

Современные бизнес приложения имеют сложную структуру, состоят из множества независимых компонентов, часто распределенных по разным узлам, контейнерам или виртуальным машинам. В связи с этим, поиск неисправностей в таких серьезных приложениях становится тоже непростой задачей, зачастую превращающейся в нетривиальный квест. При этом не стоит забывать, каждая минута простоя приложения в продакшене стоит денег, поэтому выявлять причины сбоев необходимо как можно быстрее. В этой и последующих статьях мы поговорим о том, как производить мониторинг работы приложений, осуществлять сбор событий и трейсинг для решения конкретных проблем в работе приложения. Эти статьи ориентированы на специалистов, занимающихся администрированием Linux, хотя о Windows мы тоже будем иногда упоминать.
Эта статья будет посвящена мониторингу. Мы поговорим о том, зачем вообще нужно мониторить активность приложений, как это лучше делать и какие средства лучше использовать.
Программа мониторинга, парсинга объявлений на авито — AvitoAvtoRinger (Стоп и целевые слова)
Что мониторить
Какие проблемы могут возникнуть в работе приложения или веб сайта? Прежде всего, сайт может начать тормозить. Те, кто застал времена диалапа наверняка помнят, как бесила медленная загрузка какого-нибудь сайта.
Так что, если ваш веб сайт медленно открывается, то вряд ли пользователи будут это долго терпеть и скорее всего, воспользуются другими, аналогичными ресурсами, которые не тормозят. Другая, не менее неприятная проблема, это когда сайт не тормозит, но работает неправильно. Не сохраняет данные, введенные пользователями, неправильно выводит результаты поиска и т.д. В такой ситуации пользователи тоже не будут долго терпеть и пойдут к конкурентам. Про случай, когда сайт просто лежит или приложение не открывается я думаю говорить не стоит, все понятно и так.
Между тем, у приведенных выше проблем в работе могут быть различные причины. Сайт может тормозить из-за медленного канала связи, низкой производительности веб-сервера, отказа одного из компонентов приложения и т.д. Для того, чтобы быстро выявлять причины сбоев нам необходимо получать обратную связь от инфраструктурных компонентов ОС, железо, СХД, сеть.
Также необходимо следить за работой и состоянием поддерживающих сервисов. То есть, если приложение использует например Nginx, MySQL, то работу этих компонентов тоже необходимо мониторить. Ну и естественно, нужно мониторить работу самого приложения. Что, где и как работает.
Если необходимость мониторинга представленных выше элементов обычно не вызывает вопросов, то о мониторинге деплоя частот забывают, а зря. Как мы уже говорили, каждая минута простоя стоит денег, и это относится не только к простою самого приложения, но и к простоям программистов, разрабатывающим его. Если у нас проблемы например с Jenkins, то разработчики не могут выкладывать код и процесс разработки останавливается. Поэтому важно осуществлять мониторинг компонентов процесса деплоя, для того чтобы этот процесс был непрерывными.
Системы мониторинга серверов в локальной сети
Еще один вид мониторинга, неочевидный для технарей это мониторинг бизнес метрик и поведения пользователей. Бизнес тоже интересуют многие параметры работы приложения, связанные с деньгами. Например, если взять веб сайт интернет магазина, то бизнес интересует, сколько денег мы зарабатываем по будням, выходным, в определенные временные интервалы и т.д.
Как не странно, эти бизнес метрики тоже могут помочь технарям. Например, в ситуации, когда в “высокий период” у нас вдруг перестали обновляться данные о заработанных деньгах. То есть по факту продажи идут, но в системе это никак не фиксируется. Это явный признак того, что в нашей системе не работает компонент учета платежей.
Надеюсь, все вышесказанное убедило читателя в том, мониторинг необходим. И подводя итог, предлагаю такое определение мониторинга: Мониторинг это совокупность инструментов и практик, позволяющая осуществлять контроль над работой IT систем и давать оценку качества работы этих систем.
Виды мониторинга
Собирать метрики с целевых систем можно по-разному. В случае, если наша система представляет собой “черный ящик”, то есть у нас нет доступа к исходному коду, и мы не можем вести мониторинг отдельных компонентов. В таком случае, мы можем вести мониторинг наличия процесса, доступности портов, собирать метрики по загруженности памяти, посчитывать коннекты и т.д. То есть, по сути, мы можем мониторить только службы ОС и инфраструктурные компоненты.
