

Обнаружение объектов — это тип категоризации изображений, при котором нейронная сеть предвосхищает элементы на изображении и рисует вокруг них ограничивающие рамки. Обнаружение и локализация объектов на изображении, соответствующих заданному набору классов, называется обнаружением объектов.
Обнаружение объектов (также известное как распознавание объектов) является особенно важным поддоменом Computer Vision, поскольку такие задачи, как обнаружение, идентификация и локализация, находят широкое применение в реальных контекстах.
Подход YOLO может помочь вам выполнить эти задачи. В этом эссе мы более подробно рассмотрим YOLO, включая то, что это такое, как оно работает, различные варианты и многое другое.
Итак, что такое YOLO?
YOLO — это метод идентификации и распознавания объектов на фотографиях в реальном времени. Это аббревиатура от You Only Look Once. Редмонд и др. предложил подход в статье, которая была первоначально опубликована в 2015 году на конференции IEEE/CVF по компьютерному зрению и распознаванию образов (CVPR).
YOLO C#. Распознавание объектов на фото. Урок 1
Газете была присуждена награда OpenCV People’s Choice Award. В отличие от предыдущих методов идентификации объектов, которые переназначали классификаторы для обнаружения, YOLO предлагает использовать сквозной нейронной сети который одновременно предсказывает ограничивающие рамки и вероятности классов.
YOLO дает самые современные результаты, используя принципиально новый подход к распознаванию объектов, который легко превосходит предыдущие методы обнаружения объектов в реальном времени.
YOLO работает
Метод YOLO делит изображение на N сеток, каждая из которых имеет сектор одинакового размера SxS. Каждая из этих N сеток отвечает за обнаружение и определение местоположения объекта, который она содержит.
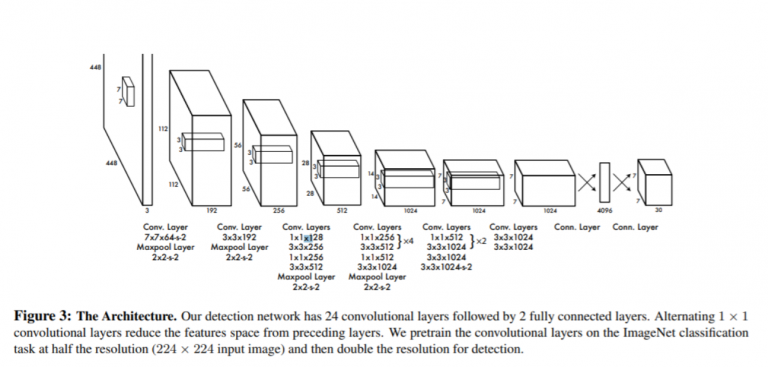
Эти сетки, в свою очередь, прогнозируют координаты ограничивающей рамки B относительно координат ячейки, а также имя элемента и вероятность присутствия объекта в ячейке. Из-за того, что многие ячейки предсказывают один и тот же элемент с различными предсказаниями ограничительной рамки, этот метод значительно сокращает вычисления, поскольку и обнаружение, и распознавание обрабатываются ячейками из изображения.
Тем не менее, он производит много повторяющихся прогнозов. Чтобы решить эту проблему, YOLO использует немаксимальное подавление. YOLO подавляет все ограничивающие рамки с более низкими показателями вероятности в немаксимальном подавлении.
YOLO делает это, изучая оценки вероятности, связанные с каждым вариантом, и выбирая вариант с наивысшим баллом. Ограничивающие рамки с наибольшим пересечением над объединением с текущей ограничивающей рамкой с высокой вероятностью затем подавляются.

Детальный разбор архитектуры yolo версий 1-5. Практика по машинному обучению и анализу данных.
Этот процесс продолжается до тех пор, пока не будут заполнены ограничивающие рамки.
Различные варианты YOLO
Что такое yolo программа

О YOLO: Наша обобщенная архитектура чрезвычайно быстра. Базовая модель YOLO обрабатывает изображения в реальном времени со скоростью 45 фреймов в секунду. Меньшая версия модели, Fast YOLO, обрабатывает целых 155 фреймов в секунду…
— You Only Look Once: Unified, Real-Time Object Detection, 2015
Что такое YOLO?
