
Визуализация данных является важным аспектом науки о данных. Хорошая визуализация может легко рассказать историю о лежащих в основе данных, что приведет к новому пониманию. Он может сделать сложные вещи более понятными, разбив их на управляемые единицы, понятные большинству людей. Выставки данных также являются прекрасной возможностью для общения с людьми, не входящими в научное сообщество, что важно для расширения влияния научной работы на общество. Каждый специалист по данным и инженер по машинному обучению должен использовать визуализацию данных в своей работе!
Что такое суперсет Apache?
Данные играют важную роль в жизненном цикле машинного обучения. С помощью Apache Superset вы можете легко визуализировать и исследовать данные. Он прост и удобен в использовании, предлагая широкий спектр возможностей для пользователей всех уровней способностей для изучения и визуализации своих данных, от простых круговых диаграмм до сложных колод. Это один из лучших инструментов MLOps , который позволяет вам брать большие объемы необработанных данных и преобразовывать их в более управляемые результаты.
Визуализация в Superset: плюсы и минусы | Анатолий Карпов | karpov.courses
Apache Superset — это инструмент для исследования данных и машинного обучения, созданный на основе популярных технологий с открытым исходным кодом, таких как JDBC и H2O. JDBC предоставляет мост, который соединяет SQL-запросы с аналитическими возможностями, такими как в SAS или SPSS, но с гораздо более удобным пользовательским интерфейсом и меньшей стоимостью лицензии. H2O позволяет пользователям исследовать свои данные с помощью прогностических моделей и интерактивных визуализаций.
Логотип Apache Superset
Основная цель суперсета — помочь вам:
Визуализация данных . Техника создания визуальных представлений данных для передачи информации, обычно в понятной форме, известна как визуализация данных. Визуализацию данных можно использовать для разных целей, но обычно она предназначена для предоставления информации о больших числах или других точках данных.
Исследование данных: исследование данных — это процесс изучения данных с разных точек зрения. Это способ понять контент новыми и творческими способами. Исследование данных также известно как исследовательский анализ данных или просто ESDA для краткости. Предположим, вы занимаетесь электронной коммерцией и получаете много заказов через свое приложение.
Итак, вы хотите проанализировать данные, например, сколько заказов размещено из определенного города. В удобном интерфейсе Superset упрощает изучение данных.
Анализ данных. Анализ данных — это метод извлечения информации из данных, собранных в результате различных измерений и наблюдений, для определения закономерностей, проверки выводов, прогнозирования и принятия решения о распределении ресурсов. Это помогает в изучении различных шаблонов и производительности вашего приложения. Это поможет вам в принятии решений, основанных на тенденциях.
Рекомендуемая литература: узнайте больше о суперсетах .
Возможности расширенного набора Apache
Суперсет имеет ряд функций, которые могут помочь вам с различными задачами.
Что такое Apache Superset?
- Он позволяет создавать собственные визуализации и расширять его возможности.
- Apache Superset позволяет выполнять SQL-запросы на вкладке SQL для исследования ваших данных.
- Он предоставляет простой конструктор визуализации без кода или нашу современную интегрированную среду разработки SQL для быстрой интеграции и анализа ваших данных.
- Это легкое и масштабируемое решение для приема данных, которое работает с вашей существующей инфраструктурой данных, не требуя отдельного уровня приема.
- Используя базовый семантический слой, вы можете управлять тем, как отображаются и обрабатываются источники данных.
Давайте изучим надмножество Apache
Superset содержит множество функций, в том числе интерактивные компоненты пользовательского интерфейса, которые упрощают визуализацию данных и управление ими для непрограммистов. В настоящее время Superset используется Airbnb, Twitter, Udemy и многими другими компаниями. Просто базовое понимание SQL, и вы можете освоить супермножество. Давайте рассмотрим суперсет, его компоненты и способы его установки на вашем компьютере.
Панель инструментов и срезы
Dashboard — это не что иное, как пользовательский интерфейс , который позволяет вам просматривать различные графики и данные. Итак, каждый раздел внутри Dashboard называется Slice. Срезы могут быть представлены в виде данных, текста, графика или чего-либо еще, что позволяет обмениваться информацией , например общее количество пользователей, купивших продукт в определенном городе.
Пример панели управления надмножеством. Визуальное представление панели управления надмножества Apache. (Графика автора)
Раздел, выделенный оранжевым цветом на изображении выше, называется фрагментом , а все отдельные разделы, представляющие информацию, являются фрагментами. В сводной панели может быть несколько фрагментов. Так как же настраиваются слайсы?
Рекомендуемая литература: Создание вашей первой информационной панели на Superset
Лаборатория SQL
SQL Lab — это SQL IDE на основе React с широким набором функций. Предположим, у вас есть веб-сайт электронной коммерции и вы разрабатываете таблицу ежедневных заказов, в которой указано количество заказов, размещенных в определенную дату.
Визуальное представление лаборатории SQL. (Графика автора)
Итак, на приведенном выше рисунке вы можете видеть, что ежедневные заказы — это данные временного ряда; на каждый день у вас есть x заказов. Допустим, вы хотите визуализировать эти данные в виде графика, поэтому с помощью SQL Lab вы можете предоставить свой собственный SQL-запрос для преобразования данных в график . Говоря простым языком, вам необходимо:
- Написать запрос
- Выберите оси X и Y
- Выберите тип графика
После того, как все шаги будут выполнены, срез графика будет отображаться на панели инструментов. Вы даже можете настроить параметры, например, сколько времени вы хотите выполнять запрос, выбрать диапазоны дат и многое другое. Таким образом, с надстройкой вам не нужно кодировать пользовательский интерфейс или визуализацию; просто напишите запрос и получите результат.
Внутренняя архитектура и установка
Давайте рассмотрим некоторые термины и процесс установки суперсета.
- Надмножество Apache полностью построено на основе Python; он использует flask app builder внутри.
- Он поддерживает версию Python > 3.6.
- Суперсет может быть установлен различными способами, наиболее распространенными из которых являются:
- Локально вам нужно установить python, а затем установить зависимости pip.
Установка суперсета Apache
Виртуальная среда . Настоятельно рекомендуется установка Superset в виртуальной среде. Вы можете установить pyenv-virtualenv, если используете pyenv. Или вы можете:
Установка суперсета в виртуальной среде
Docker . Самый простой способ попробовать Superset локально — использовать Docker и Docker Compose на Linux или Mac OSX.
- Когда вам нужно установить крупномасштабные экземпляры, вы можете использовать облако и запускать несколько экземпляров надмножества с помощью Kubernetes и Docker.
