
Криптографические хэш-функции распространены очень широко. Они используются для хранения паролей при аутентификации, для защиты данных в системах проверки файлов, для обнаружения вредоносного программного обеспечения, для кодирования информации в блокчейне (блок — основной примитив, обрабатываемый Биткойном и Эфириумом). В этой статье пойдет разговор об алгоритмах хеширования: что это, какие типы бывают, какими свойствами обладают.
В наши дни существует много криптографических алгоритмов. Они бывают разные и отличаются по сложности, разрядности, криптографической надежности, особенностям работы. Алгоритмы хеширования — идея не новая. Они появилась более полувека назад, причем за много лет с принципиальной точки зрения мало что изменилось. Но в результате своего развития хеширование данных приобрело много новых свойств, поэтому его применение в сфере информационных технологий стало уже повсеместным.
Что такое хеш (хэш, hash)?
Хеш или хэш — это криптографическая функция хеширования (function), которую обычно называют просто хэшем. Хеш-функция представляет собой математический алгоритм, который может преобразовать произвольный массив данных в строку фиксированной длины, состоящую из цифр и букв.
КАК РАСШИФРОВАТЬ ХЭШ SHA-256, MD-5, Bcrypt! БЫСТРО И ПРОСТО!
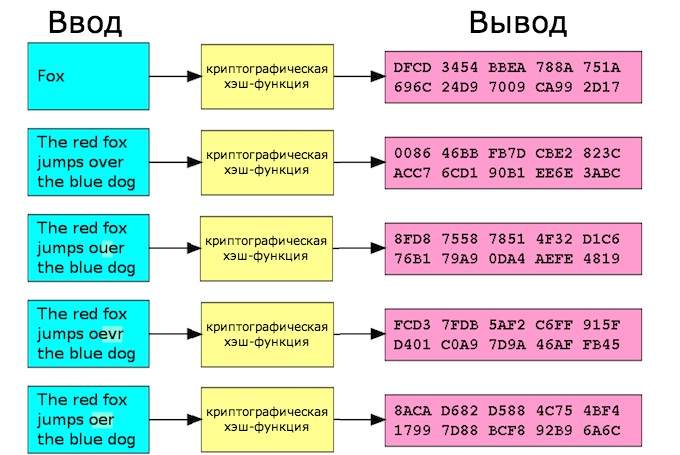
Основная идея используемых в данном случае функций — применение детерминированного алгоритма. Речь идет об алгоритмическом процессе, выдающем уникальный и предопределенный результат при получении входных данных. То есть при приеме одних и тех же входных данных будет создаваться та же самая строка фиксированной длины (использование одинакового ввода каждый раз приводит к одинаковому результату). Детерминизм — важное свойство этого алгоритма. И если во входных данных изменить хотя бы один символ, будет создан совершенно другой хэш.
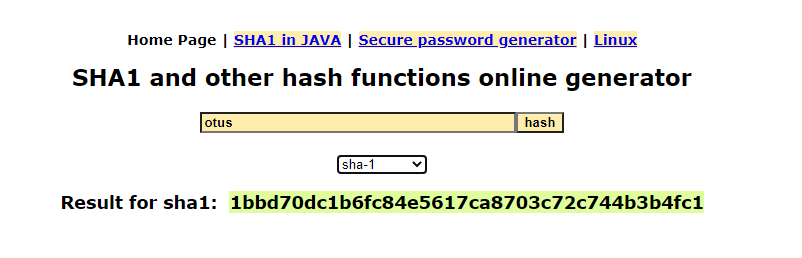
Убедиться в этом можно на любом онлайн-генераторе. Набрав слово «Otus» и воспользовавшись алгоритмом sha1 (Secure Hashing Algorithm), мы получим хеш 7576750f9d76fab50762b5987739c18d99d2aff7. При изменении любой буквы изменится и результат, причем изменится полностью. Мало того, если просто поменять регистр хотя бы одной буквы, итог тоже будет совершенно иным: если написать «otus», алгоритм хэш-функции отработает со следующим результатом: 1bbd70dc1b6fc84e5617ca8703c72c744b3b4fc1. Хотя общие моменты все же есть: строка всегда состоит из сорока символов.
В предыдущем примере речь шла о применении хэш-алгоритма для слова из 4 букв. Но с тем же успехом можно вставить слово из 1000 букв — все равно после обработки данных на выходе получится значение из 40 символов. Аналогичная ситуация будет и при обработке полного собрания сочинений Льва Толстого.
Криптостойкость функций хеширования
Говоря о криптостойкости, предполагают выполнение ряда требований. То есть хороший алгоритм обладает несколькими свойствами: — при изменении одного бита во входных данных, должно наблюдаться изменение всего хэша; — алгоритм должен быть устойчив к коллизиям; — алгоритм должен быть устойчив к восстановлению хешируемых данных, то есть должна обеспечиваться высокая сложность нахождения прообраза, а вычисление хэша не должно быть простым.
Что такое ХЭШ функция? | Хеширование | Хранение паролей
Проблемы хэшей
Одна из проблем криптографических функций хеширования — неизбежность коллизий. Раз речь идет о строке фиксированной длины, значит, существует вероятность, что для каждого ввода возможно наличие и других входов, способных привести к тому же самому хешу. В результате хакер может создать коллизию, позволяющую передать вредоносные данные под видом правильного хэша.
Цель хороших криптографических функций — максимально усложнить вероятность нахождения способов генерации входных данных, хешируемых с одинаковым значением. Как уже было сказано ранее, вычисление хэша не должно быть простым, а сам алгоритм должен быть устойчив к «атакам нахождения прообраза». Необходимо, чтобы на практике было чрезвычайно сложно (а лучше — невозможно) вычислить обратные детерминированные шаги, которые предприняты для воспроизведения созданного хешем значения.
Если S = hash (x), то, в идеале, нахождение x должно быть практически невозможным.
Алгоритм MD5 и его подверженность взлому
MD5 hash — один из первых стандартов алгоритма, который применялся в целях проверки целостности файлов (контрольных сумм). Также с его помощью хранили пароли в базах данных web-приложений. Функциональность относительно проста — алгоритм выводит для каждого ввода данных фиксированную 128-битную строку, задействуя для вычисления детерминированного результата однонаправленные тривиальные операции в нескольких раундах. Особенность — простота операций и короткая выходная длина, в результате чего MD5 является относительно легким для взлома. А еще он обладает низкой степенью защиты к атаке типа «дня рождения».
Атака дня рождения
Если поместить 23 человека в одну комнату, можно дать 50%-ную вероятность того, что у двух человек день рождения будет в один и тот же день. Если же количество людей довести до 70-ти, вероятность совпадения по дню рождения приблизится к 99,9 %. Есть и другая интерпретация: если голубям дать возможность сесть в коробки, при условии, что число коробок меньше числа голубей, окажется, что хотя бы в одной из коробок находится более одного голубя.

