
Оперативная аналитическая обработка (OLAP) — это технология, которая упорядочивает большие коммерческие базы данных и поддерживает сложный анализ. Ее можно использовать для выполнения сложных аналитических запросов без негативного воздействия на системы транзакций.
Базы данных, в которых компании хранят свои транзакции и записи, называются базами данных оперативной обработки транзакций (OLTP). Такие базы данных обычно содержат записи, которые вводятся поочередно. Часто они содержат много ценных для организации сведений. Но базы данных, используемые для OLTP, не предназначены для анализа.
Поэтому извлечение ответов из этих баз данных требует много времени и усилий. Системы OLAP предназначены для извлечения этих сведений бизнес-аналитики из данных максимально оптимальным способом. Это достигается благодаря тому, что базы данных OLAP оптимизированы для рабочих нагрузок с большим числом операций чтения и малым числом операций записи.
Многомерные базы данных
Семантическое моделирование
Семантическая модель данных — это концептуальная модель, в которой описаны значения содержащихся в ней элементов данных. Организации часто используют собственные термины, иногда синонимы или даже разные значения одного и того же термина. Например, база данных инвентаризации может отслеживать компонент оборудования с ИД ресурса и серийным номером. Но база данных по продажам может ссылаться на серийный номер как на идентификатор ресурса. Эти значения сложно связать без модели, в которой бы описывалась связь.
Семантическое моделирование обеспечивает абстракцию на уровне схемы базы данных. В этом случае пользователям не требуются знания о базовых структурах данных. Семантическое моделирование также упрощает подачу запросов данных для пользователей: им не нужно выполнять вычисления и соединения в базовой схеме. Кроме того, обычно имена столбцов преобразуются в понятные пользователям названия, чтобы контекст и значение данных были очевидными.
Семантическое моделирование преимущественно используется для сценариев с большим числом операций чтения, например для аналитики и бизнес-аналитики (OLAP), которые отличаются от обработки данных о транзакциях с большим числом операций записи (OLTP). В основном это связано с особенностями типичного семантического слоя:
- поведение агрегатов задано так, чтобы в средствах создания отчетов правильно отображались соответствующие данные;
- определены бизнес-логика и вычисления;
- включены ориентированные на время вычисления;
- данные часто интегрируются из нескольких источников.
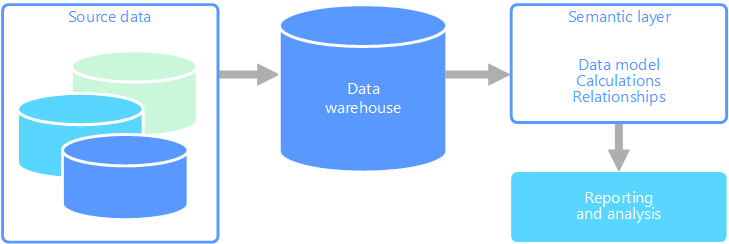
По этим причинам семантический слой обычно размещается над хранилищем данных.
BIWEB (#2) Что такое Сводные таблицы Excel и OLAP кубы
Есть два основных типа семантических моделей:
- Табличная. Используются реляционные конструкции моделирования (модели, таблицы, столбцы). На внутреннем уровне метаданные наследуются из конструкций моделирования OLAP (кубы, измерения, меры). В коде и скрипте используются метаданные OLAP.
- Многомерная. Используются традиционные конструкции моделирования OLAP (кубы, измерения, меры).
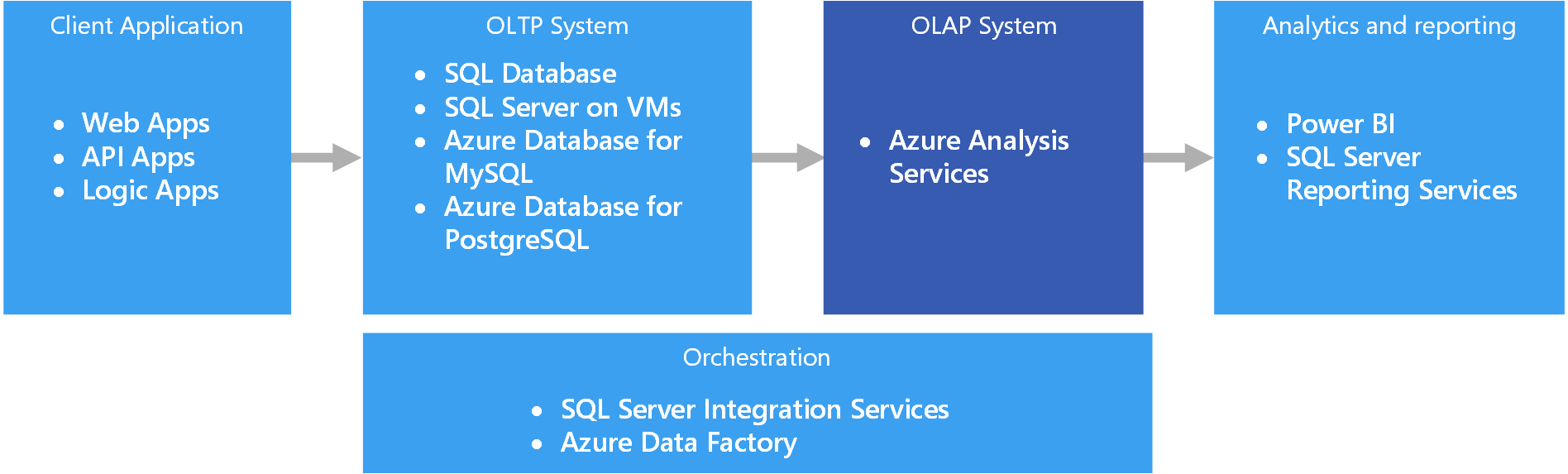
Соответствующие службы Azure:
Примеры использования
Данные организации хранятся в большой базе данных. Доступ к ним нужно предоставить бизнес-пользователям и клиентам, чтобы они могли создавать собственные отчеты и проводить анализ. Одно из решений — просто предоставить пользователям прямой доступ к базе данных. Но это решение имеет недостатки, например проблемы с безопасностью и управлением доступом.
