
Долгое время считалось, что динамический анализ программ является слишком тяжеловесным подходом к обнаружению программных дефектов, и полученные результаты не оправдывают затраченных усилий и ресурсов. Однако, две важные тенденции развития современной индустрии производства программного обеспечения позволяют по-новому взглянуть на эту проблему. С одной стороны, при постоянном увеличении объема и сложности ПО любые автоматические средства обнаружения ошибок и контроля качества могут оказаться полезными и востребованными. С другой – непрерывный рост производительности современных вычислительных систем позволяет эффективно решать все более сложные вычислительные задачи. Последние исследовательские работы в области динамического анализа такие, как SAGE, KLEE и Avalanche, демонстрируют, что несмотря на присущую этому подходу сложность, его использование оправдано, по крайней мере, для некоторого класса программ.
Динамический vs Статический анализ
- Возможен раздельный анализ отдельно взятых фрагментов программы (обычно отдельных функций или процедур), что дает достаточно эффективный способ борьбы с нелинейным ростом сложности анализа.
- Возможны ложные срабатывания, обусловленные либо тем, что при построении абстрактной модели некоторые детали игнорируются, либо тем, что анализ модели не является исчерпывающим.
- При обнаружении дефекта возникают, во-первых, проблема проверки истинности обнаруженного дефекта (false positive) и, во-вторых, проблема воспроизведения найденного дефекта при запуске программы на определенных входных данных.
- Для запуска программы требуются некоторые входные данные.
- Динамический анализ обнаруживает дефекты только на трассе, определяемой конкретными входными данными; дефекты, находящиеся в других частях программы, не будут обнаружены.
- В большинстве реализаций появление ложных срабатываний исключено, так как обнаружение ошибки происходит в момент ее возникновения в программе; таким образом, обнаруженная ошибка является не предсказанием, сделанным на основе анализа модели программы, а констатацией факта ее возникновения.
Применение
Автоматическое тестирование в первую очередь предназначено для программ, для которых работоспособность и безопасность при любых входных данных являются наиважнейшими приоритетами: веб-сервер, клиент/сервер SSH, sandboxing, сетевые протоколы.
Владимир Иванов — Динамическая (JIT) компиляция в JVM
Fuzz testing (фаззинг)
Фаззинг – методика тестирования, при которой на вход программы подаются невалидные, непредусмотренные или случайные данные.
Основная идея такого подхода состоит в том, чтобы случайным образом “мутировать”, т.е. изменять ожидаемые программой входные данные в произвольных местах. Все фаззеры работают примерно одинаковым образом, позволяя задавать некоторые ограничения на мутирование входных данных определенными байтами или последовательностью байтов. В качестве примера можно упомянуть:zzuf (linux), minifuzz (Windows), filefuzz (Windows). Фаззеры протоколов: PROTOS(WAP, HTTP-reply, LDAP, SNMP, SIP) (Java), SPIKE (linux) . Фреймворки фаззеров: Sulley (фреймворк для создания сложных структур данных).
Вербальные и числовые тесты — это Просто! Как пройти онлайн тест и выбрать ответы? Как подготовиться
Fuzz testing – предтеча автоматического тестирования, метод “грубой силы”. Из преимуществ данного подхода выделяется только его простота. Очевидным же недостатком является то, что фаззер ничего не знает о внутреннем устройстве программы и, в конечном итоге, для полного покрытия кода вынужден перебирать астрономическое количество вариантов (как нетрудно догадаться, полный перебор растет экспоненциально от размера входных данных O(c^n),c>1).
Фаззеры нового поколения (обзор)
Логическим, но не таким простым продолжением идеи автоматического тестирования стало появление подходов и программ, позволяющих накладывать ограничения на мутируемые входные данные с учетом специфики исследуемой программы.
