
Краулер (бот, паук, automaticindexer, ant, webspider, webscutter, поисковый робот) – специальная поисковая программа, которая является частью поисковой системы(Яндекс, Google и др.), и предназначенная для индексирования веб-сайтов.
Принцип работы поискового робота заключается в том, что он постоянно «бродит» по известным ему сайтам (те, которые проиндексированы), проходит по внутренним и внешним ссылкам и заносит новую информацию себе в базу. Сам по себе краулер представляет из себя аналогию веб-браузера, поэтому переход поискового робота от одной страницы к другой осуществляется по ссылкам, которые есть в теле веб-страницы.
Поисковый робот таким образом находит новые сайты, новые страницы и заносит себе в индекс, а также он фиксирует обновления на ранее известных ему страницах. Что интересно, поисковый бот способен определить частоту обновлений информации на вашей странице. Например, если у вас новостной сайт обновляется ежедневно, то поисковые боты будут посещать ваш сайт чаще, а если у вас бизнес страничка с описанием услуг компании, где контент не меняется годами, то и поисковый робот к вам будет ходить тоже раз в год.
Пишу краулер парсер с нуля на Python за 30 минут
Если вы только что создали сайт, вы должны обязательно дать знать о себе поисковым роботам. Это делается в специальной форме поисковых систем в панели веб-мастера Яндекс и Google. Также, размещение ссылок в социальных сетях и хороших новостных порталах, поможет быстрее проиндексировать ваш сайт. Только не стоит злоупотреблять — покупать ссылки на ваш сайт в огромном количестве с сомнительных ресурсов. Такой способ уже не работает, и можно попасть по фильтры поисковых систем (например, Минусинск Яндекса).
Виды поисковых роботов
У каждой поисковой системы не один Краулер, а целое множество ботов, где каждый заточен под определённые задачи и посещает ваш сайт с разной периодичностью в разное время.
Поисковые роботы Яндекса
- Yandex/1.01.001 (compatible; Win16; I) — главный краулер Яндекса, который как раз и индексирует содержимое страниц..
- Yandex/1.01.001 (compatible; Win16; P) — этот бот индексирует картинки.
- Yandex/1.01.001 (compatible; Win16; H) — этот поисковый робот ищет зеркала и дубли сайта.
- Yandex/1.03.003 (compatible; Win16; D) — это самый первый робот, который посещает сайт после добавление его через панель веб-мастера. Он проверяет соответствие добавленных параметров индексации, что указали в панели веб-мастера, и если всё Ок, то за работу принимается основной поисковый бот Yandex/1.01.001.
- Yandex/1.03.000 (compatible; Win16; M) — этот бот посещает сайт после ее открытия по ссылке «Найденные слова» в поисковой выдаче.
- YaDirectBot/1.0 (compatible; Win16; I) — служит для индексации сайтов из рекламной сети Яндекса (РСЯ).
- Yandex/1.02.000 (compatible; Win16; F) — сканирует favicon сайтов (фавикон, иконка сайта).
Поисковые роботы Google
У Google есть свои поисковые роботы.
SEO-краулер Netpeak Spider: описание программы и главные преимущества
Важно отметить, что сайт можно найти через поиск (Яндекс, Google) не сразу же после того как его проиндексирует поисковый бот. Сначала всё записывается в базу данных, а потом уже происходит апдейт (обновление базы).
На грубом примере это выглядит так:
Сегодня 1 октября и в выдаче поисковых систем представлены веб-документы, которые были проиндексированы до 15 августа. Если поисковик «захотел», то он может сделать уже на следующий день новый апдейт, и в поисковой выдаче появятся обновления, которые сделаны с 15 августа до 22 октября, а если «захочет», то апдейт будет через месяц вообще. Это так работает Яндекс. Google же проводит обновления практически ежедневно.
Поисковые роботы также искажают данные в веб-аналитике в таких системах как Яндекс.Метрика и Google Analytics. Там поисковые роботы понимаются как обычные посетители. Однако поисковых роботов можно отфильтровать, если сделать определённые настройки в системах веб-аналитики.
Источник: www.glossary-internet.ru
Что такое краулер (crawler)?
Краулер (Crawler) — программное обеспечение поисковой системы, которое обходит веб-страницы и заносит их в индекс. Также программа, позволяющая спарсить все внутренние и внешние ссылки сайта, метатеги, заголовки, канонические url и множество других данных, необходимых для SEO-специалиста.
Среди самых известных краулеров — Screaming Frog, Netpeak Spider, Xenu и другие.