YOLO – это передовая сеть для распознавания объектов (object detection), разработанная Джозефом Редмоном (Joseph Redmon). Главное, что отличает ее от других популярных архитектур – это скорость. Модели семейства YOLO действительно быстрые, намного быстрее R-CNN и других. Это значит, что мы можем распознавать объекты в реальном времени.
Во время первой публикации (в 2016 году) YOLO имела передовую mAP (mean Average Precision), по сравнению с такими системами, как R-CNN и DPM. С другой стороны, YOLO с трудом локализует объекты точно. Тем не менее, она обучается общему представлению объектов. В новой версии как скорость, так и точность системы были улучшены.
Альтернативы (на момент публикации):
Другие подходы в основном использовали метод плавающего над изображением окна, и классификатора для этих регионов (DPM – deformable part models). Кроме этого, R-CNN использовал метод предложения регионов (region proposal). Этот метод сначала генерировал потенциальные содержащие рамки, после чего для них вызывался классификатор, а потом производилась пост-обработка для удаления двойных распознаваний и усовершенствования содержащих рамок.
YOLO преобразовала задачу распознавания объектов к единой задаче регрессии. Она проходит прямо от пикселей изображения до координат содержащих рамок и вероятностей классов. Таким образом, единая CNN предсказывает множество содержащих рамок и вероятности классов для этих рамок.
Теория
Поскольку YOLO смотрит на изображение только один раз, плавающее окно – это неправильный подход. Вместо этого, все изображение разбивается с помощью сетки на ячейки размером 𝑆 ∗ 𝑆 . После этого каждая ячейка отвечает за предсказание нескольких вещей
Во-первых, каждая ячейка отвечает за предсказание нескольких содержащих рамок и показателя уверенности (confidence) для каждой из них – другими словами, это вероятность того, что данная рамка содержит объект. Если в какой-то ячейке сетки объектов нет, то очень важно, чтобы confidence для этой ячейки был очень малым.
Когда мы визуализируем все эти предсказания, мы получаем карту всех объектов и набор содержащих рамок, ранжированных по их confidence.
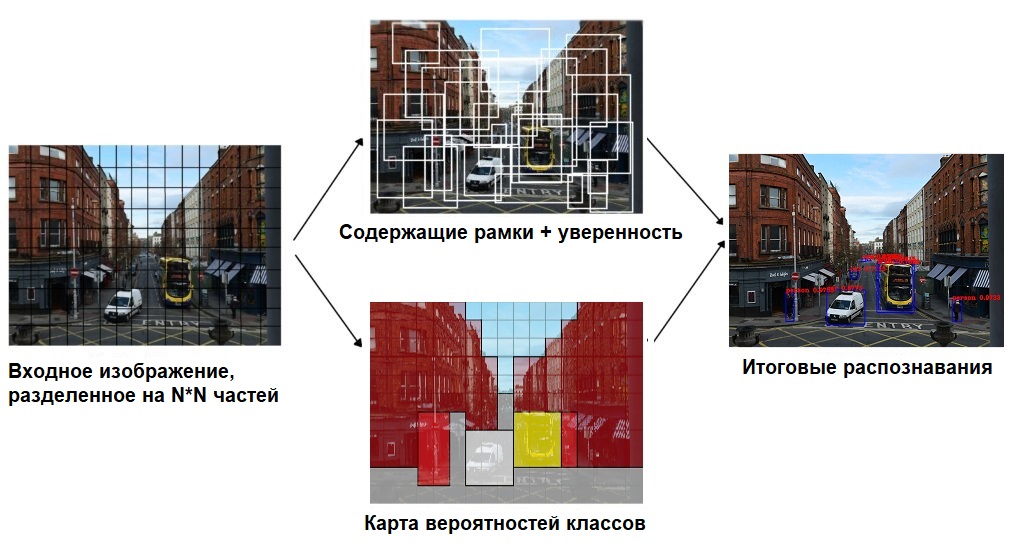
Во-вторых, каждая ячейка отвечает за предсказание вероятностей классов. Это не значит, что какая-то ячейка содержит какой-то объект, это всего лишь вероятность. Таким образом, если ячейка сети предсказывает автомобиль, это не значит, что он там есть, но это значит, что если там есть какой-то объект, то это автомобиль.