Недостатки такого подхода очевидны: мы не можем сказать, какой именно из внутренних компонентов нашей системы работает неправильно. То есть, мы можем сказать, что наше приложение расходует, к примеру более 90% памяти, но сказать какой именно компонент кушает слишком много мы не можем. То есть, мониторинг методом “черного ящика” позволяет получить общую информацию о состоянии узла, но для детального мониторинга он не пригоден.
Мониторинг методом “белого ящика” дополняет blackbox и собирает информацию о внутренней работе системы. Этот метод мы можем использовать тогда, когда нам доступны метрики с компонентов системы, такие как время запроса к БД, расход памяти при выполнении отдельных операций, количество пользователей в приложении и т.д.
Архитектура системы мониторинга
Система мониторинга Zabbix для начинающих

Zabbix — это универсальный инструмент мониторинга, способный отслеживать динамику работы серверов и сетевого оборудования, быстро реагировать на внештатные ситуации и предупреждать возможные проблемы с нагрузкой. Система мониторинга Zabbix может собирать статистику в указанной рабочей среде и действовать в определенных случаях заданным образом.
В этой обзорной статье расскажем об основных принципах и ключевых инструментах, на которых построена универсальная система мониторинга Zabbix.
Обзор
Систему создал Алексей Владышев на языке Perl. Впоследствии проект подвергся серьезным изменением, которые затронули и архитектуру. Zabbix переписали на C и PHP. Открытый исходный код появился в 2001 г., а уже через три года выпустили первую стабильную версию.
Веб-интерфейс Zabbix написан на PHP. Для хранения данных используются MySQL, Oracle, PostgreSQL, SQLite или IBM DB2.
На данный момент доступна система Zabbix 4.4. Скачать ее можно на официальном сайте. Там же можно найти официальные курсы и вебинары для начинающих пользователей системы.
Далее рассмотрим, из чего состоит и как работает технология Zabbix в доступном формате «для чайников».
Архитектура Zabbix
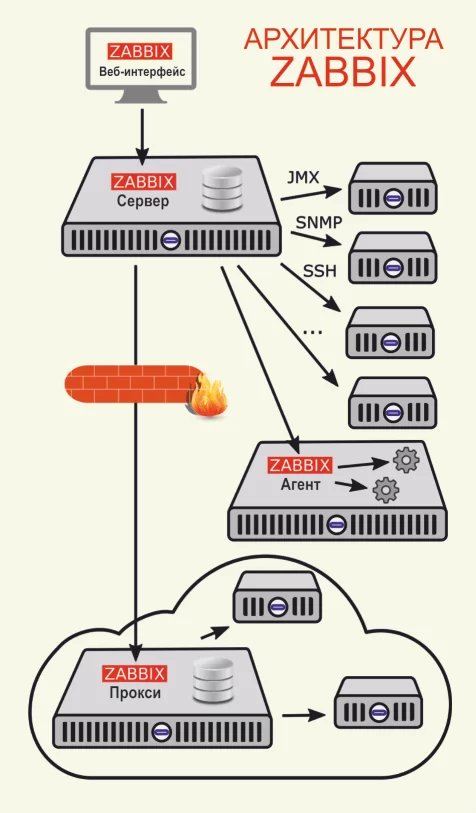
У Zabbix есть 4 основных инструмента, с помощью которых можно мониторить определенную рабочую среду и собирать о ней полный пакет данных для оптимизации работы.
- Сервер — ядро, хранящее в себе все данные системы, включая статистические, оперативные и конфигурацию. Дистанционно управляет сетевыми сервисами, оповещает администратора о существующих проблемах с оборудованием, находящимся под наблюдением.
- Прокси — сервис, собирающий данные о доступности и производительности устройств, который работает от имени сервера. Все собранные данные сохраняются в буфер и загружаются на сервер. Нужен для распределения нагрузки на сервер. Благодаря этому процессу можно уменьшить нагрузку на процессор и жесткий диск. Для работы прокси Zabbix отдельно нужна база данных.
