
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как «search globally for lines matching the regular expression, and print them». Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Linux Crash Course — The grep Command
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке. ]
$ команда | grep [опции] шаблон
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки — это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, —extended-regexp — включить расширенный режим регулярных выражений (ERE);
- -F, —fixed-strings — рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, —basic-regexp — интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, —perl-regexp — рассматривать шаблон поиска как регулярное выражение Perl;
- -e, —regexp — альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, —file — читать шаблон поиска из файла;
- -i, —ignore-case — не учитывать регистр символов;
- -v, —invert-match — вывести только те строки, в которых шаблон поиска не найден;
- -w, —word-regexp — искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, —line-regexp — искать шаблон как целую строку, от начала и до символа перевода строки;
- -c — вывести количество найденных строк;
- —color — включить цветной режим, доступные значения: never, always и auto;
- -L, —files-without-match — выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, —files-with-match — аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, —max-count — остановить поиск после того как будет найдено указанное количество строк;
- -o, —only-matching — отображать только совпавшую часть, вместо отображения всей строки;
- -h, —no-filename — не выводить имя файла;
- -q, —quiet — не выводить ничего;
- -s, —no-messages — не выводить ошибки чтения файлов;
- -A, —after-content — показать вхождение и n строк после него;
- -B, —before-content — показать вхождение и n строк после него;
- -C — показать n строк до и после вхождения;
- -a, —text — обрабатывать двоичные файлы как текст;
- —exclude — пропустить файлы имена которых соответствуют регулярному выражению;
- —exclude-dir — пропустить все файлы в указанной директории;
- -I — пропускать двоичные файлы;
- —include — искать только в файлах, имена которых соответствуют регулярному выражению;
- -r — рекурсивный поиск по всем подпапкам;
- -R — рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
GREP регулярные выражения. Поиск в Linux
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
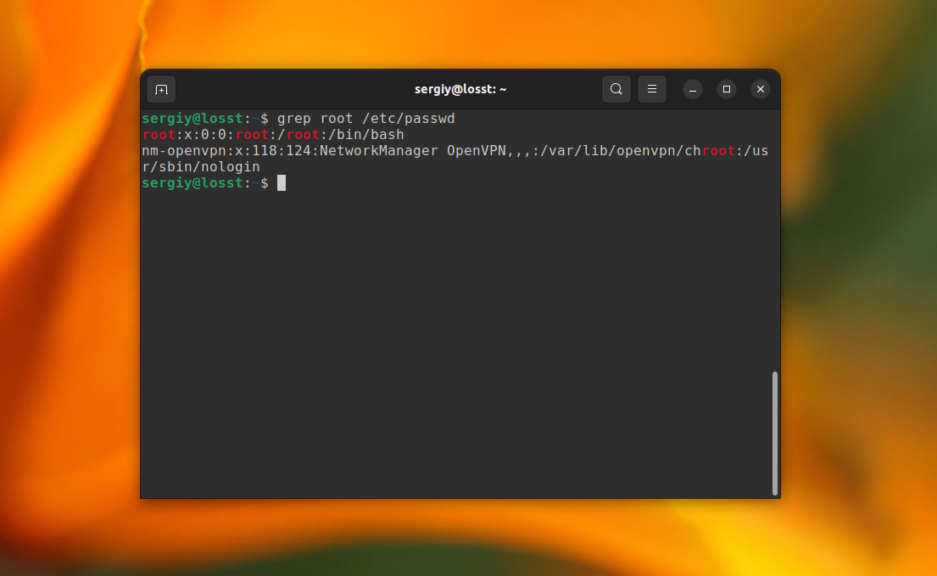
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
