
Аннотация: В рамках данной лекции будут рассмотрены следующие вопросы: определение, назначение параллельного программирования; многоядерные вычисления; множественные потоки команд/данных; ускорение; закон Амадал; закон Густафсона-Барсиса.
Определение, назначение параллельного программирования
Существуют различные способы написания программ, которые условно можно разделить на три группы:
- Последовательное программирование с дальнейшим автоматическим распараллеливанием.
- Непосредственное формирование потоков параллельного управления, с учетом особенностей архитектур параллельных вычислительных систем или операционных систем.
- Описание параллелизма без использования явного управления обеспечивается заданием только информационных связей. Предполагается, что программа будет выполняться на вычислительных системах с бесконечными ресурсами, операторы будут запускаться немедленно по готовности их исходных данных.
Каждый из перечисленных подходов обладает своими достоинствами и недостатками параллельное программирование .
Как параллельные Вселенные влияют на нас?
Параллельные вычисления — способ организации компьютерных вычислений, при котором программы разрабатываются, как набор взаимодействующих вычислительных процессов, работающих асинхронно и при этом одновременно.
Параллельное программирование — это техника программирования, которая использует преимущества многоядерных или многопроцессорных компьютеров и является подмножеством более широкого понятия многопоточности ( multithreading ).
Многоядерные вычисления
Использование параллельного программирования становится наиболее необходимым, поскольку позволяет максимально эффективно использовать возможности многоядерных процессоров и многопроцессорных систем. По ряду причин, включая повышение потребления энергии и ограничения пропускной способности памяти, увеличивать тактовую частоту современных процессоров стало невозможно. Вместо этого производители процессоров стали увеличивать их производительность за счет размещения в одном чипе нескольких вычислительных ядер, не меняя или даже снижая тактовую частоту. Поэтому для увеличения скорости работы приложений теперь следует по -новому подходить к организации кода, а именно — оптимизировать программы под многоядерные системы.
Множественные потоки команд/данных (Классификация М.Флинна)
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD , MISD , SIMD , MIMD . Описание классов приведено в Табл. 1.1.
| SISD (single instructiоn streаm / single dаtа streаm) или ОКОД (Одиночный поток Команд, Одиночный поток Данных) | Одиночный поток команд и одиночный поток данных (исполнение одним процессором одного потока команд, обрабатывающего данные, хранящиеся в одной памяти). К этому классу относятся, классические последовательные машины, или иначе, машины фон-неймановского типа (PDP-11 или VАX 11/780). |
| SIMD (single instructiоn streаm / multiple dаtа streаm) или ОКМД (одиночный поток команд, множественный поток данных) | Одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса (SISD), векторные команды, что позволяет выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. |
| MISD (multiple instructiоn streаm / single dаtа streаm) или МКОД (Множественный поток Команд, Одиночный поток Данных) | Множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. |
| MIMD (multiple instructiоn streаm / multiple dаtа streаm) или МКМД (Множественный поток Команд, Множественный поток Данных) | Множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. |
На основании Табл. 1.1 можно проранжировать архитектуры на однопоточность/многопоточность (Табл. 1.2).
Параллельные Вселенные | Морган Фримен | Discovery
| Одиночный поток данных (Single Dаtа) | SISD (ОКОД) | MISD (МКОД) |
| Множество потоков данных (Multiple Dаtа) | SIMD (ОКМД) | MIMD (МКМД) |
Ускорение (Speedup)
Ускорением параллельного алгоритма называется отношение :
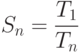
где 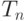 — время вычисления задачи на n процессорах,
— время вычисления задачи на n процессорах, 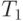 — время выполнения однопоточной программы
— время выполнения однопоточной программы
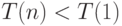
, если параллельная версия алгоритма эффективна.
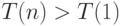 , если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
, если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
С ускорением связана эффективность параллельного алгоритма. Эффективностью параллельного алгоритма называется величина:

По определению, 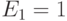 . Теоретически должно быть
. Теоретически должно быть  и
и 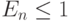 . Если алгоритм достигает максимального ускорения
. Если алгоритм достигает максимального ускорения  , то
, то  . На практике эффективность убывает при увеличении числа процессоров.
. На практике эффективность убывает при увеличении числа процессоров.