Кроме того, структура базы данных, в том числе имена таблиц и столбцов, может быть сложной для пользователя. Пользователям потребуется понять, к каким таблицам выполнять запросы, как эти таблицы должны объединяться, а также другие факторы бизнес-логики, которые следует учитывать для получения правильных результатов. Чтобы приступить к работе, пользователи также должны знать язык запросов, например SQL. Обычно это приводит к тому, что несколько пользователей предоставляют в отчете одни и те же метрики, но с разными результатами.
Второй вариант решения — инкапсулировать всю информацию, необходимую пользователям, в семантическую модель. Пользователям будет проще отправлять запросы к семантической модели с помощью любого удобного средства создания отчетов. Данные, предоставленные семантической моделью, извлекаются из хранилища данных. Благодаря этому все пользователи получают единую версию данных. Семантическая модель также предоставляет понятные имена таблиц и столбцов, связи между таблицами, описания, удобные функции вычисления и безопасность на уровне строк.
Типичные признаки семантического моделирования
Семантическое моделирование и аналитическая обработка обычно имеют следующие признаки:
| схема | Схема при записи (строгое соблюдение) |
| Использование транзакций | Нет |
| Стратегия блокировки | None |
| Возможность обновления | Нет (обычно требуется повторное вычисление куба) |
| Возможность добавления | Нет (обычно требуется повторное вычисление куба) |
| Рабочая нагрузка | Большое число операций чтения, только для чтения |
| Индексация | Многомерное индексирование |
| Размер данных | Небольшой и средний размер |
| Моделирование | Многомерная |
| Форма представления данных | Схема типа «снежинка», куб или звезда |
| Гибкость запросов | Высокая гибкость |
| Масштаб | Большой (от десятков до сотен ГБ) |
Когда следует использовать это решение
Рекомендуем использовать OLAP в следующих сценариях:
- если нужно выполнять сложные аналитические и нерегламентированные запросы быстро и без негативного воздействия на системы OLTP;
- если нужно предоставить бизнес-пользователям компании простой способ создания отчетов на основе ваших данных;
- если нужно предоставить много агрегатов, с помощью которых пользователи смогут оперативно получать согласованные результаты.
Технология OLAP особенно полезна при выполнении статистических вычислений для больших объемов данных. Системы OLAP оптимизированы для сценариев с большим числом операций чтения, например для анализа и бизнес-аналитики.
OLAP позволяет пользователям сегментировать многомерные данные на срезы, которые можно просматривать в двух измерениях (например, в сводной таблице), или фильтровать данные по определенным значениям. Этот процесс иногда называется «сегментирование и фрагментирование» данных. Его можно выполнять, даже если данные секционированы по нескольким источникам. Такой процесс помогает пользователям определять тенденции, выделять шаблоны и просматривать данные без специальных знаний о традиционном анализе.
Семантические модели помогают бизнес-пользователям абстрагировать сложности связей и быстро анализировать данные.
Сложности
При всех преимуществах систем OLAP они создают и некоторые проблемы:
- Данные в системах OLTP постоянно обновляются за счет транзакций, передаваемых в из разных источников, а хранилища данных OLAP обычно обновляются гораздо реже, в зависимости от потребностей компании. Это означает, что системы OLAP скорее подходят для стратегических бизнес-решений, чем для немедленной реакции на изменения. Кроме того, для поддержки хранилищ данных OLAP в актуальном состоянии необходимо запланировать определенный уровень очистки данных и оркестрации.
- В отличие от традиционных нормализованных реляционных таблиц в системах OLTP, модели данных OLAP обычно являются многомерными. Из-за этого бывает сложно или невозможно непосредственно сопоставить отношения сущностей или объектно-ориентированные модели, где каждый атрибут сопоставляется с одним столбцом. Поэтому вместо традиционной нормализации в системах OLAP обычно используются схемы типа «снежинка» или «звезда».
