
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Кучин И. Ю.
В статье исследуются автоматизированные методы анализа исходного кода программных продуктов с открытым кодом , предлагается оригинальный подход, использующий аппарат теории графов .
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Кучин И. Ю.
Подход к определению достижимости программных дефектов, обнаруженных методом статического анализа, при помощи динамического символьного исполнения
Современные технологии статического и динамического анализа программного обеспечения
Статический анализатор Svace для поиска дефектов в исходном коде программ
Технологии статического и динамического анализа уязвимостей программного обеспечения
Анализ сущностей программ на языках Си/Си++ и связей между ними для понимания программ
i Не можете найти то, что вам нужно?
Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Текст научной работы на тему «Обзор существующих методов анализа программного кода»
Аспирант кафедры «Информационная безопасность» ФГОУ ВПО АГТУ ОБЗОР СУЩЕСТВУЮЩИХ МЕТОДОВ АНАЛИЗА ПРОГРАММНОГО КОДА
Подробный анализ программы Lime, LimeAcademy
В статье исследуются автоматизированные методы анализа исходного кода программных продуктов с открытым кодом, предлагается оригинальный подход, использующий аппарат теории графов.
Ключевые слова: открытый код, теория графов, аудит программного обеспечения Keywords: open source, graph Theory, auditing software
В последние несколько лет популярность программ с открытым кодом возросла, и теперь мы располагаем огромным объемом исходных текстов, которые можно свободно читать и анализировать. Известный разработчик целого ряда программ с открытым кодом, Диомидис Спинеллис[1], утверждает, что от 40 до 70% трудозатрат на разработку программных систем расходуется уже после того, как эта система впервые написана и запущена. Эти трудозатраты непременно включают в себя чтение, понимание и внесение изменений в исходный код.
Код «плохого качества» можно обнаружить по следующим характерным признакам:
• неравномерный, неоднородный стиль написания программы;
• слишком сложная, «нечитабельная» структура кода без всякой на то причины;
• очевидные логические ошибки или несоответствия;
• злоупотребление плохо переносимыми конструкциями;
• отсутствие достаточной поддержки в виде документации и т.п.
В наше время вопросы безопасности и отказоустойчивости программных продуктов выходят на первый план. Одни утверждают, что свободно распространяемые программы по своей природе более защищены, чем системы с недоступными исходными текстами, другие считают, что это не так. Ни одну из этих точек зрения нельзя назвать единственно правильной. Тем не менее, открытые коды дают специалисту по безопасности немалые преимущества, поскольку позволяют использовать методы, как правило, неприменимые к коммерческим программным продуктам. Если у пользователей нет доступа к исходным текстам, они вынуждены довольствоваться тем уровнем безопасности, который обеспечил производитель.
Григорий Тамар: Анализ возможной войны с Ливаном, интервью для Влада Голлера «Первое радио»
Аудит программного обеспечения
Наименьший вред приносит то уязвимое место в программе, которое никогда не проявляется. Так что оптимально было бы иметь возможность предотвратить уязвимые места, проводя аудит программного обеспечения. Для этого идеально подходит открытый код.
Недостаток такого подхода состоит в том, что аудит исходного текста, или даже поиск наиболее общих дефектов организации защиты в коде, — вещь очень сложная и требующая больших затрат времени. Отсюда следует, что гарантировать корректность данного фрагмента кода, крайне важного для обеспечения защиты, и найти для этого людей, достаточно компетентных для того, что обнаружить уязвимые места, одинаково трудно.
Вторым важным недостатком данного метода является крайне затруднительная возможность его использования в случае больших программных продуктов, таких, например, как ядро операционной системы. В ядре ОС Linux (v.2.6.23.11) содержится более 2,5 миллионов строк кода, в ядре Windows XP — в два с лишним раза больше. В одном из исследований надежности программного обеспечения[4] показано, что в программах имеется от шести до шестнадцати ошибок на 1000 строк исполняемого кода; в другом исследовании[2] насчитывается от двух до 75 ошибок на 1000 строк исполняемого кода в зависимости от размера модуля. При таких оценках ядро Linux содержит около 15000 ошибок, а Windows XP — больше 30000 ошибок. Еще хуже то, что около 70% кода операционных систем занимает код драйверов устройств, в которых ошибки встречаются в 3-7 раз чаще, чем в обычном коде. «Ручное» исправление ошибок с учетом размеров исходных кодов невозможно; более того, при исправлении ошибок часто привносятся новые.
