
Hive OS — это универсальная платформа для майнинга, которая позволяет пользователям настраивать и контролировать все процессы на GPU и ASIC-ках с одного дашборда.
Отслеживайте хэшрейты, онлайн статусы, ошибки GPU/ASIC-ов, активность команды, конфигурации пула, энергопотребление, устраняйте неполадки и массово настраивайте оборудование из любой точки земного шара.
Последнее обновление
1 мая 2023 г.
Безопасность данных
arrow_forward
Чтобы контролировать безопасность, нужно знать, как разработчики собирают ваши данные и передают их третьим лицам. Методы обеспечения безопасности и конфиденциальности могут зависеть от того, как вы используете приложение, а также от вашего региона и возраста. Информация ниже предоставлена разработчиком и в будущем может измениться.
Это приложение может передавать указанные типы данных третьим лицам
Сведения о приложении и его производительности
Это приложение может собирать указанные типы данных.
Личная информация, История действий в приложении и Идентификаторы устройства или другие идентификаторы
Hive OS Настройка Установка. Майнинг на HiveOS. Полная пошаговая инструкция.
Данные шифруются при передаче.
Вы можете запросить удаление данных.
Оценки и отзывы
Оценки и отзывы проверены info_outline
arrow_forward
Оценки и отзывы проверены info_outline
phone_android Телефон
tablet_android Планшет
3,64 тыс. отзыва
Линар Насыбуллин
more_vert
- Пожаловаться
- Показать историю отзывов
20 мая 2023 г.
Почему не работает? Выкидывает на сайт в браузере при нажатии кнопки старт на андроиде, слетела авторизация видимо, да хрен с ним но не даёт залогиниться. Почему выкидывает в браузер по умолчанию? Don’t lie, vpn is not help too. Just do your job.
Дайте возможность на андроиде выбирать браузер хотя бы, штатный весь в бдакировках у людей обычно.
22 человека отметили этот отзыв как полезный.
Вам помогла эта информация?
22 мая 2023 г.
Is it possible to login in opened browser page?
Вадим Ермаков
more_vert
- Пожаловаться
- Показать историю отзывов
9 января 2023 г.
Всё бы хорошо, но при открытии консоли Hive Shell не работает «ввод». Пишешь команду, а запустить её из штатной клавиатуры не получается. Приходится подключать Клаву от компа через OTG и нажимать Enter. Раньше буква два раза вводилась (приходилось стирать вторую), но ввод работал, а теперь вообще без физической клавиатуры команду не отдать. Теряется смысл мобильного приложения.
И сделайте авторизацию по пальцам или как в системе, а не каждый раз пароль , два ключа и аутентификатор. Это перебор
7 человек отметили этот отзыв как полезный.
Вам помогла эта информация?
9 января 2023 г.
Приносим извинения за неудобства. Действительно существует проблема с Enter в Shell. Мы работаем над вариантами решения. Сейчас единственный workaround — установить приложение клавиатуры Hacker’s Keyboard
Страна Заказов
more_vert
- Пожаловаться
5 января 2023 г.
Последнее обновление авторизуется через браузер, что является неудобным и глупым решением), после очистки кэша, все слетает и приходится входить повторно. Не пойму логику разработчиков, для чего задействовать сторонние приложения, если в предыдущем релизе всё прекрасно работало.
Что такое автофан в Hive OS?
Источник: play.google.com
Обзор Apache Hive и HiveQL в Azure HDInsight
Apache Hive — это система хранилища данных для Apache Hadoop. Hive позволяет обобщать, запрашивать и анализировать данные. Запросы Hive создаются на языке запросов HiveQL, который похож на SQL.
Hive позволяет создавать структуру для преимущественно неструктурированных данных. После определения структуры вы можете использовать HiveQL для запроса этих данных без знания Java или MapReduce.
