
ОПИСАНИЕ
Функция select (или pselect) является основной функцией
большинства программ на языке C, эффективно обрабатывающих
одновременно более одного файловового дескриптора (или
сокета). Ее аргументами являются три массива файловых
дескрипторов: readfds, writefds и exceptfds. Как правило,
при использовании select программа ожидает «изменения
состояния» одного или более файловых дескрипторов. Под
«изменением состояния» понимается появление новых символов
в потоке, с которым связан файловый дескриптор, или
появление во внутренних буферах ядра места для записи в
поток, или возникновение ошибки, связанной с файловым
дескриптором (в случае сокета или канала это происходит,
когда другая сторона закрывает соединение).
Суммируя вышесказанное, select просто следит за
несколькими файловыми дескрипторами и является стандартным
вызовом Unix для этих целей.
Массивы файловых дескрипторов называются наборами файловых
Блендер Nutribullet Select | Обзор и рецепты
дескрипторов. Каждый набор объявлен как тип fd_set и его
содержимое может быть изменено макросами FD_CLR, FD_ISSET,
FD_SET и FD_ZERO. Обычно FD_ZERO является первой
функцией, используемой со свежеобъявленным набором. После
этого, отдельные файловые дескрипторы могут быть
по-очереди добавлены с помощью FD_SET. select изменяет
содержимое наборов в соответсвие с правилами, описанными
ниже; после вызова select вы можете проверить, находится
ли ваш файловый дескриптор все еще в наборе с помощью
макроса FD_ISSET, возвращающей ноль, если дескриптор
присутствует в наборе, и отличное от нуля значение, если
не присутствует. FD_CLR удаляет файловый дескриптор из
набора, хотя практическая ценность этого в хорошей
программе сомнительна.
АРГУМЕНТЫ
readfds
Этот набор служит для слежения за операциями
чтения. После возврата из select readfds очищается
от всех дескрипторов файлов, за исключением тех,
для которых возможно немедленное чтение функциями
recv() (для сокетов) или read() (для каналов,
файлов и сокетов).
writefds
Этот набор служит для слежения за появлением места
для записи данных в любой из файловых дескрипторов
набора. После возврата из select writefds очищатся
от всех файловых дескрипторов, за исключением тех,
для которых возможна немедленная запись функциями
send() (для сокетов) или write() (для каналов,
файлов и сокетов).
exceptfds
Этот набор служит для слежения за исключениями или
ошибками, связанными с любым из файловых
дескрипторов набора. На самом деле слежение
производится за появлением внепоточных (Out of
Bounds — OOB) данных. Внепоточные данные посылаются
через сокет с помощью флага MSG_OOB и, в
действительности, exceptfds работает только для
сокетов. Более подробно об этом написанов recv(2) и
Что такое PDO. Выполняем запрос Select
send(2). После возврата из select exceptfds
очищается от всех файловых дескрипторов, кроме тех,
для которых доступны внепоточные данные. Прочитать
можно лишь один байт внепоточных данных (это
делается с помощью recv()). Записать внепоточные
данные можно в любой момент. Эта операция является
неблокируемой. Поэтому нет необходимости в
четвертом наборе, который мог бы служить для
слежения за возможностью записи внепоточных данных
в сокет.
n Это целое число содержит значение, на единицу
большеее максимального файлового дескриптора любого
из наборов. Другими словами, при добавлении
файловых дескрипторов в наборы необходимо
подсчитывать максимальное целое значение любого из
них, затем увеличить это значение на единицу и
передать как аргумент n функции select.
utimeout
Этот аргумент задает наибольшее время, которое
функция select будет ожидать изменения состояния
дескрипторов. Если за это время ничего не
произойдет, то функция возвратит управление
вызвавшей программе. Если значение этого аргумента
равно NULL, то select будет ожидать бесконечно.
utimeout может быть установлен в ноль секунд; в
этом случае select возвратит управление немедленно.
