
При создании приложений мы часто сталкиваемся с ошибками, которые необходимо отлаживать. Итак, с помощью логов мы можем легко получить информацию о том, что происходит в приложении, с записью ошибок и необычных обстоятельств. Теперь вам может показаться, что почему бы не использовать оператор System.out.print() в Java.
Проблема с этими утверждениями состоит в том, что сообщения журнала будут печататься только на консоли. Поэтому, как только вы закроете консоль автоматически, все журналы будут потеряны. Они не хранятся постоянно и будут отображаться один за другим, так как это однопоточная среда.
Чтобы избежать таких проблем, логирование в Java упрощается с помощью API, предоставляемого через пакет java.util.logging пакет org.apache.log4j.* .
Компоненты
Компоненты ведения журнала помогают разработчику создавать их, передавать в соответствующее место назначения и поддерживать надлежащий формат. Ниже приведены три компонента:
- Loggers – отвечает за сбор записей журнала и передачу их соответствующему заявителю.
- Appenders или Handlers – они отвечают за запись событий журнала в пункт назначения. Аппендеры форматируют события с помощью макетов перед отправкой результатов.
- Layouts или Formatters – отвечает за определение того, как данные выглядят, когда они появляются в записи журнала.
Вы можете обратиться к изображению ниже для работы всех трех компонентов:
Что такое лог-файл и зачем он нужен: простыми словами

Когда приложение выполняет вызов регистрации, компонент Logger записывает событие в LogRecord и перенаправляет его соответствующему Appender. Затем он форматировал запись, используя формат в соответствии с требуемым форматом. Помимо этого, вы также можете использовать более одного фильтра, чтобы указать, какие Appenders следует использовать для событий.
Что такое Логгеры (Logger) в Java?
Логгеры (Logger) в Java – это объекты, которые запускают события журнала. Они создаются и вызываются в коде приложения, где генерируют события журнала перед передачей их следующему компоненту, который является Appender.
Вы можете использовать несколько логгеров в одном классе для ответа на различные события или использовать в иерархии. Они обычно называются с использованием иерархического пространства имен, разделенных точками. Кроме того, все имена Logger должны основываться на классе или имени пакета зарегистрированного компонента.
Кроме того, каждый логгер отслеживает ближайшего существующего предка в пространстве имен, а также имеет связанный с ним «уровень».
Как создать?
Вы должны использовать Logger.getLogger() . Метод getLogger() идентифицирует имя Logger и принимает строку в качестве параметра. Таким образом, если Logger уже существует, он возвращается, в противном случае создается новый.
Синтаксис
static Logger logger = Logger.getLogger(SampleClass.class.getName());
Здесь SampleClass – это имя класса, для которого мы получаем объект Logger.
Профессиональная отладка программ | Ведение логов | Сообщения об ошибках в программе | debug
public class Customer < private static final Logger LOGGER = Logger.getLogger(Customer.class); public void getCustomerDetails() < >>
Уровни
Уровни журналов используются для классификации их по степени серьезности или влиянию на стабильность приложения. Пакет org.apache.log4j.* и java.util.logging предоставляют разные уровни ведения журнала.
Пакет org.apache.log4j.* предоставляет следующие уровни в порядке убывания:
Пакет java.util.logging предоставляет следующие уровни в порядке убывания:
- SEVERE(HIGHEST LEVEL);
- WARNING;
- INFO;
- CONFIG;
- FINE;
- FINER;
- FINEST(LOWEST LEVEL).
Помимо этого, вышеприведенный пакет также предоставляет два дополнительных уровня ALL и OFF используются для регистрации всех сообщений и отключения регистрации соответственно.
