
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
hse-oimp.github.io / lectures / lecture6.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Cannot retrieve contributors at this time
102 lines (72 sloc) 4.85 KB
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Copy raw contents
Copy raw contents
Лекция №6 Работа с памятью
На стеке сохраняются все локальные переменные, аргументы функций и возвращаемые значения. Размер стека по дефолту достаточно мал, и основное предназначение стека — хранение небольших локальных объектов. Структура стека зависит от реализации. Из-за того, что размер стека ограничен, невозможно получить бесконечную рекурсию, так как каждый вызов занимает сколько-то памяти.
Уроки С++ Стек, Куча, Указатели (11)
В статической памяти хранятся только глобальные и статические переменные, и как следствие её размер известен во время компиляции. Глобальные переменные инициализируются при запуске программы, а статические — когда впервые выполняется строчка в которой они обьявлены. И локальные и статические переменные будут удалены когда программа завершится. Если перед глобальной переменной написать static , то она будет видна только в рамках текущей единицы трансляции. Единица трансляции — весь файл + его инклюды.
//current.cpp #include «other.h» static int GLOBAL_VARIABLE1 = 0; // Видна в current.cpp и в other.cpp int GLOBAL_VARIABLE2 = 0; //Видна везде
Однако, если мы захотим воспользоваться GLOBAL_VARIABLE2 в другой единице трансляции нам надо будет явно указать компилятору, что эта переменная из другой единицы трансляции.
//yet_another_file.cpp extern int GLOBAL_VARIABLE2 = 0; //.
Глобальные константы автоматически становятся статическими.
static const int CONSTANT = 0; //Эквивалентно const int CONSTANT = 0; //Если нужно сделать константу доступной в других единицах трансляции extern const int CONSTANT = 0;
Куча или Динамическая память
Временем жизни объектов на куче мы управляем сами. Чтобы создать объект в динамической памяти нужно использовать ключевое слово new :
int* int_ptr = new int; //вызовет конструктор std::vectorint>* vec1 = new std::vectorint>; std::vectorint>* vec2 = new std::vectorint>(100);
Чтобы удалить объект в динамической памяти нужно использовать ключевое слово delete :
delete int_ptr; delete vec1; delete vec2;
Чтобы выделить или удалить массив в динамической памяти нужно использовать специальные версии new и delete :
int* array_ptr = new int[100]; //100 — кол-во элементов delete[] array_ptr;
На куче можно аллоцировать большие объекты:
int* array_ptr = new int[static_castsize_t>(std::numeric_limitsint>::max()) * 3];
Если запросить слишком много памяти, new кинет исключение:
C# Стек и Куча | Stack and Heap | Часть 1
uint8_t* too_much = new uint8_t[60 * 1024 * 1024 /*= 60GiB*/]; //throws std::bad_alloc
Можно явно запретить new бросать исключения, тогда он вернёт nullptr :
uint8_t* too_much = new(std::nothrow) uint8_t[60 * 1024 * 1024 /*= 60GiB*/]; assert(too_much == nullptr);
Лучше использовать new и delete чем malloc и free , так как new и delete вызывают конструктор и деструктор соответственно.
Немного про устройство std::vector
Класс std::vector хранит внутри себя указатель на начало аллоцированного массива, size и capacity . std::vector сам внутри себя вызывает new и delete , соответственно размер самого вектора очень мал — всего 3 указателя, а все элементы аллоцируются на куче.
Источник: github.com
11.8 – Стек и куча
Память, которую использует программа, обычно делится на несколько разных областей, называемых сегментами:
- Сегмент кода (также называемый текстовым сегментом), в котором скомпилированная программа находится в памяти. Сегмент кода обычно доступен только для чтения.
- Сегмент bss («block started by symbol», также называемый сегментом неинициализированных данных), где хранятся глобальные и статические переменные с нулевой инициализацией.
- Сегмент данных (также называемый сегментом инициализированных данных), где хранятся инициализированные глобальные и статические переменные.
- Куча, где размещаются динамически размещаемые переменные.
