
В этом разделе будет рассмотрен процесс анализа и проиллюстрировано его использование в некоторых языках форматирования текста. Детальнее об этом будет говориться в главах 2-4 и 6. При компиляции анализ состоит из трех фаз.
Линейный анализ, при котором поток символов исходной программы считывается слева направо и группируется в токены (token), представляющие собой последовательности символов с определенным совокупным значением.
- Иерархический анализ, при котором символы или токены иерархически группируются во вложенные конструкции с совокупным значением.
- Семантический анализ, позволяющий проверить, насколько корректно совместное размещение компонентов программы.
Лексический анализ В компиляторах линейный анализ называется лексическим, или сканированием. Например, при лексическом анализе символы в инструкции присвоения position := initial + rate * 60 будут сгруппированы в следующие токены.
- Идентификатор position.
- Символ присвоения : =.
- Идентификатор initial.
- Знак сложения.
- Идентификатор rate.
- Знак умножения.
- Число 60.
Пробелы, разделяющие символы этих токенов, при лексическом анализе обычно отбрасываются. Синтаксический анализ Иерархический анализ называется разбором (parsing), или синтаксическим анализом, который включает группирование токенов исходной программы в грамматические фразы, используемые компилятором для синтеза вывода. Обычно грамматические фразы исходной программы представляются в виде дерева, пример которого показан на рис. 1.4. В выражении initial+rate*60 фраза rate*60 является логической единицей, поскольку обычные соглашения о приоритете арифметических операций гласят, что умножение выполняется до сложения. Поскольку после выражения initial+rate следует знак умножения *, само по себе оно не группируется в единую фразу на рис. 1.4. Иерархическая структура программы обычно выражается рекурсивными правилами. Например, при определении выражений можно придерживаться следующих правил.
- Любой идентификатор (identifier) есть выражение (expression).
- Любое число (number) есть выражение (expression).
- Если expression1 и expression2 являются выражениями, то выражениями являются и expression1 + expression2
expression1* expression2(expression1).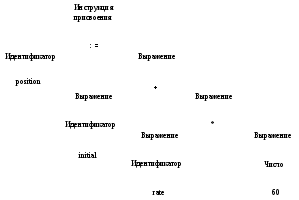 Рис. 1.4.Дереворазборадлявыраженияposition: =initial+rate*60 Правила (1) и (2) являются базовыми (нерекурсивными), в то время как (3) определяет выражения с помощью операторов, применяемых к другим выражениям. Согласно правилу (1), initial и rate представляют собой выражения; правило (2) гласит, что 60 также является выражением. Таким образом, из (3) можно сначала сделать вывод, что rate*60 — выражение, а затем — что выражением является и initial+rate*60. Точно так же многие языки программирования рекурсивно определяют инструкции языка правилами типа приведенных далее.
Рис. 1.4.Дереворазборадлявыраженияposition: =initial+rate*60 Правила (1) и (2) являются базовыми (нерекурсивными), в то время как (3) определяет выражения с помощью операторов, применяемых к другим выражениям. Согласно правилу (1), initial и rate представляют собой выражения; правило (2) гласит, что 60 также является выражением. Таким образом, из (3) можно сначала сделать вывод, что rate*60 — выражение, а затем — что выражением является и initial+rate*60. Точно так же многие языки программирования рекурсивно определяют инструкции языка правилами типа приведенных далее.
- Если identifier1 является идентификатором, a expression2 — выражением, то identifier1:=expression2
есть инструкция.