OLAP в Azure
В Azure данные, хранящиеся в системах OLTP, например в службе «База данных SQL», копируются в систему OLAP, например в Azure Analysis Services. Средства просмотра и визуализации данных, в том числе Power BI, Excel и решения сторонних производителей, подключаются к серверам Analysis Services и предоставляют пользователям интерактивные визуальные представления моделей данных для анализа. Поток данных из системы OLTP в OLAP обычно оркестрируется с помощью SQL Server Integration Services и службы Фабрика данных Azure.
Все следующие хранилища данных в Azure будут соответствовать основным требованиям для OLAP:
- SQL Server с индексами columnstore;
- Azure Analysis Services;
- SQL Server Analysis Services (SSAS)
В службах SQL Server Analysis Services (SSAS) предлагаются возможности OLAP и интеллектуального анализа данных для приложений бизнес-аналитики. Вы можете установить службы SSAS на локальных серверах или разместить их на виртуальной машине в Azure. Azure Analysis Services — это полностью управляемая служба, которая предоставляет те же основные функции, что и SSAS. Службы Azure Analysis Services поддерживают подключение к различным облачным и локальным корпоративным источникам данных.
Кластеризованные индексы columnstore доступны в SQL Server 2014 и более поздних версий, а также в Базе данных SQL Azure и отлично подходят для рабочих нагрузок OLAP. Но начиная с версии SQL Server 2016 (включая Базу данных SQL Azure) вы можете воспользоваться гибридной транзакционно-аналитической обработкой (HTAP) благодаря обновляемым некластеризованным индексам columnstore. HTAP позволяет выполнять задачи обработки OLTP и OLAP на одной платформе, что избавляет от необходимости хранить несколько копий данных и использовать отдельные системы OLTP и OLAP. Дополнительные сведения см. в статье Начало работы с Columnstore для получения операционной аналитики в реальном времени.
Основные критерии выбора
Чтобы ограничить количество вариантов, сначала ответьте на следующие вопросы:
- Вы хотите использовать управляемую службу, а не управлять собственными серверами?
- Требуется ли безопасная аутентификация с использованием Azure Active Directory (Azure AD)?
- Вам нужно проводить анализ в реальном времени? Если да, оставьте только те варианты, которые поддерживают аналитику в реальном времени. Аналитика в реальном времени в этом контексте применяется к одному источнику данных, например к приложению для управления ресурсами предприятия (ERP), в котором будут выполняться операционная и аналитическая рабочие нагрузки. Если требуется интегрировать данные из нескольких источников или обеспечить максимальную производительность для анализа с помощью предварительно вычисленных данных, таких как кубы, вам может потребоваться отдельное хранилище данных.
- Вам нужно использовать предварительно вычисленные данные, например, чтобы предоставлять семантические модели, которые делают анализ более удобным для организаций? Если да, выберите вариант, который поддерживает многомерные кубы или табличные семантические модели. Благодаря статистическим выражениям пользователи могут последовательно выполнять статистическое вычисление данных. Предварительно вычисленные данные также позволяют значительно повысить производительность при работе с несколькими столбцами с множеством строк. Предварительно вычисленные данные могут быть представлены в виде многомерного куба или табличной семантической модели.
- Нужно ли интегрировать данные из нескольких источников за пределами хранилища данных OLTP? Если да, рассмотрите варианты, которые позволяют легко интегрировать несколько источников данных.
Матрица возможностей
В следующих таблицах перечислены основные различия в возможностях.
Общие возможности
| Является управляемой службой | Да | Нет | Нет | Да |
| Поддержка многомерных кубов | Нет | Да | Нет | Нет |
| Поддержка табличных семантических моделей | Да | Да | Нет | Нет |
| Простая интеграция нескольких источников данных | Да | Да | Нет 1 | Нет 1 |
| Поддержка аналитики в режиме реального времени | Нет | Нет | Да | Да |
| Необходимость обработки данных для их копирования из источников | Да | Да | Нет | Нет |
| Интеграция с Azure AD | Да | Нет | Нет 2 | Да |
[1] Хотя SQL Server и Базу данных SQL Azure нельзя использовать для отправки запросов и интеграции нескольких внешних источников данных, можно создать конвейер для этих задач с помощью SSIS или фабрики данных Azure. Сервер SQL Server, размещенный на виртуальной машине Azure, предоставляет дополнительные варианты, например связанные серверы и PolyBase. Дополнительные сведения см. в статье Choosing a data pipeline orchestration technology in Azure (Выбор технологии оркестрации конвейера данных в Azure).
[2] Подключение к SQL Server на виртуальной машине Azure с помощью учетной записи Azure AD не поддерживается. Вместо этого используйте учетную запись домена Active Directory.
Масштабируемость
| Избыточные региональные серверы для высокого уровня доступности | Да | Нет | Да | Да |
| Поддержка масштабирования запросов | Да | Нет | Да | Да |
| Динамическая масштабируемость (увеличение масштаба) | Да | Нет | Да | Да |
Соавторы
Эта статья поддерживается Майкрософт. Первоначально она была написана следующими авторами.
- | Зойнер Теджада Генеральный директор и архитектор
Дальнейшие действия
- Общие сведения об индексах columnstore
- Создание сервера Analysis Services
- Что такое Фабрика данных Azure?
