
В сложных программных комплексах, состоящих из большого количества компонентов, встает вопрос организации обмена информацией между этими компонентами. Участников обмена информацией как правило разделяют на отправителей (producer) некоторого сообщения и его получателей ( consumer ). Если отправителей и получателей мало, то можно установить прямую связь между каждым из участников обмена данными. Но когда количество участников увеличивается и требуется более высокая интерактивность, такой способ обмена информацией становится неэффективным.
В этом случае между теми, кто отправляет и получает данные, целесообразно использование посредника, управляющего процессом обмена информацией — брокера сообщений .
Для чего нужен брокер сообщений
- Обеспечение обмена информацией между отправителем и получателем.
- Маршрутизация сообщений.
- Хранение сообщений.
- Разбиение сообщений и последующее агрегирование.
Работу брокеров сообщений мы рассмотрим на примере одного из наиболее популярных инструментов — Apache Kafka.
Что такое Apache Kafka за 5 минут
Apache Kafka разработан в компании Linkedin, а затем стал open-source продуктом в составе Apache Foundation. Оптимизированная для записи больших объёмов данных программа своим оригинальным названием обязана фамилии любимого писателя главного разработчика — Франца Кафки. Основное преимущество брокера сообщений Kafka в том, что это платформа потока событий, обладающая исключительной производительностью в системах непрерывного и высокоскоростного обмена информацией, будь то интеграция данных из большого количества источников, их потоковая аналитика, либо же любая иная система , непрерывная работа которой становится критически важной для бизнеса или организации. Подобные приложения приходится часто использовать в работе с облачными платформами, такими как Timeweb Cloud .
Как работает брокер сообщений Kafka
Отправители формируют сообщения и передают их брокеру. После этого программа раскладывает полученные сообщения по отдельным топикам ( topics ) в соответствии с потребностями получателей, а затем получатели забирают необходимые в данный момент данные. При этом отправители и получатели непосредственно друг с другом никак не связаны и общаются только с брокером по API.
Благодаря этому легко реализуется обмен информацией между произвольными комбинациями отправителей и получателей. Важно отметить, что получатели сами должны делать запрос у брокера (pull). Этим брокер сообщений Kafka отличается от другого распространенного брокера RabbitMQ , который сам отправляет сообщения получателям (push).
Схема работы Apache Kafka
Основные составляющие брокера сообщений Kafka
- Брокер (сервер, узел) . Используется для получения, хранения и отправки сообщений. Система масштабируема, поэтому может иметь много брокеров, объединенных в кластер. Для хранения состояния и конфигурации кластера Kafka использует инструмент Zookeeper. Также с помощью Zookeeper выбирается основной брокер (Controller), обеспечивающий консистентность данных.
- Сообщение представляет из себя пару «ключ — значение». Ключ опционален и используется чтобы распределять сообщения по кластеру, а значение — это содержимое сообщения. Помимо этого, каждый отдельный элемент содержит поле timestamp, то есть время в формате Unix, устанавливаемое при отправке или обработке сообщения на кластере. Опциональным является поле headers с дополнительными пользовательскими атрибутами сообщения.
- Топик и партиция (partition). Топик — это набор событий, объединенных по некоторому логическому принципу. В нём формируется очередь из получаемых от отправителей сообщений, и отсюда же данные извлекаются получателями. Кafka работает по принципу FIFO: сообщения доставляются получателям сохраняя тот же порядок, в котором были получены от отправителей. Информация не пропадает из топика после прочтения получателями.
Для параллелизации чтения и записи топики делятся на партиции. В кластерной конфигурации партиции распределяются по узлам так, чтобы на каждый приходилось примерно одинаковое количество партиций. При этом возможна ситуация, когда все партиции одного топика используют один узел, что может привести к повышенной нагрузке на такой узел. Kafka даёт возможность вручную сконфигурировать распределение партиций по брокерам, чтобы избежать этого.
Apache Kafka урок 1. Зачем нужна, что это? RabbitMQ vs Kafka vs БД
Топики хранят сообщения в лог-файлах. Каждое сообщение имеет timestamp, порядковый номер (offset) и позицию (position) в байтах от начала файла. Это позволяет читать сообщения, начиная с определенного номера или даты/времени, что выгодно отличает Kafka от другого популярного брокера сообщений ActiveMQ , не обладающего таким функционалом. Каждый лог-файл тоже имеет свой порядковый номер.
При достижении лог-файлом заданного в настройках размера запись в этот файл прекращается, и последующие сообщения пишутся в новый лог-файл со следующим по порядку номером. Отдельные лог-файлы называются сегментами. Kafka поддерживает только операции чтения и записи сообщений, но не удаления. Удалять данные можно с помощью настройки времени жизни (TTL, time-to-live) сегментов. Этот способ даёт возможность не хранить дольше заданного времени целые сегменты, отдельные же элементы удалить не получится даже так.
Отказоустойчивость обеспечивается репликацией партиций по всем брокерам в задаваемом в настройках количестве. Выход из строя любого узла при этом не приводит к потере данных. Более того, в этом случае Kafka добавляет копии партиций, хранящихся на неактивном брокере, на работающие, чтобы обеспечить требуемый фактор репликации. При репликации основной брокер назначает одну из партиций ведущей (Leader). Операции чтения и записи осуществляются через ведущую партицию.
Преимущества Kafka
- Распределенность: комплекс предназначен для работы на множестве серверов .
- Отказоустойчивость: выход из строя одного из функциональных узлов не помеха непрерывной работе.
- Согласованность и доступность: данные в системе непротиворечивы и в любой момент могут быть получены в результате запроса.
- Высокая производительность: возможность реализовать кластеры, обрабатывающие миллионы сообщений в секунду.
- Горизонтальная масштабируемость: при необходимости можно добавить в имеющуюся структуру дополнительный узел.
Брокер сообщений Apache Kafka оказался очень удачным инструментом для работы на облачных серверах , с единственным недостатком — ориентированностью на обработку больших объемов данных. Однако, по мере развития Kafka это различие стало менее заметным, а сама система — более гибкой и универсальной.
В своем официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Источник: timeweb.cloud
Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют это ПО.