Отслеживание помеченных данных в программе
Вводится понятие символических или помеченных (tainted) данных – данных, полученных программой из внешнего источника (стандартный поток ввода, файлы, переменные окружения и т. д.). Распространенным решением этой задачи является перехват набора системных вызовов: open, close, read, write, lseek (Avalanche,KLEE).
Инструментация кода
Код исследуемой программы приводится к виду, удобному для анализа. Например, используется внутреннее независимое от аппаратной платформы представление valgrind (Avalanche) или анализируется удобный для разбора сам по себе llvm-байткод программы(KLEE).
Инструментированный код позволяет легко находить потенциально опасные инструкции (например, деление на ноль или разыменование нулевого указателя) и их операнды, а также инструкции ветвления, зависящие от помеченных данных. Анализируя инструкции, инструмент составляет логические условия на помеченные данные и передает запрос на выполнимость “решателю” булевских формул (SAT Solver).
Решение булевских ограничений
SAT Solvers – решают задачи выполнимости булевых формул. Отвечают на вопрос: всегда ли выполнена заданная формула, и если не всегда, то выдается набор значений, на котором она ложна. Результаты работы подобных решателей используется широким набором анализирующих программ, от theorem provers до анализаторов генетического кода в биоинформатике. Подобные программы интересны сами по себе и требуют отдельного рассмотрения. Примеры: STP, MiniSAT.
Моделирование окружения
Кроме перехвата системных вызовов, для автоматической генерации условий для “решателя” булевских формул, анализаторам необходимо формализовать задачу. Входной файл, набор регистров и адресное пространство (память) программы представляются c помощью массивов булевского “решателя”.
Перебор путей в программе
Получив ответ от “решателя”, инструмент получает условие на входные данные для инвертирования исследуемого условного перехода или выясняет, что оно всегда истинно или ложно. Каждый вариант условия создает новый независимый путь в программе, и программе приходится рассматривать каждый путь и условия для его выполнения независимо, т.е. пути “форкаются” на каждой инструкции ветвления, зависящей от входных данных.
Новые входные данные могут открыть ранее не открытые базовые блоки исследуемой программы и так далее. Для исчерпывающего тестирования необходим полный перебор всех возможных путей в программе. Так как скорость роста количества путей хоть и значительно снизилась по сравнению с методом грубой силы (~O(2^n), где n – количество условных переходов, зависящих от входных данных), но все еще остается значительной. Анализаторы вынуждены использовать различные эвристики для приоритезации анализа некоторых путей. В частности, различают выбор пути, покрывающего наибольшее количество непокрытых (новых) базовых блоков (Avalanche, KLEE) и выбор случайного пути (KLEE).
Avalanche
Avalanche – инструмент обнаружения программных дефектов при помощи динамического анализа. Avalanche использует возможности динамической инструментации программы, предоставляемые Valgrind, для сбора и анализа трассы выполнения программы. Результатом такого анализа становится либо набор входных данных, на которых в программе возникает ошибка, либо набор новых тестовых данных, позволяющий обойти ранее не выполнявшиеся и, соответственно, еще не проверенные фрагменты программы. Таким образом, имея единственный набор тестовых данных, Avalanche реализует итеративный динамический анализ, при котором программа многократно выполняется на различных, автоматически генерированных тестовых данных, при этом каждый новый запуск увеличивает покрытие кода программы такими тестами.
Общая схема работы
Инструмент Avalanche состоит из 4 основных компонент: двух модулей расширения (плагинов) Valgrind – Tracegrind и Covgrind, инструмента проверки выполнимости ограничений STP и управляющего модуля.