- Если expression1 — выражение, a statement2 — инструкция, то
while (expression1) dostatement2if (expression1) thenstatement2 являются инструкциями 2 . Разделение анализа на лексический и синтаксический достаточно произвольно. Обычно оно используется для упрощения анализа в целом. Одним из факторов, определяющих данное разделение, является использование рекурсии в правилах анализа. Лексические конструкции не требуют рекурсии, в то время как синтаксические редко обходятся без нее. Контекстно-свободные грамматики представляют собой формализацию рекурсивных правил, используемых при синтаксическом анализе. Данные грамматики рассматриваются в главе 2 и подробно изучаются в главе 4. Например, рекурсия не нужна при распознавании идентификаторов, которые обычно представляют собой строки букв и цифр, начинающиеся с буквы. Распознать идентификатор можно с помощью простого последовательного сканирования входящего потока до тех пор, пока в нем не встретится символ, не являющийся символом идентификатора. После этого сканированные символы группируются в токен, представляющий идентификатор. Сгруппированные символы записываются в так называемую таблицу символов, удаляются из входного потока, и начинается сканирование следующего токена. Однако такое линейное сканирование недостаточно для анализа выражений или инструкций. Например, мы не можем проверить соответствие скобок в выражениях или ключевых слов begin и end в инструкциях без наложения некоторой иерархической или вложенной структуры на вводимые данные. 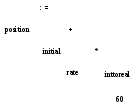
 a) б) Рис.1.5. Семантический анализ добавляет преобразование из целого числа в действительное Дерево разбора, показанное на рис. 1.4, описывает синтаксическую структуру поступающей информации. Более общее внутреннее представление этой синтаксической структуры представлено на рис. 1.5а. Синтаксическое дерево — это «сжатое» дерево разбора, в котором операторы размещены во внутренних узлах, а операнды оператора представлены дочерними ветвями узла, представляющего этот оператор. Построение подобных деревьев (рис. 1.5а) обсуждается в разделе 5.2. В главе 2, «Простой однопроходный компилятор», мы приступим к рассмотрению синтаксически управляемой трансляции (syntax-directedtranslation), а в главе 5, «Синтаксически управляемая трансляция», изучим ее подробнее. При синтаксически управляемой трансляции для построения вывода компилятор использует иерархическую структуру вводимой информации. Семантический анализ В процессе семантического анализа проверяется наличие семантических ошибок в исходной программе и накапливается информация о типах для следующей стадии — генерации кода. При семантическом анализе используются иерархические структуры, полученные во время синтаксического анализа для идентификации операторов и операндов выражений и инструкций. Важным аспектом семантического анализа является проверка типов, когда компилятор проверяет, что каждый оператор имеет операнды допустимого спецификациями языка типа. Например, определение многих языков программирования требует, чтобы при использовании действительного числа в качестве индекса массива генерировалось сообщение об ошибке. В то же время спецификация языка может позволить определенное насильственное преобразование типов, например, когда бинарный арифметический оператор применяется к операндам целого и действительного типов. В этом случае компилятору может потребоваться преобразование целого числа в действительное. Проверка типов и семантический анализ обсуждаются в главе 6, «Проверка типов». Пример 1.1 Битовое представление целого числа в компьютере, вообще говоря, отличается от битового представления действительного числа, даже если эти числа имеют одно и то же значение. Предположим, что все идентификаторы на рис. 1.5 объявлены как имеющие действительный тип, а 60 трактуется как целое число. При проверке типов на рис. 1.5а будет обнаружено, что оператор * применяется к действительному числу rate и целому 60. Обычно при этом осуществляется преобразование целого числа в действительное; на рис. 1.56 для этого создается дополнительный узел для оператора inttoreal, который неявно преобразует целое число в действительное. Однако, поскольку операнд оператора inttoreal представляет собой константу, компилятор может вместо этого сам заменить целую константу на эквивалентную действительную. □ Анализ в программах форматирования текста В программах форматирования текста удобно рассматривать входную информацию как иерархию блоков (boxes). Эти блоки являются прямоугольными областями битовых образов, представляющих светлые и темные пиксели на выводящем устройстве. Так, например, система TЕX ([260]) работает именно таким образом. Каждый символ, который не является частью команды, представляет собой блок, содержащий битовый образ этого символа в определенном шрифте требуемого размера. Последовательные символы, не отделенные «разделителями» (пробелами или символами новой строки), группируются в слова, состоящие из последовательностей горизонтальных блоков, как схематически показано на рис. 1.6. Группирование символов в слова (или команды) представляет собой линейный, или лексический аспект анализа программы форматирования текста.