HDInsight предоставляет несколько типов кластера, которые подходят для конкретных рабочих нагрузок. Для запросов Hive наиболее часто используются следующие типы кластеров:
| Интерактивный запрос | Кластер Hadoop, который обеспечивает функцию аналитической обработки с низкой задержкой (LLAP) для оптимизации времени ответа для интерактивных запросов. Дополнительные сведения см. в статье Использование Interactive Hive с HDInsight (предварительная версия). |
| Hadoop | Кластер Hadoop, который предназначен для рабочих нагрузок пакетной обработки. Дополнительные сведения см. в статье Приступая к работе с Apache Hadoop в HDInsight. |
| Spark | Apache Spark содержит встроенные функциональные возможности для работы с Hive. Дополнительные сведения см. в статье Приступая к работе с Apache Spark в HDInsight. |
| HBase | HiveQL может использоваться для создания запросов данных, хранимых в Apache HBase. Дополнительные сведения см. в статье Приступая к работе с Apache HBase в HDInsight. |
Как использовать Hive
В следующей таблице показаны различные способы использования Hive в HDInsight:
| Средства HDInsight для Visual Studio Code | ✔ | ✔ | Linux, Unix, macOS X или Windows |
| Средства HDInsight для Visual Studio | ✔ | ✔ | Windows |
| Представление Hive | ✔ | ✔ | Для приложений на основе браузера |
| клиент Beeline | ✔ | ✔ | Linux, Unix, macOS X или Windows |
| REST API | ✔ | Linux, Unix, macOS X или Windows | |
| Windows PowerShell | ✔ | Windows |
Справочник по языку HiveQL
Справочник по языку HiveQL доступен на странице руководства по языку.
Hive и структура данных
Hive поддерживает работу со структурированными и частично структурированными данными. Например, с текстовыми файлами, в которых поля разделяются с помощью определенных знаков. С помощью следующей инструкции HiveQL создается таблица для данных, разделенных пробелами:
CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ STORED AS TEXTFILE LOCATION ‘/example/data/’;
Hive также поддерживает пользовательские сериализаторы/десериализаторы (SerDe) для сложных или беспорядочно структурированных данных. Дополнительные сведения см. в документе How to use a custom JSON SerDe with HDInsight (Как использовать настраиваемую сериализацию-десериализациюJSON с HDInsight).
Сравнение внутренних и внешних таблиц Hive
Существует два типа таблиц, которые вы можете создать с помощью Hive:
- Внутренняя: данные хранятся в хранилище данных Hive. Хранилище данных расположено в /hive/warehouse/ , в хранилище по умолчанию для кластера. Используйте внутренние таблицы, если применяется одно из следующих условий:
- данные являются временными;
- вы хотите использовать Hive для управления жизненным циклом таблицы и данных.
- данные также используются за пределами Hive (например, файлы данных обновляются с помощью другого процесса, который не блокирует их);
- данные должны оставаться в базовом расположении даже после удаления таблицы;
- вам нужно пользовательское расположение, например нестандартная учетная запись хранилища;
- программа, отличная от Hive, управляет форматом данных, расположением и т. д.
Дополнительные сведения см. в записи блога HDInsight: Hive Internal and External Tables Intro (HDInsight: введение во внутренние и внешние таблицы Hive).
Определяемые пользователем функции (UDF)
Инфраструктура Hive также может быть расширена с помощью определяемых пользователем функций (UDF). UDF позволяет реализовать функции или логику, сложно моделируемые в HiveQL. Примеры использования определяемых пользователем функций с Hive приведены в следующих документах:
- Работа с определяемыми пользователем функциями Java с использованием Apache Hive в HDInsight
- Работа с определяемыми пользователем функциями Python с использованием Apache Hive в HDInsight
- Работа с определяемыми пользователем функциями C# с использованием Apache Hive в HDInsight
- Как добавить настраиваемые определяемые пользователем функции Apache Hive в HDInsight
- Пример определяемой пользователем функции Apache Hive для преобразования форматов даты и времени в метки времени Hive
Демонстрационные данные
Hive в HDInsight поставляется предварительно загруженным с внутренней таблицей hivesampletable . HDInsight также предоставляет пример наборов данных, которые могут использоваться с Hive. Эти наборы данных хранятся в каталогах /example/data и /HdiSamples . Эти каталоги находятся в хранилище по умолчанию для кластера.