- Что такое Power BI?
Связанные ресурсы
- Стиль архитектуры для обработки больших данных
- Хранилища данных в Microsoft Azure
- Оперативная аналитическая обработка (OLAP)
Источник: learn.microsoft.com
Вся правда о кубах данных OLAP: развенчиваем мифы

Кубы данных — не самая простая тема в дата-инжиниринге. Это тот самый случай, когда на пять запросов об определении приходятся пять разных вариантов ответа. Эта неоднозначность породила неудачную универсальную метафору, с помощью которой описываются кубы данных, — схему трехмерного куба. При этом в объяснениях нет примеров, рассказывающих, как в дата-пайплайне реализуется эта концепция.
Команда VK Cloud перевела статью, в которой заполняются пробелы и развенчиваются мифы, окружающие тему кубов данных.
Что такое куб данных
В общих чертах куб данных — это дизайн-паттерн, в котором показатели, например продажи, агрегируются по разным разрезам: региону, магазину или продукту.
Дизайн-паттерн реализован в основном в двух контекстах:
- Как предварительно агрегированная таблица в реляционной базе данных.
- Как объект данных в специализированной OLAP-системе.
Сегодня эти проблемы стоят не так остро. Но к этой теме мы вернёмся позже.
Кубы данных в реляционных БД
Рассмотрим пример — таблицу с данными по продажам по региону, магазину и продукту:
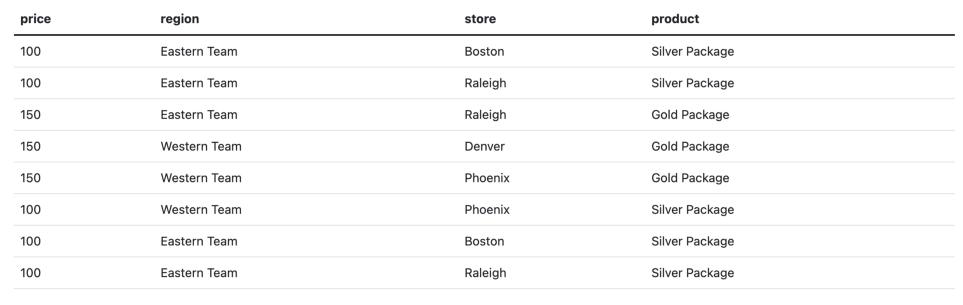
Чтобы создать куб данных из взятого для примера дата-сета, нужно агрегировать сумму цен по каждой комбинации разрезов. В PostgreSQL и MS SQL имеется подблок GROUP BY под названием CUBE, который сделает эту работу за вас.
Вот как выглядит запрос CUBE с этими данными:
SELECT SUM(price) as total_sales, region, store, product FROM sales GROUP BY CUBE(region, store, product);
Поскольку у взятого для примера дата-сета есть три разреза: регион, магазин, продукт, — вышеуказанный запрос выдаст восемь сгруппированных множеств и 29 строк данных (исходя из количества уникальных значений по разрезам).
Чтобы рассчитать общее количество сгруппированных множеств, созданных кубом данных, воспользуйтесь формулой: 2^number_of_dimensions.
Сгруппированные множества для этого примера:
(region, store, product), (region, store), (region, product), (store, product), (region), (store), (product), ()
В этом кубе данных нет ничего чрезмерно сложного: мы просто обобщили данные по каждому сочетанию разрезов. В прошлом дата-инженер создавал похожую таблицу и передавал её аналитику в виде общего представления по продажам.
Кубы данных в OLAP-системах
Как мы показали выше, куб данных можно реализовать в таблице стандартной БД, но их чаще используют в приложении Online Analytical Processing (OLAP).
Кубы — важная характеристика ядра традиционных OLAP-систем. Пожалуй, не будет преувеличением сказать, что OLAP и кубы данных — это в каком-то смысле синонимы.
Краткий исторический экскурс
Сейчас давайте ненадолго вернёмся в прошлое и разберёмся, что такое OLAP-системы и почему их вообще создали.
Сегодня, как и в 1970-х, бизнес-аналитика служит одной и той же цели: стейкхолдеры направляют запросы к данным и обобщают результаты по разным разрезам. К сожалению, десятилетия назад для выполнения этих запросов мог подойти только интерфейс используемых в компании рабочих баз данных SQL — тех самых, которые поддерживали цифровые бизнес-транзакции.
По современным меркам, компьютеры той эпохи работали очень медленно. Выполнять анализ непосредственно в рабочей базе данных было долго и дорого в плане затрат вычислительных ресурсов. Что ещё хуже, это мешало выполнять повседневные операции, для которых базы данных, собственно, и предназначались.
Приход OLAP-систем
В качестве решения этой проблемы разработчики ПО придумали отдельные хранилища, в которые загружали рабочие данные для анализа. Эти специализированные OLAP-системы хранили в предварительно агрегированном виде многомерную информацию, которую инженеры и аналитики называли OLAP-кубами.
