
Илья – главный редактор сайта softdroid.net. Является автором нескольких сотен руководств и статей по настройке Android. Около 15 лет занимается ремонтом техники и решением технических проблем iOS и Android. Имел дело практически со всеми более-менее популярными марками мобильных смартфонов и планшетов Samsung, HTC, Xiaomi и др. Для тестирования используется iPhone 12 и Samsung Galaxy S21 с последней версией прошивки.
Разговор пойдет о программе ABBYY FineReader 12, то есть, о ее последней версии. Не заглядывая слишком далеко, мы выбрали самый известный продукт компании ABBYY, который, к его достоинствам, отлично русифицирован. Уже на первый взгляд Fine Reader (FR) производит впечатление программы с хорошей русскоязычной поддержкой: в этом плане, действительно, все сделано на весьма достойном уровне, включая справочную информацию.
Вначале — отступление. Всегда актуален вопрос, как перевести весь или некоторую часть архива в цифровой формат (и что, собственно, понимать под словом «цифровой»). Едва ли покупка сканера решает все проблемы. Конечно, очень часто в комплекте с документацией к сканеру поставляется диск или несколько с фирменным программным обеспечением.
FineReader PDF – редактор для решения любых задач с бумажными и PDF документами
Однако уже на стадии санирования выясняется, что качество сканирующей программы оставляет желать лучшего либо формат, в котором происходит сохранение, к сожалению, не пригоден для хранения. Почему? Большинство графических форматов не отделяют текст от нетекстового пространства документа, и поэтому скопировать какой-либо отрывок из подобного файла не предоставляется возможным.
Именно в таких случаях на выручку приходят функциональные программы-«распознавальщики» текста, в возможности которых, в частности, входит извлечение текста из изображения.
Знакомство с ABBYY FineReader
Пакет ABBYY Finereader 12 — система оптического распознавания текстов (Optical Character Recognition — OCR ). Предназначена как для автоматического ввода печатных документов в компьютер, так и для конвертирования PDF–документов и фотографий в редактируемые форматы (из руководства к программе)
Аббревиатура «OCR» применима для всех приложений для распознавания данных (а не только текста). Источником для извлечения данных может служить печатный или электронный документ. Когда-то не очень давно об OCR , в той или иной форме, мало кто знал, да и процесс перевода текста в электронный вид превращался в сущую рутину, вплоть до ручной перепечатки текста оригинала. Сегодня, обладая планшетным сканером (ручным в домашних условиях пользуются единицы) и finereader 12 — будьте уверены — никаких сложностей в сканировании и распознании не возникнет.
Начиная с шестой версии, FineReader поддерживает импорт и экспорт в формат PDF , запатентованный компанией Adobe. Многие читатели, вероятно, сталкивались с трудностями перевода из этого формата в любой иной (doc и т. п.), поскольку действительно полезных программ в этой области не так уж и много (внимания достоин разве что дочерний продукт компании ABBYY — PDF Transformer). Дело в том, что подобные программы проводят распознавание текста только единожды, вследствие чего «идентичность» результата вовсе невелика (в зависимости от сложности документа), плюс к тому изрядно теряется форматирование документа.
FineReader. Урок 1: Интерфейс. Настройка
В случае с FineReader все обстоит по-иному. В девятую версию программы внедрена технология под названием Document OCR . В ее основе лежит принцип цельного распознавания документа: он анализируется и распознаётся как единое целое, а не постранично. При этом всевозможные колонки, колонтитулы, шрифты, стили, сноски и изображения остаются нетронутыми или заменяются близкими к оригиналу.
Установка пакета
Demo-версию Finereader 12 можно скачать на сайте Abbyy.ru, в разделе Download, полная лицензионная версия распространяется на CD-диске. О способах покупки можно узнать на этом же сайте в разделе «Купить».

ABBYY FineReader распространяется в нескольких версиях: Professional Edition, Corporate Edition, Site License Edition и др. Отличие версии Professional от остальных состоит в том, что предназначена для работы в корпоративной сети с возможностью совместной работы над распознаванием документов. В остальном разница незначительна и зависит от выбора условий лицензионного соглашения.
Сложно представить, что 12 лет назад существовал FineReader 2.0, занимавший около 10 Мб дискового пространство. Со временем пакет «вырос» десятикратно и сейчас в установленном виде занимает до 300 Мб. Много это или мало — судите сами. Новый FR поддерживает 179 языков распознавания, среди которых есть малоизвестные искусственные языки (идо, интерлингва, окциденталь и эсперанто), языки программирования, формул и т. п. Не будем забывать и о поддержке различных форматов, сценариев. Так что, если по какой-то причине вы захотите ограничить занимаемое пакетом место, при установке отметьте только те компоненты, которые будут востребованы при работе.
Выбор компонентов влияет на длительность установки, которая, впрочем, не должна занять много времени. В процессе инсталляции вас ознакомят с основными возможностями FR. После активации (по Интернету, через E-mail, с помощью полученного кода и др.) программа готова к полнофункциональной работе. В demo-режиме вы непременно столкнетесь с различными ограничениями, которые, к сожалению, не позволяют полноценно использовать пакет.
Интерфейс FineReader. Функциональные возможности
Доступ к возможностям программы доступен как с помощью сценариев, которые появятся в главном меню сразу после процесса инсталляции, так и, собственно, через основной интерфейс.

Внешний вид программы из версии к версии не претерпевает особых изменений: разработчики не видят смысла его кардинально менять. Значительное внимание уделяется эргономике, что заметно по всем продуктам компании ABBYY (Lingvo, PDF Transformer, FlexiCapture…). Другими словами, интерфейс Fine Reader 12 хорошо продуман и предрасположен ко всем пользователям, не исключая новичков.