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
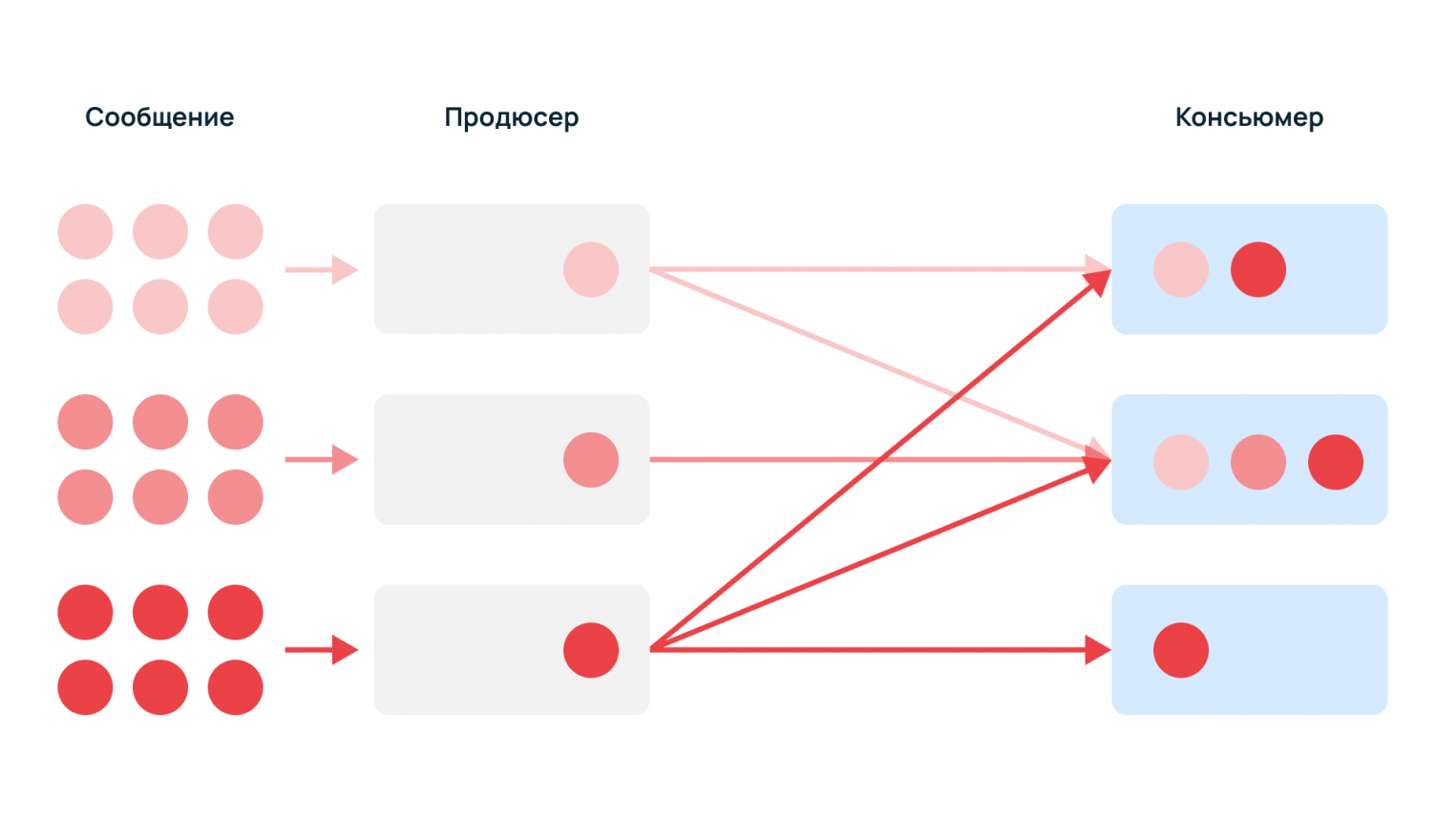
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
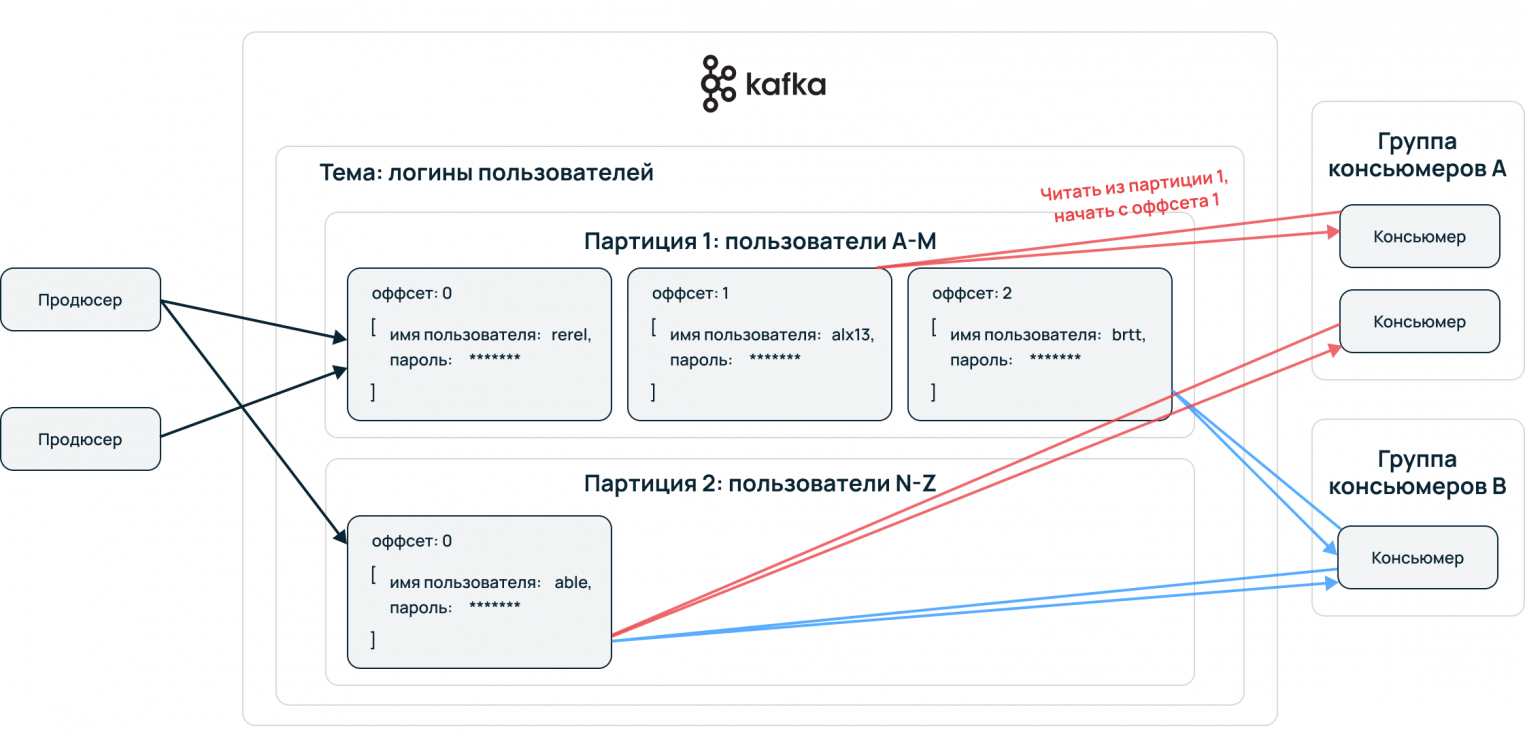
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Источник: selectel.ru
Apache Kafka: основы технологии

У Kafka есть множество способов применения, и у каждого способа есть свои особенности. В этой статье разберём, чем Kafka отличается от популярных систем обмена сообщениями; рассмотрим, как Kafka хранит данные и обеспечивает гарантию сохранности; поймём, как записываются и читаются данные.
