
Здесь, на первый взгляд, проблем вообще не существует, т.к. файловый объект однозначно идентифицируется своим полнопутевым именем. Однако, если внимательно рассмотреть архитектурные принципы реализации и возможности современных универсальных ОС, точка зрения на этот вопрос радикально меняется. В порядке примера рассмотрим предоставляемые современными ОС Windows возможности идентификации файлового объекта при запросе доступа.
В NTFS файловый объект может быть идентифицирован различными способами:
- Файловые объекты, задаваемые длинными именами, характеризуются той отличительной особенностью, что к ним можно обращаться, как по длинному, так и по короткому имени, например к каталогу “Program files” можно обратиться по короткому имени “Progra~1”;
- Файловые объекты, задаваемые русскими (либо в иной кодировке) буквами, также имеют короткое имя, которое формируется с использованием кодировки Unicode (внешне они могут существенно различаться), например, короткое имя для каталога “C:Documents and SettingsUSER1Главное меню” выглядит как “C:Docume~1USER15D29~1”. К этим объектам также можно обратиться, как по длинному, так и по короткому имени;
- Файловый объект идентифицируется не только именем, но и своим идентификатором (ID) – индекс объекта в таблице MFT, причем некоторые программы обращаются к файловым объектам не по имени, а именно по ID.
Пусть установленная в вашей информационной системе СЗИ от НСД не перехватывает и не анализирует лишь один подобный способ обращения к файловому объекту, и, по большому счету, она становится полностью бесполезной (рано или поздно, злоумышленник выявит данный недостаток средства защиты и воспользуется им).
Глаз БОГА Бот самый Честный Обзор. Как Найти Человека
Вывод. Механизмом контроля доступа к файловым объектам, объект должен однозначно идентифицироваться при любом допустимом способе обращения к нему (при любом способе его идентификации приложением), как следствие, средством защиты должны перехватываться любые способы обращения к файловому объекту, а файловый объект должен однозначно идентифицироваться при любом способе обращения к нему.
Если же говорить об информации, хранящейся на компьютере, в широком смысле, то далеко не все данные образуют файлы. Есть еще, так называемая, остаточная информация. Дело в том, что при удалении, либо модификации (с уменьшением объема) файла штатными средствами ОС, собственно данные не удаляются, осуществляется переразметка MFT-таблицы. Другими словами, на жестком диске и внешних накопителях всегда присутствует, так называемая остаточная информация, которую невозможно прочитать, обратившись к файлу, но достаточно просто, с использованием сторонних программ прямого доступа к диску.
Поскольку остаточная информация не образует какого-либо объекта, подлежащего идентификации, она должна удаляться при удалении или модификации файлового объекта. Это реализуется отдельным механизмом гарантированного удаления остаточной информации, состоящем в следующем. Запрос на удаление и модификацию файла перехватывается системой защиты, после чего ею осуществляется очистка освобождаемого дискового пространства (как правило, заданное число раз записывается какая-либо информация, например, все «0», либо случайная последовательность), затем управление передается системе для «удаления» штатными средствами.
Вывод. Задача идентификации объекта доступа «файловый объект» предполагает решение задачи гарантированного удаления остаточной информации отдельным соответствующим механизмом защиты.
Но, и при реализации данного механизма защиты, возникают требования к корректности. Рассмотрим на примере NTFS. В NTFS все данные, хранящиеся на томе, содержатся в файлах. Главная таблица файлов (MFT) занимает центральное место в структуре NTFS-тома. MFT реализована, как массив записей о файлах, где каждая запись представляет собою совокупность пар атрибутов и их значений.
Размер каждой записи фиксирован и равен 1 Кб. Если размер файла достаточно мал, чтобы поместиться в теле записи, то данные такого файла хранятся непосредственно в MFT.
В процессе работы системы, NTFS ведет запись в файл метаданных – файл журнала с именем $LogFile. NTFS использует его для регистрации всех операций, влияющих на структуру тома NTFS, как то: создание файла, удаление файла, расширение файла, урезание файла, установка файловой информации, переименование файла и изменение прав доступа к файлу. Информация, описывающая подобные транзакции, включает в себя копии записей из MFT и в дальнейшем используется для повтора или отмены изменений. Соответственно, если данные файла содержатся в записи MFT, то при каждом изменении, данные файла будут (в числе прочего) скопированы в файл журнала.
