

В это теме мы подробно расскажем как это и зачем это нужно. Рассказывать будем все это для пользователей Windows. Предполагается, что пользователи других ОС достаточно продвинуты, что бы и так знать как им сделать аналогичные манипуляции, либо могут найти инструкции в Интернет сети без моей помощи. Сначала немного теории:
Трассировка (trouce route) — Процедура получения информации о маршрутизаторах (узлах), через которые проходят пакеты к интересующему компьютеру. Позволяет обнаружить ошибки маршрутизации, а также то, к какому первичному провайдеру подключен хостинг-провайдер. Подробнее: http://ru.wikipedia.org/wiki/Traceroute
Зачем нужна трассировка? Иногда тот или иной сайт (как правило, вас волнует ваш сайт) вам недоступен. У этого могут быть разные причины:
- Проблемы на сервере (в том числе технические работы)
- Проблемы вашего провайдера доступа
- Проблемы на канале
- Проблемы с браузером
- Вас забанили и некоторые другие.
Трассировка поможет идентифицировать ситуацию. И, обращаясь в службу поддержки с проблемой о недоступности сайта, вам стоит сразу присылать данные команды tracert. Это сэкономит время, и позволит быстрее начать решать проблемы по существу. Так же, перед тем как писать о том, что ваш сайт недоступен, стоит попытаться определить ваша личная это проблема или носит глобальный характер.
RTX — как работает технология трассировки лучей? Стоит ли за нее переплачивать?
Если сайт недоступен полностью, скорее всего мы об этом знаем, хотя никто не запрещает вам еще раз нам напомнить об этом. Главное что бы ваши гневные письма не отвлекли нас от решение самой проблемы, переключив внимание на ответ вам.
Для того, чтобы ориентировочно определить с чем связана проблема, вам стоит попробовать открыть сайт в другом браузере и убедиться, что в нем он так же не открывается, если в другом браузере открылся, значит это проблема с вашими настройками браузера или фаервола. Попросить кого-то из ваших знакомых, пользующихся другим провайдером, а лучше живущих в другом регионе зайти на сайт. Если им удается благополучно зайти, а вам нет, скорее всего проблемы у вашего провайдера или на канале, хотя возможно и другие варианты. В этом случае как раз и стоит сделать трассировка, она поможет идентифицировать проблему.
Так же, в качестве аналога обращения к знакомым, можем порекомендовать воспользоваться специализированными сервисами мониторинга доступности сайтов. Например: http://host-tracker.com/
Зайдя по указанной ссылке, вводите адрес сайта и нажимаете кнопку «check». Спустя некоторое время сервис покажет статусы доступности проверяемого сайта из разных точек мира. Если выдается результат «Ok», значит, опять же, речь идет о вашей локальной проблеме.
Как же сделать трассировку? Нажимаем «Пуск» далее нажимаем «Выполнить». Там латинскими буквами без кавычек пишем «cmd» и нажимаем «Ок» (либо «Enter»):
Трассировка алгоритма
В появившемся командной строке опять же без кавычек пишем «tracert адрес интересующего сайта». Например, если трассеруем ucoz.ru, пишем «tracert ucoz.ru» и нажимаем ввод («Enter»).
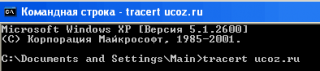
Далее, полученные данные вы, вероятно, захотите отправить в службу поддержки. Не нужно делать скриншот — их (данные) можно скопировать и передать в виде текста. Для этого, наводим мышью на командную строку, в которой содержатся результаты трассеровки, нажимаем правую кнопку мыши -> «Выделить все». После чего нажимаем «Enter». Все, теперь данные в буфере обмена.
Их можно вставить в письмо нажав правую кнопку мыши -> «Вставить» (либо CTRL + V).
Источник: rudevice.ru
Протоколирование: рекомендации по трассировке

2012-08-30 в 20:24, admin , рубрики: Блог компании Инфопульс Украина, Программирование, Проектирование и рефакторинг

В данной статье я хочу поделиться своими мыслями/наблюдениями/рекомендациями относительно реализации такой важной задачи при разработке ПО как протоколирование. В Интернете существует множество статей описывающих инструменты для протоколирования, но очень мало информации о том, какие именно события, и какую информацию, нужно записывать в протокол работы программы.