Статья подготовлена на основе открытого занятия из видеокурса по Apache Kafka. Авторы — Анатолий Солдатов, Lead Engineer в Авито, и Александр Миронов, Infrastructure Engineer в Stripe. Базовые темы курса доступны на Youtube.
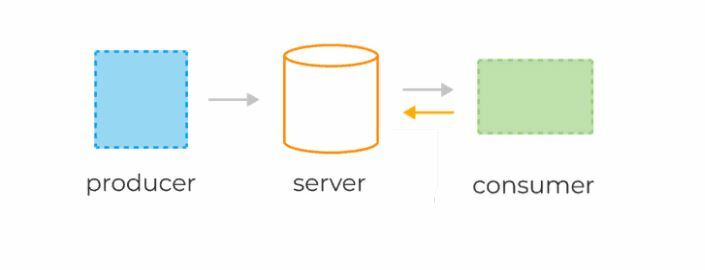
Базовые компоненты классической системы очередей
В веб-приложениях очереди часто используются для отложенной обработки событий или в качестве временного буфера между другими сервисами, тем самым защищая их от всплесков нагрузки.
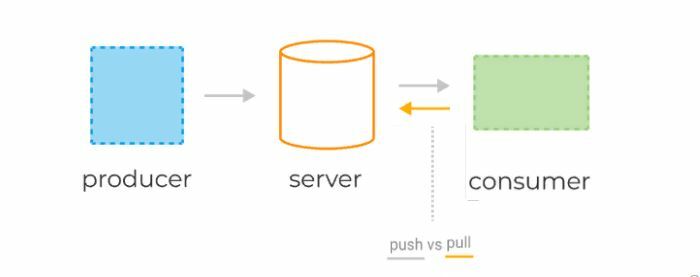
Консьюмеры получают данные с сервера, используя две разные модели запросов: pull или push.
pull-модель — консьюмеры сами отправляют запрос раз в n секунд на сервер для получения новой порции сообщений. При таком подходе клиенты могут эффективно контролировать собственную нагрузку. Кроме того, pull-модель позволяет группировать сообщения в батчи, таким образом достигая лучшей пропускной способности. К минусам модели можно отнести потенциальную разбалансированность нагрузки между разными консьюмерами, а также более высокую задержку обработки данных.
push-модель — сервер делает запрос к клиенту, посылая ему новую порцию данных. По такой модели, например, работает RabbitMQ. Она снижает задержку обработки сообщений и позволяет эффективно балансировать распределение сообщений по консьюмерам. Но для предотвращения перегрузки консьюмеров в случае с RabbitMQ клиентам приходится использовать функционал QS, выставляя лимиты.
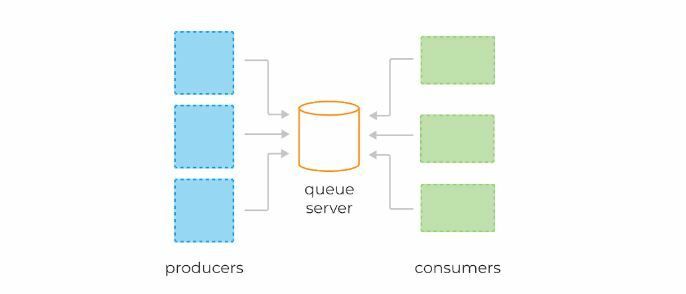
Как правило, приложение пишет и читает из очереди с помощью нескольких инстансов продюсеров и консьюмеров. Это позволяет эффективно распределить нагрузку.
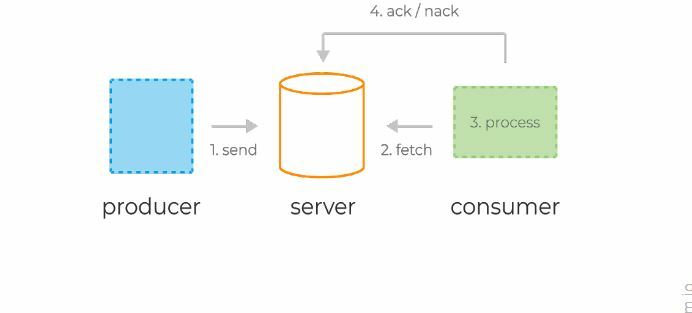
Типичный жизненный цикл сообщений в системах очередей:
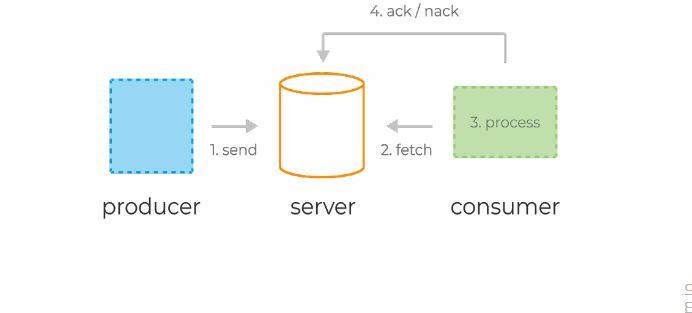
- Продюсер отправляет сообщение на сервер.
- Консьюмер фетчит (от англ. fetch — принести) сообщение и его уникальный идентификатор сервера.
- Сервер помечает сообщение как in-flight. Сообщения в таком состоянии всё ещё хранятся на сервере, но временно не доставляются другим консьюмерам. Таймаут этого состояния контролируется специальной настройкой.
- Консьюмер обрабатывает сообщение, следуя бизнес-логике. Затем отправляет ack или nack-запрос обратно на сервер, используя уникальный идентификатор, полученный ранее — тем самым либо подтверждая успешную обработку сообщения, либо сигнализируя об ошибке.
- В случае успеха сообщение удаляется с сервера навсегда. В случае ошибки или таймаута состояния in-flight сообщение доставляется консьюмеру для повторной обработки.
Типичный жизненный цикл сообщений в системах очередей
С базовыми принципами работы очередей разобрались, теперь перейдём к Kafka. Рассмотрим её фундаментальные отличия.
