
Когнитивная система IBM Watson: принципы работы с естественным языком

IBM Watson — одна из первых когнитивных систем в мире. Эта система умеет очень многое, благодаря чему возможности Watson используются во многих сферах — от кулинарии до предсказания аварий в населенных пунктах. В общем-то, большинство возможностей Watson не являются чем-то уникальным, но в комплексе все эти возможности представляют собой весьма мощный инструмент для решения разнообразных вопросов.
Например — распознавание естественного языка, динамическое обучение системы, построение и оценка гипотез. Все это позволило IBM Watson научиться давать прямые корректные ответы (с высокой степенью достоверности) на вопросы оператора. При этом когнитивная система умеет использовать для работы большие массивы глобальных неструктурированных данных, Big Data. Каковы основные принципы работы IBM Watson с языком? Об этом — в продолжении.
Шерлок Холмс и доктор Ватсон | 1 серия | Знакомство
Основные сложности распознавания естественного языка
Для человека язык — это средство выражения мысли. Мы используем язык для передачи своего мнения, каких-либо данных и сведений. Можем делать прогнозы и формировать теории. Именно язык — краеугольный камень нашего сознания. При этом, вот парадокс, язык человека очень неточный.
Многие термины — нелогичны, и компьютерным системам понять нас бывает очень сложно. Например, как может быть тонким голос? Как можно сгореть со стыда? Для машины это — проблема, для человека же — вполне обыденная вещь. Дело в том, что для правильного ответа на вопрос во многих случаях необходимо учитывать имеющийся контекст.
При отсутствии достаточной фактической информации трудно правильно ответить на вопрос, даже если вы можете найти точный ответ на элементы вопроса в буквальном смысле.
Обработка естественного языка — начало
Многие компьютерные системы способны анализировать язык, но при этом проводится поверхностный анализ. Это может иметь смысл, например, для того, чтобы поставить статистически обоснованную оценку тенденций в изменении эмоций на больших массивах информации. Здесь точность передачи информации не слишком важна, поскольку если даже если предположить, что число ошибочно-позитивных результатов примерно равно числу ошибочно-негативных результатов, то они компенсируют друг друга.
Но если значение имеют все случаи, то системы, которые работают с поверхностным анализом языка, уже не могут нормально делать свою работу. Ярким примером сказанному может быть задача для голосового помощника любого из мобильных устройств. Если сказать «найди мне пиццу», то помощник выведет список пиццерий.
Если же сказать «не ищи мне пиццу в Мадриде», например, система все равно будет искать. Такие системы работают, идентифицируя некоторые ключевые слова и используя определенный набор правил. Результат может быть точным в заданной системе правил, но неправильным.
Глубокая обработка естественного языка
Для того, чтобы научить систему анализировать сложные смысловые конструкции, с учетом эмоций и прочих факторов, специалисты использовали глубокую обработку естественного языка. А именно — вопросно-ответную систему контентной аналитики (Deep Question*Answering, DeepQA). Если требуется большая точность, то приходится использовать дополнительные методы обработки естественного языка.
IBM Watson — система глубокой обработки естественного языка. При анализе определенного вопроса, для того, чтобы дать правильный ответ, система старается оценить как можно более обширный контекст. При этом используется не только информация вопроса, но и данные базы знаний.
Создание системы, способной провести глубокую обработку естественного языка, позволило решить и другую проблему — анализ огромного количества информации, которая генерируется ежедневно. Это неструктурированная информация, вроде твитов, сообщений социальных сетей, отчеты, статьи и прочее. IBM Watson научился использовать все это для решения задач, поставленных человеком.
Когнитивная система IBM Watson
Watson — это уже иной уровень вычислительных возможностей. Система умеет разделять определенные высказывания на естественном языке и находить связи между этими высказываниями. При этом Watson справляется с задачей, во многих случаях, даже лучше человека, при этом обработка данных идет гораздо быстрее, работа ведется с гораздо большими объемами — человек на такое просто неспособен.

Основные характеристики когнитивной системы
Система работает в таком порядке:
1. Получив вопрос, Watson выполняет его синтаксический анализ, чтобы выделить основные особенности вопроса.
2. Система генерирует ряд гипотез, просматривая корпус в поисках фраз, которые с некоторой долей вероятности могут содержать необходимый ответ. Для того чтобы вести эффективный поиск в потоках неструктурированной информации, нужны совершенно другие вычислительные возможности * их называют когнитивными системами. (не очень понимаю последнее предложение и роль звёздочки)
3. Система выполняет глубокое сравнение языка вопроса и языка каждого из возможных вариантов ответа, применяя различные алгоритмы логического вывода.
Это трудный этап. Существуют сотни алгоритмов логического вывода, и все они выполняют разные сравнения. Например, одни выполняют поиск совпадающих терминов и синонимов, вторые рассматривают временные и пространственные особенности, тогда как третьи анализируют подходящие источники контекстуальной информации.
4. Каждый алгоритм логического вывода выставляет одну или несколько оценок, показывающих, в какой степени возможный ответ следует из вопроса, в той области, которая рассматривается данным алгоритмом.
5. Каждой полученной оценке затем присваивается весовой коэффициент по статистической модели, которая фиксирует, насколько успешно справился алгоритм с выявлением логических связей между двумя аналогичными фразами из этой области в “период обучения” Watson. Эта статистическая модель может быть использована впоследствии для определения общего уровня уверенности системы Watson в том, что возможный вариант ответа следует из вопроса.