 (суперлинейное ускорение). Эта аномалия вызвана, чаще всего, двумя причинами:
(суперлинейное ускорение). Эта аномалия вызвана, чаще всего, двумя причинами:
- В качестве последовательного алгоритма был применён не самый быстрый алгоритм из существующих.
- С увеличением количества вычислителей растёт суммарный объём их оперативной и кэш памяти. Поэтому всё большая часть данных задачи умещается в оперативной памяти и не требует подкачки с диска, или (чаще всего) умещается в кэше.
Закон Амдала
Закон Амдала (1967 год), описывает максимальный теоретический выигрыш в производительности параллельного решения по отношению к лучшему последовательному решению. Закон Амдала описывается следующей математической формулой:
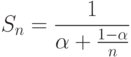
где 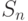 — во сколько раз можно ускорить вычисления (ускорение), n — количество процессоров (ядер),
— во сколько раз можно ускорить вычисления (ускорение), n — количество процессоров (ядер),  — доля последовательно вычисляемого кода (
— доля последовательно вычисляемого кода ( ).
).
Закон Амдаля, несмотря на то, что он не учитывает многих факторов, накладывает ограничения на максимально достижимую эффективность параллельного алгоритма.
Предположим, например, что 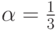 , то есть две трети операций в алгоритме могут выполняться параллельно, а треть — нет. Тогда ускоре-ние
, то есть две трети операций в алгоритме могут выполняться параллельно, а треть — нет. Тогда ускоре-ние 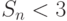
Закон Густафсона-Барсиса
Закон Густафсона — Барсиса (1988г) оценивает максимально допустимое ускорение выполнения параллельной программы, в зависимости от количества одновременно выполняемых потоков вычислений и доли последовательных расчётов. Формула Густафсона — Барсиса выглядит следующим образом:
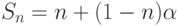
Где — доля последовательных расчётов в программе,  — количество процессоров.
— количество процессоров.
Густафсон заметил, что, работая на многопроцессорных системах, пользователи склонны к изменению тактики решения задачи. Теперь снижение общего времени исполнения программы уступает объёму решаемой задачи. Такое изменение цели обусловливает переход от закона Амдала к закону Густафсона. К примеру, на 100 процессорах программа выполняется 20 минут.
При переходе на систему с 1000 процессорами можно достичь времени исполнения порядка двух минут. Однако для получения большей точности решения имеет смысл увеличить объём решаемой задачи, т.е. при сохранении общего времени исполнения пользователи стремятся получить более точный результат. Увеличение объёма решаемой задачи приводит к увеличению доли параллельной части, так как последовательная часть ( ввод/вывод , менеджмент потоков, точки синхронизации и т.п.) не изменяется.
Источник: intuit.ru
Введение в параллелизм
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Использование мьютекса зачастую намного проще, чем использование атомарных операций. Он позволяет создать критическую секцию, которая может быть выполнена не более чем одним потоком в любой данный момент времени. Кроме того, продвинутые мьютексы, такие как shared_lock , в некоторых случаях могут повысить эффективность, позволяя группе потоков исполнять критическую секцию, если мьютекс не захвачен в эксклюзивное использование.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector vec)
int num_threads = 2;
auto thread_func = [vec,
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождаться всех потоков
// до разрушения std::vector
Запустив нашу программу, мы, вероятно, увидим неверный результат. Причина в том, что с помощью мьютекса мы защитили себя от data race при вычислении суммы, но основной поток может считывать переменную sum, в то время как другие потоки изменяют ее.
Даже если мы защитим чтение с помощью мьютекса, это приведет к другой неочевидной сложности, называемой race condition: чтение, защищённое с помощью мьютекса, не гарантирует логическую корректность алгоритма. В нашем случае мы не дожидаемся полного завершения вычислений. Чтобы решить эту проблему, мы должны дождаться завершения потоков, прежде чем считывать результат. Однако, в данном случае мьютекс не требуется для чтения общей суммы , потому что синхронизация вычислений выполняется во время ожидания потоков (с помощью функции join).
