
Что такое большие данные? Большие данные — это комбинация структурированных, полуструктурированных и неструктурированных данных, собранных организациями, которые можно извлечь для получения информации и использовать в проектах машинного обучения, прогнозном моделировании и других передовых аналитических приложениях.
Системы, обрабатывающие и хранящие большие данные, стали распространенным компонентом архитектур управления в организациях в сочетании с инструментами, поддерживающими использование аналитики больших данных. Большие данные характеризуются тремя V:
- большой объем(volume) данных во многих средах;
- разнообразие (variety) типов данных, часто хранящихся в системах больших данных;
- скорость (velocity) , с которой большая часть данных генерируется, собирается и обрабатывается.
Эти характеристики больших данных впервые определены в 2001 году Дугом Лейни, в то время аналитиком консалтинговой фирмы Meta Group Inc. Gartner еще больше популяризировала их после приобретения Meta Group в 2005 году. Недавно к описаниям больших данных добавлен ряд других V, включая достоверность (veracity) , ценность (value) и изменчивость (variability) .
Что такое Big Data
Биг дата это развертывание больших данных, включающих в себя терабайты, петабайты и даже эксабайты информации, созданной и собранной с течением времени.
Почему важны большие данные?
Многие компании используют неструктурированные данные в системах для улучшения операционной деятельности, повышения клиентского сервиса, создания таргетированных маркетинговых кампаний и принятия других мер, которые помогают увеличить доходы и прибыль. Организации, использующие ИТ, обладают конкурентным преимуществом перед компаниями, которые игнорируют технический прогресс, так как способны принимать скоростные и обоснованные бизнес-решения.
Например, Big Data предоставляют информацию о клиентах, которую руководители фирм могут использовать для совершенствования маркетинга, рекламы и рекламных акций с целью повышения вовлеченности клиентов и коэффициента конверсии. Как исторические, так и данные в реальном времени могут быть проанализированы для оценки меняющихся предпочтений потребителей или корпоративных покупателей, что позволяет компаниям чутко реагировать на желания и потребности клиентов.
Технологии Big Data также используются медицинскими исследователями для выявления признаков болезней и факторов риска, а также врачами для диагностики. Комбинация сведений из электронных медицинских карт, сайтов социальных сетей и других источников предоставляет организациям здравоохранения и государственным учреждениям информацию об угрозах или вспышках инфекционных заболеваний.
Еще примеры того, где используется Big Data :
- В энергетической отрасли большие данные помогают нефтегазовым компаниям определять места бурения и контролировать работу трубопроводов; аналогичным образом, коммунальные службы используют их для отслеживания электрических сетей.
- Фирмы, предоставляющие финансовые услуги, используют системы Big Data для управления рисками и анализа рынка в режиме Real-time.
- Производители и транспортные компании полагаются на большие данные для управления цепочками поставок и оптимизации маршрутов доставки.
- Другие виды использования правительством включают реагирование на чрезвычайные ситуации, предупреждение преступности и инициативы «умного города»
Каковы примеры больших данных?
Источники больших данных — это базы клиентов, документы, email-ы, медицинские записи, журналы кликов в Интернете, мобильные приложения и социальные сети. Это могут быть данные, сгенерированные машиной, такие как файлы журналов сети и сервера, а также показания с датчиков на производственных машинах, промышленном оборудовании и устройствах Интернета вещей.
Что такое Big Data за 6 минут
В дополнение к информации из внутренних систем, среды больших данных часто включают внешние показатели о потребителях, финансовых рынках, погодных и дорожных условиях, географической информации, научных исследованиях и проч. Изображения, видео и аудиофайлы — также формы больших данных, и ряд приложений включает потоковые данные, которые обрабатываются и собираются на постоянной основе.
Разбивка V-х больших данных
Объем — часто упоминаемая характеристика больших данных. Методы обработки больших данных позволяют не содержать большой объем информации, но большинство из них содержат их из-за характера собираемых и хранимых в них сведений. Потоки кликов, системные журналы и системы потоковой обработки относятся к числу источников, которые на постоянной основе производят огромные массивы информации.