- Установка суперсета в Windows
Примечание . Superset официально не поддерживается в Windows . Один из вариантов для пользователей Windows опробовать Superset локально — установить виртуальную машину Ubuntu Desktop через VirtualBox и выполнить инструкции Docker в Linux внутри этой виртуальной машины. — Документы Апача .
- Вы можете начать с включения подсистемы Linux , перейдя в «Программный файл»> «Включить функции Windows»> «Включить подсистему Windows для Linux».
- После включения перейдите в Microsoft Store и установите последнюю версию на Ubuntu .
- После установки Ubuntu у вас все еще может возникнуть проблема, потому что python может использовать ваши инструменты сборки Windows. Так что, чтобы справиться с этим, вы можете установить последнюю версию Visual Studio илиустановить Visual Studio SDK.
- Когда все будет готово, теперь вы можете создать virtualenv и установить суперсет.
Рекомендую прочитать: Учебное пособие по Apache Superset
Безопасность и аутентификация
В мире данных безопасность является серьезной проблемой. С надстройкой вы можете предоставить разным пользователям разные уровни доступа. Например, специалисты по данным должны иметь доступ к графикам 1 и 2, тогда как бизнес-аналитики должны видеть графики 3 и 4. Установить роли, например, кто должен просматривать визуализацию и кто может выполнять анализ данных, несложно. Когда вы используете Superset, справляться с вещами намного проще.
Визуальное представление различных ролей и разрешений. (Графика автора)
Суперсет предоставляет различные типы ролей. Как видно на изображении выше, вы получаете три основные роли — роли администратора, альфа и гамма, каждая с разным уровнем доступа. Точно так же вы можете настроить роли для разных пользователей. Вы можете предоставлять разные наборы разрешений разным пользователям вместо полного доступа к ролям.
Например, вы создали роль финансового аналитика , которая предоставляет доступ к набору источников данных. Затем пользователям будут выданы Gamma, Financial Analyst и, возможно, sql lab , которые будут содержать определенные разрешения из разных разделов.
Узнайте больше о Apache Superset Security.
Интеграция с базами данных
Расширенный набор Apache предоставляет функциональные возможности для подключения ко многим базам данных и инструментам. Он легко подключается практически ко всем основным базам данных. Это упрощает визуализацию и анализ данных, что делает разработку моделей более эффективной. Superset совместим с Amazon Athena, Amazon Redshift, Azure MS SQL, Apache Spark SQL, PostgreSQL, Google Sheets и многими другими.
В новых версиях superset добавляет больше поддержки баз данных. Ознакомьтесь со списком поддерживаемых баз данных и зависимостей.
Типы визуализации
Надмножество Apache предоставляет широкий выбор графиков, таблиц, макетов. Ниже приведены некоторые из наиболее часто используемых типов визуализации:
- Точечная диаграмма
- Сетка
- Полигоны
- Дорожка
- Сетка экрана
- Акр и многое другое.
Типы визуализации (Источник изображения: Github)
Рекомендуем прочитать: передовой подход к разработке моделей машинного обучения
Преимущества и проблемы Apache Superset
Apache Superset. Первый взгляд на BI инструмент
В последнее время изучая вакансии на сайтах по поиску работы, все чаще стал отмечать, что помимо платных инструментов BI от кандидатов требуется знание еще бесплатных платформ. Мой предыдущий опыт работы по построению графической отчетности был связан исключительно с коммерческими продуктами, поэтому я решил выделить время на ознакомление с альтернативными решениями.
Выбор Superset был случайным, так как я обратил внимание на него лишь потому, что он входит в экосистему Apache. Сразу хочу оговориться, что в данной заметке не будет сравнения Superset с платными инструментами. Такое сопоставление функционала просто некорректно из-за разных “весовых категорий”.
Также я не буду выделять плюсы и минусы решения по сравнению с бесплатными аналогами, так как это очень дискуссионный вопрос. Неизбежно найдутся адепты того или иного продукта, которые будут доказывать ошибочность моих суждений. Поэтому я построил публикацию в форме простого описания “нюансов”, которые я выделил для себя, начав знакомство с Superset. Читатели же сами смогут сделать свои выводы.
Тестирование Superset решил начать с полноценной установки программы на Linux (Debian). Несмотря на то, что я полностью выполнил список действий, описанный в документации, данный эксперимент завершился ошибкой. Попытка с запуском docker образа удалась с первого раза, список команд на Docker Hub.
Как и в случае с Apache Airflow на этапе развертывания системы разработчики предлагают загрузить демонстрационные примеры. Я решил пропустить этот шаг ( docker exec -it superset superset load_examples ), чтобы в дальнейшем не удалять вручную предустановленные элементы. Вариант с разворачиваем сервиса из файла docker-compose.yml также попробовал. Список команд вы можете найти в официальном руководстве. Единственное замечание, я указал не последний релиз, а 1.5.0.
Далее нужно было настроить коннект к базе данных. Superset поддерживает возможность подключения к нескольким десяткам БД, но я выбрал PostgreSQL, как наиболее понятное для себя хранилище. На Хабр уже есть публикация (“Поднимаем Apache Superset — необходимый и достаточный гайд”), в которой описан пошаговый алгоритм, но там приводился пример, где PostgreSQL запускается в docker контейнере.
Мне же захотелось реализовать случай, когда БД установлена локально. Разумеется, когда на этапе настройки соединения я указал стандартные 127.0.0.1 и 5432 меня постигла неудача: порт был закрыт. Первая причина указана в документации (последние два абзаца), которую традиционно никто не читает. Вторая помеха кроется в первоначальных настройках самой PostgreSQL.
По умолчанию, PostgreSQL в целях безопасности принимает только локальные подключения. Чтобы разрешить подключения извне, нужно в файле postgresql.conf раскомментировать параметр и заменить localhost на звездочку: listen_addresses = ‘*’. Сам файл расположен по адресу /etc/postgresql/14/main/postgresql.conf.
Отредактировать его напрямую не получиться, поэтому нужно прибегнуть к услугам терминала (root, плюс редактор nano или vim). Второй файл, в который необходимо внести изменения это pg_hba.conf (/etc/postgresql/14/main/pg_hba.conf). Добавляем в самый конец страницы строку: host all all 172.17.0.0/16 trust. Вместо trust нужно использовать scram-sha-256, если доступ требуется по паролю.