Принцип «Получить результат за одно нажатие» придется по вкусу тем, кто не привык что-то настраивать и изменять. С другой стороны, более опытные пользователи могут тщательно настроить FineReader через диалог настроек (Сервис -> Опции…). Единственный нюанс: для комфортной работы в приложении желательно установить разрешение экрана в 1280?800, чтобы все инструменты всегда были, что называется, под рукой.
После запуска программы Файн Ридер появится окно с кнопками быстрого доступа к функциям программы. Данное меню также доступно через меню Сервис -> ABBYY FineReader, кнопку «Основные сценарии» в крайнем правом углу программы или через сочетание клавиш Ctrl+N (по аналогии с Word, где данной комбинацией вызывается открытие нового документа).
Сканировать в Microsoft Word: в девятой версии FineReader появилась поддержка пока еще не успевшего стать популярным Microsoft Word 2007. В свою очередь, на панели инструментов в приложениях Microsoft Office, в разделе надстроек после установки FR появляется «фирменный» красный значок.


Помимо Microsoft Office, FR поддерживает интеграцию с Microsoft Outlook, обеспечивает экспорт результатов распознавания в те же Microsoft Word, Excel, Lotus Word Pro, Corel WordPerect и Adobe Acrobat. Эти возможности в некоторой мере облегчают и ускоряют работу с программой, в особенности, если вам приходится регулярно в ней работать.
Сканировать в Microsoft Excel: сканирование в XLS (формат программы Microsoft Excel) может быть оправдано в том случае, если сканируемое изображение содержит таблицы.
Сканировать в PDF : поводов для сканирования в PDF может быть множество. Один из них — безопасность: это единственный формат, знакомый FR, в настройках которого можно установить блокировку паролем. Пароль устанавливается не только на открытие документа, но и на его печать и другие операции. Имеется возможность выбрать один из трёх уровней шифрования: 40-битный, 128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте AES (Advanced Encryption Standard).
Конвертировать фотографию в Microsoft Word: перевод файла из графического формата (причем это может быть PDF или многостраничное изображение) в DOC /DOCX.
Сканировать и сохранить изображение: непосредственное сканирование аналогового графического формата в графический же, но электронный.
Открыть в Файн Ридер: открыть графический файл ( PDF , BMP , PCX , DCX , JPEG , JPEG 2000, TIFF , PNG ) для распознавания FineReader.
Работа в FineReader
Сейчас — вкратце об особенностях работы программы. Весь процесс делится на сканирование, распознавание и сохранение результатов. После того как вы выбрали тип действия программы, указали файл или устройство для сканирования, FineReader поэтапно выполняет свою задачу, кстати, достаточно ресурсоемкую для центрального процессора.
Если вы — счастливый обладатель двухъядерного процессора, то, работая в пакете Fine Reader 12, можете оценить мощь быстродействия компьютера. Дело в том, что FR, обнаружив двухъядерный процессор, распознает не одну, а сразу две страницы документа параллельно. Мелочь — а приятно.
Вначале идет сканирование, затем — распознавание и экспорт временного документа в выбранный формат.

Сканирование. Никаких предварительных настроек в приложении FineReader (кроме выбора считывающего устройства) перед сканированием делать не нужно. Именно поэтому и были придуманы сценарии: они призваны упростить выполнение однотипных действий.
Распознавание. Упрощение коснулось и других мелочей. Так, если вспомнить прошлые версии программы, раньше нам приходилось вручную менять язык (языки, если их было несколько) документа. Сейчас это происходит автоматически, правда, тоже не всегда. В последнем случае FR ненавязчиво предлагает проверить язык документа.
Возвращаясь к технологии распознавания FR: почему программа вначале сканирует весь документ целиком, а не постранично? Как уже было сказано, текст распознается, исходя из всего содержания: подбираются аналогичные по размеру/гарнитуре шрифты, таблицы и границы, отступы и т. п.
Не удивляйтесь, если программа FineReader 12 выдаст сообщение, мол, страница не может быть распознана, поскольку не найдено ни одной области текста. Эксперимента ради, мы сфотографировали на мобильный телефон с экрана LCD -дисплея область текстового документа (впрочем, зная, результат уже заранее). Fine Reader 12 не распознал текст изображения, поскольку оно было явно такого качества, которого для этого явно недостаточно. При втором заходе мы сфотографировали цифровым фотоаппаратом страницу с текстом при нормальном освещении.
FineReader без проблем распознал отрывок, сохранив форматирование и отметив маркерами некоторые сомнительные моменты или символы, у которых могут быть вариативное написание.
Как видно на изображении, преимущественно это точки, дефисы, запятые — в общем, мелкие символы. Кроме этого, хорошо видно, что программа учла неровности, изогнутости сфотографированной страницы и выровняла строки текста. Вывод — FR отлично справился со своей пусть и не очень сложной задачей.
Изредка могут оставаться незамеченными программой Файн Ридер кое-какие незначительные моменты, однако их легко откорректировать вручную. Благо, в пакете есть свой WYSIWYG -редактор, возможностей которого вполне достаточно для совершения окончательной правки документа. Проверка орфографии тоже имеется.
Как повысить точность распознавания, чтобы затем в меньшей степени заниматься правкой текста? Во-первых, вы можете подключить пользовательский словарь Microsoft Word. Правда, сложно судить о повышении точности, разве что о повышении словарного запаса спеллчекера (модуля, проверяющего орфографию и грамматику). Кроме всего прочего, для улучшения распознавания есть смысл ознакомиться с настройками программы (Сервис -> Опции) и выбрать один из двух режимов:
тщательное распознавание — его можно выбрать при распознавании документов любой «сложности»: с таблицами без линий сетки, текста, графиков, таблиц на цветном фоне и др. Также может помочь при некачественном источнике для распознавания
быстрое распознавание — данный режим рекомендуется для обработки больших объемов документов с простым оформлением или же в том случае, если время не позволяет проводить тщательное распознавание. В большинстве случаев, когда вы имеете с черным печатным текстом на белом фоне, можно остановиться на быстром распознавании.