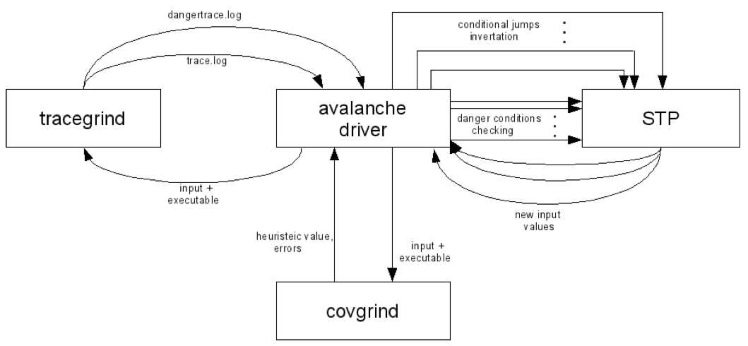
Tracegrind динамически отслеживает поток помеченных данных в анализируемой программе и собирает условия для обхода ее непройденных частей и для срабатывания опасных операций. Эти условия при помощи управляющего модуля передаются STP для исследования их выполнимости. Если какое-то из условий выполнимо, то STP определяет те значения всех входящих в условия переменных (в том числе и значения байтов входного файла), которые обращают условие в истину.
- В случае выполнимости условий для срабатывания опасных операций программа запускается управляющим модулем повторно (на этот раз без какой-либо инструментации) с соответствующим входным файлом для подтверждения найденной ошибки.
- Выполнимые условия для обхода непройденных частей программы определяют набор возможных входных файлов для новых запусков программы. Таким образом, после каждого запуска программы инструментом STP автоматически генерируется множество входных файлов для последующих запусков анализа.
- Далее встает задача выбора из этого множества наиболее “интересных” входных данных, т.е. в первую очередь должны обрабатываться входные данные, на которых наиболее вероятно возникновение ошибки. Для решения этой задачи используется эвристическая метрика – количество ранее не обойденных базовых блоков в программе (базовый блок здесь понимается в том смысле, как его определяет фреймворк Valgrind). Для измерения значения эвристики используется компонент Covgrind, в функции которого входит также фиксация возможных ошибок выполнения. Covgrind гораздо более легковесный модуль, нежели Tracegrind, поэтому возможно сравнительно быстрое измерение значения эвристики для всех полученных ранее входных файлов и выбор входного файла с ее наибольшим значением.
Ограничения
- один помеченный входной файл или сокет
- анализ ошибок ограничен разыменованием нулевого указателя и делением на ноль.
Результаты
- qtdump (libquicktime-1.1.3). Три дефекта связаны с разыменованием нулевого указателя, один – с наличием бесконечного цикла, еще в одном случае имеет место обращение по некорректному адресу (ошибка сегментации). Часть дефектов исправлена разработчиком.
- flvdumper (gnash-0.8.6). Непосредственное возникновение дефекта связано с появлением исключительной ситуации в используемой приложением библиотеке boost (один из внутренних указателей библиотеки boost оказывается равен нулю). Поскольку само приложение не перехватывает возникшее исключение, выполнение программы завершается с сигналом SIGABRT. Дефект исправлен разработчиком.
- cjpeg (libjpeg7). Приложение читает из файла нулевое значение и без соответствующей проверки использует его в качестве делителя, что приводит к возникновению исключения плавающей точки и завершению программы с сигналом SIGFPE. Дефект исправлен разработчиком.
- swfdump (swftools-0.9.0). Возникновение обоих дефектов связано с разыменованием нулевого указателя.
KLEE
- Вместо инструментации valgrind’а, которую использует Avalanche, KLEE анализурует программы в llvm-байткоде. Соответственно, это позволяет анализировать программу на любом языке программирования, для которого есть llvm-бэкэнд.
- Для решения задачи булевских ограничений KLEE так же использует STP.
- KLEE так же перехватывает около 50 системных вызовов, позволяя выполняться множеству виртуальных процессов параллельно, не мешая друг другу.