Структура struct timeval определена как
struct timeval long tv_sec; /* секунды */
long tv_usec; /* микросекунды */
>;
ntimeout
Этот аргумент имеет то же значение, что и utimeout,
но структура struct timespec позволяет указывать
время с точностью до наносекунд:
struct timespec long tv_sec; /* секунды */
long tv_nsec; /* наносекунды */
>;
sigmask
Этот аргумент содержит набор сигналов, которые
разрешены во время вызова pselect (см. sigaddset(3)
и sigprocmask(2)). В качестве аргумента может быть
передан NULL; в этом случае при входе в функцию и
выходе из нее набор разрешенных сигналов не
меняется. В этом случае функция ведет себя как
select.
ОБЪЕДИНЕНИЕ СИГНАЛОВ И СОБЫТИЙ
pselect должен использоваться как в случае если вы
ожидаете сигнала, так и в случае, если вы ожидаете данных
из файлового дескриптора. Программы, обрабатывающие
сигналы, как правило лишь выставляют в обработчике сигнала
глобальный флаг, который означает, что событие должно быть
обработано в главно цикле программы. Появление сигнала
заставит select (или pselect) вернуть управление вызвавшей
программе; при этом errno будет установлен в EINTR. Это
поведение продиктовано необходимостью обработки сигналов
программой (ее главным циклом) во избежание бесконечной
блокировки select. В главном цикле программы должно быть
условие, проверяющее глобальный флаг. Возникает вопрос: а
что если сигнал придет после проверки этого условия, но до
вызова select? В этом случае select навсегда
заблокируется, хотя и есть ожидающее событие. Для
разрешения этой проблемы существует функция pselect. Эта
функция может быть использована для маскировки сигналов,
которые не должны быть приняты нигде, кроме как внутри
pselect. Например, предположим что интересующее нас
событие — это завершение дочернего процесса. Перед
запуском главного цикла мы должны заблокировать SIGCHLD с
помощью sigprocmask. Наш вызов pselect разрешит SIGCHLD
указав изначальную маску сигналов. Программ будет
выглядеть так:
int child_events = 0;
void child_sig_handler (int x) child_events++;
signal (SIGCHLD, child_sig_handler);
>
int main (int argc, char **argv) sigset_t sigmask, orig_sigmask;
signal (SIGCHLD, child_sig_handler);
for (;;) < /* главный цикл */
for (; child_events > 0; child_events—) /* здесь обработка событий */
>
r = pselect (n, wr, orig_sigmask);
/* главная часть программы */
>
>
Обратите внимание, что вышеуказанный вызов pselect может
быть заменен:
но в этом случае все равно существует вероятность того,
что сигнал будет получен после первого вызова sigprocmask,
но до вызова select. Если вы все же решите сделать так, то
разумно, как минимум, установить конечное время ожидания,
чтобы процесс не блокировался. В настоящее время glibc
работает таким образом. Ядро Linux не имеет встроенного
вызова pselect.
ПРАКТИКУМ
Итак, какой прок от использования select? Разве нельзя
просто считывать и записывать данные в файловые
дескрипторы когда того захочется? Смысл использования
select в том, что он следит за несколькими дескрипторами
одновременно и корректно переводит процесс в режим
ожидания, когда активности не наблюдается. Таким образом
он позволяет вам одновременно обрабатывать несколько
каналов и сокетов. Программисты Unix часто попадают в
ситуацию, когда необходимо обработать ввод-вывод с более
чем одного файловго дескриптора в то время как поток
данных может быть неравномерным. Если вы создатите
последовательность вызовов read и write, то вы можете
попасть в ситуацию, когда один из вызовов будет ожидать
данные из/в файлового дескриптора, в то время как другой
будет простаивать, хотя данные для него уже появились.
select позволяет эффективно справиться с такой ситуацией.
Классический пример использования select приведен на
странице man select:
int
main(void) fd_set rfds;
struct timeval tv;
int retval;
/* Следим ввели ли что-либо в stdin (fd 0). */
FD_ZERO(
FD_SET(0,
/* Ждем до 5 секунд. */
tv.tv_sec = 5;
tv.tv_usec = 0;
retval = select(1, tv);
/* На значение tv в данный момент полагаться нельзя! */
ПРИМЕР ПЕРЕНАПРАВЛЕНИЯ ПОРТА
Пример ниже лучше демонстрирует возможности select.