Пример запроса Hive
Приведенная ниже инструкция HiveQL проецирует столбцы проекта в файл /example/data/sample.log .
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ STORED AS TEXTFILE LOCATION ‘/example/data/’; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = ‘[ERROR]’ AND INPUT__FILE__NAME LIKE ‘%.log’ GROUP BY t4;
В предыдущем примере операторы HiveQL выполняют следующие действия.
| DROP TABLE | Если таблица уже существует, удалите ее. |
| CREATE EXTERNAL TABLE | Создает внешнюю таблицу в Hive. Внешние таблицы хранят только определения таблицы в Hive. Данные остаются в исходном расположении и формате. |
| ROW FORMAT | инструкции по форматированию данных для Hive. В данном случае поля всех журналов разделены пробелом. |
| STORED AS TEXTFILE LOCATION | Указывает Hive расположение хранения данных (каталог example/data ) и их формат (текст). Данные могут храниться в одном файле или быть распределенными по нескольким файлам в каталоге. |
| SELECT | Подсчитывает количество всех строк, в которых столбец t4 содержит значение [ERROR]. Эта инструкция должна вернуть значение 3, так как данное значение содержат три строки. |
| INPUT__FILE__NAME LIKE ‘%.log’ | Hive пытается применить схему ко всем файлам в каталоге. В этом случае каталог содержит файлы, которые не соответствуют схеме. Чтобы исключить лишние данные в результатах, эта инструкция указывает Hive возвращать данные только из файлов, заканчивающихся на .log. |
Внешние таблицы следует использовать, если исходные данные должны обновляться с использованием внешних источников. Например, процессом автоматизированной передачи данных или другой операцией MapReduce.
Удаление внешней таблицы не приводит к удалению данных; будет удалено только описание таблицы.
Для создания внутренней таблицы вместо внешней используйте следующий запрос HiveQL.
CREATE TABLE IF NOT EXISTS errorLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = ‘[ERROR]’;
Эти операторы выполняют следующие действия:
| CREATE TABLE IF NOT EXISTS | Создает таблицу, если она не существует. Так как ключевое слово EXTERNAL не используется, этот оператор создает внутреннюю таблицу. Таблица хранится в хранилище данных Hive и полностью управляется Hive. |
| STORED AS ORC | Позволяет сохранить данные в формате ORC. Это высокооптимизированный и эффективный формат для хранения данных Hive. |
| INSERT OVERWRITE . SELECT | Выбирает строки из таблицы log4jLogs, содержащей значение [ERROR], а затем вставляет данные в таблицу errorLogs. |
В отличие от внешних таблиц, удаление внутренней таблицы приводит к удалению базовых данных.
Повышение производительности запросов Hive
Apache Tez
Apache Tez — это платформа, которая позволяет повысить производительность приложений, обрабатывающих большие объемы данных (включая Hive). Tez включена по умолчанию. Раздел Документация по работе Apache Hive на Tez содержит дополнительные сведения о реализации этого решения и вариантах настроек.
Аналитическая обработка с низкой задержкой (LLAP)
LLAP (иногда называемая Live Long and Process) — это новая функция в Hive 2.0, которая разрешает кэширование запросов в памяти.
HDInsight предоставляет LLAP в кластере интерактивных запросов. Дополнительные сведения см. в статье Использование Interactive Hive с HDInsight (предварительная версия).
Планирование запросов Hive
Есть несколько служб, которые поддерживают запросы Hive в рамках рабочего процесса по расписанию или по требованию.
Фабрика данных Azure
Фабрика данных Azure позволяет использовать HDInsight как часть конвейера фабрики данных. Дополнительные сведения об использовании Hive из конвейера см. в документе Преобразование данных с помощью действия Hadoop Hive в фабрике данных Azure.
Задания Pig и SQL Server Integration Services
С помощью служб SQL Server Integration Services (SSIS) можно выполнить задание Hive. Пакет дополнительных компонентов Azure для служб SSIS предоставляет следующие компоненты, которые работают с заданиями Hive в HDInsight.
