
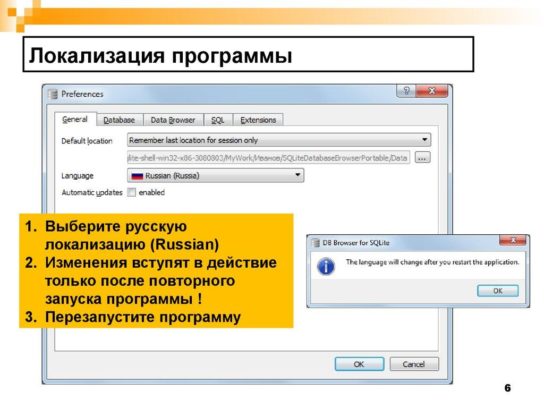
Многие разработчики мечтают о всемирной популярности своих приложений, но почти никто не создает локализованных версий своих приложений, ошибочно полагая, что программа должна сначала завоевать популярность. Локализованные версии – это первый шаг к завоеванию мирового господства!
В этой статье я расскажу о создании локализованных версий приложений и, подробнее, о локализации следующих ресурсов:
- диалоговые окна;
- меню;
- информация о версии;
- таблицы сообщений;
- таблицы строк (см. примечание)
Вообще-то, если вам нужно иметь в одном модуле строки на нескольких языках, то лучше использовать таблицы сообщений. Но об этом ниже.
Кроме того, в качестве бонуса, я покажу, как работать с локализованными значками и курсорами! Но сначала…
Несколько замечаний по локализации приложений
- Если вы хотите создать действительно многоязычное приложение, то нужно использовать Unicode-версии функций Win32 API. Для этого при сборке проекта необходимо определить символ UNICODE (и _UNICODE, если вы используете CRT). Кстати, для работы со строками в Unicode не рекомендуется использовать функции CRT. Используйте их аналоги из Win32 API.
- Но помните, что собранное таким образом приложение будет работать только на Windows NT/2K/XP.
- Для диалоговых окон используйте только шрифт “MS Shell Dlg”. Это фиктивный шрифт, который соответствует реальному, установленному в системе шрифту и способному отображать слова на выбранном пользователем, в настройках Windows, языке. В Resource Editor выбрать этот шрифт нельзя. Меняйте прямо в .rc файле, на работоспособности редактора ресурсов это не отразится.
- Если в ресурсах будут использоваться символы национальных алфавитов (например, умляуты для немецкого языка), то сначала нужно перекодировать .rc файл проекта из Windows-кодировки в Unicode. В Windows 2000 для этого можно использовать блокнот. Нужно открыть файл, выбрать «Сохранить как», кодировка – Unicode. Именно так и сделано в демонстрационном приложении. Правда, после этого он перестанет открываться в Resource Editor.
Во многих примерах из этой статьи будет использоваться функция LoadResourceLang. Вот ее исходный текст:
Как прошить Xiaomi Mi8 (china version) через TWRP на локализованную версию с Google Pay
HGLOBAL LoadResourceLang(LPCTSTR resType, DWORD resID) < HINSTANCE hAppInstance=GetModuleHandle(NULL); HRSRC hrRes=FindResourceEx(hAppInstance, resType, MAKEINTRESOURCE(resID), GetUserDefaultLangID()); if (!hrRes) < hrRes=FindResourceEx(hAppInstance, resType, MAKEINTRESOURCE(resID), MAKELANGID(LANG_ENGLISH, SUBLANG_ENGLISH_US)); >return LoadResource(hAppInstance, hrRes); >
Как видите, ничего сложного. Она просто загружает ресурс указанного типа с указанным идентификатором. При этом загружается ресурс на основном языке, который пользователь выбрал в настройках Windows (Панель управления > Языки и стандарты). Если такой ресурс загрузить не удается, функция пытается загрузить ресурс на английском языке.