Big Data также охватывают расширенный спектр типов информации, включая следующие:
- структурированные — транзакции и финансовые отчеты;
- неструктурированные — текст, документы и мультимедийные файлы;
- полуструктурированные — журналы веб-сервера и потоковые данные с датчиков.
Способы хранения информации в базах данных позволяют организовать совместное хранение и управление различными их типами. Кроме того, приложения для работы с базами часто включают в себя информационные наборы, которые могут не быть интегрированы заранее. Например, проект по анализу больших данных может попытаться спрогнозировать продажи продукта путем сопоставления данных о прошлых продажах, возвратах, онлайн-отзывах и звонках в службу поддержки клиентов.
Немало зависит от скорости, с которой генерируются данные, которые должны быть обработаны и проанализированы. Очень часто Big Data обновляются в режиме реального или почти реального времени вместо ежедневных, еженедельных или ежемесячных обновлений, выполняемых в традиционных хранилищах. Управление скоростью передачи данных также важно, поскольку анализ Big Data расширяется до машинного обучения и искусственного интеллекта (ИИ), где аналитические процессы автоматически находят закономерности в данных и используют их для получения информации.
Дополнительные характеристики больших данных
Заглядывая за рамки первоначальных трех V, вот подробная информация о некоторых других, которые теперь часто ассоциируются с большими данными:
- Достоверность относится к степени точности наборов данных и их надежности. Необработанная информация, собранная из различных источников, может вызвать проблемы с качеством файлов, которые трудно определить. Если они не устраняются с помощью процессов очистки, то приводят к ошибкам анализа, которые могут подорвать ценность инициатив в области бизнес-аналитики. Команды управления базами и аналитики также должны убедиться, что у них хватит точных данных для получения достоверных результатов.
- Некоторые эксперты по обработке массивов также добавляют ценность в список характеристик больших данных. Не все собранные данные имеют деловую ценность или преимущества. В результате организациям необходимо подтвердить, что собранная информация относится к соответствующим бизнес-вопросам, прежде чем они будут использоваться в проектах по анализу Big Data.
- Вариативность также часто применяется к наборам больших данных, которые могут иметь несколько значений или быть по-разному отформатированы в отдельных источниках информации-факторы, которые еще больше усложняют управление большими данными и аналитику.
Как хранятся и обрабатываются большие данные?
Работа с большими данными сильно зависит от того, как они будут сохранены. Большие данные часто хранятся в озере данных ( DataLake ). Хранилища строятся на основе реляционных баз и содержат только структурированные файлы, озера данных могут поддерживать различные типы данных и, как правило, основаны на кластерах Hadoop, облачных службах хранения объектов, базах данных NoSQL или других платформах больших данных.
Часто среды больших данных объединяют несколько систем в распределенной архитектуре, где хранить данные . К примеру, центральное озеро данных может быть интегрировано с другими платформами, включая реляционные базы или хранилище данных. Информация в системах больших данных может быть оставлена в необработанном виде, а затем отфильтрована и организована по мере необходимости для конкретных аналитических целей. В других случаях она предварительно обрабатывается с помощью инструментов интеллектуального анализа и программного обеспечения для подготовки данных, поэтому готова для приложений, которые регулярно запускаются.
Обработка больших данных предъявляет высокие требования к базовой вычислительной инфраструктуре. Требуемая вычислительная мощность часто обеспечивается кластерными системами, которые распределяют рабочие нагрузки по обработке на сотнях или тысячах товарных серверов, используя такие технологии, как Hadoop и механизм обработки Spark. Каждая технология хранения информации совершенствуется со временем.
Получение производственных мощностей экономически эффективным способом является сложной задачей. В результате облако является популярным местом для систем больших данных. Организации могут развертывать свои собственные облачные системы или использовать управляемые приложения «большие данные как услуга» от облачных провайдеров ( Big Data компании ), например платформу cloud.timeweb.com . Пользователи могут увеличить необходимое количество серверов ровно настолько, чтобы завершить проекты по анализу больших данных. Бизнес платит только за используемое им время хранения и вычислений.