Данный момент я также вычитал в Хабр публикации “Настройка PostgreSQL под Linux”. Работаем из терминала, с количеством пробелов между словами не ошибетесь, так как в файле будут образцы для заполнения. На финальном шаге перезагружаем БД командой в терминале: systemctl restart postgresql . В настройках сервера PostgreSQL через pgAdmin4 ничего менять не нужно. Теперь можно перейти в веб-интерфейс Superset и указать верные значения для хоста и порта: 172.17.0.1 и 5432. Название базы данных, логин и пароль указываете исходя из ваших настроек.
Так как адреса хостов отличаются в рекомендациях из Интернета, советую проверить значения для вашего конкретного случая до начала правки файлов. Для этого в терминале последовательно введите две команды: docker network ls (для получения списка запущенных сетей, ищем id bridge), далее docker network inspect id . Нас интересуют пункты: Subnet: 172.17.0.0/16 и Gateway: 172.17.0.1. Так как я не devops и не администратор БД, я не могу утверждать, что приведенные настройки адекватны с точки зрения безопасности. Поэтому не рекомендую использовать их без дополнительной консультации со специалистом на боевой БД! Все эксперименты только в тестовой среде и на демо БД.
Базовый алгоритм работы с Superset можно описать четырьмя шагами.
Шаг 1. Настроить коннект к БД (Databases).
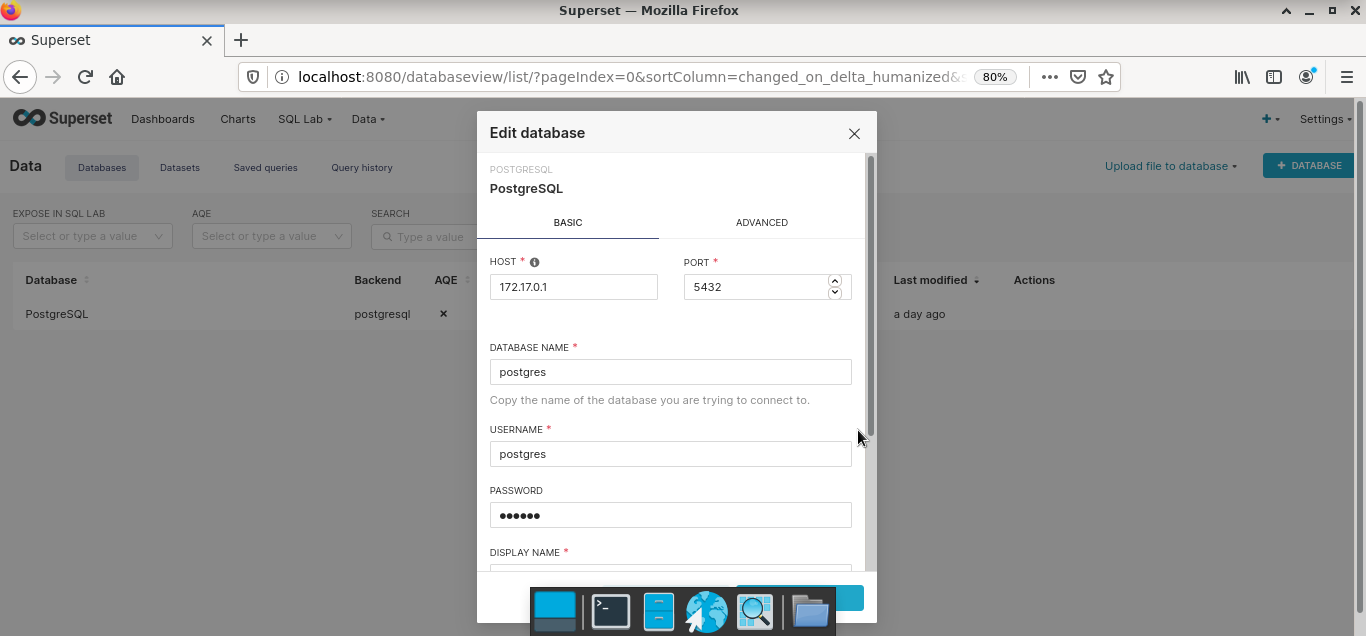
Шаг 2. Подключить физические таблицы / представления к “витринам” платформы (Datasets). Если требуется «вытащить» агрегированные данные, то можно написать запрос в разделе SQL Lab и сохранить результат как датасет.
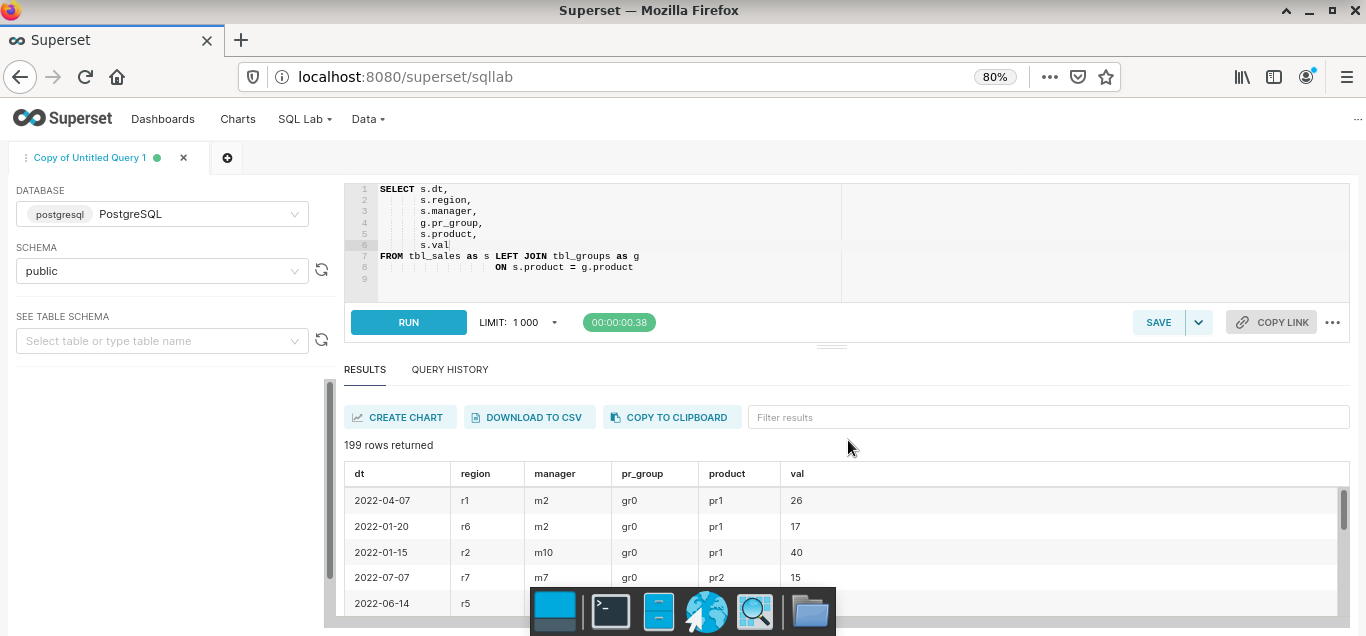
Для созданных датасетов можно рассчитывать базовые метрики.