Вообще, улучшение качества работы FineReader — это отдельная тема для разговора, о деталях которой вы можете узнать из официальной справки, а именно в разделе «Как улучшить полученные результаты».
Сохранение документа. Последний этап работы в программе Fine Reader 12 — сохранение итогового результата в определенный графический/текстовый формат. Предварительно настройки сохранения можно указать в опциях FR: Сервис ->Опции, вкладка «Сохранить». Для каждого формата предусмотрены свои настройки.
При сохранении в DOCX -формате следует побеспокоится о совместимости форматов (Файлы DOCX -формата не распознаются в Word 2003 <). В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
ABBYY Screenshot Reader
Во многие объемные пакеты очень часто разработчики любят добавлять мелкие сервисные утилиты. Скажем, в состав известного приложения для записи дисков Nero входит набор из 3 — 5 утилит, позволяющих то, чего не может даже сам Nero. Обзор Nero Express доступен здесь (здесь же можно скачать в составе Файн Ридер 12).
Что касается FineReader, то в его составе обнаруживается одно небольшое приложение Screenshot Reader. С его помощью вы можете сделать снимок экрана и быстро перевести его в желаемый формат посредством FR. Программа доступна через меню «Пуск» (Пуск -> Все программы -> ABBYY FineReader 12.0 -> ABBYY Screenshot Reader.).
Возможности Screenshot Reader несколько шире, чем может показаться на первый взгляд. (а иначе можно было бы обойтись простым нажатием клавиши «PrintScreen» на клавиатуре). В дополнение к тому, что Screenshot Reader делает снимок экрана (или, точнее, выбранной области экрана), программа тесно интегрирована с FR.
При нажатии на кнопку «Снимок» на панели Screenshot Reader курсор меняет форму и включается инструмент выделения области экрана. Выделенная область изображения заключается в рамку для дальнейшего распознавания текста (оно запускается автоматически).
В выпадающем списке вы можете выбрать желаемое действие: по сути, Screenshot Reader дублирует быстрые сценарии FR c той разницей, что вместо снимка со сканера «на вход» поступает снимок экрана.
Следует отметить, программа, наравне со всем пакетом, требует активации. При регистрации продукта ABBYY FineReader 12 Professional Edition Screenshot Reader предоставляется бесплатно, в качестве «бонуса».
Заключение
FineReader — незаменимая программа для сканирования и распознавания графических данных. Русскоязычный интерфейс и доступность настроек не отпугнут неопытного пользователя. Поддержка новейших форматов, инновационные технологии и, как следствие, качественное распознавание делают программу оптимальным выбором, тем более что конкурентов в этой области у ABBYY FineReader все еще не предвидится.
Горячие клавиши FineReader 12
- Создать новый документ ABBYY FineReader — CTRL +N
- Открыть документ ABBYY FineReader 12 — CTRL +SHIFT+N
- Сохранить страницы — CTRL +S
- Сохранить изображение в файл — CTRL +ALT+S
- Распознать все страницы документа — CTRL +SHIFT+R
- Закрыть текущую страницу — CTRL +F4
- Распознать выделенные страницы документа ABBYY FineReader — CTRL +R
- Открыть Менеджер сценариев — CTRL +T
- Открыть диалог Опции «Файн Ридер»— CTRL +SHIFT+O
- Открыть справку — F1
- Перейти в окно Документ — ALT +1
- Перейти в окно Изображение — ALT +2
- Перейти в окно Текст — ALT +3
- Перейти в окно Крупный план — ALT +4
Источник: softdroid.net
Укрощение строптивого (на самом деле, нет) FineReader
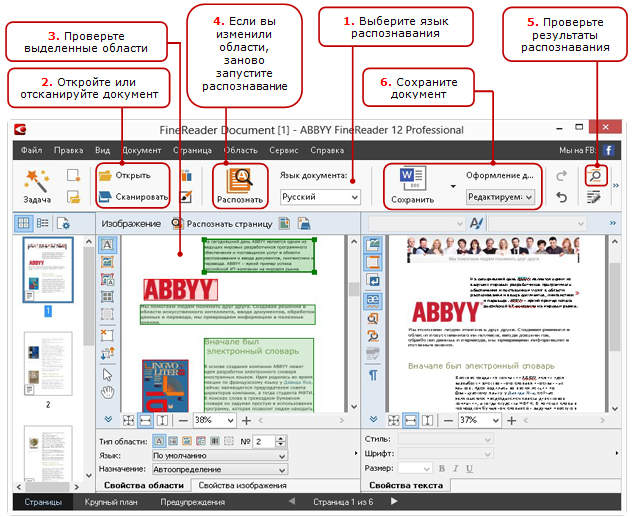
После короткого рассказа о том, как устроен ABBYY FineReader (aka «теоретическая часть»), самое время перейти к применению полученных знаний. И да, котиков под катом нет: всё очень серьёзно.
Как пользователю поучаствовать в обработке документа
Чтобы не изобретать велосипед, начну с простой и понятной схемы из Справки (см. рисунок справа).
Теперь, зная список всех операций, посмотрим на примерах – что может пойти не по плану и как с этим бороться.