Вывод прост: если есть фиксированные ограничения на выход, значит, есть и фиксированная степень перестановок, на которых существует возможность обнаружить коллизию.
Когда разговор идет о сопротивлении коллизиям, то алгоритм MD5 действительно очень слаб. Настолько слаб, что даже бытовой Pentium 2,4 ГГц сможет вычислить искусственные хеш-коллизии, затратив на это чуть более нескольких секунд. Всё это в ранние годы стало причиной утечки большого количества предварительных MD5-прообразов.
SHA1, SHA2, SHA3
Secure Hashing Algorithm (SHA1) — алгоритм, созданный Агентством национальной безопасности (NSA). Он создает 160-битные выходные данные фиксированной длины. На деле SHA1 лишь улучшил MD5 и увеличил длину вывода, а также увеличил число однонаправленных операций и их сложность.
Однако каких-нибудь фундаментальных улучшений не произошло, особенно когда разговор шел о противодействии более мощным вычислительным машинам. Со временем появилась альтернатива — SHA2, а потом и SHA3. Последний алгоритм уже принципиально отличается по архитектуре и является частью большой схемы алгоритмов хеширования (известен как KECCAK — «Кетч-Ак»). Несмотря на схожесть названия, SHA3 имеет другой внутренний механизм, в котором используются случайные перестановки при обработке данных — «Впитывание» и «Выжимание» (конструкция «губки»).
Что в будущем?
Вне зависимости от того, какие технологии шифрования и криптографические новинки будут использоваться в этом направлении, все сводится к решению одной из двух задач: 1) увеличению сложности внутренних операций хэширования; 2) увеличению длины hash-выхода данных с расчетом на то, что вычислительные мощности атакующих не смогут эффективно вычислять коллизию.
И, несмотря на появление в будущем квантовых компьютеров, специалисты уверены, что правильные инструменты (то же хэширование) способны выдержать испытания временем, ведь ни что не стоит на месте. Дело в том, что с увеличением вычислительных мощностей снижается математическая формализация структуры внутренних алгоритмических хэш-конструкций. А квантовые вычисления наиболее эффективны лишь в отношении к вещам, имеющим строгую математическую структуру.
Источник: otus.ru
Что такое хэширование и зачем оно нужно?
Это термин из ИТ. Обычному пользователю совершенно незачем задумываться о смысле хэширования. Хэширование представляет интерес только для программистов (и, возможно, математиков).
Хэширование — это процесс, в котором вы подаёте на вход некоторого хэширующего алгоритма некоторые достаточно большие по объёму данные (допустим миллион байт) и получаете на выходе относительно короткую (допустим 32 байта), но при этом достаточно уникальную строку, которая позволяет отличить эти ваши данные (что были на входе) от каких-то других данных. Эта строка называется «хэш».
Хэш используется для того, чтобы быстрее отличать одни данные от других без необходимости сравнивать каждый-каждый бит этих данных. Достаточно обработать эти данные один раз (вычислить их хэши) и можно сравнивать только их, а это гораздо быстрее. Идея такая. Если хэши различаются, значит, это совершенно точно разные данные.
Если хэши одинаковы, значит, с вероятностью в 99,99999. (и ещё 70 девяток, если предположить идеальное распределение 256-битных хэшей), это одинаковые данные. Хотя всегда существует маленький шанс, что данные всё-таки разные, несмотря на одинаковые хэши.
Хэширующий алгоритм (хэш-функция) должен стремиться как можно лучше выполнять следующие требования:
- Одни и те же данные должны давать всегда один и тот же хэш. Это обязательное условие.
- Разные данные должны давать разный хэш. Это условие не может быть выполнено полностью (понятно, что миллион байт нельзя магическим образом уменьшить до 30, на то он и миллион), но нужно стремиться к тому, чтобы выполнить его как можно лучше.
Хорошая хэш-функция ведёт себя следующим образом:
- Весь доступный диапазон хэшей используется по максимуму. То есть, если на хэш отведено 32 байта, то разные данные дают максимально разнообразный хэш, который может являться совершенно любой комбинацией битов. То есть, диапазон хэшей не «простаивает».
- Даже небольшое изменение входных данных (даже изменение 1 бита входных данных) должно давать другой хэш. Не должно быть такого, что небольшие изменения дают тот же самый хэш. Тот же самый хэш должен возникать в результате какого-то совершенно другого набора данных, чтобы вероятность случайного присутствия двух таких данных (дающих одинаковый хэш) была минимальной.
Для чего нужен хэш. Допустим, у вас есть массив из миллиона разных (неодинаковых) строк. В каждой строке миллион символов (то есть, всего у вас 1 терабайт = 1000 гигабайт данных). Вам приходит такое указание: добавьте строку, которая содержит «тото-сёто-пятое-десятое-и-ещё-миллион-символов», в ваш массив, но только в том случае, если такой строки там ещё нет.
В итоге, ваша задача превращается в посимвольное сравнение миллиона символов в миллионах строк. Очень хорошо, если начала строк у вас разные и вы сможете быстро отсеивать неподходящие строки. Но если все строки содержат примерно одинаковый текст, то вам нужно провернуть гигантское количество работы.
Но если перед записью вы имеете (вычислили их ранее) хэши эти строк, то ваша задача превращается в сравнение 32 символов вместо миллиона символов (32 мегабайта данных на весь массив). Если вы обнаружили, что у вас в списке есть точно такой же хэш, то для полной надёжности, вы можете сравнить посимвольно только эту строку. Гораздо меньше затрат, чем проверять терабайт целиком, не так ли? (На самом деле, даже 32 мегабайта хэшей проверять не потребуется, поскольку по теории вероятностей, лишь 1-2 первых символа хэшей будут совпадать, да и то очень редко, а 3 одинаковых символа подряд, возможно, не найдутся во всём миллионе хэшей. И это при том, что изначальные данные могли быть очень похожими.)
Хэш также может использоваться для проверки целостности данных при передаче. Вы передали гигабайт данных. А затем передали 32-байтный хэш. Получатель на своей стороне захешировал этот гигабайт тем же способом (той же хэш-функцией) и получил тот же самый хэш. Теперь он уверен, что он имеет точно те же данные, что и отправитель (вероятность случайной ошибки примерно около 1e-70, поэтому ей можно пренебречь; на самом деле, вероятность, скорее всего, ещё меньше, потому что хорошая хэш-функция не даст такой же хэш на похожих данных).
На практике некоторые хэш-функции также используются для шифрования. Хотя шифрование не является хэшированием, некоторые хэш-функции для этого хорошо подходят. Благодаря практически полностью хаотичному соответствию хэшей исходным данным, практически невозможно подобрать ключ, изучая закономерности в последовательностях данных.