a) б) Рис.1.5. Семантический анализ добавляет преобразование из целого числа в действительное Дерево разбора, показанное на рис. 1.4, описывает синтаксическую структуру поступающей информации. Более общее внутреннее представление этой синтаксической структуры представлено на рис. 1.5а. Синтаксическое дерево — это «сжатое» дерево разбора, в котором операторы размещены во внутренних узлах, а операнды оператора представлены дочерними ветвями узла, представляющего этот оператор. Построение подобных деревьев (рис. 1.5а) обсуждается в разделе 5.2. В главе 2, «Простой однопроходный компилятор», мы приступим к рассмотрению синтаксически управляемой трансляции (syntax-directedtranslation), а в главе 5, «Синтаксически управляемая трансляция», изучим ее подробнее. При синтаксически управляемой трансляции для построения вывода компилятор использует иерархическую структуру вводимой информации. Семантический анализ В процессе семантического анализа проверяется наличие семантических ошибок в исходной программе и накапливается информация о типах для следующей стадии — генерации кода. При семантическом анализе используются иерархические структуры, полученные во время синтаксического анализа для идентификации операторов и операндов выражений и инструкций. Важным аспектом семантического анализа является проверка типов, когда компилятор проверяет, что каждый оператор имеет операнды допустимого спецификациями языка типа. Например, определение многих языков программирования требует, чтобы при использовании действительного числа в качестве индекса массива генерировалось сообщение об ошибке. В то же время спецификация языка может позволить определенное насильственное преобразование типов, например, когда бинарный арифметический оператор применяется к операндам целого и действительного типов. В этом случае компилятору может потребоваться преобразование целого числа в действительное. Проверка типов и семантический анализ обсуждаются в главе 6, «Проверка типов». Пример 1.1 Битовое представление целого числа в компьютере, вообще говоря, отличается от битового представления действительного числа, даже если эти числа имеют одно и то же значение. Предположим, что все идентификаторы на рис. 1.5 объявлены как имеющие действительный тип, а 60 трактуется как целое число. При проверке типов на рис. 1.5а будет обнаружено, что оператор * применяется к действительному числу rate и целому 60. Обычно при этом осуществляется преобразование целого числа в действительное; на рис. 1.56 для этого создается дополнительный узел для оператора inttoreal, который неявно преобразует целое число в действительное. Однако, поскольку операнд оператора inttoreal представляет собой константу, компилятор может вместо этого сам заменить целую константу на эквивалентную действительную. □ Анализ в программах форматирования текста В программах форматирования текста удобно рассматривать входную информацию как иерархию блоков (boxes). Эти блоки являются прямоугольными областями битовых образов, представляющих светлые и темные пиксели на выводящем устройстве. Так, например, система TЕX ([260]) работает именно таким образом. Каждый символ, который не является частью команды, представляет собой блок, содержащий битовый образ этого символа в определенном шрифте требуемого размера. Последовательные символы, не отделенные «разделителями» (пробелами или символами новой строки), группируются в слова, состоящие из последовательностей горизонтальных блоков, как схематически показано на рис. 1.6. Группирование символов в слова (или команды) представляет собой линейный, или лексический аспект анализа программы форматирования текста.  Рис. 1.6. Группировка символов и слов в блоки В ТЕХ блоки могут быть построены из меньших блоков в различных горизонтальных и вертикальных сочетаниях. Например, hbox< > группирует список блоков, собранных по горизонтали. По вертикали блоки группируются с помощью команды vbox. Таким образом, следующая конструкция в ТЕХ hboxvboxvbox> представляет набор блоков, показанный на рис. 1.7. Определение иерархического расположения блоков, заданного входным потоком, является частью синтаксического анализа в ТЕХ.
Рис. 1.6. Группировка символов и слов в блоки В ТЕХ блоки могут быть построены из меньших блоков в различных горизонтальных и вертикальных сочетаниях. Например, hbox< > группирует список блоков, собранных по горизонтали. По вертикали блоки группируются с помощью команды vbox. Таким образом, следующая конструкция в ТЕХ hboxvboxvbox> представляет набор блоков, показанный на рис. 1.7. Определение иерархического расположения блоков, заданного входным потоком, является частью синтаксического анализа в ТЕХ.  Рис. 1.7. Иерархия блоков в ТЕС Еще одним примером могут послужить математические препроцессоры EQN ([246]) и Т^Х, создающие математические выражения из операторов типа sub и sup для нижних и верхних индексов. Если EQN встречает входной текст вида BOX sub box он изменяет размеры блока box и присоединяет к блоку BOX справа внизу, как показано на рис. 1.8. Оператор sup приведет к блоку такого же размера, но размещенному справа вверху.
Рис. 1.7. Иерархия блоков в ТЕС Еще одним примером могут послужить математические препроцессоры EQN ([246]) и Т^Х, создающие математические выражения из операторов типа sub и sup для нижних и верхних индексов. Если EQN встречает входной текст вида BOX sub box он изменяет размеры блока box и присоединяет к блоку BOX справа внизу, как показано на рис. 1.8. Оператор sup приведет к блоку такого же размера, но размещенному справа вверху. 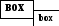 Рис. 1.8. Построение нижнего индекса в математическом тексте Такие операторы могут использоваться рекурсивно, т.е. EQN-текст a sub < i sup 2>дает в результате аi.Группировка операторов sub и sup в токены представляет собой часть лексического анализа текста EQN. Однако для определения размера и размещения блоков требуется синтаксическая структура текста.