Программа осуществляет перенаправление одного порта TCP на
другой.
static int forward_port;
static int listen_socket (int listen_port) struct sockaddr_in a;
int s;
int yes;
if ((s = socket (AF_INET, SOCK_STREAM, 0)) 0) FD_SET (fd2,
n = max (n, fd2);
>
if (fd1 > 0) FD_SET (fd1,
n = max (n, fd1);
>
if (fd2 > 0) FD_SET (fd2,
n = max (n, fd2);
>
Источник: linuxdoc.ru
SELECT (Transact-SQL)
Возвращает строки из базы данных и позволяет делать выборку одной или нескольких строк или столбцов из одной или нескольких таблиц в SQL Server. Полный синтаксис инструкции SELECT сложен, однако основные предложения можно вкратце описать следующим образом:
Операторы UNION, EXCEPT и INTERSECT можно использовать между запросами, чтобы сравнить их результаты или объединить в один результирующий набор.
Синтаксис
— Syntax for SQL Server and Azure SQL Database ::= [ WITH < [ XMLNAMESPACES ,] [ [. n] ] > ] [ ORDER BY ] [ ] [ OPTION ( [ . n ] ) ] ::= < | ( ) > [ < UNION [ ALL ] | EXCEPT | INTERSECT > | ( ) [. n ] ] ::= SELECT [ ALL | DISTINCT ] [TOP ( expression ) [PERCENT] [ WITH TIES ] ] < select_list >[ INTO new_table ] [ FROM < > [ . n ] ] [ WHERE ] [ ] [ HAVING < search_condition >]
— Syntax for Azure Synapse Analytics and Parallel Data Warehouse [ WITH [ . n ] ] SELECT [;] ::= [ TOP ( top_expression ) ] [ ALL | DISTINCT ] < * | column_name | expression >[ . n ] [ FROM < table_source >[ . n ] ] [ WHERE ] [ GROUP BY ] [ HAVING ] [ ORDER BY ] [ OPTION ( [ . n ] ) ]
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Remarks
Учитывая сложность инструкции SELECT, элементы ее синтаксиса и аргументы подробно представлены в предложении:
Порядок предложений в инструкции SELECT имеет значение. Любое из необязательных предложений может быть опущено; но если необязательные предложения используются, они должны следовать в определенном порядке.
Инструкции SELECT разрешено использовать в определяемых пользователем функциях только в том случае, если списки выбора этих инструкций содержат выражения, которые присваивают значения переменным, локальным для функций.
Четырехкомпонентное имя, использующее функцию OPENDATASOURCE в качестве части имени сервера, может служить в качестве исходной таблицы в любом месте инструкции SELECT, где может появляться имя таблицы. Четырехкомпонентное имя не может указываться для База данных SQL Azure.
Для инструкций SELECT, которые задействуют удаленные таблицы, существуют некоторые ограничения на синтаксис.
Логический порядок обработки инструкции SELECT
Следующие действия демонстрируют логический порядок обработки или порядок привязки инструкции SELECT. Этот порядок определяет, когда объекты, определенные в одном шаге, становятся доступными для предложений в последующих шагах.
Например, если обработчик запросов можно привязать (для доступа) к таблицам или представлениям, определенным в предложении FROM, эти объекты и их столбцы становятся доступными для всех последующих шагов. И наоборот, поскольку предложение SELECT является шагом 8, любые псевдонимы столбцов или производных столбцов, определенные в этом предложении, не могут быть объектом для ссылки предыдущих предложений. Вместе с тем к ним могут обращаться последующие предложения, например предложение ORDER BY. Фактическое физическое выполнение инструкции определяется обработчиком запросов и порядок из этого списка может значительно отличаться.
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE или WITH ROLLUP
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- В начало
Как правило, применяется предыдущая последовательность. Однако в редких случаях может быть указана другая последовательность.