Шаг 3. Сформировать в режиме виртуального конструктора на основе датасетов отдельные графики и диаграммы (Charts). Superset из коробки содержит большой набор типовых визуализаций. Возможно создавать кастомные решения. Насколько целесообразна данная затея – большой вопрос, так как я еще ни разу не видел, чтобы замысловатая диаграмма приводила к инсайту менеджера. А вот когда все было наоборот, такие случаи мне известны.

Шаг 4. Создать новую управленческую панель путем простого перетаскивания созданных элементов (Dashboards). По данному шагу у меня будут два замечания. Во-первых, на рисунке видно, что в отчете применены два типа фильтров. Вариант в левом углу, создается на этапе моделирования дашборда, он более современный и рекомендуется к использованию.
Элементы для фильтрации, включенные в тело самого дашборда, как отдельные элементы — устаревший подход, о чем вам будет сигнализировать всплывающее окно. Во-вторых, на части визуальных элементов присутствуют надписи на языке Шекспира. От части из них можно избавиться с помощью имеющихся настроек, вот удастся ли добиться 100%-ого перевода я не уверен. Лично мне в результате беглой рекогносцировки этого не удалось, но перфекционистам с хорошим знанием программирования эта задача будет по плечу.
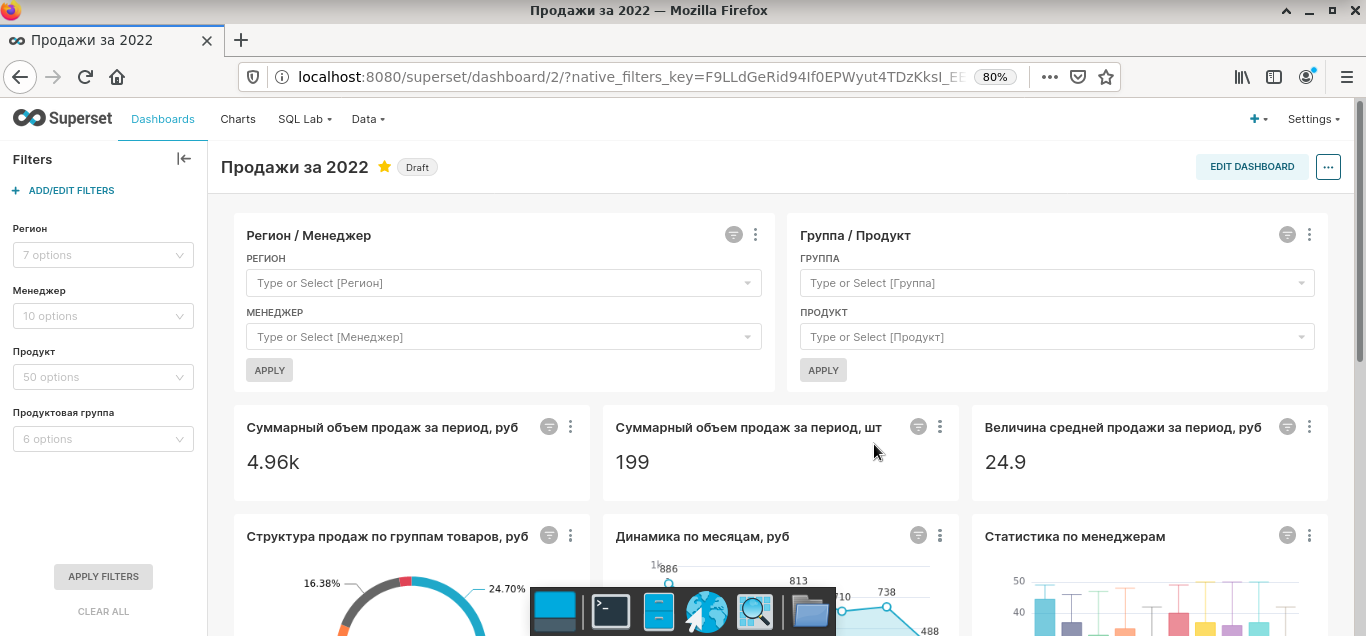
В целом интерфейс программы интуитивно понятен. Базовые возможности реализованы практически также, как и у аналогичных продуктов. Поэтому заострять внимание на них нет смысла. Если разобраться с функционалом программы, то дашборд, как на приведенном рисунке, можно собрать за считанные минуты.

Работать напрямую с файлами txt, csv, xlsx нельзя. Нужно предварительно загружать информацию в БД и только потом писать SQL запросы. Заливка информации возможна прямо из интерфейса, но нужно разрешить данную операцию в настройках БД. Инструментов для предварительной обработки сырых данных нет.
Поэтому быстрая ad hoc аналитика со сбором данных из разрозненных плохо структурированных файлов с помощью Superset крайне затруднена. Так как SQL, по сути, основной язык платформы, то и реализация сложных расчетов на стыке данных из разных датасетов будет также проблематична. Но функциональность языка можно расширить путем использования шаблонов Jinja в запросах.
Для старта работы с Superset от специалистов компании могут потребоваться следующие вещи.
Если Superset еще не установлен – нужны знания бэкенд-разработчика: умение работать с Docker; базовые команды терминала Linux; настройка Flask, Redis, Celery; выбор веб-сервера для платформы и т.д. Важно понимать, что данный BI инструмент это продукт с открытым исходным кодом. Это дает плацдарм для доработки под нужды бизнеса, но, с другой стороны, требует затрат времени на грамотную настройку компонентов системы и последующую утилизацию возможностей (как пример, возможность взаимодействия с артефактами Superset посредством Rest API).
Если продукт уже развернут, но подходящее DWH отсутствует — навыки дата инженера данных: создание Data Lake для сырых логов; ETL/ELT; умение выбрать, установить и настроить DWH (возможно колоночную базу данных, чтобы ускорить обработку запросов).
Если в DWH уже есть подготовленные витрины с актуальными данными — знание SQL хотя бы на среднем уровне, плюс экспресс-курс по возможностям BI решения.