Рис. 1.8. Построение нижнего индекса в математическом тексте Такие операторы могут использоваться рекурсивно, т.е. EQN-текст a sub < i sup 2>дает в результате аi.Группировка операторов sub и sup в токены представляет собой часть лексического анализа текста EQN. Однако для определения размера и размещения блоков требуется синтаксическая структура текста.
#487 Разбор программы Шреддера «Эффективный минимум» (старая версия)
Разбор программы Навального (стрим)
Источник: studfile.net
Как разобрать программу
В процессе профессиональной деятельности программисту приходится сталкиваться с множеством ситуаций, требующих комплексного анализа больших фрагментов исходного кода или же даже целых приложений. Исследование удачных решений и практик, анализ уже реализованных алгоритмов или же просто перевод в команду другого проекта часто вызывает необходимость разобрать программу, написанную кем-то еще.

Статьи по теме:
- Как разобрать программу
- Как делать синтаксический разбор предложения
- Можно ли восстановить удаленные файлы
Вам понадобится
- — программа для просмотра исходного кода;
- — возможно, средства реверс-инженерии и case-средства.
Инструкция
Исследуйте потоки передачи управления разбираемой программы. Выявите точку входа. Ей, например, является функция main в C и C++, начало неименованного структурного блока первого уровня, завершающегося ключевым словом END с точкой, в pascal.Начиная от точки входа, проследите все маршруты вызовов функций, процедур, методов классов. Составьте укрупненную диаграмму потоков управления.
Для упрощения данного процесса можно использовать различные средства реверс-инженеринга.Более подробно проанализируйте исходный код структурных элементов разбираемой программы. Составьте диаграммы потоков управления или блок-схемы алгоритмов, реализуемых отдельными функциями и методами.
Осуществите анализ потоков данных разбираемой программы. Выявите структуры, используемые для хранения информации и ее передачи между функциональными элементами приложения. Выявите фрагменты кода, в которых осуществляется преобразование данных из одной формы в другую. Составьте перечень мест программы, в которых производится получение информации из внешней среды, а также ее вывод куда-либо. При проведении анализа подобного рода также помогут средства реинжиринга и case-средства (например, для построения диаграммы наследования и диаграммы зависимостей).
Разберите программу, составив полное представление о принципах ее функционирования. На основе знаний о потоках передачи управления между структурными элементами, а также внутри них, знаний о потоках и типах преобразований данных, выявите основные алгоритмы работы.Разделите алгоритмы обработки данных и управления интерфейсом. Среди алгоритмов обработки выделите типовые, классифицируйте их. Выявите алгоритмы, основанные на взаимодействии различных компонентов (например, поиск может использоваться как самостоятельно, так и в составе сортировки). При необходимости составьте блок-схемы различной степени детализации, иллюстрирующие работу программы.
Источник: www.kakprosto.ru
Как научиться читать и понимать код программирования
Рассказываем, зачем читать чужой код и с чего стоит начать.

Егор Барковский
Автор статьи
23 ноября 2022 в 14:48
Более 80% времени разработчики тратят на чтение кода. Уметь читать код — даже важнее, чем уметь его писать.
Есть несколько популярных методов понимания кода, которые стоит запомнить. Вот о них и рассказываем в статье.
«Действительно, соотношение времени, затрачиваемого на чтение и написание, составляет более 10 к 1. Мы постоянно читаем старый код в рамках усилий по написанию нового кода. [Поэтому] облегчение чтения облегчает написание».
Роберт К. Мартин
Зачем читать чужой код
Программисты на проекте или продукте меняются, а вот код чаще всего остается одним и тем же. И если изначально его написали плохо, сложно или на свой манер, то остальным разработчикам будет нелегко его понять.
В идеале код должен быть хорошо написан, задокументирован, структурирован и внятно протестирован. Но такие идеальные ситуации случаются редко. А читать его нужно всегда. Уметь читать код — даже важнее, чем уметь его писать.
Допустим, вы пришли на проект, выполняете задачу. Нужно прочитать код, который написал предыдущий программист, и вы понимаете, что ничего не понимаете: надо проникнуть в ход мыслей предыдущего разработчика, попытаться понять, о чем он думал, когда писал, и вообще — он ли его писал. В общем, это как чтение романа или рассказа: вы читаете не просто инструкции на экране, а историю.
Но давайте разберемся, что нужно делать, чтобы читать чужой код, и каких принципов стоит придерживаться, чтобы понимать его быстро и легко.
Веб-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
С чего начать
Поиск понятной части кода
Найдите понятную часть кода и раскрутите ее. Допустим, перед вами отчет по месячным расходам пользователя.
- Сначала определите, в каком конкретном месте код создает этот файл.