Источник: yandex.ru
Хеш-функция, что это такое?

Сегодня я хотел бы рассказать о том, что из себя представляет хеш-функция, коснуться её основных свойств, привести примеры использования и в общих чертах разобрать современный алгоритм хеширования SHA-3, который был опубликован в качестве Федерального Стандарта Обработки Информации США в 2015 году.
Общие сведения
Криптографическая хеш-функция — это математический алгоритм, который отображает данные произвольного размера в битовый массив фиксированного размера.
Результат, производимый хеш-функцией, называется «хеш-суммой» или же просто «хешем», а входные данные часто называют «сообщением».
Для идеальной хеш-функции выполняются следующие условия:
а) хеш-функция является детерминированной, то есть одно и то же сообщение приводит к одному и тому же хеш-значению
b) значение хеш-функции быстро вычисляется для любого сообщения
c) невозможно найти сообщение, которое дает заданное хеш-значение
d) невозможно найти два разных сообщения с одинаковым хеш-значением
e) небольшое изменение в сообщении изменяет хеш настолько сильно, что новое и старое значения кажутся некоррелирующими
Давайте сразу рассмотрим пример воздействия хеш-функции SHA3-256.
Число 256 в названии алгоритма означает, что на выходе мы получим строку фиксированной длины 256 бит независимо от того, какие данные поступят на вход.
На рисунке ниже видно, что на выходе функции мы имеем 64 цифры шестнадцатеричной системы счисления. Переводя это в двоичную систему, получаем желанные 256 бит.
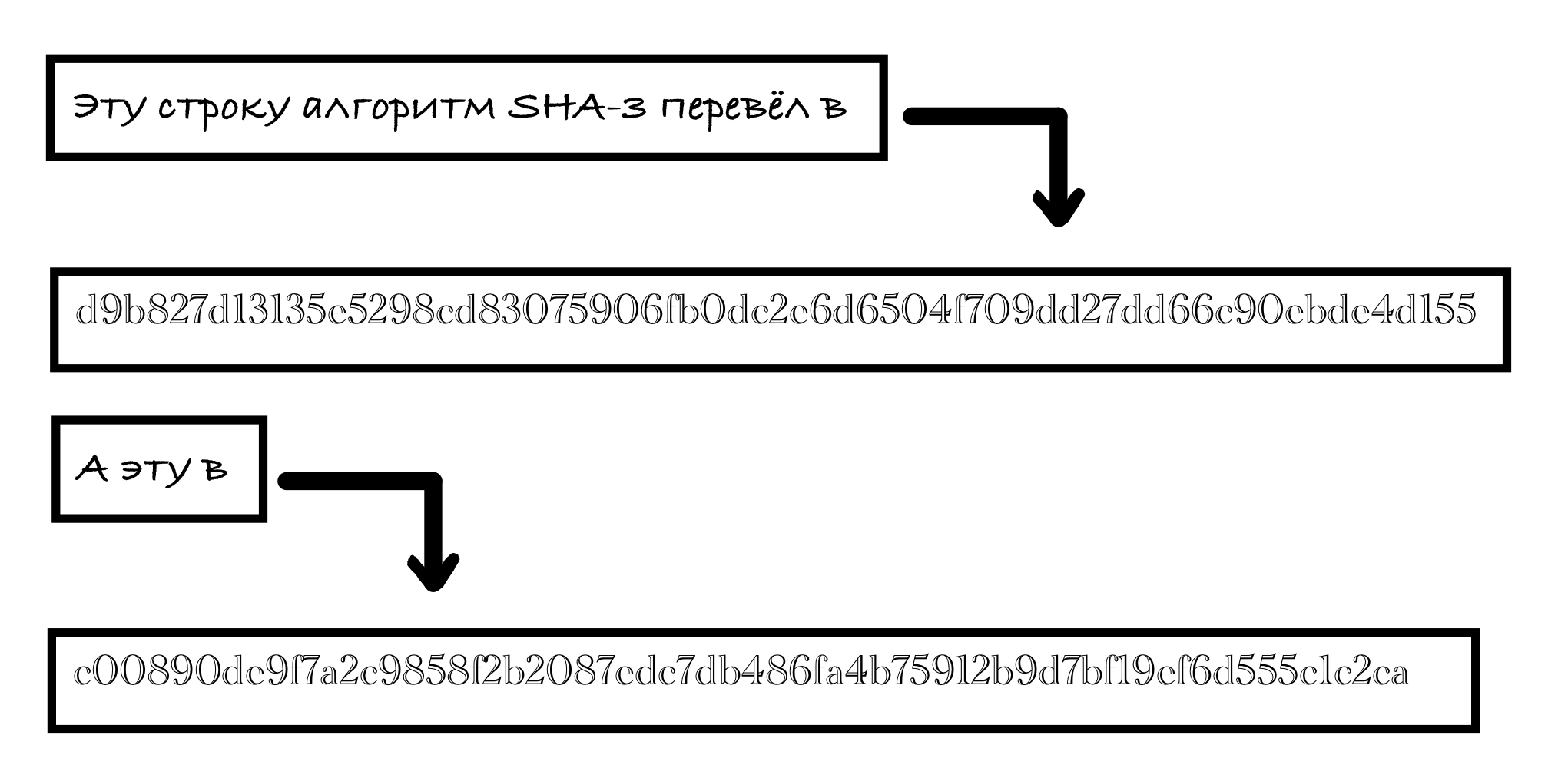
Любой заинтересованный читатель задаст себе вопрос: «А что будет, если на вход подать данные, бинарный код которых во много раз превосходит 256 бит?»
Ответ таков: на выходе получим все те же 256 бит!
Дело в том, что 256 бит — это соответствий, то есть различных входов имеют свой уникальный хеш.
Чтобы прикинуть, насколько велико это значение, запишем его следующим образом:
Надеюсь, теперь нет сомнений в том, что это очень внушительное число!
Поэтому ничего не мешает нам сопоставлять длинному входному массиву данных массив фиксированной длины.
Свойства
Криптографическая хеш-функция должна уметь противостоять всем известным типам криптоаналитических атак.
В теоретической криптографии уровень безопасности хеш-функции определяется с использованием следующих свойств:
Pre-image resistance
Имея заданное значение h, должно быть сложно найти любое сообщение m такое, что
Second pre-image resistance
Имея заданное входное значение , должно быть сложно найти другое входное значение такое, что
Collision resistance
Должно быть сложно найти два различных сообщения и таких, что
Такая пара сообщений и называется коллизией хеш-функции
Давайте чуть более подробно поговорим о каждом из перечисленных свойств.
Collision resistance. Как уже упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хеш. Таким образом, хеш-функция считается устойчивой к коллизиям до того момента, пока не будет обнаружена пара сообщений, дающая одинаковый выход. Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Несмотря на то, что хеш-функций без коллизий не существует, некоторые из них достаточно надежны и считаются устойчивыми к коллизиям.