Вместо выводов. Apache Superset – интересный продукт со своим характером. BI инструмент плохо подходит для срочной разработки дашбордов на основе разрозненных источников данных. Из-за нюансов платформы на этапе внедрения нетехническим компаниям обязательно потребуется помощь в установке и настройке. В организациях, где хорошо развита культура дата инжиниринга, Superset вполне может использоваться для создания несложной регламентированной отчетности.
На этом все. Всем здоровья, удачи и профессиональных успехов!
Источник: temofeev.ru
Apache Superset. Первый взгляд на BI инструмент
В последнее время изучая вакансии на сайтах по поиску работы, все чаще стал отмечать, что помимо платных инструментов BI от кандидатов требуется знание еще бесплатных платформ. Мой предыдущий опыт работы по построению графической отчетности был связан исключительно с коммерческими продуктами, поэтому я решил выделить время на ознакомление с альтернативными решениями.
Выбор Superset был случайным, так как я обратил внимание на него лишь потому, что он входит в экосистему Apache. Сразу хочу оговориться, что в данной заметке не будет сравнения Superset с платными инструментами. Такое сопоставление функционала просто некорректно из-за разных “весовых категорий”.
Также я не буду выделять плюсы и минусы решения по сравнению с бесплатными аналогами, так как это очень дискуссионный вопрос. Неизбежно найдутся адепты того или иного продукта, которые будут доказывать ошибочность моих суждений. Поэтому я построил публикацию в форме простого описания “нюансов”, которые я выделил для себя, начав знакомство с Superset. Читатели же сами смогут сделать свои выводы.
Тестирование Superset решил начать с полноценной установки программы на Linux (Debian). Несмотря на то, что я полностью выполнил список действий, описанный в документации, данный эксперимент завершился ошибкой. Попытка с запуском docker образа удалась с первого раза, список команд на Docker Hub.
Как и в случае с Apache Airflow на этапе развертывания системы разработчики предлагают загрузить демонстрационные примеры. Я решил пропустить этот шаг ( docker exec -it superset superset load_examples ), чтобы в дальнейшем не удалять вручную предустановленные элементы. Вариант с разворачиваем сервиса из файла docker-compose.yml также попробовал. Список команд вы можете найти в официальном руководстве. Единственное замечание, я указал не последний релиз, а 1.5.0.
Далее нужно было настроить коннект к базе данных. Superset поддерживает возможность подключения к нескольким десяткам БД, но я выбрал PostgreSQL, как наиболее понятное для себя хранилище. На Хабр уже есть публикация (“Поднимаем Apache Superset — необходимый и достаточный гайд”), в которой описан пошаговый алгоритм, но там приводился пример, где PostgreSQL запускается в docker контейнере.
Мне же захотелось реализовать случай, когда БД установлена локально. Разумеется, когда на этапе настройки соединения я указал стандартные 127.0.0.1 и 5432 меня постигла неудача: порт был закрыт. Первая причина указана в документации (последние два абзаца), которую традиционно никто не читает. Вторая помеха кроется в первоначальных настройках самой PostgreSQL.
По умолчанию, PostgreSQL в целях безопасности принимает только локальные подключения. Чтобы разрешить подключения извне, нужно в файле postgresql.conf раскомментировать параметр и заменить localhost на звездочку: listen_addresses = ‘*’. Сам файл расположен по адресу /etc/postgresql/14/main/postgresql.conf.
Отредактировать его напрямую не получиться, поэтому нужно прибегнуть к услугам терминала (root, плюс редактор nano или vim). Второй файл, в который необходимо внести изменения это pg_hba.conf (/etc/postgresql/14/main/pg_hba.conf). Добавляем в самый конец страницы строку: host all all 172.17.0.0/16 trust. Вместо trust нужно использовать scram-sha-256, если доступ требуется по паролю.
Данный момент я также вычитал в Хабр публикации “Настройка PostgreSQL под Linux”. Работаем из терминала, с количеством пробелов между словами не ошибетесь, так как в файле будут образцы для заполнения. На финальном шаге перезагружаем БД командой в терминале: systemctl restart postgresql . В настройках сервера PostgreSQL через pgAdmin4 ничего менять не нужно. Теперь можно перейти в веб-интерфейс Superset и указать верные значения для хоста и порта: 172.17.0.1 и 5432. Название базы данных, логин и пароль указываете исходя из ваших настроек.
Так как адреса хостов отличаются в рекомендациях из Интернета, советую проверить значения для вашего конкретного случая до начала правки файлов. Для этого в терминале последовательно введите две команды: docker network ls (для получения списка запущенных сетей, ищем id bridge), далее docker network inspect id . Нас интересуют пункты: Subnet: 172.17.0.0/16 и Gateway: 172.17.0.1. Так как я не devops и не администратор БД, я не могу утверждать, что приведенные настройки адекватны с точки зрения безопасности. Поэтому не рекомендую использовать их без дополнительной консультации со специалистом на боевой БД! Все эксперименты только в тестовой среде и на демо БД.
Базовый алгоритм работы с Superset можно описать четырьмя шагами.
Шаг 1. Настроить коннект к БД (Databases).

Шаг 2. Подключить физические таблицы / представления к “витринам” платформы (Datasets). Если требуется «вытащить» агрегированные данные, то можно написать запрос в разделе SQL Lab и сохранить результат как датасет.
