
Segment — сервис, собирающий информацию о пользователях для дальнейшего экспорта в хранилища данных или аналитические платформы. Благодаря интеграции с сотнями различных сервисов, можно собирать показатели из разнообразных устройств, перерабатывать в единый массив данных, а затем отправлять в любую систему или приложение для анализа и создания отчётов.
Благодаря возможности обработки большого объёма информации, сервис в первую очередь будет полезен крупным компаниям с клиентами, которые покупают товары или услуги, пользуясь десятками разных каналов. При этом Segment содержит понятные инструкции о том, как экспортировать сведения из различных устройств и сервисов, что делает платформу доступной не только для разработчиков, но и для маркетологов.
Segment работает с аналитическими сервисами, которые собирают сведения с мобильных устройств, компьютеров, облачных сервисов, трекингов электронной почты, рекламных кампаний. За счёт отказоустойчивых библиотек гарантируется защита от потери данных. Также есть возможность отслеживать поведение аудитории в режиме реального времени. База знаний содержит советы о том, как сервисы, с которыми интегрируется Segment, помогают улучшить продукт клиента. Например, для мобильного приложения предлагается провести исследования о его использовании, переместить часть процессов на сторонний сервер и оптимизировать уведомления для того, чтобы уменьшить размер приложения и сэкономить расходование батареи телефона.
ПРОГРАММА ДЛЯ БИЗНЕС ПАРТНЕРОВ В ОКТЯБРЕ СЕГМЕНТ 1
Ключевые особенности
- Интеграция с сотней сервисов и хранилищ данных
- Сбор данных с различных устройств
- Анализ в режиме реального времени
- API
Видео и скриншоты Segment
Тарифы Segment
Бесплатный тариф Да
Пробный период 14 дней
Цена от 100 usd в месяц
10000 отслеживаемых пользователей, неограниченное число источников данных и направлений для экспорта, 1 хранилище данных с синхронизацией 2 раза в день, 7 аккаунтов
Цена до 0 usd в месяц
стоимость 10 долларов за 1000 отслеживаемых пользователей, неограниченное число источников данных и направлений для экспорта, неограниченное число хранилищ данных, синхронизация по желанию клиента, неограниченное число аккаунтов, кросс-доменная аналитика, возможность загрузки исторических данных, персональный менеджер, инженерная поддержка
Источник: coba.tools
Организация памяти процесса
Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем.
B2B сегмент: что это и что вообще о нем нужно знать | SEMANTICA
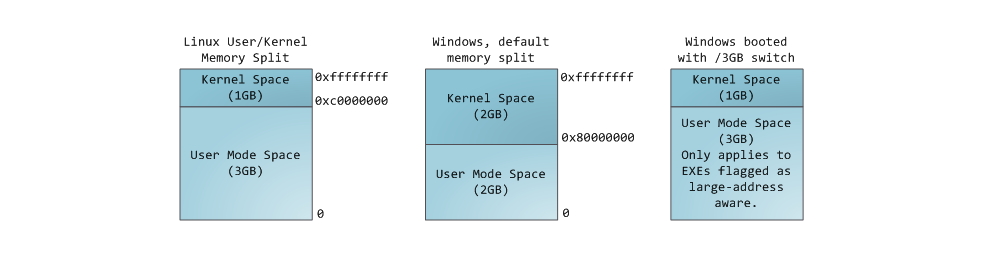
Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table).
Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).
Это конечно не значит, что ядро занимает все это пространство, просто данный диапазон адресов может быть использован для мэппирования любой части физического адресного пространства по выбору ядра. Страницы памяти, соответствующие kernel space, помечены в таблицах страниц как доступные исключительно для привилегированного кода (кольцо 2 или более привилегированное).
При попытке обращения к этим страницам из user mode кода генерируется page fault. В случае с Linux, kernel space всегда присутствует в памяти процесса, и разные процессы мэппируют kernel space в одну и ту же область физической памяти. Таким образом, код и данные ядра всегда доступны при необходимости обработать прерывание или системный вызов. В противоположность, оперативная память, замэппированная в user mode space, меняется при каждом переключении контекста.

