
Абстрактное описание сущности, находящейся вне системы, подсистемы или класса, которая напрямую взаимодействует с системой. Актант участвует в варианте использования или множестве вариантов использования с целью воплощения определенных намерений.
См. use case.
Актант — это абстрактное понятие, которое характеризует внешнего пользователя (или нескольких пользователей), взаимодействующих с системой или классификатором. При этом актант далеко не всегда соответствует физическому объекту. Иногда один физический объект может взаимодействовать с системой несколькими различными способами.
Иначе говоря, он будет представлять собой несколько актантов. С другой стороны, может существовать целое множество объектов, взаимодействующих с системой сходным образом. Такие объекты можно моделировать в виде одного актанта.
Актантом (объектом-пользователем) может быть как человек, так и неодушевленные объекты — компьютерная система, другая подсистема или еще какой-либо вид объектов. Например, пользователями компьютерной сети являются Оператор, Системный администратор, Администратор базы данных и обычный Пользователь. В этой сети могут существовать и неодушевленные актанты: УдаленныйКлиент, ПечатающееУстройство.
НЕ УПАДИТЕ! Как сложилась судьба кассирши АИДЫ НИКОЛАЙЧУК — победительницы шоу Х-фактор
Каждый актант определяет те роли, которые может играть пользователь во время взаимодействия с системой. Все возможные актанты системы покрывают вес возможные пути взаимодействия пользователей и системы. При реализации системы актанты воплощаются в физических объектах.
Один физический объект может представлять собой сразу несколько актантов, при условии, что он описывает все их роли. Например, один и тот же человек может быть как Продавцом, так и Покупателем. В процессе проектирования системы различные актанты реализуются в виде классов (см. realization).
Взаимодействия актантов с системой делятся на варианты использования. Вариант использования — это некая часть функциональности, в которую включено взаимодействие пользователя с системой для достижения определенной цели. В одном варианте использования может быть задействовано несколько актантов.
Таким же образом, один актант может участвовать в нескольких вариантах использования. Итак, актант определяется вариантами использования и теми ролями, которые оно в них играет. Актант, не участвующий ни в одном варианте использования, не имеет смысла.
Модель вариантов использования описывает поведение сущности (например, системы, подсистемы или класса) во время взаимодействия с внешними объектами. Внешние объекты являются актантами этой сущности. С точки зрения системы, актанты могут воплощаться как в людях, так и в других системах. Если речь идет о подсистемах или классах, актантами могут быть внешние элементы или другие элементы этой же системы, например подсистемы или классы.
Экземпляры актантов общаются с системой, получая экземпляры сообщений (вызовы и сигналы) и отправляя их экземплярам вариантов использования — на уровне реализации уже не вариантам использования, а объектам, которые реализуют эти варианты использования. Такие отношения актанта и вариантов использования выражаются с помощью ассоциаций.
Известный актер увел девушку лучшего друга. На самом деле
У актанта может быть список сигналов, которые оно получает и отправляет, а кроме того, список интерфейсов, которые для него требуются или которые оно поддерживает. При этом интерфейсы актанта должны быть совместимы с интерфейсами всех вариантов использования, в которых он фигурирует. Другими словами, актант должен иметь возможность получать все сигналы, отправляемые вариантом использования, и не отправлять такие сигналы, которые тот не может принять. Интерфейсы актанта определяют, каким образом оно будет соотноситься с классами. У актанта также может быть список атрибутов, которые характеризуют его состояние.
Несколько актантов могут иметь общие черты, иначе говоря, они взаимодействуют с системой сходным или одинаковым образом. С помощью отношения обобщения это сходство можно выразить следующим образом: существует некий (возможно, абстрактный) актант, с помощью которого описываются черты сходства нескольких актантов. Актанты-потомки наследуют роли и отношения, которые есть у этого абстрактного актанта-предка. При этом экземпляр потомка всегда можно использовать в том месте системы, где объявлено использование актанта-предка (принцип подстановочности). Актант-потомок сохраняет все атрибуты и операции своего предка.