- Стек вызовов, в котором хранятся параметры функций, локальные переменные и другая информация, относящаяся к функциям.
В этом уроке мы сосредоточимся в первую очередь на куче и стеке, так как именно там происходит большинство интересных вещей.
Сегмент кучи
Сегмент кучи (также известный как «free store», «свободное хранилище») отслеживает память, используемую для динамического распределения памяти. Мы уже говорили немного о куче в уроке «10.13 – Динамическое распределение памяти с помощью new и delete », поэтому это будет резюме.
В C++, когда вы используете оператор new для выделения памяти, эта память выделяется в сегменте кучи приложения.
int *ptr = new int; // ptr присваивается 4 байта в куче int *array = new int[10]; // array присвоено 40 байт в куче
Адрес этой памяти возвращается оператором new и затем может быть сохранен в указателе. Вам не нужно беспокоиться о механизме того, где расположена свободная память, и как она выделяется пользователю. Однако стоит знать, что последовательные запросы памяти могут не привести к выделению последовательных адресов памяти!
int *ptr1 = new int; int *ptr2 = new int; // ptr1 и ptr2 могут не содержать соседних адресов
Когда динамически размещаемая переменная удаляется, память «возвращается» в кучу и затем может быть переназначена по мере получения будущих запросов на выделение. Помните, что удаление указателя не удаляет переменную, а просто возвращает память по соответствующему адресу обратно операционной системе.
У кучи есть достоинства и недостатки:
- Выделение памяти в куче происходит сравнительно медленно.
- Выделенная память остается выделенной до тех пор, пока она не будет специально освобождена (остерегайтесь утечек памяти) или пока приложение не завершит работу (после чего ОС должна ее очистить).
- Доступ к динамически выделяемой памяти должен осуществляться через указатель. Разыменование указателя происходит медленнее, чем прямой доступ к переменной.
- Поскольку куча – это большой пул памяти, здесь могут быть размещены большие массивы, структуры или классы.
Стек вызовов
Стек вызовов (обычно называемый «стеком») играет гораздо более интересную роль. Стек вызовов отслеживает все активные функции (те, которые были вызваны, но еще не завершились) от начала программы до текущей точки выполнения и обрабатывает размещение всех параметров функций и локальных переменных.
Стек вызовов реализован в виде структуры данных стек. Итак, прежде чем мы сможем говорить о том, как работает стек вызовов, нам нужно понять, что такое структура данных стек.
Структура данных стек
Структура данных – это программный механизм для организации данных таким образом, чтобы их можно было эффективно использовать. Вы уже видели несколько типов структур данных, таких как массивы и структуры. Обе эти структуры данных предоставляют механизмы для хранения данных и эффективного доступа к ним. Существует множество дополнительных, обычно используемых в программировании структур данных, многие из которых реализованы в стандартной библиотеке, и стек является одной из них.
Представьте себе стопку тарелок в кафетерии. Поскольку каждая тарелка тяжелая и они сложены друг на друга, вы можете сделать только одно из трех:
- посмотреть на поверхность верхней тарелки;
- снять верхнюю тарелку со стопки (открывая нижнюю, если она есть);
- поместить новую тарелку на верх стопки (скрывая нижнюю, если она есть).
В компьютерном программировании стек – это структура контейнера данных, который содержит несколько переменных (как массив). Однако в то время как массив позволяет вам получать доступ к элементам и изменять их в любом порядке (так называемый произвольный доступ), стек более ограничен. Операции, которые могут быть выполнены со стеком, соответствуют трем вещам, упомянутым выше:
- посмотреть верхний элемент в стеке (обычно это делается с помощью функции top() , но иногда называется peek() );
- снять верхний элемент из стека (выполняется с помощью функции pop() );
- поместить новый элемент на верх стека (выполняется с помощью функции push() ).
Стек – это структура типа «последним пришел – первым ушел» (LIFO, «last-in, first-out»). Последний элемент, помещенный в стек, будет первым извлеченным элементом. Если вы положите новую тарелку поверх стопки, первая тарелка, удаленная из стопки, будет тарелкой, которую вы только что положили последней. Последней положена, первой снята. По мере того, как элементы помещаются в стек, стек становится больше – по мере того, как элементы извлекаются, стек становится меньше.