Рецензент статьи:
Голомолзин Денис
Управляющий партнер компании «Альтера». В прошлом — оптимизатор, ведущий специалист SEO-команды, руководитель отдела продвижения, консультант-евангелист компании.

Вы дочитали статью! Отличная работа!
- В некоторых нюансах продвижения сайтов сложно разобраться без опыта. Вы можете доверить продвижение вашего сайта нам. Отправьте заявку и мы изучим ваш сайт и предложим эффективную стратегию продвижения вашего бизнеса в сети.
- Подпишитесь на нашу рассылку — ежемесячно мы публикуем статьи про SEO-продвижение, онлайн-маркетинг, контекстную рекламу, новости отрасли и многое другое.
- Понравилась статья? Поделитесь ссылкой на статью в социальных сетях — возможно, статья окажется полезной для ваших друзей и коллег.
Источник: www.altera-media.com
Что такое поисковый робот: и как им управлять
Краулер (от английского crawler — «ползать») — это поисковый робот, используемы поисковой системой для обнаружения новых страниц в интернете. Простыми словами, краулер — это поисковый робот Google, «Яндекса» и других поисковых систем.
Принцип работы заключается в постоянном сканировании страниц и нахождении на них ссылок с дальнейшим переходом по ним. Всю собранную информацию робот заносит в специальную базу данных, которая называется индексом. Данные о новых страницах в интернете поисковая машина берет как раз из такого индекса.
Отдельно следует отметить большое количество синонимов, которыми могут называть поискового краулера. Среди них поисковый паук, робот, бот, ant, webspider, webrobot и т. д.

Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
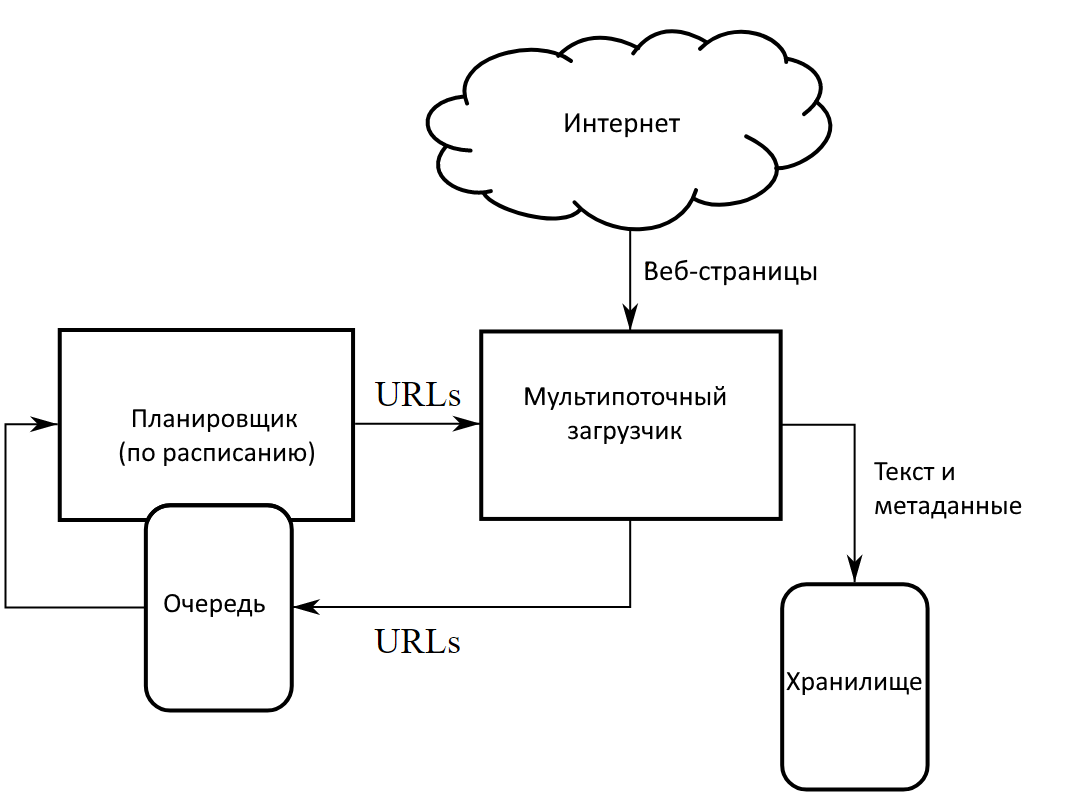
Как поисковый робот видит страницу
Он видит веб-сайт совсем не так, как его видит пользователь. Вместо привычного нам визуального контента паук обращает внимание на заголовок, ответ и IP-адрес:
