
В ряде случаев бывает неудобно или невозможно пользоваться пошаговой отладкой программ. В таких ситуациях могут помочь контрольные точки, которые не прерывают работу программы, а лишь помещают некоторую информацию в специальный файл трассировки. Для реализации такой точки следует раскрыть окно Run|Add Breakpoint|Source Breakpoint (рис.
6.1), убрать флажок в переключателе Break и написать сообщение в строке Log message. Можно также в строке Eval expression указать выражение, которое будет вычислено и вместе с сообщением помещено в протокол работы программы. Этот протокол можно просмотреть в любой момент (в том числе и после завершения прогона программы) с помощью опции View|Debug Windows|Event Log.
Вопросы для самоконтроля
1. Что такое трассировка программы?
2. Какие средства отладки могут быть использованы в среде Turbo Delphi?
3. Назовите встроенные средства отладки и условия их использования.
4. Каким образом провести контроль значения переменных?
Как работает интернет? Протоколы HTTP/HTTPS, FTP. Хостинг. Для самых маленьких.
5. Назовите способы останова программ и их перезапуска.
6. Какие действия можно производить в точках останова?
7. Что такое группировка точек останова?
8. Назовите способы контроля/модификации значений параметров.
9. Когда заканчивается процесс отладки?
10. Как и для чего ведется протокол работы программы?
Упражнения
Провести отладку своей программы, составленной при выполнении упражнения гл. 4, с помощью отладочных печатей и на специально подобранных тестовых наборах параметров программы. Проверить выполнение всех ветвей и циклов. Получить листинг программы с комментариями и отладочными печатями, результаты контрольных вычислений.
Для той же программы провести отладку, используя встроенные средства среды Turbo Delphi. Провести на экране трассировку программы, установку и использование точек останова, работу с окном отладки. Обосновать введение точек останова и контролируемых в окне отладки параметров программы, а также произвести сравнение результатов работы программы с результатами контрольных вычислений.
Глава 7. ОБРАБОТКА МАССИВОВ ДАННЫХ
Описание массива
Все рассмотренные ранее типы данных называются скалярными и имеют два характерных свойства: неделимость и упорядоченность их значений. В Паскале на основе скалярных типов можно определять новые структурированные типы, которые представляют структуры данных – целые наборы значений, организованные определенным образом и выступающие под общим именем. Переменные, представляющие такие структуры, называются структурированными переменными. Числовые наборы принято задавать в виде массивов.
Массив– это упорядоченный набор объектов (например, чисел) одного типа, называемых элементами массива, у каждого из которых имеется его номер в общей последовательности (индекс).
Основные характеристики массива:
· имя массива– общее имя, под которым выступают все элементы массива;
· размерность/количество индексов массива – способ организации его элементов, определяющий их порядок;
Что такое TCP/IP: Объясняем на пальцах
· размер массива – количество элементов;
Общая форма описания массива имеет следующий вид:
Var
Тип индексовможет быть любым порядковым типом, например, целым, символьным или логическим типом, отрезком целого или символьного типа, перечисляемым типом. Использование вещественного типа недопустимо, поскольку он не относится к порядковому типу.
Тип элементов массиваможет быть любым скалярным или структурированным, кроме файлового.
Пример 7.1.Описание массива вещественных чисел.
Var
a : array [1..10] of real;
Здесь описан массив с именем a, состоящий из 10 элементов a1, a2, . a10, каждый из которых является переменной вещественного типа.
Одномерные массивы
Количество индексов, стоящих в описании массива, определяет число измерений массива. Одномерные массивысодержат в описании один индекс и представляют линейную последовательность элементов (вектор, линейную таблицу).
Пусть имеется массив чисел Ball, содержащий средний балл успеваемости студентов Иванова, Соколова, Андреева, а также массивы Mas1 и Mas2, содержащие отметки двух групп студентов по математике. В примере 7.2 приведен один из вариантов описания данных массивов.
Пример 7.2.Описание одномерных массивов.