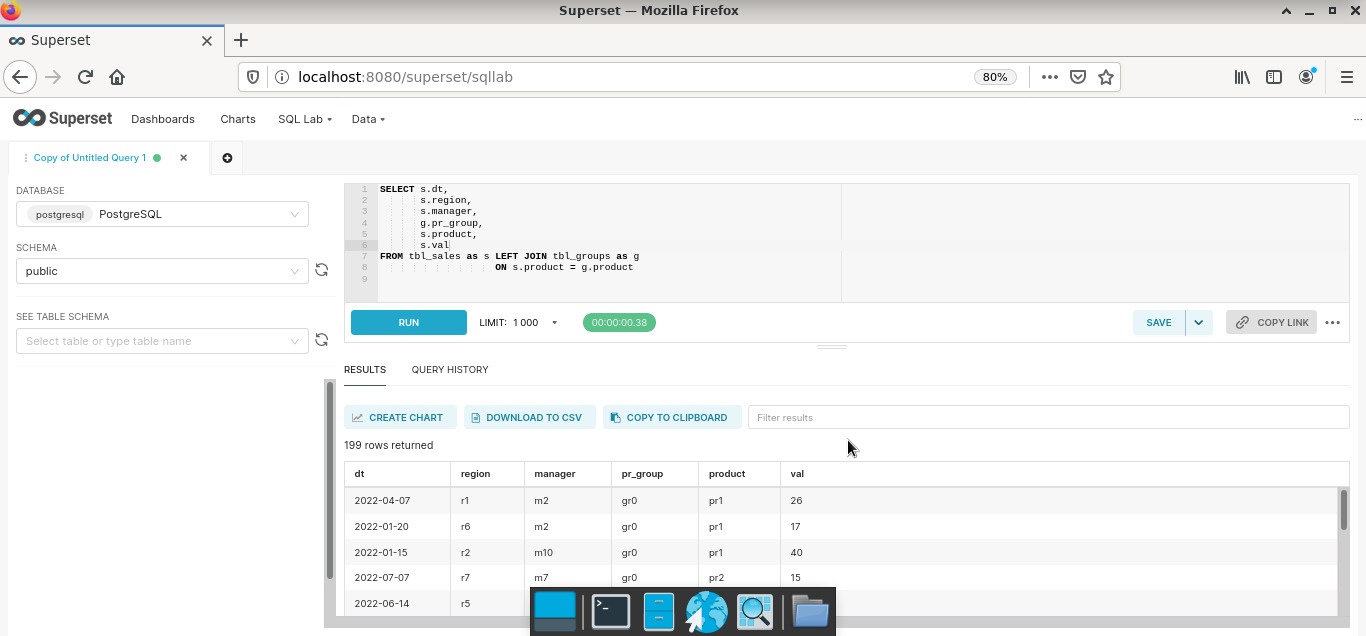
Для созданных датасетов можно рассчитывать базовые метрики.
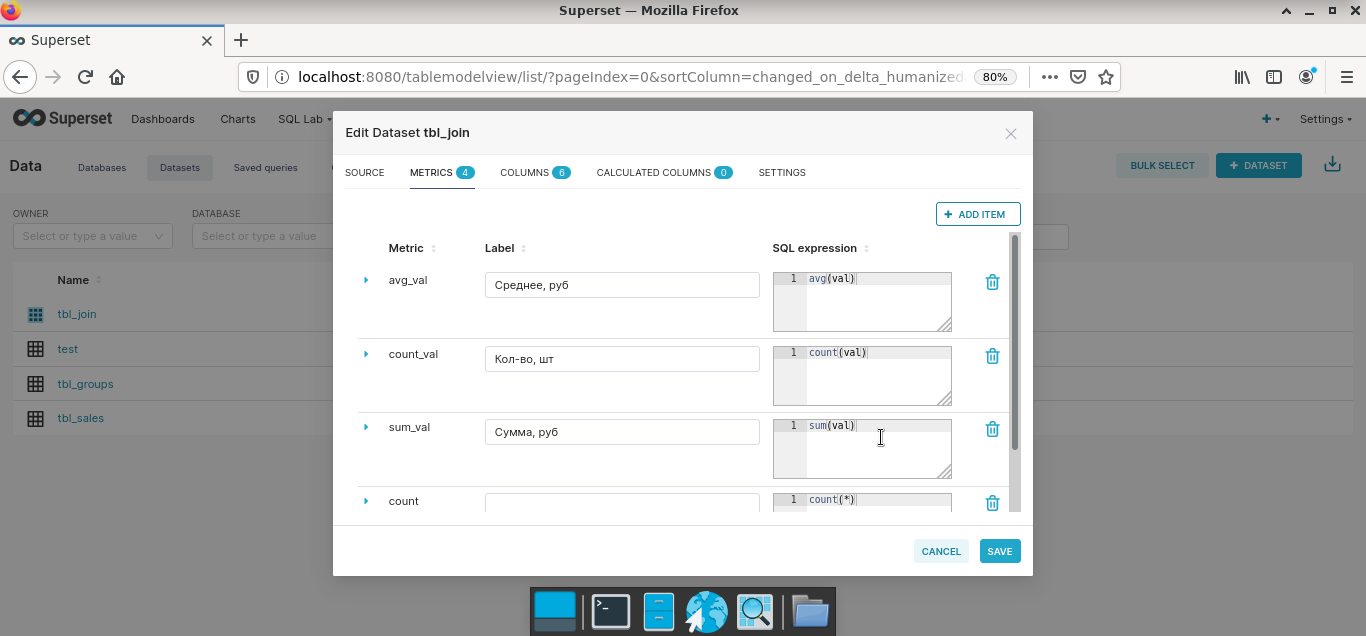
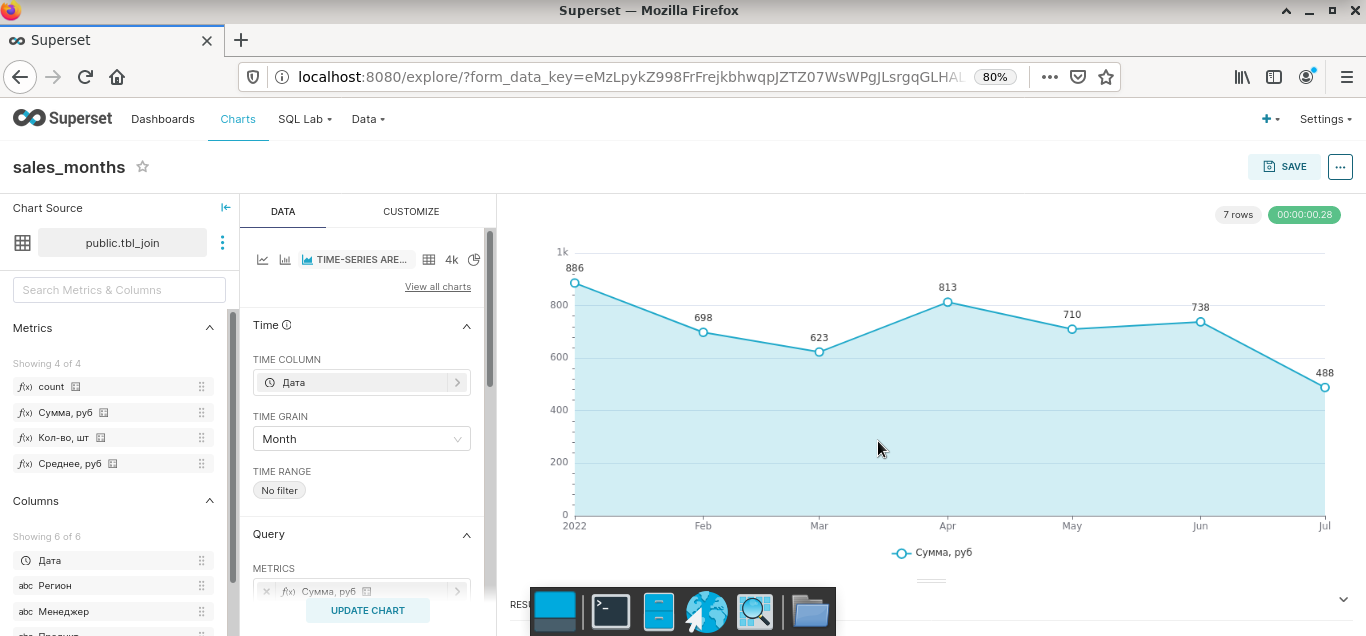
Шаг 3. Сформировать в режиме виртуального конструктора на основе датасетов отдельные графики и диаграммы (Charts). Superset из коробки содержит большой набор типовых визуализаций. Возможно создавать кастомные решения. Насколько целесообразна данная затея – большой вопрос, так как я еще ни разу не видел, чтобы замысловатая диаграмма приводила к инсайту менеджера. А вот когда все было наоборот, такие случаи мне известны.