Введение
Очень часто возникает проблема диагностики дефектов в тестовой или рабочей среде, где нет инструментов разработки и отладки. И единственным способом понять, в чем ошибка – добавление строк кода с отладочной информацией и повторная установка приложения, если такие строки не были добавлены ранее. А можно ли сразу писать код так, чтобы информации, которую протоколирует приложение, было бы достаточно для диагностики проблемы?
В статье я совсем не буду касаться таких вопросов как инструменты для протоколирования. Но в любом случае, нужно понимать, что такие инструменты существуют и позволяют фильтровать записываемые в протокол данные и настраивать запись протокола в различные источники.
Основная задача статьи – дать представление разработчикам, какими способами проводится протоколирование, и дать рекомендации о том, где в программе вставлять строчки кода для протоколирования. В этой статье, в основном, будем говорить о трассировке.
Протоколирование
Я рассматриваю протоколирование намного шире, чем просто запись в лог-файл. Для меня протоколирование — это набор средств и методов, которые решают такие задачи:
- Быть уверенным, что система работает и работает правильно
- Понимать, почему система и ее данные находятся в текущем состоянии
- Иметь возможность быстро найти неисправность
- Узнать, как систему можно усовершенствовать
Подходы к протоколированию
Вышеуказанные цели можно конкретизировать, выделив «пользователей» результатов протоколирования, и задачи этих «пользователей». Далее можно выделить средства и методы, с помощью которых эти задачи можно реализовать. Итак, я вижу 4 основных категории «пользователей»:
- Разработчик — специалист, который разрабатывает и улучшает приложение
- Тест инженер — специалист, который отвечает за качество приложения, обнаружение и локализацию дефектов в период разработки
- Системный администратор — специалист службы сопровождения, который отвечает за бесперебойную работу приложения в рабочей среде и своевременное обнаружение ошибок.
- Владелец приложения — бизнес-пользователь, который знает и понимает функционал приложения в целом и, по сути, является владельцем данных приложения; сотрудник для которого разрабатывалось это приложение
В таблице ниже для типов пользователей приведены наиболее часто используемые ими в работе методы и средства для решения своих задач.
- Найти место возникновения проблем и исправить их
- Выполнить оптимизацию
- Трассировка
- Счетчики производительности
- Состояние объектов/процессов
- Быть уверенным, что система работает корректно
- Обнаружение дефектов
- Максимально точно определить место и причину возникновения найденных дефектов
- Журнал событий
- Журнал аудита
- Состояние объектов/процессов
- Быть уверенным, что система работает
- Если есть ошибки понять почему (по чьей вине, где исправлять)
- Если работает медленно – понять почему
- Журнал событий
- Счетчики производительности
- Состояние объектов/процессов
- Быть уверенным, что система работает именно так, как нужно
- Журнал аудита
- Состояние объектов/процессов
Указанные в таблице средства и методы кратко описаны ниже.
- Трассировка — инструмент, который обычно называют «логом», по сути, хранилище, куда пишется подробная информация о ходе выполнения программы (последовательно, в порядке возникновения событий). Это обычно текстовый файл или таблица базы данных. Данный инструмент нужен разработчику, тест-инженеру или специалист службы сопровождения для детального анализа того, что происходит в приложении.
- Журнал событий — инструмент, который показывает события в приложении с точки зрения администратора. Т.е. события, по которым системный администратор может сказать в рабочем ли состоянии приложение или нет. Если говорить о разработке ПО для Windows —то это чаще всего Windows Event Log или собственные журналы приложений. Я сторонник того, чтобы не смешивать хранилища для трассировки и журнал событий.
- Журнал аудита — инструмент, который позволяет пользователю приложения понять, кто и какие действия выполнял (или пытался выполнять) в системе
- Счетчики производительности— инструмент системного администратора, который помогает обнаружить узкое место в производительности системы. Примером такого инструмента может быть Performance Monitor, встроенный в операционную систему Windows. Для других ОС существуют аналогичные инструменты
- Состояние объектов/процессов — инструмент, который помогает понять, в каком состоянии (или в какой стадии) находятся в текущий момент объекты или процессы в приложении, и как они в это состояние или стадию обработки они попали.
