
Представителем временного параллелизма является конвейерное выполнение программы, которое предполагает, что каждая команда программы выполняется не на отдельном устройстве за один такт, как на традиционном компьютере, а на устройстве, состоящем из нескольких последовательно соединенных устройств (ступеней), называемом конвейером. Таким образом, выполнение команды разделяется на несколько стадий, каждая из которых выполняется на соответствующей ступени конвейера.
Типичный набор стадий: выборка команды, декодирование команды, выборка и загрузка операндов, выполнение операции и сохранение результатов в память (рис. 21). Выигрыш во времени достигается за счет того, что на конвейере на разных ступенях одновременно (параллельно) обрабатывается несколько команд. Действительно, как только очередная команда завершила свое выполнение на первой ступени конвейера и готова перейти на вторую, следующая за ней команда уже может начать свое выполнение на первой ступени конвейера (рис. 22, а) и т. д.
Вычислительный конвейер

Рис. 21. Пяти стадийное выполнение команды
Основные характеристики конвейера — это пропускная способность и латентность. Пропускная способность (или производительность) конвейера определяется как число команд, выполненных в единицу времени. Латентность конвейера — это промежуток времени между моментами попадания команды на конвейер и получения ее результата на выходе конвейера.
Если считать, что для пятиступенчатого конвейера каждая ступень срабатывает за один такт, то первая команда полностью выполнится за пять тактов. Таким образом, латентность этого конвейера составляет пять тактов. Причем начиная с пятого такта работы конвейера в выполнение будут вовлечены уже пять команд на всех пяти ступенях.
Промежуток времени с момента запуска конвейера и до момента, когда начинают работать все ступени, называется временем разгона конвейера. Для рассматриваемого конвейера время разгона составляет четыре такта. Начиная с пятого такта, после разгона конвейера его производительность становится равной одной команде в секунду.
Предположим, что при последовательном выполнении без конвейеризации каждая команда логически проходит те же стадии, что и при конвейеризации. Тогда последовательное выполнение можно проиллюстрировать рисунком (рис. 22, б). Видно, что производительность такого функционального устройства будет в пять раз ниже, чем у пятиступенчатого конвейера (рис. 22, а).
Таким образом, N-ступенчатый конвейер увеличивает производительность процессора в N раз.

Рис. 22. Временная диаграмма выполнения последовательности команд: с конвейеризацией (а) и без конвейеризации (б)
В реальных процессорных конвейерах ситуация не такая простая. Существует факторы, которые мешают конвейеру следовать описанной выше схеме работы и постоянно сохранять максимально возможную производительность. Можно выделить три таких фактора:
Конвейер процессора
- • зависимость по данным;
- • зависимость по управлению;
- • зависимость по ресурсам.
Зависимость по данным — это ситуация, когда последующей команде требуется прочитать значение той же ячейки памяти (оперативной памяти или регистра), в которую должна записать результат предыдущая команда. Если предыдущая команда записывает значение в регистр только после выполнения стадии сохранения результата, а последующая требует его уже на стадии загрузки операндов, то она вынуждена ждать на этой стадии дополнительно два такта. Соответственно выполнение всех последующих команд также задерживается на два такта. Если представить, как команды продвигаются по конвейеру от начала до конца, то, начиная со стадии загрузки операндов, по конвейеру будет продвигаться «пустое место» размером в две ступени, обычно называемое пузырьком (рис. 23, а).
Для устранения задержек вследствие зависимостей по данным в конвейере используется технология ускоренной пересылки данных между ступенями. Суть этой технологии состоит в том, что результат предыдущей команды со ступени, отвечающей за выполнение команды, по специальному каналу отправляется на ступень загрузки операндов, где его ждет последующая команда (рис. 23, б). Таким образом, простоя конвейера не происходит. Еще одним способом устранения задержек стало разнесение зависимых команд в коде программы, при котором заполняется пространство между ними другими независимыми от них командами.