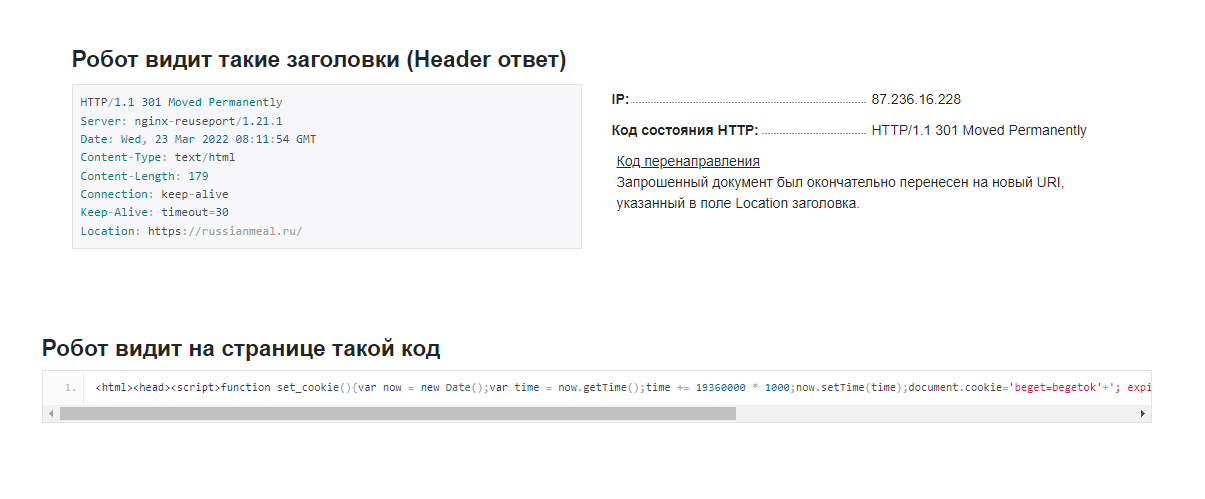
Поисковый робот анализирует следующие параметры:
- Ответ HTTP-заголовка страницы.
- Текущий веб-сервер.
- Текущую дату в GMT-формате.
- Тип контента.
- Объем контента.
- Наличие Keep-Alive (постоянное HTTP-соединение).
- Локейшн (URL сайта / страницы).
- Код перенаправления.
- IP-адрес.
- Установленные сайтом правила cookie.
- Внешние и внутренние ссылки на странице.
Как работает робот Google и «Яндекса»
Если представить алгоритм взаимодействия поискового робота со страницей обобщенно, оно выглядит следующим образом:
- Переход по URL.
- Сканирование контента страницы.
- Сохранение содержимого на сервере. На этом этапе может происходить конвертация формата данных в удобочитаемый для поисковой машины формат.
- Повторение указанной цепочки с переходом по новому URL.
У каждой поисковой машины свои роботы, и порядок сканирования может немного различаться. Например, по количеству посещений, максимальному количеству переходов, зацикливанию и т. д.
Все это регламентируется поисковой системой. Соответственно, нельзя вывести какие-то общие цифры, но можно посмотреть на поведение типичного, на примере паука Googlebot:

Апдейты в поисковых системах: что это, виды апдейтов и где отслеживать
Типы краулеров
Поисковые системы используют разные типы для сканирования разного контента. Например, у Google есть отдельные поисковые роботы для обработки изображений, видео, новостного контента, общего качества страницы. Кроме этого, у зарубежной ПС имеется собственный целевой робот для индексации мобильных страниц и проверки качества рекламы. Каждый из перечисленных поисковых роботов обладает собственным user-agent’ом, и при желании для любого из них можно создать директиву в стандарте исключения для роботов. Об этом мы расскажем в разделе «Как запретить обход сайта».