Например: представим себе приложение, которое обрабатывает входящие почтовые электронные сообщения. Для каждого такого сообщения можно выделить состояния: получено, обработано, удалено. В «журнал состояний объектов/процессов» в таком случае следует записать ключевую информацию по письму, историю смены состояний письма и сообщения при его обработке. Таким образом, полностью отделяется важная информация по процессу обработки письма от «мусора»
Выбор и реализация методов протоколирования — очень важная задача, от реализации которой зависит скорость и качество обнаружения и исправления дефектов и качества сопровождения. Поэтому на стадии планирования и разработки этой задаче нужно уделить досрочно внимания и подобрать достаточный набор методов протоколирования.
Трассировка

* картинка взята из статьи Lazy logger levels
- обо всех ошибках – обработанных и не обработанных
- параметры запуска и загруженную конфигурацию
- а также события, описанные ниже.
Трассировочная информация предназначена главным образом для разработчика и тест инженера (или в рабочей среде — для сотрудников службы сопровождения очень высокого уровня квалификации).
Особенность трассировки заключается в том, что обычно этот функционал не описывается в требованиях, и поэтому разработчикам в начале проекта обычно сложно представить какая трассирующая информация может понадобиться, и, поэтому, сложно понять, что и когда нужно записывать.
Самое главное — понять, что трассировка в рабочей среде включается только при необходимости, т.е. не засоряет журнал событий. Для среды разработчика и среды тестирования трассировка чаще всего включена постоянно для наблюдения за правильностью работы приложения и отладки.
Инструменты для протоколирования обычно дают возможность вести запись в журнал, указывать, куда именно эта информация будет записываться. Важным элементом является также возможность в конфигурации указывать, какие записи попадут в журнал, а какие — нет (обычно это делается на основе категорий событий и уровней событий).
Однако большой проблемой является то, что, несмотря на наличие инструментов редко можно встретить рекомендации как их правильно использовать, а именно:
- Какие события нужно писать в трассировочный лог
- Как правильно выбрать уровень для события
- Как правильно выбрать категории событий
- Какую информацию нужно записывать при возникновении того или иного события
Это и будет рассмотрено далее в статье.
Какие события нужно вносить в трассировочный лог
Важным фактором при выборе событий, которые нужно писать в трассировочный лог зависит, на мой взгляд, от двух факторов:
- Используется ли модульные тесты при разработке.
Использование модульных тестов позволяет значительно снизить количество ошибок в бизнес логике методов, не взаимодействующих с внешними системами (внешними по отношению к данному слою приложения). Однако при взаимодействии кода с внешней системой (взаимодействие кода бизнес слоя с базой данных, взаимодействие слоев бизнес логики, расположенных на разных компьютерах и прочее) модульные тесты не эффективны потому, что конфигурация разных слоев может быть разной в разных средах. Исходя из этого, можно сделать вывод, что при использовании модульных тестов логично выполнять только трассировку взаимодействий между слоями и трассировку ошибок (т.к. считаем, что логика каждого слоя в отдельности очень хорошо протестирована). Если же модульных тестов нет — трассировать нужно каждую ветку логики программы (вход в метод, выход, возникновение в методе ошибки, каждую ветку условного оператора) - Тип приложения.
В таблице представлены некоторые типы приложений и события для протоколирования в трассировочный лог (понятно, что есть и другие типы приложений).
| Тип приложения | Особенности протоколирования |
| Изолированное desktop приложение (даже не сохраняет ничего на диск) | Если такое приложение хорошо протестировано модульными тестами, то трассировку делать не имеет смысла |
| Приложение для внесения данных и получения отчетов | Тут уже имеется взаимодействие между приложением и хранилищем, и поэтому рационально протоколировать информацию о таком взаимодействии: запросы, количество внесенных и полученных записей, скорость обработки запросов, ключевые параметры для формирования отчетов |
| Инсталлятор приложения (исправления, обновления ) | В данном случае программа тесно взаимодействует с внешней системой и поэтому каждый шаг (попытка выполнить и результат выполнения) должны вносится в трассировочный лог |
| Интеграционная шина | Краткая или полная (полностью данные) информация о поступающих или отправляемых данных |
| Приложение, которое может быть сильно изменено пользователем (или расширено дополнительными модулями и плагинами) | Все взаимодействия с такими внешними модулями (входные/выходные параметры) и влияние установленных параметров конфигурации на работу программы |
Какие данные нужно вносить в трассировочный лог
Кроме простого названия (описания) события, для анализа работы часто нужна еще дополнительная информация. Следующая таблица показывает данные, которые полезно было бы записывать. Понятно, что далеко не всегда нужно писать события настолько подробно. Кроме того, обычно инструменты трассировки позволяют некоторую из указанной ниже информации записывать автоматически.