Type
Fam = (Ivanov, Sokolov, Andreev);
Ball : array [Fam] of real;
Mas1, Mas2 : array [1..30] of integer;
Для массива Ball тип элемента – вещественный, тип индекса представлен перечисляемым типом. Значением перечисляемого типа может быть идентификатор, пользователь в разделе описания типов указывает имя типа и в скобках значения этого типа. Перечисляемый тип может быть использован в программе как своеобразный комментарий. Для массивов Mas1 и Mas2 тип элемента – целый, тип индекса представлен отрезком целого типа.
Выбор отдельного элемента массива осуществляется указанием имени массива, за которым в квадратных скобках следует его индекс/номер, который может быть представлен индексным выражением, в частности, константой или переменной. Индексное выражениедолжно задавать значение, лежащее в диапазоне, определяемом типом индекса. К элементам массива применимы операции и стандартные функции, допустимые для базового типа. Для данных, рассмотренных в примере 7.2, определив дополнительно i, j, k как переменные целого типа, можно записать операторы, приведенные ниже.
Пример 7.3.Обращение к элементам одномерных массивов.
i := 15; j := 20; k := 10;
Все операции над массивами (над структурированными переменными) в Паскале выполняются поэлементно!
В программе одному массиву может быть присвоено значение другого массива, если их базовые типы и типы индексов совпадают. Так как для массивов Mas1 и Mas2, рассмотренных в примере 7.3, это требование выполняется, то в программе допустим оператор
Пример 7.4. Определить минимальное значение элемента и его номер в одномерном массиве из 20 элементов.
Задача может быть решена последовательным сравнением «текущего» минимального значения со значением очередного элемента массива и «запоминанием» нового минимального значения. Схема алгоритма показана на рис. 7.1. Программа имеет вид:
Program Vvod_Vyvod_mas;
Const
Type
vector = array [1..3] of integer;
stroka = array[1..10] of char;
Var
mas : array [1..2] of vector;
i, j : integer;
Begin
WriteLn(pr5, ‘введите массив v’);
WriteLn(pr5, ‘введите массив mas’);
for i := 1 to 2 do
for j := 1 to 3 do
WriteLn(pr5, ‘введите s1 и s2’);
for i := 1 to 10 do
for i := 1 to 10 do
WriteLn(pr5, ‘массив v’);
WriteLn(pr5, v[1]:5, v[2]:5, v[3]:5);
WriteLn(pr5, ‘массив mas ‘);
for i := 1 to 2 do
Begin
forj := 1 to3 do
Write(pr5, mas[i, j]);
end;
for i := 1 to10 do
fori := 1 to10 do
End.
Результат работы программы:
s1 = abcdefgijk s2 = lmn
Для ввода-вывода двумерного массиваиспользованы вложенные циклы, осуществляющие ввод-вывод элементов по строкам. В качестве символьных данных вводились 13 букв латинского алфавита. При длине строк s1 и s2, равных 10 байтам, первая строка заполнилась полностью, а во вторую из входного потока было прочитано 3 символа, и строка была дополнена пробелами.
Источник: allrefrs.ru
Протокол работы программы
Программирование на ToyCode и закрепление знаний по отладке программы. Использование знаний из курса «Программирование на ЯВУ».
2.Порядок выполнения работы:
1. Ознакомиться с теоретическими материалами по теме.
2. Разобрать лекционные примеры.
3. Ознакомиться с заданием согласно варианту.
4. Составить таблицу внешних спецификаций
5. Выполнить проектирование тестов к задачам.
6. Разработать и описать алгоритмы решения в виде блок-схемы или псевдокода.
4. Закодировать алгоритмы на языке ассемблера с необходимыми комментариями.
5. Получить исполняемый файл (.tcp)
7. Отладить и протестировать программу.
Задание 1
3.1. Постановка задачи:

Выполнить вычисления Y по формуле . Значения аргументов вводятся с клавиатуры.
