображение на точки (пиксели): 30 по вертикали и 30 по горизонтали. Каждый из пикселей имеет свою яркость. Пусть черные пиксели имеют значение 0, белые — 1, а градации серого дают дробные значения, например 0,4 или 0,8. Эти 900 пикселей — наши первые нейроны, точнее нейроны входного слоя, или сенсоры.

Псевдоживое многослойное
Структура нейросети
Наша нейросеть будет состоять из входного, выходного и двух промежуточных (скрытых) слоев. Входной слой воспринимает рукописные цифры и состоит из 900 нейронов. Выходной слой выдает один из десяти возможных результатов: числа от 0 до 9. Поэтому нейронов в нем будет 10, они называются реагирующими. Промежуточные слои имеют по 15 нейронов, их элементы называются ассоциативными.
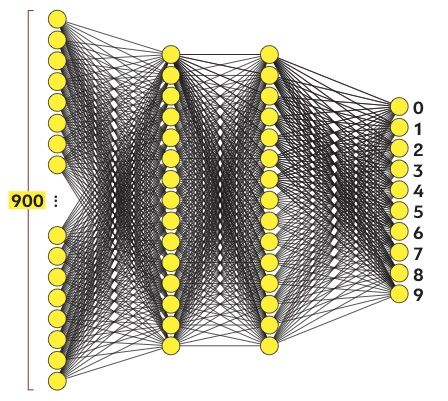
Концептуально нейроны имитируют клетки живого мозга. Как и для настоящих нейронов, для компьютерных тоже важны связи. Каждый нейрон связан со всеми нейронами соседнего слоя.
Тайное искомое
Связи и веса
Посмотрим на первый нейрон промежуточного слоя (назовем его b1). Он связан с каждым из 900 нейронов входного слоя (назовем их a1 — a900). Собственно, нейрон b1 — это математическая формула, длинная, но довольно простая. Она показывает, насколько сильно каждый из сенсоров a1 — a900 влияет на значение b1.
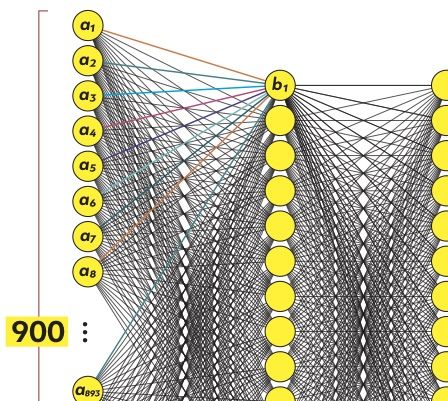
На рисунке связи нейрона b1 имеют разные цвета, чтобы показать: каждый нейрон входящего слоя имеет свой коэффициент, или вес, в общей формуле b1. Эти веса, настроенные оптимальным образом, — вот то тайное знание, которое является результатом глубокого машинного обучения.
Абстрактное обобщенное
Ассоциативные слои
Итак, процесс машинного обучения направлен на то, чтобы придать всем связям внутри искусственной нейронной сети оптимальные веса. Для чего нужны промежуточные слои? Выражаясь очень образно, они помогают машине обобщить накопленный опыт. Проведем мысленный эксперимент. Как мы, люди, узнаем шестерку?
Она состоит из кружочка и «хвостика» слева вверху.
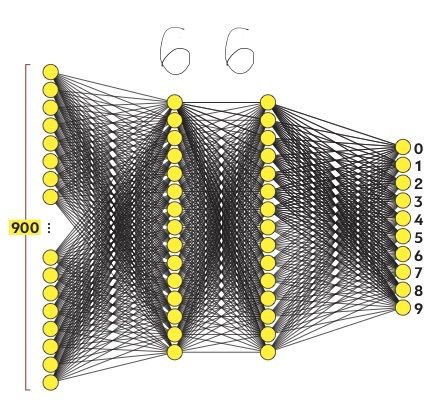
Представим, что предпоследний (второй скрытый) слой нейронной сети разбирается во взаимном расположении кружочков, «хвостиков» и «крючочков», из которых состоят цифры. А первый скрытый слой умеет выделять на картинке сами кружочки и «хвостики» по сочетанию пикселей. Если бы речь шла о человеческой логике, то скрытые слои представляли бы собой разные уровни абстракции и обобщения.
