
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Кракозябры в программе что делать? Фикс кракозябр и иероглифов в любой версии виндовс!
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста.
В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 2 8 =256).
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость.
Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Кракозябры вместо русских букв в Windows 10 применяем 2 метода исправления ситуации
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование.
Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111 . В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111 . И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
110 10000 10 111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся ( 10000111100 ), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 = 0000000000 1111010101 (ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять))
- 0 + D800 = D800 ( 110110 0 000000000 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат
- 3D5 + DC00 = DFD5 ( 110111 1 111010101 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат
- итого данный символ в UTF-16 — 1101100000000000 1101111111010101
- переведем в шестнадцатиричный вид = D822DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
- 110110 0 000100010 — десятый бит (справа) нулевой, значит первый суррогат
- 110111 1 010001000 — десятый бит (справа) единица, значит второй суррогат
- отбрасываем по 6 бит отвечающих за определение суррогата, получим 0000100010 1010001000 (8A88)
- прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Источник: habr.com
Как выбрать кодировку и исправить все проблемы с ней

Сергей Ломакин Редакция «Текстерры»
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ.
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.
Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:
Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:
Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
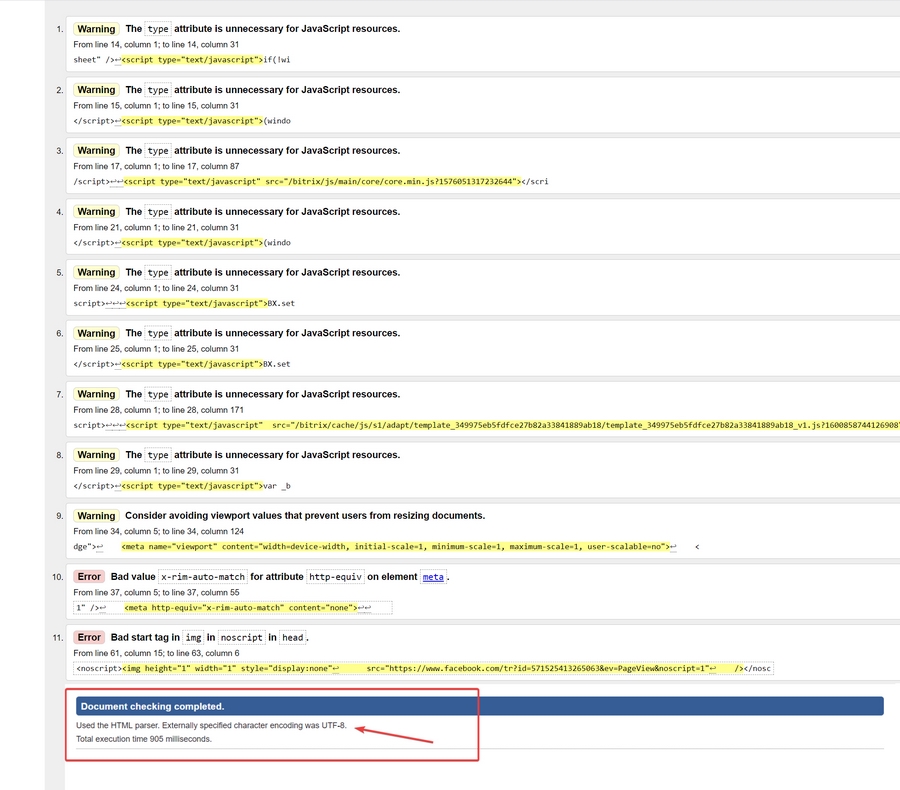
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:
Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:
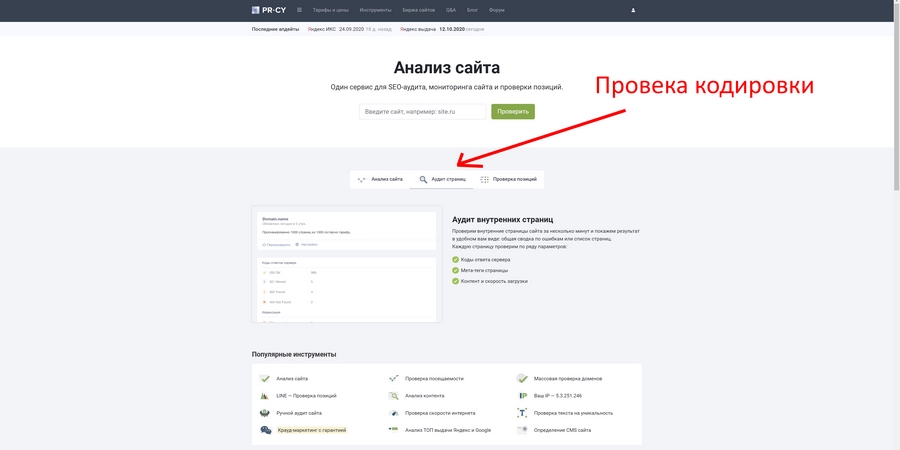
Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:
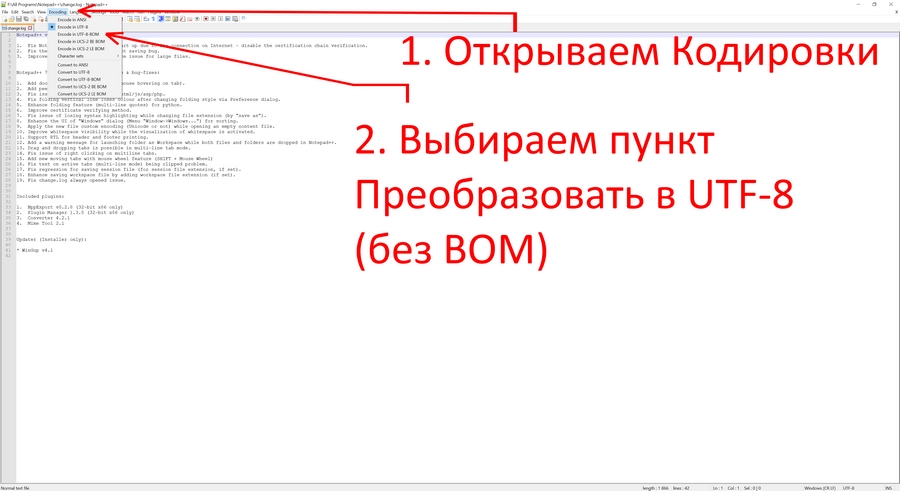
Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:
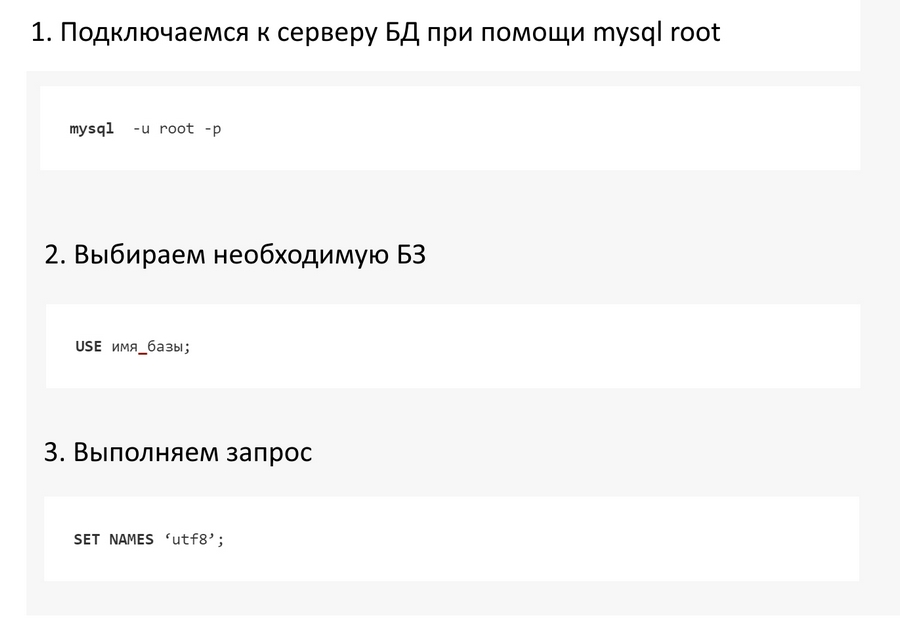
Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:

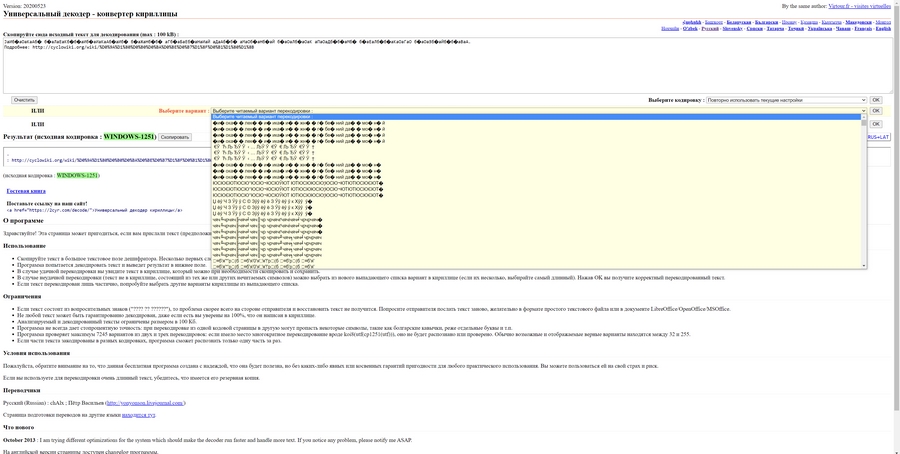
2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:
Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Источник: texterra.ru
Как исправить «кракозябры» в меню программ и заголовках окон

Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Устранение проблем с кодировкой (крякозябликами) в ОС Windows XP/Vista/7
На днях у меня тоже случилась подобная вещь. В некоторых русифицированных программах часть надписей интерфейса стала выглядеть так, как будто вместо букв туда вставили отпечатки лап птиц:
Скажу честно — я потратил на поиск решения проблемы почти два дня.
На всех форумах и сервисах «вопросов и ответов», во всех мануалах и инструкциях, все как один повторяли тот-же рецепт решения, который возможно кому-то и помог. Но не мне.