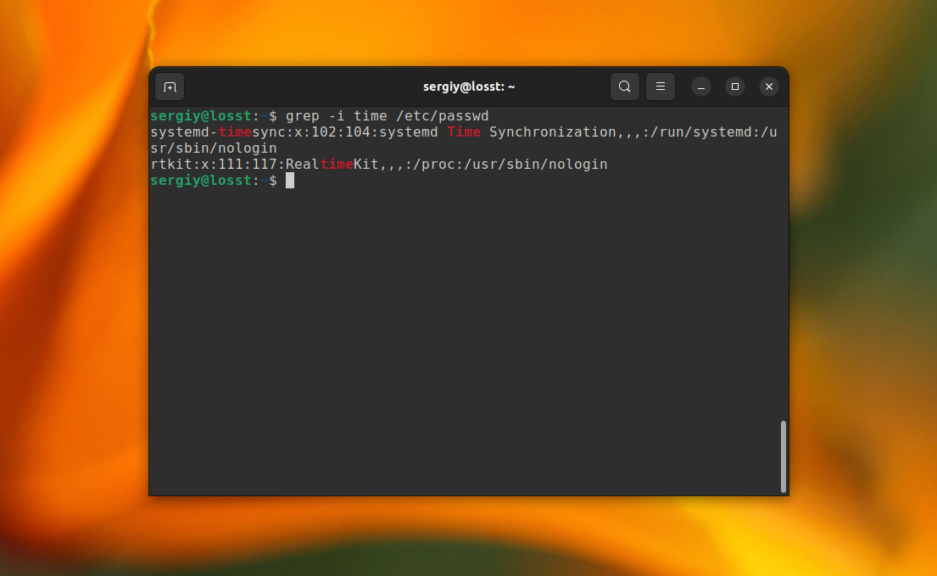
grep -i «time» /etc/passwd
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
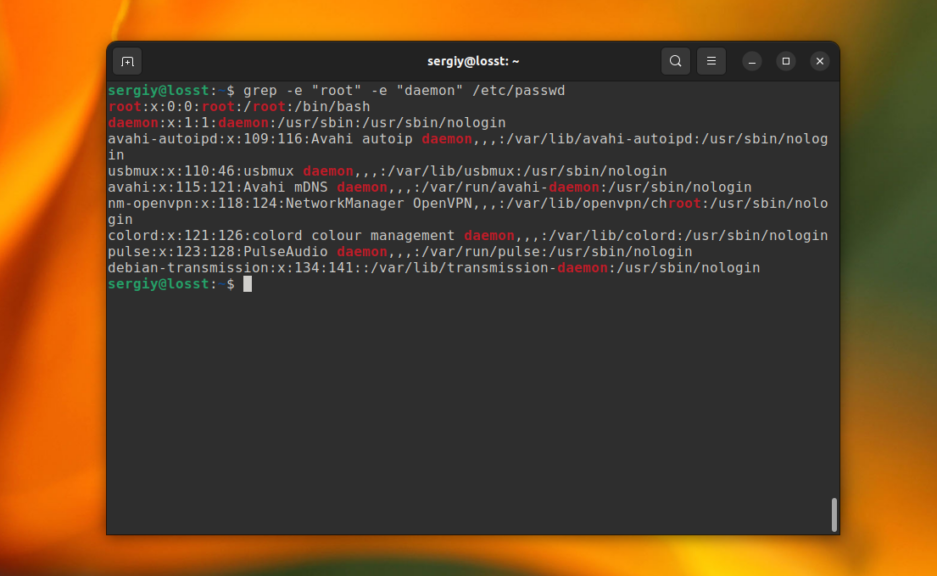
grep -e «root» -e «daemon» /etc/passwd
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
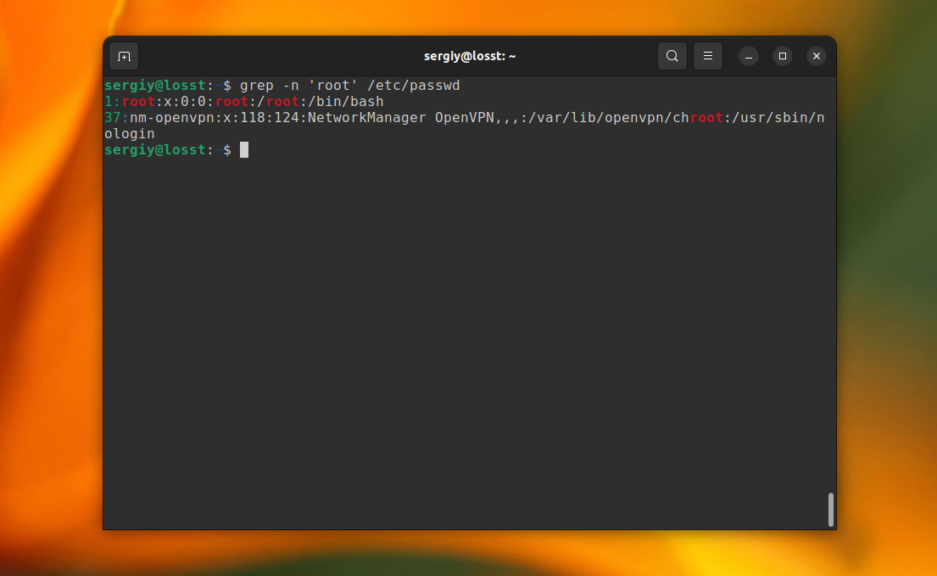
grep -n ‘root’ /etc/passwd
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ «[» в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
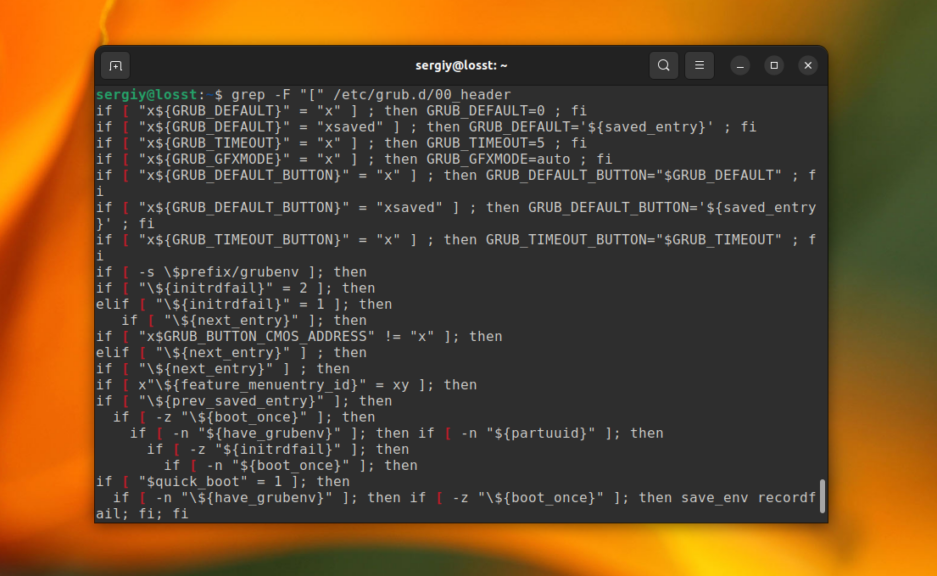
grep -F «[» /etc/grub.d/00_header
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
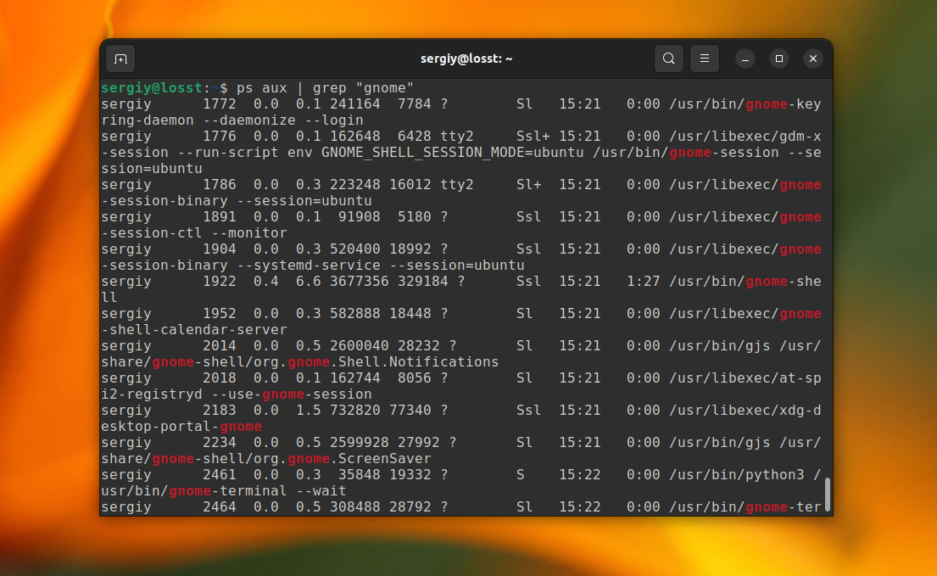
ps aux | grep «gnome»
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
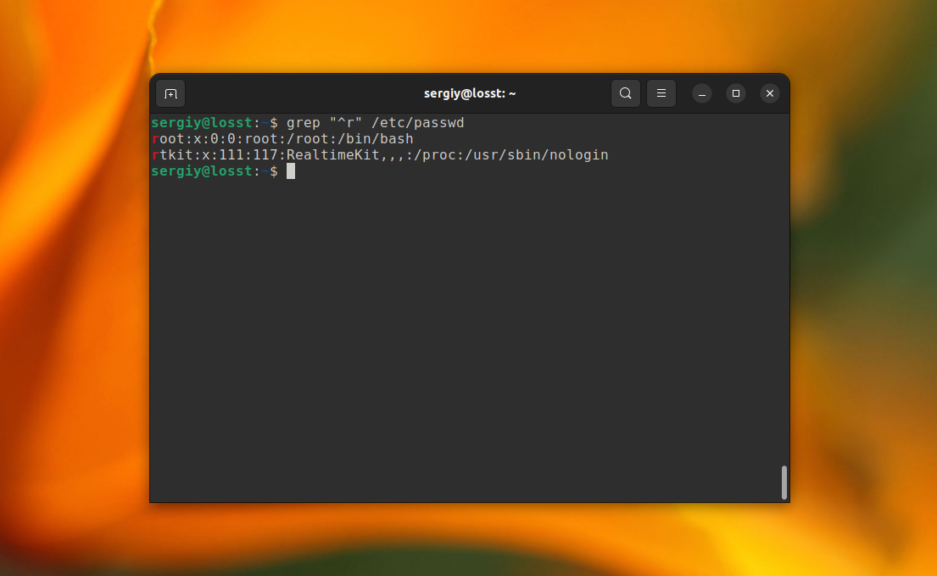
grep «^r» /etc/passwd
Или же строки, которые содержат большие буквы:
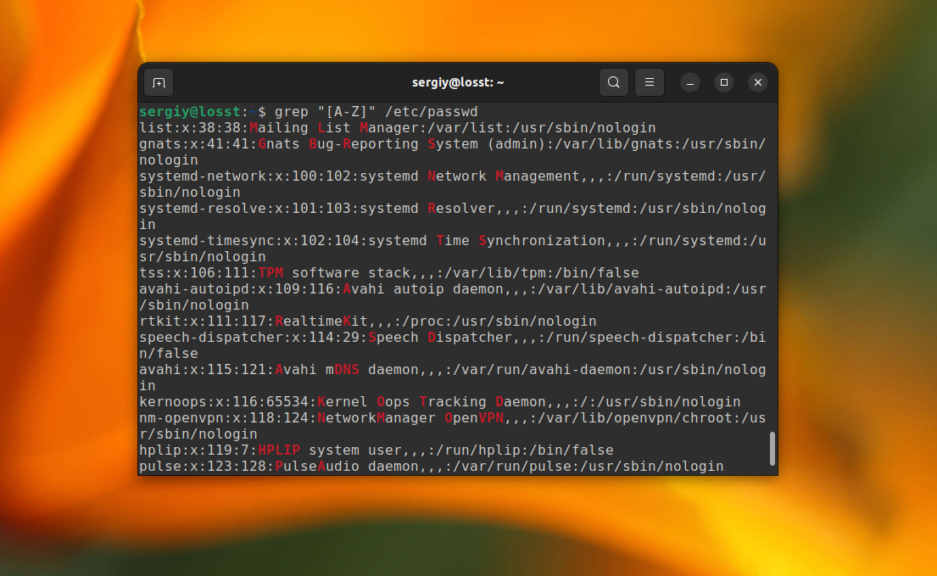
grep «[A-Z]» /etc/passwd
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
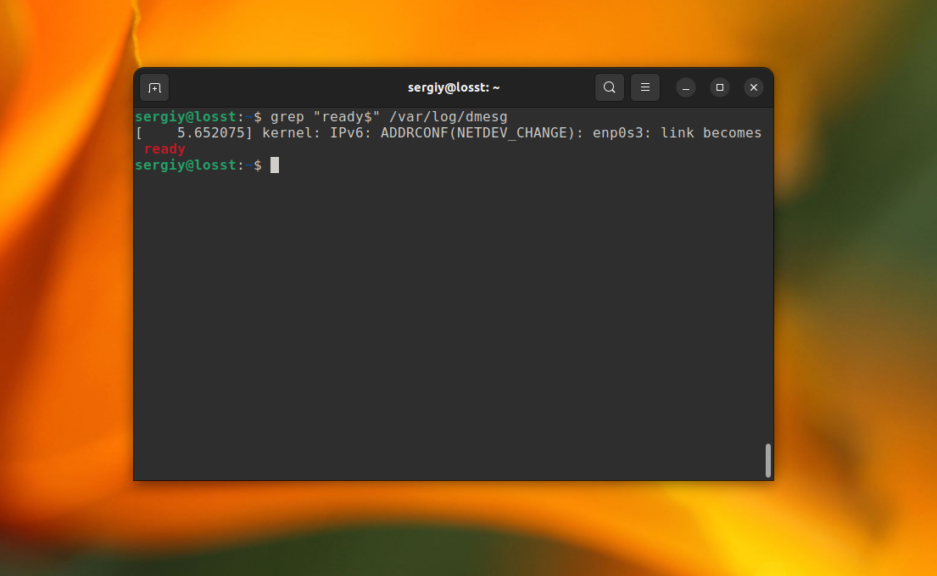
grep «ready$» /var/log/dmesg
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + — одно или больше повторений предыдущего символа;
- ? — ноль или одно повторение предыдущего символа;
- — повторение предыдущего символа от n до m раз;
- | — позволяет объединять несколько паттернов.