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти.
Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:

Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей.
Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным.
И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается.
Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент.
Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows.
Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Кстати о куче. Она идет следующей в нашем описании адресного пространства процесса. Подобно стеку, куча используется для выделения памяти во время выполнения программы. В отличие от стека, память, выделенная в куче, сохранится после того, как функция, вызвавшая выделение этой памяти, завершится. Большинство языков предоставляют средства управления памятью в куче.
Таким образом, ядро и среда выполнения языка совместно осуществляют динамическое выделение дополнительной памяти. В языке C, интерфейсом для работы с кучей является семейство функций malloc(), в то время как в языках с поддержкой garbage collection, вроде C#, основной интерфейс – это оператор new.
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk).
Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

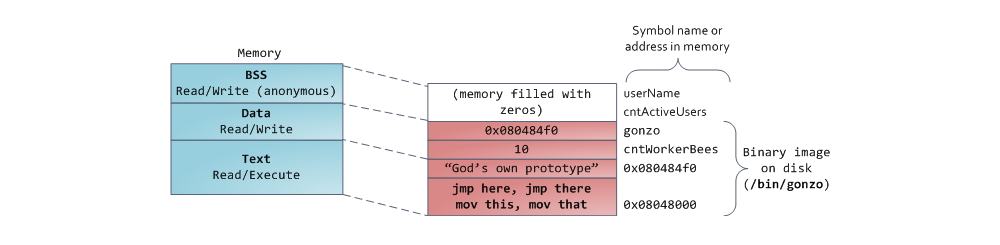
Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
С указателями все немножко посложнее. В примере из наших диаграмм, содержимое объекта, соответствующего переменной gonzo – это 4-байтовый адрес – размещается в data сегменте. А вот строка, на которую ссылается указатель, не попадет в data сегмент.
Строка будет находиться в сегменте кода, который доступен только на чтение и хранит весь Ваш код и такие мелочи, как, например, строковые литералы (в действительности, строка хранится в секции .rodata, которая вместе с другими секциями, содержащими исполняемый код, рассматривается как сегмент, который загружается в память с правами на выполнение кода / чтения данных – прим. перевод.). В сегмент кода также мэппируется часть исполняемого файла. Если Ваша программа попытается осуществить запись в text сегмент, то заработает Segmentation Fault. Это позволяет бороться с «бажными» указателями, хотя самый лучший способ борьбы с ними – это вообще не использовать C. Ниже приведена диаграмма, изображающая сегменты и переменные из наших примеров:
Segment
API для аналитики и хаб для сбора данных о пользователях.
Похожие на Segment
Описание Segment
Segment — это веб-платформа и API для веб-аналитики и сбора данных о пользователях для дальнейшей их отправки на сотни инструментов или хранилищ данных.
Segment поможет разобраться в данных о клиентах, поступающих из различных источников. Приложение интегрируется с сотнями других сервисов, обрабатывая их данные в единую платформу. Он также извлекает данные с веб-сайтов, мобильных устройств, браузеров, часов, iBeacons, пунктов продажи и др.
С помощью Segment можно экспортировать данные в любую внутреннюю систему и приложение, воспроизводить исторические данные, просматривать события в режиме реального времени, например, когда кто-то совершает покупку на сайте или в приложении.
Основные характеристики Segment:
- Управление данными клиентов.
- Сотни интеграций.
- Запрос данных в Amazon Redshift.
- Визуализация данных SQL.
- Воспроизведение исторических данных.
- Отправка данных с устройств.
- Извлечение данных с POS, iBeacons, умных часов.
- Аналитика для электронной коммерции.
- Аналитика событий в режиме реального времени.
- Текущие события в потоке.
- API.
- Исходные данные.
- Приглашения соавторов.
- Неограниченные проекты.
- Интеграция Webhook.
Контакты Segment
Сайт: https://segment.com/
Основан в 2011 г.
Сервисы, с которыми у Segment есть интеграция
Яндекс.Метрика MailChimp Zendesk Freshdesk Google Analytics Slack HubSpot Intercom Mixpanel Salesforce Sales Cloud
Источник: startpack.ru