- Оптимизация и кэширование запросов к STP.
unsigned mod_opt ( unsigned x, unsigned y ) <
if ( ( y ( y− 1 ) ;
else
return x % y ;
>
unsigned mod ( unsigned x, unsigned y ) <
return x % y ;
>
int main ( ) <
unsigned x,y ;
make symbolic (
make symbolic (
assert ( mod ( x,y ) == mod_opt ( x,y ) ) ;
return 0 ;
>
Запустив KLEE на данном примере, можно убедится в эквивалентности двух функций во всем диапазоне входных значений (y!=0). Решая задачу на невыполнение условия в ассерте, KLEE на основе перебора всех возможных путей приходит к выводу об эквивалентности двух функций на всем диапазоне значений.
Результаты
Для получения реальных результатов тестирования авторы проанализировали весь набор программ пакета coreutils 6.11. Средней процент покрытия кода составил 94%. Всего программа сгенерировала 3321 набор входных данных, позволяющих покрыть весь указанный процент кода. Так же было найдено 10 уникальных ошибок, которые были признаны разработчиками пакета как реальные дефекты в программах, что является очень хорошим достижением, так как этот набор программ разрабатывается более 20 лет и большинство ошибок было устранено.
Ограничения
- нет поддержки многопоточных приложений, символических данных с плавающей точкой (ограничение STP), ассемблерные вставки.
- тестируемое приложение должно быть собрано в llvm-байт код (так же как и его библиотеки!).
- для эффективного анализа нужно править код.
Предварительные выводы
Безусловно, динамический анализ найдет свою нишу среди инструментов помогающих отдельным программистам и командам программистов решать поставленную задачу, т.к. является эффективным способом нахождения ошибок в программах, а так же доказательством их отсутствия! В в некоторых случаях подобные инструменты просто жизненно необходимы (Mission critical software: RTOS, системы управления производством, авиационное программное обеспечение и так далее).
Источник: habr.com
Динамический анализ исходных текстов программ
Динамический анализ исходных текстов программ — совокупность методов контроля (несоответствия реализованных и декларированных в документации функциональных возможностей программного обеспечения, основанных на идентификации фактических маршрутов выполнения функциональных объектов с последующим сопоставлением маршрутам, построенным в процессе проведения статического анализа.
Требования
| Контроль выполнения функциональных объектов | — | + | + | = |
| Сопоставление фактических маршрутов выполнения функциональных объектов и маршрутов, построенных в процессе проведения статического анализа | — | + | + | = |
Источник: wikisec.ru
Зачем нужен динамический анализ кода, если есть статический?
Для проверки качества программного обеспечения приходится применять много разных инструментов. В частности, к ним относятся инструменты статического и динамического анализа. В данной статье мы попробуем разобраться, почему одной методологии, будь то статический или динамический анализ, может оказаться недостаточно для проведения комплексного анализа программ и почему лучше совместно использовать эти два подхода.

Наша команда много пишет о пользе статического анализа и о том, какую выгоду может принести его использование в вашем проекте. Мы любим искать ошибки в различных проектах с открытым исходным кодом с помощью нашего инструмента, тем самым популяризируя методологию статического анализа кода.
В свою очередь эта методология помогает улучшать качество программ, делает их более надёжными и уменьшает количество потенциальных уязвимостей. Наверное, каждый, кто непосредственно работает с кодом, получает внутреннее удовлетворение от исправления ошибок. Но даже в том случае, если вы не получаете выброс эндорфинов от того, что вам удалось найти (и исправить) очередной баг, то, скорее всего, вам нравится мысль о том, что у вас получилось сократить денежные затраты на разработку путём того, что статический анализатор помог более продуктивно использовать время программистов. Подробнее о том, какую пользу в денежном эквиваленте может принести использование инструмента статического анализа, можно узнать из данной статьи. Приблизительные расчёты показаны на примере использования анализатора PVS-Studio, но подобное можно проэкстраполировать и для других статических анализаторов, имеющихся на рынке.
Из написанного выше можно сделать вывод, что смысл статического анализа в том, чтобы как можно раньше находить ошибки в исходном коде программ, тем самым уменьшая денежные затраты на их исправление. Но для чего тогда нужен динамический анализ, и почему использование только одного из этих двух подходов может оказаться недостаточным? Давайте несколько формализуем понятия статического и динамического анализа и дадим им более чёткие определения, попутно стараясь ответить на поставленные выше вопросы.