Актант можно изображать на диаграмме с помощью символа класса (прямоугольник), внутри которого следует указывать стереотип «actor». Однако стандартной пиктограммой является схематический человечек, под которым указано его имя. На диаграмме у актанта могут также быть разделы, в которых указываются его атрибуты и события, которые он принимает.
Кроме этого, он может иметь зависимости, которые указывают на события, которые он отправляет. Все это входит в обычные характеристики классификатора (рис. 17).
Источник: openu.ru
Погружение в Акторы в Swift 5.5
Давайте посмотрим на изменения в параллелизме в новой версии Swift.

С новыми изменениями, связанными с параллелизмом, которые появятся в Swift 5.5, язык упрощает написание параллельного кода. Существует огромное количество предложений, которые были приняты в версии 5.5, есть масса новинок, которые нужно изучить и к которым привыкнуть.
Одна из новых функций, которые появятся в новом релизе Swift, — это доступность нового примитива, называемого Актором (actor — актер, действующее лицо, деятель). И прежде, чем мы начнем их использовать, давайте попробуем понять, что они из себя представляют и какие изменения вносит Swift для поддержки этой модели «Акторов» в языке.
Статья будет разбита на два основных раздела. В первом разделе мы попытаемся понять, что такое Акторы, какова основная проблема, которую они пытаются решить, и как они ее решают. Затем мы рассмотрим, как Swift представляет нам Акторов.
Параллелизм и модель Акторов
Конкурентность и параллелизм в программировании — это очень эффективные способы убедиться, что ваша программа использует преимущества аппаратного и программного обеспечения процессора, чтобы ваша программа работала с максимально возможной скоростью. Но с большой силой приходят и большие обязанности!
Одна из самых больших проблем параллельных систем — это проблемы общего состояния. Чтобы быть более конкретным, управление общим состоянием часто приводит к двум типам проблем в параллельной системе:
- Гонка данных — когда два или более потока пытаются получить доступ (по крайней мере один доступ является записью) к одному ресурсу, что вызывает несогласованность данных.
- Состояние гонки — из-за недетерминированного выполнения фрагмента кода на общем ресурсе результат в различных сценариях оказывается непредсказуемым. В основном, поскольку порядок выполнения не определен, он часто приводит к разным результатам.
Между ними есть разница, но, вообще говоря, они возникают из-за того, что есть какой-то доступ к общему состоянию. Как правило, гораздо проще обнаруживать гонки данных, но очень сложно отлаживать состояние гонки, потому что первые могут быть воспроизведены, а вторые не могут воспроизводиться каждый раз.
Существуют различные модели параллелизма, которые помогают нам решать проблемы гонки данных (например, блокировки и мьютексы, сериализованный доступ к общим данным и т.д.).
Swift пытается избежать этой проблемы, поощряя нас использовать семантику значений (то есть структуры и перечисления), поскольку их, как правило, легче использовать в параллельных средах.
Но даже семантика значений не помогает во всех случаях (либо потому, что они не имеют смысла для использования в таком контексте, либо из-за неправильной реализации), и в конечном итоге вы используете какой-то механизм синхронизации, такой как блокировки или последовательные очереди. Здесь нам на помощь приходит новая модель Акторов.
Модель актора — это модель параллелизма, в которой актор представляет собой новую примитивную структуру, которая поддерживает и защищает локальное состояние, будучи единственным, кто может вносить в него изменения/мутации. Любой внешний член может просто попросить актора действовать в соответствии с его состоянием, и актор обеспечит синхронизацию всех запросов на доступ/изменение его состояния.
Актеры обладают следующими характеристиками:
- Имеют собственное изолированное состояние.
- Может содержать логику для изменения собственного состояния.
- Может общаться с другими участниками только асинхронно (через их адреса).
- Может создавать других дочерних акторов (в данном случае нас это не особо волнует).