Как работает аналитика больших данных
Чтобы получать достоверные и релевантные результаты из приложений проводится анализ больших данных . Специалисты по обработке данных должны иметь четкое представление о доступных данных и понимать, что такое инструменты Big Data . Это делает подготовку данных, которая включает профилирование, очистку, проверку и преобразование наборов данных, первым шагом в процессе аналитики.
Как только нужная информация собрана и подготовлена, в дело вступают приложения с использованием инструментов, обеспечивающих функции и возможности анализа Big Data. Методы анализа больших данных включают машинное обучение, прогнозное моделирование, интеллектуальный анализ данных, статистический анализ, интеллектуальный анализ текста и т. д. Относится сюда и потоковая аналитика Big Data .
Используя информацию клиентов в качестве примера, разделы аналитики, которые можно выполнять с наборами больших данных, включают следующее:
- Сравнительный анализ. При этом анализируются показатели поведения клиентов и взаимодействие с ними в режиме реального времени, чтобы сравнить продукты, услуги и брендинг компании и ее конкурентов.
- Прослушивание в социальных сетях. Это анализ того, что люди говорят в социальных сетях о бизнесе или продукте, что может помочь определить потенциальные проблемы и целевую аудиторию для маркетинговых кампаний.
- Маркетинговая аналитика. Это обработка информации, которая может быть использована для улучшения маркетинговых кампаний и рекламных предложений для продуктов, услуг и бизнес-инициатив.
- Анализ настроений. Информация, собранная о клиентах, может быть проанализирована, чтобы выявить их отношение к компании или бренду, уровень удовлетворенности клиентов, проблемы и способы улучшения обслуживания.
Технологии управления большими данными
Hadoop, платформа распределенной обработки с открытым исходным кодом, выпущенная в 2006 году, изначально находилась в центре большинства Big Data технологий . Развитие Spark и других движков обработки данных отодвинуло MapReduce, движок, встроенный в Hadoop, в сторону. Результатом является технология больших данных , используемых для разных приложений, но часто развертываются вместе.
Платформы больших данных и управляемые сервисы, предлагаемые ИТ-поставщиками, объединяют многие из этих технологий в одном пакете, в первую очередь для использования в облаке. Рассмотрим эти предложения, перечисленные в алфавитном порядке:
- Amazon EMR (эластичный MapReduce)
- Платформа Cloudera
- Google Cloud Dataproc
- Структура данных HPE Ezmeral (платформа MapR)
- Microsoft Azure HDInsight
Для компании, которые хотят самостоятельно развертывать системы больших данных, будь то локально или в облаке, технологии, доступные им в дополнение к Hadoop и Spark, включают следующие категории инструментов:
- хранилища, как основной инструмент сбора хранения и переработки информации — файловая система Hadoop (HDFS) и облачные службы хранения объектов, которые включают службу Amazon Simple Storage Service (S3), облачное хранилище Google и хранилище больших двоичных объектов Azure;
- структуры управления кластерами, такие как Kubernetes, Mesos и YARN, встроенный менеджер ресурсов и планировщик заданий Hadoop, который означает еще один переговорщик по ресурсам, но обычно известен только под аббревиатурой;
- механизмы потоковой обработки: Flink, Hudi, Kafka, Samza, Storm, а также модули потоковой передачи и структурированной потоковой передачи, встроенные в Spark;
- базы данных NoSQL, включающие Cassandra и Couchbase, CouchDB и HBase. Также — центр обработки данных MarkLogic, MongoDB, Neo4j, Redis и другие технологии;
- озеро данных и платформы хранилища больших данных , в том числе Amazon Redshift, Delta Lake, Google BigQuery, Kylin и Snowflake;
- механизмы SQL-запросов, такие как Drill, Hive, Impala, Presto и Trino.