Хорошо распознаются только хорошие изображения
А что делать, когда изображения есть, но не очень хорошие? Улучшить прямо в FineReader всё что можно, а, если улучшить нельзя, — попытаться получить изображение заново, устранив проблему. Поскольку тема очень обширная, то при должном интересе будет отдельный пост про то, как подружиться с автоматическими и ручными инструментами обработки изображений прямо в FineReader. Пока же ограничусь замечанием, что изображение будет обработано лучше, если оно:
- (после сканирования) не имеет выраженных геометрических искажений — перекоса или заметного изгиба страниц толстой книги у корешка двухстраничного разворота,
- (после фотографирования, в дополнение к предыдущему) не имеет ещё и нелинейных геометрических искажений («подушка», «трапеция»), имеет равномерную фокусировку (а желательно и яркость) по всей площади, не имеет шумов от недостаточной освещённости, не имеет выраженной засветки от вспышки (особенно на глянцевой бумаге).
Этап настройки документа/проекта
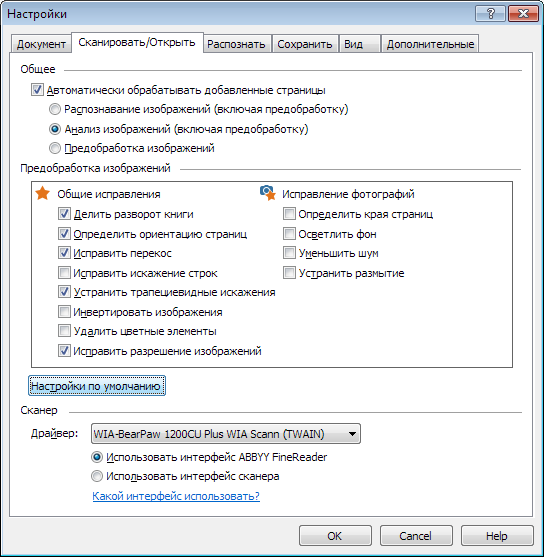
Можно и нужно сразу указать язык текста, параметры предобработки изображений, некоторые параметры анализа и распознавания. Вот скриншот одной из вкладок диалога настроек.
Эти и прочие настройки подробно описаны в Справке
Этап анализа
Программа автоматически выделяет области различных типов с точки зрения распознавания. На этом этапе мы можем как самостоятельно разметить области, так и поправить (при необходимости) те, что нашёл модуль Анализа.
Чтобы не писать много лишнего про инструменты работы с областями, сошлюсь на раздел Справки, а здесь объясню, что для чего, «что такое хорошо, что такое плохо» (применительно к областям) и как исправить плохой результат.
Назначение областей разных типов
В пользовательском интерфейсе FineReader доступны области нескольких типов, для них есть разные варианты скрываемой панели свойств (внизу окна «Изображение») и контекстного меню (по щелчку правой кнопкой мыши):
-
«Зона распознавания» (по умолчанию серая рамка) — такое название использовано в пользовательском интерфейсе, на мой взгляд правильнее было бы назвать «область для автоматического анализа». Назначение такой области – указать, где на странице вообще нужно искать что-то полезное. Поэтому в результате последующего анализа или анализа+распознавания в пределах каждой «зоны распознавания» может найтись ноль и более областей других типов. Особенно полезны зоны распознавания бывают в шаблонах блоков (подробнее о них в Справке).
Примеры правильно нарисованных зон распознавания
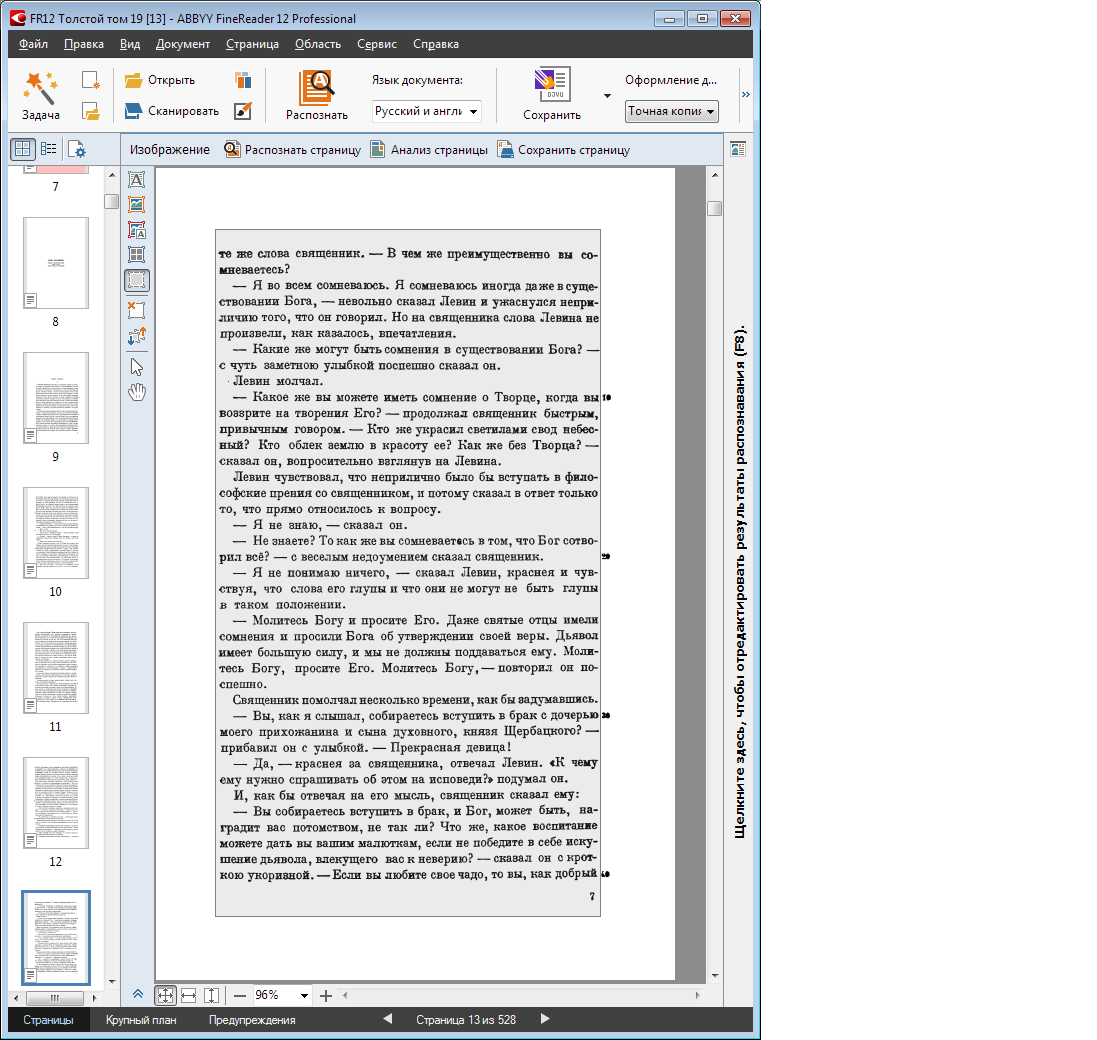
Реальный пример из проекта оцифровки Толстого — часть страниц имеет нумерацию строк (пронумерованы строки с номерами, кратными 10), не нужную в результате и затрудняющую вычитку/правку текста, если автоматический анализ включил эти номера в текстовую область колонки. Если страницы были почти одинаково выровнены на сканере или качественно обрезаны после сканирования, то перед анализом к нужной группе страниц можно применить шаблон блоков, где область (или области) распознавания просто не содержит не нужных нам частей страницы:
Помните, что в отличие от текстовой области область распознавания может превратиться в области разных типов, что бывало нужно и в этом проекте.