Элементарно. Локализованная заставка сериала
Диалоговые окна
Для создания локализованного диалогового окна нужно указать в его свойствах требуемый язык и набрать все строки в этом диалоговом окне на выбранном языке. Для загрузки диалогового окна с нужным языком необходимо написать следующий код:
DialogBoxIndirect(hAppInstance, (LPDLGTEMPLATE)LoadResourceLang(RT_DIALOG, IDD_DIALOG_ID), hParent,
Сначала мы находим ресурс диалога на нужном нам языке, затем загружаем его и передаем функции DialogBoxIndirect(Param) как указатель на структуру DLGTEMPLATE. Хитрость состоит в том, что ресурсы диалоговых окон лежат внутри файла в виде корректно сформированных структур DLGTEMPLATE, поэтому не нужно прикладывать никаких дополнительных усилий для создания диалога из указателя на ресурс.
Если вы используете MFC, то в классе, производном от CDialog необходимо перегрузить метод DoModal и написать в нём следующий код (всё остальное оставьте без изменений):
HRSRC hrRes=FindResourceEx(hAppInstance, resType, m_lpszTemplateName, GetUserDefaultLangID()); if (!hrRes) < hrRes=FindResourceEx(hAppInstance, resType, m_lpszTemplateName, MAKELANGID(LANG_ENGLISH, SUBLANG_ENGLISH_US)); >if (!CreateIndirect( (LPDLGTEMPLATE)LoadResource(hAppInstance, hrRes), m_pParentWnd)) return IDCANCEL; return CDialog::DoModal();
Меню
Работа с меню на разных языках во многом аналогична работе с диалоговыми окнами. Вот пример кода, загружающего локализованное меню:
HMENU hMenu=LoadMenuIndirect(LoadResourceLang(RT_MENU, IDR_MAIN));
Как вы, наверное, уже догадались, ресурс меню представляет собой корректную структуру MENUTEMPLATE. Поэтому работа с локализованными меню также не должна вызвать затруднений.
Информация о версии
Поскольку приложению редко приходится работать со своей «информацией о версии» (обычно это делают специальные утилиты), я не буду описывать её получение. Скажу лишь, что Win32 API предоставляет набор функций, которые позволяют сделать это без особых ухищрений.
Для добавления в приложение локализованной «информации о версии» вам следует добавить не новый ресурс Version Info, а в уже существующий добавить новый Version Info Block и выбрать для него требуемый язык.
Таблицы сообщений
Таблицы сообщений нельзя назвать широко используемым ресурсом. Так произошло потому, что Resource Editor из комплекта Visual Studio не поддерживает их создание и редактирование. Но, с другой стороны, этот тип ресурса широко применяется в самой Windows и, в отличие от таблиц строк, напрямую поддерживает локализацию. Рассмотрим этот ресурс подробнее.
Таблицы сообщений во многом похожи на таблицы строк, но, в отличие от последних, позволяют сопоставить каждому идентификатору несколько текстовых строк, отличающихся языком. Кроме того, в строке могут встречаться специальные комбинации символов %n (где n — число от 1 до 99), которые при загрузке строки (при помощи функции FormatMessage) могут автоматически заменяться предоставляемыми вами строками или числами.
На что именно будет заменена та или иная комбинация символов, вы можете указать, написав такую последовательность символов: %n!x!, где x – один из форматных символов функции printf. Например, если вы хотите, чтобы на место первой специальной комбинации символов было подставлено беззнаковое число, напишите следующее: %1!u!. По умолчанию считается, что на место всех спецпоследовательностей будут подставляться строки.
Исходный файл таблицы строк обрабатывается компилятором mc (Message Compiler), который в результате своей работы создает:
- .h-файл с идентификаторами строк для включения в проект;
- .rc-файл для включения в .rc-файл вашего проекта;
- несколько .bin-файлов (точнее столько, на скольких языках имеются строки в исходном файле).
Формат исходного файла для компилятора mc я описывать не буду, так как он очень прост. Подробнее вы можете ознакомиться с ним здесь.