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
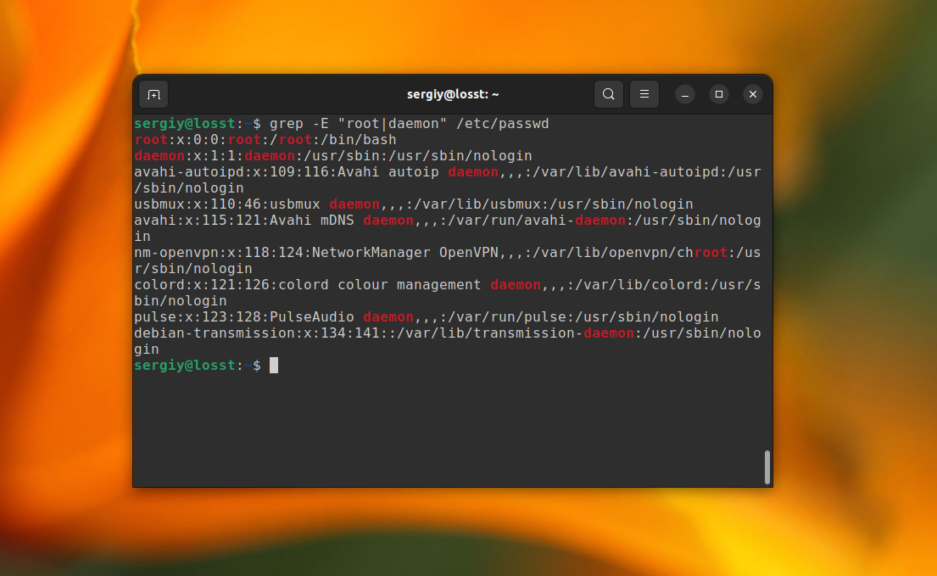
grep -E «root|daemon» /etc/passwd
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
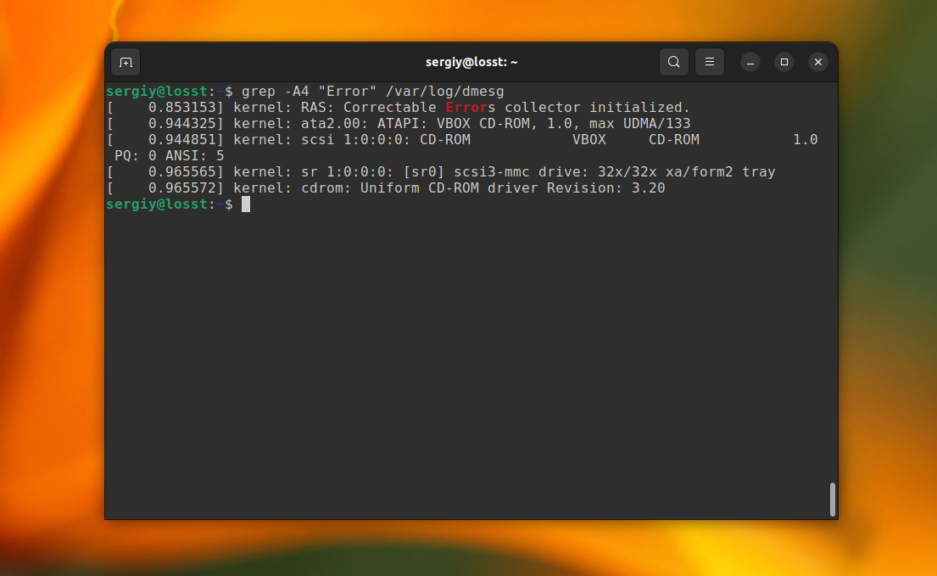
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону «Error»:
grep -A4 «Error» /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
grep -B4 «Error» /var/log/dmesg
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
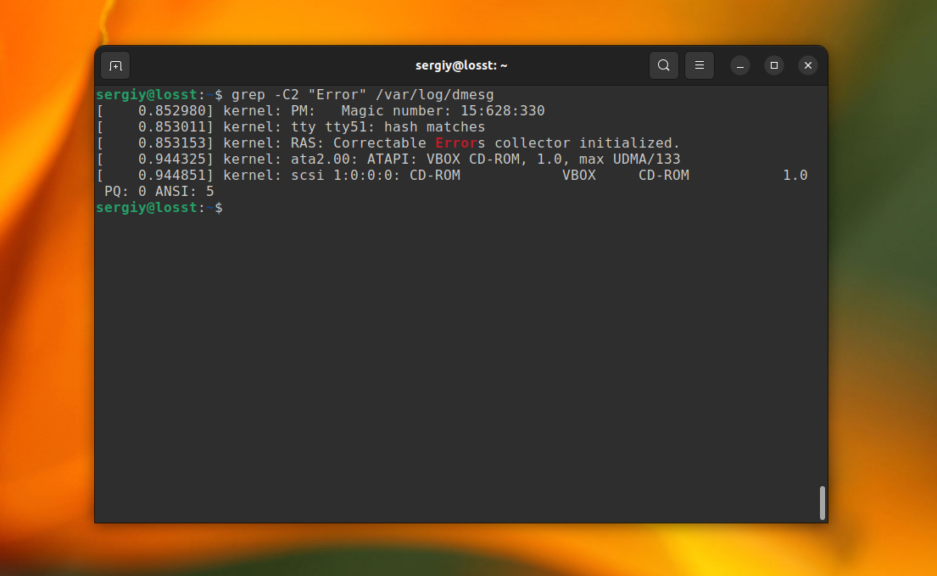
grep -C2 «Error» /var/log/dmesg
6. Рекурсивный поиск в grep
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
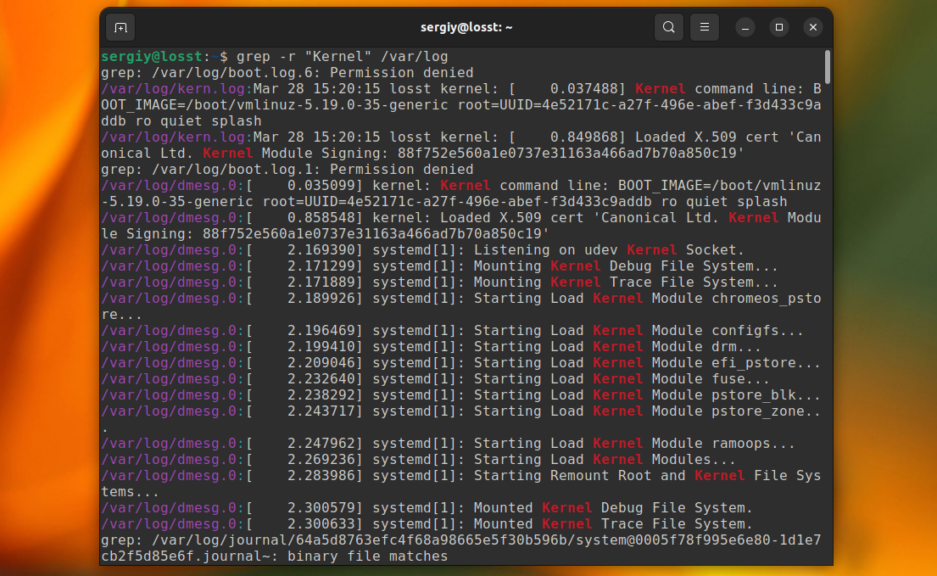
grep -r «Kernel» /var/log
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI «Kernel» /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs «Kernel» /var/log
7. Выбор файлов для поиска
С помощью опций —include и —exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
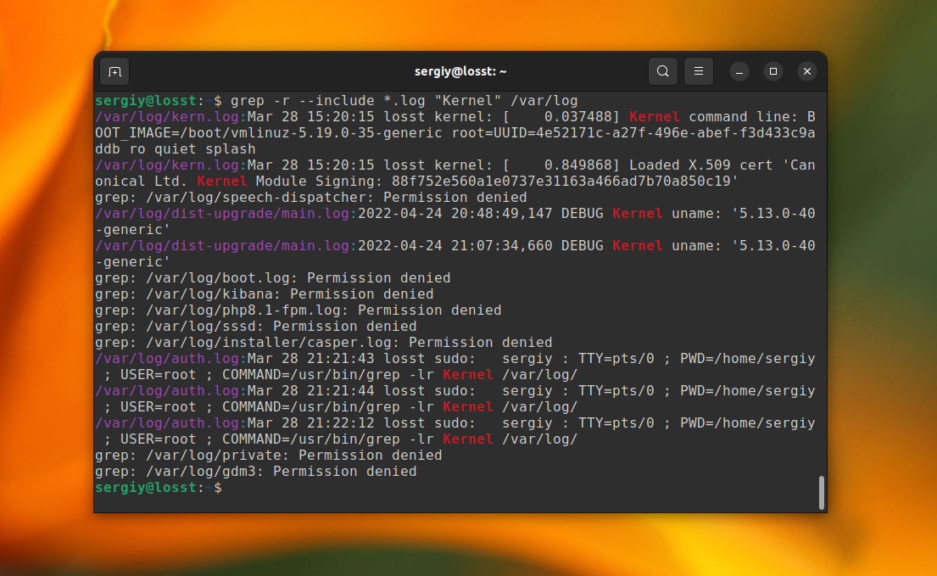
grep -r —include=»*.log» «Kernel» /var/log
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию —exclude:
grep -r —exclude=»*.journal» «Kernel» /var/log
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
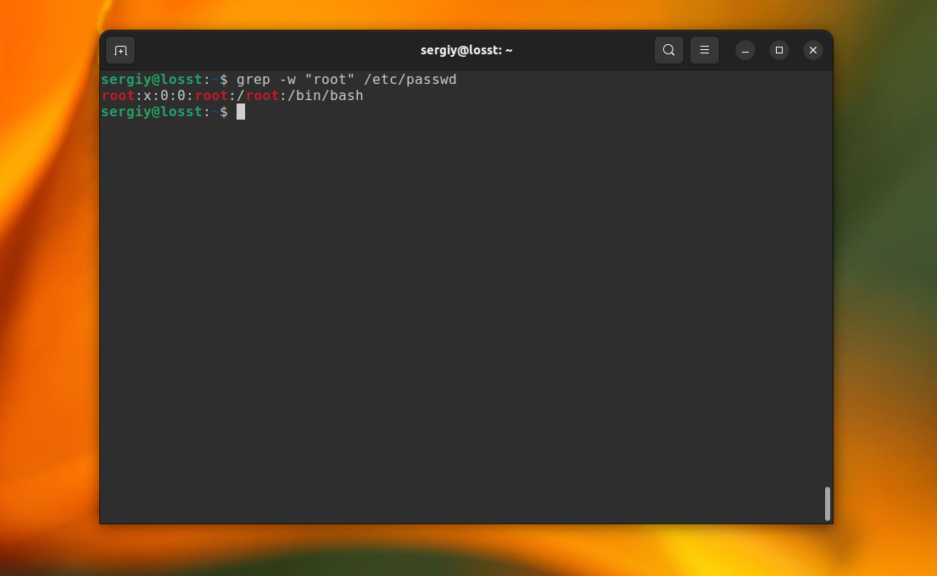