Горящее пороговое
Активация нейронов
Запустим нашу нейросеть: расставим веса в произвольном порядке, покажем сенсорам шестерку и посмотрим, какой из выходных нейронов активируется. Под активацией подразумевается превышение некоего порогового значения. Например, если формула нейрона выдает результат больше 0,8, то он «загорается», или активируется.
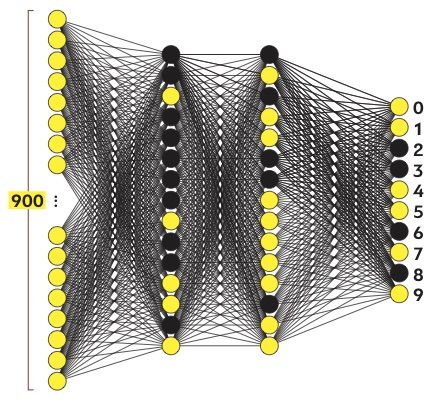
Вполне вероятно, что при первом запуске «загорелось» несколько реагирующих нейронов. Машина «признала» в шестерке и 8, и 2, и 3, и все эти результаты не имеют никакого отношения к истине. Нейросеть еще предстоит обучить.
Остроумное реверсивное
Обратное распространение ошибки
Если бы вес каждой связи искали простым перебором, процесс занял бы вечность. Сокращает путь главное ноу-хау машинного обучения — алгоритм обратного распространения ошибки. Метод обратного распространения позволяет нейронной сети, словно находчивому школьнику, подогнать значения переменных в уравнении, зная правильный ответ.
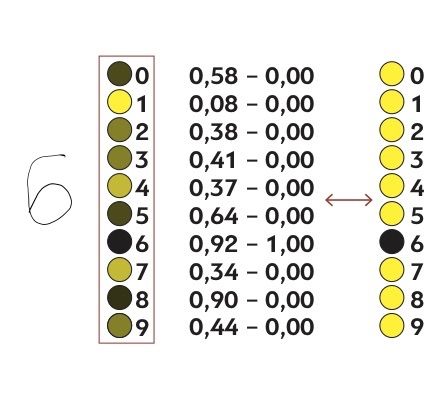
Посмотрим, насколько полученный в первой итерации результат отличается от желаемого. Допустим, нейрон, обозначающий единицу, получил значение 0,08. Это мало, как и должно быть, ведь на входе не единица. Значит, веса для связей, подключенных к этому нейрону, нужно скорректировать совсем немного. А вот нейрон, отвечающий за восьмерку, «загорелся» и показал результат 0,9.
Это никуда не годится: восьмерка не шестерка. Значит, связи этого нейрона нуждаются в сильной коррекции.
Теплое быстрое
Градиентный спуск
Говоря чуть более математическим языком, каждый набор нейронов есть функция от множества переменных — весов нейронов, стоящих за ним. Для одного выходного нейрона — того, что отвечает за шестерку, — нам нужно найти максимум этой функции. Для всех остальных — минимумы.
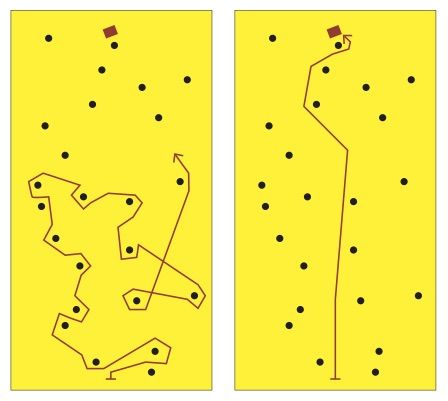
Представьте, что вам нужно найти кошелек, потерявшийся в лесу. Методично прочесать весь лес — практически невыполнимая задача. Но если что-то подсказывает вам направление движения и оставшееся расстояние до кошелька, найти его будет намного проще. Вы сперва разгонитесь до высокой скорости, а подойдя ближе к искомому объекту, замедлитесь и поищете внимательнее.
Такая технология поиска в математике называется градиентным спуском. А маячок, на который вы ориентируетесь, появляется благодаря алгоритму обратного распространения ошибки.