Расскажу о том, что делать с заголовочными файлами, полученными после компиляции таблицы строк. h-файл нужно включить в тот же файл, в который включен resource.h (в сам resource.h его включать не стоит). Это предоставит вам доступ к числовым идентификаторам сообщений.
rc-файл нужно включить в rc-файл вашего проекта с помощью директивы #include. Сделать это лучше ближе к началу файла (например, сразу после строки #undef APSTUDIO_READONLY_SYMBOLS, если она у вас есть). После этого в Resource Editor вы увидите новый Custom Resource. Только не пытайтесь открывать даже папку этого ресурса! Иначе Resource Editor вставит все содержимое bin-файлов прямо в rc-файл вашего проекта, после чего он перестанет компилироваться.
После того как вы проделали эти нехитрые манипуляции, можете приступать к использованию содержимого таблицы сообщений. Для того, чтобы загрузить текст сообщения на определенном языке, необходимо написать следующий код:
LPTSTR buff=NULL; FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_HMODULE, hAppInstance, IDM_MSG_ID, GetUserDefaultLangID(), (LPTSTR) // . // Используем buff // . LocalFree(buff);
Если же в вашем сообщении есть спецпоследовательности и вы хотите произвести подстановку, то напишите следующий код:
BYTE argArr[sizeof(DWORD)+sizeof(LPCTSTR)]; BYTE *pCurr=pArr; (*(DWORD*)pCurr)=10; pCurr+=sizeof(DWORD); (*(LPCTSTR*)pCurr)=TEXT(«aaa»); LPTSTR buff=NULL; FormatMessage(FORMAT_MESSAGE_ALLOCATE_BUFFER | FORMAT_MESSAGE_FROM_HMODULE | FORMAT_MESSAGE_ARGUMENT_ARRAY, hAppInstance,IDM_MSG_ID, GetUserDefaultLangID(), (LPTSTR)pArr); // . // Используем buff // . LocalFree(buff);
Такой хитрый способ передачи значений используется потому, что паскалевская конвенция вызова (__stdcall), которая используется в Win32 API, не позволяет передавать переменное число аргументов.
Таблицы строк
Вот мы и подошли к самому неприятному моменту. Дело в том, что Win32 API принципиально не поддерживает работу с таблицами строк на нескольких языках, поэтому нам придется собственноручно написать аналог функции LoadString:
WORD LoadStringLang(UINT strID, LPTSTR destStr /*=NULL*/, WORD strLen /*=0*/) < LPCWSTR str=(LPCWSTR)LoadResourceLang(RT_STRING, 1+(strID >> 4)); if (!str) return 0; for (WORD strPos=0; strPos < (strID strPos++) str+=*str+1; if (!strLen) return *str; if (!destStr) return 0; #ifdef _UNICODE lstrcpyn(destStr, str+1, min(strLen, *str+1)); #else WideCharToMultiByte(CP_ACP, 0, str+1, *str+1, destStr, strLen, NULL, NULL); #endif destStr[min(strLen-1, *str)]=TEXT(‘�’); return min(strLen, *str+1); >
Поясню принцип работы этой функции: строки хранятся в ресурсах (в кодировке Unicode) группами по 16 штук, и минимальная загружаемая единица – это группа строк. Каждая группа имеет свой идентификатор, который равен идентификатору первой строки в группе плюс 1. После того, как мы загрузили нужную группу строк, мы ищем (последовательным перебором) нужную строку в группе. Строки внутри группы хранятся следующим образом:
| 2 байта | (длина строки)*2 байт | 2 байта | (длина строки)*2 байт |
Тем, кто знаком с COM, это напомнит строки BSTR. При переборе мы просто прибавляем к текущему значению указателя длину строки плюс 1. Обратите внимание, что завершающий нулевой символ у строк отсутствует! Такое поведение компилятора ресурсов можно изменить, указав при компиляции ключ /n.
Любая группа строк всегда заполнена полностью. На местах отсутствующих строк находятся слова, хранящие длину строки, в которые записаны нули. Например:
| 13 | Просто строка | 5 | Текст |
Вот, собственно, и все. Теперь, при необходимости, нужно перевести строку из Unicode в ANSI и скопировать в предоставленный пользователем буфер.