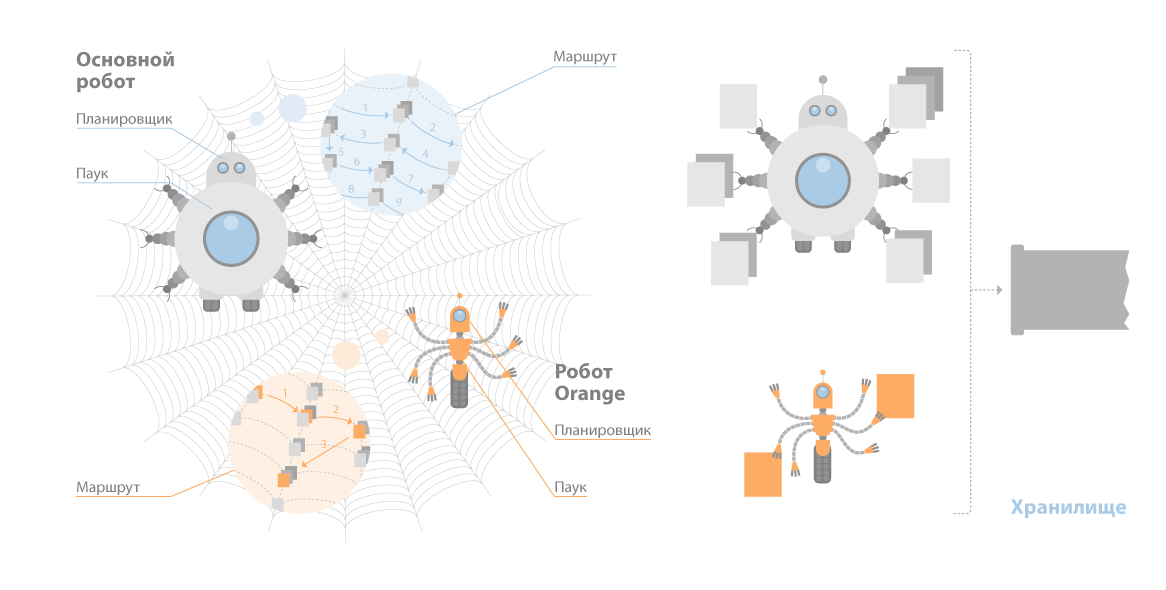
У «Яндекса» разноцелевых гораздо меньше: по разным оценкам — от четырех до пяти штук. Основных пауков у «Яндекса» два: стандартный бот и быстрый паук Orange.
Работа краулера на примере поискового робота «Яндекса» выглядит так:
- Планировщик строит очередность сканирования.
- Этот маршрут отправляется роботу.
- Он обходит документы.
- Если сайт отдает корректный ответ, он скачивает данные.
- Самостоятельно идентифицирует параметры документа, включая язык.
- Затем он отправляет полученные сведения в кэш «Яндекса» или иное хранилище.
Вот примерная визуализация этих процессов:
Как часто обновляется индекс Google и «Яндекса»
Информация о найденных ссылках попадает в базы данных поисковых машин не сразу, а через определенный период времени. Обновление индекса — базы данных, содержащей ссылки на вновь