3.2 Система команд TOYCODE:
| КОП в числовой форме | КОП в форме символического имени | Название |
| STOP | Останов | |
| LD | Загрузка в аккумулятор | |
| STO | Запись в память | |
| ADD | Сложение | |
| SUB | Вычитание | |
| MPY | Умножение | |
| DIV | Деление нацело | |
| IN | Ввод | |
| OUT | Вывод | |
| B | Переход безусловный | |
| BGTR | Переход, если больше нуля | |
| BZ | Переход, если равно нулю |
Таблица внешних спецификаций
| № | Имя | Назначение | Тип | ОДЗ |
| a | Переменная | целый | -999..999 | |
| b | Переменная | целый | -999..999 | |
| c | Переменная | целый | -9999..9999 | |
| x | Константа | целый | ||
| y | Искомая переменная | целый | -9999..9999 |
Таблица тестов
| № теста | a | b | c | y | Комментарии |
| -2 | — | Ошибка | |||
| -1 |
Таблица памяти
| Переменные | |
| Имя переменной | Номер ячейки памяти |
| a | |
| с | |
| b | |
| y | |
| R (рабочая ячейка) | |
| Постоянные |
Листинг программы
REM Исходные данные
REM Задаем рабочую ячейку
REM Записываем константу 5 в память
REM Загружаем значение переменной «а» в аккумулятор
REM Вычисляем числитель (а+с)
REM сохраняем результат в рабочую ячейку «r»
REM Записываем 5 в аккумулятор
REM Вычисляем произведение 5a
REM Вычисляем разность 5а-b
REM Делим числитель на содержимое рабочей ячейки
REM Записываем в y результат
REM Выводим результат
Протокол работы программы
Заносим наш код в поле исходного кода в трансляторе языка TOYCODE, и нажимаем кнопку «Трансляция».
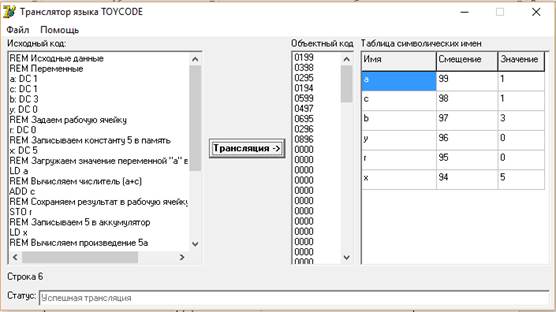
Рисунок 1 –Трансляция TOYCODE
Далле сохраняем обьектный код, и получаем фаил с расширением.tcp.

Рисунок 2 – Сохранение объектного кода
Файл с кодом запускаем на TOYCOMP и проверяем результат выполнения программы. Исходя из таблицы тестов при заданных a=1, b=3, c=1 Y должен получиться равным 1.
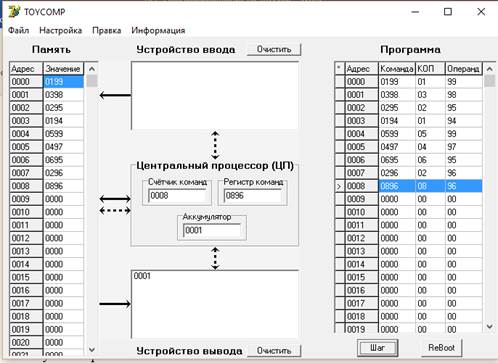
Рисунок 3 – Результат выполнения транслированного TOYCODE
Из рисунка 3 видно, что на устройство вывода пришла 1, что говорить о правильности транслированного TOYCODа. Проведем еще два прогона программы следуя таблице тестов:
| № теста | a | b | c | y | Комментарии |
| -2 | — | Ошибка |

Рисунок 4 – Прогон 2 с выдачей ошибки
Из рисунка 4 видно сообщение об ошибке, как и предполагалось в таблице тестов. Проведем последний 3 прогон:
| № теста | a | b | c | y | Комментарии |
| -1 |
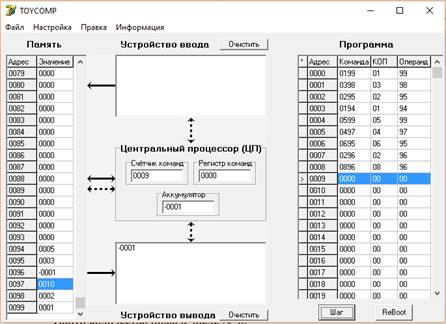
Рисунок 5 – Прогон 3, получение отрицательного числа
Из рисунка 5 видно, что в результате выполнения программы получилось отрицательное число, а именно -1, как и предполагалось нами.