Статические анализаторы проверяют исходные тексты и сообщают о подозрительных строках кода, которые могут оказаться уязвимыми. В то же время, статические анализаторы могут посчитать подозрительными совершенно безопасные фрагменты кода. Излишняя подозрительность приводит к увеличению соотношения ложных/истинных тревог.
В случае слишком частого появления ложных тревог, разработчики начинают относиться к анализатору с недоверием и зачастую вообще отказываются от него. Так что избирательность для анализатора исходных текстов абсолютно необходима. С другой стороны, анализатор должен обладать достаточно высокой восприимчивостью: пропуская отдельные «патологии», на поиск которых он не рассчитан (не распознавание ошибки), он внушает разработчикам ложное чувство уверенности. Таким образом, анализатор исходных текстов должен быть точным (т.е. восприимчивым и избирательным).
К сожалению, в языках без строгого контроля типов, как правило, применяемых в разработке систем с открытым кодом (Си, Perl и т.д.), обнаружить дефекты защиты практически невозможно, и во многих случаях это требует слишком больших по сравнению с размером исходного текста ресурсов. Примером таких программ могут служить разработки ученых университета Беркли BOON, CQual, MOPS.
Итак, статические анализаторы исходных текстов используют разные эвристики, но при этом не способны дать абсолютно надежный результат. Такие инструментальные средства выступают лишь в качестве вспомогательного инструментария для специалиста, проверяющего корректность исходных текстов программ.
Анализ исходного кода методами теории графов
Аудит программного обеспечения и применение статических анализаторов представляют собой методы анализа исходного кода, которые мало применимы для больших систем (например, таких, как ядра операционных систем). Непосредственно чтение исходного кода является обязательным для глубокого понимания функционирования ядра и анализа его на предмет безопасности, однако, в случае ядер, содержащих миллионы строк исходного кода, нужно знать, что и, самое главное, где читать. Взгляд на ядро «сверху» мог бы помочь исследователям выявить именно ту часть ядра и даже тот фрагмент кода, который следует тщательно изучить, используя методы анализа, описанные ранее. В данном случае граф вызовов функций мог бы помочь выделить из многомиллионного кода взаимозависимые компоненты.
Одной из главных задач структурного анализа является построение наглядной формальной модели, отображающей существующую систему отношений элементов как между собой, так и с внешней средой. Для решения данной задачи можно применить
утилиту cflow[3] для простого и быстрого построения графа вызовов программ с открытым кодом на языке Си.
Утилита cflow предназначена для построения графа вызовов C-программ, анализирует набор C-, YACC-, LEX-, а также ассемблерных и объектных файлов и пытается построить граф внешних ссылок. По графу можно выявить, какие функции являются наиболее загруженными, определить связность, наличие циклов и другие параметры, на основании которых можно делать вывод об уязвимости отдельных элементов. Например, наличие на графе петли говорит о присутствии рекурсивной функции в исходном коде, являющейся потенциальным источником ошибок.
Для графического представления графа можно использовать утилиту «DOT», из пакета graphviz, разработанного специалистами лаборатории AT
2. К. Кован — Безопасность систем с открытым кодом // Открытые системы. — 2003. — №78.
Источник: cyberleninka.ru
О статическом анализе начистоту
Последнее время все чаще говорят о статическом анализе как одном из важных средств обеспечения качества разрабатываемых программных продуктов, особенно с точки зрения безопасности. Статический анализ позволяет находить уязвимости и другие ошибки, его можно использовать в процессе разработки, интегрируя в настроенные процессы.
Однако в связи с его применением возникает много вопросов. Чем отличаются платные и бесплатные инструменты? Почему недостаточно использовать линтер? В конце концов, при чем тут статистика? Попробуем разобраться.

Сразу ответим на последний вопрос – статистика ни при чем, хотя статический анализ часто по ошибке называют статистическим. Анализ статический, так как при сканировании не происходит запуск приложения.
Для начала разберемся, что мы хотим искать в программном коде. Статический анализ чаще всего применяют для поиска уязвимостей – участков кода, наличие которых может привести к нарушению конфиденциальности, целостности или доступности информационной системы. Однако те же технологии можно применять для поиска и других ошибок или особенностей кода.