Одно из лучших объяснений ELI5 для общения в модели Акторов выглядит следующим образом:
Представьте, что каждый актор похож на остров, а наша кодовая база — это мир с островами. Каждый остров может общаться с другим островом, отправляя ему сообщения в бутылке. Каждый остров знает, куда отправить сообщение (то есть адрес другого острова), и именно так работает связь между островами.
Хотя теория, лежащая в основе модели акторов, гораздо больше (смотрите различные ссылки внизу статьи), мы рассмотрим, как эта модель работает в Swift.
Акторы в Swift
Swift 5.5 вводит новое ключевое слово под названием «актор». Так же, как вы можете определить класс или структуру, теперь вы можете определить актор.
Эти субъекты могут соответствовать протоколам и функционировать как любые примитивы (за исключением наследования, которое в настоящее время не поддерживается). Единственное отличие состоит в том, что взаимодействие между разными участниками происходит асинхронно.
Один из наиболее часто используемых примеров при объяснении параллелизма — это пример внесения/снятия денег с банковского счета. Итак, давайте продолжим и определим актора для BankAccount:
В приведенном выше примере, если BankAccount был бы определен как класс, а не как актор, переменная balance могла бы считаться небезопасным «изменяемым состоянием» (mutable state) в BankAccount, что могло бы привести к потенциальным ситуациям гонки данных в параллельной среде. Но теперь, когда BankAccount определен как actor, переменная баланса защищена от гонки. Посмотрим как.
Изоляция акторов
Теперь защита от гонки данных, описанная выше, осуществляется с помощью концепции, называемой изоляцией акторов. Это просто термин, используемый для определения нескольких правил, касающихся того, как должен работать доступ между участниками (как функциями, так и свойствами). Правила следующие:
- Актор может читать свои собственные свойства или вызывать свои функции (т.е. используя self) синхронно.
- Актор может обновлять только свои собственные свойства (и может делать это синхронно). Это означает, что вы можете обновлять свойства только с помощью ключевого слова self. Попытка обновить свойство другого актера приведет к ошибке компилятора.
- Считывание свойств между участниками или вызовы функций должны происходить асинхронно с использованием ключевого слова await. Однако перекрестное чтение неизменяемых свойств может происходить синхронно (тех, что объявлены с помощью let).
Повторный вход в актор
Выполнение функций в акторах повторяется. Под повторным входом я подразумеваю тот факт, что среда выполнения может повторно войти в выполнение кода в точке приостановки и продолжить работу оттуда. Давайте посмотрим на это на примере:
Допустим, вы пытались закрыть свой банковский счет, и для этого вам необходимо связаться с серверами вашего банка. Мы предпринимаем следующие шаги:
- Проверяем, открыт ли аккаунт. Нет смысла закрывать уже закрытый аккаунт.
- Сообщаем на серверы банка, что счет запрашивает закрытие (этот шаг может занять время).
- Проверяем, открыт ли еще счет. Если счет все еще открыт, закрываем счет и возвращаем остаток. В противном случае выдаем ошибку, сообщающую, что во время сетевого запроса был произведен другой запрос на отмену, который, вероятно, уже закрыл учетную счет.
Повторный вход в акторы определяется тем фактом, что функция может быть приостановлена на полпути на некоторое время, в то время как поток, выполнявший функцию, выполняет некоторые другие задачи, а затем возобновляет функцию с точки приостановки.
Например, в этом вызове для закрытия банковского счета вы можете «приостановить» свой код на некоторое время (пока он обменивается данными с серверами банка), заставить тот же поток выполнять некоторую другую работу, а затем «возобновить» выполнение работать с того места, где он остановился, как только вы получите ответ от серверов банка.
Есть небольшое, но важное замечание относительно строки 8, где происходит «приостановка» работы текущего потока (то есть строки, в которой происходит вызов ожидания).
Помните, что каждый вызов await — это потенциальная точка приостановки вашего кода.