И только когда мои мозги уже начали закипать и всякая надежда на решения проблемы покинула меня, все стало на свои места.
Результаты же поисков я решил оформить в «Универсальное руководство по решению всех проблем с кодировкой в операционных системах Windows XP и Windows Vista/7». Хотя возможно оно не так уже и универсально…
Решение проблем с кодировкой в Windows XP
1. Сначала нужно убедится, что для программ не поддерживающих Юникод установлен русский язык.
Открываем «Панель управления» и дважды кликаем по иконке «Язык и региональные стандарты». Переходим во вкладку «Дополнительно» и устанавливаем русский язык в качестве «Языка программ, не поддерживающих Юникод».
После этого найдите в списке, который размещен на этой-же вкладке пункт 20880 и поставте возле него галочку:
Сохраните изменения и перезагрузите компьютер. Если проблема не исчезла переходим к пункту 2.
2. Возможно, что проблемы с кодировкой вызваны нарушением системных настроек шрифтов.
Для восстановления настроек шрифтов скачайте этот архив и запустите файл который находится в нем игнорируя все предупреждения системы:
Перезапустите систему. Если проблема не исчезла переходим к пункту 3.
3. Следующий этап — изменение ключей реестра которые отвечают за кодировки. Делать эти изменения желательно только в крайнем случае и только если все предыдущие пункты ни к чему не привели.
Для выполнения этих изменений скачайте этот архив и запустите файл находящийся в нем. Как и в предыдущем пункте появятся предупреждения системы.
