

Вашему вниманию предлагается проект, целью которого является знакомство и изучение замечательного мира Героев Меча и Магии. На сайте представлены справочники по всем частям Heroes и King’s Bounty! Возможно, именно здесь Вы найдете информацию, которую так долго искали. Мы всегда рады новым игрокам, ценителям и любителям классических игр!
 Программа Count v.4.8 для Героев IV
Программа Count v.4.8 для Героев IV
Сегодня раздел Программы и утилиты пополнился многофункциональной программой для Героев Меча и Магии IV под названием Count v.4.8.
Программа имеет целый спектр возможностей от рассчета очков на карте, до незаменимого сканера сейва, позволяющего определять наличие и месторасположение артефактов и прочих полезностей в игровых сейвах Heroes4. Результат выдаётся в виде txt-файлов.
Функция COUNT — СЧЁТ в Excel / David Kunela Academy
Скачать программу можно по этой прямой ссылке.
Выражаю благодарность bobchik’у за присланный материал!

Рубрика: Новости
Один комментарий: Программа Count v.4.8 для Героев IV
dnaop-wr говорит:
Попробовал программу Count v.4.8. Она конечно не такая, как Проспектор для тройки, тем не менее очень полезная.
Расчет очков за игру — это может быть на любителя, тем не менее сразу можно вычислить, к чему нужно стремиться. Единственно нижняя графа — бои — компьютер ее как-то игнорирует, хотя она и заложена в игре.
Чит-коды — я об этом ранее писал. У меня в игре стоит меню чит-кодов, которым я ни разу не воспользовался. Так что это на любителя. И для анализа карты на проходимость картостроителям и офлайнщикам.
Местность подбирать не пробовал, хотя надо бы поюзать.
А вот сканер стартового сейва с проверкой нужных артефактов, заклинаний и навыков на карте — очень полезная вещь, позволяет быстро переиграть сложный сценарий при неподходящем раскладе и выбрать более подходящий.
Так что также выражаю свою благодарность bobchik’у за эту утилиту.
Источник: handbookhmm.ru
5 незаменимых функций Pandas для Data Science
Перевод статьи «5 Must-Know Pandas Functions for Data Science».
Каждый проект из области data science начинается с анализа данных. Когда мы говорим об анализе данных, невозможно не упомянуть pandas – библиотеку Python, также известную как Panel Data Analysis.
В этой статье я поделюсь с вами важными функциями pandas, которые помогают осуществлять различные операции над датасетами.
Я буду работать с датасетом от Kaggle для предсказания цен на недвижимость. Скачать его можно здесь.
Функция COUNT (SQL для Начинающих)
Сперва изучим наши данные.
import pandas as pd df = pd.read_csv(«House data.csv»)
Вид датасета следующий.
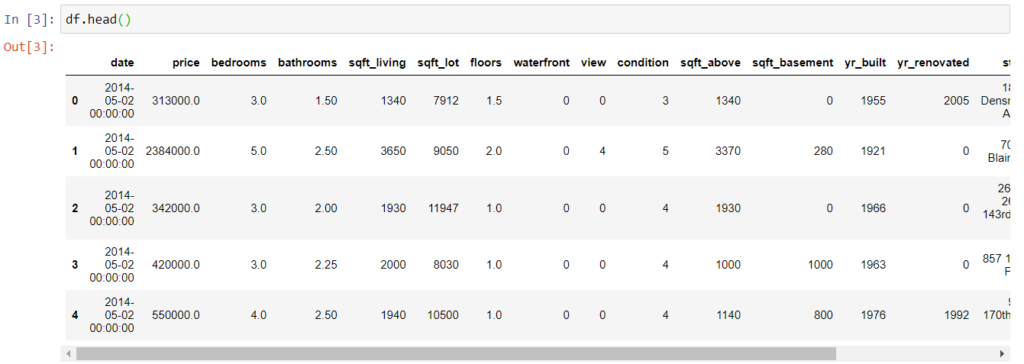
Так как это данные для предсказания цен на недвижимость, здесь учитывается количество комнат, ванные, этажность и другие факторы, способные повлиять на цену дома с различными особенностями.
Применим к этим данным некоторые функции pandas.