int summarize(const std::vector
auto thread_func = [vec,
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождатьсявсех потоков до
Этот подход к распараллеливанию, очевидно, будет работать медленнее, чем последовательная версия, потому что для каждого sum += vec[i] мы берем мьютекс std:: lock_guard lock (m) . Таким образом, мы полностью упорядочиваем вычисления, т. е. разрешаем работать только одному потоку в любой момент времени. Чтобы избежать этого, мы можем сначала выполнить локальное суммирование в каждом потоке, а в конце вычислений добавить результат к глобальной сумме.
auto thread_func = [vec,
int end_index = vec.size() / 2 * (thread_id + 1);
int local_sum = 0;
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
Этот простой пример демонстрирует, что параллельное программирование приводит к ряду проблем, которые невозможно наблюдать в последовательной программе. Более того, эти проблемы не всегда легко обнаружить, и они не всегда очевидны. Библиотеки, такие как oneTBB, упрощают параллельное программирование во многих аспектах. Для наглядности наш пример можно переписать с помощью parallel_reduce , который не требует каких-либо специальных синхронизаций и механизмов, чтобы избежать race conditions:
int summarize(const std::vectorvec] (const auto i != r.end(); ++i)
Хотя этот пример относительно небольшой, он показывает набор значительных упрощений, которые предоставляет oneTBB. Например, oneTBB автоматически создаст набор потоков, которые будут повторно использоваться между несколькими вызовами параллельных алгоритмов. Кроме того, parallel_reduce реализует все необходимые синхронизации, а пользователю достаточно описать требуемую операцию свертки, например, std::plus .
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
- Блог компании Intel
- Высокая производительность
- Программирование
- C++
- Параллельное программирование
Источник: habr.com
Модель параллельного программирования
В вычислении, параллельная модель программирования является абстракцией из параллельной компьютерной архитектуры, с которой удобно выразить алгоритмы и их состав в программах. О ценности модели программирования можно судить по ее общности: насколько хорошо может быть выражен ряд различных проблем для множества различных архитектур, и по ее производительности: насколько эффективно могут выполняться скомпилированные программы. Реализация модели параллельного программирования может принимать форму библиотеки, вызываемой из последовательного языка, как расширение существующего языка или как совершенно новый язык.
Консенсус по поводу конкретной модели программирования важен, потому что он приводит к созданию различных параллельных компьютеров с поддержкой этой модели, тем самым облегчая переносимость программного обеспечения. В этом смысле модели программирования называют мостом между аппаратным и программным обеспечением.
Классификация моделей параллельного программирования
Классификации моделей параллельного программирования можно условно разделить на две области: взаимодействие процессов и декомпозиция проблемы.
Взаимодействие процессов
Взаимодействие процессов относится к механизмам, с помощью которых параллельные процессы могут взаимодействовать друг с другом. Наиболее распространенными формами взаимодействия являются разделяемая память и передача сообщений, но взаимодействие также может быть неявным (невидимым для программиста).
Общая память
Основная статья: Общая память (межпроцессное взаимодействие)
Общая память — эффективное средство передачи данных между процессами. В модели с общей памятью параллельные процессы совместно используют глобальное адресное пространство, которое они читают и записывают в асинхронном режиме. Асинхронный параллельный доступ может привести к состояниям гонки, и для их предотвращения можно использовать такие механизмы, как блокировки, семафоры и мониторы. Обычные многоядерные процессоры напрямую поддерживают разделяемую память, для использования которой предназначены многие языки и библиотеки параллельного программирования, такие как Cilk, OpenMP и Threading Building Blocks.
Передача сообщений
Основная статья: Передача сообщений
В модели передачи сообщений параллельные процессы обмениваются данными, передавая сообщения друг другу. Эти коммуникации могут быть асинхронными, когда сообщение может быть отправлено до того, как получатель будет готов, или синхронным, когда получатель должен быть готов. Формализация передачи сообщений « Последовательные процессы связи» (CSP) использует синхронные каналы связи для соединения процессов и привела к появлению таких важных языков, как Occam, Limbo и Go. Напротив, модель акторов использует асинхронную передачу сообщений и использовалась при разработке таких языков, как D, Scala и SALSA.