После этих изменений также нужно будет перезапустить систему.
Решение проблем с кодировкой в Windows Vista/7
1. Как и в случае с Windows XP сначала убедитесь что для программ не поддерживающих Юникод установлен русский язык.
Открываем «Панель управления» и дважды кликаем по иконке «Язык и региональные стандарты». Переходим во вкладку «Дополнительно» и устанавливаем русский язык в качестве «Языка программ, не поддерживающих Юникод»:
Сохраните изменения и перезагрузите компьютер. Если проблема не исчезла переходим к пункту 2.
2. Для восстановления настроек шрифтов скачайте этот архив и запустите файл который находится в нем игнорируя все предупреждения системы:
Перезапустите систему. Если проблема не исчезла переходим к пункту 3.
3. Следующий этап — изменение ключей реестра которые отвечают за кодировки. Делать эти изменения желательно только в крайнем случае и только если все предыдущие пункты ни к чему не привели.
Для выполнения этих изменений скачайте этот архив и запустите файл находящийся в нем. Как и в предыдущем пункте появятся предупреждения системы.
После этих изменений также нужно будет перезапустить систему.
4. Если все вышеуказанное не помогло нужно поменять имена следующих файлов кодовых страниц в папке C:WindowsSystem32:
Файл «c_1252.nls» на «c_1252.nls.bak» Файл «c_1253.nls» на «c_1253.nls.bak» Файл «c_1254.nls» на «c_1254.nls.bak» Файл «c_1255.nls» на «c_1255.nls.bak»
Поскольку эти файлы защищены от изменения для выполнения этой операции желательно воспользоваться замечательной программой Unlocker.
После ее установки нужно кликнуть правой кнопкой мыши по нужному файлу, и выбрать пункт «Unlocker». В открывшемся окне выберите в выпадающем списке «Переименовать».
Измените имя файла и нажмите кнопку «OK»:
После переименования вышеуказанных файлов скопируйте файл «c_1251.nls» в какую-то другую папку (или скопируйте в буфер обмена), а затем переименуйте его на «c_1252.nls».
Вновь вставьте (скопируйте) файл «c_1251.nls» в папку C:WindowsSystem32 и переименуйте на «c_1253.nls», а затем повторите это еще два раза с переименованием в «c_1254.
nls» и «c_1255.nls».
В результате выполнения этого пункта, файлы «c_1252.nls», «c_1253.nls», «c_1254.nls», «c_1255.nls» будут заменены файлом «c_1251.nls». Не забудьте также вернуть в первоначальную папку файл «c_1251.nls»:
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10

Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Иероглифы вместо русских букв, вместо текста квадратики, что делать?
Иногда при открытии скачанного или скопированного с другого ПК текстового файла, он не подлежит прочтению. Все буквы заменяются на иероглифы, символы, квадратики или иные нечитаемые знаки.
Бывает, что буквы и цифры узнаваемы, но стоят на произвольных местах, что делает текст бессвязным и не читаемым. Такая проблема возникает не только в документах, но и в браузерах при открытии некоторых страниц.
Дело тут в кодировке, ее нужно либо снять, либо изменить.
Текстовые документы
Именно в документах Ворда, Блокнота и т.п. такая кодировка встречается чаще всего. Кодировка – набор знаков, благодаря которым происходит печать текста на определенном алфавите. Теоретически, любой документ сохраняется в различных шифрованиях, но пользователи почти никогда не прибегают к таким действиям.
Использование реестра, если метод выше не помог
Создадим в текстовом редакторе обычный файлик, но дадим ему расширение .reg, дабы впоследствии можно было применить все настройки, хранящиеся в нем. Итак, какое же содержимое reg-файла должно быть?