Во избежание такого многократного дублирования данных небольших файлов, система защиты должна при создании файлов принудительно выделять пространство на томе вне таблицы MFT размером 1 Кб, что обеспечит гарантированную очистку данных даже небольшого файла при его удалении и модификации штатными средствами ОС.
Источник: studfile.net
Русские Блоги
Имя распознавание объекта, называемое «особым именем. Обычно включают в себя две части: (1) идентификация границы субъекта; (2) Определить категорию объекта (имя, имя, название учреждения или другое).
Имя идентификация сущности обычно представляет собой первый шаг в области добычи знаний, добычу информации, широко используются в области обработки натурального языка. Далее мы представим методы общепринятых названных объектов признания.
Во-вторых, признание объекта именования NLTK
NLTK: набор натурального языка, реализованный компьютерным и информационным наукой Pennsylvania, использует язык Python, который имеет большое количество наборов общественности, а также модель, которая обеспечивает всеобъемлющие, простые в использовании интерфейсы, охватывающие слово, и слово Определение. -peech Tag, POS-тег, именованное распознавание объекта, NER, синтаксический анализ и т. Д.
Вам нужно скачать NLTK перед использованием, скачать адрес:http://pypi.python.org/pypi/nltkПосле завершения установки введите тест импорта NLTK в среде Python, а затем введите NLTK.Download () для загрузки пакета, который вам нужно сделать, завершите установку.
Реализация кода Python (обратите внимание, что кодированный формат файла — UTF-8 без формата BOM):
— coding: utf-8 —
SYS.SETDEFAUAUTKOUCKODING («UTF8») # Пусть CMD идентифицирует правильное кодирование
Text = newfile.read () # читать файлы
Токены = nltk.word_tokedize (текст) #
Tagged = nltk.pos_tag (токены) # Номер слова
Предприятия = NLTK.Chunk.ne_chunk (Tagged) # Имя Идентификация сущности
A1 = STR (объекты) # конвертировать файлы в строки
file_object = open(‘out.txt’, ‘w’)
File_object.write (A1) # Написать в файл
Специфический метод может сослаться на официальный веб-сайт NLTK:http://www.nltk.org/Результат вывода:
(‘on’, ‘IN’), (‘Thursday’, ‘NNP’), (‘morning’, ‘NN’),
Tree(‘PERSON’, [(‘Arthur’, ‘NNP’)]),
Конечно, чтобы облегчить просмотр, мы можем рисовать результаты в виде древесной структуры:
>>> from nltk.corpus import treebank
В-третьих, на основе Стэнфорда:
STANFORD по имени Установление сущности (NER) является одним из результатов спонсируемой группы исследований натурального языка университета, а домашняя страница:http://nlp.stanford.edu/software/CRF-NER.shtmlОтказ STANFORD NER — это реализация Java по имени идентификация субъекта (далее называемая NER)) программой. Нир отмечает объекты в тексте, такие как имена, корпоративные имена, регионы, гены и белки.
NER основан на учебной модели (модель идентифицирует время, местоположение, организацию, человек, деньги, процент, дату), который используется для обучения, что является большим количеством искусственно отмеченного хорошим текстом, теоретически используемым для обучения больше объема данных, тем лучше идентификация NER.
Поскольку оригинал NER основан на реализации Java, вы должны установить среду JAR1.8 на вашем компьютере перед использованием Python (в противном случае ошибка на сокетке).
Затем мы используем Pyner, чтобы использовать язык Python для реализации идентификации объекта имена. Адрес загрузки:https://github.com/dat/pyner
Установите Pyner: Unzip загруженного Pyner, переключите рабочий каталог в папку Pyner в командной строке, и введите команду: Установка Python Setup.py завершает установку.
Затем вам также нужно скачать STANFordner Toolkit, адрес загрузки:http://nlp.stanford.edu/software/stanford-ner-2014-01-04.zipЗатем, затем откройте форму команд CMD, выполните, Java -MX1000M -CP stanford-ner.jar edu.stanford.nlp.ie.nyverver -load классификаторы классификаторы / English.muc.7class.dissim.crf.nlp.ie.dister.ruverver — GZ -Opt 8080 -Outputformat Inlinexml до результата: Загрузка классификатора от классификаторов / English.muc.7class.dism.crf.ser.gz . сделано [1,2 сек].