Pre-image resistance. Это свойство называют сопротивлением прообразу. Хеш-функция считается защищенной от нахождения прообраза, если существует очень низкая вероятность того, что злоумышленник найдет сообщение, которое сгенерировало заданный хеш. Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Second pre-image resistance. Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Отсюда становится ясно, что атака по нахождению второго прообраза включает в себя поиск коллизии. Поэтому любая хеш-функция, устойчивая к коллизиям, также устойчива к атакам по поиску второго прообраза.
Неформально все эти свойства означают, что злоумышленник не сможет заменить или изменить входные данные, не меняя их хеша.
Таким образом, если два сообщения имеют одинаковый хеш, то можно быть уверенным, что они одинаковые.
В частности, хеш-функция должна вести себя как можно более похоже на случайную функцию, оставаясь при этом детерминированной и эффективно вычислимой.

Применение хеш-функций
Рассмотрим несколько достаточно простых примеров применения хеш-функций:
• Проверка целостности сообщений и файлов
Сравнивая хеш-значения сообщений, вычисленные до и после передачи, можно определить, были ли внесены какие-либо изменения в сообщение или файл.
• Верификация пароля
Проверка пароля обычно использует криптографические хеши. Хранение всех паролей пользователей в виде открытого текста может привести к массовому нарушению безопасности, если файл паролей будет скомпрометирован. Одним из способов уменьшения этой опасности является хранение в базе данных не самих паролей, а их хешей. При выполнении хеширования исходные пароли не могут быть восстановлены из сохраненных хеш-значений, поэтому если вы забыли свой пароль вам предложат сбросить его и придумать новый.
• Цифровая подпись
Подписываемые документы имеют различный объем, поэтому зачастую в схемах ЭП подпись ставится не на сам документ, а на его хеш. Вычисление хеша позволяет выявить малейшие изменения в документе при проверке подписи. Хеширование не входит в состав алгоритма ЭП, поэтому в схеме может быть применена любая надежная хеш-функция.
Предлагаю также рассмотреть следующий бытовой пример:
Алиса ставит перед Бобом сложную математическую задачу и утверждает, что она ее решила. Боб хотел бы попробовать решить задачу сам, но все же хотел бы быть уверенным, что Алиса не блефует. Поэтому Алиса записывает свое решение, вычисляет его хеш и сообщает Бобу (сохраняя решение в секрете). Затем, когда Боб сам придумает решение, Алиса может доказать, что она получила решение раньше Боба. Для этого ей нужно попросить Боба хешировать его решение и проверить, соответствует ли оно хеш-значению, которое она предоставила ему раньше.
Теперь давайте поговорим о SHA-3.

SHA-3
Национальный институт стандартов и технологий (NIST) в течение 2007—2012 провёл конкурс на новую криптографическую хеш-функцию, предназначенную для замены SHA-1 и SHA-2.
Организаторами были опубликованы некоторые критерии, на которых основывался выбор финалистов:
Способность противостоять атакам злоумышленников
• Производительность и стоимость
Вычислительная эффективность алгоритма и требования к оперативной памяти для программных реализаций, а также количество элементов для аппаратных реализаций
• Гибкость и простота дизайна
Гибкость в эффективной работе на самых разных платформах, гибкость в использовании параллелизма или расширений ISA для достижения более высокой производительности
В финальный тур попали всего 5 алгоритмов:
Победителем и новым SHA-3 стал алгоритм Keccak.
Давайте рассмотрим Keccak более подробно.
Keccak
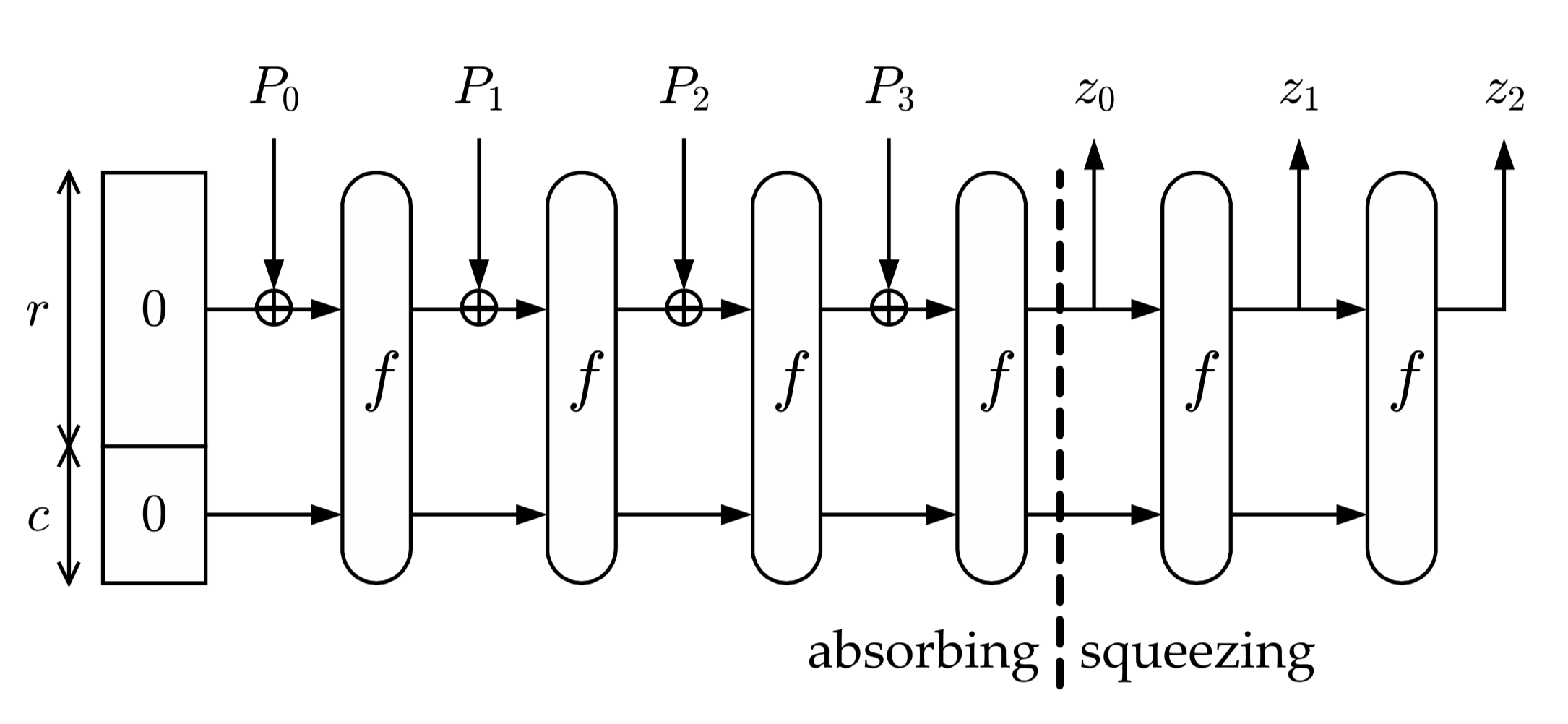
Хеш-функции семейства Keccak построены на основе конструкции криптографической губки, в которой данные сначала «впитываются» в губку, а затем результат Z «отжимается» из губки.