6. Watson повторяет процесс для каждого возможного варианта ответа до тех пор, пока не найдет ответы, которые будут иметь больше шансов оказаться правильными, чем остальные.
Как уже говорилось выше, для правильного ответа на вопрос системе необходимо обращаться к дополнительным источникам данных. Это могут быть учебники, мануалы, FAQ, новости и все прочее. Watson за считанные секунды обрабатывает огромные массивы информации для получения правильного ответа. При этом найденное содержимое тоже проверяется, отсеиваются устаревшие и бесполезные данные.

Элементы когнитивной системы
Общий смысл текста Watson выводит из полученной информации, из дополнительной базы. При этом используется заголовок документа, часть текста документа или весь текст.
Когнитивные системы, их способы сбора, запоминания и извлечения информации схожи с тем, как анализирует информацию человек. При этом когнитивные системы могут передавать информацию и действовать. Вот примеры поведенческих конструктов, которые используются в этом случае:
— способность создавать и проверять гипотезы; — способность разбивать на составляющие и строить логические выводы о языке; — способность извлекать и оценивать полезную информацию (такую как даты, местоположения и характеристики).
Без этих способностей ни компьютер, ни человек не смогут определить правильную взаимосвязь между вопросами и ответами. Когнитивные процессы более высокого порядка могут достичь высокого уровня понимания, ориентируясь на основные способы поведения. Для того чтобы понять что-то, мы должны уметь разделить информацию на более мелкие элементы, которые достаточно хорошо упорядочены на рассматриваемом уровне. Физические процессы у человека протекают совсем не так, как процессы в космическом масштабе или на уровне элементарных частиц. Так же и когнитивные системы предназначены для работы на уровне человека, хотя они представляют огромное множество людей.
В связи с этим понимание языка начинается с понимания более простых правил языка – не только формальной грамматики, но и неформальных соглашений, которые наблюдаются в повседневном использовании.
Зачем все это?
Сейчас когнитивная система IBM Watson, благодаря многолетнему обучению и совершенствованию, может выполнять работу в самых разных сферах. Здесь и медицина, и кулинария, и лингвистика, и решение бизнес-задач с задачами научными.
Изначально у специалистов был выбор — сделать систему универсальной или специализированной. У каждого из вариантов есть свои достоинства и недостатки, но выбор был сделан в сторону универсальности.
Компания уже много раз убедилась в правильности совершенного выбора — перед IBM Watson открылось огромное количество возможностей. Например, когнитивная система помогает найти индивидуальный метод лечения раковых заболеваний, или составить оригинальнейший рецепт, или наладить бизнес-процесс в компании. Множество проблем решено, но еще больше только предстоит решить.



Долгая дорога доктора Ватсона
Под капотом Watson всегда был (и остается) программным продуктом DeepQA. Если простыми словами, DeepQA — это сложная архитектура программного обеспечения, которая анализирует, размышляет и отвечает на контент, который скармливают Watson. В 2012 году система работала на 80-терафлопсовом компьютере — машине, способной производить 80 000 000 000 000 операций в секунду — расположенном в Йорктаун Хайтсе, штат Нью-Йорк, с серверами в небольшой комнатке.
IBM считала, что Watson может стать «сверхспособной Siri для бизнеса», и он стал. Сегодня он обозначен как когнитивный компьютер для бизнеса. Или, если точнее, «платформа для когнитивного бизнеса».
Вот чем стал Watson: платформой.
Как и обещалось, Watson 2012 года получил мощное обновление. Он уменьшился в размерах, от большой спальни до четырех коробок из-под пиццы, и теперь доступен в облаке на планшете и смартфоне. Система на 240% продуктивнее своего предшественника и может обрабатывать 28 типов (или модулей) данных, по сравнению с 5, которые были раньше.
В 2013 году IBM открыла исходный код API Watson и теперь предлагает IBM Bluemix, комплексную облачную платформу для сторонних разработчиков для создания и запуска приложений на основе внушительных вычислительных возможностей Watson.
Но один из самых больших шагов, которые проделал Watson к своему нынешнему состоянию, произошел в 2014 году, когда IBM инвестировала 1 миллиард долларов в IBM Watson Group, большой отдел, посвященный работе Watson, на 2000 сотрудников.
В этот момент «доктор Ватсон» вышел из яслей стартапа и стал чувствовать себя значительно увереннее. В некотором смысле он стал «как IMB в каждом аспекте».
Перенесемся в 2021 год: сегодня Watson предлагает больше корпоративных сервисов и решений, чем могло бы уместиться в этой статье, — советник по финансам, автоматизированный представитель по обслуживанию клиентов, поисков — что бы вы ни назвали, Watson это умеет, скорее всего.
По мере развития технологии, стоящей за суперкомпьютером 2012 года, развивалось и позиционирование IBM Watson. И в большей степени это позиционирование касалось медицины.
Найти знаменитость, характер которой похож на характер пользователя

Это не самое серьезное и практичное приложение, но многим людям понравится. Сервис помогает найти знаменитость, которая больше всего по характеру похожа на характер пользователя определенного Twitter-аккаунта.
Приложение, как уже говорилось, не слишком серьезное, но технологии, которые за ним стоят — весьма сложные. Сервис способен обрабатывать огромные массивы данных, анализируя особенности сообщений пользователей Twitter для получения структурированной и пригодной для сравнения информации.