Проблемы с большими данными
Хотя эксперты по обработке данных стараются улучшить качество данных и сделать аналитические алгоритмы надежнее (невосприимчивыми к проблемам), анализ больших данных не идеален. Пока невозможно решить некоторые проблемы:
- Несовершенная аналитика
- Поспешное технологическое развитие
- Техно-неопределенность
- Нехватка экспертов
- Негативное социальное воздействие
Ключи к эффективной стратегии больших данных
В организации создание стратегии больших данных требует понимания бизнес-целей и информации, которая доступна для использования, а также оценки потребности в дополнительных данных для достижения целей. Шаги, которые необходимо предпринять, включают следующее:
- определение приоритетов запланированных вариантов использования и приложений;
- определение новых систем и инструментов, которые необходимы;
- создание дорожной карты развертывания;
- оценка внутренних навыков, чтобы определить, требуется ли переподготовка или прием на работу.
Для того чтобы наборы Big Data были чистыми, согласованными и использовались нужным образом, программы и процессы управления качеством данных также должны быть приоритетными. Другие методы управления и анализа больших данных включают сосредоточение внимания на потребностях бизнеса в информации с использованием доступных технологий и использование визуализации больших данных для облегчения поиска и анализа.
Источник: timeweb.cloud
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
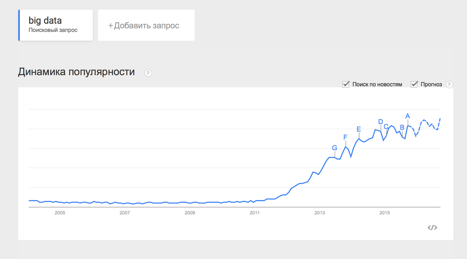
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):

MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
def map(doc): for word in doc: yield word, 1
def reduce(word, values): yield word, sum(values)
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
,,,,, 11111,RU,Moscow,2,4,0.3 22222,RU,Voronezh,2,3,0.2 13413,UA,Kiev,4,11,0.7 …
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
def map(record): user_id, country, city, campaign_id, creative_id, payment = record.split(«,») payment=float(payment) if country == «RU»: yield city, payment
def reduce(city, payments): yield city, sum(payments)/len(payments)
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Источник: habr.com
Что такое программа биг дата

Одно из определений больших данных звучит следующим образом: «данные можно назвать большими, когда их размер становится частью проблемы». Такие объемы информации не могут быть сохранены и обработаны с использованием традиционного вычислительного подхода в течение заданного периода времени. Но насколько огромными должны быть данные, чтобы их можно было назвать большими?
Обычно мы говорим о гигабайтах, терабайтах, петабайтах, эксабайтах или более крупных единицах измерения. Тут и возникает неправильное представление. Даже данные маленького объема можно назвать большими в зависимости от контекста, в котором они используются.
Например, почтовый сервер может не позволить отправить письмо с вложением на 100 мегабайт, или, допустим, у нас есть около 10 терабайт графических файлов, которые необходимо обработать. Используя настольный компьютер, мы не сможем выполнить эту задачу в течение заданного периода времени из-за нехватки вычислительных ресурсов.
Как классифицируются большие данные?
Выделим три категории:
Характеристики больших данных
Большие данные характеризуются четырьмя правилами (англ. 4 V’s of Big Data: Volume, Velocity, Variety, Veracity) :
- Объем: компании могут собирать огромное количество информации, размер которой становится критическим фактором в аналитике.
- Скорость, с которой генерируется информация. Практически все происходящее вокруг нас (поисковые запросы, социальные сети и т. д.) производит новые данные, многие из которых могут быть использованы в бизнес-решениях.
- Разнообразие: генерируемая информация неоднородна и может быть представлена в различных форматах, вроде видео, текста, таблиц, числовых последовательностей, показаний сенсоров и т. д. Понимание типа больших данных является ключевым фактором для раскрытия их ценности.
- Достоверность: достоверность относится к качеству анализируемых данных. С высокой степенью достоверности они содержат много записей, которые ценны для анализа и которые вносят значимый вклад в общие результаты. С другой стороны данные с низкой достоверностью содержат высокий процент бессмысленной информации, которая называется шумом.
Традиционный подход к хранению и обработке больших данных
При традиционном подходе данные, которые генерируются в организациях, подаются в систему ETL (от англ. Extract, Transform and Load) . Система ETL извлекает информацию, преобразовывает и загружает в базу данных. Как только этот процесс будет завершен, конечные пользователи смогут выполнять различные операции, вроде создание отчетов и запуска аналитических процедур.