Постепенно эти OLAP-системы доросли до полноценных приложений. В них аналитики или стейкхолдеры могли изучать OLAP-кубы, используя специальный синтаксис запросов или графический пользовательский интерфейс. Это позволяло выполнять нескольких функций, характерных для сводных таблиц:
- Roll up: объединить показатели в категории разрезов уровнем выше (город => область).
- Drill Down: разбить обобщённые категории на категории уровнем ниже (область => город).
- Slice and Dice: выбрать сегмент данных из одного или нескольких разрезов.
- Pivot: поменять оси табличного представления.
Если искать в интернете, что такое OLAP-куб, Google будет раз за разом выводить описания в виде трёхмерного изображения куба, который состоит из кубиков поменьше. Суть таких схем — наглядно представить, как вышеописанные функции работают в OLAP-системе и как выглядят сегменты агрегированных данных, созданных пересекающимися разрезами.
Но поскольку этому визуальному представлению не хватает контекста, оно скорее запутывает, чем проясняет дело. Зато теперь, когда мы разобрались с основами, эта схема может нам пригодиться.

OLAP drill uphttps://habr.com/ru/companies/vk/articles/703508/» target=»_blank»]habr.com[/mask_link]
OLAP-системы

OLAP (от англ. OnLine Analytical Processing — оперативная аналитическая обработка данных, также: аналитическая обработка данных в реальном времени, интерактивная аналитическая обработка данных) — подход к аналитической обработке данных, базирующийся на их многомерном иерархическом представлении, являющийся частью более широкой области информационных технологий — бизнес-аналитики (BI).
Каталог OLAP-решений и проектов смотрите в разделе OLAP на TAdviser.
С точки зрения пользователя, OLAP-системы представляют средства гибкого просмотра информации в различных срезах, автоматического получения агрегированных данных, выполнения аналитических операций свёртки, детализации, сравнения во времени. Всё это делает OLAP-системы решением с очевидными преимуществами в области подготовки данных для всех видов бизнес-отчетности, предполагающих представление данных в различных разрезах и разных уровнях иерархии — например, отчетов по продажам, различных форм бюджетов и так далее. Очевидны плюсы подобного представления и в других формах анализа данных, в том числе для прогнозирования.
Требования к OLAP-системам. FASMI
Ключевое требование, предъявляемое к OLAP-системам — скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. В этом смысле OLAP-системы противопоставляются, во-первых, традиционным РСУБД, выборки из которых с типовыми для аналитиков запросами, использующими группировку и агрегирование данных, обычно затратны по времени ожидания и загрузке РСУБД, поэтому интерактивная работа с ними при сколько-нибудь значительных объемах данных сложна. Во-вторых, OLAP-системы противопоставляются и обычному плоскофайловому представлению данных, например, в виде часто используемых традиционных электронных таблиц, представление многомерных данных в которых сложно и не интуитивно, а операции по смене среза — точки зрения на данные — также требуют временных затрат и усложняют интерактивную работу с данными.
Термин OLAP, предложенный Эдгаром Коддом (Edgar Codd) для разграничения таких систем с OLTP-системами (от англ. OnLine Transaction Processing — обработка транзакций в реальном времени), некоторые эксперты считают слишком широким. Поэтому Найджел Пендс (Nigel Pendse) предложил использовать для описания этой концепции и взамен предложенных Коддом 12-ти правил OLAP так называемый тест FASMI (от англ. Fast Analysis of Shared Multidimensional Information — быстрый анализ доступной многомерной информации), более точно харакетеризующую требования к этим системам.
Fast (быстрый) в отражает упомянутое выше требование к скорости реакции системы. По Пендсу, интервалы с момента инициации запроса до получения результата должен измеряться секундами. Важность этого требования возрастает при использовании таких систем в качестве инструмента оперативного представления данных для аналитика, так как длительное время ожидания может пагубно влиять на цепочку рассуждений аналитика.
Analysis (анализ) предполагает приспособленность системы к использованию в релевантной для задачи и пользователя бизнес-логике с сохранением доступной «обычному» пользователю легкости оперирования данными без использования низкоуровневого специального инструментария.
Shared (доступность, общедоступность) описывает очевидное требование к возможности одновременного многопользовательского доступа к информации с интегрированной системой разграничения прав доступа вплоть до уровня конкретной ячейки данных.
Multidimensional (многомерность) является ключевым требованием концепции. Предполагается, что система должна обеспечивать полную поддержку многомерного иерархического представления как «наиболее логичного пути анализа бизнеса и организаций». Отметим, что многомерность указывает на модель концептуального представления данных, то есть на то, как пользователь должен представлять организацию данных при формулировании запросов, а не на то, в каких структурах хранятся данные физически.
Многомерность в рамках OLAP предполагает концептуальное представление данных в виде многомерной структуры данных — гиперкуба (OLAP-куба), рёбрами в котором выступают измерения(dimension), а данные (facts — факты; measures — меры, показатели) расположены на пересечении осей измерений.