Исходный код: github.com/watson-developer-cloud/yourcelebritymatch
IBM Watson может помочь правильно организовать свой режим дня

Watson анализирует суточную активность пользователя, данные по сну и питанию. Эту информацию человек вводит в приложение, а когнитивная система оценивает и анализирует. Интересно еще и то, что приложение работает не только с данными своего пользователя, но и с информацией, полученной от других пользователей системы.
Еще Watson может дать характеристику личности человека, изучив его аккаунты в социальных сетях.
Или помочь выбрать подарок на праздники. Здесь используется API IBM Watson Trend, который помогает найти наиболее популярные товары в определенный момент времени.
И не стоит забывать о том, что IBM Watson может заменить собой целое справочное бюро.
Что такое когнитивные технологии?
Когнитивные технологии — это программные и аппаратные средства, которые имитируют работу человеческого мозга.
В скором будущем мыслящие системы приобретут мобильный формат, но пока это корпоративные суперкомпьютеры, функции которых доступны другим устройствам через облачные сервисы. Благодаря особой архитектуре когнитивные системы совмещают гигантские вычислительные мощности с инновационными способами обработки данных, похожими на наши мыслительные процессы. В перспективе от таких систем ожидают полноценного восприятия любой информации, представленной в привычном для человека виде. Это, к примеру, устная и письменная речь, визуальные образы, эмоции, чувства — все то, что помогает нам выражать мысли естественным путем.
Как и мы, когнитивные системы постоянно обучаются и автоматически приспосабливаются к работе с новыми данными и задачами, а не тупо следуют четким инструкциям программиста. У мыслящих машин есть и свои учителя — высоколобые люди с экспертными знаниями в определенных областях. С помощью пар вопросов и ответов такие наставники тренируют системы, учат правильно интерпретировать новую информацию, корректируют их работу. Взаимодействие с новыми данными и пользователями также способствует совершенствованию когнитивных систем.
Неудивительно, если дочитав до этого момента, вы вспомнили какой-нибудь монструозный SkyNet или недавние высказывания Хокинга и Маска насчет потенциальных угроз со стороны искусственного интеллекта. Эксперты по когнитивным системам спешат нас успокоить, дескать, мыслящие компьютеры лишены самосознания и личных мотиваций в привычном понимании этих понятий. По мнению доктора Джона Келли из компании IBM, которая имеет непосредственное отношение к когнитивным технологиям, не нужно противопоставлять машину человеку. Келли и его коллеги называют своей целью союз человека и машины, где последняя — только придаток, который должен расширить возможности первого.
Что в перспективе?
Сейчас IBM Watson является лидером в своей сфере — возможности этой когнитивной системы, конечно, не безграничны, но гораздо больше того, о чем мог мечтать человек еще недавно.
Ученые стараются использовать возможности системы для предсказания землетрясений или извержений вулканов в определенных регионах. Бизнесмены оптимизируют товарные потоки и выясняют, что будет наиболее популярно среди покупателей в ближайшее время. Медики вводят в практику индивидуальный подход лечения раковых и прочих заболеваний.
Как было показано выше, на основе IBM Watson созданы различные приложения и сервисы, которые облегчают человеку работу и делают жизнь более комфортной. Попробовать создать собственный сервис на основе Watson может практически любой разработчик, которому это интересно. Цель IBM на данном этапе – создать как можно более развитую экосистему приложений и сервисов, работающих с Watson, предоставив всем заинтересованным людям, ученым и бизнесменам надежного помощника, который способен справиться с большим количеством проблем и вопросов. И это уже не будущее, описанное фантастами, а настоящее.
Источник: justsurvivalcraft.ru
Отвечаем на вопросы читателей: что такое когнитивная система IBM Watson, и как она работает?

Александр Дмитриев
Добрый день, Хабрахабр! Сегодня о том, что собой представляет когнитивная система Watson и как она работает расскажет Александр Дмитриев, бизнес-консультант Клиентского центра IBM в Москве. Он ответит на вопросы, которые возникали у читателей по прочтении других материалов на эту тему.
Александр, на Хабре наши читатели регулярно задают вопросы, основной посыл которых можно уложить в один: «Что такое когнитивная система IBM Watson, и как она работает?» Помогите, пожалуйста, ответить на него.
Здравствуйте. Прежде всего, Watson в целом – это большой набор пакетов программного обеспечения, использующих самые разнообразные алгоритмы. Часть этих пакетов доступна в облаке, а часть – предназначена для местного развертывания. Компания IBM собрала разнообразные аналитические модули и построила систему, которая может справляться с поистине огромным количеством данных. Эта система работает как с цифровой, так и с текстовой информацией на различных языках, в том числе на русском – пока еще на базовом, но все же достаточно глубоком уровне.
При обработке информации устанавливаются связи и корреляции между самыми разными данными, событиями, фактами и явлениями. Одна из главных задач системы — выявление связей, которые незаметны простому глазу и которые не могут быть выявлены обычным способом, либо сделать это стандартными методами сложно. К примеру, если у какого-нибудь предприятия есть система мониторинга, которая выдает тысячи меняющихся параметров за минуту, то ни один аналитик не в состоянии проанализировать такую информацию оперативно. Инструментарий Watson же это позволяет сделать. Это если говорить об IBM Watson в целом.