- Агент — программа (демон), которая активно мониторит и собирает статистику работы локальных ресурсов (накопители, оперативная память, процессор и др.) и приложений.
- Веб-интерфейс — является частью сервера системы и требует для работы веб-сервер. Часто запускается на том же физическом узле, что и Zabbix.
Основные возможности
Функционал включает в себя общие проверки для наиболее распространенных сервисов, в том числе СУБД, SSH, Telnet, VMware, NTP, POP, SMTP, FTP и т.д. Если стандартных настроек системы недостаточно, их можно изменить самостоятельно или же пользоваться дополнением через API.

Стандартные функции системы
- Контроль нагрузки на процессор, касается и отдельных процессов.
- Сбор данных об объеме свободной оперативной и физической памяти.
- Мониторинг активности жесткого диска.
- Мониторинг сетевой активности.
- Пинг для проверки доступности узлов в сети.
Проверки
Для описания системы мониторинга Zabbix существует два ключевых понятия:
- Узлы сети — рабочие устройства и их группы (серверы, рабочие станции, коммутаторы), которые необходимо проверять. С создания и настойки узлов сети обычно начинается практическая работа с Zabbix.
- Элементы данных — набор самостоятельных метрик, по которым происходит сбор данных с узлов сети. Настройка элементов данных производится на вкладке «Элемент данных» или в автоматическом режиме — через подключение шаблона.
Сам Zabbix-агент способен отражать текущее состояние физического сервера, собирая совокупность данных. У него достаточно много метрик. С их помощью можно проверить загруженность ядра (Processor load), время ожидания ресурсов (CPU iowait time), объем системы подкачки (Total swap space) и многое другое.
В Zabbix существует целых 17 способов, дающих возможность собирать информацию. Указанные ниже, входят в число наиболее часто применяемых.
- Zabbix agent (Zabbix-агент) — сервер собирает информацию у агента самостоятельно, подключаясь по определенному интервалу.
- Simple check (Простые проверки) — простые операции, в том числе пинг.
- Zabbix trapper (Zabbix-траппер) — сбор информации с трапперов, представляющих собой мосты между используемыми сервисами и самой системой.
- Zabbix aggregate (Zabbix-комплекс) — процесс, предусматривающий сбор совокупной информации из базы данных.
- SSH agent (SSH-агент) — система подключается по SSH, использует указанные команды.
- Calculate (Вычисление) — проверки, которые система производит, сопоставляя имеющиеся данные, в том числе после предыдущих сборов.
У проверок есть заданные шаблоны (Templates), которые упрощают создание новых. Кроме обычных операций существует возможность регулярно проверять доступность веб-сервера с помощью имитации запросов браузера.
Проверка через пользовательский параметр
Чтобы выполнить проверку через агент, нужно прописать соответствующую команду в конфигурационный файл Zabbix-агента в качестве пользовательского параметра ( UserParameter ). Сделать это можно с помощью выражения следующего вида:
UserParameter=,
Помимо самой команды, приведенный синтаксис содержит уникальный (в пределах узла сети) ключ элемента данных, который надо придумать самостоятельно и сохранить. В дальнейшем, ключ можно использовать для ссылки на команду, внесенную в пользовательский параметр, при создании элемента данных.
Пример
UserParameter=ping,echo 1
С помощью данной команды можно настроить агент на постоянное возвращение значения « 1 » для элемента данных с ключем « ping ».
Триггеры
Это логические выражения со значениями FALSE , TRUE и UNKNOWN , которые используются для обработки данных. Их можно создать вручную. Перед использованием триггеры возможно протестировать на произвольных значениях.
У каждого триггера существует уровень серьезности угрозы, который маркируется цветом и передается звуковым оповещением в веб-интерфейсе.
- Не классифицировано (Not classified) — серый.
- Информация (Information) — светло-синий.
- Предупреждение (Warning) — жёлтый.
- Средняя (Average) — оранжевый.
- Высокая (High) — светло-красный.
- Чрезвычайная (Disaster) — красный.
Некоторые функции триггеров
- abschange — абсолютная разница между последним и предпоследним значением (0 — значения равны, 1 — не равны).
- avg — среднее значение за определенный интервал в секундах или количество отсчетов.