Любая губчатая функция Keccak использует одну из семи перестановок которая обозначается , где
перестановки представляют собой итерационные конструкции, состоящие из последовательности почти одинаковых раундов. Число раундов зависит от ширины перестановки и задаётся как где
В качестве стандарта SHA-3 была выбрана перестановка Keccak-f[1600], для неё количество раундов
Далее будем рассматривать
Давайте сразу введем понятие строки состояния, которая играет важную роль в алгоритме.
Строка состояния представляет собой строку длины 1600 бит, которая делится на и части, которые называются скоростью и ёмкостью состояния соотвественно.
Соотношение деления зависит от конкретного алгоритма семейства, например, для SHA3-256
В SHA-3 строка состояния S представлена в виде массива слов длины бит, всего бит. В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
Алгоритм получения хеш-функции можно разделить на несколько этапов:
• С помощью функции дополнения исходное сообщение M дополняется до строки P длины кратной r
• Строка P делится на n блоков длины
• «Впитывание»: каждый блок дополняется нулями до строки длиной бит (b = r+c) и суммируется по модулю 2 со строкой состояния , далее результат суммирования подаётся в функцию перестановки и получается новая строка состояния , которая опять суммируется по модулю 2 с блоком и дальше опять подаётся в функцию перестановки . Перед началом работы криптографической губки все элементыравны 0.