Вышеуказанная операция состоит в том, что объект именования Стэнфорда определяет запись сокета на основе Java, поэтому необходимо убедиться, что есть окно для связи с нами. О программировании сокета Java вы можете обратиться к следующей статье:http://www.cnblogs.com/rond/p/3565113.html
Наконец, мы, наконец, можем использовать программирование Python для реализации NER:
Tagger = ner. Socketner (Host = ‘localhost’, port = 8080) #socket Programming
Результат = tagger.get_entities (текст) #stansford реализует NER
file_object = open(‘outfile.txt’, ‘w’)
Выше находится тест текстового файла, официальный случай веб-сайтаhttps://github.com/dat/pynerРезультат операции:
>>> tagger = ner.SocketNER(host=’localhost’, port=8080)
>>> tagger.get_entities(“University of California is located in California, United States”)
‘ORGANIZATION’: [‘University of California’]>
В-четвертых, сравнение двух методов:
Я взял один и тот же текстовый файл двумя способами сделать идентификацию объекта именования следующим образом:

Рисунок 1 Результаты работы NLTK

Рисунок 2 Режим Стэнфорда Результаты работы
По двум способам, мы можем найти, что именомонные объекты под NLTK более склонны к слову и слову сексуальные стандарты, хотя он также обозначает организационное имя, имя, имя место, но поскольку он ставит предикат, объекты в файл также Отмечена, вызывая избыточность выходного текста, который не способствует хорошо идентифицированному объекту читателя, и нам нужно дополнительно обработать текст. Когда сущность имени под NLTK немного немного немного, вы можете использовать пакет Treebank под NLTK, чтобы нарисовать текст как дерево, что делает результат более четко. Напротив, я предпочитаю идентификацию подъемы именования Стэнфорда, что может занять время, местоположение, организацию, личность, деньги, процент, дату семи юридических лиц, и без дополнительных слов. Однако, поскольку NER основан на разработке Java, могут быть много ошибок в пакетах JAR или проблемы при использовании Python.
Приведенное выше о NLTK и STANFORD идентификации имени объекта английского языка, а также китайский файл обработки естественного языка, мы можем рассмотреть слово Jieba: https://www.oschina.net/p/jieba。
[Резюме]: Объект именования определяет первый шаг в создании карт знаний, выполняя проблемы при обработке естественных языков, эта статья суммирует два способа обработки вопросов идентификации сущности, которые вы освоили?
Источник: russianblogs.com
Идентификация, аутентификация, авторизация — в чем разница?
Перед серией уроков по информационной безопасности нам нужно разобраться с базовыми определениями.

Сегодня мы узнаем, что такое идентификация, аутентификация, авторизация и в чем разница между этими понятиями
Что такое идентификация?
Сначала давайте прочитаем определение:
Идентификация — это процедура распознавания субъекта по его идентификатору (проще говоря, это определение имени, логина или номера).
Идентификация выполняется при попытке войти в какую-либо систему (например, в операционную систему или в сервис электронной почты).
Сложно? Давайте перейдём к примерам, заодно разберемся, что такое идентификатор.

Пример идентификатора в социальной сети ВКонтакте
Когда нам звонят с неизвестного номера, что мы делаем? Правильно, спрашиваем “Кто это”, т.е. узнаём имя. Имя в данном случае и есть идентификатор, а ответ вашего собеседника — это будет идентификация.
Идентификатором может быть:
- номер телефона
- номер паспорта
- номер страницы в социальной сети и т.д.
Подробнее об идентификаторах и ID рекомендую прочитать здесь.
Что такое аутентификация?
После идентификации производится аутентификация:
Аутентификация – это процедура проверки подлинности (пользователя проверяют с помощью пароля, письмо проверяют по электронной подписи и т.д.)
Чтобы определить чью-то подлинность, можно воспользоваться тремя факторами:
- Пароль – то, что мы знаем (слово, PIN-код, код для замка, графический ключ)
- Устройство – то, что мы имеем (пластиковая карта, ключ от замка, USB-ключ)
- Биометрика – то, что является частью нас (отпечаток пальца, портрет, сетчатка глаза)

Отпечаток пальца может быть использован в качестве пароля при аутентификации
Получается, что каждый раз, когда вы вставляете ключ в замок, вводите пароль или прикладываете палец к сенсору отпечатков пальцев, вы проходите аутентификацию.