- Задача Hive для Azure HDInsight
- Диспетчер подключений подписки Azure
Дополнительные сведения см. в документации по пакету функций Azure.
Apache Oozie
Apache Oozie — это система рабочих процессов и координации, управляющая заданиями Hadoop. Дополнительные сведения см. в статье об использовании Apache Oozie с Hive для определения и запуска рабочего процесса.
Дальнейшие действия
Теперь, когда вы знаете, что такое инфраструктура Hive и как ее использовать с Hadoop в HDInsight, воспользуйтесь следующими ссылками, чтобы изучить другие способы работы с Azure HDInsight.
- Отправка данных в HDInsight
- Использование определяемых пользователем функций Python с Apache Hive и Apache Pig в HDInsight
- Использование заданий MapReduce с HDInsight
Источник: learn.microsoft.com
Hive
Apache Hive — это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код заданий MapReduce.
Запросы Hive создаются на языке запросов HiveQL, который основан на языке SQL, но не имеет полной поддержки стандарта SQL-92. Однако, этот язык позволяет программистам использовать их собственные запросы, когда неудобно или неэффективно использовать возможности HiveQL. HiveQL может быть расширен с помощью пользовательских скалярных функций (UDF), агрегаций (UDAF кодов), и табличных функций (UDTF).
Архитектура HIVE:
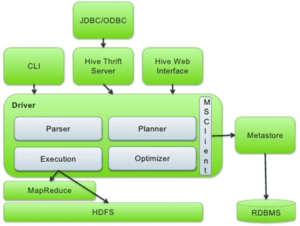
UI Пользовательский интерфейс
Позволяет выполнять запросы и команды в Hive:
- Hive Web UI
- командная строка Hive CLI или Beeline
- Hive HD Insight (на сервере Windows)
- Apache Zeppelin или HUE server
Meta Store ( Хранилище мета-данных)
Hive QL Process Engine (процессор HiveQL)
Подробнее об Apache Hive читайте в наших следующих статьях:
- Hive и Impala: коллеги или конкуренты – обзор SQL-инструментов для Apache Hadoop
- Hive vs Impala: сходства и различия SQL-инструментов для Apache Hadoop
- Что такое HiveQL: SQL для Big Data в Apache Hadoop — как работают Hive и Impala
- Как защитить Big Data в Hive и Impala: проблема безопасности в SQL-on-Hadoop
Related Entries
Новое на сайте
- Средства обеспечения безопасности в приложениях Apache Spark
- 5 советов по проектированию процессоров в Apache NiFi
- Под капотом табличного хранилища Apache Flink
- Kafka Streams vs ksqlDB: что и когда использовать
- Кто кому заплатил: пример поиска банковских транзакций в Neo4j
Отзывы на Google

07:42 27 Apr 21
Курсы от инженеров и для инженеров. Всё чётко, по делу. Тренеры глубоко знают продукты, о которых читают лекции. read more
04:43 12 Mar 21
Принимал участие в обучении по курсу «KAFKA: Администрирование кластера Kafka». В целом понравилось, но хотелось бы более качественной организации работы с лабгайдами. Когда лектор выполняет лабораторную работу, не совсем удобно выполнять её параллельно — где-то отстаешь, где-то убегаешь вперед. Может будет лучше разделить на более мелкие модули. read more
18:31 22 Dec 20
Прошел Курс Администрирование кластера Hadoop. Подача материала хорошая, размеренная. Преподаватель отвечает на все вопросы, и пытается как можно прозрачней приподнести материал. read more
14:47 18 Dec 20
Обучался на программе HADM. Подача материала доступная. Порадовало соотношение теории и практики 50/50. Отзывчивый преподаватель. Однозначно рекомендую. read more
15:07 17 Dec 20
Заканчиваю прохождения курса «ADH: Администрирование кластера Arenadata Hadoop». Хочу сказать, что выстроен грамотный план обучения, где отслеживается отличное соотношение практики и теории. Преподаватель, Комисаренко Николай, обладает отличным чувством юмора, что позволило не скучать на серьезных темах, и обладает отличным навыком объяснять сложные вещи простыми словами. На курс приходил с большим числом вопросов, на все из которых получил грамотные ответы, после чего все разложилось по полочкам. read more
19:17 12 Dec 20
В декабре 2020 прошел курс «Администрирование кластера Kafka». Курс проводился удаленно. В части организации обучения придраться не к чему. Необходимую информацию прислали заранее, лабораторный стенд и портал обучения работали стабильно. Немного разочаровали лабораторные работы.