Неявное взаимодействие
Основная статья: Неявный параллелизм
В неявной модели программисту не видно взаимодействия с процессами, и вместо этого компилятор и / или среда выполнения несут ответственность за его выполнение. Два примера неявного параллелизма относятся к предметно-ориентированным языкам, где предписывается параллелизм в рамках высокоуровневых операций, и к функциональным языкам программирования, поскольку отсутствие побочных эффектов позволяет независимым функциям выполняться параллельно. Однако этим типом параллелизма сложно управлять, и такие функциональные языки, как Concurrent Haskell и Concurrent ML, предоставляют функции для явного и правильного управления параллелизмом.
Разложение проблемы
Параллельная программа состоит из одновременно выполняющихся процессов. Декомпозиция проблемы связана со способом формулирования составляющих процессов.
Параллелизм задач
Основная статья: Параллелизм задач
Модель с параллельными задачами фокусируется на процессах или потоках выполнения. Эти процессы часто отличаются поведенческими особенностями, что подчеркивает необходимость общения. Параллелизм задач — естественный способ выразить коммуникацию с передачей сообщений. В таксономии Флинна параллелизм задач обычно классифицируется как MIMD / MPMD или MISD.
Параллелизм данных
Основная статья: Параллелизм данных
Модель с параллельными данными фокусируется на выполнении операций с набором данных, обычно с регулярно структурированным массивом. Набор задач будет работать с этими данными, но независимо от непересекающихся разделов. В таксономии Флинна параллелизм данных обычно классифицируется как MIMD / SPMD или SIMD.
Неявный параллелизм
Основная статья: Неявный параллелизм
Как и в случае неявного взаимодействия процессов, неявная модель параллелизма ничего не раскрывает программисту, поскольку за это несут ответственность компилятор, среда выполнения или оборудование. Например, в компиляторах автоматическое распараллеливание — это процесс преобразования последовательного кода в параллельный, а в компьютерной архитектуре суперскалярное выполнение — это механизм, посредством которого параллелизм на уровне команд используется для параллельного выполнения операций.
Терминология
Модели параллельного программирования тесно связаны с моделями вычислений. Модель параллельных вычислений — это абстракция, используемая для анализа стоимости вычислительных процессов, но она не обязательно должна быть практичной, поскольку ее можно эффективно реализовать в аппаратном и / или программном обеспечении. Модель программирования, напротив, конкретно подразумевает практические аспекты аппаратной и программной реализации.
Язык параллельного программирования может быть основан на одной или на комбинации моделей программирования. Например, высокопроизводительный Fortran основан на взаимодействии с разделяемой памятью и декомпозиции проблемы параллельных данных, а Go обеспечивает механизм взаимодействия с разделяемой памятью и передачей сообщений.
Примеры моделей параллельного программирования
| Актерская модель | Асинхронная передача сообщений | Задача | D, Erlang, Scala, SALSA |
| Массовая синхронная параллель | Общая память | Задача | Apache Giraph, Apache Hama, BSPlib |
| Связь последовательных процессов | Синхронная передача сообщений | Задача | Ада, Оккам, VerilogCSP, Go |
| Схемы | Передача сообщений | Задача | Verilog, VHDL |
| Поток данных | Передача сообщений | Задача | Lustre, TensorFlow, Apache Flink |
| Функциональный | Передача сообщений | Задача | Параллельный Haskell, Параллельный ML |
| Машина LogP | Синхронная передача сообщений | Не указано | Никто |
| Параллельная машина с произвольным доступом | Общая память | Данные | Cilk, CUDA, OpenMP, стандартные блоки потоков, XMTC |
Смотрите также
- Автоматическое распараллеливание
- Модель моста
- Параллелизм
- Степень параллелизма
- Явный параллелизм
- Список языков параллельного и параллельного программирования
- Параллельная внешняя память (модель)
использованная литература
дальнейшее чтение
- Блэз Барни, Введение в параллельные вычисления, Ливерморская национальная лаборатория Лоуренса
- Мюррей И. Коул. Алгоритмические скелеты: структурированное управление параллельными вычислениями (PDF), Университет Глазго
- Дж. Дарлинтон; М. Ганем; HW To (1993), «Структурированное параллельное программирование», в моделях программирования для массивно параллельных компьютеров. IEEE Computer Society Press: 160-169, DOI : 10,1109 / PMMP.1993.315543, ISBN 0-8186-4900-3 , S2CID15265646
- Ян Фостер, Разработка и создание параллельных программ, Аргоннская национальная лаборатория
Источник: alphapedia.ru