- delta — разность между максимумом и минимумом с определенным интервалом или количеством отсчетов.
- change — разница между последним и предпоследним значением.
- count — количество отсчетов, удовлетворяющих критерию.
- date — дата.
- dayofweek — день недели от 1 до 7.
- diff — у параметра есть значения, где 0 — последнее и предпоследнее значения равны, 1 — различаются.
- last — любое (с конца) значение элемента данных.
- maxmin — максимум и минимум значений за указанные интервалы или отсчеты.
- now — время в формате UNIX.
- prev — предпоследнее значение.
- sum — сумма значений за указанный интервал или количество отсчетов.
- time — текущее время в формате HHMMSS.
Прогнозирование
Триггеры обладают еще одной важной функцией для мониторинга — прогнозированием. Она предугадывает возможные значения и время их возникновения. Прогноз составляется на основе ранее собранных данных.
Анализируя их, триггер выявляет будущие проблемы, предупреждает администратора о возникшей вероятности. Это дает возможность предотвратить пики нагрузки на оборудование или заканчивающееся место на жестком диске.
Функционал прогнозирования добавили с обновлением системы 3.0, вышедшим в феврале 2016 года.
Действие
Действие (Action) представляет собой заданную реакцию на событие (Event). Действие может устанавливаться автоматически или вручную как для одного из событий, так и для целой группы.
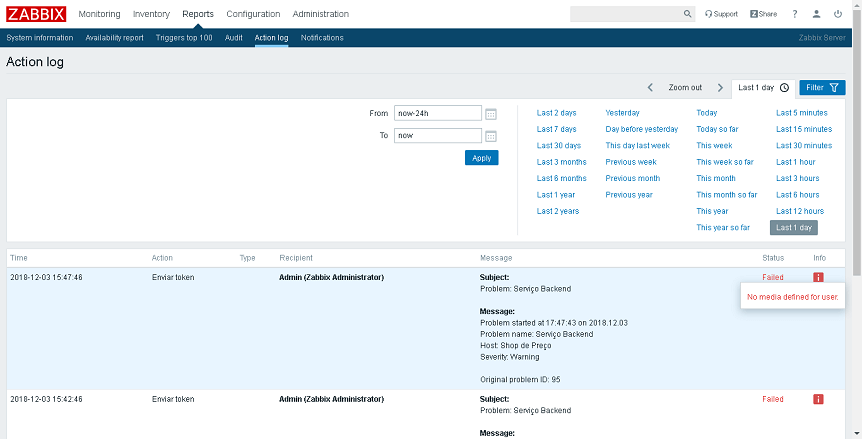
Параметры действий
- Name — имя действия.
- Event source — источник события. Источниками событий служат обнаружение (Discovery Events), авторегистрация (Auto registration Events) или заданный триггер (Trigger Events).
- Enable escalations — разрешение на эскалацию событий.
- Period — период времени для шага эскалации, указывается в секундах.
- Default subject — указывается, кто извещается по умолчанию.
- Default message — стандартный текст сообщения.
- Recovery message — текст уведомления после решения проблемы.
- Recovery subject — субъект, которого извещают после операции.
- Status — статус действия, может быть «активно» и «запрещено».
Для событий, вызванных триггером или обнаружением, есть свои типы условий. Например, «Application» с операторами « = », « like » и « not like » значит, что триггер является частью указанного приложения. Или «Service type» с операторами « = », « < »и « >» предусматривает, что обнаруженный сервис совпадает с указанным.
Операции
Пользователь может указать для событий операцию или группу операций.
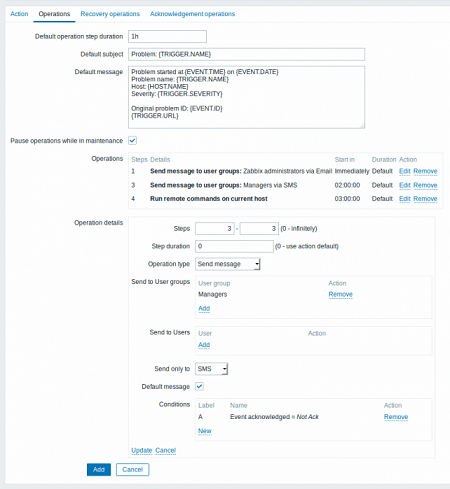
Параметры операций
- Step — при эскалации событий.