Среднее разнообразное
Обучение на датасетах
Посчитав, насколько сильно значения всех нейронов отличаются от желаемых, мы получим суммарную ошибку сети. Найти ее минимум было бы достаточно, если бы мы хотели научить такую сеть отличать шестерку от других цифр. Чтобы машина могла распознавать любую цифру, нужно каждый раз демонстрировать ей датасет (набор data, то есть данных) из десяти цифр и стремиться свести к минимуму среднюю ошибку для всех десяти. Сложность задачи возводится в десятую степень.

Чтобы нейросеть научилась распознавать цифры, написанные разным почерком, нужно продемонстрировать ей множество рукописных цифровых комплектов. И проделать множество вычислений, чтобы найти оптимальные средние значения для всех весов. Это ресурсоемкая задача — как по вычислительной мощности, так и в плане подготовки огромного датасета. Но результат того стоит.
Неизвестное машинное
Неразумная математика
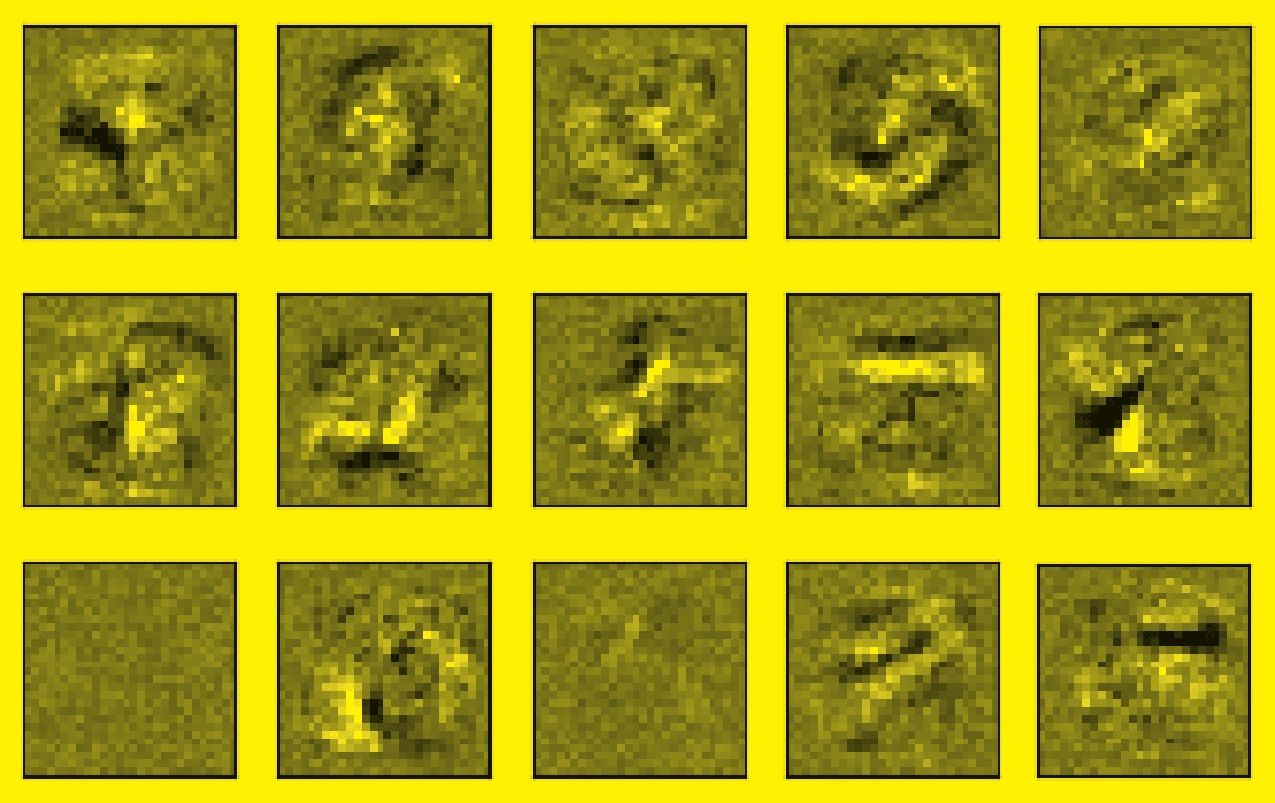
Помните разговор о кружочках и «хвостиках»? Компьютер позволяет визуализировать происходящее на скрытых уровнях нейронной сети, чтобы увидеть… что никаких кружочков там нет. Абстракция и обобщение — человеческие понятия. Нейросеть «мыслит», точнее сказать, работает совершенно по-другому. Это просто математика, а вовсе не разум.