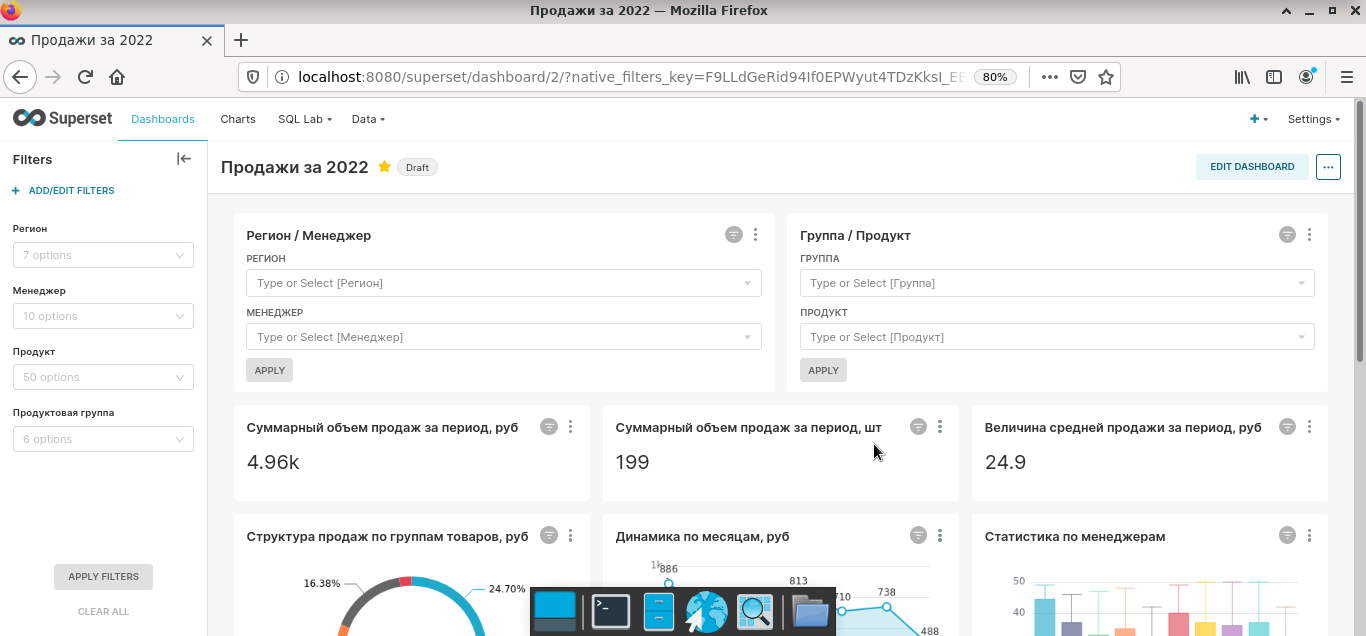
Шаг 4. Создать новую управленческую панель путем простого перетаскивания созданных элементов (Dashboards). По данному шагу у меня будут два замечания. Во-первых, на рисунке видно, что в отчете применены два типа фильтров. Вариант в левом углу, создается на этапе моделирования дашборда, он более современный и рекомендуется к использованию.
Элементы для фильтрации, включенные в тело самого дашборда, как отдельные элементы — устаревший подход, о чем вам будет сигнализировать всплывающее окно. Во-вторых, на части визуальных элементов присутствуют надписи на языке Шекспира. От части из них можно избавиться с помощью имеющихся настроек, вот удастся ли добиться 100%-ого перевода я не уверен. Лично мне в результате беглой рекогносцировки этого не удалось, но перфекционистам с хорошим знанием программирования эта задача будет по плечу.