- Operation type — действия на определенном шаге, например, «Send message» или «Execute command».
- Event Source — источник событий.
- Send message to — отдельное сообщение (Single user) или групповое (User group).
- Default message — текст по умолчанию.
- Subject — кого оповещает система.
- Message — текст сообщения.
- Remote command — команда для удаленного управления.
Низкоуровневое обнаружение
Функция Низкоуровневого обнаружения (LLD) автоматически создает элементы и триггеры, которые позволяют отслеживать системы сервера, находящимся под наблюдением. Включение функции происходит через настройку атрибутов, которую можно сделать, пройдя по пути: «Настройка» → «Шаблоны» → «Обнаружение» (вкладка в строке с шаблоном) → вкладки «Правила обнаружения»/«Фильтры».
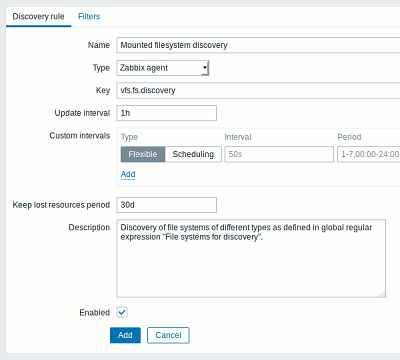
Что можно обнаружить
- Распространённые OID, используемые SNMP.
- Сетевые интерфейсы.
- Процессоры, их ядра.
- Файловые системы.
- Службы Windows.
- ODBC.
Дополнительные типы
Задать собственные типы низкоуровневого обнаружения возможно с применением формата JSON. Типы проверок, для которых можно указать список портов и интервал для них:
Если хост пропадает или обнаруживается, для события можно привязать любое действие — условия и операцию для них.
Прокси
Функция буферизации через прокси используется в том случае, когда существующая инфраструктура достаточно большая, а выделенный сервер не способен нести такую нагрузку. Прокси выступает промежуточным звеном, которое собирает информацию с агентов в буфер, а после отправляет данные на сервер.
Прокси используется еще в нескольких случаях — если агенты находятся далеко друг от друга или ограничены локальной сетью. Это сказывается на доступности агентов и величине пингов.
Zabbix прокси функционирует как демон. Для его использования обязательно наличие отдельной базы данных.
Особенности веб-интерфейса
Система мониторинга Zabbix располагает удобным веб-интерфейсом, в котором сгруппированы элементы управления. Консоль предусматривает просмотр собранных данных, их настройку. Для безопасности входа и работы осуществляется автоматическое отсоединение через 30 минут пользовательского бездействия.
На главном экране всегда представлена информация о состоянии узлов сети и триггеров.
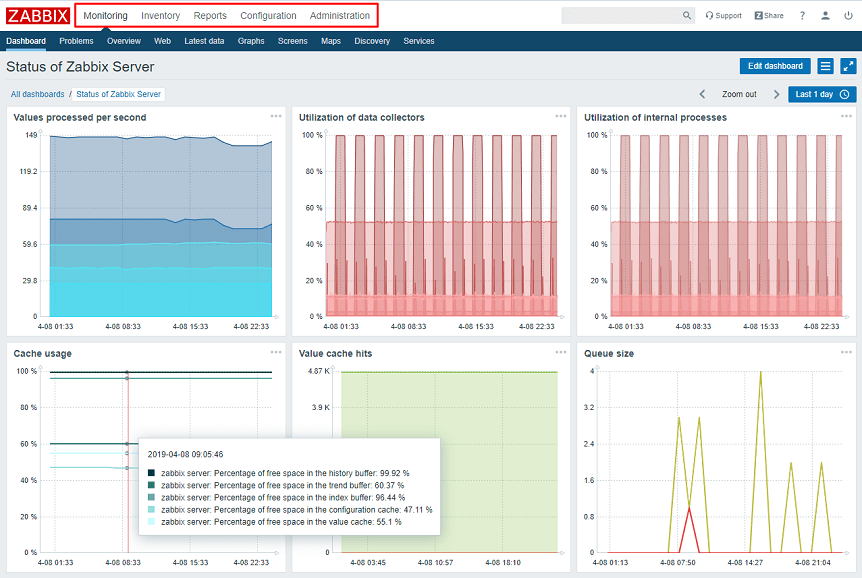
Пользователю доступны пять функциональных разделов, включая Monitoring («Мониторинг»), Inventory («Инвентарные данные»), Reports («Отчеты»), Configuration («Конфигурация») и Administration («Администрирование»).