| Данные | Описание |
| Дата и время | Дата и время возникновения события |
| Сервер | Сервер, на котором событие возникло (полезно при анализе журналов, собранных с различных серверов) |
| Процесс | Название процесса, где возникло событие. Это необходимо, например, в случае если разные процессы используют общие библиотеки. |
| Метод | Название метода, возможно, включающий название класса и библиотеки |
| Категория события | Название слоя или логического модуля |
| Уровень | Уровень детализации события |
| Название | Название события (запуск или завершение метода, ошибка, изменение состояние объекта и прочее) |
| Детальная информация | Например, детальная информация об ошибке (а при критической ошибке может быть и детальная информация о системе), значение параметра(-ов), название объекта или описание действия над объектом |
| Учетная запись, под которой работает процесс | |
| Учетная запись пользователя, который вызвал действие | Учетная запись пользователя, который сделал начальный вызов, что привело к данному событию |
| Стек | Стек вызовов методов, которая привела к данному событию. Может быть полезен при детальном анализе события |
| Корреляционный номер процесса | Если приложение многопользовательское, то важно понимать к какому запросу (пользователю) относится та или иная запись о события |
| Корреляционный номер инициирующего процесса | Если приложение распределенное, то данный номер используется для сопоставления событий на разных серверах (или процессах). Например, можно передавать с клиента на сервер корреляционный номер и сохранять его при трассировке. В дальнейшем можно сопоставлять вызов клиентского приложения с событием на сервере |
Уровни трассировки
Уровни в основном используются для фильтрации событий при записи в журнал. Это нужно для предотвращения записи в журнал данных, которые в данный период времени не нужны.
Например, такой инструмент как NLog, предоставляет по умолчанию 6 уровней событий (от более детального до менее детального): trace, debug, info, warn, error, fatal (более детально см. в документации к NLog)
Далее, в конфигурации можно указать, что, например, в рабочей среде, в журнал трассировки писать события уровня Error и Fatal (а все остальные игнорировать), а при возникновении проблемы изменить конфигурацию так, чтобы записывать все события.
Следующая таблица показывает мои рекомендации по выбору уровней событий при трассировке
| Событие | Уровень |
| Загруженная конфигурация / смена конфигурации | Info |
| Действия пользователя | Info |
| Начало и окончание каждого «публичного» метода (или метода, который реализует логику согласно спецификации), входные/выходные параметры, результат работы такого метода | Info |
| В публичных методах входные/выходные параметры, которые являются наборами данных | Debug |
| Логика (ветки программы) описанная спецификацией | Info |
| Начало и окончание остальных методов, входные/выходные параметры, результат работы | Trace |
| Шаги остальных методов | Trace |
| Доступ к внешним ресурсам (например: БД, web-сервисы) | Info |
| Детальная информация о запросах (командах) доступа к внешним ресурсам и полученном результате | Debug |
| Неожиданные исключения (не критические) | Error |
| Исключение, описанное в спецификации | Warn/Error |
| Обработанные исключения | Warn/Info/ Debug |
| Критическое исключение (обработанное или не обработанное) | Fatal |
Выбор категорий событий
Второй важный параметр, по которому можно настроить фильтрацию записи событий в журнал — это категории событий. Эти категории разработчик должен выбирать сам (т.е. инструменты не предоставляют категории по умолчанию)
Я рекомендую придерживаться таких рекомендаций — для каждого отдельного логического уровня сделать отдельную категорию. Например: уровень интерфейса (UIControls), уровень бизнес-логики (BusinessLogic), уровень доступа к данным (DAL), модуль поиска (Search), программа настройки конфигурации (ConfigManager) и так далее.
Далее, если у вас есть отдельные компоненты внутри слоя, то можно для их трассировки выбрать отдельные подкатегории, отделяя от основной категории точкой.
Например, визуальный компонент для отображения облака тегов (который располагается в уровне интерфейса)— UIControls.TagsControl.