Как и сервисы обработки очередей, Kafka условно состоит из трёх компонентов:
1) сервер (по-другому ещё называется брокер),
2) продюсеры — они отправляют сообщения брокеру,
3) консьюмеры — считывают эти сообщения, используя модель pull.
Базовые компоненты Kafka
Пожалуй, фундаментальное отличие Kafka от очередей состоит в том, как сообщения хранятся на брокере и как потребляются консьюмерами.
- Сообщения в Kafka не удаляются брокерами по мере их обработки консьюмерами — данные в Kafka могут храниться днями, неделями, годами.
- Благодаря этому одно и то же сообщение может быть обработано сколько угодно раз разными консьюмерами и в разных контекстах.
Теперь давайте посмотрим, как Kafka и системы очередей решают одну и ту же задачу. Начнём с системы очередей.
Представим, что есть некий сайт, на котором происходит регистрация пользователя. Для каждой регистрации мы должны:
1) отправить письмо пользователю,
2) пересчитать дневную статистику регистраций.
В случае с RabbitMQ или Amazon SQS функционал может помочь нам доставить сообщения всем сервисам одновременно. Но при необходимости подключения нового сервиса придётся конфигурировать новую очередь.
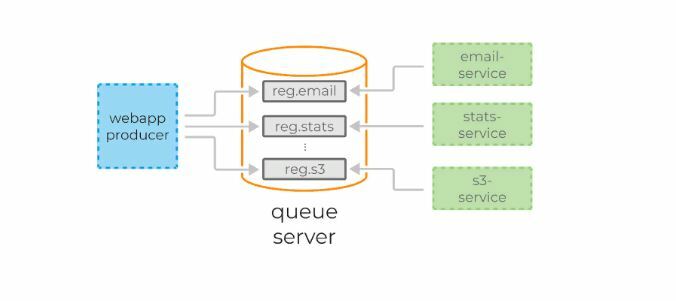
Kafka упрощает задачу. Достаточно послать сообщения всего один раз, а консьюмеры сервиса отправки сообщений и консьюмеры статистики сами считают его по мере необходимости.
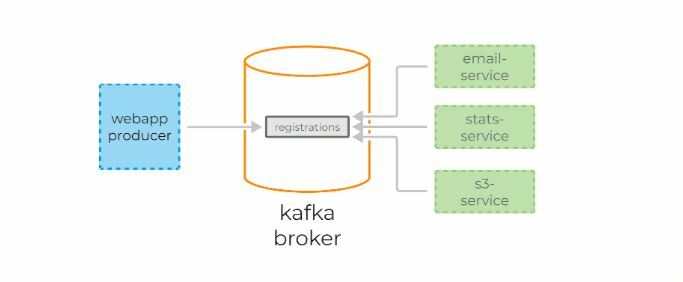
Kafka также позволяет тривиально подключать новые сервисы к стриму регистрации. Например, сервис архивирования всех регистраций в S3 для последующей обработки с помощью Spark или Redshift можно добавить без дополнительного конфигурирования сервера или создания дополнительных очередей.
Кроме того, раз Kafka не удаляет данные после обработки консьюмерами, эти данные могут обрабатываться заново, как бы отматывая время назад сколько угодно раз. Это оказывается невероятно полезно для восстановления после сбоев и, например, верификации кода новых консьюмеров. В случае с RabbitMQ пришлось бы записывать все данные заново, при этом, скорее всего, в отдельную очередь, чтобы не сломать уже имеющихся клиентов.
Структура данных
Наверняка возникает вопрос: «Раз сообщения не удаляются, то как тогда гарантировать, что консьюмер не будет читать одни и те же сообщения (например, при перезапуске)?».
Для ответа на этот вопрос разберёмся, какова внутренняя структура Kafka и как в ней хранятся сообщения.
Каждое сообщение (event или message) в Kafka состоит из ключа, значения, таймстампа и опционального набора метаданных (так называемых хедеров).

Например:
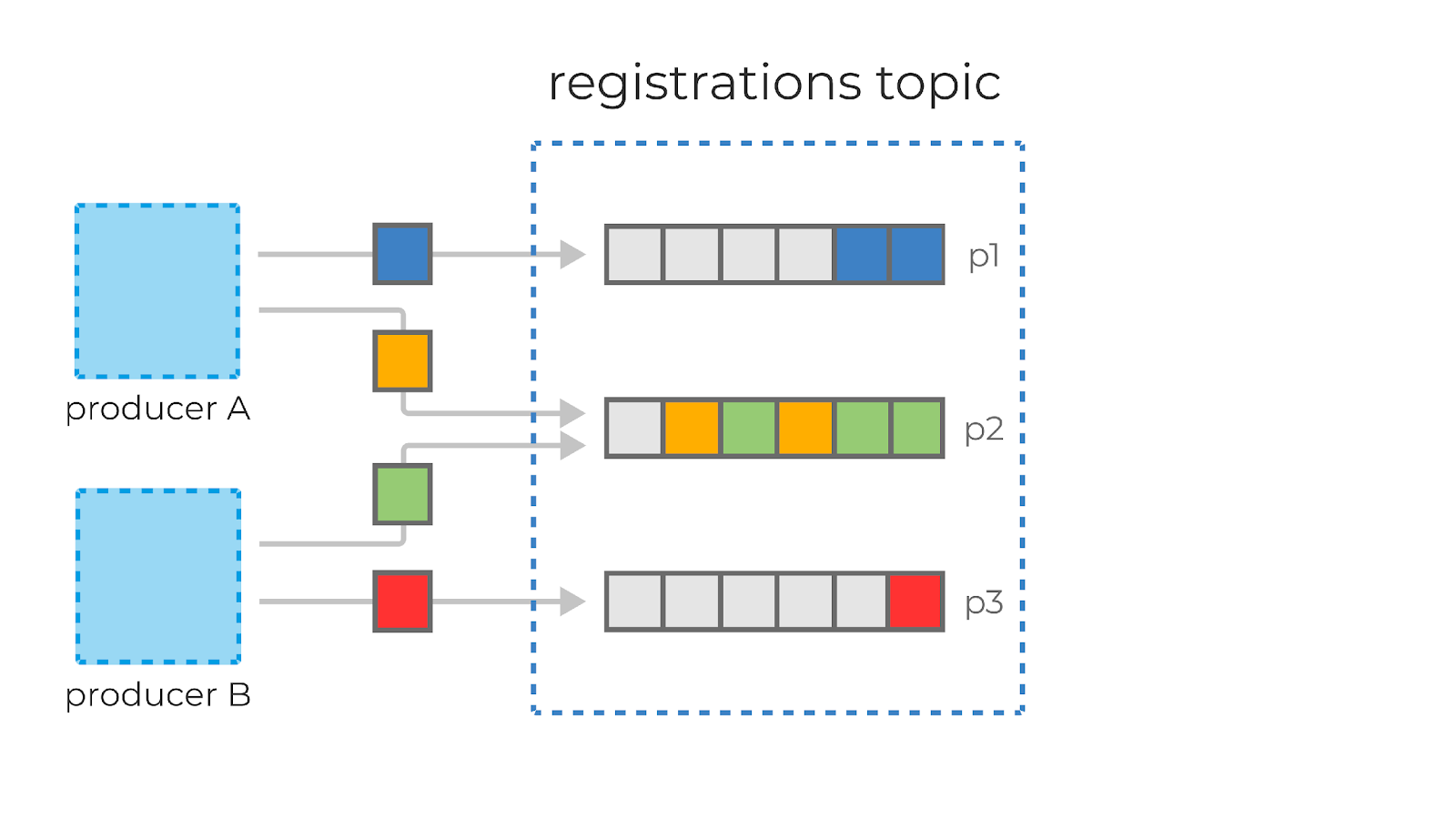
Сообщения в Kafka организованы и хранятся в именованных топиках (Topics), каждый топик состоит из одной и более партиций (Partition), распределённых между брокерами внутри одного кластера. Подобная распределённость важна для горизонтального масштабирования кластера, так как она позволяет клиентам писать и читать сообщения с нескольких брокеров одновременно.