grep -w «root» /etc/passwd
9. Количество строк
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
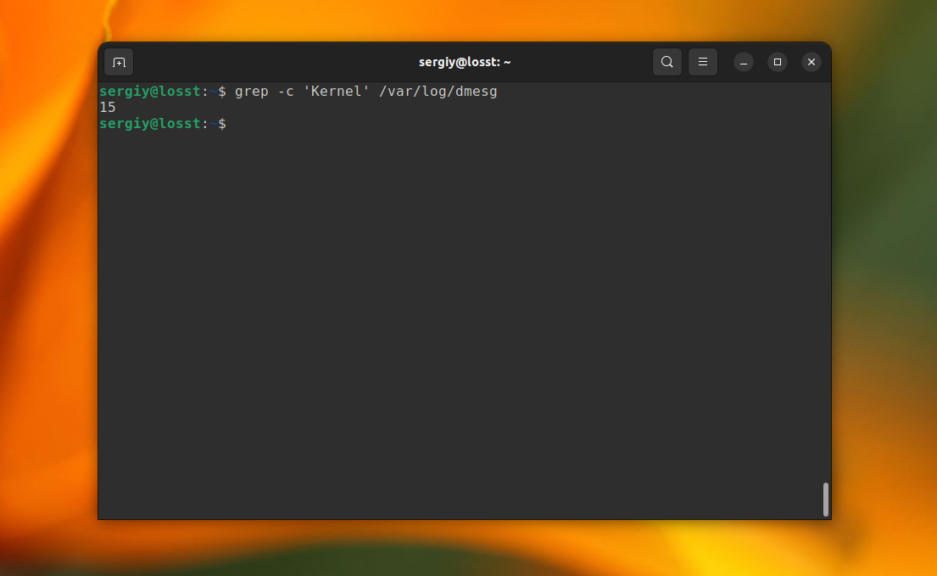
grep -c ‘Kernel’ /var/log/dmesg
10. Инвертированный поиск
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
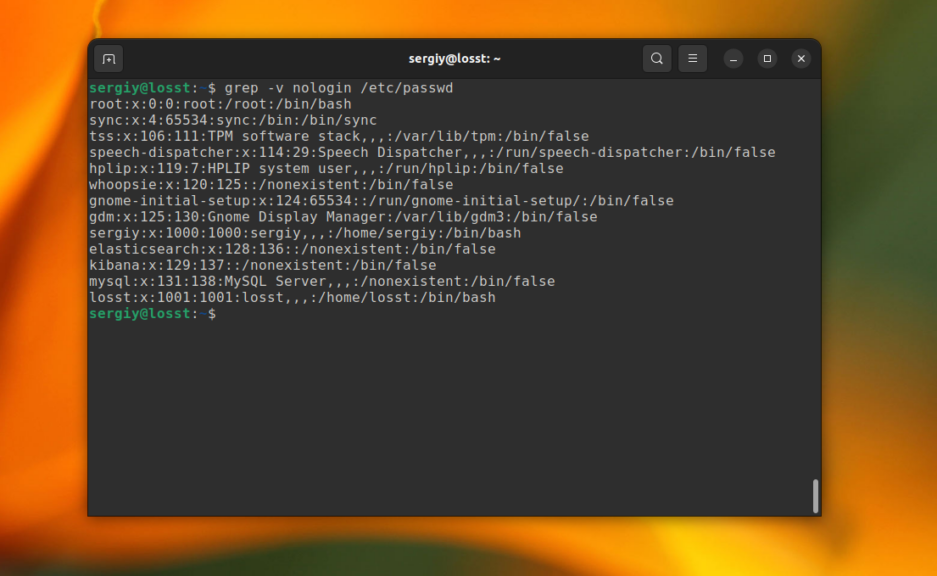
grep -v nologin /etc/passwd
11. Вывод имен файлов
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
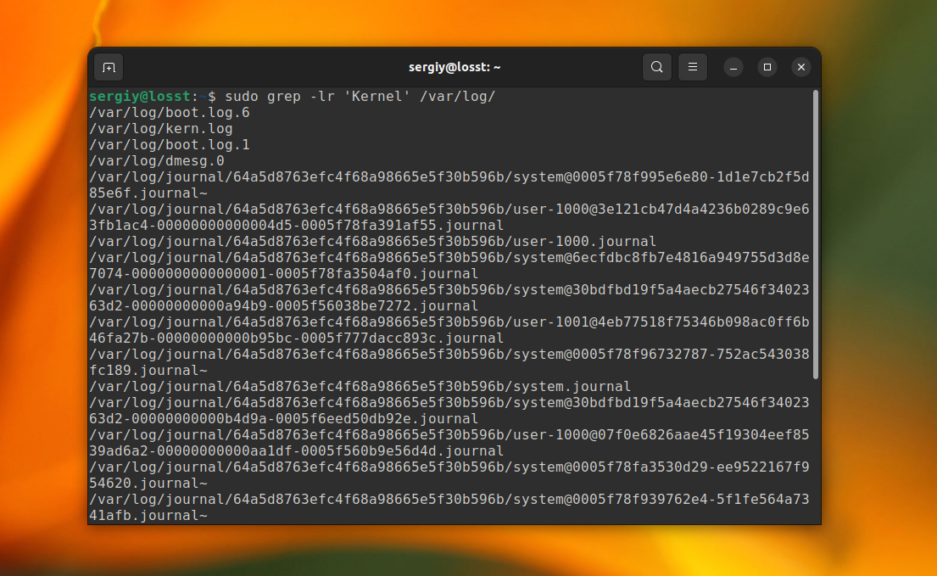
grep -lr ‘Kernel’ /var/log/
12. Цветной вывод
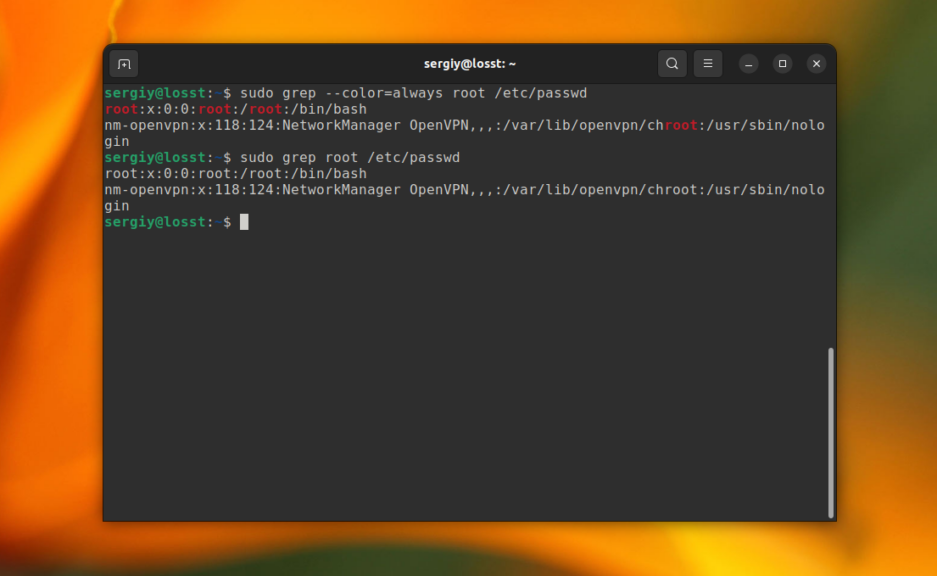
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию —color со значением always:
sudo grep —color=always root /etc/passwd
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Источник: losst.pro
grep(1)
/usr/bin/grep [ -bchilnsvw ] ограниченное_регулярное_выражение
[ имя_файла . ] /usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
-e список_образцов . [ -f файл_образцов ] .
[ имя_файла . ] /usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
[ -e список_образцов . ] -f файл_образцов .
[ имя_файла . ] /usr/xpg4/bin/grep [ -E | -F ] [ -c | -l | -q ] [ -bhinsvwx ]
образец [ имя_файла . ]
ОПИСАНИЕ
Утлита grep выполняет поиск образца в текстовых файлах и выдает все строки, содержащие этот образец. Она использует компактный недетерминированный алгоритм сопоставления.
Будьте внимательны при использовании в списке_образцов символов $, *, [, ^, |, (, ) и , поскольку они являются метасимволами командного интерпретатора. Лучше брать весь список_образцов в одиночные кавычки ‘. ‘.
Если имя_файла не указано, grep предполагает поиск в стандартном входном потоке. Обычно каждая найденная строка копируется в стандартный выходной поток. Если поиск осуществлялся в нескольких файлах, перед каждой найденной строкой выдается имя файла.
/usr/bin/grep
Утилита /usr/bin/grep использует для задания образцов ограниченные регулярные выражения, описанные на странице справочного руководства regexp(5).
/usr/xpg4/bin/grep
Опции -E и -F влияют на способ интерпретации списка_образцов программой /usr/xpg4/bin/grep. Если указана опция -E, программа /usr/xpg4/bin/grep интерпретирует образцы в списке как полные регулярные выражения (см. описание опции -E). Если же указана опция -F, grep интерпретирует список_образцов как фиксированные строки. Если ни одна из этих опций не указана, grep интерпретирует элементы списка_образцов как простые регулярные выражения, описанные на странице справочного руководства regex(5).