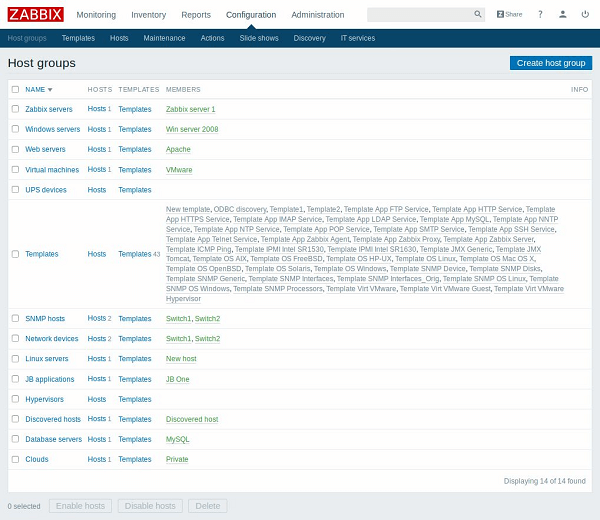
В разделе «Конфигурации» можно найти группы хостов. По каждому элементу списка можно посмотреть более подробную информацию, например, последние события и графики данных.
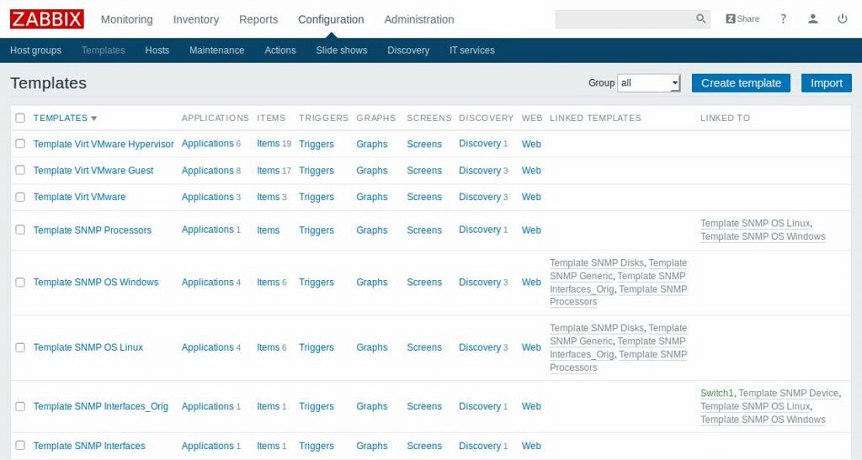
Управлять шаблонами, доступными администратору, можно в соответствующем подразделе — Templates («Шаблоны»).
Версия 4.4
Узнать версию установленного Zabbix сервера можно во время запуске в файле-протоколе.
Основные нововведения в Zabbix 4.4
- Новый Zabbix Agent (zabbix_agent2) создан на языке Go.
- Опции вывода графиков данных.
- Внешние уведомления, система отслеживания ошибок.
- Официальная поддержка TimescaleDB.
- База знаний для триггеров и элементов данных.
- Группировка данных и гистограммы.
- Официальная поддержка платформ, теперь Zabbix работает с SUSE Linux Enterprise Server 15, Debian 10, Raspbian 10, Mac OS/X, RHEL 8, MSI for Windows Agent и др.
Заключение
Zabbix по праву считается одним из самых продвинутых инструментов для удалённого мониторинга аппаратных и программных ресурсов. Система с успехом позволяет решать задачи по отслеживанию сетевой активности и работоспособности серверов, а также предупреждать о потенциально опасных ситуациях. Благодаря встроенным механизмам анализа и прогнозирования, Zabbix может стать основой для создания полноценной стратегии эффективного использования IT-инфрастуктуры в компаниях любого масштаба.