Пока серверы банка не ответят, этот поток может выполнять другую незавершенную работу, которую, вероятно, запланировал наш код, или какую-то новую работу, которую запрашивает код. Мы можем отправить запрос на withdraw (снятие) денег, deposit (внесение денег) или другой запрос cancellation (на отмену), и это в конечном итоге будет запущено в этом потоке.
Теперь, когда сервер банка ответит, состояние актора может отличаться от состояния до точки приостановки. Это очень важный момент, так как вы должны осознавать тот факт, что вы не можете делать предположения о состоянии вашего актера до и после вызова функции await.
Это единственная причина, по которой я еще раз проверил, открыта ли еще учетная запись, в строке 9 (после вызова await), потому что вполне возможно, что второй вызов отмены мог быть выполнен и завершен, а счет уже был закрыт.
Следовательно, рассуждая о повторном вхождении в актор, вам нужно помнить две вещи:
- Всегда пытайтесь выполнить изменение состояния в синхронном коде (избегайте вызовов асинхронных async функций в функциях, в которых вы меняете внутреннее состояние).
- Если вам необходимо выполнить вызовы асинхронных функций внутри функции, которая изменяет состояние, не делайте никаких предположений о состоянии после завершения await.
Apple предлагает вызывать весь код пользовательского интерфейса в основном потоке. Поэтому всякий раз, когда нам нужно выполнить тяжелую обработку данных или сделать сетевой вызов для получения данных для отображения нашего пользовательского интерфейса, мы делаем это в фоновых потоках. После завершения обработки мы обычно делаем следующее:
Вы можете аннотировать свойства, функции и определения классов/структур с помощью этого property wrapper.
Классы UIKit (например, UILabel, UIView и т.д.) уже отмечены этой оберткой. Таким образом, вы можете быть уверены, что они всегда будут доступны в основном потоке.
Единственная загвоздка заключается в том, что эти члены будут доступны только в основном потоке при использовании новых вызовов async/await — а не при использовании обработчиков завершения. Вот фрагмент кода, который поможет вам лучше понять это:
Если вы запустите этот фрагмент кода и установите точку останова в строке 11/12, вы увидите, что вызов из DispatchQueue.global не будет выполняться в основном потоке, но вызов из asyncDetached будет выполняться в основном потоке.
Акторы в Swift 5.5: заключение
Как вы увидели, акторы — определенно необходимое дополнение к такому современному языку, как Swift. Я уверен, что вся система будет продолжать развиваться, и в Swift может быть много обновлений параллелизма. С учетом сказанного, основные моменты, которые вам нужно вынести из этой статьи, следующие:
Ссылки
- SE-0303 Proposal
- WWDC Talk on Actors
- WWDC Talk on the implementations of Actors
- Doug Gregor’s talk on Swift Concurrency — Swift By Sundell
Источник: apptractor.ru
DDD, CQRS, Event-Driven, модель акторов и микросервисы
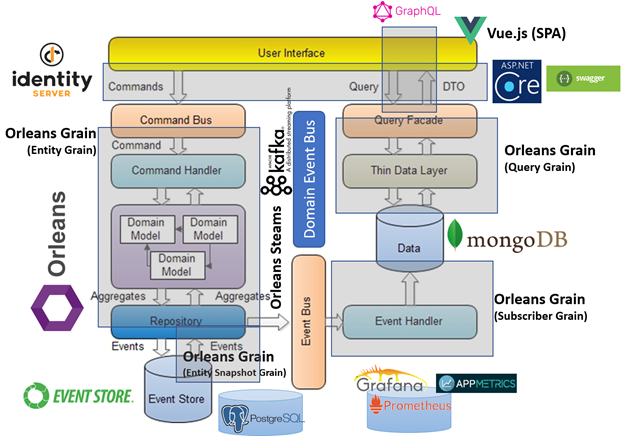
Хочу поделиться своим опытом реализации микросервисной архитектуры поверх actor-model фреймоворков, таких как AKKA и Microsoft Orleans.