Например, предположим, что в представлении есть кластеризованный индекс и представление исключает некоторые строки таблицы, а для списка столбцов SELECT представления используется инструкция CONVERT, которая изменяет тип данных с varchar на integer. В этом случае CONVERT может выполняться до выполнения предложения WHERE. Это нестандартное поведение. Если это имеет значение в вашем случае, можно изменить представление, чтобы исключить использование другой последовательности.
Разрешения
Для выборки данных требуется разрешение SELECT на таблицу или представление, которое может быть унаследовано из области более высокого уровня, например разрешение SELECT на схему или разрешение CONTROL на таблицу. Или необходимо быть членом предопределенных ролей базы данных db_datareader или db_owner либо предопределенной роли сервера sysadmin. Для создания новой таблицы с помощью SELECT INTO необходимо также разрешение CREATE TABLE и разрешение ALTER SCHEMA для схемы, которой принадлежит новая таблица.
Примеры:
В следующих примерах используется база данных AdventureWorksPDW2022 .
A. Использование SELECT для получения строк и столбцов
В этом разделе приведены три примера кода. В ходе выполнения первого примера кода возвращаются все строки (предложение WHERE не указано), а также все столбцы (используется * ) таблицы DimEmployee .
SELECT * FROM DimEmployee ORDER BY LastName;
В этом примере для достижения такого же результата используется присвоение псевдонима таблице.
SELECT e.* FROM DimEmployee AS e ORDER BY LastName;
SELECT FirstName, LastName, StartDate AS FirstDay FROM DimEmployee ORDER BY LastName;
Этот пример возвращает только строки для DimEmployee , имеющие EndDate , не равное NULL, и MaritalStatus , равное «M» (состоит в браке).
SELECT FirstName, LastName, StartDate AS FirstDay FROM DimEmployee WHERE EndDate IS NOT NULL AND MaritalStatus = ‘M’ ORDER BY LastName;
Б. Использование SELECT с заголовками столбцов и вычислениями
В следующем примере возвращаются все строки из таблицы DimEmployee и вычисляется заработная плата до вычетов для каждого сотрудника на основе их BaseRate и с учетом 40-часовой рабочей недели.
SELECT FirstName, LastName, BaseRate, BaseRate * 40 AS GrossPay FROM DimEmployee ORDER BY LastName;
В. Совместное использование DISTINCT и SELECT
В следующем примере используется DISTINCT для создания списка всех уникальных должностей в таблице DimEmployee .
SELECT DISTINCT Title FROM DimEmployee ORDER BY Title;
Г. Использование GROUP BY
В следующем примере вычисляется общий объем всех продаж за каждый день.
SELECT OrderDateKey, SUM(SalesAmount) AS TotalSales FROM FactInternetSales GROUP BY OrderDateKey ORDER BY OrderDateKey;
Так как в запросе используется предложение GROUP BY , то выводится только одна строка, содержащая общий объем продаж по каждому дню.
Д. Использование GROUP BY с несколькими группами
В следующем примере вычисляются значения средней цены и суммы продаж через Интернет за каждый день, сгруппированные по дате заказа и ключу продвижения.
SELECT OrderDateKey, PromotionKey, AVG(SalesAmount) AS AvgSales, SUM(SalesAmount) AS TotalSales FROM FactInternetSales GROUP BY OrderDateKey, PromotionKey ORDER BY OrderDateKey;
Е. Использование GROUP BY и WHERE
В следующем примере после извлечения строк, содержащих даты заказов позднее 1 августа 2002 г., происходит их разделение на группы.
SELECT OrderDateKey, SUM(SalesAmount) AS TotalSales FROM FactInternetSales WHERE OrderDateKey > ‘20020801’ GROUP BY OrderDateKey ORDER BY OrderDateKey;
Ж. Использование GROUP BY с выражением
В следующем примере производится группировка с помощью выражения. Группировку можно производить только с помощью выражения, не содержащего агрегатных функций.
SELECT SUM(SalesAmount) AS TotalSales FROM FactInternetSales GROUP BY (OrderDateKey * 10);
З. Использование GROUP BY с ORDER BY
В следующем примере вычисляется сумма продаж за день и выполняется поиск заказов по определенному дню.