Рис. 23. Временная диаграмма выполнения на конвейере последовательности команд с зависимостью по данным: без ускоренной пересылки данных (а), с ускоренной пересылкой данных между ступенями конвейера (б)
Зависимость по управлению — это зависимость, вызванная командой перехода. В результате выполнения команды перехода на соответствующей стадии становится известно, какая команда должна выполняться после нее.
Если это не та команда, которая следует за ней в коде программы, то процессор вынужден сделать сброс конвейера — все последующие команды, которые уже начали выполняться, должны быть удалены с конвейера. И тогда вместо них из памяти организуется загрузка потока команд по вычисленному адресу перехода. В результате на конвейере образуется пузырек размером почти с длину конвейера (рис. 24, а).
Для устранения задержек, вызванных командами перехода, используется механизм раннего обнаружения и предсказания переходов. Команда перехода обнаруживается еще на начальных ступенях конвейера, после чего специальное устройство в процессоре делает предсказание, выполнится ли этот переход, и если да, то по какому адресу. По результатам этого предсказания принимается решение, какую команду загружать на конвейер следующей.
Если переход окажется предсказанным верно, то задержка будет или очень небольшой, или нулевой. Если же переход окажется предсказанным неверно, то происходит сброс конвейера, и задержка будет очень большой. Для предсказания переходов в процессорах применяются как статические, так и динамические методы.
Статические методы используют информацию из кода программы, специально выработанную компилятором. При этом способе процессор делает однозначный вывод о срабатывании команды перехода по ее виду. Статическое предсказание срабатывает на стадии декодирования команды (рис. 24, б).
Динамические способы основаны на истории срабатывания переходов, которая формируется в процессе выполнения программы. История и статистика срабатывания команд перехода сохраняются в специальных таблицах, на основе которых процессор делает предсказание об их дальнейшем поведении. Динамическое предсказание срабатывает уже на стадии выборки команды (рис. 24, в), поскольку команды перехода в таблицах истории идентифицируются по своему адресу.
Зависимость по ресурсам — это ситуация, когда на некоторой стадии команда должна обратиться к ресурсу процессора, который занят другой командой. Таким ресурсом может быть функциональное устройство, регистровый файл, кэш-память и другие. Например, отдельные команды могут проводить на стадии выполнения более одного такта. Все это время следующая за ней команда, которой требуется данный ресурс, будет простаивать.

Рис. 24. Временная диаграмма выполнения на конвейере последовательности команд с зависимостью по управлению: без предсказания переходов (а), со статическим предсказанием переходов (6), с динамическим
предсказанием переходов (в)
Для устранения зависимостей по ресурсам на уровне микроархитектуры обычно используется дублирование ресурсов. Например, в процессоре может быть несколько функциональных устройств, которые работают одновременно. Один регистровый файл может быть разбит на два (или даже продублирован), доступ к которым осуществляется независимо. На уровне кода конфликтующие по ресурсам команды обычно разносятся компилятором на некоторое расстояние и между ними вставляются другие, не зависящие от них команды.
Источник: studref.com
34. Конвейерная обработка данных
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработкиинформации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда вконвейерепродвигается на следующую стадию обработки, выполненная команда покидаетконвейер, а новая поступает в него.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Выполнение типичной команды можно разделить на следующие этапы:
С 1 – выборка команды (по адресу, заданному счетчиком команд, из памяти извлекается команда и помещается в буфер);
С 2 – декодирование команды (определение КОП и типа операндов);
С 3 – выборка операндов (определение местонахождения операндов и вызов их из регистров);
С 4 – выполнение команды;
С 5 – запись результата в нужный регистр.
Работу конвейера можно условно представить в виде временной диаграммы на которой обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд. В качестве примера рассмотрим конвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно.
Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. Тогда среднее время выполнения команды в не конвейерной машине будет равно 260 нс. Если же используется конвейерная организация, длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере. Таким образом, ускорение, полученное в результате конвейеризации, будет равно отношению:
Среднее время выполнения команды в не конвейерном режиме:
——- = 4 Среднее время выполнения команды в конвейерном режиме: 65