Я видел вопросы относительно того, является ли Watson искусственным интеллектом. Отвечаю — нет, это не искусственный интеллект. Это – своеобразный усилитель естественного интеллекта человека, который позволяет быстрее обрабатывать информацию, охватывать большие объемы данных и находить то, что проходит мимо человеческого взгляда.
Станислав Лем писал об этом в своей книге «Сумма технологии»: «Человек непосредственно не может соперничать с Природой: она слишком сложна, чтобы он мог ей в одиночку противостоять. Образно говоря, человек должен построить между собой и Природой целую цепь из звеньев, в которой каждое последующее звено будет как усилитель Разума более мощным, чем предыдущее».
Как это делается и зачем? Существует система аналитики верхнего уровня на базе Watson и системы аналитики более мелких уровней. Последние фактически представляют собой поисковые и аналитические системы с определенной спецификой. Они решают прикладные задачи. Как это работает?
Заливаем большое количество информации определенной тематики в виде файлов распространенных форматов типа xls и csv. Загружаем эти данные в облако, после чего система Watson Analytics приступает к анализу этой информации, находя корреляции самостоятельно – с минимальным участием оператора. Это и есть небольшое, но очень важное отличие от других систем, поскольку здесь не просто поиск по ранее загруженным данным. Подчеркну – система сама анализирует загруженную информацию.
Что значит — сама? Система так настроена, что она просматривает все загруженные данные, проводит их очистку, указывая на технические проблемы вроде несовпадения форматов, пробелы, пропуски. Человек выбрасывает все экстремумы, которые являются ошибками или поводом для отдельного рассмотрения, выбирает метод обработки. Далее система занимается анализом данных, ищет корреляции, находит наиболее сильные и показывает оператору несколько гипотез с корреляциями, скажем, от 0,3 до 0,8.
Эти задачи я бы назвал условно задачами нижнего уровня. Они предназначены для того, чтобы упростить и ускорить работу аналитика. Рутинные операции автоматизируются самой системой. Это если говорить о Watson как системе поиска корреляций в массивах больших данных. То, на что шести аналитикам потребуется около недели, система IBM Watson Analytics через облако делает примерно за два часа.
Насколько сложно работать с Watson? Я однажды провел эксперимент, усадив за систему людей, более-менее разбирающихся в статистике. Они в первый раз видели интерфейс. Через полтора часа они уже самостоятельно и весьма активно работали с ней.
Верхний уровень — это большие системы, внедрение которых требует значительного времени (от полугода и выше). Их принцип работы основан на идее исследования Gartner, в котором говорится, что к 2030 году общая квалификация специалистов в большинстве индустриальных отраслей существенно снизится. Один из факторов этого можно пояснить.
Дело в том, что специалист, который привык (и которому по долгу службы нужно) постоянно пользоваться справочной информацией, уже не считает нужным помнить все то, что помнили специалисты «старой закалки» (от высоты стратосферы до точки кипения меди). Новое поколение охотно прибегает к интернету как к справочнику и не держит все необходимые знания в голове. Получается, что специалист становится в определенной степени зависим от машинных систем, а общий уровень его квалификации соответственно понижается. Это раз.

Второе, зачем нужны такие сложные системы? У нефтедобывающих и многих других корпораций огромная проблема — это передача информации от «поколения к поколению». Например, предыдущим коллективом сотрудников накоплен архив очень ценной технической информации. Но вот проблема — его никто в состоянии прочитать. Ведь на это нужно огромное количество времени.
Специалисту для того, чтобы с этой информацией, ознакомиться, потребуется несколько лет — это человек должен читать сутками напролет без еды и отдыха.
Так что, обучение новых работников – дорогостоящая проблема. Смена кадров на крупных предприятиях – тут могут быть сотни и тысячи специалистов в год. Ушел человек — и с ним ушел бесценный опыт и знания. Как передать опыт? Путем записей?
О них мы говорили выше.
Получается, что на уровне транснациональных корпораций, где огромное количество данных, номенклатуры, сотни тысяч человек персонала, требуется создать определенную систему, которая накапливала бы данные определенной тематической специализации. В идеале этой системой можно пользоваться не просто как справочником, но как справочником, который дает советы.
В чем же задача системы Watson верхнего уровня?
Огромное многообразие аналитических пакетов, входящих в общий инструментарий Watson, собираются воедино, из них выбираются нужные пакеты, которые будут обрабатывать информацию по определенному методу. Ну а в систему после этого загружаются данные любого типа — цифровые, протоколы совещаний, деловая переписка и переговоры, связи, контакты, цены, номенклатура оборудования, учебники по нефтяной промышленности, отчеты за различные периоды времени. На это может потребоваться больше года, но в результате создается пул основной базы знаний корпорации, которым можно активно пользоваться.
После этого настраиваются алгоритмы, которые позволяют анализировать информацию, детализировать ее, выделять и строить дерево актуальных тем — для той же «нефтянки» это наладка оборудования, разработка пластов, статистика, тенденции в технологиях и т.п. Все это собирается по темам, создается система подсказок. Системы такого рода, разработанные специалистами IBM, уже функционируют в ряде корпораций, включая австралийскую компанию Woodside Petroleum.