найденные URL — у «Яндекса» может занимать от нескольких дней до 1–2 недель. Google же обновляет индекс гораздо чаще — несколько раз за сутки.
Это, пожалуй, одно из самых принципиальных отличий между двумя поисковыми системами именно с точки зрения процессов обработки новых страниц.

Отличия SEO под Яндекс и Google
Почему краулер не индексирует все страницы сайта сразу
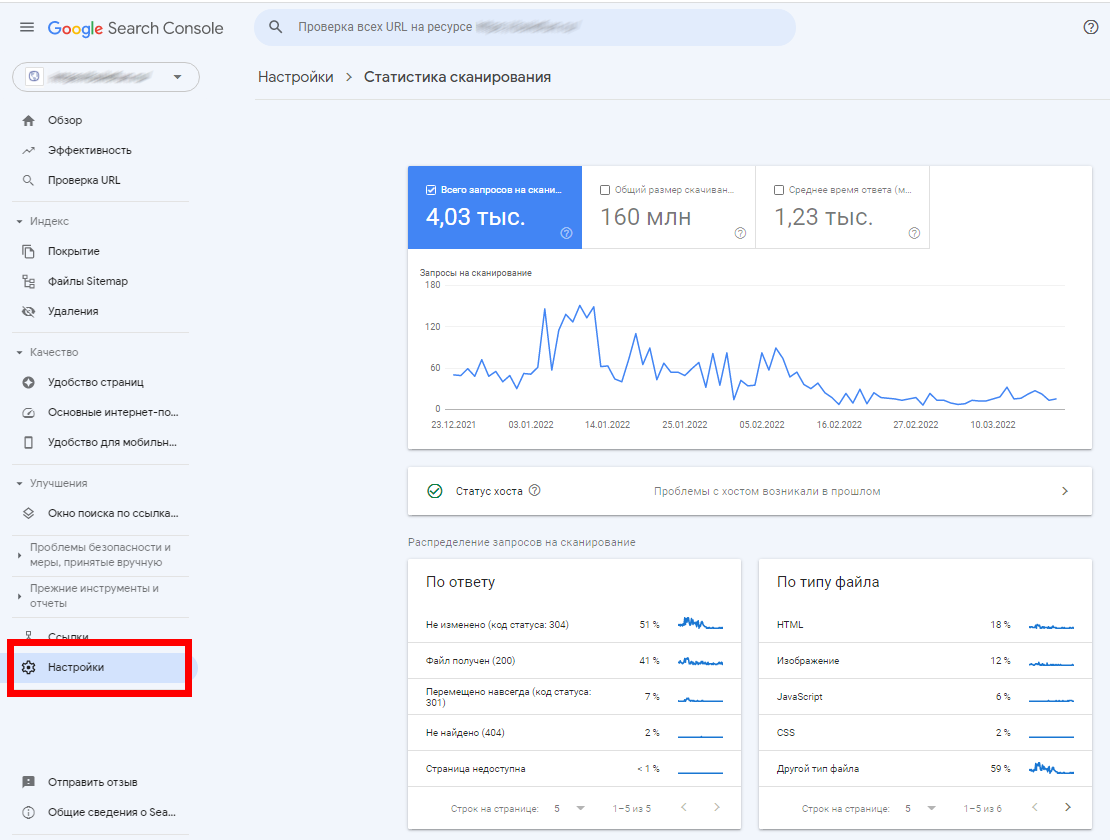
Учитываются и повторные запросы сканирования одного и того же URL. Кроме того, у каждой поисковой машины существуют ограничения по уровням доступа, а также по размеру текстового контента.
По всем вышеуказанным причинам сайт, особенно если он имеет сложную структуру и большое количество страниц, не может быть проиндексирован за один раз (и даже за 2-3-4).
Индексация в поисковых системах: что это простыми словами