Оговоримся, что в общем виде задача статического анализа алгоритмически неразрешима (например, по теореме Райса). Поэтому приходится либо ограничивать условия задачи, либо допускать неточность в результатах (пропускать уязвимости, давать ложные срабатывания). Оказывается, что на реальных программах рабочим оказывается второй вариант.
Существует множество платных и бесплатных инструментов, которые заявляют поиск уязвимостей в приложениях, написанных на разных языках программирования. Рассмотрим, как обычно устроен статический анализатор. Дальше речь пойдет именно о ядре анализатора, об алгоритмах. Конечно, инструменты могут отличаться по дружелюбности интерфейса, по набору функциональности, по набору плагинов к разным системам и удобству использования API. Наверное, это тема для отдельной статьи.
Промежуточное представление
В схеме работы статического анализатора можно выделить три основных шага.
- Построение промежуточного представления (промежуточное представление также называют внутренним представлением или моделью кода).
- Применение алгоритмов статического анализа, в результате работы которых модель кода дополняется новой информацией.
- Применение правил поиска уязвимостей к дополненной модели кода.

Аналогично компиляторам, лексический и синтаксический анализ применяются для построения внутреннего представления, чаще всего — дерева разбора (AST, Abstract Syntax Tree). Лексический анализ разбивает текст программы на минимальные смысловые элементы, на выходе получая поток лексем. Синтаксический анализ проверяет, что поток лексем соответствует грамматике языка программирования, то есть полученный поток лексем является верным с точки зрения языка. В результате синтаксического анализа происходит построение дерева разбора – структуры, которая моделирует исходный текст программы. Далее применяется семантический анализ, он проверяет выполнение более сложных условий, например, соответствие типов данных в инструкциях присваивания.
Дерево разбора можно использовать как внутреннее представление. Также из дерева разбора можно получить другие модели. Например, можно перевести его в трехадресный код, по которому, в свою очередь, строится граф потока управления (CFG). Обычно CFG является основной моделью для алгоритмов статического анализа.

При бинарном анализе (статическом анализе двоичного или исполняемого кода) также строится модель, но здесь уже используются практики обратной разработки: декомпиляции, деобфускации, обратной трансляции. В результате можно получить те же модели, что и из исходного кода, в том числе и исходный код (с помощью полной декомпиляции). Иногда сам бинарный код может служить промежуточным представлением.
Теоретически, чем ближе модель к исходному коду, тем хуже будет качество анализа. На самом исходном коде можно делать разве что поиск по регулярным выражениям, что не позволит найти хоть сколько-нибудь сложную уязвимость.
Анализ потока данных
Одним из основных алгоритмов статического анализа является анализ потока данных. Задача такого анализа — определить в каждой точке программы некоторую информацию о данных, которыми оперирует код. Информация может быть разная, например, тип данных или значение. В зависимости от того, какую информацию нужно определить, можно сформулировать задачу анализа потока данных.

Например, если необходимо определить, является ли выражение константой, а также значение этой константы, то решается задача распространения констант (constant propagation). Если необходимо определить тип переменной, то можно говорить о задаче распространения типов (type propagation). Если необходимо понять, какие переменные могут указывать на определенную область памяти (хранить одни и те же данные), то речь идет о задаче анализа синонимов (alias analysis). Существует множество других задач анализа потока данных, которые могут использоваться в статическом анализаторе. Как и этапы построения модели кода, данные задачи также используются в компиляторах.
В теории построения компиляторов описаны решения задачи внутрипроцедурного анализа потока данных (отследить данные необходимо в рамках одной процедуры/функции/метода). Решения опираются на теорию алгебраических решеток и другие элементы математических теорий. Решить задачу анализа потока данных можно за полиномиальное время, то есть за приемлемое для вычислительных машин время, если условия задачи удовлетворяют условиям теоремы о разрешимости, что на практике происходит далеко не всегда.
Расскажем подробнее про решение задачи внутрипроцедурного анализа потока данных. Для постановки конкретной задачи, помимо определения искомой информации, нужно определить правила изменения этой информации при прохождении данных по инструкциям в CFG. Напомним, что узлами в CFG являются базовые блоки – наборы инструкций, выполнение которых происходит всегда последовательно, а дугами обозначается возможная передача управления между базовыми блоками.