Когда новое сообщение добавляется в топик, на самом деле оно записывается в одну из партиций этого топика. Сообщения с одинаковыми ключами всегда записываются в одну и ту же партицию, тем самым гарантируя очередность или порядок записи и чтения.
Для гарантии сохранности данных каждая партиция в Kafka может быть реплицирована n раз, где n — replication factor. Таким образом гарантируется наличие нескольких копий сообщения, хранящихся на разных брокерах.
У каждой партиции есть «лидер» (Leader) — брокер, который работает с клиентами. Именно лидер работает с продюсерами и в общем случае отдаёт сообщения консьюмерам. К лидеру осуществляют запросы фолловеры (Follower) — брокеры, которые хранят реплику всех данных партиций. Сообщения всегда отправляются лидеру и, в общем случае, читаются с лидера.
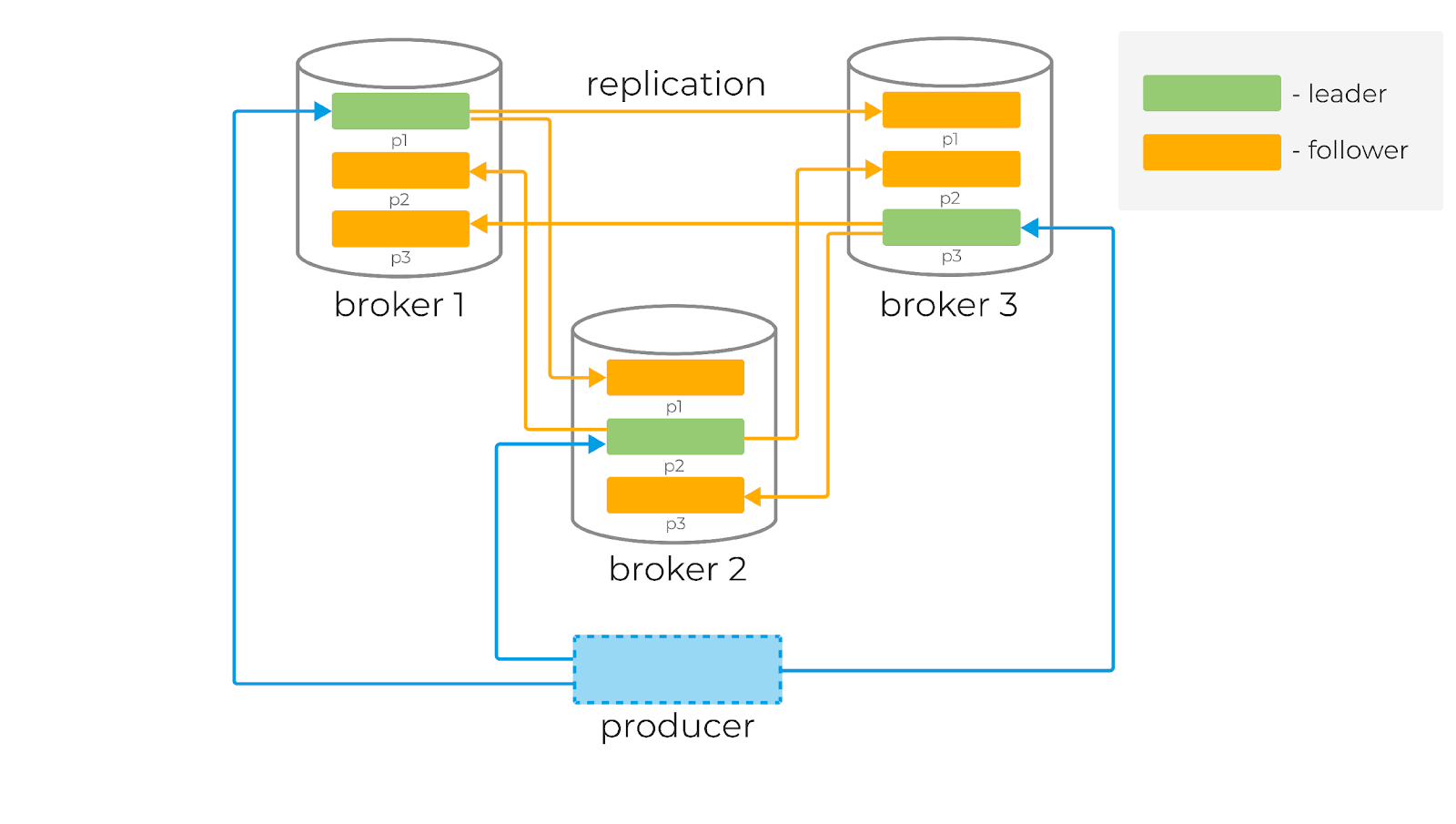
Чтобы понять, кто является лидером партиции, перед записью и чтением клиенты делают запрос метаданных от брокера. Причём они могут подключаться к любому брокеру в кластере.