1. count()
Скажем, вам нужно быстро проверить, есть ли в таблице значения NaN. В этом случае мы можем воспользоваться функцией count() , которая посчитает количество ячеек, содержащих какое-либо число.
df.count()
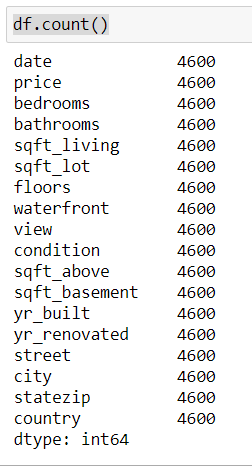
Отличные новости: в нашем датасете нет NaN. Поэтому поместим значение NaN в одну ячейку и посмотрим, что изменится.
df.at[0,’price’]= np.nan
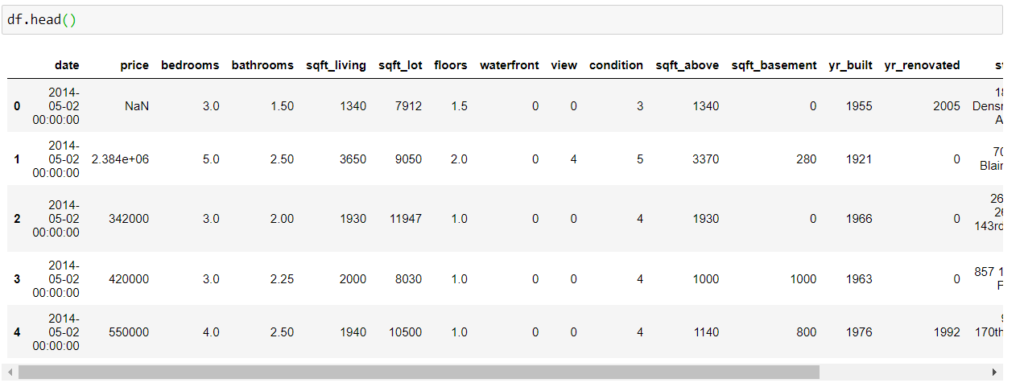
Теперь, если я вызову count() , получу следующий результат:
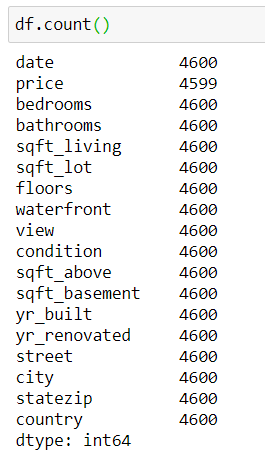
[machinelearning_ad_block]
2. idxmin() и idxmax()
Эти функции возвращают индекс строки, удовлетворяющей определённому условию.
Скажем, нам нужно посмотреть подробную информацию о доме с наименьшей ценой. Существует множество способов сделать это с помощью других методов. Но функции idxmin() и idxmax() наиболее эффективны.
df.loc[df[‘price’].idxmin()]
Запустив этот код, я получу данные о жилье с минимальной ценой:
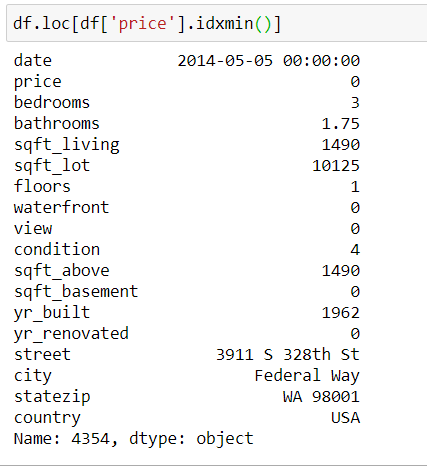
Это будет трёхкомнатная квартира в Федерал-Уэй с ценой 0.
Очевидно, что в данных ошибка, ведь мы тренируемся на open-source датасете. Но, думаю, суть вы уловили:) То же самое можно проделать с idxmax() , чтобы найти дом с наибольшей ценой.
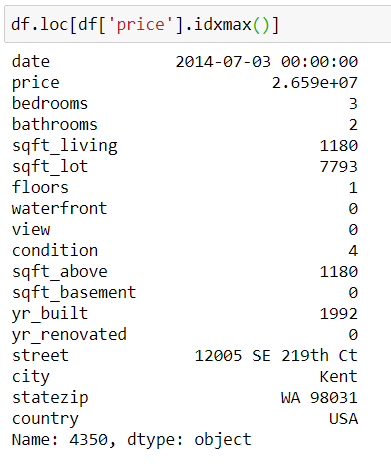
Но что, если домов с минимальной/максимальной ценой окажется несколько? В этом случае функции возвращают первое вхождение. Далее в статье мы разберём и такой случай.
3. cut()
Допустим, у нас есть непрерывная переменная. Но, например, в рамках вашей задачи эту переменную необходимо рассматривать как категориальную.