Пример с использованием пакета org.apache.log4j.*
import org.apache.log4j.Logger; public class Customer < static Logger logger = Logger.getLogger(Customer.class); public static void main(String[] args) < logger.error(«ERROR»); logger.warn(«WARNING»); logger.fatal(«FATAL»); logger.debug(«DEBUG»); logger.info(«INFO»); System.out.println(«Final Output»); >>
Таким образом, если в нашем файле log4j.properties ваш вывод является корневым логгером уровня WARN, то все сообщения об ошибках с более высоким приоритетом, чем WARN, будут напечатаны, как показано ниже:
Вы также можете установить уровень с помощью метода setLevel() из пакета java.util.logging , как java.util.logging ниже:
logger.setLevel(Level.WARNING);
Пример с использованием пакета java.util.logging
package edureka; import java.io.IOException; import java.util.logging.Level; import java.util.logging.Logger; import java.util.logging.*; class EdurekaLogger < private final static Logger LOGGER = Logger.getLogger(Logger.GLOBAL_LOGGER_NAME); public void sampleLog() < LOGGER.log(Level.WARNING, «Welcome to Edureka!»); >> public class Customer < public static void main(String[] args) < EdurekaLogger obj = new EdurekaLogger(); obj.sampleLog(); LogManager slg = LogManager.getLogManager(); Logger log = slg.getLogger(Logger.GLOBAL_LOGGER_NAME); log.log(Level.WARNING, «Hi! Welcome from Edureka»); >>
Чтобы включить вход в приложение с помощью пакета org.apache.log4j.* Или пакета java.util.logging , необходимо настроить файл свойств. Далее в этой статье о Logger в Java давайте обсудим файл свойств обоих из них.
Файл свойств пакета Log4j и Java Util
Пример файла свойств Log4j
# Enable Root logger option log4j.rootLogger=INFO, file, stdout # Attach appenders to print file log4j.appender.file=org.apache.log4j.RollingFileAppender log4j.appender.file.File=E:loglogging.log log4j.appender.file.MaxFileSize=10MB log4j.appender.file.MaxBackupIndex=5 log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern=%d %-5p %c:%L — %m%n # Attach appenders to print on console log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %-5p %c:%L — %m%n
- Файл свойств Log4j создается внутри папки src проекта.
- log4j.appender.file = org.apache.log4j.RollingFileAppender -> Печатает все журналы в файле
- log4j.appender.stdout = org.apache.log4j.ConsoleAppender -> Печатает все журналы в консоли
- log4j.appender.file.File = D: loglogging.log -> Указывает расположение файла журнала
- log4j.appender.file.MaxFileSize = 10 МБ -> Максимальный размер файла журнала до 10 МБ
- log4j.appender.file.MaxBackupIndex = 5 -> Ограничивает количество файлов резервных копий до 5
- log4j.appender.file.layout = org.apache.log4j.PatternLayout -> Указывает шаблон, в котором журналы будут печататься в файл журнала.
- log4j.appender.file.layout.ConversionPattern =% d % -5p% c :% L -% m% n -> Устанавливает шаблон преобразования по умолчанию.
Пример файла свойств пакета Java Util
handlers= java.util.logging.ConsoleHandler .level= WARNING # Output will be stored in the default directory java.util.logging.FileHandler.pattern = %h/java%u.log java.util.logging.FileHandler.limit = 60000 java.util.logging.FileHandler.count = 1 java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter # Level of logs will be limited to WARNING and above. java.util.logging.ConsoleHandler.level = WARNING java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
- java.util.logging.FileHandler.pattern =% h / java% u.log -> Файлы журнала будут записаны в C: TEMPjava1.log
- java.util.logging.FileHandler.limit = 50000 -> Максимальная сумма, которую регистратор записывает в один файл в байтах.
- java.util.logging.FileHandler.count = 1 -> Указывает количество выходных файлов
- java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter -> Упоминает форматер, используемый для форматирования. Здесь используется XML Formatter.
- java.util.logging.ConsoleHandler.level = WARNING -> Устанавливает уровень журнала по умолчанию для WARNING
- java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter -> Указывает форматер, используемый всеми ConsoleHandler. Здесь используется SimpleFormatter.
Регистрация событий
Чтобы регистрировать события в Java, вы должны убедиться, что вы назначаете уровень, чтобы легко отфильтровать события. Чтобы назначить уровень и упомянуть сообщение, вы можете использовать следующие методы:
Способ 1
logger.log(Level.INFO, “Display message”);
Here, level is INFO and the message to be printed is «Display Message».
Способ 2
logger.info(“Display message”);
Чтобы убедиться, что Logger регистрирует только события, которые находятся на уровне или выше уровня INFO, вы можете использовать метод setLevel(), описанный выше.