При этом измерение обычно представляет собой плоский или иерархический список. Например, измерение «Партнёры» может включать список партнёров компании, измерение «Время» — список филиалов с географической группировкой (регион мира, страна, регион, город, филиал). Если в качестве меры определён объём продаж, то на срезе по измерениям «Партнёры» и «Время» будем иметь таблицу с данными об изменении объема продажа по партнёрам во времени, в качестве заголовков строк и столбцов которой будут выступать наши измерения — «Время» и «Партнёры», а в ячейках на пересечении строк и столбцов будут расположены значений меры, т. е. данные об объеме продаж в конкретный период времени для конкретного партнёра.
Information (информация) — это все релевантные целям пользователя данные, при этом наличие «лишних» данных негативно сказывается на требовании к скорости реакции системы.
Особенности архитектуры. Классификация OLAP-систем
На архитектуру конкретных OLAP-систем оказывают влияние несколько факторов. Среди них — взаимодействие с источниками данных, особенности организации хранения данных в самой OLAP-системе и подход к обработке данных в ней.
Источники данных
OLAP-системы редко используются как средство непосредственного хранения и модификации данных (за исключением некоторых простых и маломасштабных систем бюджетирования, учета и анализа продаж и т. п.), так как большинство данных, используемых в OLAP для анализа, генерируются в других информационных системах (ERP, CRM, HRM и т. д.).
При этом, с одной стороны, специфичные для OLAP-систем требования к данным обычно подразумевают хранение данных в специальных оптимизированных под типовые задачи OLAP структурах, с другой сторны, непосредственное извлечение данных из существующих систем в процессе анализа привело бы к существенному падению их производительности.
Следовательно, важным требованием является обеспечение макимально гибкой связки импорта-экспорта между существующими системами, выступающими в качестве источника данных и OLAP-системой, а также OLAP-системой и внешними приложениями анализа данных и отчетности.
При этом такая связка должна удовлетворять очевидным требованиям поддержки импорта-экспорта из нескольких источников данных, осуществления процедур очистки и трансформации данных, унификации используемых классификаторов и справочников. Кроме того, к этим требованиям добавляется необходимость учёта различных циклов обновления данных в существующих информационных системах и унификации требуемого уровня детализации данных. Сложность и многогранность этой проблемы привела к появлению концепции хранилищ данных, и, в узком смысле, к выделению отдельного класса утилит конвертации и преобразования данных — ETL (Extract Transform Load).
Модели хранения активных данных
Выше мы указали, что OLAP предполагает многомерное иерархическое представление данных, и, в каком-то смысле, противопоставляется базирующимся на РСУБД системам.
Это, однако, не значит, что все OLAP-системы используют многомерную модель для хранения активных, «рабочих» данных системы. Так как модель хранения активных данных оказывает влияние на все диктуемые FASMI-тестом требования, её важность подчёркивается тем, что именно по этому признаку традиционно выделяют подтипы OLAP — многомерный (MOLAP), реляционный (ROLAP) и гибридный (HOLAP).
Вместе с тем, некоторые эксперты, во главе с вышеупомянутым Найджелом Пендсом, указывают, что классификация, базирующаяся на одном критерии недостаточно полна. Тем более, что подавляющее большинство существующих OLAP-систем будут относиться к гибридному типу. Поэтому мы более подробно остановимся именно на моделях хранения активных данных, упомянув, какие из них соответствуют каким из традиционных подтипов OLAP.
Хранение активных данных в многомерной БД
В этом случае данные OLAP хранятся в многомерных СУБД, использующих оптимизированные для такого типа данных конструкции. Обычно многомерные СУБД поддерживают и все типовые для OLAP операции, включая агрегацию по требуемым уровням иерархии и так далее.
Этот тип хранения данных в каком-то смысле можно назвать классическим для OLAP. Для него, впрочем, в полной мере необходимы все шаги по предварительной подготовке данных. Обычно данные многомерной СУБД хранятся на диске, однако, в некоторых случаях, для ускорения обработки данных такие системы позволяют хранить данные в оперативной памяти. Для тех же целей иногда применяется и хранение в БД заранее рассчитанных агрегатных значений и прочих расчётных величин.
Многомерные СУБД, полностью поддерживающие многопользовательский доступ с конкурирующими транзакциями чтения и записи достаточно редки, обычным режимом для таких СУБД является однопользовательский с доступом на запись при многопользовательском на чтение, либо многопользовательский только на чтение.
Среди условных недостатков, характерных для некоторых реализаций многомерных СУБД и базирующихся на них OLAP-систем можно отметить их подверженность непредсказуемому с пользовательской точки зрения росту объёмов занимаемого БД места. Этот эффект вызван желанием максимально уменьшить время реакции системы, диктующим хранить заранее рассчитанные значения агрегатных показателей и иных величин в БД, что вызывает нелинейный рост объёма хранящейся в БД информации с добавлением в неё новых значений данных или измерений.
Степень проявления этой проблемы, а также связанных с ней проблем эффективного хранения разреженных кубов данных, определяется качеством применяемых подходов и алгоритмов конкретных реализаций OLAP-систем.