Функция cut() поможет вам привести непрерывную переменную к виду дискретной, разбив весь диапазон значений на интервалы.
В нашем случае я хочу создать набор ценовых данных, поскольку значение цены колеблется от 0 до 26590000. Если я сгруппирую данные, с ними будет проще работать.
pd.cut(df[«price»], 4)
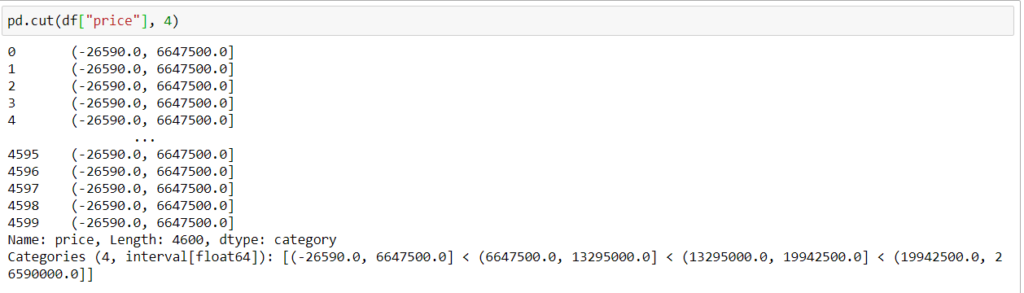
Каждому интервалу можно также дать название.
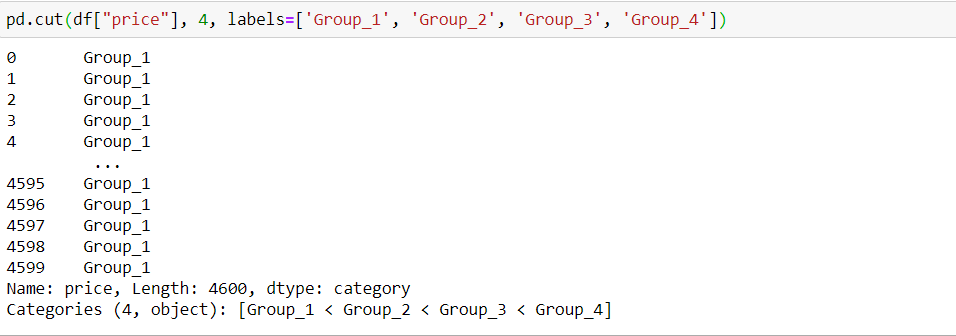
Неплохо! Можно заменить соответствующую колонку ценой в новом формате или же добавить новый столбец.
4. pivot_table()
Если вы работали в excel, вы точно использовали эту функцию.
Допустим, нам нужно найти среднюю цену дома в каждом городе, основываясь на количестве комнат.
df.pivot_table(index=»city» , columns=»bedrooms» ,values=»price» , aggfunc=»mean»)
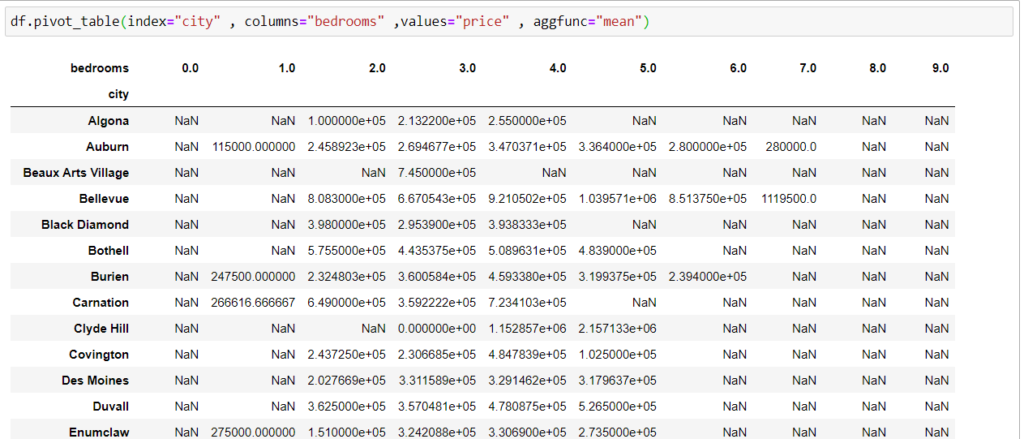
Здесь вы можете заметить NaN, так как не в каждом городе есть двухкомнатные квартиры – также особенность нашего датасета.