Appender или Handlers
Appender или Handlers отвечают за запись событий журнала в пункт назначения. Каждый регистратор имеет доступ к нескольким обработчикам и получает сообщение журнала от регистратора. Затем Appenders используют средства форматирования или макеты для форматирования событий и отправки их в соответствующее место назначения.
Appender можно отключить с помощью метода setLevel (Level.OFF). Два наиболее стандартных обработчика в пакете java.util.logging :
- FileHandler: записать сообщение журнала в файл.
- ConsoleHandler: записывает сообщение журнала в консоль.
Layout или Formatters
Используются для форматирования и преобразования данных в журнале событий. Каркасы журналов предоставляют макеты для HTML, XML, Syslog, JSON, простого текста и других журналов.
Источник: java-blog.ru
Зачем нужно логирование

Привет! При написании лекций я особо отмечаю, если какая-то конкретная тема обязательно будет использоваться в реальной работе.  Так вот, ВНИМАНИЕ! Тема, которой мы коснемся сегодня, точно пригодится тебе на всех твоих проектах с первого дня работы. Мы поговорим о логировании.
Так вот, ВНИМАНИЕ! Тема, которой мы коснемся сегодня, точно пригодится тебе на всех твоих проектах с первого дня работы. Мы поговорим о логировании.
Тема эта совсем не сложная (я бы даже сказал легкая). Но на первой работе и без того будет достаточно стресса, чтобы еще разбираться с очевидными вещами, поэтому лучше досконально разобрать ее сейчас 🙂 Итак, начнем. Что такое логирование? Логирование — это запись куда-то данных о работе программы. Место, куда эти данные записываются называется «лог».
Возникает сразу два вопроса — куда и какие данные записываются? Начнем с «куда». Записывать данные о работе программы можно во множество разных мест. Например, ты во время учебы часто выводил данные в консоль с помощью System.out.println() . Это настоящее логирование, хоть и самое простое.
Конечно, для клиента или команды поддержки продукта это не очень удобно: они явно не захотят устанавливать IDE и мониторить консоль 🙂 Есть и более привычный человеку формат записи информации — в текстовый файл. Людям гораздо удобнее читать их в таком виде, и уж точно гораздо удобнее хранить! Теперь второй вопрос: какие данные о работе программы должны записываться в лог?
А вот здесь все зависит от тебя! Система логирования в Java очень гибкая. Ты можешь настроить ее таким образом, что в лог попадет весь ход работы твоей программы. Это, с одной стороны, хорошо. Но с другой — представь себе, каких размеров могут достичь логи Facebook или Twitter, если туда писать вообще все.
У таких крупных компаний наверняка есть возможность хранить даже такое количество информации. Но вообрази, как сложно будет искать информацию об одной критической ошибке в логах на 500 гигабайт текста? Это даже хуже, чем иголка в стоге сена. Поэтому логирование в Java можно настроить так, чтобы в журнал (лог) записывались только данные об ошибках.
Или даже только о критических ошибках! Хотя, говорить «логирование в Java» не совсем верно. Дело в том, что потребность ведения логов возникла у программистов раньше, чем этот функционал был добавлен в язык. И к тому времени, как в Java появился собственная библиотека для логирования, все уже пользовались библиотекой log4j.
История появления логирования в Java на самом деле очень долгая и познавательная, на досуге можешь почитать этот пост на Хабре. Короче говоря, своя библиотека логирования в Java есть, но ей почти никто не пользуется 🙂 Позже, когда появились несколько разных библиотек логирования, и все программисты начали пользоваться разными, возникла проблема совместимости.
Чтобы люди не делали одно и то же с помощью десятка разных библиотек с разными интерфейсами, был создан абстрагирующий фреймворк slf4j («Service Logging Facade For Java»). Абстрагирующим он называется потому, что хотя ты и пользуешься классами slf4j и вызываешь их методы, под капотом у них работают все предыдущие фреймворки логирования: log4j, стандартный java.util.logging и другие.