3.8 Заключение о первом задание:
Программа отлажена, тестирование показало, что программа правильно решает поставленную задачу.
Задание 2
4.1 Постановка задачи:
Найти количество цифр в числе N>0;
Таблица внешних спецификаций
Таблица тестов
| № теста | n | k | Комментарии |
| -4 | Завершение программы так, как n | ||
| Завершение программы так, как n=0 |
4.4 Таблица памяти:
| Переменные | |
| Имя переменной | Номер ячейки памяти |
| n | |
| k | |
| R (рабочая ячейка) | |
| Постоянные |
4.5 Алгоритм на языке PASCAL:
4.6 Блок схема:

Листинг программы в TOYCODE
REM Вводим исходные данные
REM Вводим необходимые постоянные
REM Резервируем рабочую ячейку
REM Загружаем в аккумулятор величину n
REM Заносим в память величину n
REM Записываем в аккумулятор значение рабочей ячейки
REM Делаем переход для проверки введеного числа, оно должно быть строго больше 0
REM Выводим на устройство вывода ответ
REM Остановка программы
REM Делаем метку М1, для организации цикла
REM И делим содержимое аккумулятора на 10
REM Записываем содержимое аккумулятора в рабочую ячейку
REM Записываем значение «к» в аккумулятор
REM Прибавляем 1
REM Записываем в память новое значение «k»
REM Снова записываем содержимое рабочей ячейки в аккумулятор
REM Делаем переход на метку М1 если содержимое аккумулятора >0
REM Выводим на устройство вывода ответ
REM Остановка программы
Источник: poisk-ru.ru
Основные принципы протоколирования работы приложения

Цель данной статьи – попытка выделить, обобщить и проанализировать основные критерии программных средств протоколирования, основные механизмы протоколирования, а также конфигурацию протоколирования.
Протоколирование работы приложения – полезный инструмент разработчика. Даже в примитивном варианте он позволяет экономить массу времени на поиск ошибок на стороне клиента. [5]
Средства протоколирования, как правило, пишутся для уже имеющегося приложения, либо для разрабатываемого приложения. То есть носят прикладной характер. Поэтому говорить о правилах или
концепциях их разработки не приходится – архитектурные особенности и
методика протоколирования зависят от конкретно взятой задачи.
Тема протоколирования достаточно широкая и каждый разработчик
ПО сам решает, каким образом ему вести протокол работы программы.
Протоколирование. Общие критерии программных средств протоколирования
Протоколирование (логирование) (англ. logging, tracing) — хронологическая запись с различной (настраиваемой) степенью детализации сведений о происходящих в системе событиях (ошибки, предупреждения, сообщения) куда-либо (файл, приложение мониторинга и т. д.) для последующего анализа. На программистском сленге логами называют протоколы работы, которые ведутся как самой операционной системой, так и самостоятельно многими программами и программными системами. [3]
Тема протоколирования работы программы довольно широко распространена, многие разработчики прибегают к ведению протоколов, журналов, логов работы программы. Впрочем, эти аспекты приложений часто бывают, доступны и полезны не только разработчикам, но и пользователям программных продуктов. Различные системы аудита, ведения истории, предоставления журнала действий – многое содержится
в тех программах, с которыми работают люди, решая различные задачи и пользуясь различными программами.
В UNIX-системах существуют демоны-логгеры, которые собирают информацию и пишут сообщения в системный журнал [2]. Подобные компоненты есть и Windows-системах, там они представлены службами.