Например, вот короткая последовательность, показывающая, как работает стек при вставке (push) и извлечении (pop) данных:
Стек: пустой Вставка 1 Стек: 1 Вставка 2 Стек: 1 2 Вставка 3 Стек: 1 2 3 Извлечение Стек: 1 2 Извлечение Стек: 1
Аналогия с тарелками – довольно хорошая аналогия того, как работает стек вызовов, но мы можем провести лучшую аналогию. Представьте себе группу почтовых ящиков, сложенных друг на друга.
Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается к почтовому ящику под ним, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, как мы можем добиться поведения, подобного стеку?
Во-первых, мы используем маркер (например, наклейку), чтобы отслеживать, где находится самый нижний пустой почтовый ящик. Вначале это будет самый нижний почтовый ящик (внизу стопки). Когда мы помещаем элемент в наш стек почтовых ящиков, мы помещаем его в отмеченный почтовый ящик (который является первым пустым почтовым ящиком) и перемещаем маркер на один ящик вверх.
Когда мы извлекаем элемент из стека, мы перемещаем маркер на один почтовый ящик вниз так, чтобы он указывал на верхний непустой почтовый ящик, и удаляем элемент из этого почтового ящика. Всё, что ниже маркера, считается «в стеке». Всё, что находится на уровне маркера или над ним, – не в стеке.
Сегмент стека вызовов
Сегмент стека вызовов содержит память, используемую для стека вызовов. Когда приложение запускается, операционная система помещает в стек вызовов функцию main() . Затем программа начинает выполняться.
Когда встречается вызов функции, эта функция помещается в стек вызовов. Когда текущая функция завершается, эта функция удаляется из стека вызовов. Таким образом, глядя на функции, помещенные в стек вызовов, мы можем увидеть все функции, которые были вызваны для перехода к текущей точке выполнения.
Приведенная выше аналогия с почтовыми ящиками в значительной степени похожа на то, как работает стек вызовов. Сам стек представляет собой блок адресов памяти фиксированного размера. Почтовые ящики – это адреса памяти, а «элементы», которые мы помещаем в стек, называются кадрами (фреймами) стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции.
Мы поговорим о стековых кадрах чуть позже. «Маркер» – это регистр (небольшой фрагмент памяти в CPU), известный как указатель стека (иногда сокращенно «SP», «stack pointer»). Указатель стека отслеживает текущее положение вершины стека вызовов.
Как устроена память
Разбираем как устроена память на примере простой модели. Знакомимся с понятиями «стек» и «куча».
Время чтения: 9 мин
Открыть/закрыть навигацию по статье
- Зачем мне понимать модели памяти?
- Древние модели памяти
- Модели памяти. Чуть ближе к реальности
- Кто и как использует память
- Что происходит со стеком
- Зачем нужна куча?
- Упражнение, упражнение!
- На собеседовании
- Вспомните, как устроена память, и попробуйте ответить на вопросы:
Обновлено 28 апреля 2023
Зачем мне понимать модели памяти?
Скопировать ссылку «Зачем мне понимать модели памяти?» Скопировано
При изучении нового языка программирования, вы быстро напишите свой первый Hello , world! и начнёте использовать переменные.
Так происходит, например, когда учите JavaScript. А вот если изучаете Haskell, «Hello, world!» станет для вас наградой после прочтения первой половины книги И «переменные» окажутся «постоянными».
Но что действительно происходит при создании или присваивании переменных и как выполняются функции? Во всех этих процессах участвует память. Если вы примерно поймёте как она устроена, будет значительно проще использовать инструменты разработчика и легче ответить на вопросы, связанные с памятью.