Если показать нашей нейронной сети, скажем, фотографию кота, она с уверенностью скажет, что это три, пять или девять. Для нее весь мир состоит только из цифр, и никакой иной контекст ей неведом.
Наше журнальное объяснение нейронной сети упрощено до предела, а структура давно устарела — таким машинное обучение было в 1960-е. Современным специалистам приходится иметь дело с десятками и сотнями всевозможных параметров, не только весами и количеством слоев. И чем совершеннее становится искусственный интеллект, тем сложнее нам становится понять, что творится глубоко в его «мыслях».
Как работает блокчейн Максимально простое и полное объяснение
Блокчейн — одна из самых надежных технологий на планете. Его нельзя выключить и практически невозможно взломать. «Цифровой океан» разобрался, как работает блокчейн на примере первой и главной цепочки блоков — Биткойна
876 Комментировать —>
Источник: digitalocean.ru
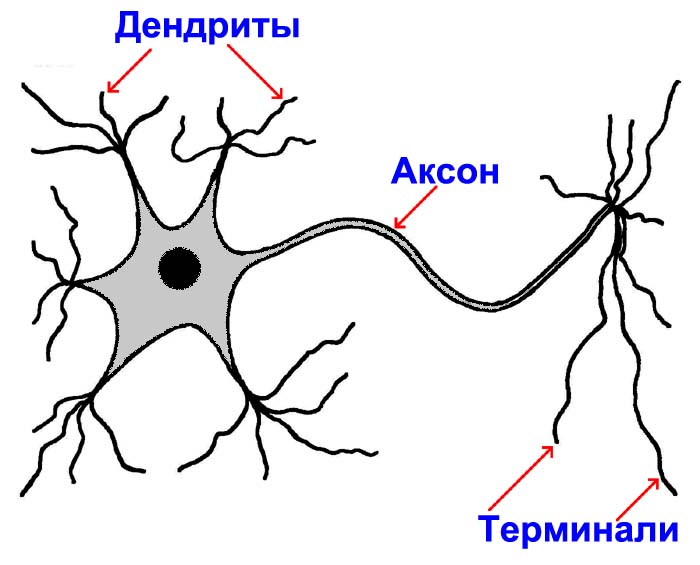
Работа нейрона
Мультиполярный нейрон имеет много коротких отростков дендритов и один длинный отросток аксон. На конце аксона идет разветвление на короткие отростки терминали. Терминали одного нейрона соединяются с дендритами других нейронов. Это соединение терминаля и дендрита называется синапсом. Благодаря этим синапсам нейроны способны обмениваться информацией между собой.
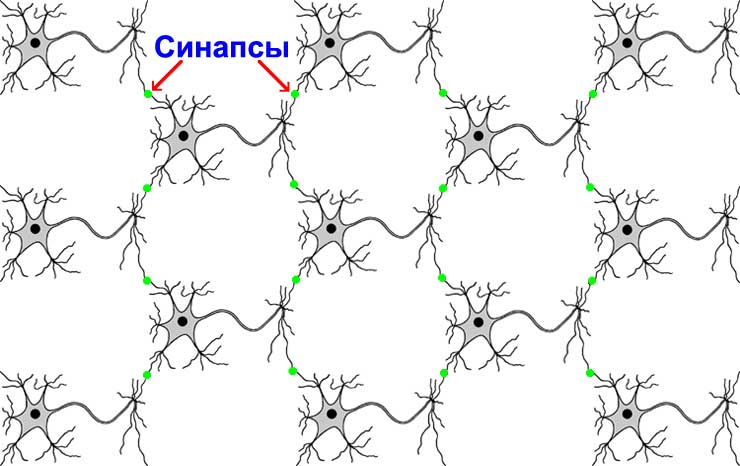
Нейронная сеть головного мозга
Все нейроны связаны друг с другом в одну общую сеть головного мозга. Количество нейронов в мозге человека примерно равно 100 миллиардам. Это столько же, сколько примерно звезд в Нашей Галактике. У каждого нейрона в среднем 7000 связей. Всего в мозге около 100 триллионов синапсов.