Рис. 12.2 Диаграмма работы простейшего конвейера

Рис. 12.3 Эффект конвейеризации – четырехкратное ускорение
Конвейеры операций
Уже много лет известно, что главным препятствием высокой скорости выполнения команд является необходимость их вызова из памяти. Для разрешения этой проблемы можно вызывать команды из памяти заранее и хранить в специальном наборе регистров. Эта идея использовалась еще в 1959 году при разработке компьютера Stretch компании IBM, а набор регистров был назван буфером выборки с упреждением. Таким образом, когда требовалась определенная команда, она вызывалась прямо из буфера, а обращения к памяти не происходило.
В действительности при выборке с упреждением команда обрабатывается за два шага: сначала происходит вызов команды, а затем — ее выполнение. Еще больше продвинула эту стратегию идея конвейера. При использовании конвейера команда обрабатывается уже не за два, а за большее количество шагов, каждый из которых реализуется определенным аппаратным компонентом, причем все эти компоненты могут работать параллельно.
На рисунке 2.1 а) изображен конвейер из пяти блоков, которые называются ступенями. Первая ступень (блок С1) вызывает команду из памяти и помещает ее в буфер, где она хранится до тех пор, пока не потребуется. Вторая ступень (блок С2) декодирует эту команду, определяя ее тип и тип ее операндов. Третья ступень (блок СЗ) определяет местонахождение операндов и вызывает их из регистров или из памяти. Четвертая ступень (блок С4) выполняет команду, и, наконец, блок С5 записывает результат обратно в нужный регистр.
Чтобы лучше понять принципы работы конвейера, рассмотрим аналогичный пример. Представим себе кондитерскую фабрику, на которой выпечка тортов и их упаковка для отправки производятся раздельно. Предположим, что в отделе отправки находится длинный конвейер, вдоль которого располагаются 5 рабочих (или ступеней обработки).
Каждые 10 секунд (это время цикла) первый рабочий ставит пустую коробку для торта на ленту конвейера. Эта коробка отправляется ко второму рабочему, который кладет в нее торт. После этого коробка с тортом доставляется третьему рабочему, который закрывает и запечатывает ее. Затем она поступает к четвертому рабочему, который ставит на ней штамп.
Наконец, пятый рабочий снимает коробку с конвейерной ленты и помещает ее в большой контейнер для отправки в супермаркет. Примерно таким же образом действует компьютерный конвейер: каждая команда (в случае с кондитерской фабрикой — торт) перед окончательным выполнением проходит несколько ступеней обработки.
Возвратимся к нашему конвейеру на рисунке 2.1. Предположим, что время цикла у этой машины — 2 нс. Тогда для того, чтобы одна команда прошла через весь конвейер, требуется 10 нс. На первый взгляд может показаться, что такой компьютер будет выполнять 100 млн команд в секунду, в действительности же скорость его работы гораздо выше. В течение каждого цикла (2 нс) завершается выполнение одной новой команды, поэтому машина выполняет не 100, а 500 млн команд в секунду! [2]
2.2 Оценка производительности идеального конвейера
Пусть задана операция, выполнение которой разбито на n последовательных этапов. Пусть ti — время выполнения i-го этапа. При последовательном их выполнении операция выполняется за время
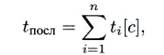
а быстродействие ЭВМ или одного процессора ВС, выполняющего только эту операцию, составит
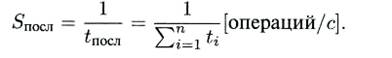
Выберем время такта — величину tT = max и потребуем при разбиении на этапы, чтобы для любого i = 1. n выполнялось условие ti + t(i+1) mod n= tT . То есть чтобы никакие два последовательных этапа (включая конец и новое начало операции) не могли быть выполнены за время одного такта.
Максимальное быстродействие процессора при полной загрузке конвейера составляет
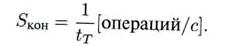
Число n — количество уровней конвейера, или глубина перекрытия, так как каждый такт на конвейере параллельно выполняются n операций. Чем больше число уровней (станций), тем больший выигрыш в быстродействии может быть получен.
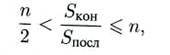
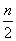
то есть выигрыш в быстродействии получается от до n раз.
Реальный выигрыш в быстродействии оказывается всегда меньше, чем указанный выше, поскольку:
1) некоторые операции, например, над целыми, могут выполняться за меньшее количество этапов, чем другие арифметические операции. Тогда отдельные станции конвейера будут простаивать.
2) при выполнении некоторых операций на определённых этапах могут требоваться результаты более поздних, ещё не выполненных этапов предыдущих операций. Приходится приостанавливать конвейер.
3) поток команд порождает недостаточное количество операций для полной загрузки конвейера [3].
Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов:
IF (Instruction Fetch) — считывание команды в процессор;
ID (Instruction Decoding) — декодирование команды;
OR (Operand Reading) — считывание операндов;
EX (Executing) — выполнение команды;
WB (Write Back) — запись результата.
Выполнение команд в таком конвейере представлено в таблице 2.1.
Так как в каждом такте могут выполняться различные стадии обработки команд, то длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии на другую требуется определенное дополнительное время (Дt), связанное с записью промежуточных результатов обработки в буферные регистры.
Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени составляют Дt = 5 единиц, получим время такта:
Оценим время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
Анализ таблицы 2.1 показывает, что при конвейерной обработке после того, как получен результат выполнения первой команды, результат очередной команды появляется в следующем такте работы процессора. Следовательно,
Tконв = 5T + (N-1) * T.
Примеры длительности выполнения некоторого количества команд при последовательной и конвейерной обработке приведены в таблица 2.2.
Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в процессоре Pentium длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 — уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц).
Информация о работе «Принципы организации параллелизма выполнения машинных команд в процессорах»
Раздел: Информатика, программирование
Количество знаков с пробелами: 102663
Количество таблиц: 6
Количество изображений: 1
Источник: kazedu.com