SELECT OrderDateKey, SUM(SalesAmount) AS TotalSales FROM FactInternetSales GROUP BY OrderDateKey ORDER BY OrderDateKey;
И. Использование предложения HAVING
Для ограничения результатов поиска в этом запросе используется предложение HAVING .
SELECT OrderDateKey, SUM(SalesAmount) AS TotalSales FROM FactInternetSales GROUP BY OrderDateKey HAVING OrderDateKey > 20010000 ORDER BY OrderDateKey;
Источник: learn.microsoft.com
Оператор SELECT
Наиболее используемым, но и самым сложным оператором является оператор выборки SELECT. Он позволяет производить выборку данных из таблиц и преобразовывать к нужному виду полученные результаты.
20 дек. 2020 · 9 минуты на чтение
Результатом выполнения оператора SELECT является таблица. К этой таблице может быть снова применен оператор SELECT и т.д., то есть такие операторы могут быть вложены друг в друга. Вложенные операторы SELECT называют подзапросами.
Синтаксис оператора SELECT использует следующие основные предложения:
SELECT FROM [WHERE ] [GROUP BY ] [HAVING ] [ORDER BY ]
Кратко пояснить смысл предложений оператора SELECT можно следующим образом:
- SELECT — выбрать данные из указанных столбцов и (если необходимо) выполнить перед выводом их преобразование в соответствии с указанными выражениями и (или) функциями
- FROM — из перечисленных таблиц, в которых расположены эти столбцы
- WHERE — где строки из указанных таблиц должны удовлетворять указанному перечню условий отбора строк
- GROUP BY — группируя по указанному перечню столбцов с тем, чтобы получить для каждой группы единственное значение
- HAVING — имея в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора групп
- ORDER BY — сортируя по указанному перечню столбцов
Как видно из синтаксиса рассматриваемого оператора, обязательными являются только два первых предложения: SELECT и FROM .
Рассмотрим каждое предложение оператора SELECT .
Спонсор поста
База данных для примеров
Дальше будет много примеров и логично постоянно использовать одну и ту же БД. Так что на основании базы данных ниже будут продемонстрированы все примеры, не только в этой статье, но и в других.
Постановка задачи: пусть требуется разработать БД для предметной области «Поставка деталей»!
Требуется хранить следующую информацию:
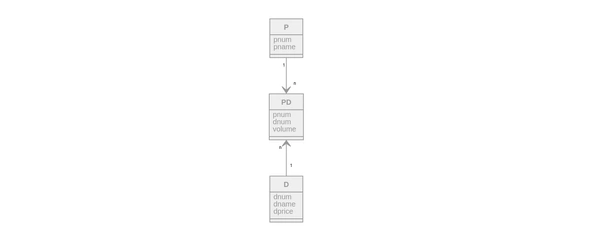
- О поставщиках (P) pnum, pname
- О деталях (D) pnum, dname, dprice
- О поставках (PD) volume
Значения таблицы P
| 1 | Иванов |
| 2 | Петров |
| 3 | Сидоров |
| 4 | Кузнецов |
Значения таблицы D
| 1 | Болт | 10 |
| 2 | Гайка | 20 |
| 3 | Винт | 30 |
Значения таблицы PD
| 1 | 1 | 100 |
| 1 | 2 | 100 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 1 | 2 | 250 |
| 3 | 1 | 1000 |
Предложение SELECT
После служебного слова SELECT перечисляются имена столбцов, значения которых будут входить в результат выполнения запроса.
Столбцы в результирующей таблице размещаются в том порядке, в котором они были указаны в предложении SELECT . Имена столбцов указываются через запятую.
Если имя столбца содержит пробелы или разделители, то его необходимо заключить в квадратные скобки.
При обработке данных из разных таблиц может возникнуть ситуация, когда столбцы разных таблиц имеют одинаковые имена. В этом случае имя столбца необходимо записывать как составное, указывая перед ним имя соответствующей таблицы: .
Предложение FROM
В предложении FROM перечисляются имена таблиц, которые содержат столбцы, указанные после слова SELECT .