Аксоны могут быть очень длинными, длиной более метра. Поэтому нет никаких проблем, в наличие связей между нейронами из самых разных частей мозга. Многие из таких связей науке до сих пор непонятны и остаются загадочными. В мозге обнаружены также загадочные замкнутые цепочки связанных нейронов, назначение которых остается также очень сильно непонятным.
Передача информации между нейронами
Информация между нейронами передается и электрическими импульсами и ионами. То есть нейроны используют электрохимический способ обмена информацией.
При этом электрический импульс бежит от тела нейрона по аксону, затем по терминалям и через синапсы проходит в дендриты других нейронов. А по дендритам этих нейронов электрический сигнал попадает в тела нейронов.
Химическая передача информации происходит в синапсах. Заряженные ионы одного нейрона через синапс попадают в другой нейрон. Регулируют этот ток ионов специальные молекулы, которые называются медиаторы. Их много разных видов. Их свойством является то, что они могут изменять работу синапса и тем самым влиять на прохождение электрического тока через синапс.
Элементарная работа нейрона
В первой половине XX века были выяснены очень интересные принципиально важные свойства работы нейронов по передаче электрических сигналов.
Пока нейрон жив, он никогда не спит. В неактивном состоянии нейрон и всё время посылает другим нейронам низкочастотные импульсы с частотой от 10 Гц и выше. Он как бы дает понять другим нейронам, что он жив, и что канал связи через него работает. Эти низкочастотные импульсы он посылает через случайные промежутки времени.
В активном (возбужденном) состоянии нейрон посылает высокочастотный импульс с частотой до 200 Гц. (На самом деле, в физике высокочастотными колебаниями называют колебания из мегагерцового диапазона, но мы здесь и далее пренебрегаем этой терминологией физиков.)
Все эти электрические импульсы достаточно короткие по времени и, в общем случае, отличаются друг от друга по величине их передаваемой энергии (частоте и амплитуде). Чем выше частота импульса и его амплитуда, тем больше его энергия.
Слабый импульс (или сигнал), это импульс (или сигнал), который несет с собой относительно маленькую энергию, так как имеет низкую частоту колебаний электрического поля (и, возможно, маленькую амплитуду). Сильный сигнал (или импульс), это сигнал (или импульс), который передает относительно большую энергию.
Пороговые свойства прохождения сигнала
Первое самое замечательное свойство нейрона заключается в том, что, если в него попал слишком слабый сигнал, то этот сигнал подавляется и уже не передается другим нейронам. Такой слабый сигнал просто пропадает и всё. То есть не передаются другим нейронам не только обычные для неактивного нейрона очень низкочастотные колебания, которые приходят от нейронов в неактивном состоянии, но могут не передаваться дальше и сигналы от активных нейронов, если их частота недостаточно высокая для активации данного нейрона.
Если же сигнал достаточно сильный (имеет достаточно высокую частоту), то нейрон генерирует свой собственный сигнал, который передает по своему аксону и терминалям другим нейронам, которые связаны своими дендритами с рассматриваемым нейроном. То есть передается через нейрон не в точности сам сигнал, который в него пришел, а передается, как бы, информация о самом факте того, что в нейрон пришел достаточно сильный сигнал.
В этом смысле нейрон похож не на проводник в обычной технической цепи электрического тока, а на какой-нибудь пороговый элемент, типа транзистора. И поэтому более корректно говорить, что через нейрон передается не физический электрический сигнал со своими свойствами, а передается информация (или трансформированный сигнал).
Итак, чтобы рассматриваемый нейрон передал сигнал через себя по сети, нужно, чтобы входящий сигнал был достаточно сильным, свыше некоторого определенного порога активации нейрона.
Аккумулятивные свойства прохождения сигнала
Второе самое замечательное свойство нейрона заключается в том, что при поступлении в нейрон одновременно нескольких сигналов от разных нейронов, все эти сигналы суммируются друг с другом, и именно эта сумма учитывается при преодолении порога активации нейрона.