• «Отжимание»: пока длина результата меньше чем , где — количество бит в выходном массиве хеш-функции, первых бит строки состояния добавляется к результату . После каждой такой операции к строке состояния применяется функция перестановок и данные продолжают «отжиматься» дальше, пока не будет достигнуто значение длины выходных данных .
Все сразу станет понятно, когда вы посмотрите на картинку ниже:
Функция дополнения
В SHA-3 используется следующий шаблон дополнения 10. 1: к сообщению добавляется 1, после него от 0 до r — 1 нулевых бит и в конце добавляется 1.
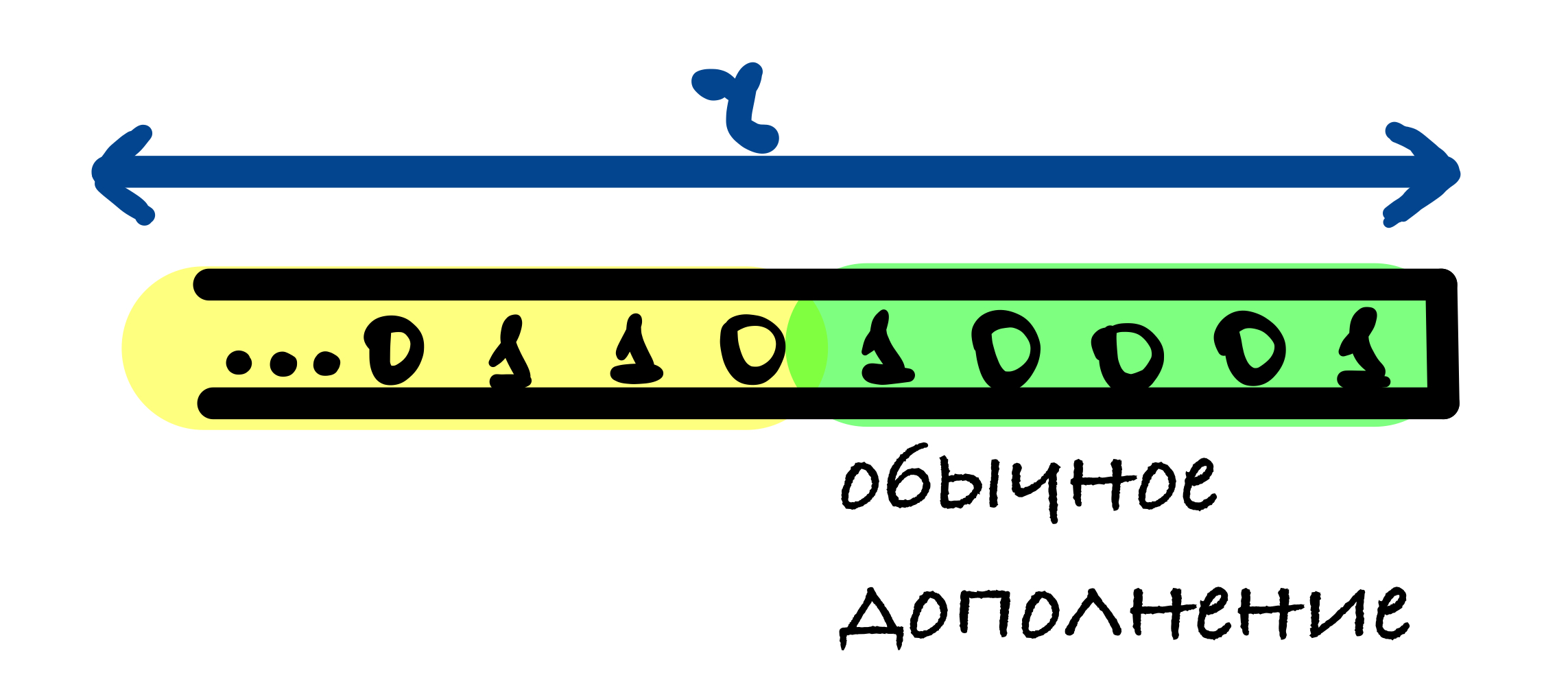
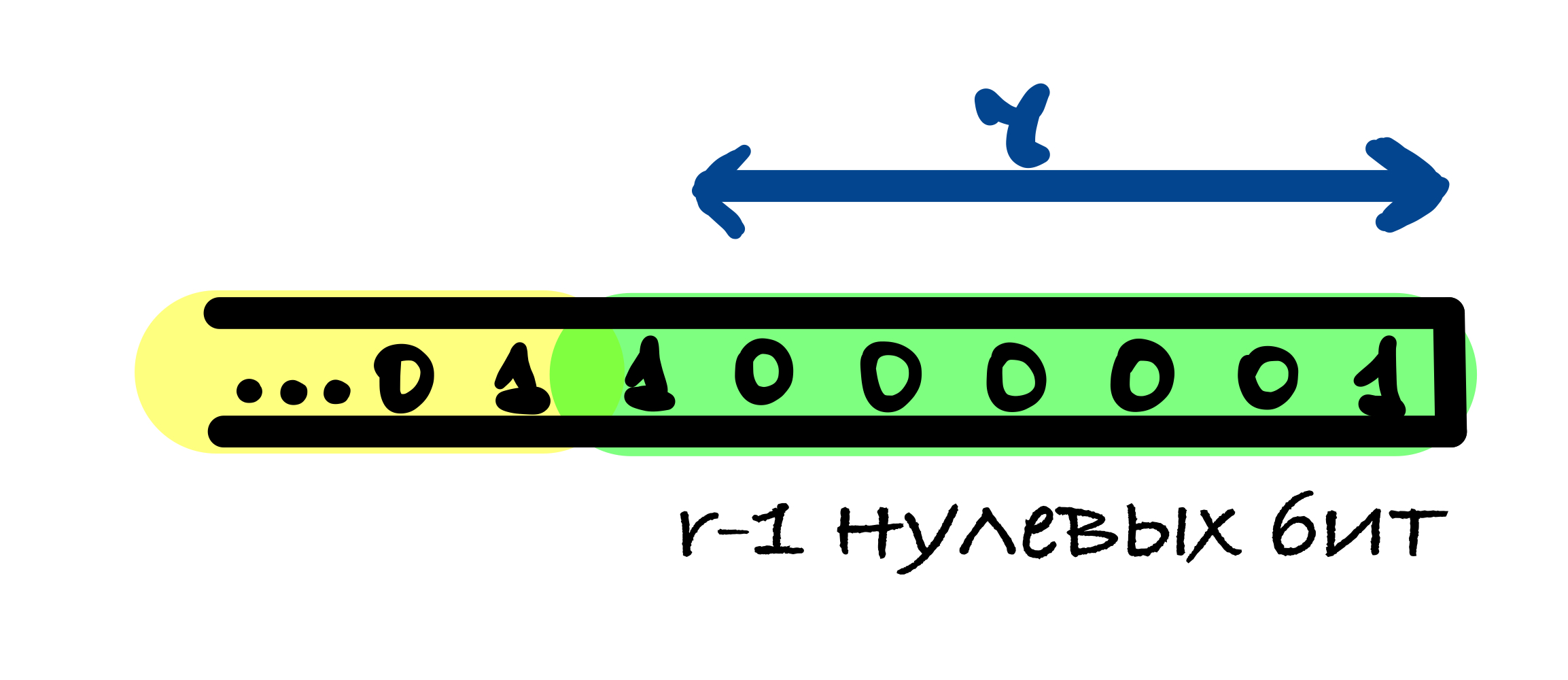
r — 1 нулевых бит может быть добавлено, когда последний блок сообщения имеет длину r — 1 бит. В этом случае последний блок дополняется единицей и к нему добавляется блок, состоящий из r — 1 нулевых бит и единицы в конце.
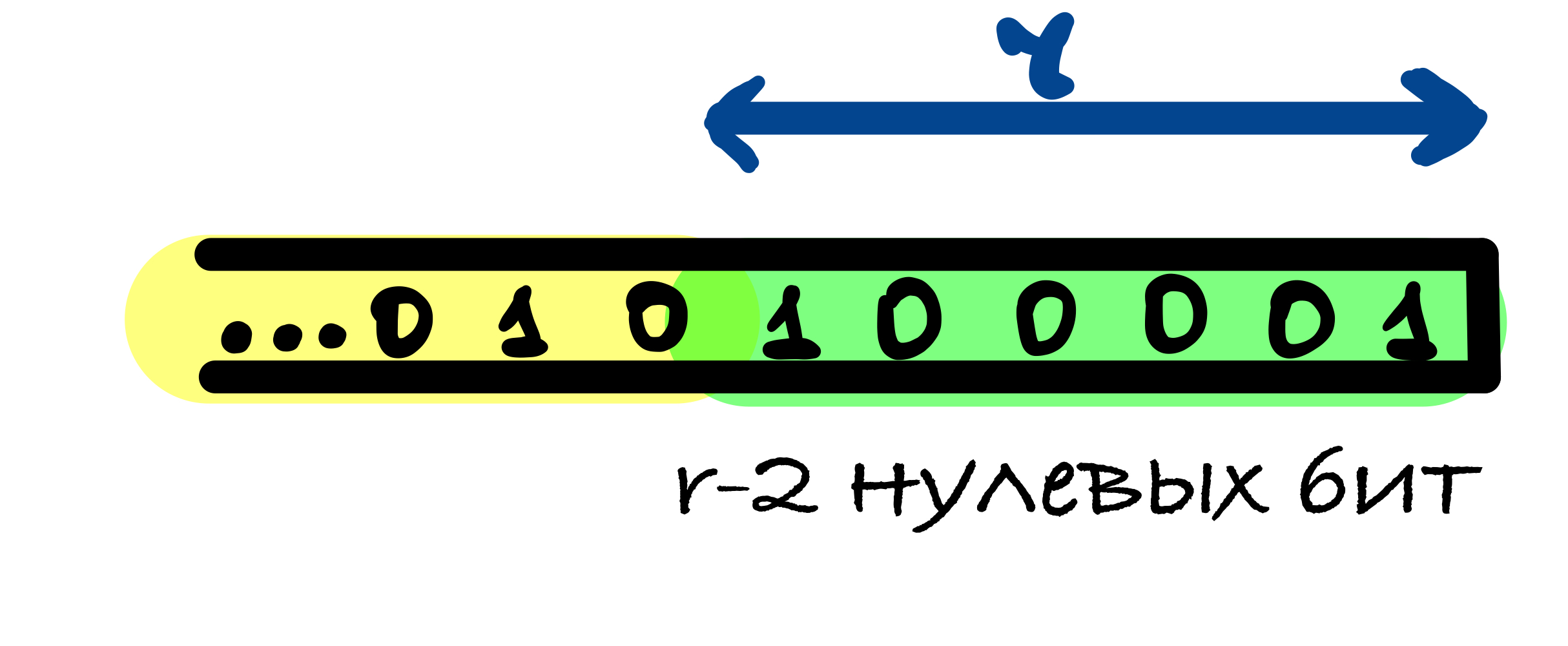
Если длина исходного сообщения M делится на r, то в этом случае к сообщению добавляется блок, начинающийся и оканчивающийся единицами, между которыми находятся r — 2 нулевых бит. Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
Первый единичный бит в функции дополнения нужен, чтобы результаты хеш-функции от сообщений, отличающихся несколькими нулевыми битами в конце, были различны.