Пример 1.
Вывести список наименований деталей из таблицы D (“Детали”).
SELECT dname FROM D
Пример 2.
Получить всю информацию из таблицы D (“Детали”).
Получить результат можно двумя способами:
-
Явным указанием всех столбцов таблицы.
SELECT dnum, dname, dprice FROM D
SELECT * FROM D
В результате и первого и второго запроса получаем новую таблицу, представляющую собой полную копию таблицы D (“Детали”).
Можно осуществить выбор отдельных столбцов и их перестановку.
Пример 3.
Получить информацию о наименовании и номере поставщика.
SELECT pname, pnum FROM P
Пример 4.
Определить номера поставщиков, которые поставляют детали в настоящее время (то есть номера тех поставщиков, которые присутствуют в таблице PD (“Поставки”)).
SELECT pnum FROM PD
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |

Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с SELECT и FROM , можно ненадолго снова вернуться к SELECT .
Агрегатные функции
В операторе SELECT можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде: ()
Пользователю доступны следующие агрегатные функции:
- SUM ‑ вычисляет сумму множества значений указанного столбца;
- COUNT ‑ вычисляет количество значений указанного столбца;
- MIN / MAX ‑ определяет минимальное/максимальное значение в указанном столбце;
- AVG ‑ вычисляет среднее арифметическое значение множества значений столбца;
- FIRST / LAST ‑ определяет первое/последнее значение в указанном столбце.
Пример 5.
Определить общий объем поставляемых деталей.
SELECT SUM(volume) FROM PD
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все NULL -значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции COUNT возможен особый вариант использования — COUNT(*) . Его назначение состоит в подсчете всех строк в результирующей таблице, включая NULL -значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: MAX(SUM(VOLUME))
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция AS . Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
SELECT SUM(volume) AS SUM FROM PD
Пример 6.
Определить количество поставщиков, которые поставляют детали в настоящее время.
SELECT COUNT(pnum) AS COUNT FROM PD
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6. Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения.
Операция DISTINCT
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово DISTINCT .
SELECT COUNT(DISTINCT pnum) AS COUNT FROM PD
DISTINCT можно задать только один раз для одного предложения SELECT .
Противоположностью DISTINCT является операция ALL . Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
Операция TOP
Итоговый набор записей, получаемых после выполнения запроса можно ограничить первыми N строками или первыми N процентами от общего количества строк результата.
Для этого используется операция TOP , которая записывается в предложении SELECT следующим образом: SELECT TOP N [PERCENT]
Пример 7.
Определить номера первых двух деталей таблицы D.
SELECT TOP 2 dnum FROM D
Стандарт SQL требует, чтобы при сортировке NULL -значения трактовались либо как превосходящие, либо как уступающие по сравнению со всеми остальными значениями. Так как конкретный вариант стандартом не оговаривается, то в зависимости от используемой СУБД при сортировке NULL -значения следуют до или после остальных значений. В MS SQL Server NULL -значения считаются уступающими по сравнению с остальными значениями.
Рандомный блок
Предложение WHERE
После служебного слова WHERE указываются условия выбора строк, помещаемых в результирующую таблицу. Существуют различные типы условий выбора:
Типы условий выбора:
- Сравнение значений атрибутов со скалярными выражениями, другими атрибутами или результатами вычисления выражений.
- Проверка значения на принадлежность множеству.
- Проверка значения на принадлежность диапазону.
- Проверка строкового значения на соответствие шаблону.
- Проверка на наличие null -значения.
Сравнение
В языке SQL используются традиционные операции сравнения = , <> , < , , >= .
В качестве условия в предложении WHERE можно использовать сложные логические выражения, использующие атрибуты таблиц, константы, скобки, операции AND , OR , отрицание NOT .
Пример 8.
Определить номера деталей, поставляемых поставщиком с номером 2.
SELECT dnum FROM PD WHERE pnum = 2
Пример 9.
Получить информацию о поставщиках Иванов и Петров.
SELECT * FROM P WHERE pname=’Иванов’ OR pname=’Петров’
Строковые значения атрибутов заключаются в апострофы.