Чтобы понять это рассмотрим пример на картинке. Допустим, что для нарисованного нейрона порог его активации составляет некоторые 5 условных единиц энергии сигнала. Если от нейрона A пришел сигнал величиной 4 условных единицы, то наш нейрон не возбудился, так как 4 меньше величины порога активации, равного 5. Если затем от нейрона B пришел сигнал тоже величиной 4 условных единицы, то наш нейрон опять не возбудился по той же причине.
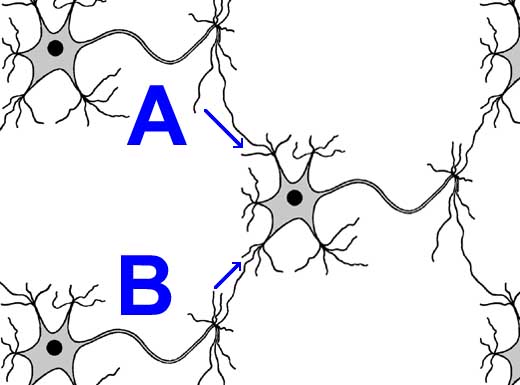
Но если эти два сигнала от нейронов A и B пришли в наш нейрон одновременно, то они складываются друг с другом. Получаем, что наш нейрон получил сигнал эквивалентный 4 + 4 = 8 единиц энергии. Это больше порога активации нашего нейрона. Поэтому наш нейрон генерирует свой собственный сигнал, который передает следующим нейронам по аксону и терминалям.
Если от нейрона A пришел сигнал равный 3 условным единицам, и одновременно от нейрона B пришел сигнал равный 1 условной единице, то порог активации преодолен не будет, так как сумма 3 + 1 = 4 меньше 5.
Нейропластичность
Еще одно свойство нейронов, которое в некоторой степени присуще искусственным нейронным сетям, это пластичность или нейропластичность. Нейропластичность, это способность нейронов принимать на себя функции, которые им изначально были не свойственны.
Нейропластичность происходит не только из-за того, что нейроны постоянно образуют всё новые и новые связи прорастанием своих аксонов, дендритов и терминалей. И не только из-за постоянного обновления старых нейронов на новые в процессе нейрогенезиса. В первую очередь нейропластичность обусловлена тем, что уже существующие нейроны могут переобучиться для того, чтобы обрабатывать совершенно новые для них сигналы.
На нейропластичности основан эффект фантомных болей у человека с ампутированными органами. Те нейроны, которые раньше отвечали за работу утраченного органа, обучаются каким-то новым функциям, а другие нейроны некоторое время ничего «не знают» об этом. Они начинают новые сигналы от тех нейронов интерпретировать, как сигналы от утраченного органа. Причем, иногда интерпретируют эти сигналы, как неправильные сигналы от органа. В результате, например, у человека с ампутированной рукой появляется ощущение, что у него начинает «болеть» палец на ампутированной руке.
Другим примером нейропластичности является, например, обостренный слух у слепых людей. Некоторые слепые люди даже успешно развивают у себя способность к эхолокации. Заходя в какое-нибудь новое помещение, они по отраженному звуку от стен и предметов могут определить размеры помещения и где находятся разные препятствия.
Синапс
Синапс, это самое интересное и удивительное в нейронных сетях. Самое интересное свойство синапса состоит в том, что в ходе передачи сигнала от одного нейрона к другому в синапсе может произойти изменение частоты и амплитуды электрического импульса. Эта модификация физических характеристик сигнала зависит от наличия тех или иных молекул медиаторов в синаптической щели (пространство между двумя нейронами в синапсе).
Молекулы медиаторов находятся в синапсе не только в пространстве между нейронами, но и на мембранах обеих нейронах. Молекулы медиаторов усиливают или уменьшают поток заряженных ионов через синапс.
Считается, что именно электрические и смешанные синапсы обуславливают электромагнитное излучение мозга. Такое электромагнитное поле головного мозга фиксируется специальными датчиками, сеточка которых крепится на голове человека. С помощью таких детекторов можно зафиксировать, как меняется электромагнитное поле при определенных мыслях человека и в простейших случаях расшифровать их.

Именно так работает гаджет для управления курсором компьютерной мышки для людей, которые или парализованны или не имеют рук, чтобы самим двигать компьютерную мышку по поверхности стола. Это устройство распознает электромагнитный сигнал от мысли человека, когда он, например, думает, что курсор должен на экране монитора подниматься вверх. Данный сигнал преобразуется в сигнал, понятный для компьютерного контроллера мышки и подается на него. В результате курсор на экране монитора действительно начинает двигаться туда, куда желает человек.