Древние модели памяти
Скопировать ссылку «Древние модели памяти» Скопировано
В давние времена, когда компьютеры только изобретали, было предложено две модели их устройства:
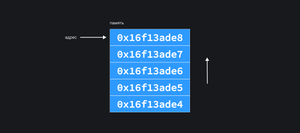
Эти архитектуры во многом схожи: Процессор выполняет различные операции с данными. Какую именно операцию выполнить определяет инструкция. Инструкции и данные поступают к процессору из памяти. Память разделена на ячейки, каждая ячейка заботливо пронумерована. Номер ячейки называется адресом в памяти. Адрес — величина фиксированной длинны.
Процессор может обращаться к любой ячейке, не обязательно делать это по порядку. Если данные не влезают в одну ячейку, их можно разместить в нескольких.
Основное отличие между этими моделями заключается в том, как именно хранятся инструкции и данные. В Гарвардской модели данные и инструкции разделены, а в архитектуре Фон Неймана они помещаются в одно хранилище. Это значит, что процессор, который использует данные и инструкции, будет доставать их одинаковым способом — с помощью одной шины. Используйте архитектуру Фон Неймана как ментальную модель, чтобы представить себе, что происходит в памяти, когда запускается программа.
На самом деле в ваших компьютерах используется гибрид двух архитектур. Например, в ближайших к процессору кешах, данные и инструкции разделены.
Количество возможных адресов памяти определяется длиной адреса. Длина зависит от архитектуры процессора. Например, 64-битный адрес позволяет обратиться к 18 446 744 073 709 552 000 ячейкам памяти. Это примерно 18 эксабайт
Модели памяти. Чуть ближе к реальности
Скопировать ссылку «Модели памяти. Чуть ближе к реальности» Скопировано
Модель выше хорошо подходит для рассуждений о работе программы. В реальности всё немного сложнее. Адреса, на которые смотрели в предыдущем разделе, — виртуальные. Чтобы обратиться к реальному адресу, вашему процессору нужно превратить виртуальный адрес в физический адрес ячейки оперативной памяти.
Когда процессу требуется память, операционная системы выдаёт процессу блок памяти, называемый страницей (page). Обычно размер страницы относительно небольшой — 4–8 Кб. Процессу можно выдавать много страничек. Эти страницы — виртуальные кусочки памяти, которые как-то отображаются на физическую память.
Кто и как использует память
Скопировать ссылку «Кто и как использует память» Скопировано
Операционная система запускает программу в рамках определённого процесса. Для этого процесса выделяются ресурсы и адресное пространство – то, какие адреса памяти может использовать данный процесс. Операционная система гарантирует, что один процесс не будет иметь доступа к памяти другого процесса, если другой процесс этого не разрешит.
В рамках процесса может существовать один или несколько потоков. Для каждого потока выделяется кусочек памяти.
Помните, что это модель. В реальности кто и как запускает поток зависит от того, на чём и для чего пишите программу. Посмотрите, например, на POSIX Threads.
В этот кусочек памяти загружается код программы, глобальные переменные и ещё кое-что. В этом же кусочке памяти выделяются две важные области: стек (stack) и куча (heap). Стек — это область памяти, которую очень легко выделять.
Чтобы выделить или удалить память на стеке, нужно просто переместить специальный указатель — stack pointer (указатель стека). Значение текущего указателя хранится в специальном регистре процессора, что означает что выделять и удалить память на стеке можно очень быстро. Этот указатель всегда указывает следующую свободную ячейку памяти стека.
Данные на стеке можно читать. Данные нужно «положить» на стек, чтобы их записать. Вы не можете записать данные в произвольную область стека, только в конец. Также не можете удалить данные из произвольной области стека, однако возможно перемотать указатель стека. Это равносильно удалению всех данных.
Программа в процессе выполнения активно работает со стеком. Память для стека может закончиться, тогда возникнет всем известное переполнение стека (stack overflow).
Очень популярная и известная картинка, которая объясняет всё:
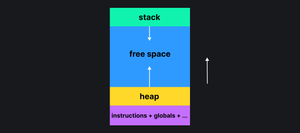
Стек и куча растут навстречу друг другу
Что происходит со стеком
Скопировать ссылку «Что происходит со стеком» Скопировано
Давайте посмотрим на функцию подсчёта собачек count Dogs ( ) . Она принимает один аргумент — happy Dogs , создаёт внутри переменную sad Coefficient и как-то считает количество собачек.
function countDogs(happyDogs) const sadCoefficient = 0.1; return happyDogs + sadCoefficient * happyDogs;> function countDogs(happyDogs) const sadCoefficient = 0.1; return happyDogs + sadCoefficient * happyDogs; > Скопировать Скопировано Не удалось скопировать
Чтобы выполнить эту функцию, нужно положить аргументы функции и локальные переменные на стек.