Обратите внимание, что наша реализация имеет полезную особенность, отсутствующую у LoadString. Если передать ей при вызове в качестве длины буфера 0, то она вернет размер загружаемой строки, не считая завершающего нуля.
Значки и курсоры
А теперь обещанный бонус – локализованные значки и курсоры! Это непростая задача, но ее решение стоит того. Представьте, как было бы удобно использовать эту возможность, например, в индикаторах клавиатуры! Итак, приступим:
HICON LoadIconLang(DWORD iconID, bool bIcon /*=true*/) < int iid=LookupIconIdFromDirectory((BYTE*)LoadResourceLang(bIcon ? RT_GROUP_ICON : RT_GROUP_CURSOR, iconID), bIcon); if (!iid) return NULL; HRSRC hrIcon=FindResource(hAppInstance, MAKEINTRESOURCE(iid), bIcon ? RT_ICON : RT_CURSOR); return CreateIconFromResource((BYTE*)LoadResource(hAppInstance, hrIcon), SizeofResource(hAppInstance, hrIcon), bIcon, 0x00030000); >
Вы наверняка знаете, что один ресурс значка (или ico-файл) может содержать значки разного размера и с разной глубиной цвета.
Один такой «сложный» значок (называемый Icon Directory) и определяется идентификатором, который вы видите в редакторе ресурсов. Каждый «простой» значок имеет свой уникальный идентификатор, который, в общем случае, не равен идентификатору каталога. С помощью функции LookupIconIdFromDirectory можно получить идентификатор значка из группы, указатель на которую передан ей в качестве одного из параметров. Функция возвращает идентификатор значка, который, по ее мнению, лучше всего подходит к текущим параметрам экрана.
Затем необходимо загрузить значок с полученным идентификатором и передать указатель на него функции CreateIconFromResource. Функция по данным, определяемым этим указателем, и другой переданной информации создаст значок и вернет его дескриптор.
Для того чтобы загрузить не значок, а курсор, нужно передать нашей функции LoadIconLang в качестве последнего параметра false.
Вот, собственно, и все, что я хотел рассказать про создание локализованных приложений. Приложение — пример к статье умеет полностью изменять язык интерфейса на тот, который вы выберете в настройках Windows. Приложение поддерживает следующие языки:
- Русский
- Английский
- Немецкий
- Украинский
Помните, что видеть на экране слова на родном языке значительно приятней, чем на чужом!
Статья опубликована с разрешения автора
Источник: www.rsdn.org
Что такое перевод и локализация
Локализация программного обеспечения — адаптация программ, приложений для регионов, в которых их будут использовать. Локализация ПО — это не просто точный, максимально адаптированный перевод с учетом национальных особенностей. Это сложный, многошаговый процесс.

Локализация программного обеспечения — что это
Локализация ПО необходима иностранным продуктам для реализации на внутреннем рынке, российскому программному обеспечению — для продажи зарубежным потребителям.

Локализуют следующие виды программного обеспечения:
- массовые и корпоративные программные продукты;
- мобильные приложения — локализация заключается в технической, языковой адаптации для упрощения использования в конкретной стране;
- базы данных — ПО для хранения разных данных организации;
- игры.
Любую программу сейчас можно скачать, разобраться в ней при помощи онлайн-переводчика. Локализованная версия повышает популярность ПО, что влияет на распространенность программы в стране или регионе.
Из чего состоит локализация программного обеспечения
Локализация ПО способна повысить рейтинг приложения и количества загрузок в определенных магазинах приложений, увеличить лояльность пользователей. При улучшении взаимодействия с пользователями расширяется аудитория и рынок сбыта.
Локализация ПО состоит из нескольких этапов:
- Перевод текстовой части. Необходимо перевести весь текст, элементы интерфейса, аудиоматериалы, графические изображения или скрины, если они содержат текстовые элементы.
- Адаптация единиц измерения. В англоязычных документах десятичные дроби пишут через точку, в русском языке — через запятую. Такие тонкости нельзя игнорировать. Нередко в ПО на английском языке используют неметрические единицы измерения — дюймы, футы. Если не перевести их в метры или сантиметры, могут возникнуть проблемы при работе с данной программой.