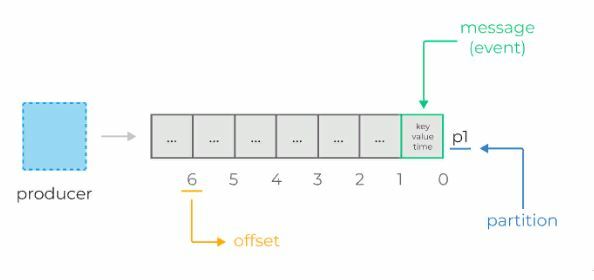
Основная структура данных в Kafka — это распределённый, реплицируемый лог. Каждая партиция — это и есть тот самый реплицируемый лог, который хранится на диске. Каждое новое сообщение, отправленное продюсером в партицию, сохраняется в «голову» этого лога и получает свой уникальный, монотонно возрастающий offset (64-битное число, которое назначается самим брокером).
Как мы уже выяснили, сообщения не удаляются из лога после передачи консьюмерам и могут быть вычитаны сколько угодно раз.
Время гарантированного хранения данных на брокере можно контролировать с помощью специальных настроек. Длительность хранения сообщений при этом не влияет на общую производительность системы. Поэтому совершенно нормально хранить сообщения в Kafka днями, неделями, месяцами или даже годами.
Consumer Groups
Теперь давайте перейдём к консьюмерам и рассмотрим их принципы работы в Kafka. Каждый консьюмер Kafka обычно является частью какой-нибудь консьюмер-группы.
Каждая группа имеет уникальное название и регистрируется брокерами в кластере Kafka. Данные из одного и того же топика могут считываться множеством консьюмер-групп одновременно. Когда несколько консьюмеров читают данные из Kafka и являются членами одной и той же группы, то каждый из них получает сообщения из разных партиций топика, таким образом распределяя нагрузку.
Вернёмся к нашему примеру с топиком сервиса регистрации и представим, что у сервиса отправки писем есть своя собственная консьюмер-группа с одним консьюмером
c1
внутри. Значит, этот консьюмер будет получать сообщения из всех партиций топика.
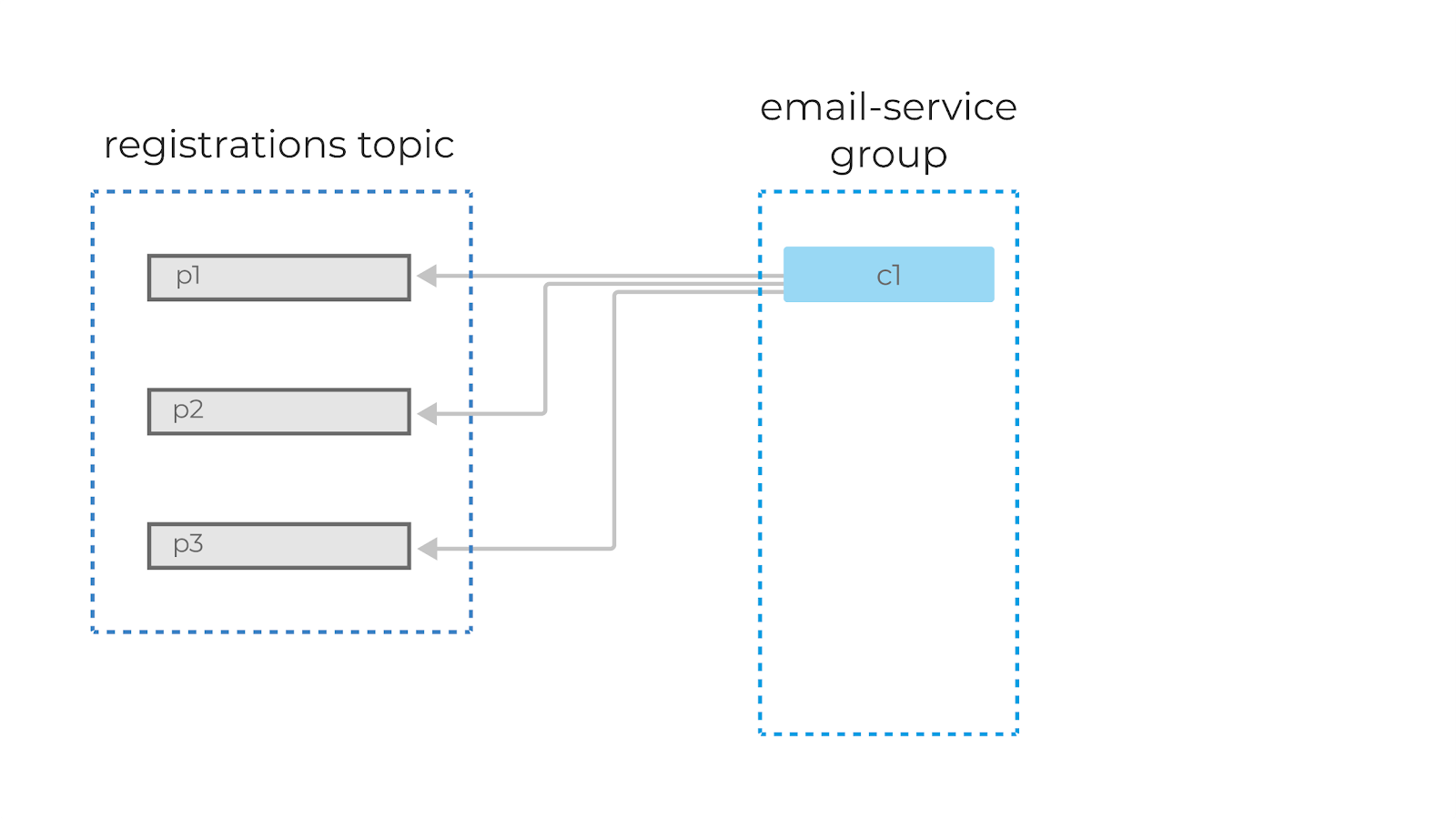
Если мы добавим ещё одного консьюмера в группу, то партиции автоматически распределятся между ними, и
c1
теперь будет читать сообщения из первой и второй партиции, а
c2
— из третьей. Добавив ещё одного консьюмера (c3), мы добьёмся идеального распределения нагрузки, и каждый из консьюмеров в этой группе будет читать данные из одной партиции.