Зачем поисковые роботы притворяются реальными пользователями
Краулеры поисковых систем почти всегда «играют по правилам». Они никогда не представляются пользовательским клиентом — например, браузером. Однако пауки различных сервисов сканируют огромные массивы данных. Если они будут соблюдать все ограничения для краулеров (бюджеты обращений, интервалы между обращениями), скорость сканирования будет оставаться очень низкой.
Чтобы решить эту проблему, разработчики веб-сервисов в частном порядке создают пауков, которые представляются пользовательским клиентом, чаще всего — браузером.
Фактор роботности

Google Analytics для начинающих: самое полное руководство. Часть 1. Universal Analytics
В любом отчете «Яндекс.Метрики» можно ограничить отображение визитов, создаваемых роботами. Для этого откройте любой интересующий вас отчет, кликните по строке «Данные с роботами» и выберите необходимый сценарий фильтрации:
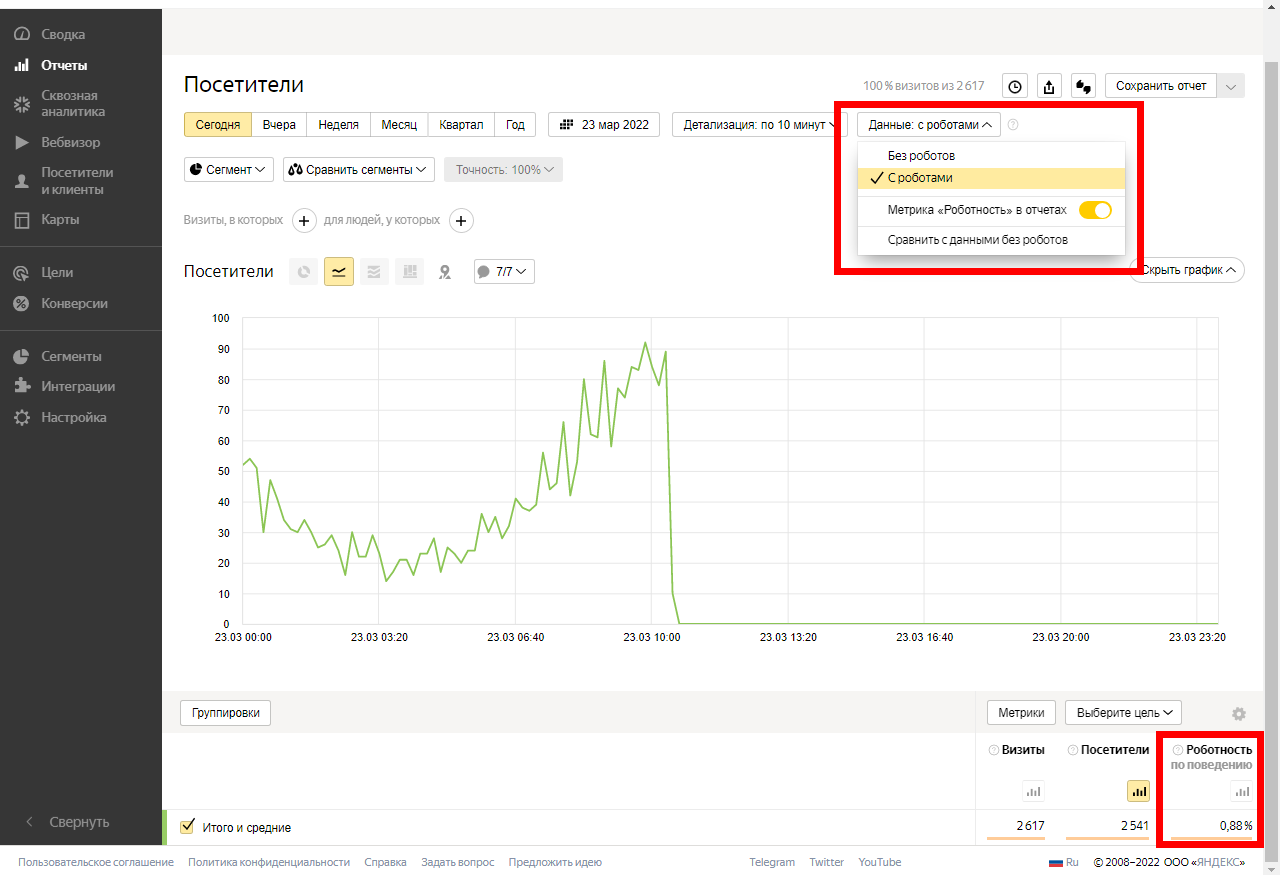
Роботность по поведению — это доля визитов роботов, определенных по поведенческим факторам. Роботы по поведению маскируются под реальных посетителей
В Google Analytics также можно фильтровать роботов. Для этого откройте настройки администратора и перейдите в параметры представления:
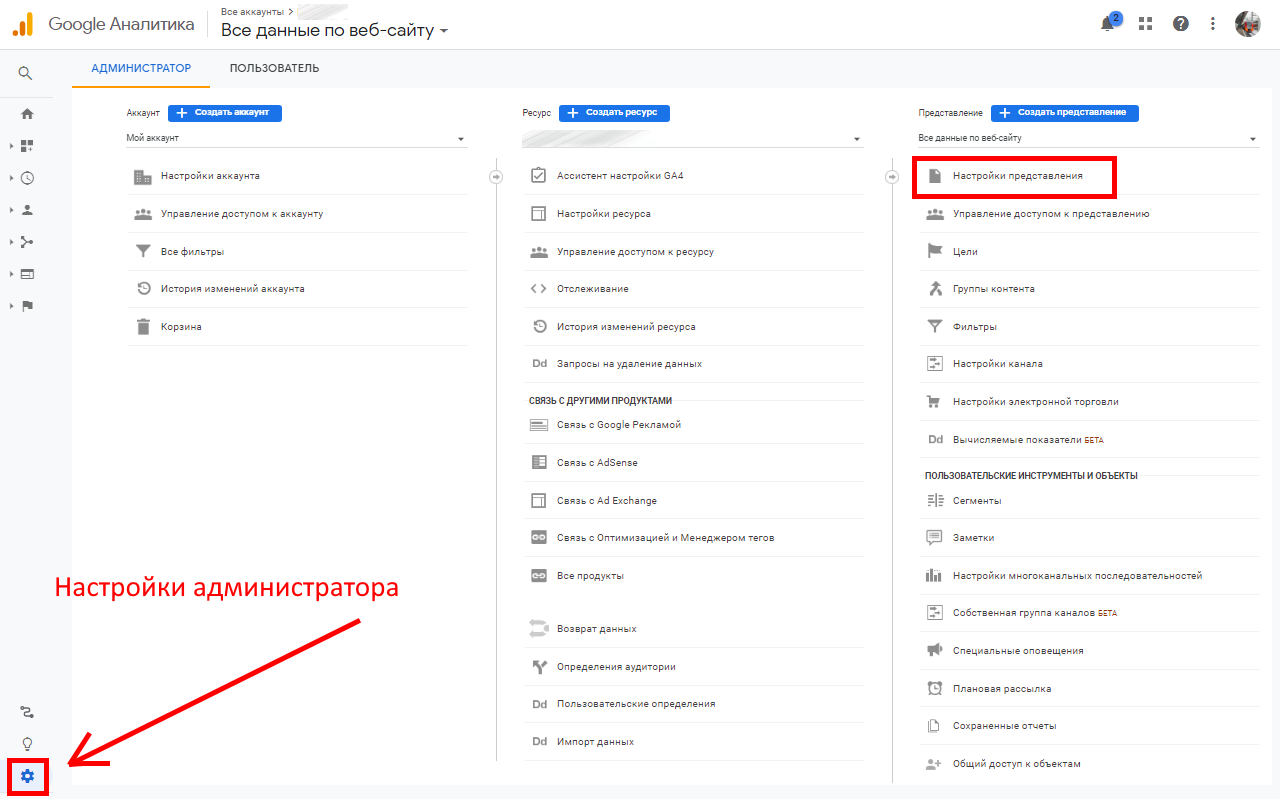
Сделайте активным чекбокс «Исключить обращения роботов и пауков»:
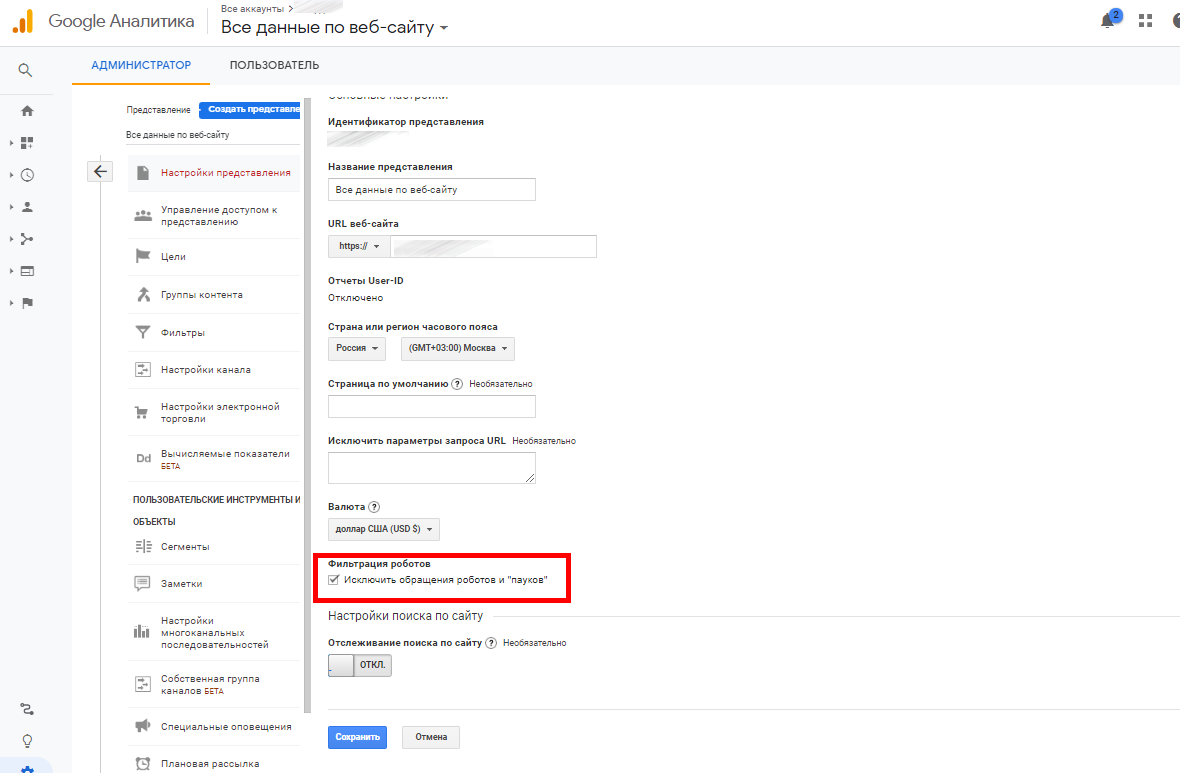
Всё. Теперь GA не будет учитывать их своих отчетах.
Комплексная веб-аналитика
- Позволяет видеть каждый источник трафика, его качество — процент конверсии по каждой кампании, группе объявлений, объявлению, ключевому слову.
- Даст понимание насколько качественный трафик дает каждый канал, стоит ли в него вкладываться или стоит ограничить.