Способности Zabbix ограничены только имеющимися в распоряжении ресурсами. VDS от Eternalhost на SSD-дисках обеспечит системе максимальное быстродействие и возможность мониторить множество узлов в сети.
Источник: eternalhost.net
Что такое мониторинг IT и его уровни
Даже современные IT-инфраструктуры нередко дают сбой. Возникают случайные программные баги, скачки напряжения или естественный износ оборудования – в любом случае остается риск внезапной поломки. Это приводит к падению сервера, остановке программы и другим неожиданным сбоям. Именно поэтому практически в каждой системе используется ИТ-мониторинг, позволяющий администраторам узнавать о любых проблемах раньше пользователей. В рамках такого решения применяется целый комплекс диагностических процедур, позволяющих быстро оценить работу отдельных компонентов и обнаружить имеющиеся баги.
Что это такое

Мониторинг предполагает постоянный сбор и анализ различных параметров системы. Благодаря полученным данным удается проанализировать работу каждого элемента в числовом выражении. За счет этого можно заметить неполадки в отдельных сервисах и понять, как это отражается на работе все ИТ-инфраструктуры.
Чаще всего процесс осуществляется в автоматическом режиме. Это позволяет сделать данные более точными и повышает их актуальность. Ранее информация о работе отдельных серверов и сетевых устройств собиралась вручную системным администратором. Далее он анализировал данные и отслеживал возможные проблемы. Но, как вы понимаете, такой процесс занимал много времени, в результате чего процедуру нельзя было назвать эффективной.
Сегодня параметры мониторинга стали сложнее. Например, нередко производится анализ с тесной привязкой к бизнес-серверам, чтобы получить информацию «в вакууме». Также проводится контроль от лица пользователя – тестирование системы с эмуляцией действий обычного человека. Это позволяет найти ранее не выявленные ошибки в приложениях и внести необходимые изменения.
Активно применяется конфигурационная база данных, в которой присутствует информация обо всех объектах анализа. То есть, в единой базе содержатся данные о каждом сервере и сетевом устройстве, что позволяет отслеживать ошибку до конечной единицы. Существует большое количество уровней отслеживания, на каждом из них применяются свои инструменты и методики.
Мониторинг оборудования

Начнем рассмотрение процесса с самого нижнего уровня. Независимо от типа и особенностей ИТ-инфраструктуры, ее использование предполагает наличие серверов в дата-центре (как собственных, так и арендованных). А это значит, что у каждого устройства будут собственные параметры производительности, которые нужно постоянно отслеживать.
К числу основных критериев для мониторинга «железа» можно отнести следующее:
- нагрузки на сеть;
- нагрузки на процессор;
- количество производимых операций;
- количество запущенных на выполнение задач;
- наличие свободного места в оперативной памяти и на жестком диске.
Анализ этих параметров позволяет предотвратить полный или частичный простой в работе инфраструктуры. Например, проверка нагрузки сети позволяет выявить критические показатели и понять, что система нуждается в масштабировании. Если внезапно сократилось место в оперативной памяти, то можно заподозрить взлом системы.
Для контроля серверов используются различные инструменты. Есть штатные средства, но для крупной инфраструктуры стоит подумать о масштабируемых решениях. С их помощью удастся анализировать параметры кластера серверов и собирать все полученные данные в единой панели.
Мониторинг приложений
В том случае, если оборудование находится в полностью исправном состоянии, но какие-либо сервисы или программы у пользователей не запускаются, то возможны ошибки именно на этом уровне.
Для контроля используются метрики приложений, по которым разработчики могут отслеживать основные параметры. Чаще всего анализируются следующие сведения:
- Количество запросов за определенное время (данные могут отслеживаться как за час, так и за минуту – все зависит от предполагаемого трафика).
- Число активных пользователей за выбранное время.
- Количество новых записей в базу данных.
- Количество ошибок, которые были зарегистрированы в системе.
Стоит понимать, что полного отсутствия ошибок практически не избежать. Однако резкий скачок отказов может говорить о наличии сбоя. При этом метрики нагрузки на сервер могут быть в полном порядке, поэтому данные мониторинга приложений и программ стоит рассматривать отдельно.