Если тебе в данный момент нужна какая-то специфическая фича log4j, которой нет у других библиотек, но ты не хотел бы при этом жестко привязывать проект именно к этой библиотеке, просто используй slf4j. А о она уже «дернет» методы log4j. Если ты передумаешь и решишь, что фичи log4j тебе больше не нужны, тебе надо только перенастроить «обертку» (то есть slf4j) на использование другой библиотеки.
Твой код не перестанет работать, ведь в нем ты вызываешь методы slf4j, а не конкретной библиотеки. Небольшое отступление. Чтобы следующие примеры заработали, тебе нужно скачать библиотеку slf4j отсюда, и библиотеку log4j отсюда. Далее архив нужно распаковать,и добавить нужные нам jar-файлы в classpath через Intellij IDEA. Пункты меню: File -> Project Structure -> Libraries Выбираешь нужные jar-ники и добавляешь в проект (в архивах, которые мы скачали, лежит много jar’ников, посмотри нужные на картинках) 
 Примечание — эта инструкция для тех студентов, которые не умеют использовать Maven. Если ты умеешь им пользоваться, лучше попробуй начать с него: это обычно намного проще Если используешь Maven, добавь такую зависимость:
Примечание — эта инструкция для тех студентов, которые не умеют использовать Maven. Если ты умеешь им пользоваться, лучше попробуй начать с него: это обычно намного проще Если используешь Maven, добавь такую зависимость:
org.apache.logging.log4j log4j-slf4j-impl 2.14.0
Отлично, с настройками разобрались 🙂 Давай рассмотрим, как работает slf4j. Как же нам сделать так, чтобы ход работы программы куда-то записывался? Для этого нам нужны две вещи — логгер и аппендер. Начнем с первого.
Логгер — это объект, который полностью управляет ведением записей. Создать логгер очень легко: это делается с помощью статического метода — LoggerFactory.getLogger() . В качестве параметра в метод нужно передать класс, работа которого будет логироваться. Запустим наш код:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyTestClass < public static final Logger LOGGER = LoggerFactory.getLogger(MyTestClass.class); public static void main(String[] args) < LOGGER.info(«Test log record. «); LOGGER.error(«В программе возникла ошибка!»); >>
Вывод в консоль: ERROR StatusLogger No Log4j 2 configuration file found. Using default configuration (logging only errors to the console), or user programmatically provided configurations. Set system property ‘log4j2.debug’ to show Log4j 2 internal initialization logging.
See https://logging.apache.org/log4j/2.x/manual/configuration.html for instructions on how to configure Log4j 2 15:49:08.907 [main] ERROR MyTestClass — В программе возникла ошибка! Что же мы тут видим? Сначала мы видим сообщение об ошибке. Она появилась, потому что сейчас у нас не хватает необходимых настроек. Поэтому наш логгер сейчас умеет выводить только сообщения об ошибках (ERROR) и только в консоль. Метод logger.info() выполнен не был.
А вот logger.error() сработал! В консоли появилась текущая дата, метод, где возникла ошибка ( main ), слово ERROR и наше сообщение! ERROR — это уровень логгрования. В общем, если запись в логе помечена словом ERROR, значит, в этом месте программы произошла ошибка. Если запись помечена словом INFO — значит это просто текущая информация о нормальной работе программы.
В библиотеке SLF4J довольно много разных уровней логгирования, которые позволяют гибко настроить ведение журнала. Управлять ими очень легко: вся необходимая логика уже заложена в класс Logger . Тебе достаточно просто вызывать нужные методы.
Если ты хочешь залогировать обычное сообщение, вызывай метод logger.info() . Сообщение об ошибке — logger.error() . Вывести предупреждение — logger.warn() Теперь поговорим об аппендере. Аппендер — это место, куда приходят твои данные. Можно сказать, противоположность источнику данных — «точка B». По умолчанию данные выводятся в консоль.
Обрати внимание, в предыдущем примере нам не пришлось ничего настраивать: текст появился в консоли сам, но при этом логгер из библиотеки log4j умеет выводить в консоль только сообщения уровня ERROR. Людям же, очевидно, удобнее читать логи из текстового файла и хранить логи в таких же файлах. Чтобы изменить поведение логгера по умолчанию, нам нужно сконфигурировать свой файловый аппендер. Для начала, прямо в папке src нужно создать файл log4j.xml, или в папке resources, если используешь Maven, or in the resources folder, in case you use Maven. С форматом xml ты уже знаком, у нас недавно была лекция про него 🙂 Вот таким будет его содержимое:
[%t] %-5level %logger — %msg%n»/>
Выглядит не особо-то и сложно 🙂 Но давай все-таки пройдемся по содержимому.