Что за папка SoftwareDistribution и как ее очистить или удалить
Наберем в него ручками или скопируем через буфер обмена следующие значения:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontMapper] «ARIAL»=dword:00000000
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontSubstitutes] «Arial,0″=»Arial,204» «Comic Sans MS,0″=»Comic Sans MS,204» «Courier,0″=»Courier New,204» «Courier,204″=»Courier New,204» «MS Sans Serif,0″=»MS Sans Serif,204» «Tahoma,0″=»Tahoma,204» «Times New Roman,0″=»Times New Roman,204» «Verdana,0″=»Verdana,204»
Когда все указанные строки окажутся в reg-файле, запустим его, согласимся с внесением изменений в систему, после чего выполним перезагрузку ПК и смотрим на результаты. Кракозябры должны исчезнуть.
Важное замечание: перед внесением изменений в реестр лучше создать резервную копию (другими словами, бэкап) реестра, дабы вносимые впоследствии изменения не повлекли за собой крах операционки, и ее не пришлось переустанавливать с нуля. Тем не менее, если вы уверены, что эти действия безопасны для вашей ОС, можете этот пункт упустить.
Word
Иногда кодировка появляется и в документах Ворд. Иногда причиной того, что в ворде появились непонятные символы, является то, что у Вас на ПК установлен старый Ворд (до 2007 года), а документ создан в более поздних версиях софта. Чаще всего, такие «новые» файлы просто не открываются в старой версии, но иногда открываются в странной кодировке.
Чтобы понять, так ли это, посмотрите в Свойствах файла, какой он имеет формат. «Новые» документы имеют формат docx. Преобразование файла в word до старого формата невозможно. Лучше установить обновление на MS Word. Изменить формат текстового документа на читаемый не сложно.
- Еще до открытия файла, софт «понимает», что в нем проблема. При двойном клике на него Ворд откроет окно, где спросит – в какой кодировке открыть файл. Чтобы изменить кодировку текста в word, выполните алгоритм;
- Попробуйте кодировку, предложенную программой;
- Если не сработало, кликайте по очереди на предлагаемые типы;
- LiveJournal
- Blogger
- Пробуйте менять типы кодировки и алфавит, типы кириллицы;
- Как только текст станет читаемым нажмите ОК.
- LiveJournal
- Blogger
Иногда возникает проблема другого характера. Вы набираете текст в Ворде или Блокноте и замечаете, что на клавиатуре вместо букв печатаются цифры. Проблема связана с режимом Num Look и возникает на некоторых ноутбуках. Посмотрите на клавиатуру.
Если на кнопках в правой части, кроме букв написаны и цифры, а вверху присутствует кнопка num lk, значит ноутбук оснащен данным режимом и Вы случайно включили. Для отключения нажмите кнопку Num Look или Fn+F11. Набор цифр прекратится, появятся буквы в привычном виде.
Изменение кодовых страниц для исправления иероглифов Виндовс 10
Кодовые страницы являются таблицами, в которых определенные символы сопоставляются определенным байтам, а отображение кириллицы в качестве кракозябров в Windows 10 связано с установкой по умолчанию не той кодовой страницы. Это исправляется различными способами, которые будут полезными, когда нужно в параметрах не изменять системный язык.
Редактор реестра
К первому способу относится использование редактора реестра. Это будет наиболее щадящим методом для системы, тем не менее, лучше создать точку восстановления перед началом работы.
- Нажимаем клавиши «Win+R», затем следует ввести regedit и подтвердить Enter. Будет открыт реестровый редактор.
- Переходим к меню HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage, а в правой части нужно пролистать значения до конца данного раздела.
Кракозябры вместо русских букв в Windows 10 — исправляем неправильное отображение кириллицы
Время от времени происходит так, что в операционной среде Windows вместо кириллических символов мы видим полную абракадабру: нагромождение иероглифов и непонятных значков, лишенных какого-либо смысла. Причин тому может быть несколько: начиная от неправильного выбора локали(параметров) в региональных настройках до некорректной инсталляции языкового русскоязычного пакета для поддержки кириллицы в англоязычной среде. Как бы то ни было, эта проблема вполне разрешима, и в этой статье мы расскажем, как ее преодолеть.