На месте BigDataSchool я бы их переделал. В документах с лабами нужно сделать нормальное форматирование и нумерацию пунктов. Все пункты, необходимые для выполнения, нужно сделать в виде текста. В лабах много работ по созданию «обвязки» kafka (создание самоподписных сертификатов, развертывание MIT и т.п), которые можно сделать заранее.
Это позволит студентам уделять больше времени изучению самой kafka. BigDataSchool идет навстречу и позволяет пользоваться лабораторным стендом гораздо дольше установленных часов обучения. Это очень к стати, если в течении дня Вы вынуждены отвлекаться от обучения. В целом, курс дает хорошую базу по kafka. Преподаватель хорошо подает материал, делает акценты в нужных местах, подробно отвечает на вопросы. read more
02:55 10 Dec 20
С 30 ноября по 4 декабря прошел курс «Администрирование кластера Hadoop». Учитывая, что я обладал довольно поверхностной информацией в данной теме (я CIO) — ушел с курсов просветленным. Многое стало понятным, в процессе обучения наложил знания на существующую инфраструктуру компании, в которой работаю.
Рекомендую коллегам руководителям в ИТ — прокачаться на данном курсе, вы поймете куда двигаться в ближайшие 2-3 года. Админам, работающим или стремящимся в BigData- обязательно! Рекомендация — настойчиво, для тех кто «думает, что знает»: перед курсом уделите время работе с командной строкой Linux! Total recall — обязательное условие. Много практической работы, и если есть затык в Linux — будете безнадежно отставать при выполнении лабораторных работ. read more
13:49 26 Oct 20
В октябре прошел курс Анализ данных с Apache Spark, это был второй раз, когда я обучался в этом месте. В целом, все хорошо, думаю что не последний. Не могу не подчеркнуть профессионализм преподавателя Королева Михаила, отвечал на поставленные вопросы, делился своим опытом. В общем, рекомендую! read more
16:36 25 Sep 20
Прошел тут курс «NIFI: Кластер Apache NiFi», вёл Комисаренко Николай. Живое и понятное обучение. Преподаватель отвечал на все вопросы от самых глупых, до самых умных и это было приятно. Так же порадовало, что преподаватель не идёт по заранее проложенным рельсам, а проходит весь путь вместе с вами, стараясь привнести, что-то новое. read more
14:16 18 Sep 20
Спасибо за обучение!
18:18 24 Jan 20
Очень крутое место, много практики, понятное объяснение заданной темы. Еще вернусь 🙂 read more
14:03 04 Oct 19
Обучался на курсе HADM администрирование кластера Arenadata Hadoop. Интересный курс, хорошая подача. read more
20:16 10 Apr 19
Обучался на курсе по администрированию Apache Kafka. Хорошая подача материала, интересные практические задачи. Возникающие вопросы доходчиво и ясно объясняют. Остался очень доволен. read more
19:20 03 Apr 19
Был на курсе «Администрирование кластера Hadoop». Отличная подача материала. Очень много практики и технических подробностей. Подробный обзор стека технологий, платформы и инструментов. Рекомендую! read more
07:08 01 Apr 19
Учился на курсе Администрирование Hadoop. Курс вёл Николай Комиссаренко. Отлично подготовленная, продуманная, системная программа курса. Практические занятия организованы так, что у студентов есть возможность познакомиться с реальными особенностями изучаемого продукта. Отключил голову и прощёлкал лабы по книжке — здесь не работает. Преподаватель легко и развёрнуто отвечает на возникающие вопросы не только по теме предмета, но и по смежным. read more
03:24 07 Feb 19
Прошёл курс по администрированию Apache Kafka. Очень понравилась как подача материала, так и структура курса. Только вот времени маловато оказалось. не всё успел доделать, но это уже не к курсу претензии :). Практики было довольно много, и это хорошо read more
11:37 22 Dec 18