- Потом поймите, в каком месте отчет заполняется.
- Сделайте еще один шаг и выясните, откуда взялась информация о пользователе, и так далее, шаг за шагом следуйте из конца в начало.
Так вы поймете, как организована основная масса кода: где определены функции и переменные, как называются файлы, отвечающие за бизнес-логику. А еще поймете логику программистов, которые писали этот код.
Этот процесс чем-то похож на судоку: сначала вы решаете легкие клеточки, а они приводят к решению сложных и неочевидных.
Git blame и git log
Скорее всего, код, который вы пытаетесь понять, импортировали из общей системы контроля версий — Git, SVN. Посмотрите историю изменения непонятной строчки с помощью команд git blame и git log — они выдадут историю всех коммитов и изменений.
Посмотрите историю файла от начала до конца, узнайте план его развития. Определите, какие функции и методы авторы изменяли больше всего, и сделайте упор на эти фрагменты кода.
Git blame может дать информацию об авторе этого кода — можете расспросить его лично.

Картина целиком
Если есть документация, обязательно ее прочтите. Даже если сначала покажется, что код сложный и непонятный, продолжайте изучать и скоро поймете, что в этих неясных строках есть смысл. Сначала получи́те общее представление, а потом погружайтесь в детали.
Зафиксируйте для себя структуру каталога проекта в целом, пробегитесь по названиям файлов, попытайтесь понять их примерное предназначение.
27 апреля 19:00 МСК
Как работать из дома без навыков программирования

Чтение спецификации
Если в репозитории, который вы изучаете, есть test suite, то половина дела сделана за вас.
Тесты — отличное место, откуда стоит начинать читать код. Тесты — это намерение разработчика.
Когда будете читать, обратите внимание на ожидаемые результаты и сфокусируйтесь на положительных.
Если кажется, что процесс всё равно непонятен, запустите конкретный тест в дебаге: большая часть тестов не требует запуска всего приложения, поэтому на этот шаг вы потратите меньше времени, чем на полный трейсинг.
Комментарии как подсказки
Оставляйте закладки в тех местах программы, которые показались наиболее интересными и непонятными. Такие пометки поддерживают почти все редакторы кода.
Ставьте точки, делайте пометки и записывайте предположения. Это поможет в процессе отладки и уменьшит количество времени, которое вы могли бы потратить на поиск методов.
Поиск Main
Когда получаете код, который нужно прочитать и понять, первое, что нужно сделать, — запустить его и посмотреть, что он делает: что принимает в качестве входных и каковы выходные данные.
Обратите внимание на подключаемые файлы и стандартные конфигурации, пробегитесь по логам запуска — и общая картина уже в кармане.
Структура и стиль
Обратите внимание на стиль, когда читаете код. Потому что в итоге нужно будет писать его в таком же стиле.
Изучите даже такие вещи, как соглашения об именах, интервалы между строками и расстановку скобок.
Определите общий уровень абстракции. Если это высокоабстрактный код со многими слоями, то вы будете писать такой же.
Если вы достаточно покопаетесь в истории, вы, вероятно, сможете найти точный момент времени, когда один из разработчиков решил абстрагировать часть кода. Поймите, как это выглядело до и как стало выглядеть после, и постарайтесь следовать тому же принципу при написании.
Если столкнулись с решением, которое не нравится, поговорите с командой о том, чтобы изменить его в будущем, но не смешивайте разные стили в одном файле: это сделает код еще менее читабельным.
Чем сильнее файл выглядит так, будто его писал один человек, тем лучше. Быть последовательным важнее: разобраться в одном стиле проще, чем в нескольких.
Мусорная часть кода
Будьте готовы, что найдете мусорную часть кода. Вы можете найти методы, целые файлы или закомментированный код, который никогда не использовался.
Не переживайте и смело удаляйте эти части. Человек, который придет на проект после вас, скажет спасибо.
Повторение и закрепление
Повторите процесс чтения и запуска несколько раз. Это нужно, чтобы начать понимать общую кодовую базу.
Краткие итоги
Читать чужой код сложно только сначала. Пользуйтесь нашими советами — и шаг за шагом вы разберетесь в задаче, над которой работаете.
- Найдите понятную часть кода.
- Посмотрите историю изменений с помощью git blame и git log.
- Прочитайте спецификацию.
- Оставьте себе комментарии, чтобы потом было легче ориентироваться.
- Запустите код и посмотрите, как он работает.
- Определите стиль и продолжайте его придерживаться в дальнейшей работе с кодом.
- Удалите мусорную часть кода.
Источник: sky.pro