В большинстве браузеров хранится история посещенных пользователем URL-ов.
В СУБД часто имеются утилиты для ведения протокола всех операций с данными. Например, утилита SQL Trace в MS SQL Server. [4]
Http-сервер ведет протоколы, в которые попадают все обращения к серверу, ошибки и прочая информация.
Таких примеров можно собрать огромное множество.
Как видно, протоколирование работы программы – очень важная часть в работе программы, часто оказывающаяся полезной как для разработчика, так и для пользователя. Подобные средства, как правило,
пишутся для уже имеющегося приложения, либо для разрабатываемого
приложения, то есть они носят прикладной характер. Поэтому говорить о правилах или концепциях разработки системы протоколирования не приходится – ее архитектурные особенности и методика протоколирования зависят от конкретно взятой задачи. Однако можно выделить общие для всех программ-логгеров показатели.
Итак, для всех программных средств протоколирования выделяют следующие критерии:
Цели ведения протокола:
o отладка приложения,
o ведение истории действий пользователя,
o слежение за действиями пользователя в целях безопасности
Формат хранения и представления протокола:
o текстовый файл,
o бинарный файл (с последующей обработкой программой),
Архитектурная организация (относительно протоколируемой программы):
o библиотека dll,
o программный модуль,
o программный агент,
o внешняя программа.
o ведение протокола для одной конкретной программы,
o возможность использования для разных программ.
Конкретизация, подробность протоколов.
Степень влияния на программу.
Типы регистрируемых объектов:
o элементы форм (активизация, ввод данных, модификация деактивация),
o программные модули (пакеты, библиотеки),
o классы, методы, атрибуты.
Сохранение отношений между регистрируемыми объектами:
o иерархическое протоколирование (отношения сохраняются),
o «плоское» протоколирование (отношения не сохраняются).
Механизмы протоколирования информации
1. Самый простой и потому самый распространенный способ — это протоколирование в текстовый файл. Способ, при котором отдельное событие представляет собой отдельною строку. Например, известный Symantec Antivirus или Linux Syslog. Способ хорош как с точки зрения реализации – довольно легко наладить такое протоколирование в коде большинства языков программирования, — так и со стороны использования – читать такой лог можно любым текстовым редактором. [1]
2. Чуть более сложный случай – логи, в которых отдельное событие представляет собой не одну строку, а несколько. С некоторым допущением к этому же типу относятся логи, которые пишутся в формате XML (либо сходных с ним форматах данных). Такой лог гораздо более сложен для анализа, потому что каждое событие может представлять собой набор более мелких записей.
3. Бинарный лог представляет собой самый нечитаемый тип логов.
Для того чтобы с ними работать, нужна специальная программа (обычно от того же производителя, что и приложение, которое пишет такой лог), с помощью которой бинарный лог и анализируется. Обычно бинарный лог — это последовательно сбрасываемые в файл структуры, которые разделяются символомразделителем. Обрабатывать такой лог очень тяжело, впрочем, довольно часто в технической информации, которую предоставляет производитель, есть описание структуры такого лога.
4. Приложения, которые используют базы данных либо сами являются СУБД, довольно часто используют базу данных в качестве хранилища логов. В большинстве своем это отдельная
таблица базы данных, каждая строка которой является отдельным событием. Такое протоколирование часто может отрицательно сказаться на общей производительности базы данных, так как протоколирование в базу данных может быть довольно интенсивным (к примеру, MS SQL Server 2000/2005 успевает в C2
Audit логи писать несколько десятков записей в секунду). Естественно, что все зависит от того, как сконфигурировано приложение.