Эти параметры задаются на блок, так что выделять текст разного направления или разной инверсности в один блок – другая плохая идея.
Про направления основного текста страницы
В европейских языках в нормальной ориентации текста строки читаются сверху вниз (в блоке с повёрнутым текстом – от логического верха в сторону логического низа), но в случае иероглифических языков всё гораздо веселее – даже на одной странице одни области могут содержать текст в горизонтальной ориентации, а другие – в колоночной, причём иероглифы имеют одинаковую ориентацию во всех этих областях (если тема дальневосточных и ближневосточных языков интересна – просите отдельный пост про тамошние навороты).
Табличная область – содержит таблицу, как с видимыми разделителями строк и столбцов, так и невидимыми (частично или везде). Таблица может иметь только прямоугольную форму, каждая из ячеек тоже является прямоугольником, но используя объединение групп ячеек или групп строк, можно передавать весьма сложные конфигурации текста.
В каждой ячейке может быть распознаваемый текст (возможно, пустой) или картинка. Если вы хотите распознавать текст в ячейке, то можно задать ему особые параметры распознавания, а если нет, то стоит указать «картинка во всю ячейку». Кстати, можно выделить сразу прямоугольную группу ячеек таблицы и изменить нужное свойство у всех сразу.
Важные соображения
- Распознавание и синтез видят только те фрагменты текста, которые оказались выделены в текстовые области или текстовые ячейки таблиц. Если кусок текста не выделен в блоки – распознаваться он не будет.
- Аналогично и с картинками — если часть картинки оказалась вне области или одна целостная картинка оказалась разделена на несколько областей – скорее всего, в результате обработки будут проблемы.
- Языки распознавания в FineReader задаются не для галочки – они влияют на очень многие механизмы, начиная уже с анализа: например, иероглифический (китайский, японский, корейский языки) или арабский текст имеют много особенностей, которые учитываются не всегда, а только при выборе соответствующих языков распознавания.
Особенности взаимодействия близкорасположенных или пересекающихся областей
-
Пересечение текстовых и табличных блоков друг с другом, если есть символы или их части, оказавшиеся в более чем одном блоке – практически всегда ошибка, такие результаты анализа нужно исправлять, тем более что обычно это делается в несколько движений мыши.
Пересечение картиночных областей друг с другом – практически всегда ошибка, хотя и менее критичная для обработки именно текста. Такие случаи тоже желательно исправлять.


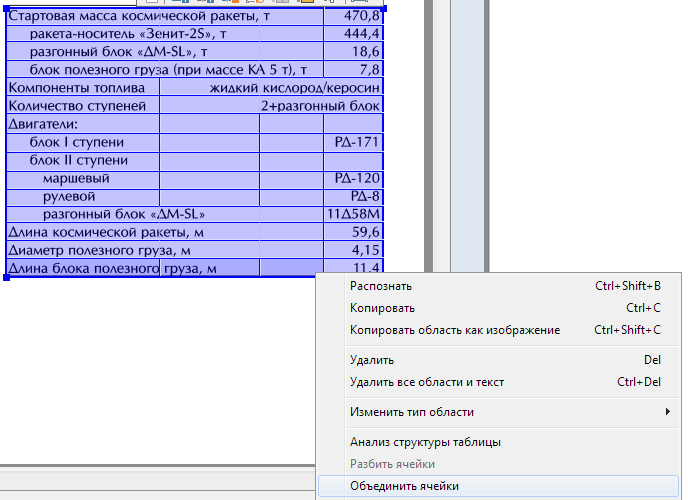
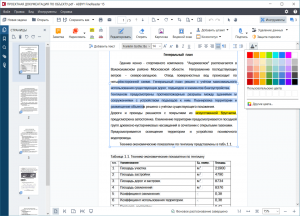
Примеры правильного использования картинок в таблице
Обратите внимание, что с помощью галочки в панели свойств области (внизу) ячейки из левой колонки таблицы сделаны картинками.
Текстовая область на фоне «картиночной» области — тоже важный инструмент: на фоне обычных картиночных областей могут находиться подписи к ним, на «фоновых» картиночных областях может располагаться и основной («колоночный») текст документа, а также таблицы.