Кроме этого нужно понимать какой код выполнить после того, как функция завершится. Для этого на стеке создаётся stack_frame. В нём хранятся аргументы и локальные переменные. После того как функция выполнится, стек фрейм удаляется вместе со всем аргументами и переменными функции. При создании стек фрейма используется ещё одна полезная штука – указатель на фрейм (frame pointer).
Этот указатель всегда указывает на активный фрейм на стеке.
Давайте посмотрим что произойдёт, если захотим посчитать собачек в консоли.
function logDogs() console.log(countDogs(20), countDogs(9));> logDogs(); function logDogs() console.log(countDogs(20), countDogs(9)); > logDogs(); Скопировать Скопировано Не удалось скопировать
- На стеке создастся фрейм для функции log Dogs ( ) .
- Потом добавится фрейм для первого вызова count Dogs ( 20 ) .
- После выполнения функции count Dogs ( 20 ) фрейм удаляется.
- Потом добавится фрейм для второго вызова count Dogs ( 9 ) .
- После выполнения функции count Dogs ( 9 ) фрейм удаляется.
- После выполнения функции log Dogs ( ) фрейм удаляется.
Фрейм для функции count Dogs ( ) будет содержать аргумент функции (20) и локальную переменную ( sad Coefficient ).
Вы же всё ещё помните, что это модель? JavaScript слабо типизированный язык. Если это учитывать, наша ментальная модель сломается. Чтобы выделить на стеке память под аргументы и локальные переменные, нужно знать сколько памяти выделять. Так как мы не знаем тип переменной, не понятно, сколько памяти под неё нужно выделить.
Компилятор JavaScript делает некоторые предположения о типах переменных и на их основе выделяет память на стеке. Эти предположения могут оказаться ошибочными, но это уже совсем другая история.
Если в процессе выполнения функции код выбросит ошибку, то произойдёт разматывание стека (stack unwinding). Вы увидите в консоли знакомый stack trace.

Давайте модифицируем функцию count Dogs ( ) и заставим её выкинуть ошибку.
function countDogs(happyDogs) const sadCoefficient = 0.1; if (happyDogs < 10) throw new Error(‘Сликшом мало весёлых собачек!’); > return happyDogs + sadCoefficient * happyDogs;> function countDogs(happyDogs) const sadCoefficient = 0.1; if (happyDogs 10) throw new Error(‘Сликшом мало весёлых собачек!’); > return happyDogs + sadCoefficient * happyDogs; > Скопировать Скопировано Не удалось скопировать
Получим следующий результат, когда запустим код из этого примера в консоли браузера:
Uncaught Error: Сликшом мало весёлых собачек! at countDogs (:4:11) <— вот фрейм count dogs at logDogs (:2:30) <— вот фрейм logDogs at :1:1
Увидим при разматывании стека, что сначала будет удалён фрейм count Dogs ( ) , а потом log Dogs ( ) . После этого выполнение кода прекратится.
Зачем нужна куча?
Скопировать ссылку «Зачем нужна куча?» Скопировано
Данные на стеке хранятся не долго. Когда функция завершает своё выполнение, то все данные удаляются. Кроме этого вы не можете положить на стек данные произвольного размера.
Рассмотрим функцию работы с массивом create Dog Array ( ) .
function createDogArray() const dogs = [», », »]; // 3 элемента if (Math.random() > 0.5) dogs.push(»); // а может и 4 элемента 🙂 >> function createDogArray() const dogs = [», », »]; // 3 элемента if (Math.random() > 0.5) dogs.push(»); // а может и 4 элемента 🙂 > > Скопировать Скопировано Не удалось скопировать