Для каждой инструкции определяются множества:
- (информация, порождаемая инструкцией ),
- (информация, уничтожаемая инструкцией ),
- (информация в точке перед инструкцией ),
- (информация в точке после инструкции ).
Второе соотношение формулирует правила, по которым информация «объединяется» в точках слияния дуг CFG ( – предшественники в CFG). Может использоваться операция объединения, пересечения и некоторые другие.
Искомая информация (множество значений введенных выше функций) формализуется как алгебраическая решетка. Функции и рассматриваются как монотонные отображения на решётках (функции потока). Для уравнений потока данных решением является неподвижная точка этих отображений.
Алгоритмы решения задач анализа потока данных ищут максимальные неподвижные точки. Существует несколько подходов к решению: итеративные алгоритмы, анализ сильно связных компонент, T1-T2 анализ, интервальный анализ, структурный анализ и так далее. Существуют теоремы о корректности указанных алгоритмов, они определяют область их применимости на реальных задачах. Повторюсь, условия теорем могут не выполняться, что приводит к усложнению алгоритмов и неточности результатов.
Межпроцедурный анализ
На практике необходимо решать задачи межпроцедурного анализа потока данных, так как редко уязвимость будет полностью локализовываться в одной функции. Существует несколько общих алгоритмов.
Встраивание (inline) функций. В точке вызова функции мы осуществляем встраивание вызываемой функции, тем самым сводим задачу межпроцедурного анализа к задаче внутрипроцедурного анализа. Такой метод легко реализуем, однако на практике при его применении быстро достигается комбинаторный взрыв.
Построение общего графа потока управления программы, в котором вызовы функций заменены на переходы по адресу начала вызываемой функции, а инструкции возврата заменены на переходы на все инструкции, следующие после всех инструкций вызова данной функции. Такой подход добавляет большое количество нереализуемых путей выполнения, что сильно уменьшает точность анализа.
Алгоритм, аналогичный предыдущему, но при переходе на функцию происходит сохранение контекста – например, стекового фрейма. Таким образом решается проблема создания нереализуемых путей. Однако алгоритм применим при ограниченной глубине вызовов.
Построение информации о функциях (function summary). Наиболее применимый алгоритм межпроцедурного анализа. Он основан на построении summary для каждой функции: правил, по которым преобразуется информация о данных при применении данной функции в зависимости от различных значений входных аргументов. Готовые summary используются при внутрипроцедурном анализе функций.
Отдельной сложностью здесь является определение порядка обхода функций, так как при внутрипроцедурном анализе для всех вызываемых функций уже должны быть построены summary. Обычно создаются специальные итеративные алгоритмы обхода графа вызовов (call graph).
Межпроцедурный анализ потока данных является экспоненциальной по сложности задачей, из-за чего анализатору необходимо проводить ряд оптимизаций и допущений (невозможно найти точное решение за адекватное для вычислительных мощностей время). Обычно при разработке анализатора необходимо искать компромисс между объемом потребляемых ресурсов, временем анализа, количеством ложных срабатываний и найденных уязвимостей. Поэтому статический анализатор может долго работать, потреблять много ресурсов и давать ложные срабатывания. Однако без этого невозможно находить важнейшие уязвимости.
Именно в этом моменте серьезные статические анализаторы отличаются от множества открытых инструментов, которые, в том числе, могут себя позиционировать в поиске уязвимостей. Быстрые проверки за линейное время хороши, когда результат нужно получить оперативно, например, в процессе компиляции. Однако таким подходом нельзя найти наиболее критичные уязвимости – например, связанные с внедрением данных.
Taint-анализ
Отдельно стоит остановиться на одной из задач анализа потока данных — taint-анализе. Taint-анализ позволяет распространить по программе флаги. Данная задача является ключевой для информационной безопасности, так как именно с помощью нее обнаруживаются уязвимости, связанные с внедрением данных (внедрения в SQL, межсайтовый скриптинг, открытые перенаправления, подделка файлового пути и так далее), а также с утечкой конфиденциальных данных (запись пароля в журналы событий, небезопасная передача данных).