На этом уровне мониторинга используются специализированные СУБД, которые помогают рассчитать все данные метрики и свести их в единую базу. Нередко применяются графические инструменты, позволяющие отобразить полученные статистические данные.
Многие разработчики с используют встроенные системы мониторинга своих серверов. Такие решения помогают сократить время на поиск ошибок и провести базовую диагностику системы.
Мониторинг бизнес-метрик

На этом уровне могут использоваться различные метрики, которые помогут отслеживать эффективность бизнес-задач. Например, нередко настраиваются метрики для следующих данных:
- Количество пользователей, зарегистрированных в системе за определенный отрезок времени.
- Процент пользователей, которые дошли до покупки/оплаты.
- Особенности использования приложений пользователями.
- Общая выручка и прибыль от ваших приложений.
Это далеко не полный список возможных метрик. Как правило, необходимые метрики определяются с учетом задач проекта и сферы деятельности компании. Например, для отслеживания минимальных параметров можно использовать инструменты Google Analytics. Однако в других случаях потребуется составление собственных метрик и отслеживание поступающих данных для внесения необходимых корректировок.
Мониторинг событий
Помимо системы мониторинга сервера, приложений и бизнес-метрик также стоит отслеживать происходящие события. Это необходимо для того, чтобы четко понимать, что происходит в системе и почему бизнес-показатели принимают имеющиеся значения.
Отслеживание происходящих событий позволит понять, почему пользователи именно так взаимодействуют с вашими программами и приложениями и какой аспект нуждается в улучшении. Именно на этом уровне используется тип метрики, который отслеживает все события, генерируемые пользователями и компонентами системы.
События помогают понять причины определенного поведения пользователей и обнаружить баги, которые были пропущены на предыдущих уровнях мониторинга. Например, если при клике на определенную страницу увеличивается количество ошибок или отказов, то это говорит о проблеме на программном уровне.
Многие компании ограничиваются системами клиентской аналитики. Однако подобные решения не позволяют полностью понять поведение пользователей, поэтому рекомендуется использоваться собственные системы трекинга различных активностей.
Как внедрить систему контроля

Система мониторинга внедряется поэтапно, так как является достаточно сложной и объемной. На этапе проектирования выбираются объекты мониторинга (например, конкретное сетевое оборудование или серверы), а затем – определяются показатели для каждого объекта. При этом количество анализируемых данных должно быть не слишком большим – это может привести к тому, что администраторы просто не заметят критическую ошибку среди массы других.
На следующем этапе внедрения системы потребуется выбрать архитектуру и конкретное решение. Нередко используются готовые продукты, которые нуждаются только в настройке. Также разумным считается использование тестового мониторинга части системы. Это позволит внести необходимые корректировки на раннем этапе и только потом расширять контроль на всю инфраструктуру.
Системы мониторинга ориентированы на ИТ-инфраструктуры различного уровня и размеров. Сложные и многоуровневые системы требуют больших денежных и временных затрат на внедрение. Однако для крупного бизнеса не подойдут готовые «коробочные» продукты.
Настраивать отслеживание потребуется в любой системе, где системный администратор не может контролировать каждый сервер. Как правило, в небольших фирмах такой проблемы не возникает, так как используется один или несколько серверов, которые легко контролировать вручную. Но для среднего и крупного бизнеса ручной мониторинг является не слишком эффективным.
Использование программ мониторинга серверов и приложений позволяет не только отслеживать происходящие события и возникающие ошибки, но и строить отчеты по использованию ресурсов. Например, можно получить данные о загрузке процессора или памяти в пиковые моменты. Это позволит понять, какие задачи требуют доработки, куда можно перенести часть сервисов и насколько инфраструктура справляется с имеющимися задачами.
Кроме этого, удается визуализировать имеющиеся проблемы. А это в большинстве случаев сокращает время простоя системы и позволяет устранить баги в минимальные сроки. Так что не удивительно, что большинство крупных компаний уже в той или иной мере используют различные способы мониторинга.
Если у вас остались вопросы об инструментах диагностики ИТ-инфраструктуры или вы хотите внедрить такую систему для собственного бизнеса, то обращайтесь за помощью к специалистам дата-центра Xelent. Мы поможем подобрать подходящий инструмент для ваших бизнес-задач!
Источник: www.xelent.ru