Прошёл курс «Hadoop для инженеров данных» у Николая Комиссаренко. Информация очень актуальна и полезна, заставляет задуматься о текущих методах работы с большими данными в нашей компании и, возможно, что-то поменять. Занятия с большим количеством практики, поэтому материал хорошо усваивается. Отдельное спасибо Николаю за то, что некоторые вещи объяснял простым языком, понятным даже для «чайников» в области Hadoop. read more
17:23 21 Dec 18
I did not find any disadvantages in the course. Pluses: + A lot of practice (50% of the time). + The teacher can explain difficult topics easy way. + Announced topics were considered. Besides additional materials were studied. read more
08:23 20 Dec 18
Посетил курс администрирование Hadoop. На курсе устанавливали кластер с нуля на виртуалках в облаке Amazon. Настраивали Kerberos, тестировали выполнение задач на кластере, управление ресурсами кластера. Т.к. кластер развернут в облаке, после завершения занятий можно самостоятельно работать с кластером из дома. Лекции вел Николай Комиссаренко, после обучения предоставил все материалы.
На занятиях отвечал на дополнительные вопросы, рассмотрели как решить пару живых задач от студентов. Хороший курс для начала изучения BigData. Update Дополнительно прошел обучения по Airflow и NiFi. Курсы двух дневные упор на занятиях делался на использовании продуктов, администрированию уделялось меньше времени.
Т.к. курсы короткие, то перед занятиями желательно почитать обзорные статьи по продуктам, чтобы не терять время на базовое погружение и задавать более предметные вопросы. Перед началом занятий желательно связаться с школой и запросить что больше интересуется на обучении. Может быть предложить свои кейсы, чтобы на лабораторных отработать не только общий функционал. read more
05:51 14 Dec 18
Был на основах хадупа, все материалы описаны доступным языком. В частности хочу отметить преподавателя Николая Комисаренко, как очень квалифицированного преподавателя и специалиста. read more
16:40 12 Oct 18
Отличные курсы по «Администрированию Hadoop» и отличная организация проведения занятий, все по делу и понятно. Очень понравилось, знания получены основательные. Материал подаётся основательно. Постараюсь ещё попасть на другие курсы. read more
05:25 11 Oct 18
Курс по Isilon у Николая Комиссаренко мне тоже понравился. Грамотный и отзывчивый. Возникали вопросы по курсу он отвечал на все вопросы. Спасибо. Успехов ему read more
21:32 09 Oct 18
Посетил курс администрирование Hadoop. На курсе устанавливали кластер с нуля на виртуалках в облаке Amazon. Настраивали Kerberos, тестировали выполнение задач на кластере, управление ресурсами кластера. Т.к. кластер развернут в облаке, после завершения занятий можно самостоятельно работать с кластером из дома. Лекции вел Николай Комиссаренко, после обучения предоставил все материалы.
На занятиях отвечал на дополнительные вопросы, рассмотрели как решить пару живых задач от студентов. Хороший курс для начала изучения BigData. read more
16:33 09 Oct 18
Эффективный практический курс. Прошел курс Администрирование Hadoop в октябре 2018. Хорошо наполненный материал, оптимальная длительность курса и все делалось своими руками. Местами было непросто, но преодолимо. Оправдал все ожидания, после курса появилось целостное понимание создания и работы кластера. Николай, большое спасибо read more
10:22 05 Oct 18
Прошёл курс по администрированию Hadoop Cloudera. Отличная «живая» подача материала на «простом» языке. Как плюс работа с кластером построена на платформе AWS. На курсах не скучно, рекомендую! read more
04:34 04 Oct 18
Я узнал много нового посетив курс уважаемого Николая Комиссаренко по айзелону. Очень грамотный специалист обучение было очень полезным и грамотным. Спасибо вам большое read more
Источник: bigdataschool.ru