Проверка на принадлежность множеству
Операция IN проверяет, принадлежит ли значение атрибута заданному множеству.
Пример 10.
Получить информацию о поставщиках ‘Иванов’ и ‘Петров’.
SELECT * FROM P WHERE pname IN (‘Иванов’,’Петров’)
Пример 11.
Получить информацию о деталях с номерами 1 и 2.
SELECT * FROM D WHERE dnum IN (1, 2)
Проверка на принадлежность диапазону
Операция BETWEEN определяет минимальную и максимальную границу диапазона, в которое должно попадать значение атрибута. Обе границы считаются принадлежащими диапазону.
Пример 12.
Определить номера деталей, с ценой от 10 до 20 рублей.
SELECT dnum FROM D WHERE dprice BETWEEN 10 AND 20
Пример 13.
Вывести наименования поставщиков, начинающихся с букв от ‘К’ по ‘П’.
SELECT pname FROM P WHERE pname BETWEEN ‘К’ AND ‘Р’
Сравнение символов
Буква Р в условии запроса объясняется тем, что строки сравниваются посимвольно. Для каждого символа при этом определяется код. Для нашего случая справедливо условие: П < Петров < Р
Проверка строкового значения на соответствие шаблону
Операция LIKE используется для поиска подстрок. Значения столбца, указываемого перед служебным словом LIKE сравниваются с задаваемым после него шаблоном. Форматы шаблонов различаются в конкретных СУБД.
Для СУБД MS SQL Server:
- Символ % заменяет любое количество любых символов.
- Символ _ заменяет один любой символ.
- [] ‑ вместо символа строки может быть подставлен один любой символ из множества возможных, указанных в ограничителях.
- [^] ‑ вместо символа строки может быть подставлен любой из символов кроме символов из множества, указанного в ограничителях.
Множество символов в квадратных скобках можно указывать через запятую, либо в виде диапазона.
Пример 14.
Вывести фамилии поставщиков, начинающихся с буквы И .
SELECT pname FROM P WHERE pname LIKE ‘И%’
Пример 15.
Вывести фамилии поставщиков, начинающихся с букв от К по П .
SELECT pname FROM P WHERE dname LIKE ‘[К-П]%’
Проверка на наличие null -значения
Операции IS NULL и IS NOT NULL используются для сравнения значения атрибута со значением NULL .
Пример 16.
Определить наименования деталей, для которых не указана цена.
SELECT dname FROM D WHERE dprice IS NULL
Пример 17.
Определить номера поставщиков, для которых указано наименование.
SELECT pnum FROM P WHERE pname IS NOT NULL
Предложение GROUP BY
Использование GROUP BY позволяет разбивать таблицу на логические группы и применять агрегатные функции к каждой из этих групп. В результате получим единственное значение для каждой группы.
Обычно предложение GROUP BY применяют, если формулировка задачи содержит фразу «для каждого…», «каждому..» и т.п.
Пример 18.
Определить суммарный объем деталей, поставляемых каждым поставщиком.
SELECT pnum, SUM(VOLUME) AS SUM FROM PD GROUP BY pnum
| 1 | 600 |
| 2 | 400 |
| 3 | 1000 |
Выполнение запроса можно описать следующим образом: СУБД разбивает таблицу PD на три группы, в каждую из групп помещаются строки с одинаковым значением номера поставщика. Затем к каждой из полученных групп применяется агрегатная функция SUM, что дает единственное итоговое значение для каждой группы.
Рассмотрим два похожих примера. В примере 19 определяется минимальный объем поставки каждого поставщика. В примере 20 определяется объем минимальной поставки среди всех поставщиков.
Пример 19:
SELECT pnum, MIN(VOLUME) AS MIN FROM PD GROUP BY pnum
Пример 20:
SELECT MIN(VOLUME) AS MIN FROM P
Результаты запросов представлены в следующей таблице:
| 1 | 100 | 100 |
| 2 | 150 | |
| 3 | 1000 |
Следует обратить внимание, что в первом примере мы можем вывести номера поставщиков, соответствующие объемам поставок, а во втором примере – не можем.