Попробуем смоделировать задачу. Пусть мы хотим отследить n флагов – . Множеством информации здесь будет множество подмножеств , так как для каждой переменной в каждой точке программы мы хотим определить ее флаги.
Далее мы должны определить функции потока. В данном случае функции потока могут определяться следующими соображениями.
- Задано множество правил, в которых определены конструкции, приводящие к появлению или изменению набора флагов.
- Операция присваивания перебрасывает флаги из правой части в левую.
- Любая неизвестная для множеств правил операция объединяет флаги со всех операндов и итоговое множество флагов добавляется к результатам операции.
Наконец, нужно определить правила слияния информации в точках соединения дуг CFG. Слияние определяется по правилу объединения, то есть если из разных базовых блоков пришли разные наборы флагов для одной переменной, то при слиянии они объединяются. В том числе отсюда появляются ложные срабатывания: алгоритм не гарантирует, что путь в CFG, на котором появился флаг, может быть исполнен.
Например, необходимо обнаруживать уязвимости типа «Внедрение в SQL» (SQL Injection). Такая уязвимость возникает, когда непроверенные данные от пользователя попадают в методы работы с базой данных. Необходимо определить, что данные поступили от пользователя, и добавить таким данным флаг taint. Обычно в базе правил анализатора задаются правила постановки флага taint. Например, поставить флаг возвращаемому значению метода getParameter() класса Request.
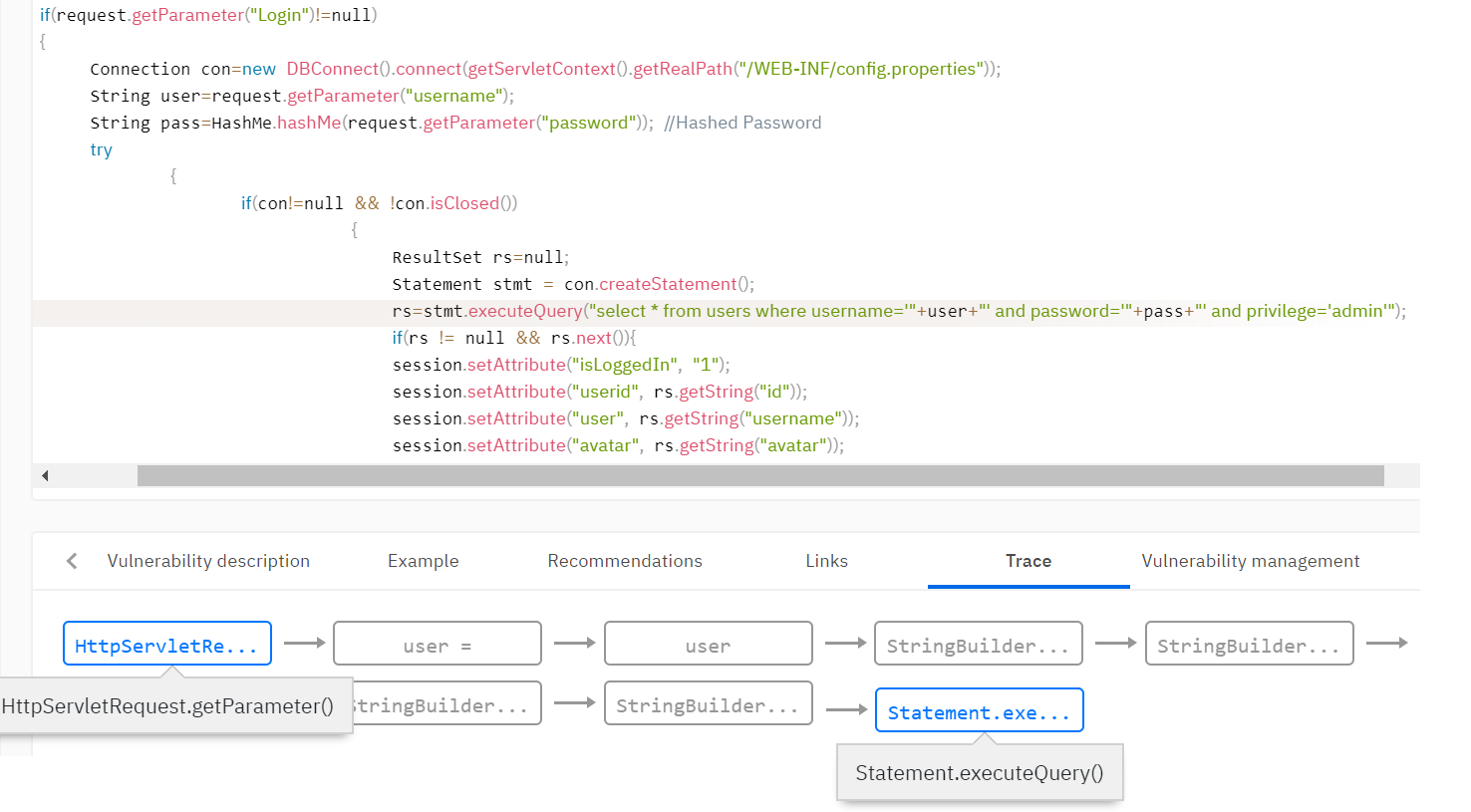
Далее необходимо распространить флаг по всей анализируемой программе с помощью taint-анализа, учитывая, что данные могут быть валидированы и флаг может исчезнуть на одном из путей исполнения. В анализаторе задается множество функций, которые снимают флаги. Например, функция валидации данных от html-тегов может снимать флаг для уязвимости типа «Межсайтовый скриптинг» (XSS). Или функция привязки переменной к SQL-выражению снимает флаг о внедрении в SQL.
Правила поиска уязвимостей
В результате применения указанных выше алгоритмов промежуточное представление дополняется информацией, необходимой для поиска уязвимостей. Например, в модели кода появляется информация о том, каким переменным принадлежат определенные флаги, какие данные являются константными. Правила поиска уязвимостей формулируются в терминах модели кода. Правила описывают, какие признаки в итоговом промежуточном представлении могут говорить о наличии уязвимости.