Таким образом, при возникновении проблемы с компонентом, с одной стороны вы всегда сможете по журналу определить, какой компонент создал то или иное событие, с другой — более гибко настроить фильтрацию записи в журнал событий только по выбранному компоненту.
Заключение
Протоколирование — важная функция в любом приложении и требует внимательного анализа и проектирования. Несмотря на то, что трассировка обычно не описывается в требованиях, правильное ее использование может в значительной степени ускорить процесс обнаружения и исправление дефектов на тестовой и рабочей среде.
Данные выкладки — это мои практика и наблюдения, и, соответственно, у вас могут быть свой опыт и своя методика по использованию протоколирования (и трассировки в частности). С удовольствием выслушаю критические отзывы и замечания для улучшения рекомендаций.
Что еще почитать по трассировке
- Способы отладки приложений: Протоколирование http://dtf.ru/articles/read.php?id=36547
- Каким должен быть правильный лог-файл — http://www.codeart.ru/2011/02/23/kakim-dolzhen-byt-pravilnyj-log-fajl/
- What Goes Into A Trace Log? — http://www.informit.com/guides/content.aspx?g=dotnethttps://www.pvsm.ru/programmirovanie/14132″ target=»_blank»]www.pvsm.ru[/mask_link]
Альтернативные методы трассировки приложений

Трассировка используется во многих видах ПО: в эмуляторах, динамических распаковщиках, фаззерах. Традиционные трейсеры работают по одному из четырех принципов: эмуляция набора инструкций (Bochs), бинарная трансляция (QEMU), патчинг бинарных файлы для изменения потока управления (Pin), либо работа через отладчик (PaiMei, основанный на IDA). Но сейчас речь пойдет о более интересных подходах.

WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
Зачем отслеживать?
Задачи, которые решают с помощью трассировки можно условно разделить на три группы в зависимости от того, что именно отслеживается: выполнение программы (поток управления), поток данных или взаимодействие с ОС. Давай поговорим о каждом подробнее.
Поток управления
Отслеживание потока управления помогает понять, что делает бинарник во время исполнения. Это хороший способ работы с обфусцированным кодом. Также, если ты работаешь с фаззером, это поможет с анализом покрытия кода. Или возьмем, например, антивирусное ПО, где трассировщик проследит за исполнением бинарного файла, сформулирует некий паттерн его поведения, а также поможет с динамической распаковки исполняемого файла.
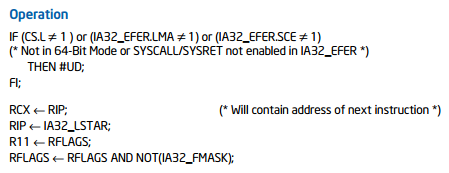
Трассировка может происходить на разных уровнях: отслеживание каждой инструкции, базовых блоков либо только определенных функций. Как правило, она осуществляется путем пред/постинструментации, то есть патчинга потока управления в наиболее «интересных» местах. Другой метод состоит в том, чтобы просто приаттачить отладчик к исследуемой программе и обрабатывать ловушки и точки останова. Однако есть еще один не очень распространенный способ — задействовать функции центрального процессора. Одна из интересных возможностей процессоров Intel — флаг MSR-BTF, который позволяет отслеживать выполнение программы на уровне базовых блоков — на ветвлениях (бранчах). Вот что говорится по поводу данного флага в документации:
«Когда ПО устанавливает флаг BTF в MSR-регистре MSR_DEBUGCTLA и устанавливает флаг TF в регистре EFLAGS, процессор будет генерировать отладочное прерывание только после встречи с ветвлением или исключением.»
Поток данных
В этом сценарии трассировка применяется для распаковки кода, а также для наблюдения за обработкой ценной информации — во время его можно обнаружить неправильное использование объектов, переполнения и прочие ошибки. Кроме того, оно также может использоваться для сохранения и восстановления контекста в процессе трассировки. Обычно это делается так: исследуемая библиотека полностью дизассемблируется, после этого в ней локализуются все инструкции чтения/записи, а затем в процессе выполнения кода происходит их парсинг и определяется адрес назначения. Есть и другой вариант — с помощью соответствующей API-функции устанавливается защита виртуальной памяти, после чего отслеживаются все нарушения доступа к ней. Реже используется метод, когда в памяти изменяется таблица страниц.

Другие статьи в выпуске:
Хакер #181. Вся власть роботам!