Это так называемый status-logger. Он не имеет отношения к нашему логгеру и используется во внутренних процессах log4j.
Можешь установить status=”TRACE” вместо status=”INFO”, и в консоль будет выводиться вся информация о внутренней работе log4j (status-logger выводит данные именно в консоль, даже если наш аппендер для программы будет файловым). Нам это сейчас не нужно, поэтому оставим все как есть.
[%t] %-5level %logger — %msg%n»/>
Тут мы создаем наш аппендер. Тег указывает что он будет файловым. name=»MyFileAppender» — имя нашего аппендера. fileName=»C:UsersUsernameDesktoptestlog.txt» — путь к лог-файлу, куда будут записываться все данные. append=»true» — нужно ли дозаписывать ли данные в конец файла. В нашем случае так и будет.
Если установить значение false, при каждом новом запуске программы старое содержимое лога будет удаляться. [%t] %-5level %logger — %msg%n»/> — это настройки форматирования. Здесь мы с помощью регулярных выражений можем настраивать формат текста в нашем логе.
Здесь мы указываем уровень логгирования (root level). У нас установлен уровень INFO: то есть, все сообщения уровней выше INFO (по таблице, которую мы рассматривали выше) в лог не попадут. У нас в программе будет 3 сообщения: одно INFO, одно WARN и одно ERROR. С текущей конфигурацией все 3 сообщения будут записаны в лог.
Если ты поменяешь значение root level на ERROR, в лог попадет только последнее сообщение из LOGGER.error(). Кроме того, сюда же помещается ссылка на аппендер. Чтобы создать такую ссылку, нужно внутри тега создать тег и добавить ему параметр ref=”имя твоего аппендера” . Имя аппендера мы создали вот тут, если ты забыл:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyTestClass < public static final Logger LOGGER = LoggerFactory.getLogger(MyTestClass.class); public static void main(String[] args) < LOGGER.info(«Начало работы программы. «); try < LOGGER.warn(«Внимание! Программа пытается разделить одно число на другое»); System.out.println(12/0); >catch (ArithmeticException x) < LOGGER.error(«Ошибка! Произошло деление на ноль!»); >> >
Он, конечно, немного кривоватый (перехват RuntimeException — идея так себе), но для нашей целей отлично подойдет 🙂 Давай запустим наш метод main() 4 раза подряд и посмотрим на наш файл testlog.txt. Создавать его заранее не нужно: библиотека сделает это автоматически. Все заработало! 🙂 Теперь у тебя есть настроенный логгер.
Ты можешь поиграться с какими-то написанными тобой ранее программами, добавив вызовы логгера во все методы, и посмотреть на получившийся журнал:) В качестве дополнительного чтения очень рекомендую тебе вот эту статью. Там тема логирования рассмотрена углубленно, и за один раз прочитать ее будет непросто. Но в ней содержится очень много полезной дополнительной информации. Например, ты научишься конфигурировать логгер так, чтобы он создавал новый текстовый файл, если наш файл testlog.txt достиг определенного размера:) А наше занятие на этом завершено! Ты сегодня познакомился с очень важной темой, и эти знания точно пригодятся тебе в дальнейшей работе. До новых встреч! 🙂
Источник: javarush.com
Логирование как инструмент повышения стабильности веб-приложения
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.

Профессия тестировщик: разбираемся в QA, QC и testing
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
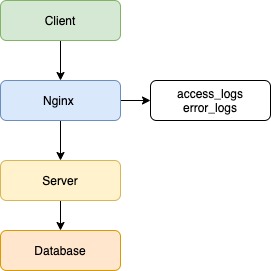
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: «GET /api/v1/users/levels HTTP/2.0», upstream: «http://127.0.0.1:5000/api/v1/users/levels», host: «app.dunice-testing.com»
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Источник: tproger.ru