Чаще всего протоколирование — процесс тихий и незаметный. Система пишет логи, тихо используя некоторую конфигурацию, которая предусмотрена производителем. Обычно конфигурация протоколирования подбирается так, чтобы это не вызывало какой-то проблемы у пользователя. Проблемы могут быть самые разные: от понижения производительности из-за постоянной записи информации в логи (на жесткий диск) до проблем со свободным местом на жестком диске. [1]
Довольно часто либо протоколирование выключено полностью, либо инсталляционная программа потребует точных указаний о том, что делать с протоколированием. Если есть подозрение, что протоколирование будет
довольно интенсивным, то следует заранее задуматься о том воздействии,
которое оно будет оказывать на систему. Кроме самого простейшего случая, когда протоколирование может быть или включено, или выключено, приложения часто предоставляют куда более настраиваемые и удобные средства управления. Типичные функции таковы:
1. Имя файла, директория или полный путь к тому файлу, в который пишется лог. Это очень полезно, если протоколирование необходимо и есть возможность или необходимость организовать
запись логов на отдельный жесткий диск, сетевой диск и т. п.
Такой способ удобен, если логи будут интерпретироваться сторонним приложением, которое находится на отдельном компьютере и каким-либо образом может повлиять на работу основной системы.
2. Критерий замены лога (Log Rotation). Рано или поздно логи становятся большими или их становится слишком много. Чтобы избежать проблем, которые с этим связаны (постоянная работа с огромным файлом отрицательно сказывается на производительности системы), программы, осуществляющие протоколирование, обычно используют что-нибудь из следующего списка возможностей управления логами:
Каждый день (неделю, месяц и т. д.) система использует новый лог-файл.
Смена файла происходит по достижении им определенного размера.
Смена файла происходит одновременно с перезапуском сервиса, который пишет лог.
3. Набор событий, которые будут протоколироваться. Довольно часто важно иметь возможность настроить протоколирование только тех
событий, которые реально необходимы. К примеру, часто нет
необходимости протоколировать информацию обо всех транзакциях в базе данных, особенно если это куча select-запросов, которые, вероятно, не содержат угрозы с точки зрения безопасности. В таком случае можно изрядно снизить нагрузку на сервер, выключив протоколирование транзакций, но оставив учет только реально необходимых событий: попыток авторизации, попыток доступа к файлам, изменения системных настроек и т. п.
Были рассмотрены основные принципы протоколирования работы приложения, однако, следует отметить, что указанные основные принципы очень часто расширяются разработчиками под свои конкретные нужды. Разрабатываются новые форматы хранения данных, новые методы и стандарты представления данных. Улучшаются производительность и универсальность систем протоколирования.
ИСПОЛЬЗОВАНИЕ XML ПРЕДСТАВЛЕНИЯ ДАННЫХ ДЛЯ ОПИСАНИЯ ГРАФИКО-ТЕКСТОВОЙ ИНФОРМАЦИИ ВО ВСТРАИВАЕМЫХ СИСТЕМАХ
Выбор способа представления входных данных
При выборе способа представления нужно учитывать следующие особенности, связанные со спецификой полётных инструкций и авиационной области применения:
Данные могут быть разнородных типов (текстовые, табличные,
Применение в бортовых системах предъявляет жёсткие требования по быстродействию.
Данные имеют изменяющуюся структуру.
XML формат предоставляет возможности для реализации базы данных полётных инструкций, позволяет учесть выше приведённые особенности. Язык XML и некоторые другие стандарты основанной на нем платформы уже, несомненно, стали стандартами де-факто. Все ведущие поставщики программного обеспечения не только Web, но и систем баз данных, включают в свои программные продукты поддержку языка XML или даже создают специализированные основанные на нем системы.
В настоящее время создано множество успешных подмножеств языка
XML, применяемые в специальных областях и описывающие различные данные. К ним можно отнести SVG (Scalable Vector Graphics), VML (англ. Vector Markup Language — язык векторной разметки), CML (Chemical Markup Language – описание молекулярных структур) и т. д. Элементы этих языков можно использовать в области отображения на индикаторах полётных инструкций. В частности, в основу может лечь язык описания графики SVG, который необходимо оптимизировать для встраиваемого применения.
Генерация XML базы данных на основе графического представления
(Материал взят из книги Информатика и вычислительная техника — Н. Н. Войта)
Источник: studik.net