- Содержание выпуска
- Подписка на «Хакер» -60%
Взаимодействие с ОС
Мониторинг взаимодействия с ОС позволяет отфильтровывать попытки доступа к реестру, контролировать изменения файлов, отслеживать взаимодействие процесса с различными системными ресурсами, а также вызовы определенных API-функций. Как правило, это реализуется через перехват API-функций, путем вставки «трамплинов», inline-хуков, модификацию таблицы импорта, установку брейкпоинтов. Другой вариант — задействовать системный вызов SYSCALL. Ведь если вспомнить, то каждая API-функция, которая вносит какие-то изменения в ОС, на самом деле представляет собой не что иное, как простую обертку для определенного системного вызова.
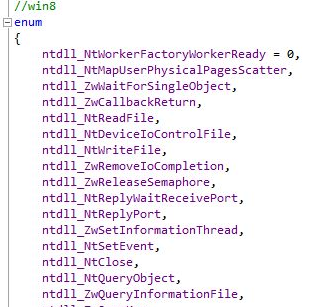
Механизм SYSCALL представляет собой быстрый способ переключить CPL (Current Privilege Level) из режима пользователя в режим супервайзера, таким образом, приложение режима пользователя может вносить изменения в ОС (рис. 4).
Погружаемся в ядро
Для выполнения упомянутых функций необходимо опуститься на уровень ядра (ring 0). Однако в режиме супервайзера уже появляется доступ к некоторым функциям, предоставляемым самой операционной системой: LoadNotify , ThreadNotify , ProcessNotify . Их использование помогает собрать информацию по загрузке и выгрузке для целевого процесса, такую как: список модулей, диапазоны адресов стека какого-либо потока, список дочерних процессов и прочее.
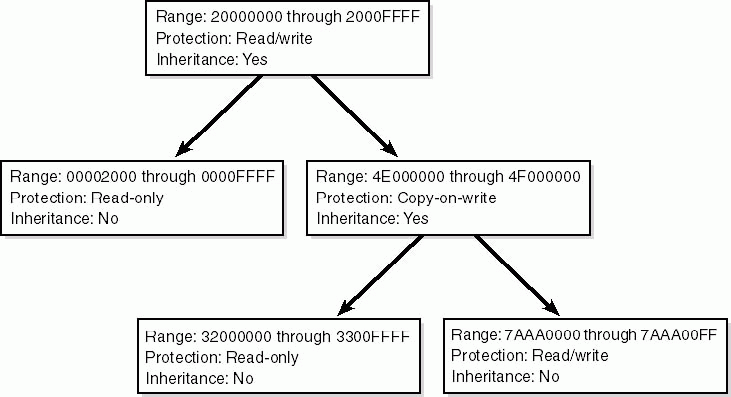
Вторая группа функций включает в себя дампер памяти, использующий MDL (memory descriptor list — список дескрипторов памяти), монитор памяти процессов, основанный на VAD (Virtual Address Descriptor), монитор взаимодействия с системой, который задействует nt!KiSystemCall64 , перехват доступа к памяти и ловушкам через IDT (Interrupt Descriptor Table).
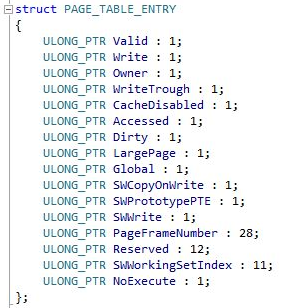
Монитор памяти использует для своей работы VAD-дерево, которое представляет собой AVL-дерево, используемое для хранения информации об адресном пространстве процесса. Оно же используется, когда необходимо инициализировать PTE (Page Table Entry) для конкретной страницы памяти.
Как я предложил выше, отслеживание доступа к памяти может осуществляться через механизм защиты памяти (такая вот тавтология), но его реализация в режиме пользователя с помощью API-функций может слишком сильно отразиться на производительности. Однако если принять во внимание, что защита памяти основана на механизме MMU — пейджинге, то есть более простой способ: изменять таблицу страниц в режиме ядра, после чего нарушение режима доступа к памяти будет обрабатываться через генерацию процессором исключения PageFault, а управление будет передаваться на обработчик IDT[PageFault]. Установка перехватчика на обработчик PageFault позволит быстро получить сигнал о запросе на доступ к выбранным страницам.