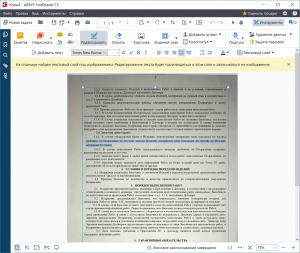
Примеры правильного использования текстовых областей на фоне картинок
Маленькие хитрости для облегчения работы с блоками
Описанные соглашения отражены в поведении редактора блоков. Например, если вы рисуете новый или растягиваете имеющийся блок так, что он полностью или почти полностью перекрывает другие блоки — эти другие блоки автоматически удаляются.
Логичность/нелогичность выделения областей
Тут самое время подумать — для каких целей и какого формата документ хочется получить в результате обработки. Вот некоторые соображения, влияющие на количество и характер исправлений разметки блоков в сложных случаях:
Вариант 1: нам нужен только текст (возможно, мы этого не понимаем, но дело обстоит именно так)
- нет «мусорных» областей, где в качестве текста или таблиц распознаются (мусором) элементы картинок или элементов оформления страницы.
- области логично выделяют строки, не допуская попадания символов в более чем одну область и неоправданного дробления строк на более чем одну область.
- то, что с точки зрения человека является таблицами в оригинале, должно быть выделено в табличные области. Это влияет как на качество распознавания (например, базовые линии строк в разных ячейках могут быть не выровнены по вертикали), так и на удобство поиска и копирования фрагментов текста в выходном документе.
Если отдельные картинки не должны копироваться из выходного PDF-документа – то такие области можно из документа исключить вовсе (не создавать новые и не оставлять найденные автоматикой, как минимум – удалять нелогично найденные картинки, а если не лень – то и все).
Я надеюсь шире и глубже раскрыть тему «разумности» картинок в статье про сохранение документов — если такая будет интересна читателям данного материала.
Вариант 2: нужно всё и сразу
Если документ, включающий не одно лишь текстовое содержимое (в одну или две колонки), предполагается сохранить сразу как электронную книгу в форматах FB2/e-pub или в любой промежуточный редактируемый формат (Вордовый или HTML) для дальнейшего редактирования и производства электронной книги, то осмысленное выделение таблиц и картинок становится особенно важно.
Среди прочего нужно определиться с тем, что делать с группами рядом расположенных картинок, и что делать с подписями к картинкам, как рядом стоящими, так и накладывающимися на картинки. Подробнее разберём эту тему в «Практикуме», на реальных примерах.
Что-то типа заключения данной части
- FineReader
- ocr
- распознавание текста
- Блог компании Content AI
- Обработка изображений
Источник: habr.com
Инструкция: как редактировать документы и распознавать тексты с иероглифами в ABBYY FineReader 15
PDF-документы давно стали необходимой составляющей офисной работы. В этом формате хранятся цифровые архивы, юристы согласуют договоры, дизайнеры верстают брошюры, издательства публикуют электронные книги. До недавнего времени главным достоинством и одновременно с этим недостатком PDF-документов было отсутствие возможности редактировать текст в них. Благодаря развитию технологий эту и другие задачи научилась решать программа ABBYY FineReader, которая стала многофункциональным редактором любых документов. «Хайтек» вместе с ABBYY рассказывает, как технологически устроено редактирование PDF-документов в новой версии FineReader 15, каким образом программа сравнивает версии документов и как работает распознавание иероглифов с помощью нейросетей.
Читайте «Хайтек» в
Диджитализация документооборота массово началась еще во второй половине ХХ века. Многие предприятия переходили на электронные документы. В офисах устанавливали первые компьютеры со специальным софтом для обработки и хранения важной информации. Тогда и появились популярные текстовые редакторы.
Сотрудники набирали вручную документы, а затем, с появлением в 1993 году PDF, стали экспортировать их в этот формат. На первый взгляд казалось: если весь документооборот станет электронным, то о шкафах с бумажными каталогами и завалах на рабочих столах можно будет забыть.
На практике оказалось, что чем больше организация использует компьютеры для цифрового документооборота, тем больше документов она печатает. 64% крупных компаний уверены, что по крайней мере до 2025 года печать будет значимой частью их бизнеса. С другой стороны, если сегодня в офис по традиционной почте приходит бумажный документ, его немедленно отсканируют и переведут в цифру.
Как правило, сканы документов хранят в виде PDF-файлов. Документом в формате PDF удобнее пользоваться — его можно послать по электронной почте с уверенностью, что информация дойдет до адресата без искажений (если, конечно, кто-то не решит внести изменения собственноручно), и, в отличие от DOC, его трудно изменить.
Это особенно важно, если речь идет о контрактах или коммерческих предложениях. Офисные сотрудники отмечают рост объемов использования PDF: каждый второй респондент ответил, что регулярно работает с документами в этом формате и нуждается в специализированной программе.
За последние два года количество таких рабочих файлов в мире выросло в три раза — эти данные приводят эксперты IDC в исследовании «Addressing the document disconnect». В России PDF также пользуется популярностью. Также по результатам исследования ABBYY выяснилось, что в наиболее частые сценарии работы с PDF-документами вошли совершенно не типичные для этого формата ранее задачи: 52% респондентов вносят мелкие правки в текст PDF, исправляют ошибки или опечатки; 62% опрошенных часто ищут информацию в тексте PDF и 60% копируют текст из документа. Поэтому от программ, работающих с PDF, требуются новые возможности для редактирования, сравнения и распознавания текстов. Все они есть в новом FineReader 15.
Почему так сложно редактировать текст в PDF?
Изначально PDF не предназначался для того, что его каким-либо образом изменяли. Что было и его преимуществом — это безопасность, одинаковое отображение на любом устройстве и удобный способ обмена информацией, и недостатком — невозможность внесения правок, поиска по тексту и сравнения документов.