ОПЦИИ
Следующие опции поддерживаются обеими программами, /usr/bin/grep и /usr/xpg4/bin/grep:
| -b | Предваряет каждую строку номером блока, в котором она была найдена. Это может пригодиться при поиске блоков по контексту (блоки нумеруются с 0). |
| -c | Выдает только количество строк, содержащих образец. |
| -h | Предотвращает выдачу имени файла, содержащего сопоставившуюся строку, перед собственно строкой. Используется при поиске по нескольким файлам. |
| -i | Игнорирует регистр символов при сравнениях. |
| -l | Выдает только имена файлов, содержащих сопоставившиеся строки, по одному в строке. Если образец найден в нескольких строках файла, имя файла не повторяется. |
| -n | Выдает перед каждой строкой ее номер в файле (строки нумеруются с 1). |
| -s | Подавляет выдачу сообщений о не существующих или недоступных для чтения файлах. |
| -v | Выдает все строки, за исключением содержащих образец. |
| -w | Ищет выражение как слово, как если бы оно было окружено метасимволами < и >. |
/usr/xpg4/bin/grep
Следующие опции поддерживаются только утилитой /usr/xpg4/bin/grep:
- Полное регулярное выражение, за которым идет +, соответствует одному или более вхождениям полного регулярного выражения.
- Полное регулярное выражение, за которым идет ?, соответствует 0 или одному вхождению полного регулярного выражения.
- Полным регулярным выражениям, разделенным символами | или символами новой строки, соответствуют строки, сопоставляющиеся с любым из указанных выражений.
- Полные регулярные выражения можно брать в круглые скобки () для группировки.
ОПЕРАНДЫ
Поддерживаются следующие операнды:
| имя_файла | Имя файла, в котором должен выполняться поиск по образцу. Если файлы не указаны, поиск ведется в стандартном входном потоке. |
/usr/bin/grep
| образец | Задает образец для поиска во входных строках. |
/usr/xpg4/bin/grep
| образец | Задает один или несколько образцов для поиска во входных строках. Этот операнд используется так же, как если бы он был задан в виде -eсписок_образцов. |
ИСПОЛЬЗОВАНИЕ
Опция -epattern_list имеет тот же эффект, что и операнд список_образцов, но позволяет начинать список_образцов с дефиса. Она также пригодится в случаях, когда удобнее задавать несколько образцов в виде отдельных аргументов.
Можно задавать несколько опций -e и -f. При этом утилита grep использует все заданные образцы при сопоставлении с входными строками. (Учтите, что порядок проверки не задается. Если реализация находит среди образцов пустую строку, она может искать сначала именно ее, тем самым, сопоставление будет найдено для каждой строки, а остальные образцы, по сути, — проигнорированы.)
Опция -q дает средства простого определения, находится ли образец (или строка) в группе файлов. При поиске в нескольких файлах она обеспечивает более высокую производительность (поскольку позволяет завершить работу, как только будет найдено первое соответствие) и не требует дополнительных усилий пользователя при формировании набора файлов-аргументов (поскольку grep вернет нулевой статус выхода при обнаружении соответствия даже если при работе с предыдущими операндами-файлами произошла ошибка доступа или чтения.)
Работа с большими файлами
Описание поведения утлиты при работе с файлами размером от 2 Гбайтов (2**31 байтов) см. на странице справочного руководства largefile(5).
ПРИМЕРЫ
Пример 1: Поиск всех вхождений слова
Чтобы найти все вхождения слова «Posix» (независимо от регистра) в файле text.mm и выдать номера соответствующих строк:
example% /usr/bin/grep -i -n posix text.mm
Пример 2: Поиск пустых строк
Чтобы найти все пустые строки в стандартном входном потоке:
example% /usr/bin/grep -v .
Пример 3: Поиск строк, содержащих фиксированные подстроки
Обе следующих команды выдают все строки, содержащие подстроки abc, def или и ту, и другую:
example% /usr/xpg4/bin/grep -E ‘abc def’
example% /usr/xpg4/bin/grep -F ‘abc def’
Пример 4: Поиск строк, соответствующих образцу
Обе следующих команды выдают все строки abc или def:
example% /usr/xpg4/bin/grep -E ‘^abc$ ^def$’
example% /usr/xpg4/bin/grep -F -x ‘abc def’
ПЕРЕМЕННЫЕ СРЕДЫ
Описание следующих переменных среды LC_COLLATE, LC_CTYPE, LC_MESSAGES и NLSPATH, влияющих на работу команды grep, см. на странице справочного руководства environ(5).
СТАТУС ВЫХОДА
Команда заврешается со следующими статусами выхода:
| Найдена одна или несколько соответствующих строк. | |
| 1 | Соответствующие строки не найдены. |
| 2 | Выявлены синтаксические ошибки или недоступные файлы (даже если были найдены соответствующие строки). |
АТРИБУТЫ
Описание следующих атрибутов см. на странице справочного руководства attributes(5):
/usr/bin/grep
| ТИП АТРИБУТА | ЗНАЧЕНИЕ АТРИБУТА |
| Доступен в пакете | SUNWcsu |
| CSI | включено |
/usr/xpg4/bin/grep
| ТИП АТРИБУТА | ЗНАЧЕНИЕ АТРИБУТА |
| Доступен в пакете | SUNWxcu4 |
| CSI | включено |
ССЫЛКИ
ПРИМЕЧАНИЯ
/usr/bin/grep
Строки ограничены только размером доступной виртуальной памяти. Если обрабатывается строка со встроенными нулевыми символами, grep будет вести поиск только до первого такого символа; если эта часть строки соответствует образцу, будет выдана вся строка.
/usr/xpg4/bin/grep
Если файл содержит строки длиннее LINE_MAX байтов или двоичные данные, результаты работы непресказуемы. Значение LINE_MAX определено в файле /usr/include/limits.h.
Copyright 2002 В. Кравчук, OpenXS Initiative, перевод на русский язык
Источник: www.opennet.ru
Использование команды grep в Linux
Утилита grep, с которой мы сегодня познакомимся, — это инструмент Unix, принадлежащий к тому же семейству, что и утилиты egrep и fgrep. Все эти инструменты Unix предназначены для выполнения повторяющихся задач поиска в файлах и тексте. Вы можете искать файлы и их содержимое для извлечения полезной информации, задавая определенные критерии поиска с помощью команды grep.