Моя гипотеза: если использовать один стек для реализации микросервисов, то можно:
• Существенно снизить сложность разработки и объем кода
• Упростить отладку и поиск ошибок
• Упростить деплой
• Упростить задачу определения границ сервисов
• Избавится от ограничения применения stateful-сервисов
• Упростит работу с распределенными транзакциями.
О… Похоже на «серебряную пулю»! Давайте разберемся, так ли это.
Зачем это нужно?
Всем знакомы ключевые преимущества микросервисной архитектуры:
- сервисы можно легко заменить в любое время: акцент на простоту, независимость развёртывания и обновления каждого из микросервисов;
- сервисы организованы вокруг функций: микросервис по возможности выполняет только одну достаточно элементарную функцию;
- сервисы могут быть реализованы с использованием различных языков программирования, фреймворков, связующего программного обеспечения и пр.;
- архитектура симметричная, а не иерархическая: зависимости между микросервисами одноранговые
Не являются секретом и сложности при использование этого подхода:
- Возросшая сложность разработки: сложность работы над задачей, затрагивающей множество сервисов, сложности отладки.
- Возросшая сложность эксплуатации и DevOps: чем больше сервисов, больше способов их взаимодействия и больше возможностей для потенциальных проблем.
- Реальные системы обычно не имеют чётко определённых границ: сложно провести границы между сервисами, определить зависимости между ними, необходимость одновременного выката множества версий множества сервисов при деплое фичи.
- Ограничения реализации stateful-сервисов: реализация stateful-сервисов существенно усложняет деплой.
- Распределенные транзакции и итоговая согласованность: распределённых системы требуют механизма распределенных транзакций.
Анализируя плюсы и минусы, появилась идея: а что, если избавиться о части проблем за счет сокращения некоторых невостребованных преимуществ?
На практике, во всех проектах стараются избежать «зоопарка технологий» и стек на котором происходит разработка сервисов практически всегда один. Так что, достаточно часто можно пожертвовать таким преимуществом как «сервисы могут быть реализованы с использованием различных языков программирования, фреймворков, связующего программного обеспечения и пр.». Если мы можем использовать один стек для разработки сервисов, то это открывает нам новые возможности!
Единый стек для сервисов
Возьмём за основу DDD подход, который рекомендует нам разбивать предметную область на ограниченные контексты (Bounded context).
Ограниченный контекст – это явная граница, внутри которой существует модель предметной области, которая отображает единый язык в модель программного обеспечения. Очевидно, что ограниченный контекст это и есть микросервис со своей моделью данных.
В рамках каждого ограниченного контекста, в соответствии с DDD, свой набор сущностей (entities), состоящих из других сущностей и объектов-значений (value-objects). Сущности объединены в агрегаты (aggregation roots). Доступ к сущностям возможен только через агрегаты, которые имеют уникальный идентификатор агрегата (aggregate identity) в рамках системы.
Вся логика, которая относится к конкретным сущностям/агрегатам должна быть определена в них. Логика, затрагивающая несколько агрегатов, должна быть реализована в рамках доменных сервисов (domain services).
Агрегат может оповещать другие агрегаты об изменении своего состояния через единую шину событий (event bus), выбрасывая доменные события (domain events).
Добавим к этом походу CQRS – как «протокол» для общения с агрегатами:
• Команды (commands) – это примитивы для вызова методов агрегата.
• Запросы (queries) – это примитивы для получения состояния агрегатов или даже группы агрегатов. Согласно CQRS обработка запросов должна быть реализована вне агрегатов в рамках отдельных сущностей – обработчиков запросов (command handlers).
Нам нужны будут шина команд (command bus) и шина запросов (query bus) для доставки этих примитивов агрегатам и обработчикам и получения результатов вызова.
Таким образом, любой наш сервис строится из следующих компонентов:
• объекты-значений (value-objects)
• сущности (entities)
• агрегаты (aggregation roots)
• доменные сервисы (domain services)
• идентификаторы агрегата (aggregate identity)
• доменные события (domain events)
• команды (commands)
• запросы (queries)
• обработчики запросов (command handlers).