Ну как, понятно, что такое аутентификация? Если остались вопросы, можно задать их в комментариях, но перед этим разберемся еще с одним термином.
Что такое авторизация?
Когда определили ID, проверили подлинность, уже можно предоставить и доступ, то есть, выполнить авторизацию.
Авторизация – это предоставление доступа к какому-либо ресурсу (например, к электронной почте).
Разберемся на примерах, что же это за загадочная авторизация:
- Открытие двери после проворачивания ключа в замке
- Доступ к электронной почте после ввода пароля
- Разблокировка смартфона после сканирования отпечатка пальца
- Выдача средств в банке после проверки паспорта и данных о вашем счете

Дверь открылась? Вы авторизованы!
Взаимосвязь идентификации, аутентификации и авторизации
Наверное, вы уже догадались, что все три процедуры взаимосвязаны:
- Сначала определяют имя (логин или номер) – идентификация
- Затем проверяют пароль (ключ или отпечаток пальца) – аутентификация
- И в конце предоставляют доступ – авторизация
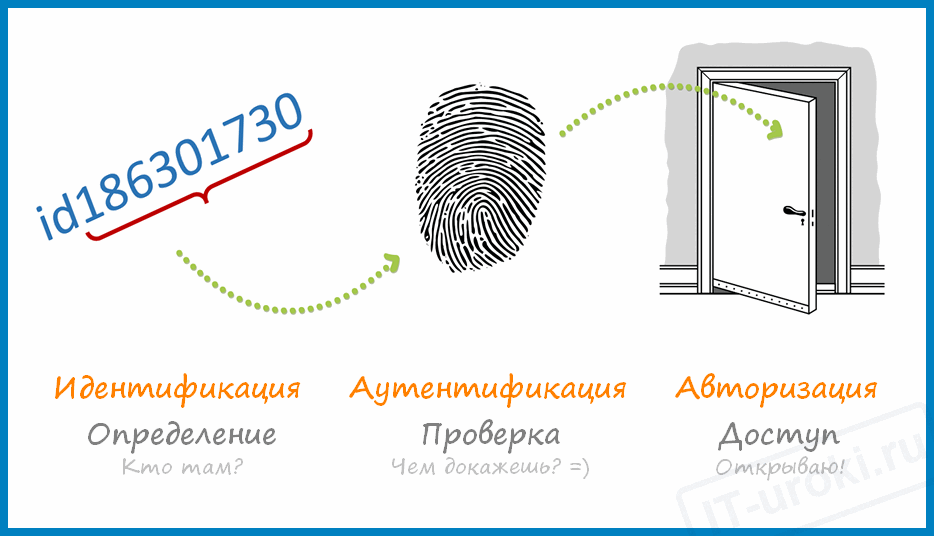
Инфографика: 1 — Идентификация; 2 — Аутентификация; 3 — Авторизация
Проблемы безопасности при авторизации
Помните, как в сказке «Красная Шапочка» бабушка разрешает внучке войти в дом? Сначала бабушка спрашивает, кто за дверью, затем говорит Красной Шапочке, как открыть дверь. Волку же оказалось достаточным узнать имя внучки и расположение дома, чтобы пробраться в дом.
Какой вывод можно сделать из этой истории?
Каждый этап авторизации должен быть тщательно продуман, а идентификатор, пароль и сам принцип авторизации нужно держать в секрете.
Заключение
Итак, сегодня вы узнали, что такое идентификация, аутентификация и авторизация.
Теперь мы можем двигаться дальше: учиться создавать сложные пароли, знакомиться с правилами безопасности в Интернете, настраивать свой компьютер с учетом требований безопасности.
А в заключение, занимательная задачка для проверки знаний: посчитайте, сколько раз проходят идентификацию, аутентификацию и авторизацию персонажи замечательного мультфильма «Петя и Красная Шапочка» (ответы в комментариях).
P.S. Самые внимательные могут посчитать, сколько раз нарушены рассмотренные в данном уроке процедуры.
Копирование запрещено, но можно делиться ссылками:
Источник: it-uroki.ru