- Перевод и адаптация величин, которые отличаются, в зависимости от страны и региона. Это валюты, номера телефонов, правила оформления дат.
- Локализация элементов графических изображений. При переводе ПО нужно учитывать национальные особенности страны или региона. Некоторые оригинальные символы, изображения и цветовые сочетания могут негативно восприниматься целевой аудиторией из-за разницы в культуре. Спорные элементы необходимо заменить.
- Шрифты. Не все шрифты присутствуют одновременно в русском, английском и других иностранных языках.
В локализации и переводе ПО участвуют технические, юридические и переводчики других специализаций, разработчики программного обеспечения, которые могут вовремя внести необходимые изменения в программный код, тестировщики.
Какие сложности могут возникнуть при локализации ПО?
При локализации программного обеспечения могут возникнуть лингвистические и технические сложности.
- Перевод без учета контекста. Если переводчик-локализатор получит просто файл с фразами и отдельными словами, он не сможет сделать перевод правильно. Многие термины, в зависимости от контекста, на русский язык можно перевести по-разному. Могут быть разные варианты перевода и внутри самой программы. Нередко в программах встречаются кнопки, которые при переводе будут обозначаться одинаковым словом, при этом функции абсолютно разные.
- Перевод приложения с большим количеством числительных или других переменных параметров. В английском языке числительные в единственном числе употребляются только с цифрой 1. Во всех остальных случаях присутствует окончание, которое указывает на множественное число. В русском языке все не так однозначно — одна страница, две страницы, 6 страниц.
Тестирование локализации — что это
Тестирование локализации — это проверка поведения, корректной работы программного обеспечения с учетом определенного местоположения, особенностей культуры и местности. Локализованное тестирование часто называют L10N, поскольку слово «локализация» на английском языке состоит из 10 символов, которые расположены между L и N.
Задача тестирования — убедиться, что основные характеристики ПО приемлемы для целевой аудитории в определенном месте. Этот процесс существенно влияет на пользовательский интерфейс, контент, основные настройки. Тестировщики проверяют текстовые и языковые ошибки, соответствие культурным ценностям.

Особенности тестирования локализации:
- Проверка локализованного пользовательского интерфейса. При тестировании проверяют, насколько пользовательский интерфейс приятен целевой аудитории. Отслеживают правильность грамматики, орфографии, пунктуации.
- Проверка локализованного контента. Содержимое приложения должно не противоречить местным культурным обычаям, только так ПО будет приемлемым для местных жителей.
- Тест на определение языков, которые поддерживает программа. Необходим для выявления возможной несовместимости с языком в конкретном регионе.
- Тест на совместимость оборудования. Проводят для оценки слаженной работы программного и аппаратного обеспечения в заданной области.
- Тестирование на носителях языка. Необходимо для оценки точности и понятности перевода для тех, кто общается на данном языке.
- Общая оценка работы приложения с учетом обратной связи от пользователей.
Заказать технический перевод и локализацию ПО лучше в специализированном бюро переводов. Так можно избежать ошибок и погрешностей, которые могут негативно повлиять на распространение, взаимодействие пользователей с ПО.
В Москве и регионе прекрасно зарекомендовало себя бюро переводов “ЭксЛибрис”. Команда переводчиков выполнит локализацию на 64 языка и предоставит гарантии качества.
Источник: ecoportal.info
Культура локализации ПО, есть ли она?
Всем привет! Сегодня речь пойдет о том, что такое локализация и какое место она занимает в процессе разработки программного обеспечения.
Статья состоит из трех частей, последовательно приближающих нас к вопросу, который все еще требует ответа: существует ли сегодня то, что называется культурой в индустрии локализации ПО? Говоря о культуре, в первую очередь я имею в виду чувство ответственности и заинтересованности каждого инженера в создании качественного продукта, а также создание условий со стороны руководителя, способствующих достижению этой цели.