Теперь можно взаимодействовать с любым микросервисом по стандартному «протоколу»:
• Посылать команды агрегатам миросервиса для изменения их состояния
• Подписываться и получать события, как результат изменения состояния агрегата
• Отправлять запросы и получать в ответ данные о состоянии групп агрегатов
Ну и нельзя забывать о логике уровня приложения, которая оперирует агрегатами различных сервисов (оркеструет их работу), управляет распределенными транзакциями. Это саги (saga) –конечные автоматы с состоянием, которые подписываются на доменные события и вызывают команды различных агрегатов, реализуя логику уровня приложения.
Stateful против Stateless
Пришло время поговорить о модели акторов (actor model). Акторы — альтернативный подход к организации параллельных вычислений и распределенных систем.
В упрощенном виде актор (actor) – это, обычно, stateful сущность, которая принимает сообщения, производит вычисления на основе этих сообщений и изменяет свое состояние. Акторы изолированы друг от друга и их внутреннее состояние не может быть изменено извне. Актор получает сообщения асинхронно. Но обрабатывает их по очереди (синхронно, в рамках одного потока).
Существуют фреймворки, которые упрощают разработку акторов:
• АККА (АККА.Net) – модель акторов для Java и Scala (C#)
• Microsoft Orleans – модель виртуальных акторов для .NET Core (C#)
Все эти фреймворки позволяют создавать акторы, управлять их жизненным циклом, доставкой и обменом сообщении. Они позволяют элегантно решить задачу создания stateful-сервисов и обеспечивают их отказоустойчивую работу в кластере.
Очевидно, что акторы в нашем подходе очень хорошо лежаться на реализацию stateful-объектов: агрегатов и саг. Их так же можно использовать для кэширования результатов выполнения запросов.
Ох, но Stateful – это плохо! Или нет?
Понятно, что нет универсального ответа на это вопрос. Также очевидно, что тенденции последних лет были направлены в сторону разработки stateless-сервисов, обеспечивающих хорошее горизонтальное масштабирование.
Но при настоящем highload становится очевидным, что stateless-сервисы – это не панацея. Они либо дают серьёзную нагрузку на базу, которую становится сложно решить или приводят к проблемам с кэшированием (когда обновлять кэш?).
Модель акторов, которая позволяет хранить состояние сервиса в памяти кластера и обращаться к нему без восстановления состояния из базы или кэша – это более продуктивное решение, чем stateless-сервис. Причем, фреймворк модели акторов берет на себя задачу выгрузки из памяти неиспользуемых объектов, а также задачи отказоустойчивости.
Именно такой поход мы применим для работы с нашими агрегатами и сагами.
Также, стоит отметить, что фреймворки модели акторов «из коробки» дают нам реактивные потоки (reactive streams), которые идеально подходят для реализации шин событий, команд и запросов. Это позволяет нашим сервисам взаимодействовать друг с другом единым, универсальным образом через реактивные потоки.
А как же взаимодействие с микросервисов с клиентскими приложениями?
Универсальный API-proxy
Очевидно, что если все взаимодействие с микросервисами строится с помощью команд, событий и запросов, то мы можем сделать универсальный API-proxy, который будет строиться автоматически на основании семантики этих примитивов.
В свои проектах я реализовывал такой подход для автоматической генерации «налету» WebAPI для вызова команд и запросов, swagger документации к этим вызовам, graphql для вызова запросов, signalR подписку и получение любых доменных событий.
Среда исполнения
В описываемом подходе акторы (агрегаты, саги, обработчики запросов) материализуются в кластере под управлением фреймворка акторов – это наша единая среди исполнения всех микросервисов.
Это позволяет гибко управлять структурой кластера, запуском микросервисов в нем. Например, мы можем поднять все сервисы на одном сервере в рамках одного процесса, что очень удобно для отладки. Или в режиме реального времени добавлять новые серверы в кластер, на которых поднимать интересующие нас сервисы. У нас есть возможность управлять правилами материализации акторов в кластере, что позволяет нам поднимать связанные сущности в одном процессе, чтобы существенно сократить затраты на взаимодействие между ними.