Все имена столбцов, перечисленные после ключевого слова SELECT должны присутствовать и в предложении GROUP BY , за исключением случая, когда имя столбца является аргументом агрегатной функции.
Однако в предложении GROUP BY могут быть указаны имена столбцов, не перечисленные в списке вывода после ключевого слова SELECT .
Если предложение GROUP BY расположено после предложения WHERE , то группы создаются из строк, выбранных после применения WHERE .
Пример 21.
Для каждой из деталей с номерами 1 и 2 определить количество поставщиков, которые их поставляют, а также суммарный объем поставок деталей.
SELECT dnum, COUNT(pnum) AS COUNT, SUM(volume) AS SUM FROM PD WHERE dnum=1 OR dnum=2 GROUP BY dnum
| 1 | 3 | 1250 |
| 2 | 2 | 450 |
Чтобы организовать вложенные группировки, после GROUP BY следует указать несколько группирующих столбцов через запятую. В этом случае реальный подсчет данных будет происходить по той группе, которая указана последней.
Предложение HAVING
Предложение HAVING определяет критерий, согласно которому, определенные группы, сформированные с помощью предложения GROUP BY , исключаются из результирующей таблицы.
Выполнение предложения HAVING сходно с выполнением предложения WHERE . Но предложение WHERE исключает строки до того, как выполняется группировка, а предложение HAVING — после. Поэтому предложение HAVING может содержать агрегатные функции, а предложение WHERE — не может.
Пример 22.
Определить номера поставщиков, поставляющих в сумме более 500 деталей.
SELECT pnum, SUM(volume) AS SUM FROM PD GROUP BY pnum HAVING SUM(volume) > 500
| 1 | 600 |
| 3 | 1000 |
Пример 23.
Определить номера поставщиков, которые поставляют только одну деталь.
SELECT pnum, COUNT(dnum) AS COUNT FROM PD GROUP BY pnum HAVING COUNT(dnum) = 1
Предложение ORDER BY
При выполнении запроса СУБД возвращает строки в случайном порядке. Предложение ORDER BY позволяет упорядочить выходные данные запроса в соответствии со значениями одного или нескольких выбранных столбцов.
Можно задать возрастающий — ASC (от слова Ascend) или убывающий — DESC (от слова Descend) порядок сортировки. По умолчанию принят возрастающий порядок сортировки.
Пример 24.
Отсортировать таблицу PD в порядке возрастания номеров поставщиков, а строки с одинаковыми значениями pnum отсортировать в порядке убывания объема поставок.
SELECT pnum, volume, dnum FROM PD ORDER BY pnum ASC, volume DESC
| 1 | 300 | 3 |
| 1 | 200 | 2 |
| 1 | 100 | 1 |
| 2 | 250 | 2 |
| 2 | 150 | 1 |
| 3 | 1000 | 1 |
Операцию TOP удобно применять после сортировки результирующего набора с помощью предложения ORDER BY .
Пример 25.
Определить номера первых двух деталей с наименьшей стоимостью.
SELECT TOP 2 dnum FROM D ORDER BY dprice ASC
Следует отметить, что если в таблице D будут две детали без указания цены, то именно их и отобразит предыдущий запрос. Поэтому при наличии NULL -значений их необходимо исключать с помощью предложения WHERE .
SELECT TOP 2 dnum FROM D WHERE dprice IS NOT NULL ORDER BY dprice ASC
Заключение
В статье было рассмотрен оператор выборки SELECT . Знание оператора SELECT является ключевым при написании любых SQL-запросов. Он позволяет производить выборку данных из таблиц и преобразовывать результаты в соответствии с нужными выражениями и функциями.
Результатом выполнения оператора SELECT является таблица, которую можно вложить в другой оператор SELECT в качестве подзапроса.
Синтаксис оператора SELECT содержит несколько предложений, из которых обязательными являются только SELECT и FROM . Остальные предложения, такие как WHERE , GROUP BY , HAVING и ORDER BY , могут использоваться по желанию для уточнения выборки данных.
Источник: struchkov.dev