Наиболее вероятная причина возникновения проблемы, почему мы видим кракозябры вместо русских букв в Windows 10 – это неправильно выставленные установки локали (другими словами региональных настроек). В результате этого при попытке системы отобразить кириллические шрифты на экране мы видим полную сумятицу и хаос, при чем такое наблюдается не со всеми русскими символами. Насколько вы можете заметить из представленного ниже скриншота, некорректно отображаются не все символы. Так, наименования программ и ярлыков на рабочем столе написаны полностью корректно, а вот при попытке вызвать инсталлятор с описанием на русском наша проблема тут же вылазит на передний план, и мы видим кракозябры вместо русских букв.
Помимо некорректной установки локали, это может быть вызвано тем, что вы изначально установили англоязычную версию дистрибутива Windows, «заточенную” под латиницу. В этом случае все, что нам нужно сделать, — это переустановить систему на русскоязычную версию. Но мы будем подразумевать, что вы хотите работать именно с англоязычной средой, в которой все русские символы должны отображаться корректно и без ошибок, вне зависимости от того, какими программами вы пользуетесь, английскими или русскими. Как сделать так, чтобы не отображались кракозябры вместо русских букв в Windows 10 – читайте дальше.
Первое, что нам нужно сделать для преодоления сложившейся ситуации, — это зайти в панель управления. Осуществить данную операцию можно рядом методов, наиболее очевидный из которых – это применить правое нажатие кнопки мышки на пуске, после чего в возникшем меню выбрать соответствующее значение из списка.
В открывшемся окне панели управления выбираем раздел «Часы, язык и регион». Именно здесь сконцентрированы все региональные настройки: выбор часового пояса, разделители дробной и целой частей для чисел с плавающей точкой, обозначения валют, группировка крупных чисел по заданным признакам. Выбираем обозначенный выше раздел.
Войдя в описанную ранее категорию, отдаем предпочтение сектору «Региональные стандарты».
Помимо локали, здесь также можно задать настройки числа знаков после запятой, системы измерения (метрической или американской), формата чисел меньше нуля. Но нас прежде всего интересует региональная локаль для корректной репрезентативности кириллических символов в среде, чтобы не отображались кракозябры вместо русских букв в Windows 10. Чтобы задать ее параметры, перейдем на закладку «Дополнительно».
В категории, где устанавливается язык приложений, по дефолту не поддерживающих Юникод, щелкаем на кнопке «Изменить язык системы». В результате мы попадем на форму для кастомизации локали операционной среды, что нам, собственно, и нужно.
В возникшем на дисплее мини-окне выбираем «Русский (Россия)» в качестве текущего языка системы, тем самым указываем, что используемым по умолчанию в операционной среде языком будет именно русский, тем самым явно задавая соответствующий режим региональных настроек.
Далее в системе появится предупреждение о том, что в региональные параметры среды были внесены изменения, для вступления в силу которых понадобится перезагрузка системы. Соглашаемся с этим, перезагружаемся, и проверяем результате. В результате, кракозябры вместо русских букв в Windows 10 отображаться больше не должны, что можно проверить, еще раз запустив тот же самый, ранее проблемный дистрибутив на установку, либо любой другой, с отображением которого ранее возникали проблемы.
Как видим, возникшие трудности успешно разрешились, и теперь все шрифты должны отображаться корректно. Представленное вашему вниманию решение подходит в большинстве ситуаций, когда на экране отображаются кракозябры вместо русских букв в Windows 10.
Еще один способ решить описанную проблему – это выполнить определенные манипуляции с реестром. Но в силу возможной некорректной работы системы в результате их применения мы этот метод в нашем материале приводить не будем, так как в случае каких-либо ошибок с пользовательской стороны это может вылиться в необходимость полной переустановки операционной системы, а это для нас неприемлемо.
Итак, надеемся, что представленный выше алгоритм позволит вам обойти все подводные камни в решении вопроса, как убрать кракозябры в Windows 10 при работе в среде с англоязычной оболочкой, а также избавит вас от головной боли, связанной с отображением русскоязычных шрифтов в ОС.
Источник: android-mob.ru