Сказанное выше можно проиллюстрировать примером. Есть главный инженер на предприятии, он дает задание пробурить скважину в пласте, по которому есть актуальные данные. Тот, кому дали задание, обращается к системе на естественном языке: «Что нужно сделать, чтобы пробурить скважину в таком пласте до такой-то глубины?» И система дает ответ, она работает как подсказка по конкретной нефтяной задаче. Сконфигурированная для «нефтянки» система делает подборку документации с выводами, и «говорит» — вот раньше поступали так, но при этом возникали такие-то проблемы, которые можно решить вот так. Вот это и есть система Watson — она подсказывает то, что человеку нужно делать в конкретном случае, выступает в качестве помощника.
Может ли система Watson работать онкологом, метеорологом, кем-то еще?
В качестве советника или помощника – да, безусловно. Под IBM Watson понимается общая система продуктов для любых прикладных сфер. Но в каждом конкретном случае необходимо настраивать систему для решения специфических вопросов.
В случае онкологии — это создание базы данных по конкретному заболеванию, например, раку легкого. В систему загружают огромное количество данных, включая деперсонализированные истории болезней пациентов. После этого врач задает вопрос о методе лечения конкретного пациента, и система дает ответ с учетом индивидуальных особенностей человека. Watson не берет на себя функции врача – все равно именно врач будет ставить диагноз и назначать лечение, но она помогает персонализировать лечение, очистить необходимые данные от ошибок и сделать подборку наилучших на данный момент вариантов лечения именно этого пациента.
Это важно, что система также проверяет все данные на легитимность и ошибки, поскольку в тех же врачебных данных могут быть ошибки. Проблема врачей (да и не только врачей, а современных специалистов вообще) еще в том, что они не успевают обучаться всему новому. Это не их вина.
Просто если есть много работы, а у квалифицированного специалиста она всегда есть, то времени для обучения не хватает. Поэтому те же врачи часто используют не самые современные методы. А система Watson может предложить новый метод лечения, даже несколько методов, с определенной вероятностью излечения пациента и фиксированной степенью риска для его здоровья.
И врач, посоветовавшись с пациентом или родственниками больного, может принять решение на основе этих данных. Еще раз стоит подчеркнуть, что ответственность лежит на враче, ведь ответы системы носят рекомендательный характер. Врачу система помогает, предоставляя самую новую информацию о том, какие методы подходят для конкретного больного.
Каким образом IBM Watson работает с естественным языком? Может ли система понимать контекст литературного произведения?
Однозначно, да. Но вопрос — зачем? Еще вопрос — кому это нужно, и кто за это платит? При работе с языком в плане обработки литературного произведения необходимо рассматривать текст в связи с историческим контекстом самой работы. Система может все понимать, если ей поставить такую задачу, включая произведения О. Генри, переводы которого лучше всего получались у Корнея Чуковского.
Нужно сказать, что системы, работающие с языком, так же настраиваются и обучаются. В простейшем случае это тривиальный парсинг, то есть разбор очистка текста от излишней информации. Что касается Watson, то это, в первую очередь, создание словарей разных языков. Систему в любом случае нужно обучать с прицелом на конкретную задачу.
Я лично участвовал в проекте эмоционального анализа. Сегодня Watson улавливает эмоциональную окраску текста. Например, она научилась определять иронию. В целом, здесь снова речь заходит о выявлении корреляций. Что касается той же иронии — ее придумали еще древние греки.
Кажется, любой человек распознает ее по каким-то определенным признакам. Если машину научить улавливать эти признаки, она тоже научится определять иронию.
Повторюсь, возможности системы определяются актуальностью решаемой задачи. В основном, в помощи IBM Watson нуждаются крупные компании, которым вряд ли нужно в первую очередь определять иронию в отчетах своих сотрудников (хотя и такое, наверное, бывает). А вот для них, в случае необходимости, мы настраиваем систему таким образом, чтобы она могла определять отношение пользователей/покупателей к брендам и продуктам компаний.

Пример: в Испании более двух лет назад был реализован крупный проект по оценке отношения пользователей к бренду. Заказчиком выступала крупная компания, которая попросила проанализировать отношение к ней по различным источникам, включая социальные сети, газеты, журналы и т.п. Это было с успехом проделано. В ходе такой работы мы выделяем и анализируем ложные данные, которые имеют отношение к подделкам, которые бросают тень на репутацию оригинального бренда. В настоящий момент этой системой пользуются известные мировые бренды, проект очень удачный и позволяет повышать эффективность продаж.
В целом, Watson решает конкретные задачи. Делать система может многое, что именно — определяется в зависимости от общей постановки задачи и ее направленности.
Вопрос — границы возможности системы. Возьмем пример — если взять того же О. Генри, можно ли настроить Watson на литературный перевод произведений этого автора, и сколько времени на это потребуется? Скажем, это понадобилось издательству, которое готово за это платить.
Ответ — однозначно можно. Но я не могу ответить точно, сколько времени на это потребуется. Это вопрос усилий и вложений.
Любая специализированная система Watson, будь то «медик», «финансовый аналитик» или «инженер» требует участия специалистов. В этом случае я бы набирал команды лучших лингвистов по теории и практике языка. Часть команд будет составлять словари, идиомы, искать данные по текстам, корреляции между русскими словами и английскими. Зачем?
Одно слово на любом языке может значить очень многое. В словари и будут попадать такие слова, с указанием максимально обширного спектра их знания.
После этого нужно приступить к решению второй задачи. А именно — загнать в базу тексты переводов О. Генри, которые считаются наиболее качественными и удачными. Затем Watson для поиска подходящих по смыслу слов будет использовать методику оценки корреляций с максимальными значениями.