Часть 1. Про локализацию и перевод
Ежедневно каждый из нас использует десятки сервисов и приложений, не придавая значения тому, где и кем они были созданы. Даже если продукт был произведен не в России, мы, как пользователи, не испытываем дискомфорта и трудностей при работе с ним. Чтобы это стало возможным, производителю необходимо провести большую работу по адаптации услуги/сервиса к языковым и культурным особенностям принимающей страны — локализацию. Признак совершенной локализации — предоставление возможности взаимодействия с продуктом на абсолютно естественном для потребителя уровне, даже не замечая, что продукт был локализован.
Существует мнение, что перевод контента — достаточное условие для создания интернационального продукта. В связи с широким распространением этого суждения локализация, как правило, остается низкоприоритетной задачей, откладывается на потом или вовсе не рассматривается. Однако нужно помнить, что у перевода и локализации всё же разные цели. У первого — для каждой фразы текста на исходном языке подобрать равнозначное ей выражение в целевом языке, у второй — сделать то же самое с учетом множества факторов, которые могут повлиять на получение позитивного/негативного впечатления в процессе работы с продуктом: культурные особенности и нормы, использование сленга, профессионализмов и т.д.
Часть 2. Про локализацию в разработке
В то время как процесс локализации статического контента — документа, презентации — определен и конечен, локализация программного обеспечения, которое постоянно совершенствуется, происходит непрерывно вместе с процессом разработки продукта. Это означает, что по мере внесения изменений в продукт, также необходимо проводить работу над переводом и локализацией новых и измененных строк. Здесь в работу включены не только переводчики, но и разработчики, тестировщики, дизайнеры. Для часто обновляющихся проектов построение оптимальных процессов локализации становится необходимым.
В теории локализационные процессы выглядят довольно просто. Поэтому на практике реализация полного цикла локализации часто делегируется рядовому разработчику, включая тестирование, адаптацию дизайна и, возможно, даже перевод строк. Но разработчик не может быть экспертом одновременно во всех областях. В результате возникает ряд проблем: от неверно переведенного контента до вовсе не работающей программы.
Методологии, используемые в процессе разработки, также применимы и к локализации. Индустрия переводов исторически применяет каскадную модель (waterfall). Это означает, что процесс перевода начинается только тогда, когда работа над документом закончена. В контексте разработки программного обеспечения это эквивалентно задержкам в выпуске новых версий продукта.
Но сегодня, когда разработка приложения происходит итеративно и релизы могут случаться несколько раз в день, а новые локализованные строки должны выходить с каждым релизом приложения, такие задержки непозволительны. Всё это приводит к необходимости выстраивания работы команды таким образом, чтобы процесс локализации стал таким же естественным, как и сам процесс разработки приложения.
И здесь будет уместно поговорить о построении механизма локализации ПО таким образом, что наиболее актуальная локализованная версия продукта готова к релизу в каждый момент времени. Это достигается путем тесного взаимодействия команды локализации и команды разработчиков продукта. Например, вот так:
Команда локализации вовлечена в процесс создания ПО ровно в той же степени, что и команда разработки, имея возможность вносить необходимые изменения в кодовую базу продукта. Обе команды работают в одной системе управления проектом и всегда имеют доступ к актуальной версии приложения, что позволяет им максимально быстро реагировать на функциональные изменения. При этом задачи команды локализации существуют в спринтах наряду с задачами для команды разработки приложения и доставляются итеративно, а не целиком.
Команда локализации — это группа специалистов, состав которой определяется на этапе планирования проекта, и зависит от объема и типа задач, которые необходимо выполнить. На картинке выше представлены отдельные роли участников команды локализации и стоящие перед ними задачи:
- разработчики — интернационализация приложения, работа со строками, полученными от переводчиков и т.д.;
- тестировщики — локализованный вариант приложения должен быть протестирован так же тщательно, как и оригинальный;
- дизайнеры — в большинстве случаев возникает необходимость в адаптации существующих прототипов к полученным от переводчиков изменениям (изменение длины слов, направление письма и т.д.);
- переводчики — предоставление локализованных строк;
Команда локализации умеет не только эффективно транслировать технические задачи на язык переводчиков, предоставлять им контекст перевода, правки и прочее, но и обладает достаточной экспертизой тогда, когда она необходима. Например, в отдельных случаях локализация может потребовать внесения изменений в архитектуру приложения.