Особенности отображения текста в PDF
Несмотря на то, что PDF — это формат текста, в цифровом виде эти буквы, слова и предложения на самом деле не существуют, они «нарисованы». Содержимое хранится в виде потоков — это могут быть текст, изображения и векторная графика. Типичных для формата DOC слов, строчек, абзацев и таблиц в PDF нет. В формате нет и букв как таковых, а есть коды символов.
Такие коды с одинаковыми характеристиками объединяются в группы по виду и размеру шрифта. Этот шрифт определяет, как символ должен отображаться в документе, сопоставляя код символа и глиф — набор команд для отрисовки. Еще одно отличие от обычного текстового документа — объекты в PDF существуют в трех измерениях.
По координате Z судят о глубине расположения объекта на странице, ведь текст может находиться поверх изображения или наоборот. Текст в PDF-документе напоминает «мешочек букв», который нужно правильно отобразить в конкретных местах документа с соответствующим форматированием.
С 2008 года PDF стал открытым форматом, что позволило разработчикам без проблем и дополнительных отчислений создавать программы для чтения файлов PDF, конвертеры и другие полезные вещи. Развитие OCR привело к тому, что у ранее неизменного PDF-документа появилась возможность редактирования — сначала построчного, а затем и в пределах абзацев.
Если речь идет о digital-born-документе (изначально созданный на компьютере, а не отсканированный бумажный документ — «Хайтек»), то в режиме редактирования подключаются фоновые процессы, и программа приступает к анализу структуры документа. Для этого используется технология, которая строит блоки на основе данных, записанных в PDF, а не на основе распознавания.
За считанные доли секунды технология должна пройти всю цепочку по определению параметров текста: места, где находятся заголовки, подзаголовки, отдельные абзацы и другие элементы. Потом — распихать «мешочки букв» по этим блокам, сформировать строки. Следующий этап — синтез. Специальные технологии определяют внешние параметры текста — отступы и межстрочные интервалы.
Благодаря этому из хаотичной структуры снова появляется текстовый документ с форматированием. И уже в него можно вносить правки — менять слова и целые абзацы, исправлять форматирование, сохранять изменения и так далее.
Функция построчного редактирования уже была в предыдущей версии FineReader (ABBYY FineReader 14 вышла в январе 2017 года — «Хайтек»). Этого было достаточно, чтобы внести небольшие исправления в текст: заменить несколько букв или цифр. Новый ABBYY FineReader 15 стал универсальным текстовым редактором, в котором вносить изменения можно в целые абзацы.
Как отредактировать текст в отсканированном документе
Отдельная офисная задача — отредактировать скан-копию бумажного документа. Раньше для этого пользователю приходилось конвертировать файл в редактируемый формат или просто искать исходник. Когда пользователь редактирует скан, ABBYY FineReader 15 в первую очередь распознает документ и создает временный текстовый слой на тех страницах, которые пользователь просматривает. В режиме редактирования создается текстовое представление страницы — именно его редактирует пользователь. Затем эти правки встраиваются в изображение страницы в отсканированном документе.
Как найти в PDF внесенные правки и избежать обмана
Сравнение документов — особо важный для бизнеса сегмент офисных задач. Прежде всего, потому что неожиданные правки могут стоить очень больших денег. Иногда их незаметно пытаются внести в уже подписанный договор и воспользоваться человеческой невнимательностью — такие документы обычно сравнивают юристы, внимательно вычитывая распечатки оригинала, созданного в Word, и ответа контрагента — отсканированный вариант. Поиск отличий в текстовых документах может быть полезен еще и в том случае, если над ними работают одновременно несколько человек или со временем один и тот же файл периодически изменяют. Это позволяет быстро найти последние правки, которые внесли в файл коллеги. В файлах DOCX для этого есть режим Track Changes, создающий на основе двух версий документа третью — с подсвеченными отличиями в тексте. В новом ABBYY FineReader 15 можно сохранить результаты сравнения любых документов в таком DOCX c Track Changes и в привычном режиме увидеть все различия.  Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов. Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.
Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов. Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.  В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу. В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word. Среди поддерживаемых ABBYY FineReader 15 функций:
В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу. В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word. Среди поддерживаемых ABBYY FineReader 15 функций:
- просмотр PDF-документов;
- редактирование текста в PDF-документе в пределах абзаца;
- удаление конфиденциальных данных;
- сравнение документов разного формата и написанных на разных языках;
- автоматизация задач по оцифровке и конвертации;
- распознавание и конвертирование документов;
- комментирование и согласование;
- защита и цифровая подпись.
Как работают нейросети для распознавания иероглифов и арабской вязи
Распознавание иероглифов осложняется тем, что в отличие от европейских языков, они состоят из большого количества черточек, палочек, наклонов. Но размер иероглифов вполне сопоставим с размером европейских букв. В низком разрешении сканов иероглифы могут и вовсе выглядеть как кляксы. Носитель языка поймет символ, исходя из контекста.
Программа же работает поэтапно: сначала анализирует изображение всего документа, определяет абзацы, разбивает распознанные строки на слова, а слова — на отдельные символы. На этом этапе алгоритмы опираются не на контекст, как человек, а на внешний вид иероглифа, и здесь многое зависит от качества изображения. Для распознавания японского, китайского и корейского языков компания ABBYY внедрила нейросети. Они решают две главные задачи при работе с иероглифами — улучшение качества распознавания и «модернизацию» языков.