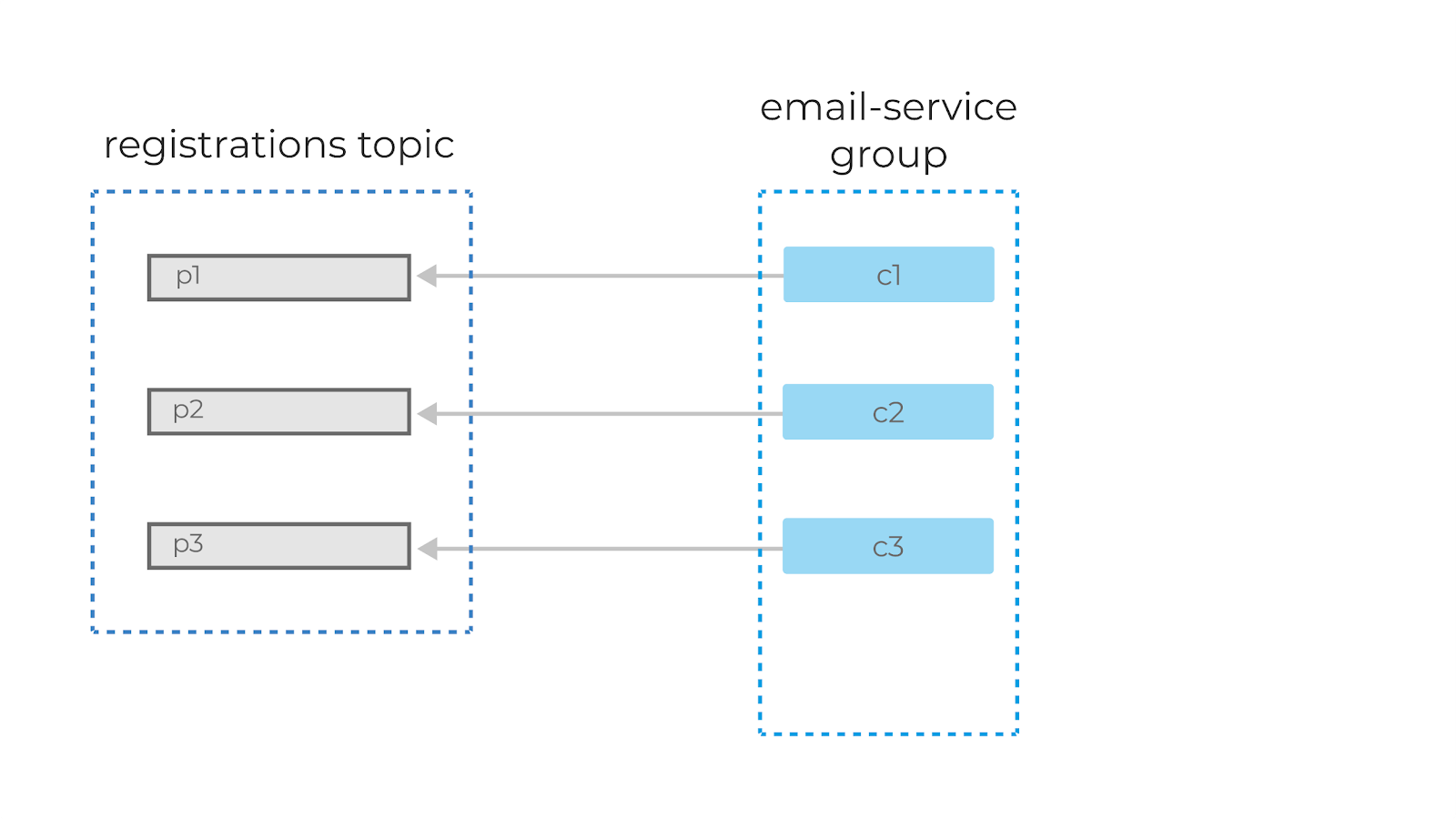
А вот если мы добавим в группу ещё одного консьюмера (c4), то он не будет задействован в обработке сообщений вообще.
Важно понять: внутри одной консьюмер-группы партиции назначаются консьюмерам уникально, чтобы избежать повторной обработки.
Если консьюмеры не справляются с текущим объёмом данных, то следует добавить новую партицию в топик. Только после этого консьюмер c4 начнёт свою работу.
Механизм партиционирования является нашим основным инструментом масштабирования Kafka. Группы являются инструментом отказоустойчивости.
Кстати, как вы думаете, что будет, если один из консьюмеров в группе упадёт? Совершенно верно: партиции автоматически распределятся между оставшимися консьюмерами в этой группе.
Добавлять партиции в Kafka можно на лету, без перезапуска клиентов или брокеров. Клиенты автоматически обнаружат новую партицию благодаря встроенному механизму обновления метаданных. Однако, нужно помнить две важные вещи:
- Гарантия очерёдности данных — если вы пишете сообщения с ключами и хешируете номер партиции для сообщений, исходя из общего числа, то при добавлении новой партиции вы можете просто сломать порядок этой записи.
- Партиции невозможно удалить после их создания, можно удалить только весь топик целиком.
Помимо этого, механизм групп позволяет иметь несколько несвязанных между собой приложений, обрабатывающих сообщения.
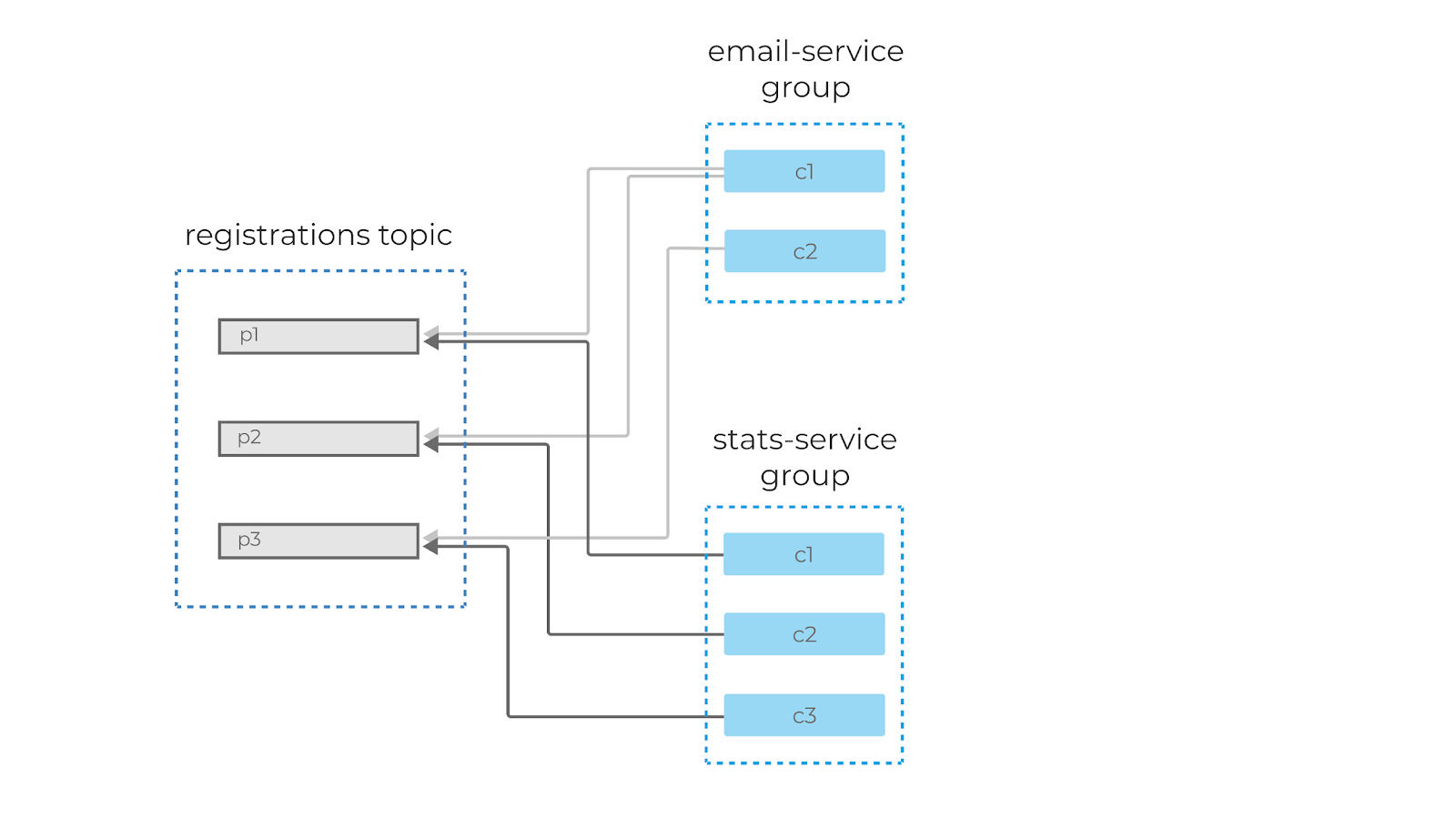
Как мы обсуждали ранее, можно добавить новую группу консьюмеров к тому же самому топику, например, для обработки и статистики регистраций. Эти две группы будут читать одни и те же сообщения из топика тех самых ивентов регистраций — в своём темпе, со своей внутренней логикой.
А теперь, зная внутреннее устройство консьюмеров в Kafka, давайте вернёмся к изначальному вопросу: «Каким образом мы можем обозначить сообщения в партиции, как обработанные?».
Для этого Kafka предоставляет механизм консьюмер-офсетов. Как мы помним, каждое сообщение партиции имеет свой собственный, уникальный, монотонно возрастающий офсет. Именно этот офсет и используется консьюмерами для сохранения партиций.
Консьюмер делает специальный запрос к брокеру, так называемый offset-commit с указанием своей группы, идентификатора топик-партиции и, собственно, офсета, который должен быть отмечен как обработанный. Брокер сохраняет эту информацию в своём собственном специальном топике. При рестарте консьюмер запрашивает у сервера последний закоммиченный офсет для нужной топик-партиции, и просто продолжает чтение сообщений с этой позиции.
В примере консьюмер в группе email-service-group, читающий партицию p1 в топике registrations, успешно обработал три сообщения с офсетами 0, 1 и 2. Для сохранения позиций консьюмер делает запрос к брокеру, коммитя офсет 3. В случае рестарта консьюмер запросит свою последнюю закоммиченную позицию у брокера и получит в ответе 3. После чего начнёт читать данные с этого офсета.