Давайте опишем детально, как может выглядеть выдаваемый моделью результат.
В YOLO для предсказания содержащих рамок используются якорные рамки (anchor boxes). Их основная идея заключается в предопределении двух разных рамок, называемых якорными рамками или формой якорных рамок. Это позволяет нам ассоциировать два предсказания с этими якорными рамками. В общем, мы можем использовать и большее количество якорных рамок (пять или даже больше). Якоря были рассчитаны на датасете COCO с помощью k-means кластеризации.
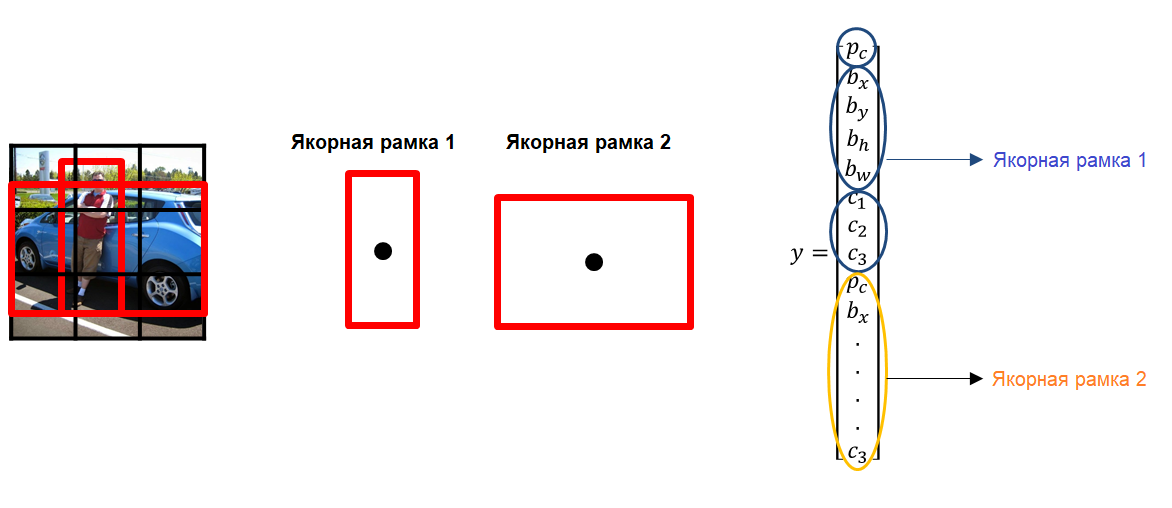
У нас есть сетка, каждая ячейка которой должна предсказать:
- для каждой содержащей рамки: 4 координаты ( 𝑡 𝑥 , 𝑡 𝑦 , 𝑡 𝑤 , 𝑡 ℎ ) и одну «ошибку объектности» – то есть, метрику confidence, определяющую, есть объект или нет.
- некоторое количество вероятностей классов.
Если есть некоторое смещение относительно верхнего левого угла 𝑐 𝑥 , 𝑐 𝑦 , то эти предсказания соответствуют следующим формулам:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h
где 𝑝 𝑤 и 𝑝 ℎ соответствуют ширине и высоте содержащей рамки. Вместо предсказания смещений, как было во второй версии YOLO, авторы предсказывают координаты локации относительно расположения ячейки сети.
Этот вывод – это вывод нашей нейронной сети. Всего там 𝑆 ∗ 𝑆 ∗ [ 𝐵 ∗ ( 4 + 1 + 𝐶 ) ] выводов, где 𝐵 – количество содержащих рамок, предсказываемых каждой ячейкой (зависит от того, в скольких масштабах мы хотим делать наши предсказания), 𝐶 – количество классов, 4 – количество содержащих рамок, а 1 – предсказание объектности. За один проход мы можем пройти от исходного изображения до выходного тензора, соответствующего распознанным объектам изображения. Стоит также упомянуть, что YOLO v3 предсказывает рамки в трех разных масштабах.