INFO
Дереву VAD посвящена очень интересная статья Брендана Долан-Гэвитта «The VAD tree: A process-eye view of physical memory5».
Все потому, что процесс может использовать только страницы памяти, помеченные как Valid (то есть выгруженные в память), в противном же случае будет возникать исключение PageFault, которое и будет перехватываться. Это означает, что если мы намеренно поставили Valid-флаг выбранной страницы памяти в значение invalid(0), то каждая попытка доступа к этой странице будет вызывать обработчик PageFault, что позволяет легко отфильтровать и обработать соответствующий запрос (вызывая callback к трейсеру и выставляя Valid-флаг для конкретного PTE).
Копаем глубже — идем в VMM!
В предыдущем разделе я предложил некоторые «грязные» методы для режима ядра. Вообще, установка хуков — это неправильный способ, и мне он не нравится, точно так же, как не нравится он и ребятам из Microsoft. Для борьбы с такими методами мелкомягкие и разработали PatchGuard. К счастью, есть и другой способ для отлова PageFaults, ловушек или SYSCALL’ов — это гипервизор. Правда, данный вариант имеет как свои плюсы, так и свои минусы.
Минусы:
- Виртуализировано не отдельное приложение, а вся система — на уровне ядра ЦП.
- Оператор switch( VMMExit ) отбирает немного производительности, равно как и код гипервизора, выполняющийся для каждого из вариантов switch’а.
Плюсы:
- Более высокий уровень прав, чем уровень супервайзера, а также целый набор callback’ов, предоставляемый технологией виртуализации.
При этом сам VMM (Virtual Machine Monitor) может быть минималистичным (микроVMM) и реализовывать только необходимую обработку, занимая при этом минимальный объем кода (пример).
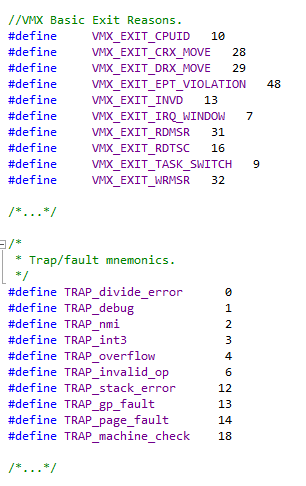
Помимо всего, в данном случае вместо того, чтобы ставить хуки на IDT, можно все обрабатывать напрямую с помощью дебаг-исключения в VMM. То же самое относится и к перехвату ошибок страниц с помощью исключения PageFault в VMM или через реализацию EPT (Extended Page Table).

Подводные камни VMM
Можно отметить некоторые основные особенности описанного подхода:
- целевой файл остается практически неизмененным:
- для отслеживания (как пошагового, так и на уровне ветвлений) внедряется флаг TRAP;
- адресные брейкпоинты через 0xCC или использование DRx;
- мониторинг памяти путем изменения таблицы страниц процесса;
- не нужно патчить бинарный файл;
Выделение трейсера из пространства целевого процесса в другой процесс дает несколько преимуществ: можно использовать его как отдельный модуль, можно сделать биндинги для Python, Ruby и других языков. Однако у этого решения есть и недостаток — очень большой удар по производительности (взаимодействие между процессами: чтение из памяти другого процесса, событийный механизм ожидания). Для ускорения трассировки необходимо перенести логику в адресное пространство целевого процесса, чтобы можно было быстро получать доступ к его ресурсам (памяти, стеку, содержимому регистров), а также опционально отказаться от VMM из-за негативного влияния обработки VMMExit на производительность и вернуться обратно к установке хуков для ловушек и обработчиков PageFault. Но с другой стороны, в будущих процессорах технологии виртуализации, наверное, станут более эффективными и не будут оказывать настолько большого влияния на производительность. К тому же возможности виртуализации для трассировки можно использовать гораздо шире, чем мы рассматриваем в рамках статьи, поэтому плюсы могут компенсировать снижение производительности.
Трейсер для ядра
Что касается трассировщика для ядра, то здесь действуют все те же принципы:
- отслеживание через ловушки (TRAP);
- мониторинг памяти через изменение таблицы страниц;
- callback’и трейсера передаются в приложения уровня пользователя;
- не нужно патчить бинарные файлы целевого приложения.