Говорят, что GREP означает Global Regular Expression Print, но откуда взялась эта команда «grep»? grep в основном происходит от конкретной команды для очень простого и старого текстового редактора Unix под названием ed. Вот как выглядит команда ed:
g/re/p
Цель этой команды очень похожа на то, что мы подразумеваем под поиском с помощью grep. Эта команда собирает все строки в файле, соответствующие определенному текстовому шаблону.
Давайте рассмотрим команду grep подробнее. В этой статье мы расскажем об установке утилиты grep и приведем несколько примеров, с помощью которых вы сможете узнать, как и в каких сценариях ее можно использовать.
Установка grep
Утилита grep поставляется по умолчанию в большинстве систем Linux
Если она не установлена в вашей системе, откройте терминал Ubuntu или Debian, либо через Dash, либо с помощью сочетания клавиш Ctrl+Alt+T. Затем введите следующую команду от имени root, чтобы установить grep через apt-get:
sudo apt-get install grep
В CentOS
sudo yum install grep
Введите y, когда вам будет предложено выбрать y/n во время процедуры установки. После этого утилита grep будет установлена в вашей системе.
Вы можете убедиться в правильности установки, проверив версию grep с помощью следующей команды:
grep —version

Использование команды grep с примерами
Команду grep можно лучше всего объяснить, представив несколько сценариев, в которых она может быть использована. Вот несколько примеров:
Поиск файлов
Если вы хотите найти имя файла, содержащее определенное ключевое слово, вы можете отфильтровать список файлов с помощью команды grep следующим образом:
ls -l | grep -i «слово»
ls -l | grep -i drives
Эта команда выведет список всех файлов в текущем каталоге с именем файла, содержащим слово «drives».

Поиск строки в файле
С помощью команды grep можно получить предложение из файла, содержащее определенную строку текста.
grep «строка» имя файла
grep «Lorem» sample.txt

Мой пример файла sample.txt содержит предложение со строкой «Lorem», которое вы можете видеть в приведенном выше выводе. В результатах поиска ключевое слово и строка отображаются в цветном виде.
Поиск строки в более чем одном файле
Если вы хотите найти предложения, содержащие вашу текстовую строку, во всех файлах одного типа, к вашим услугам команда grep.
grep «строка» ИмяФайла*
grep «строка» *.расширение
grep «Vivamus» sample*

Эта команда извлечет все предложения, содержащие строку «Vivamus» из всех файлов с именем, содержащим ключевое слово «sample».
grep «Vivamus» *.txt

Эта команда извлечет все предложения, содержащие строку «Vivamus», из всех файлов с расширением .txt.
Поиск строки в файле без учета регистра строки
В приведенных выше примерах моя текстовая строка, к счастью, была в том же регистре, что и в моих образцах текстовых файлов. Если бы я ввел следующую команду, результатом поиска был бы ноль, потому что текст в моем файле не начинается со слова «Vivamus», написанного в верхнем регистре.
grep «Vivamus» *.txt
Давайте попросим grep игнорировать регистр строки поиска и выводить результаты поиска на основе этой строки с помощью опции -i.
grep -i «строка» имя_файла
grep -i «vivamus» *.txt

Эта команда извлечет все предложения, содержащие строку «Vivamus», из всех файлов с расширением .txt. При этом не будет учитываться, в верхнем или нижнем регистре была строка поиска.
Поиск на основе регулярного выражения
С помощью команды grep вы можете задать регулярное выражение с начальным и конечным ключевым словом. На выходе вы получите предложение, содержащее все выражение между указанным вами начальным и конечным ключевым словом. Эта возможность очень удобна, так как вам не нужно писать целое выражение в команде поиска.
grep «НачалоСтроки.*КонецСтроки» имя файла
grep «Vivamus.*.pellentesque» sampleFile.txt

Эта команда выведет предложение, содержащее выражение (начинающееся с моего Vivamus и заканчивающееся на моем pellentesque) из файла, который я указал в команде grep.
Вывод заданного количества строк после/перед строкой поиска
Вы можете использовать команду grep для печати N-ного количества строк до/после строки поиска из файла. Результат поиска также включает строку текста, содержащую строку поиска.
Синтаксис для N количества строк после ключевой строки:
grep -A «строка» имя_файла
grep -A 3 -i «Vivamus» sample3.txt
Вот как выглядит мой образец текстового файла:
А вот как выглядит вывод команды:
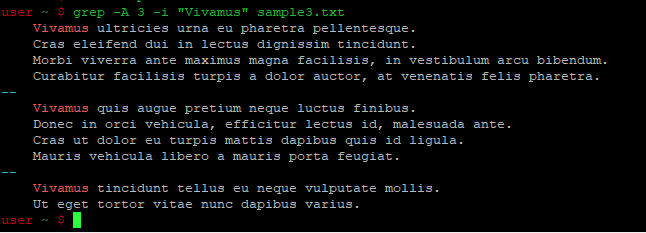
Выводится 3 строки, включая ту, которая содержит искомую строку, из файла, который я указал в команде grep.
Синтаксис для N количества строк перед ключевой строкой:
grep -B «строка» имя_файла
Вы также можете искать N количество строк «вокруг» текстовой строки. Это означает N количество строк до и N после текстовой строки.
grep -B 3 -i «Vivamus» sample3.txt
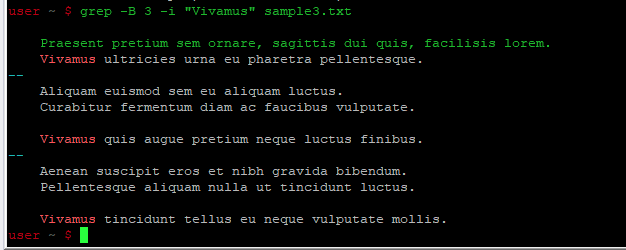
Синтаксис для поиска N количества строк вокруг ключевой строки:
grep -C «строка» имя файла
grep -C 2 -i «Vivamus» sample3.txt

Благодаря простым примерам, описанным в этой статье, вы можете получить представление о команде grep. Затем вы можете использовать ее для поиска отфильтрованных результатов, которые могут включать файлы или содержимое файла. Это сэкономит много времени, которое тратилось на пролистывание всех результатов поиска до того, как вы освоили команду grep.
Похожие записи:
- Общие случаи использования команды Touch в Linux
- Усечение файла в Bash
- Обновление ядра Linux в Ubuntu с помощью UKUU
- 4 способов редактирования PDF-файлов в Ubuntu
- Установка FFmpeg в Linux
- Crontab — Планировщик задач в Linux
- Использование команды Top в Linux
Источник: g-soft.info