Битва экстрасенсов
Идея телепередачи «Битва экстрасенсов» на первый взгляд кажется очень здравой. Если отбросить оттуда весь колдовской шаманский антураж, то с научной точки зрения там люди, называющие себя экстрасенсами, просто пытаются читать мысли источника. Мозг источника излучает электромагнитные волны, а мозг, так называемых, экстрасенсов, должен улавливать это излучение и интерпретировать возникающие у них образы в виде какой-нибудь версии ответа на предложенное задание.
Источник всегда присутствует рядом с экстрасенсом. Если внимательно смотреть все выпуски «Битвы экстрасенсов», то нетрудно определить, кто из участников этого шоу в том или ином задании играет роль источника. Чаще всего, это один из ведущих или приглашенный гость. В задачу источника входит интенсивно думать о той версии, которую должен озвучить экстрасенс. В зависимости от того, что хочет администрация телепередачи, помочь экстрасенсу или, наоборот, завалить его, источник должен думать ту или иную версию ответа.
Но, на самом деле, это телешоу не выдерживает критики.
Во-первых, чтобы хорошо улавливать излучение синапсов другого человека, синапсы экстрасенса должны быть в точности такими же, как и те синапсы, которые излучают электромагнитное излучение. Они должны в точности совпадать по своей геометрии. Только так в принимающем синапсе произойдет резонанс и усиление полученного электромагнитного поля.
В противном случае пришедшая в синапсы экстрасенса электромагнитная волна не будет усиливаться и не сможет генерировать такие же сигналы, как в мозге источника. В результате, слабые сигналы не смогут преодолеть порог активации нейронов. И поэтому по нейронной сети экстрасенса не пойдут аналогичные сигналы, как в нейронной сети источника.
Во-вторых, не факт, что у экстрасенса структура мозга очень похожая на структуру мозга источника. Из предыдущей статьи Вы уже знаете, что у каждого человека своя индивидуальная структура нейронных связей. Поэтому даже, если в синапсах у экстрасенса произошел резонанс и сигнал от синапса преодолевает пороги активации нейронов мозга экстрасенса, то совсем не факт, что в мозгу экстрасенса создается образ, который имеет хоть какое-то отношение к тому, о чем думает источник.
Одинаковая геометрия синапсов, по идее, должна быть у однояйцовых близнецов. Если такие близнецы проживают вместе и проводят большую часть жизни вместе, то и структуры их нейросетей в чем-то похожи. Эксперименты по угадыванию цифр или игральных карт из колоды такими близнецами показывают результат, который только слегка отличается от случайного угадывания.
Упоминавшийся выше гаджет для управления курсором мышки на экране монитора обладает одним серьезным недостатком, который не позволяет внедрить его в массовое производство и продажу. Этот недостаток заключается в том, что его надо достаточно долго настраивать под каждого пользователя индивидуально. Вы не можете взять такой гаджет, которым кто-то уже успешно пользуется, и тут же начать использовать его самому. От ваших синапсов пойдут другие сигналы, которые это устройство не сможет распознать.
В-третьих, энергия электромагнитных волн уменьшается обратно пропорционально квадрату расстояния от источника. Упомянутые выше эксперименты на близнецах с угадыванием цифр и карт проводились, когда близнецы сидят спина к спине и между их черепами расстояние не более полметра. При увеличении этого расстояния свыше одного метра получается результат, который ничем не отличается от случайного угадывания.
В телешоу «Битва экстрасенсов» можно иногда увидеть, что расстояние между источником и экстрасенсом составляет несколько метров. Например, однажды при поиске спрятавшегося в лесу ребенка, одна очень активная участница битвы в азарте убежала от источника вперед метров на 20-30 и после этого правильно определила нужное направление поиска. Ну, что тут сказать. Это такое расстояние, что даже герои Гарри Поттера будут завидовать такому магическому дальнодействию.
- Нейросеть:
- Отличие мозга от компьютера
- Работа нейрона
- Математический ликбез:
- Теория групп
Источник: quarkon.ru