Главная особенность таких трейсеров в том, что не надо патчить бинарный файл, а также что трассировку (включая распаковку и фаззинг) можно осуществлять из уровня пользователя (например, из трейсера, написанного на Python), хотя с точки зрения производительности гораздо более эффективно делать это напрямую из режима ядра.
С другой стороны, за все эти возможности тоже приходится расплачиваться:
- адресное пространство драйвера принадлежит не ему;
- фаззинг в памяти — не такое уж простое дело;
- неверное значение RIP, регистров, памяти. манипулирование ими может очень плохо закончиться;
- необходимо четко представлять себе, что именно ты отслеживаешь или проверяешь;
- необходимо в течение всего процесса трассировки помнить о многочисленных IRQL;
- обработка исключений.
Отделение от целевого процесса, а также инкапсуляция в модуль дают нам высокую масштабируемость и возможность совместной работы с другими модулями для создания более сложного инструмента. Таким образом, в случае реализации трейсера, например, на Python, можно будет использовать IDA Python, привязки LLVM, Dbghelp для отладочных символов, дизассемблеры (движки capstone и bea) и многое другое. Чтобы показать, насколько легко и быстро можно реализовать трассировщик на Python, приведу пример, в котором контролируется более трех вариантов доступа (RWE) в заданную область памяти:
target = tracer.GetModule(«codecoverme») dis = CDisasm(tracer) for i in range(0, 3): print(«next access») tracer.SetMemoryBreakpoint(0x2340000, 0x400) tracer.Go(tracer.GetIp()) inst = dis.Disasm(tracer.GetIp()) print(hex(inst.VirtualAddr), » : «, inst.CompleteInstr) tracer.SingleStep(tracer.GetIp())
Как видишь, код очень лаконичен и понятен.
DbiFuzz-фреймворк
Все рассмотренные выше подходы к трассировке я воплотил в DbiFuzz-фреймворке, который демонстрирует, как можно отслеживать работу исполняемого файла альтернативными методами. Как мы уже отмечали, некоторые из известных методов используют инструментацию, которая дает быстрое решение, но при этом предполагает серьезное вмешательство в целевой процесс и не сохраняет целостности бинарного файла. В отличие от них, DbiFuzz оставляет бинарный файл практически нетронутым, изменяя только PTE, BTF и вставляя флаг TRAP. Другая сторона этого подхода состоит в том, что при интересующем событии включается прерывание: переход ring 3 —ring 0 — ring 3. Так как DbiFuzz подразумевает прямолинейное вмешательство в контекст и поток управления целевого процессора, то его можно использовать для написания собственных инструментов (даже на Python) для доступа к целевому бинарному файлу и его ресурсам.
INFO
Более подробно узнать про DbiFuzz-фреймворк ты можешь на моем сайте, на SlideShare и на портале ZeroNights
Show time
Для многих задач, решаемых с помощью трассировки, может оказаться полезной динамическая бинарная инструментация. Что касается DbiFuzz-фреймворка, то его можно использовать в следующих случаях:
- когда необходимо отслеживать код на лету;
- при распаковке бинарного файла, трассировке упаковщика вредоносной программы;
- для мониторинга обработки конфиденциальных данных;
- для фаззинга в памяти (легко отслеживать и изменять поток);
- при использовании в разных инструментах, не обязательно написанных на С.
Нет никаких проблем в запуске DbiFuzz на лету, просто установи ловушку или INT3-перехватчик. Поскольку мы не трогаем бинарный код целевого файла, то не будет никаких проблем с проверкой целостности, а флаг TRAP может быть заменен на MTF. Отслеживание ценных данных тоже не представляет никаких проблем, нужно просто установить соответствующий PTE — и твой монитор готов! Инструменты Python/Ruby/…? Просто создай нужные привязки (bindings) — и вперед!
Конечно, у этого фреймворка тоже есть свои недостатки, но в целом он обладает многими полезными возможностями. И ты всегда можешь поиграть с DbiFuzz, использовать входящие в него инструменты для своих нужд и отслеживать все, что пожелаешь.
Полезные ссылки
Блоги:
- Трассировка ветвлений при помощи MSR-регистров
- ExcpHook Monitor
Intel:
- Расширения для виртуальных машин
- Мануал для разработчиков ПО
Относительно VAD:
- Кратко про дескрипторы виртуальных адресов
- ReactOS
Источник: xakep.ru