Теперь, если мы возьмем вероятности и умножим их на значения confidence, мы получим все содержащие рамки, взвешенные по их вероятности содержания этого объекта.
Простое сравнение с порогом позволит нам избавиться от предсказаний с низкой confidence. Для следующего шага важно определить, что такое пересечение относительно объединения (intersection over union). Это отношение площади пересечения прямоугольников к площади их объединения:

После этого у нас еще могут быть дубликаты, и чтобы от них избавиться, мы применяем подавление не-максимумов. Подавление не-максимумов берет содержащую рамку с максимальной вероятностью и смотрит на другие содержащие рамки, расположенные близко к первой. Ближайшие рамки с максимальным пересечением относительно объединения с первой рамкой будут подавлены.
Поскольку все делается за один проход, модель работает почти с такой же скоростью, как классификация. Кроме того, все предсказания производятся одновременно, а это значит, что модель неявно встраивает в себя глобальный контекст. Проще говоря, модель может усвоить, какие объекты обычно встречаются вместе, относительные размеры и расположение объектов и так далее.
Алгоритм YOLO простым языком

Что такое YOLO? Эта аббревиатура расшифровывается как “You Only Look Once” (“Стоит только раз взглянуть”). YOLO — современный алгоритм глубокого обучения, который широко используется для обнаружения объектов. Он был разработан Джозефом Редмоном и Али Фархади в 2016 году.
Чем YOLO отличается от других алгоритмов глубокого обучения для обнаружения объектов?
Основное отличие YOLO от других алгоритмов сверточной нейронной сети (CNN), используемых для обнаружения объектов, заключается в том, что он очень быстро опознает объекты в режиме реального времени. Принцип работы YOLO подразумевает ввод сразу всего изображения, которое проходит через сверточную нейронную сеть только один раз. Именно поэтому он называется “Стоит только раз взглянуть”. В других алгоритмах этот процесс происходит многократно, то есть изображение проходит через CNN снова и снова. Так что YOLO обладает преимуществом высокоскоростного обнаружения объектов, чем не могут похвастать другие алгоритмы.
Представьте себе автомобиль, оснащенный функцией самостоятельного вождения, который использует обычный алгоритм обнаружения объектов сети CNN. Если алгоритм заметит впереди препятствие, машина затормозит сама. Но в данном случае все будет происходить медленно, и алгоритм увидит объект-препятствие довольно поздно. Это может привести к аварии.
Теперь представьте себе ту же ситуацию с YOLO. На этот раз автомобиль оснащен алгоритмом YOLO и остановится как раз вовремя, так как очень быстро обнаружит препятствие в режиме реального времени.
Как работает YOLO?
Алгоритм YOLO был обучен на определенном типе набора данных, который состоит из 80 различных типов классов (см. ниже):
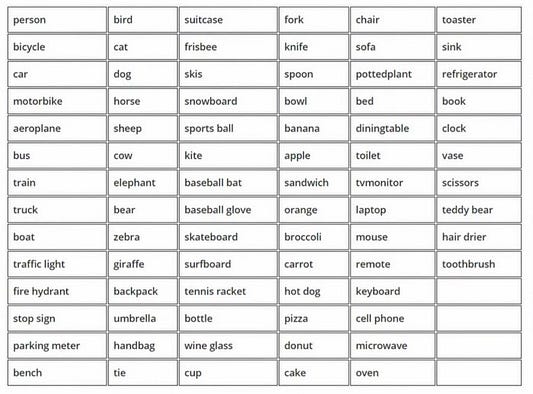
Алгоритм YOLO способен обнаруживать все эти 80 видов объектов на изображении. Он также может быть специально обучен, чтобы легко находить новые объекты. Набор данных, который использовался для обучения обнаружения 80 классов объектов, известен под названием “Coco”.