Хранение активных данных в реляционной БД
Могут храниться данные OLAP и в традиционной РСУБД. В большинстве случаев этот подход используется при попытке «безболезненной» интеграции OLAP с существующими учётными системами, либо базирующимися на РСУБД хранилищами данных. Вместе с тем, этот подход требует от РСУБД для обеспечения эффективного выполнения требований FASMI-теста (в частности, обеспечения минимального времени реакции системы) некоторых дополнительных возможностей. Обычно данные OLAP хранятся в денормализованном виде, а часть заранее рассчитанных агрегатов и значений хранится в специальных таблицах. При хранении же в нормализованном виде эффективность РСУБД в качестве метода хранения активных данных снижается.
Проблема выбора эффективных подходов и алгоритмов хранения предрассчитанных данных также актуальна для OLAP-систем, базирующихся на РСУБД, поэтому производители таких систем обычно акцентируют внимание на достоинствах применяемых подходов.
В целом считается, что базирующиеся на РСУБД OLAP-системы медленнее систем, базирующихся на многомерных СУБД, в том числе за счет менее эффективных для задач OLAP структур хранения данных, однако на практике это зависит от особенностей конкретной системы.
Среди достоинств хранения данных в РСУБД обычно называют большую масштабируемость таких систем.
Хранение активных данных в «плоских» файлах
Этот подход предполагает хранение порций данных в обычных файлах. Обычно он используется как дополнение к одному из двух основных подходов с целью ускорения работы за счет кэширования актуальных данных на диске или в оперативной памяти клиентского ПК.
Гибридный подход к хранению данных
Большинство производителей OLAP-систем, продвигающих свои комплексные решения, часто включающие помимо собственно OLAP-системы СУБД, инструменты ETL (Extract Transform Load) и отчетности, в настоящее время используют гибридный подход к организации хранения активных данных системы, распределяя их тем или иным образом между РСУБД и специализированным хранилищем, а также между дисковыми структурами и кэшированием в оперативной памяти.
Так как эффективность такого решения зависит от конкретных подходов и алгоритмов, применяемых производителем для определения того, какие данные и где хранить, то поспешно делать выводы о изначально большей эффективности таких решений как класса без оценки конкретных особенностей рассматриваемой системы.
OLAP (англ. on-line analytical processing) – совокупность методов динамической обработки многомерных запросов в аналитических базах данных. Такие источники данных обычно имеют довольно большой объем, и в применяемых для их обработки средствах одним из наиболее важных требований является высокая скорость.
В реляционных БД информация хранится в отдельных таблицах, которые хорошо нормализованы. Но сложные многотабличные запросы в них выполняются довольно медленно. Значительно лучшие показатели по скорости обработки в OLAP-системах достигаются за счет особенности структуры хранения данных.
Вся информация четко организована, и применяются два типа хранилищ данных: измерения (содержат справочники, разделенные по категориям, например, точки продаж, клиенты, сотрудники, услуги и т.д.) и факты (характеризуют взаимодействие элементов различных измерений, например, 3 марта 2010 г. продавец A оказал услугу клиенту Б в магазине В на сумму Г денежных единиц). Для вычисления результатов в аналитическом кубе применяются меры. Меры представляют собой совокупности фактов, агрегированных по соответствующим выбранным измерениям и их элементам. Благодаря этим особенностям на сложные запросы с многомерными данными затрачивается гораздо меньшее время, чем в реляционных источниках.
Одним из основных вендоров OLAP-систем является корпорация Microsoft. Рассмотрим реализацию принципов OLAP на практических примерах создания аналитического куба в приложениях Microsoft SQL Server Business Intelligence Development Studio (BIDS) и Microsoft Office PerformancePoint Server Planning Business Modeler (PPS) и ознакомимся с возможностями визуального представления многомерных данных в виде графиков, диаграмм и таблиц.
Например, в BIDS необходимо создать OLAP-куб по данным о страховой компании, ее работниках, партнерах (клиентах) и точках продаж. Допустим предположение, что компания предоставляет один вид услуг, поэтому измерение услуг не понадобится.
Сначала определим измерения. С деятельности компании связаны следующие сущности (категории данных):
- Точки продаж
— Сотрудники
— Партнеры
Также создаются измерения Время и Сценарий, которые являются обязательными для любого куба.
Далее необходима одна таблица для хранения фактов (таблица фактов).
Информация в таблицы может вноситься вручную, но наиболее распространена загрузка данных с применением мастера импорта из различных источников.