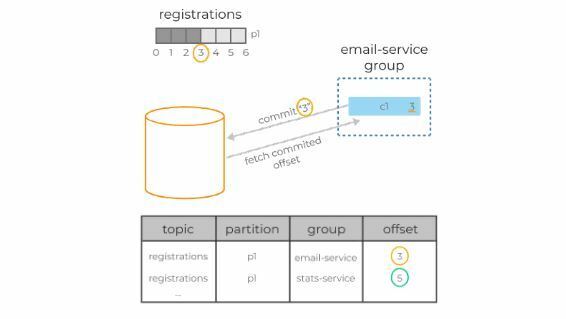
Консьюмеры вольны коммитить совершенно любой офсет (валидный, который действительно существует в этой топик-партиции) и могут начинать читать данные с любого офсета, двигаясь вперёд и назад во времени, пропуская участки лога или обрабатывая их заново.
Ключевой для понимания факт: в момент времени может быть только один закоммиченный офсет для топик-партиции в консьюмер-группе. Иными словами, мы не можем закоммитить несколько офсетов для одной и той же топик-партиции, эмулируя каким-то образом выборочный acknowledgment (как это делалось в системах очередей).
Представим, что обработка сообщения с офсетом 1 завершилась с ошибкой. Однако мы продолжили выполнение нашей программы в консьюмере и запроцессили сообщение с офсетом 2 успешно. В таком случае перед нами будет стоять выбор: какой офсет закоммитить — 1 или 3. В настоящей системе мы бы рекомендовали закоммитить офсет 3, добавив при этом функционал, отправляющий ошибочное сообщение в отдельный топик для повторной обработки (ручной или автоматической). Подобные алгоритмы называются Dead letter queue.
Разумеется, консьюмеры, находящиеся в разных группах, могут иметь совершенно разные закоммиченные офсеты для одной и той же топик-партиции.
Apache ZooKeeper
В заключение нужно упомянуть об ещё одном важном компоненте кластера Kafka — Apache ZooKeeper.
ZooKeeper выполняет роль консистентного хранилища метаданных и распределённого сервиса логов. Именно он способен сказать, живы ли ваши брокеры, какой из брокеров является контроллером (то есть брокером, отвечающим за выбор лидеров партиций), и в каком состоянии находятся лидеры партиций и их реплики.
В случае падения брокера именно в ZooKeeper контроллером будет записана информация о новых лидерах партиций. Причём с версии 1.1.0 это будет сделано асинхронно, и это важно с точки зрения скорости восстановления кластера. Самый простой способ превратить данные в тыкву — потеря информации в ZooKeeper. Тогда понять, что и откуда нужно читать, будет очень сложно.
В настоящее время ведутся активные работы по избавлению Kafka от зависимости в виде ZooKeeper, но пока он всё ещё с нами (если интересно, посмотрите на Kafka improvement proposal 500, там подробно расписан план избавления от ZooKeeper).
Важно помнить, что ZooKeeper по факту является ещё одной распределённой системой хранения данных, за которой необходимо следить, поддерживать и обновлять по мере необходимости.
Традиционно ZooKeeper раскатывается отдельно от брокеров Kafka, чтобы разделить границы возможных отказов. Помните, что падение ZooKeeper — это практически падение всего кластера Kafka. К счастью, нагрузка на ZooKeeper при нормальной работе кластера минимальна. Клиенты Kafka никогда не коннектятся к ZooKeeper напрямую.
Источник: slurm.io