Выбирать система будет различные варианты перевода от простого к сложному (слова, фразы, предложения и т.д.). В ходе этого процесса понадобятся группы экспертов, которые будут дополнительно обучать систему. Они будут корректировать переводы, проводить тонкую настройку для того, чтобы после такого обучения система Watson начала давать действительно хорошие переводы.
Это так и работает — первый перевод будет не очень хорошим, второй — получше, а потом — очень хорошим. Большой плюс Watson в том, что систему можно донастраивать, благодаря обратной связи. Ведь без обратной связи система просто потеряет управление. Обратная связь позволяет системе в динамике, в ходе работы уточнять и корректировать основную цель.
В нашем случае обратную связь обеспечивают специалисты в предметной области. Если это нефтяная компания, как Woodside, то лучшие эксперты будут отмечать лучшие, удачные ответы системы, и система это будет запоминать, постепенно улучшая качество выдаваемых рекомендаций. Так что у Watson есть еще одно преимущество. Если большинство систем со временем устаревает и требует переделки, то данная система со временем только набирается опыта и становится еще мощнее.
Еще вопрос — есть ли какие-то задачи, которые Watson не может решить сейчас ни при каких условиях?
Есть очень важный аспект — этический. Часть задач нерешаема потому, что существующие вопросы выходят за рамки технических систем. В качестве примера можно привести робомобиль. Грубо говоря – на кого или во что наедет автомобиль, если невозможно избежать столкновения, но есть выбор – скажем, в стену, пожилого человека или беременную женщину?
Водитель-человек ведь все равно сделает свой выбор. Но машина — нет, она выбор сделать не может, поскольку этот вопрос пока не решен ни юридически, ни этически. И в машину эти знания и правила поведения в экстремальных ситуациях просто пока нельзя заложить. Это первый класс задач, пока не решаемых, поскольку не решен целый ряд этических, юридических, социальных и других проблем, связанных с самими задачами.

Второй класс — чрезвычайно сложные технические задачи, которые потребуют огромного количества ресурсов. Для того, чтобы понять, есть ли решение такой задачи, нужно хотя бы попробовать ее решить. Пример — тот же, что и с текстами О. Генри. Пока этого никто не делал. Вероятно, если постараться, то все получится, но точно мы сказать сейчас не можем.
Подводя итог сказанному, я хочу высказать уверенность в том, что решить можно практически любую задачу. Если сейчас кажется, что на какой-то вопрос нельзя получить ответ, спустя время находится человек, который дает идею, открывающую невиданные прежде возможности. Пример: одно время считали, что состав звезд определить нельзя, и этого нельзя будет сделать никогда. Но вскоре изобрели спектрограф, и тут же определили, что превалирующий элемент в составе звезды — гелий. Спустя некоторое время состав звезд научились очень точно определять.
Регулярно находятся решения, которые кардинально меняют видение нашего мира. Границы возможного установить сложно и, честно говоря, я бы их даже не ставил.
Каким вы видите IBM Watson в будущем?
Как уже говорилось выше, Watson в общем виде можно описать как систему, которая помогает человеку принять решение в условиях большой неопределенности. Я полагаю, что, как и все другие системы, она станет существенно дешевле, станет более универсальной, ее можно будет использовать в других сферах.
Я думаю, что это будет универсальная система подсказок, которая сможет отвечать на широчайший круг вопросов и которая станет нам привычной. Причем отвечать она будет не так, как современные поисковики — не просто давать ссылки на источники в интернете, а предоставлять рекомендации с указанием источника информации и используемых методик.
- IBM watson
- когнитивные системы
- облачные сервисы
- будущее
Источник: habr.com
Искусственный интеллект на примере IT-гиганта. IBM и её проект Watson

Являясь одним из лидеров в области инновационных технологий, компания IBM традиционно уделяет особое внимание развитию искусственного интеллекта. По данным аналитической организации Venture Scanner, в 2016 общее количество патентов IBM, связанных с искусственным интеллектом, приблизилось к 500, и это абсолютный рекорд отрасли.
Искусственный интеллект IBM. Суперкомпьютер Watson
Лицом искусственного интеллекта IBM является суперкомпьютер Watson. Разработка данного суперкомпьютера велась на протяжении трех лет и стоила компании порядка $20 млрд. Большую известность Watson получил после 2011 года, когда он сумел выиграть людей в телевикторине Jeopardy! (российский аналог «Своя игра»). Именно эта победа продемонстрировала высокий уровень интеллектуальности созданной машины. Примечательно, что компания любит принимать участие в подобного рода мероприятиях. Так, в 1997 году предшественник Watson, суперкомпьютер Deep Blue, сумел обыграть в шахматы Гарри Каспарова. 
Шахматный матч между Deep Blue и Гарри Каспаровым Однако в отличие от игры в шахматы, где от компьютера требовалось всего лишь соблюдать правила игры, в телевикторине Jeopardy задача у Watson была гораздо труднее. Прежде, чем найти ответы на поставленные вопросы, суперкомпьютеру необходимо было понять их суть. Основная сложность здесь заключалась в том, что все вопросы задавались исключительно на естественном языке без каких-либо упрощений и уточнений. Естественный язык имеет большое количество специфических особенностей, понять который компьютеру очень сложно. Горло мы можем назвать лужённым, а ногу – широкой. Выражения «высокий голос» и «тонкий голос» являются одинаковыми по смыслу, в то время как «умник» и «умница» имеют противоположные значения. Несмотря на упомянутые сложности, Watson не только победил в телепередаче, но и сумел сделать это, имея в соперниках рекордсменов игры: Брэда Раттера — обладателя самого большого денежного приза в программе, и Кени Дженнинга, имеющего самую длительную беспроигрышную серию. Чтобы добиться такого успеха разработчики использовали в системе технологию, позволяющую проводить глубокий анализ естественного языка. 