Имея такой универсальный набор компонентов для создания сервисов и единую среду для их исполнения, мы можем создать свой единый фреймворк, на основе которого будем строить все наши микросервисы.
Единый фреймворк
Я на практике использовал для реализации описанного выше подхода АККА.Net и Microsoft Orleans. По моему мнению Microsoft Orleans лучше подходит для решения этой задачи, т.к. виртуальная модель акторов существенно упрощает управление жизненным циклом акторов и обработку исключений.
Как устроен единый фреймворк:
- Сборка с примитивами Framework.Primitives
Содержит базовые классы для создания публичных примитивов миросервисов, таких как:
• объекты-значений (value-objects)
• идентификаторы агрегата (aggregate identity)
• доменные события (domain events)
• команды (commands)
• запросы (queries) - Сборка с базовыми объектами компонентами миросервиса Framework.Domain
Содержит базовые классы для создания приватных объектов миросервисов, таких как:
• сущности (entities)
• агрегаты (aggregation roots)
• доменные сервисы (domain services)
• обработчики запросов (command handlers) - Сборка Framework.Application содержит базовые классы для саг.
- Сборка Framework.Infrastructure содержит базовые классы для сохранения состояния агрегатов и саг в различные базы данных
- Сборка Framework.Host содержит реализацию хоста, среды исполнения микросервисов, построения и управления кластером, работой с конфигурацией.
Как с помощью единого фреймворка создается микросервис:
- Определяется набор сущностей, объектов значений и агрегатов. Определяется модель состояния каждого агрегата.
- Создаются классы для хранения состояния агрегатов и классы сущностей, объектов значений и агрегатов.
- Определяется набор команд, меняющих состояние агрегатов и события, информирующие об изменении состояния агрегата.
- Создаются классы команд и обработчики этих команд в агрегате, меняющие состояние и выбрасывающие события. При необходимости создаются доменные сервисы (stateless-сервисы), содержащие логику, которая выходит за рамки одного агрегата.
- Создаются провайдеры для чтения и сохранения состояния агрегатов в базы данных.
Таким образом, каждый микросервис, обычно сдержит следующие сборки:
- Service1.Primitives – публичные примитивы (события, команды, идентификаторы агрегатов)
- Service1.Domain – приватная реализация доменной логики (сущности, агрегаты, доменные сервисы)
- Service1.Infrastructure – провайдеры чтения и сохранения состояния агрегатов в базы данных
В отдельных сборках уровня приложения (Application) создаются саги и обработчики запросов.
Для примера, добавлю немного когда, а то «многобукв» получилось 🙂
Ниже пример реализации агрегата, как видно код простой и очевидный.