Теперь понятно, что процесс локализации продукта — это не просто перевод контента, а ряд задач как профессиональных, так и организационных. Для создания качественного интернационального продукта важно инвестировать ресурсы и время уже на ранних этапах разработки (например, интернационализованное приложение — важное условие, существенно упрощающее локализацию продукта), выстроить все процессы и наладить взаимодействие с командой локализации. Как только этот процесс будет выстроен, команда локализации сможет легко и быстро реагировать на функциональные изменения в приложении, обрабатывать новые строки и предоставлять их команде разработки.
Часть 3. Про то, где может «хоститься» команда локализации
Во время подготовки продукта к выходу на международный рынок важно заранее подумать об организации ресурсов, которые потребуются для реализации этой задачи. При этом следует обратить внимание на ряд факторов, влияющих на выбор стратегии, подходящей для локализации текущего проекта (по этой теме есть очень хорошая статья). Один из таких факторов — localization maturity. Иначе говоря, “зрелость” компании в построении системы управления качеством и прозрачностью процессов локализации. Чем меньше компетенций существует внутри команды, тем большее количество задач следует отдавать на аутсорс. На основании этого возможны следующие варианты:
- Создание собственной команды из сотрудников, обладающих экспертизой в локализации Плюсы:
- минимизирование финансовых затрат
- тесное взаимодействие с командой разработки и глубокое знание продукта существенно сокращают сроки выполнения задач
- необходимость обеспечения полноценной загруженности команды
- необходимость создания условий для развития команды в этом направлении
В случае отсутствия постоянных задач по локализации содержать такую команду становится невыгодно. Действительно, можно занять команду задачами другого рода, но тогда специалисты перестанут развиваться в своей основной профессиональной области. Если же создавать временную команду локализации из существующих непрофильных специалистов, есть риск, что результат будет посредственным, «лишь бы сейчас работало». Велики шансы того, что поддерживать такой вариант реализации будет очень сложно, что в конце концов приведет к необходимости полной переработки существующего механизма локализации.
- нет необходимости в организации работы команды, только контроль выполнения;
- такую команду можно привлекать частично по мере появления новых задач;
- может потребоваться более детальная формулировка задач, а также время на адаптацию команды;
- значительные финансовые затраты;
При этом важно подобрать внешнюю команду таким образом, чтобы программный продукт был не просто переведен, а тщательно переработан с учетом многих технических и лингвистических особенностей, которых требует правильно выстроенный процесс локализации.
- оптимальное соотношение цены и качества;
- обязательным условием здесь является готовность команды/компании к управлению такой моделью, чтобы оптимально сбалансировать работу штатных и внешних сотрудников;
Построение полного цикла локализации характеризуется повышенными требованиями к знаниям в этой области, поэтому помощь привлеченной команды здесь может быть полностью оправдана. В тех случаях, когда весь процесс уже выстроен, а задача состоит в минимальных изменениях строк, то целесообразно оставить эту задачу штатным сотрудникам. Когда требуется локализовать новые строки, имеет смысл делегировать эту задачу внешней команде, а внедрять уже локализованные строки самостоятельно.
Локализация программного продукта — непростой и длительный процесс, в действительности часто не рассчитанный на постоянные изменения в приложении и становящийся причиной возникновения ряда сложностей каждый раз при появлении новых задач.Вот несколько пунктов, о которых нужно помнить:
- Локализация — не перевод;
- Полный процесс локализации начинается с интернационализации и заканчивается локализационным тестированием;
- Локализация должна происходить одновременно с разработкой продукта;
- Правильно выстроенные процессы локализации работают с той же скоростью, что и вся команда, и не становятся причиной задержки релизов продукта;
- Важно найти баланс в распределении ресурсов между внутренней и внешней командой для построения оптимального процесса локализации.
Источник: habr.com