Статический анализ кода — это процесс выявления ошибок и недочетов в исходном коде программ. Для его выполнения не нужно запускать программу, весь анализ будет выполнен на имеющейся кодовой базе. Самая ближайшая аналогия, которую можно провести со статическим анализом кода, это так называемый процесс code review, только автоматизированный (выполняемый программой-роботом).
К основным преимуществам статического анализа можно отнести:
- Обнаружение ошибок на ранних этапах разработки программного обеспечения. Это существенно снижает стоимость устранения дефектов в программе, так как чем раньше выявлена ошибка, тем легче и, как следствие, дешевле её исправить.
- Позволяет точно определять местонахождение потенциальной ошибки в исходном коде.
- Полное покрытие кода. Вне зависимости от того, как часто получают управление те или иные участки кода во время исполнения программы, весь исходный код будет полностью проанализирован.
- Простота использования. Для запуска статического анализа не нужно заранее подготавливать какие-либо наборы входных данных.
- С помощью статического анализа кода можно достаточно легко и быстро обнаруживать опечатки и последствия использования Copy-Paste.
К объективным недостаткам статического анализа кода относятся следующие факторы:
- Неизбежное появление так называемых ложно-позитивных срабатываний. Статический анализатор кода может указывать на те места, где на самом деле нет никаких ошибок. Разрешить подобную ситуацию и дать понять анализатору, что он дал ложное срабатывание, может только программист, тем самым потратив своё рабочее время.
- Статический анализ, как правило, слаб в диагностике утечек памяти и параллельных ошибок. Чтобы выявлять подобные ошибки, фактически необходимо виртуально выполнить часть программы. Это крайне сложно реализовать. Также подобные алгоритмы требуют очень много памяти и процессорного времени. Как правило, статические анализаторы ограничиваются диагностикой простых случаев. Более эффективным способом выявления утечек памяти и параллельных ошибок является использование инструментов динамического анализа.
Отметим, что использование статического анализа кода не ограничивается только выявлением ошибок в программе. Например, используя инструменты статического анализа, можно получать рекомендации по оформлению кода. Некоторые статические анализаторы позволяют проверять, соответствует ли исходный код принятому в компании стандарту оформления кода.
Имеется в виду контроль количества отступов в различных конструкциях, использование пробелов/символов табуляции и так далее. Помимо этого, статический анализ можно использовать для подсчёта метрик. Метрика программного обеспечения — это мера, позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций. Если вас интересует, каким ещё образом можно использовать статический анализатор кода, вы можете обратиться к этой статье.
Динамический анализ кода – это способ анализа программы непосредственно при её выполнении. Отсюда следует, что из исходного кода в обязательном порядке должен быть получен исполняемый файл, то есть нельзя таким способом проанализировать код, содержащий ошибки компиляции или сборки. Динамический анализ выполняется с помощью набора данных, которые подаются на вход исследуемой программе. Поэтому эффективность анализа напрямую зависит от качества и количества входных данных для тестирования. Именно от них зависит полнота покрытия кода, которая будет получена по результатам тестирования.
Используя динамическое тестирование, можно получить следующие метрики и предупреждения:
- Используемые ресурсы: время выполнения программы в целом или ее отдельных модулей, количество внешних запросов (например, к базе данных), количество используемой оперативной памяти и других ресурсов.
- Степень покрытия кода тестами и другие метрики программы.
- Программные ошибки: деление на ноль, разыменование нулевого указателя, утечки памяти, «состояние гонки».
- Детектировать некоторые уязвимости.