public class UserId : Identity < public UserId(System.String value) : base(value) < >> [Validator(typeof(BirthValidator))] public class Birth : SingleValueObject < public Birth(DateTime value) : base(value) < >> public class BirthValidator : AbstractValidator < public BirthValidator() < RuleFor(p =>p.Value).NotNull(); RuleFor(p => p.Value).LessThan(DateTime.Now); > > [Description(«Создание нового пользователя»)] [HasPermissions(DemoContext.CreateUser, DemoContext.ChangeUser)] [Validator(typeof(CreateUserCommandValidator))] public class CreateUserCommand : Command < public LocalizedString UserName < get; >public Birth Birth < get; >public CreateUserCommand(UserId aggregateId, LocalizedString userName, Birth birth) : base(aggregateId) < UserName = userName; Birth = birth; >> public class CreateUserCommandValidator : AbstractValidator < public CreateUserCommandValidator(IServiceProvider sp) < RuleFor(p =>p.AggregateId).NotNull(); RuleFor(p => p.UserName).SetValidator(new UserNameValidator()); RuleFor(p => p.Birth).ApplyRegisteredValidators(sp); > > [Validator(typeof(BirthValidator))] public class Birth : SingleValueObject < public Birth(DateTime value) : base(value) < >> public class BirthValidator : AbstractValidator < public BirthValidator() < RuleFor(p =>p.Value).NotNull(); RuleFor(p => p.Value).LessThan(DateTime.Now); > > public class UserState : AggregateState, IApply, IApply, IApply, IApply, IApply, IApply < public LocalizedString Name < get; private set; >public Birth Birth < get; private set; >public System.String Notes < get; private set; >= System.String.Empty; public IEnumerable Projects => _projects; public void Apply(UserCreatedEvent e) < (Name, Birth) = (e.Name, e.Birth); >public void Apply(UserRenamedEvent e) < Name = e.NewName; >public void Apply(UserNotesChangedEvent e) < Notes = e.NewValue; >public void Apply(UserTouchedEvent _) < >public void Apply(ProjectCreatedEvent e) < _projects.Add(new Entities.Project(e.ProjectId, e.Name)); >public void Apply(ProjectDeletedEvent aggregateEvent) < var projectToRemove = _projects.FirstOrDefault(i =>i.Id == aggregateEvent.ProjectId); if (projectToRemove != null) _projects.Remove(projectToRemove); > private readonly ICollection _projects = new List(); > public class UserAggregate : EventDrivenAggregateRoot, IExecute, IExecute, IExecute < public UserAggregate(UserId id) : base(id) < Command(); Command(); Command(); > internal async Task CreateProject(ProjectId projectId, ProjectName projectName) < await Emit(new ProjectCreatedEvent(Id, projectId, projectName)); >internal async Task DeleteProject(ProjectId projectId) < await Emit(new ProjectDeletedEvent(Id, projectId)); >public async Task Execute(CreateUserCommand cmd) < //SecurityContext.Authorized(); //SecurityContext.HasPermissions(cmd.AggregateId, DemoContext.TestUserPermission); await Emit(new UserCreatedEvent(cmd.UserName, cmd.Birth)); return ExecutionResult.Success(); >public async Task Execute(ChangeUserNotesCommand cmd) < await Emit(new UserNotesChangedEvent(Id, State.Notes, cmd.NewValue)); return ExecutionResult.Success(); >public async Task Execute(TrackUserTouchingCommand cmd) < await Emit(new UserTouchedEvent()); return ExecutionResult.Success(); >public async Task Rename(UserName newName) < await Emit(new UserRenamedEvent(newName)); >>
Что этот дает?
Что дает этот единый фреймворк для разработки микросервисов:
Существенно снизить сложность разработки и объем кода
Основной объем кода сервиса – это прикладная бизнес-логики. Разработчики определяю объекты-значений, сущности и агрегаты, и их логику, доменные сервисы. Одновременно формализуя интерфейс работы с микросервисом, определяя команды, запросы и события.
Код существенно упрощается, т.к. вся логика работы агрегата исполняется в одном потоке (нет многопоточных проблем), не нужно создавать контроллеры для обработки API, все берет на себя фреймворк. Весь код разнесен по слоям с четкой односторонней зависимостью между слоями.
Вызов других микросервисов прост и строго типизирован, для этого используются публичные сборки с примитивами (команды, события, идентификаторы, запросы).
Упростить отладку и поиск ошибок
Можно подключить и поднять рамках одного процесса откладки (одной IDE) нужное количество сервисов и легко их отладить.
Упростить деплой
При небольших объемах можно поднять систему на одном сервере («как монолит»). Есть возможность гибко управлять структурой кластера.
Упростить задачу определения границ сервисов
Применение DDD и Event Storming при проектировании системы позволяет корректно решить задачу разбивки системы на сервисы.
Избавится от ограничения применения stateful-сервисов
Можно использовать как stateful, так и stateless подход без ограничений. Stateful поход реализован максимально просто для разработчика, при это обеспечивает беспрецедентную производительности, масштабируемость и отказоустойчивость.
Источник: temofeev.ru