По мере роста объема данных, становится сложнее ими управлять и тяжелее обрабатывать их с помощью традиционного подхода. К его основным недостаткам относятся:
Термины
Облачные Вычисления
Облачные вычисления или облако можно определить, как интернет-модель вычислений, которая в значительной степени обеспечивает доступ к вычислительным ресурсам. Эти ресурсы включают в себя множество вещей, вроде прикладного программного обеспечение, вычислительных ресурсов, серверов, центров обработки данных и т. д.
Прогнозная Аналитика
Технология, которая учится на опыте (данных) предсказывать будущее поведение индивидов с помощью прогностических моделей. Они включают в себя характеристики (переменные) индивида в качестве входных данных и производит оценку в качестве выходных. Чем выше объясняющая способность модели, тем больше вероятность того, что индивид проявит предсказанное поведение.
Описательная Аналитика
Описательная аналитика обобщает данные, уделяя меньше внимания точным деталям каждой их части, вместо этого сосредотачиваясь на общем повествовании.
Базы данных
Данные нуждаются в кураторстве, в правильном хранении и обработке, чтобы они могли быть преобразованы в ценные знания. База данных – это механизм хранения, облегчающий такие преобразования.
Хранилище Данных
Хранилище данных определяется как архитектура, которая позволяет руководителям бизнеса систематически организовывать, понимать и использовать свои данные для принятия стратегических решений.
Бизнес-аналитика
Бизнес-аналитика (BI) – это набор инструментов, технологий и концепций, которые поддерживают бизнес, предоставляя исторические, текущие и прогнозные представления о его деятельности. BI включает в себя интерактивную аналитическую обработку (англ. OLAP, online analytical processing) , конкурентную разведку, бенчмаркинг, отчетность и другие подходы к управлению бизнесом.
Apache Hadoop
Apache Hadoop – это фреймворк с открытым исходным кодом для обработки больших объемов данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений.
Apache Spark
Apache Spark – это мощный процессорный движок с открытым исходным кодом, основанный на скорости, простоте использования и сложной аналитике, с API-интерфейсами на Java, Scala, Python, R и SQL. Spark запускает программы в 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Его можно использовать для создания приложений данных в виде библиотеки или для выполнения специального анализа в интерактивном режиме. Spark поддерживает стек библиотек, включая SQL, фреймы данных и наборы данных, MLlib для машинного обучения, GraphX для обработки графиков и потоковую передачу.
Интернет вещей
Интернет вещей (IoT) – это растущий источник больших данных. IoT – это концепция, позволяющая осуществлять интернет-коммуникацию между физическими объектами, датчиками и контроллерами.
Машинное Обучение
Машинное обучение может быть использовано для прогностического анализа и распознавания образов в больших данных. Машинное обучение является междисциплинарным по своей природе и использует методы из области компьютерных наук, статистики и искусственного интеллекта. Основными артефактами исследования машинного обучения являются алгоритмы, которые облегчают автоматическое улучшение на основе опыта и могут быть применены в таких разнообразных областях, как компьютерное зрение и интеллектуальный анализ данных.
Интеллектуальный Анализ Данных
Интеллектуальный анализ данных – это применение специфических алгоритмов для извлечения паттернов из данных. В интеллектуальном анализе акцент делается на применении алгоритмов в ходе которых машинное обучение используются в качестве инструмента для извлечения потенциально ценных паттернов, содержащихся в наборах данных.
Где применяются большие данные
Аналитика больших данных применяется в самых разных областях. Перечислим некоторые из них:
- Поставщикам медицинских услуг аналитика больших данных нужна для отслеживания и оптимизации потока пациентов, отслеживания использования оборудования и лекарств, организации информации о пациентах и т. д.
- Туристические компании применяют методы анализа больших данных для оптимизации опыта покупок по различным каналам. Они также изучают потребительские предпочтения и желания, находят корреляцию между текущими продажами и последующим просмотром, что позволяет оптимизировать конверсии.
- Игровая индустрия использует BigData, чтобы получить информацию о таких вещах, как симпатии, антипатии, отношения пользователей и т. д.
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.
Источник: proglib.io