Функция перестановок
Базовая функция перестановки состоит из раундов по пять шагов:
Тета, Ро, Пи, Хи, Йота
Далее будем использовать следующие обозначения:
Так как состояние имеет форму массива , то мы можем обозначить каждый бит состояния как
Обозначим результат преобразования состояния функцией перестановки
Также обозначим функцию, которая выполняет следующее соответствие:
— обычная функция трансляции, которая сопоставляет биту бит ,
где — длина слова (64 бит в нашем случае)
Я хочу вкратце описать каждый шаг функции перестановок, не вдаваясь в математические свойства каждого.
Шаг
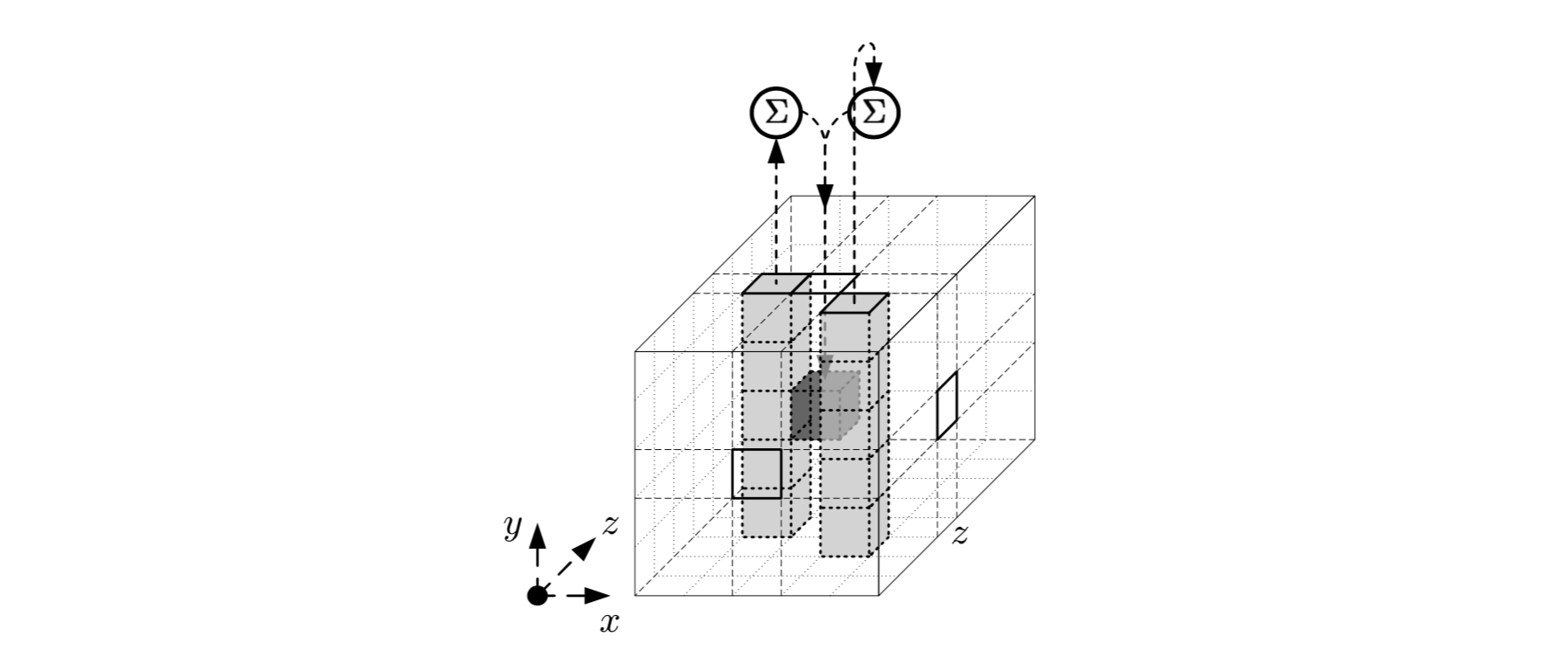
Эффект отображения можно описать следующим образом: оно добавляет к каждому биту побитовую сумму двух столбцов и
Схематическое представление функции:

Шаг
Отображение направлено на трансляции внутри слов (вдоль оси z).
Проще всего его описать псевдокодом и схематическим рисунком:

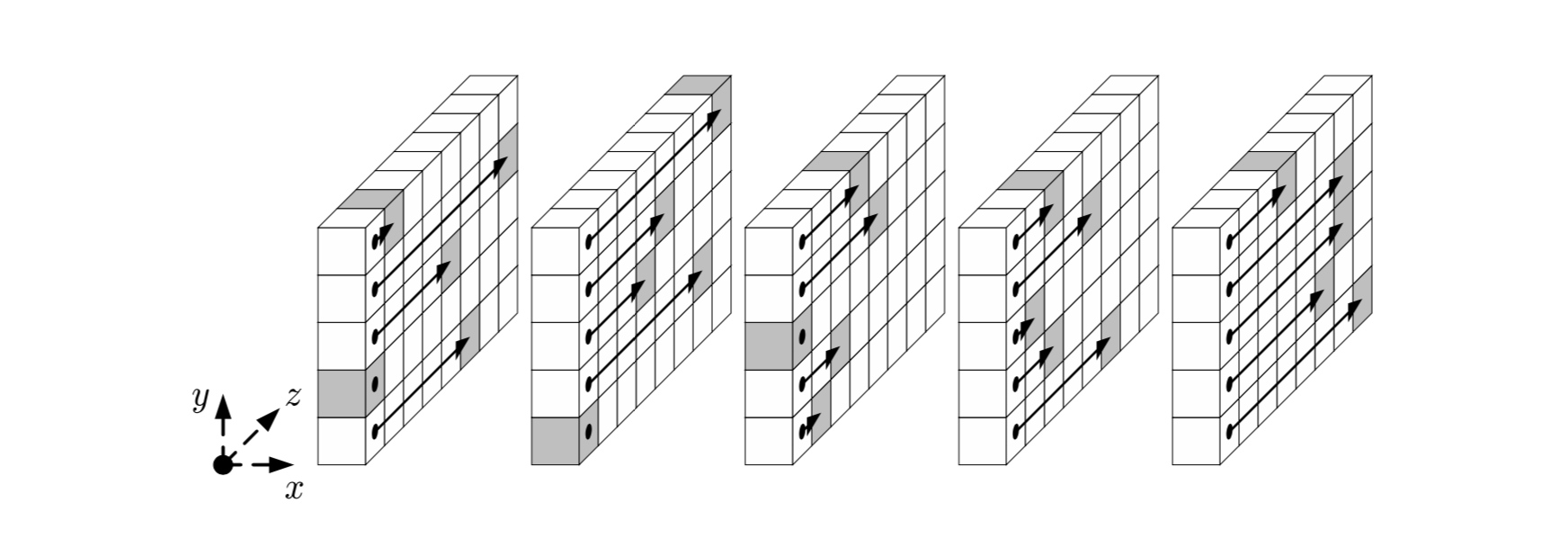
Шаг
Шаг представляется псевдокодом и схематическим рисунком:


Шаг
Шаг является единственный нелинейным преобразованием в
Псевдокод и схематическое представление:

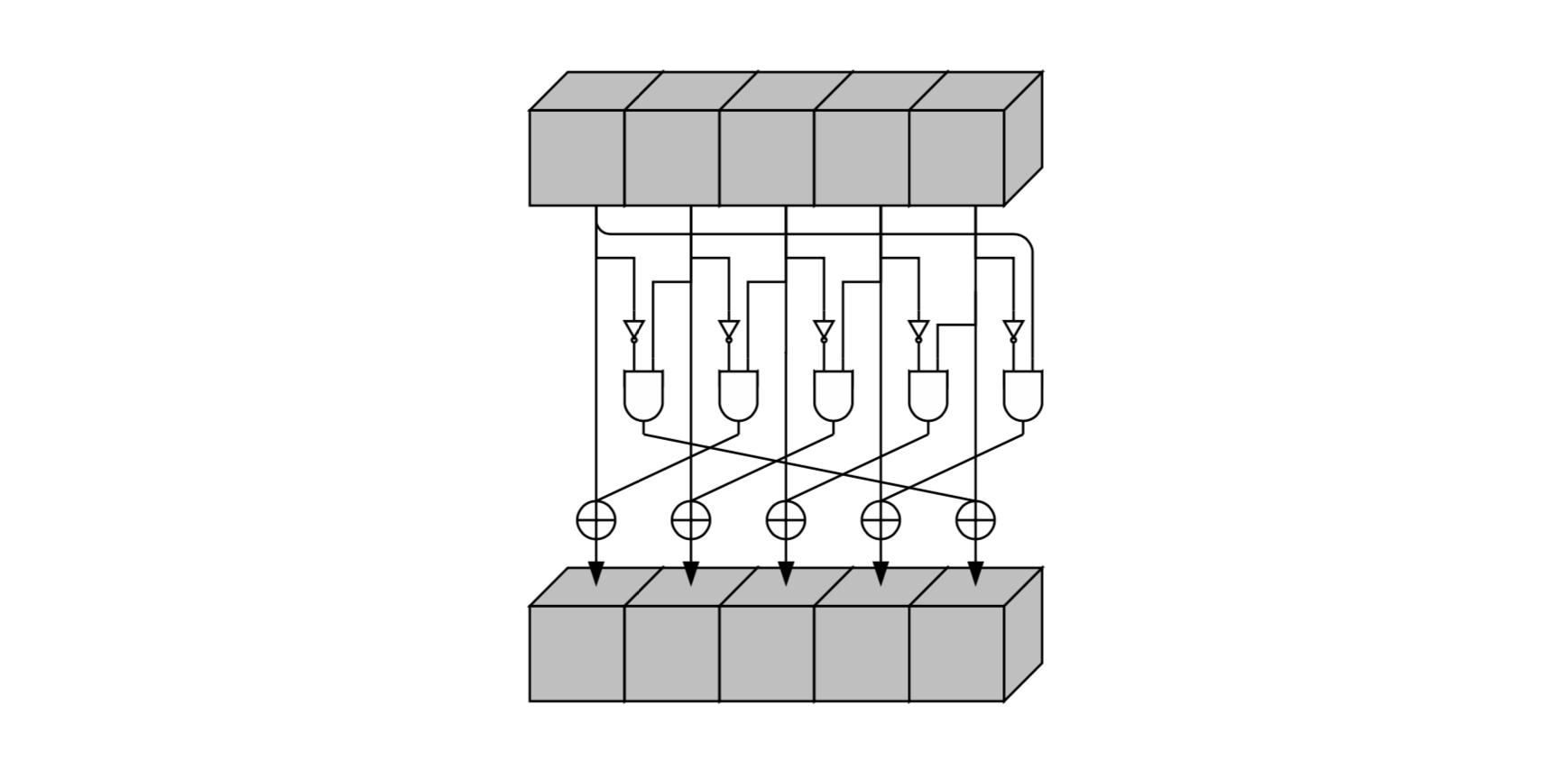
Шаг
Отображение состоит из сложения с раундовыми константами и направлено на нарушение симметрии. Без него все раунды были бы эквивалентными, что делало бы его подверженным атакам, использующим симметрию. По мере увеличения раундовые константы добавляют все больше и больше асимметрии.
Ниже приведена таблица раундовых констант для бит

Все шаги можно объединить вместе и тогда мы получим следующее:


Где константы являются циклическими сдвигами и задаются таблицей:
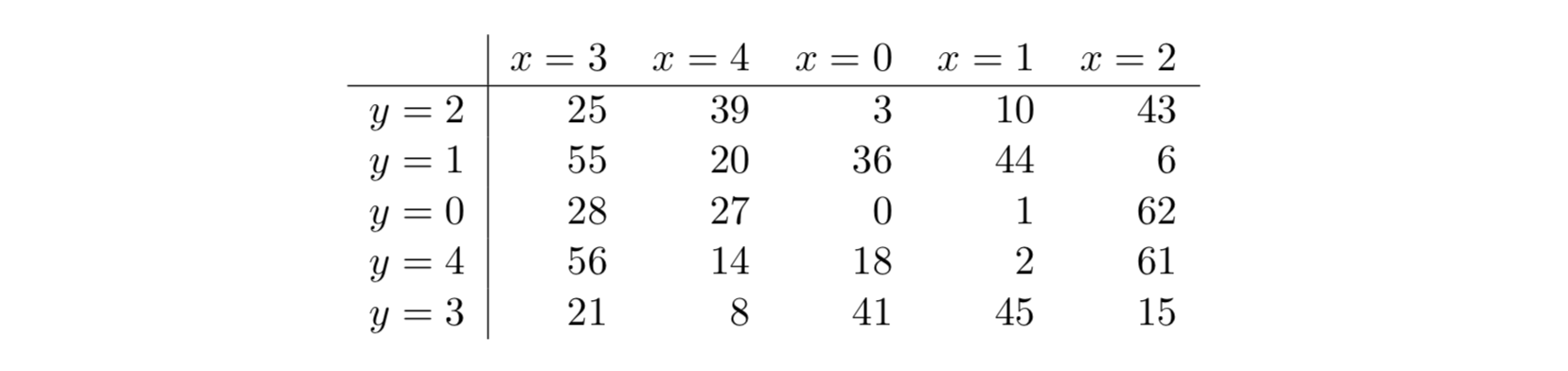
Итоги
В данной статье я постарался объяснить, что такое хеш-функция и зачем она нужна
Также в общих чертах мной был разобран принцип работы алгоритма SHA-3 Keccak, который является последним стандартизированным алгоритмом семейства Secure Hash Algorithm
Надеюсь, все было понятно и интересно
Всем спасибо за внимание!
Источник: habr.com