Например, можно применить правило поиска уязвимости, которое будет определять вызов метода с параметром, у которого есть флаг taint. Возвращаясь к примеру SQL-инъекции, мы проверим, что переменные с флагом taint не попадают в функции запроса к базе данных.
Получается, важной частью статического анализатора, помимо качества алгоритмов, является конфигурация и база правил: описание, какие конструкции в коде порождают флаги или другую информацию, какие конструкции валидируют такие данные, и для каких конструкций критично использование таких данных.
Другие подходы
Помимо анализа потока данных существуют и другие подходы. Одним из известных является символьное выполнение или абстрактная интерпретация. В этих подходах происходит выполнение программы на абстрактных доменах, вычисление и распространение ограничений по данным в программе. С помощью такого подхода можно не просто находить уязвимость, но и вычислить условия на входные данные, при которых уязвимость является эксплуатируемой. Однако у такого подхода есть и серьезные минусы – при стандартных решениях на реальных программах алгоритмы экспоненциально взрываются, а оптимизации приводят к серьезным потерям в качестве анализа.
Выводы
Под конец, думаю, стоит подвести итог, сказав о плюсах и минусах статического анализа. Логично, что сравнивать будем с динамическим анализом, в котором поиск уязвимостей происходит при выполнении программы.

Безусловным преимуществом статического анализа является полное покрытие анализируемого кода. Также к плюсам статического анализа можно отнести то, что для его запуска нет необходимости выполнять приложение в боевой среде. Статический анализ можно внедрять на самых ранних стадиях разработки, минимизируя стоимость найденных уязвимостей.
Минусами статического анализа является неизбежное наличие ложных срабатываний, потребление ресурсов и длительное время сканирований на больших объемах кода. Однако, эти минусы неизбежны, исходя из специфики алгоритмов. Как мы увидели, быстрый анализатор никогда не найдет реальную уязвимость типа SQL-инъекции и подобных.
Об остальных сложностях использования инструментов статического анализа, которые, как оказывается, вполне можно преодолевать, мы писали в другой статье.
- sast
- статический анализ кода
- поиск уязвимостей
- анализ потока данных
- Блог компании Ростелеком-Солар
- Информационная безопасность
- Тестирование IT-систем
- Совершенный код
- Тестирование мобильных приложений
Источник: habr.com
Что такое анализ состава программного обеспечения (SCA) и с чем его едят?