Вежливые и вредные роботы
Классификация не официальная, но вполне подходящая в данном случае.
Вежливые роботы — те, которые представляются. Вредные роботы — маскируются под пользователя.
Не стоит думать, что объем трафика, генерируемого роботами, ничтожен: поисковые роботы есть не только у Google и «Яндекса», а также других поисковых систем, но и у огромного количества аналитических сервисов, сервисов статистики, SEO-инструментов. Например, существуют: Alexa, Amazon, Xenu, NetPeak, SEranking.
Поисковые роботы указанных сервисов в некоторых случаях — например, при сверхограниченных ресурсах сервера — могут становиться настоящей проблемой. Часто вебмастеры сталкиваются и с откровенно вредоносными краулерами, которые постоянно добывают определенный тип данных: например, электронные адреса для создания баз данных для организации дальнейших почтовых рассылок.
Способов борьбы предостаточно. Например, для многих CMS сегодня доступны разнообразные инструменты, ограничивающие воздействие вредных пауков на сайт. Часто они сделаны в виде плагинов или расширений. Например, в WordPress разработан плагин Blackhole for Bad Bots.
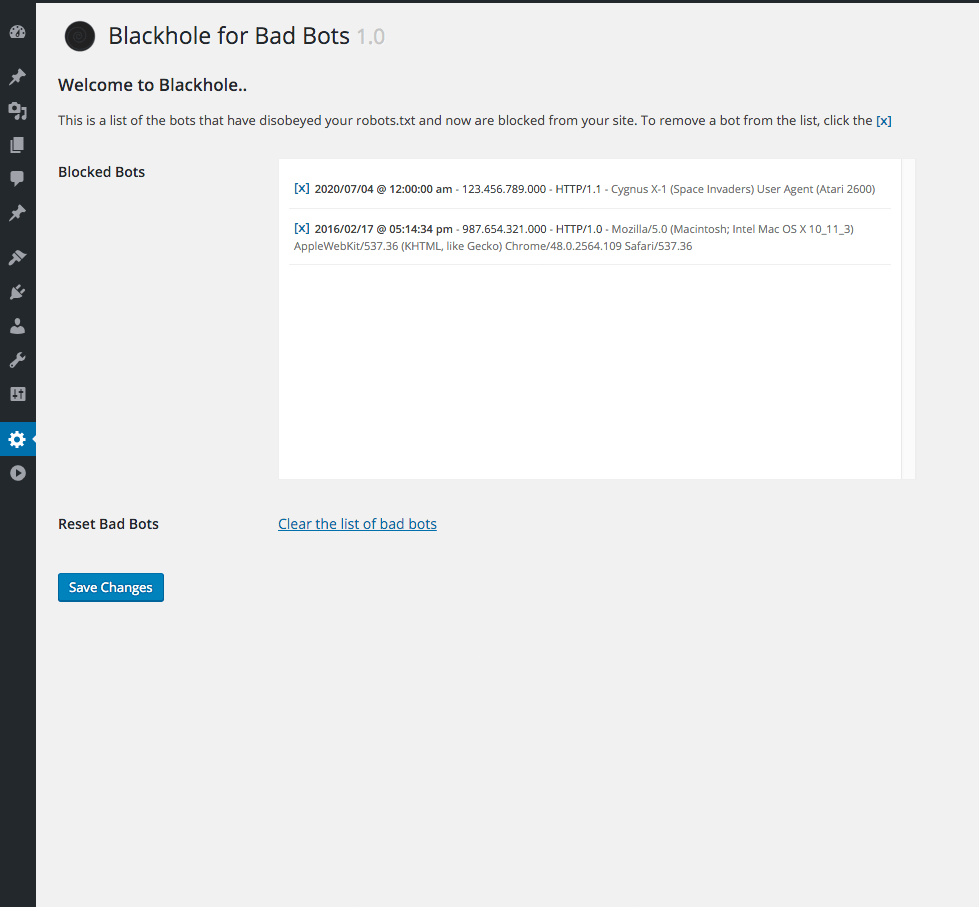
Этот плагин работает так: сначала плагин добавляет скрытую триггерную ссылку в нижний коллонтитул страниц. Вебмастер добавляет в robots.txt строку, запрещающую всем паукам переходить по скрытой ссылке. Те, которые игнорируют или не подчиняются правилам, сканируют ссылку и автоматически попадают в ловушку.
Плохие краулеры вредны для сайта в первую очередь тем, что создают высокую нагрузку на сервер. В особо тяжелых случаях сайт даже может стать недоступным.
Источник: kokoc.com