На следующем рисунке представлена последовательность процесса создания и заполнения таблиц измерений и фактов вручную:
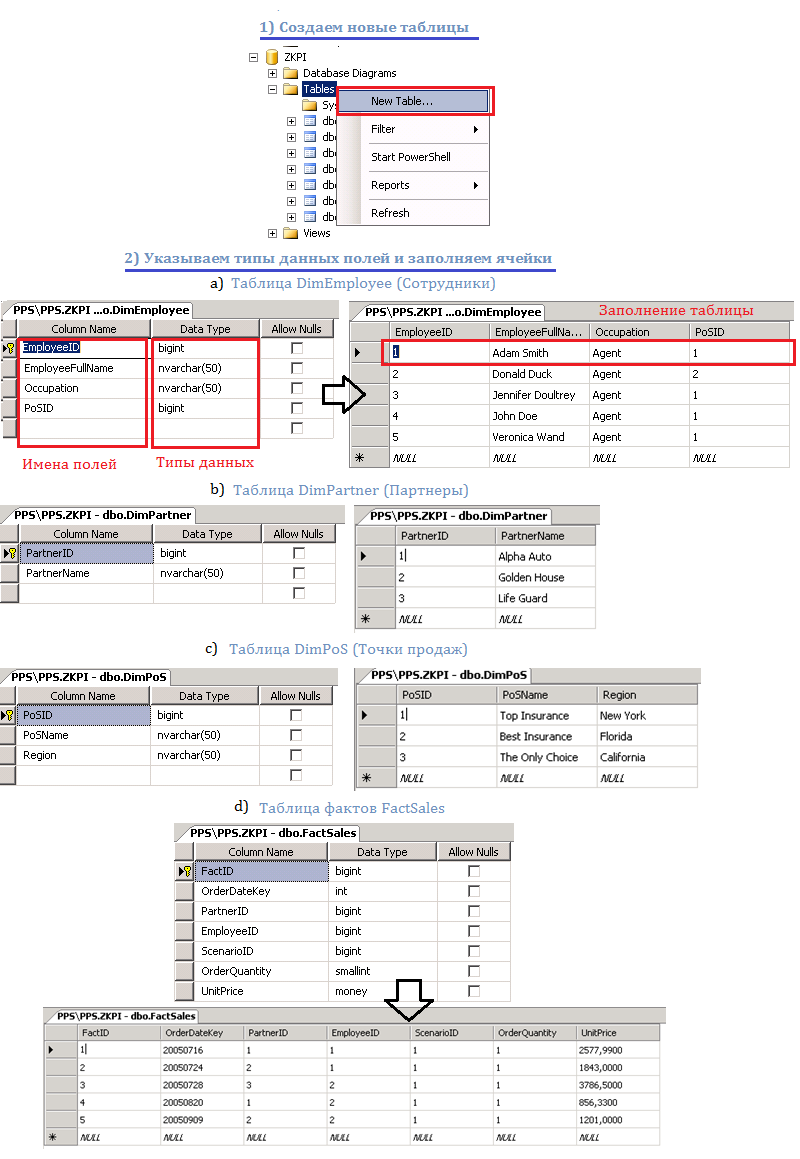
Рис.1. Таблицы измерений и фактов в аналитической БД. Последовательность создания
После создания многомерного источника данных в BIDS имеется возможность просмотреть его представление (Data Source View). В нашем примере получится схема, представленная на рисунке ниже.
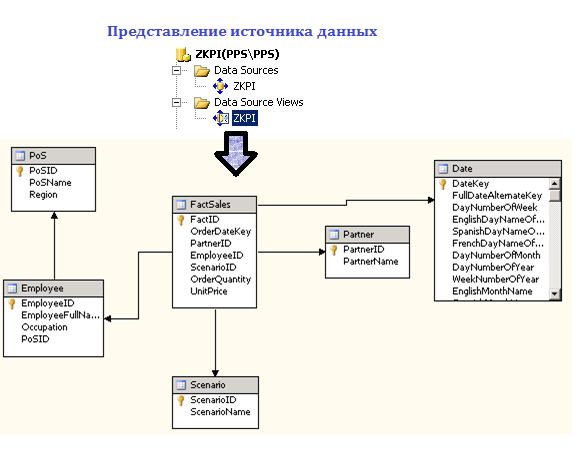
Рис.2. Представление источника данных (Data Source View) в Business Intellingence Development Studio (BIDS)
Как видим, таблица фактов связана с таблицами измерений посредством однозначного соответствия полей-идентификаторов (PartnerID, EmployeeID и т.д.).
Далее производится развертывание куба. Кроме того, при необходимости дополнительно настраиваются иерархии, атрибуты измерений, создаются вычисляемые меры.
Посмотрим на результат. На вкладке обозревателя куба, перетаскивая меры и измерения в поля итогов, строк, столбцов и фильтров, можем получить представление интересующих данных (к примеру, заключенные сделки по страховым договорам, заключенные определенным работником в 2005 году):
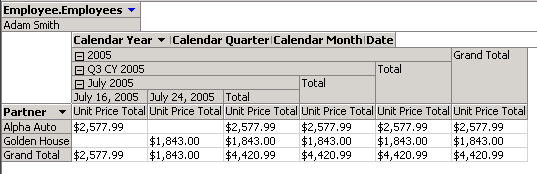
Рис.3. Просмотр аналитического куба
Основные игроки и решения
OLAP-системы входят в состав подавляющего большинства решений для бизнес-аналитики, «корпоративных» редакций СУБД основных поставщиков (IBM, Microsoft, Oracle). В той или иной мере технологии OLAP используются в существенной части современных ERP-систем. В государственном секторе РФ отдается предпочтение OLAP-инструментарию, предложенному Группой компаний БАРС Груп.
Внешние ссылки
Ознакомиться с примерами визуализации данных на основе куба BIDS, а также узнать о возможностях создания многомерных моделей в Microsoft Office PerformancePoint Server можно здесь
Источники
Nigel Pendse. «OLAP architectures». Retrieved on 2008-12-15.
Источник: www.tadviser.ru