Анализ состава программного обеспечения (SCA) – техника, используемая для автоматического поиска и контроля программного обеспечения с открытым исходным кодом (OSS). Она крайне востребована, так как большая часть компаний использует ПО с открытым исходным кодом и им важно знать все об используемом приложении и его составе. Ведь если приложение будет содержать уязвимые компоненты, злоумышленники могут воспользоваться этим, чтобы украсть важные корпоративные данные. И когда это произойдет, вы можете потерять все конфиденциальные данные вашего бизнеса и клиентов, хранящиеся в приложении.
Для чего используется SCA?
Для создания Bill of Materials (BOM) приложений. В нем можно найти список компонентов с открытым кодом, их версии и типы лицензий. BOM помогает специалистам лучше понять состав компонентов и получить представление о возможных уязвимостях и проблемах с лицензированием. Для поиска и отслеживания компонентов с открытым исходным кодом.
Для этого в инструментах SCA используются системы для поиска OSS и управления лицензиями, позволяющие специалистам найти все open-source элементы в исходном коде, двоичных файлах, контейнерах, сборках, подкомпонентах и т.д. Для обеспечения соблюдения лицензионных требований.
Соблюдение лицензионных требований OSS одинаково важно для всех – как для разработчиков, так и для высшего руководство. SCA подчеркивает необходимость установления политик, реагирования на события, связанные с соблюдением лицензионных требований и безопасностью. Для обеспечения проактивного и непрерывного мониторинга. Чтобы лучше управлять рабочими нагрузками и повысить производительность, SCA-решения отслеживают уязвимости и позволяют пользователям предупреждать других пользователей о брешах в защите, найденных в продуктах.
Какие преимущества предлагает SCA?
- Использование SCA обеспечивает быстрый и безопасный выход на рынок.
- SCA позволяет разработчикам быстрее и эффективнее развивать приложение, так как берет на себя все заботы по проверке используемых компонентов с открытым кодом.
- Устраняет бизнес-риски за счет быстрого обнаружения и устранения проблем безопасности и лицензирования.
Чем инструменты SCA отличаются от других инструментов, отвечающих за безопасность приложений?
SCA отличаются от других инструментов своей ролью в растущем мире ПО с открытым исходным кодом. Решение SCA позволяет безопасно управлять рисками использования открытого исходного кода на протяжении всей цепочки поставок программного обеспечения.
Что SCA-решение должно предлагать пользователю?
В идеале, оно должно предлагать следующее:
- Обнаруживать и отслеживать все компоненты с открытым исходным кодом;
- Обеспечивать соблюдение лицензионных лицензионных требований;
- Помогать устранять уязвимости в компонентах с открытым исходным кодом;
- Проводить гибкое сканирование в зависимости от ситуации и потребностей пользователя;
- Легко интегрироваться в среду разработки компании.
Кто использует SCA?
Ответ прост – в первую очередь это поставщики ПО и организации, которые планируют или уже используют компоненты с открытым исходным кодом в ПО, поставляемом клиентам. Кроме того, SCA инструменты помогают командам DevOps ускорить процессы разработки с упором на безопасность.
Что такое инструменты SCA и зачем их использовать?
Инструменты SCA помогают искать и управлять компонентами с открытым исходным кодом, их косвенными и прямыми зависимостями, вспомогательными библиотеками, устаревшими зависимостями, потенциальными эксплойтами и уязвимостями.
Почему анализ состава ПО важен?
Внедрение SCA – это необходимый шаг для обеспечения безопасности приложения. Кроме того, оно спасает от проблем с лицензиями, что снижает риск различных юридических последствий, из-за которых компании несут репутационные и финансовые убытки.
Подводим итоги!
SCA помогает разработчикам повысить безопасность разрабатываемого продукта и соответствие требованиям, проверяя компоненты с открытым исходным кодом, которые могут быть уязвимы, и позволяя вовремя их исправить. Правильно выбранные инструменты SCA помогают снизить затраты, повышают гибкость бизнеса и позволяют разработчикам узнать, как обеспечить безопасность приложений на этапах планирования и проектирования.
Интересуетесь КИБЕРШПИОНАЖЕМ?
Подпишитесь на наш ТГ канал и узнайте, как остаться незамеченным для шпионов.
Источник: www.securitylab.ru