К основным преимуществам динамического анализа кода относят:
- Возможность проводить анализ программы без необходимости доступа к её исходному коду. Здесь стоит сделать оговорку, так как программы для динамического анализа различают по способу взаимодействия с проверяемой программой (подробнее с этим можно ознакомиться в этой статье). Например, распространён способ проведения динамического анализа путём предварительного инструментирования исходного кода, то есть добавления специального кода в исходный текст приложения для обнаружения ошибок. В этом случае доступ к коду проверяемой программы будет необходим.
- Возможность обнаружения сложных ошибок, связанных с работой с памятью: выход за границу массива, обнаружение утечек памяти.
- Возможность проводить анализ многопоточного кода непосредственно в момент выполнения программы, тем самым обнаруживать потенциальные проблемы, связанные с доступом к разделяемым ресурсами, возможные deadlock ситуации.
- В большинстве реализаций появление ложных срабатываний исключено, так как обнаружение ошибки происходит в момент ее возникновения в программе; таким образом, обнаруженная ошибка является не предсказанием, сделанным на основе анализа модели программы, а констатацией факта ее возникновения.
Перечислим недостатки, которые присущи динамическому анализу кода:
- Нельзя гарантировать полного покрытия кода, т.е., скорее всего, процент кода программы, который был проанализирован в процессе динамического тестирования, не будет равен ста процентам.
- Почти не выявляются ошибки логического типа. Например, с точки зрения динамического анализатора, всегда истинное условие не является ошибкой, так как такая некорректная проверка просто исчезает ещё на этапе компиляции программы.
- Тяжело локализовать место с ошибкой в исходном коде.
- Более высокая сложность использования по сравнению со статическим анализом, так как для достижения большей эффективности динамического анализа тестируемой программе требуется подача достаточного количества входных данных, чтобы получить более полное покрытие кода.
Динамическое тестирование наиболее важно в тех областях, где главным критерием является надежность программы, время отклика или потребляемые ресурсы. Это может быть, например, система реального времени, управляющая ответственным участком производства, или сервер базы данных. В таких областях любая допущенная ошибка может оказаться критической.
Возвращаясь к вопросу о том, почему использование только одного варианта анализа может оказаться недостаточным, давайте приведём пару довольно тривиальных примеров ошибок в коде, с которыми справляется один подход к анализу программ, но который не по зубам другому, и наоборот.
Это пример кода из проекта Clang:
MapTy PerPtrTopDown; MapTy PerPtrBottomUp; void clearBottomUpPointers() < PerPtrTopDown.clear(); >void clearTopDownPointers()
Здесь статический анализ укажет на то, что тела двух функций абсолютно идентичны. Конечно, нельзя с абсолютной уверенностью говорить, что если тела функций одинаковы, то это ошибка.
Однако существует вероятность, что это был результат копипаста, совмещённый с невнимательностью разработчика, что уже и приведёт к непредвиденному поведению программы. В данном случае, внутри метода clearBottomUpPointers должен был быть осуществлён вызов PerPtrBottomUp.clear. В приведённом примере динамический анализ кода не сможет увидеть ничего подозрительного, ведь с его точки зрения это абсолютно рабочий код.
Другой пример. Представим, что имеется следующий код:
size_t index = 0; . if (scanf(«%zu», небезопасных входных данных» (tainted data) и отслеживать, может ли полученное значение привести к ошибке.
Из приведённого выше примера кода анализатор может понять, что переменная index получила своё значение из проаннотированной функции scanf. Основываясь на том, что значение переменной index может получиться большим чем размер массива arr, анализатор выдаст предупреждение. Оно будет сообщать о том, что перед обращением к значению массива arr по индексу index, эту переменную следует предварительно проверить. Например, в приведённом ниже коде перед обращением к значению массива по индексу, производится соответствующая проверка переменной index. Анализатор это понимает и не выдаёт предупреждение.
size_t index = 0; . if (scanf(«%zu», https://pvs-studio.ru/ru/blog/posts/0643/» target=»_blank»]pvs-studio.ru[/mask_link]