Watson выигрывает в игре Jeopardi. Источник Watson2016.com Упрощённый алгоритм работы Watson при ответе на вопрос, заданный на естественном языке, выглядит следующим образом:
- В каждом вопросе выделяются его основные синтаксические особенности.
- Анализируя базу данных с фразами, в которых с определённой долей вероятности может содержатся правильный ответ, система выдвигает ряд гипотез (вариантов ответа).
- Происходит глубокое сравнение языка, на котором был задан вопрос, с языками, на которых содержится каждый один из возможных вариантов ответа. Для этого применяются различные алгоритмы определения логических связей. В системе содержатся сотни таких алгоритмов, и все они направлены на различную группу сравнений. Например, одни направлены на поиск совпадающих терминов и синонимов, другие рассматривают временные и пространственные особенности, третьи анализируют подходящие источники контекстуальной информации.
- По результатам анализа, каждый логический алгоритм выставляет одну или несколько оценок, отражающих степень соответствия найденного ответа заданному вопросу.
- Каждой оценке ставится в соответствие определённый весовой коэффициент. При этом используется статистическая модель, фиксирующая успешность работы каждого алгоритма при выявлении логических связей. Впоследствии данная модель используется для определения общего уровня уверенности Watson в том, что найденный ответ действительно является верным.
- Пункты 3-5 повторяются до тех пор, пока система не найдет ответ, который имеет наибольшие шансы оказаться правильным.
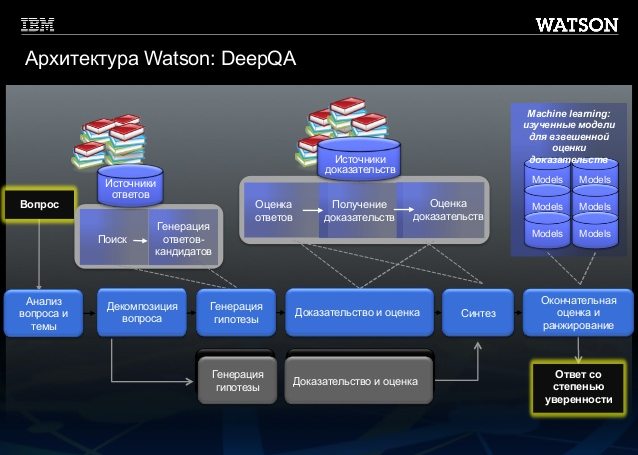
Система работы Watson
Коммерческое использование Watson
Безусловно, передача Jeopardy была для IBM лишь полигоном, где можно было наглядно продемонстрировать всему миру уникальные возможности разработанной машины. Американский гигант ещё на этапе создания Watson предполагал его использовать в коммерческих целях. В январе 2014 года был создан отдел IBM Watson Group, специализирующийся исключительно на разработке передовых когнитивных сервисов на платформе суперкомпьютера. В данное подразделение американский гигант инвестировал порядка $1 млрд, рассчитывая на основе разработанных сервисов получать около $10 млрд выручки ежегодно к 2024 году.
Когнитивные технологии предполагают использование совершенно новой модели проводимых вычислений, основанной на технологических инновациях в аналитике, машинном обучении и анализе естественного языка. Аналитическое агентство IDC прогнозирует, что к 2018 году когнитивными системами так или иначе будут пользоваться около половины потребителей по всему миру. Исходя из этого, в конце 2015 года IBM создал специальный отдел Cognitive Business Solutions, основной задачей которого является консультирование корпоративных клиентов о том, насколько им будет выгодно использовать в своём бизнесе когнитивные вычисления IBM Watson. Данное подразделение включает в себя около 2 тысяч сотрудников, что показывает высокую заинтересованность американского гиганта в данном сегменте бизнеса. Основной упор в когнитивных вычислениях компания планирует сделать на бизнес-аналитику, информационную безопасность и IoT-технологии.
«Анализируя наше взаимодействие с корпоративными клиентами, мы понимает, что когнитивные технологии являются следующим поколением в разработке решения для бизнеса. Наши клиенты осознают, что сегодня им приходится обрабатывать огромные объёмы данных. Около 80% таких данных являются изображениями, голосовыми записями, книгами, химическими формулами, разговорными выражениями.
Информацию такого типа традиционные системы обработать не в состоянии. И здесь на помощь приходят когнитивные технологии. Опираясь на собственный опыт, мы помогаем нашим клиентам становиться “интеллектуальными” банками, розничными магазинами, автопроизводителями, страховыми компаниями и медицинскими учреждениями», – рассказал Бриджит ван Кралинген, старший вице-президент подразделения IBM Global Business Service.
Области применения Watson
Сочетание в одной платформе возможностей анализа естественного языка, построения и оценки гипотез при обработке больших объёмов данных, а также динамического обучения на основе полученных результатов делают Watson по-настоящему уникальной системой, позволяющей повысить интеллектуальность практически любой компании. При этом разработчики с каждым годом повышают возможности системы, позволяя ей анализировать не только речь, но и другие типы информации, такие как текст, видео, картинки, и др. Всё это даёт возможность Watson решать самые разные и сложные задачи.