Качество и скорость в быстром и нормальном режиме
Внедрение нейросетей значительно повысило качество распознавания японского и китайского в быстром режиме, но скорость работы на начальном этапе разработки снизилась. Для клиентов, работающих с большим потоком документов, даже небольшая просадка по скорости может привести к сильному замедлению в обработке данных. Оказалось, что скорость проседает в документах с большим количеством символов с простой структурой — таких, как японская буквенная азбука (в современном японском языке используется три основных системы письма: кандзи — иероглифы китайского происхождения и две слоговые азбуки, созданные в Японии — хирагана и катакана — «Хайтек»).

Эту проблему решили с помощью кэша. Когда программа распознает страницу, одна и та же буква может попадаться на ней несколько раз. Встретив букву «А», написанную одним и тем же шрифтом, ABBYY FineReader анализирует и запоминает ее особенности. Этот принцип оптимизации позволяет не тратить время на распознавание одинаковых символов.
Для японского и китайского ранее не использовался кэш, потому что встретить один и тот же иероглиф на странице, написанной естественным языком, можно очень редко. Но для символов с простой структурой это оказалось полезным. Включение кэша позволило ускорить и нормальный, и быстрый режим распознавания.
Почему важно следить за развитием языка
В предыдущих версиях FineReader в японском языке присутствовали иероглифы, которые уже не используются в современных документах. Это заметили сотрудники японского офиса ABBYY: время от времени программа вставляла при распознавании один-два устаревших символа. Для рядового носителя языка это воспринимается как буквы из русского дореволюционного алфавита для нас.
Чтобы исправить эту ошибку, потребовалось создать в программе «новый язык» — Japanese Modern. Легко заставить программу не отображать те или иные устаревшие символы. Но необходимо было не просто выбросить ненужное, но и оставить всё необходимое, найти множество иероглифов, которые отображают всё богатство современного японского языка.
Новое множество символов формировалось в несколько этапов. Для тестирования создавали подходящие наборы изображений документов. Если в пакет попадала хотя бы одна страница с устаревшими формами, весь комплект оказывался непригодным. Приходилось вынимать эту страничку и формировать новый комплект материалов. Наконец удалось добиться того, чтобы в результатах распознавания почти не было устаревших символов и при этом правильно отображались все современные иероглифы.
Для китайского в FineReader всегда поддерживали традиционный и упрощенный языки. При этом по составу символов они не отличались. Получить разный результат распознавания всё равно было возможно, потому что в программе было заложено разное распределение вероятностей.
В новой версии в результате экспериментов удалось выделить символы, необходимые для распознавания упрощенного китайского. В FineReader заложена возможность создавать пользовательский язык. Используя этот инструмент и внося изменения в состав, специалисты сравнивали результаты распознавания на разных образцах документов, и в результате в упрощенном китайском остался только необходимый набор иероглифов.
Корейская письменность, хангыль — нечто среднее между китайским и европейским письмом. Внешне это квадратные символы, напоминающие иероглифы, и на одной странице текста можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков.
Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать диграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Каждый блок может состоять из двух, трех или четырех букв. Первой всегда идет согласная, затем одна или две гласных, и в конце может стоять еще одна согласная.
Для корейского обучили отдельную нейросеть, которая, помимо корейских слогов, распознает и некоторые иероглифы. Вместо распознавания символов целиком технология определяет отдельные буквы в них.
Как резать арабскую вязь на фрагменты
Арабский язык отличается от других тем, что найти линии порезки между символами в арабской вязи очень сложно. Даже гистограмма при распознавании арабского отличается: выглядит как бесконечный набор горбиков и ямочек.
Варианты разделения текста на символы создаются всегда, даже для европейских языков. В процессе работы программа выбирает наиболее вероятный путь распознавания. В случае с арабским языком таких вариантов очень много, и это приводило к ошибкам. Поэтому для повышения точности программу научили видеть не отдельную букву, а всё слово целиком.
Для этого была разработана сеть end-to-end (e2e). Она полезна не только для арабского, но и для европейских языков — например, в дизайнерских шрифтах, когда на изображениях сложно построить путь для распознавания.
При e2e-подходе на вход в нейросеть поступает набор изображений — фрагментов, состоящих из отдельных слов. На выходе такая нейросеть выдает последовательность графем, которые затем проходят дополнительную обработку: проводится словарный анализ, корректируются пробелы.
Для обучения использовался набор из нескольких сотен тысяч фрагментов — отдельные слова из отсканированных газет, журналов, официальных документов. Они были выбраны в несколько итераций: сначала собирали базу из слов, которые удачно распознали, и обучали нейросеть на этом датасете. Потом еще раз обучали, корректировали, выявляли ошибки. Часть, которую не смогли распознать, отдельно отдавали на доразметку и корректировку фрагментов. В результате всё больше очищали датасет для обучения, улучшая общее качество распознавания.
Кроме того, часть данных для обучения была создана искусственно. Это было необходимо для распознавания шрифтов, для которых было собрано мало образцов. В таких случаях использовался корпус текста, в который добавлялись различные искажения, типичные для этапа сканирования документа: шум, размытие символа. Это делала в автоматическом режиме специальная программа — генератор синтетики, или «портилка».
Сначала в ходе обучения такой подход привел к тому, что потерялась информация об охватывающих прямоугольниках символов, которые необходимо отображать для пользователя на этапе верификации. Отказавшись от посимвольного распознавания, пришлось внедрить альтернативный механизм, который дополнял результаты распознавания информацией об охватывающих прямоугольниках и резал слова на отдельные символы.
Сочетание новых алгоритмов машинного обучения сделало возможным создание многофункционального текстового редактора для работы с PDF, сканами и digital-born-документами. Внесение правок, сравнение файлов и распознавание сложных языков дает пользователю возможность полноценно работать с файлами вне зависимости от их формата. По сути, это позволяет охватить все спектры офисных задач по работе с электронными и даже бумажными документами, максимально упрощая работу сотрудникам и снижая вероятность ошибок из-за человеческого фактора.
Источник: hightech.fm