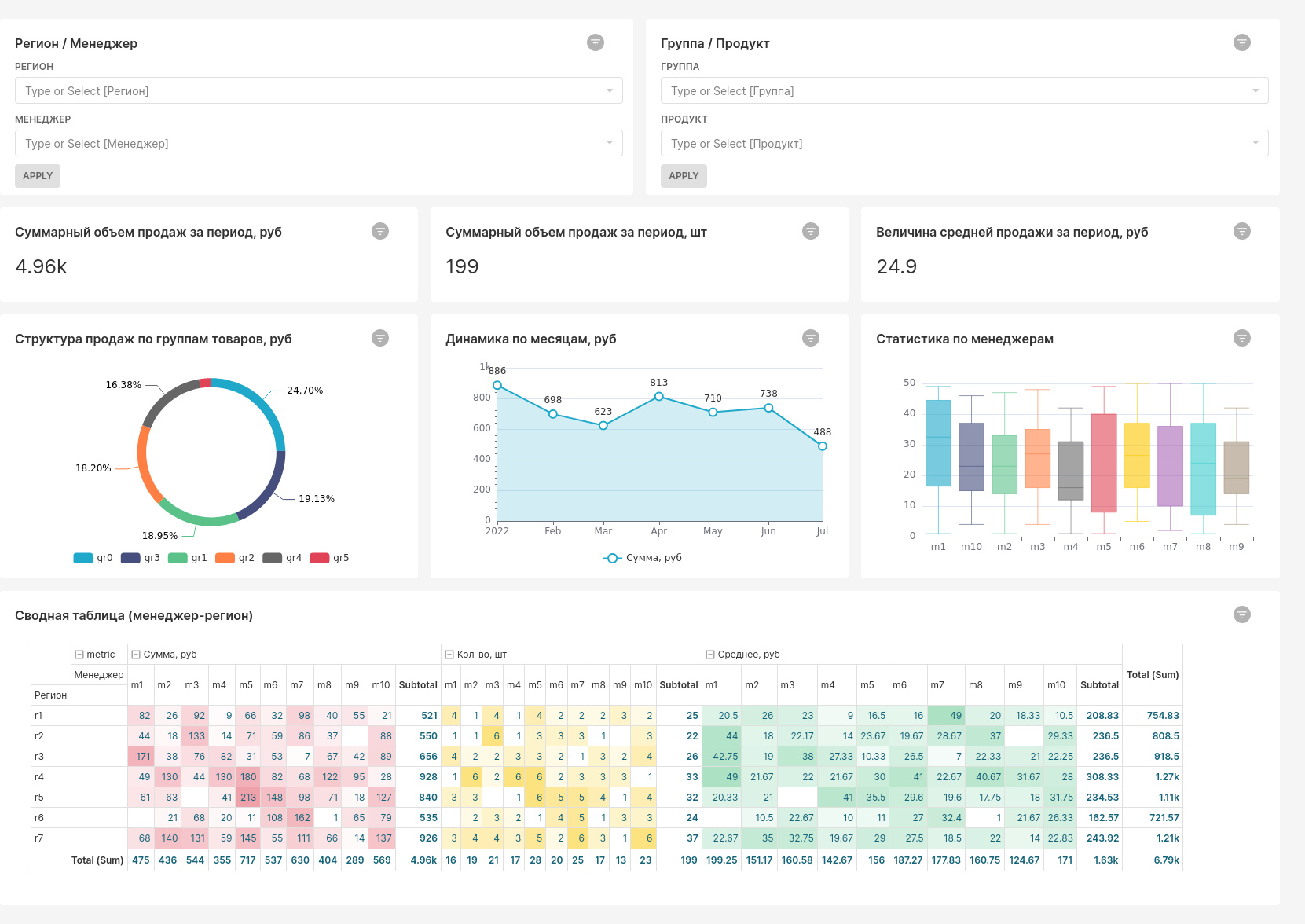
В целом интерфейс программы интуитивно понятен. Базовые возможности реализованы практически также, как и у аналогичных продуктов. Поэтому заострять внимание на них нет смысла. Если разобраться с функционалом программы, то дашборд, как на приведенном рисунке, можно собрать за считанные минуты.
Работать напрямую с файлами txt, csv, xlsx нельзя. Нужно предварительно загружать информацию в БД и только потом писать SQL запросы. Заливка информации возможна прямо из интерфейса, но нужно разрешить данную операцию в настройках БД. Инструментов для предварительной обработки сырых данных нет.
Поэтому быстрая ad hoc аналитика со сбором данных из разрозненных плохо структурированных файлов с помощью Superset крайне затруднена. Так как SQL, по сути, основной язык платформы, то и реализация сложных расчетов на стыке данных из разных датасетов будет также проблематична. Но функциональность языка можно расширить путем использования шаблонов Jinja в запросах.
Для старта работы с Superset от специалистов компании могут потребоваться следующие вещи.
Если Superset еще не установлен – нужны знания бэкенд-разработчика: умение работать с Docker; базовые команды терминала Linux; настройка Flask, Redis, Celery; выбор веб-сервера для платформы и т.д. Важно понимать, что данный BI инструмент это продукт с открытым исходным кодом. Это дает плацдарм для доработки под нужды бизнеса, но, с другой стороны, требует затрат времени на грамотную настройку компонентов системы и последующую утилизацию возможностей (как пример, возможность взаимодействия с артефактами Superset посредством Rest API).
Если продукт уже развернут, но подходящее DWH отсутствует — навыки дата инженера данных: создание Data Lake для сырых логов; ETL/ELT; умение выбрать, установить и настроить DWH (возможно колоночную базу данных, чтобы ускорить обработку запросов).
Если в DWH уже есть подготовленные витрины с актуальными данными — знание SQL хотя бы на среднем уровне, плюс экспресс-курс по возможностям BI решения.
Вместо выводов. Apache Superset – интересный продукт со своим характером. BI инструмент плохо подходит для срочной разработки дашбордов на основе разрозненных источников данных. Из-за нюансов платформы на этапе внедрения нетехническим компаниям обязательно потребуется помощь в установке и настройке. В организациях, где хорошо развита культура дата инжиниринга, Superset вполне может использоваться для создания несложной регламентированной отчетности.
На этом все. Всем здоровья, удачи и профессиональных успехов!
P.S. Поступил интересный вопрос, косвенно связанный с основной темой: “Если настраивать коннект между локальной БД PostgreSQL и Redash (контейнер Docker), то применим ли приведенный в публикации алгоритм действий?” Ответ: “Последовательность действий при настройке БД будет аналогичной, за исключением двух параметров. В файле /etc/postgresql/14/main/pg_hba.conf указываем 172.18.0.0/16, а в окне настройки подключения к PostgreSQL в среде Redash — 172.18.0.1. Объясняется это тем, что при развертывании сервиса BI из файла docker-compose.yml (официальный репозиторий для загрузки всех необходимых компонентов) создается отдельный bridge.”
P.S.S. Еще один вопрос по теме: «Как настроить подключение локальной ClickHouse и Apache Superset (контейнер Docker)?». После установки ClickHouse согласно инструкции (официальная документация), необходимо создать новую БД, провести настройку прав доступа для нового пользователя, а также настройку сетевого доступа. Данные шаги описаны в публикации «Установка и настройка ClickHouse на Ubuntu». Здесь же я приведу два ключевых момента.
Для настройки прав доступа на созданную базу данных test_db в папке /etc/clickhouse-server/users.d создаем файл new_user.xml c описанием прав доступа.
nopswd ::/0 default default test_db
По умолчанию ClickHouse слушает только 127.0.0.1. Чтобы настроить сетевой доступ к серверу, в папке /etc/clickhouse-server/config.d создаем конфигурационный файл listen.xml.
Далее перезапускаем сервер командой sudo systemctl restart clickhouse-server и проверяем порты sudo ss -tulpn | grep clickhouse. Повторю момент, на котором уже заострял внимание в начале данной статьи, все манипуляции с портами БД нужно проверять на адекватность информационной безопасности!
- apache superset
- dashboard
- data analysis
- postgresql
- визуализация данных
- Apache
- Визуализация данных
Источник: habr.com