В розничной сфере IBM разработала на основе Watson решение, позволяющее анализировать не только данные клиента, но и информацию внешних источников, включая прогноз погоды и результаты опроса общественного мнения. Как итог, у заказчика появляется возможность оперативно определить изменения спроса на какую-либо продукцию и получить подробные рекомендации касательно различных вопросов (например, четкий алгоритм действий для повышения цены на продукт).
Для страховых клиентов используется способность Watson понимать естественный язык. В процессе онлайн-общения система отвечает на вопросы пользователей и предоставляет консультации касательно продукции компании. В сфере образования система применяется для персонализации учебной программы для школьников и студентов. В финансовой сфере система эффективно управляет рисками, определяет потенциальные объекты для инвестиций и подготавливает соответствующие рекомендации.
Крайне интересны факты использования Watson в здравоохранении – сфере с проблемой низкой информационной поддержки. С одной стороны, в данной области имеется большое количество книг и журналов, описывающих различные клинические случаи и заключения экспертов. С другой стороны, каждый пациент имеет свою собственную медницкую карту, включающую в себя его истории болезней и генетические особенности. Проанализировать такой большой объём информации врач не в состоянии, что может привести к ошибочному диагнозу и неверному методу лечения заболевания. Решением этой проблемы и занимается подразделение IBM Watson Health, которое было создано в апреле 2015 года.
«Нашей задачей является анализ “сырых” исходных данных с целью помочь врачам лучше диагностировать больных. В настоящий момент к нашей партнёрской программе в области здравоохранения присоединилось более 15 крупнейших мировых клиник и лечебных учреждений. Используя платформу Watson Health, все они успешно диагностируют пациентов, постепенно увеличивая область применения», – Роберт Меркель, вице-президент компании IBM Watson Health.
В 2015 году Роберт Меркель заявил, что IBM готова предложить свои когнитивные системы в области здравоохранения и для российской медицины. В частности, на первом этапе речь идет о решениях Watson Health в области лечения онкологических заболеваний.
Помимо лечения больных, IBM ведет работу для использования Watson в качестве средства, позволяющего обычным людям вести здоровой образ жизни, а спортсменам ещё более продуктивно использовать свои возможности. Упрощённый пример данной области применения представлен на следующем видео, на котором Watson даёт рекомендации Сирене Уильямс.
В 2015 году IBM объявила о создании подразделения Watson Internet of Things (Watson IoT). На сегодняшний день насчитывается порядка 9 млрд. устройств Интернета вещей, которые ежедневно генерируют около 2,6 квинтильона байт данных. Возможность выявить связи и закономерности в такого рода информации создает хорошую почву для дальнейшего развития области IoT.
«Совсем скоро Интернет вещей будет являться крупнейшим источником данных в мире. Однако, пока мы не используем около 90% такого рода информации. Уникальная возможность Watson анализировать эти данные позволяет обнаружить неожиданные корреляции, которые дадут возможность сделать ценные выводы и оказать положительное влияние как на бизнес, так и на общество в целом», – Гарриет Грин, руководитель подразделения IBM Watson IoT.
Новые предложения для разработчиков, работающих в сфере IoT, доступны на облачной платформе IBM Watson IoT Cloud. Помимо этого, американский гигант на этой платформе сделал доступ к API. В результате, специалисты различных компаний, старатаперы и представители научных кругов получили возможность разрабатывать и создавать когнитивные приложения и сервисы Интернета Вещей нового поколения. В компании считают, что наибольшую выгоду от платформы IBM Watson IoT Cloud могут получить представители автомобильной отрасли, электроники, здравоохранения, страхования и промышленности.
В настоящий момент Watson является одним из лидеров на рынке когнитивных систем. При этом, по словам представителей компании, основная цель данной системы — не заменить человека для решения каких-то задач, а улучшить процесс принятия им решений благодаря наличию дополнительной информации. Watson имеет возможность проанализировать миллионы факторов, выявить корреляцию между ними и предложить определённые решения, которые многократно проверяются с помощью соответствующих моделей.
IBM создала для разработчиков отличные условия для разработки собственных сервисов на основе Watson. В настоящий момент, платформа IBM Watson включает в себя несколько десятков сервисов, заточенных для решения различных задач. Чтобы не запутаться в этих сервисах и дать разработчикам возможность их комбинировать, IBM создала соответствующий набор инструментов — Watson Knowledge Studio. На сегодняшний день, сообщество Watson включает в себя около 80 000 разработчиков, исследователей, ученых и предпринимателей по всему миру.
Как заявила генеральный директор IBM Джинни Рометти, в ближайшее время все наработки компании в области искусственного интеллекта Watson останутся открытыми. Также Рометти убеждена, что искусственный интеллект будет иметь все больше влияние в жизни людей.
«Полагаю, что никто не сомневается в том, что высокоинтеллектуальные машины будут в ближайшее время оказывать всё больше влияния на все сферы общественной жизни», – генеральный директор IBM Джинни Рометти
По словам представителей IBM, компания ежегодно выделяет около $5 млрд. на новые разработки. При этом, около 2/3 данного бюджета расходуются на технологии, позволяющие проводить сбор и обработку данных, аналитику и когнитивные исследования. Львиная доля этих средств идет на развитие системы Watson.
Источник: iot.ru