
Несмотря на то, что в настоящее время большинство документов составляется на компьютерах, задача создания полностью электронного документооборота ещё далека до полной реализации. Как правило, существующие системы охватывают деятельность отдельных организаций, а обмен данными между организациями осуществляется с помощью традиционных бумажных документов.
Задача перевода информации с бумажных на электронные носители актуальна не только в рамках потребностей, возникающих в системах документооборота. Современные информационные технологии позволяют нам существенно упростить доступ к информационным ресурсам, накопленным человечеством, при условии, что они будут переведены в электронный вид.
Наиболее простым и быстрым является сканирование документов с помощью сканеров. Результат работы является цифровое изображение документа – графический файл. Более предпочтительным, по сравнению с графическим, является текстовое представление информации. Этот вариант позволяет существенно сократить затраты на хранение и передачу информации, а также позволяет реализовать все возможные сценарии использования и анализа электронных документов. Поэтому наибольший интерес с практической точки зрения представляет именно перевод бумажных носителей в текстовый электронный документ.
Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы
На вход системы распознавания поступает растровое изображение страницы документа. Для работы алгоритмов распознавания желательно, чтобы поступающее на вход изображение было как можно более высокого качества. Если изображение зашумлено, нерезко, имеет низкую контрастность, то это усложнит задачу алгоритмов распознавания.
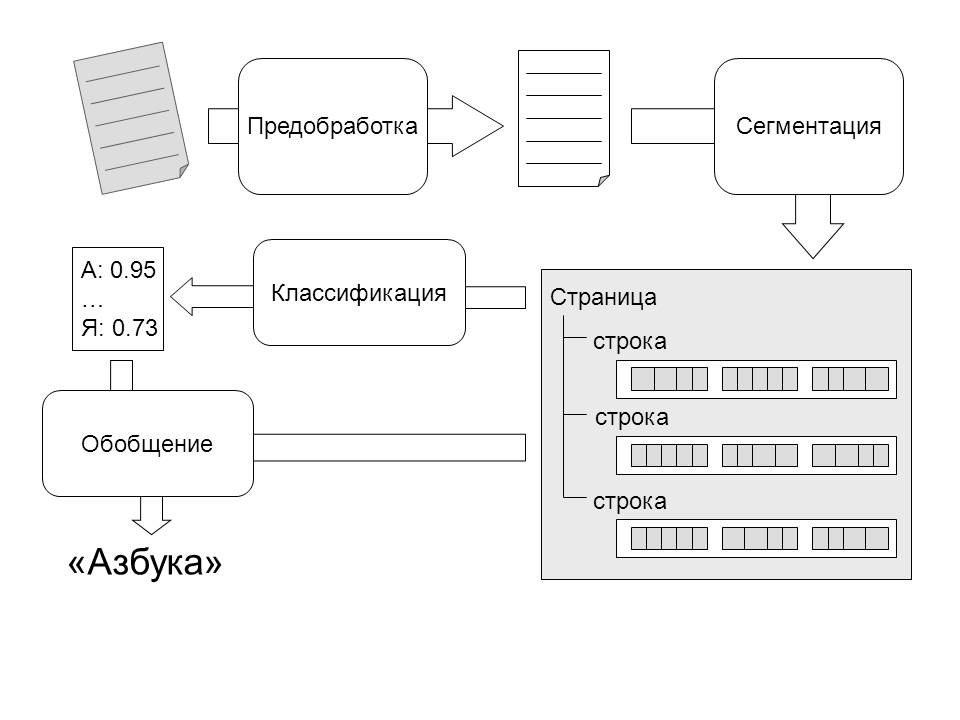
Поэтому перед обработкой изображения алгоритмами распознавания проводится его предварительная обработка, направленная на улучшение качества изображения. Она включает фильтрацию изображения от шумов, повышение резкости и контрастности изображения, выравнивание и преобразование в используемый системой формат (в нашем случае 8-битное изображение в градациях серого).
Подготовленное изображение попадает на вход модуля сегментации. Задачей этого модуля является выявление структурных единиц текста – строк, слов и символов. Выделение фрагментов высоких уровней, таких как строки и слова, может быть осуществлено на основе анализа промежутков между тёмными областями.
К сожалению, такой подход не может быть применён для выделения отдельных букв, поскольку, в силу особенностей начертания или искажений, изображения соседних букв могут объединяться в одну компоненту связанности (рис. 1) или наоборот — изображение одной буквы может распадаться на отдельные компоненты связанности (рис. 2). Во многих случаях для решения задачи сегментации на уровне букв используются сложные эвристические алгоритмы.

Рисунок 1. Объединение нескольких букв в одну компоненту связанности.

Рисунок 2. Распадение изображений букв на несвязанные компоненты вследствие низкого качества сканирования.
Полагаем, что для принятия окончательного решения о прохождении границы букв на таком раннем этапе обработки, системе распознавания недостаточно информации. Поэтому задачей модуля сегментации на уровне букв в разработанном алгоритме является нахождение возможных границ символов внутри буквы, а окончательное решение о разбиении слова принимается на последнем этапе обработки, с учётом идентификации отдельных фрагментов изображения как букв. Дополнительным преимуществом такого подхода является возможность работы с начертаниями букв, состоящих из нескольких компонент связанности без специальной обработки таких случаев.
Результатом работы модуля сегментации является дерево сегментации – структура данных, организация которой отражает структуру текста на странице. Самому верхнему уровню соответствует объект страница. Он содержит массив объектов, описывающих строки. Каждая строка в свою очередь включает набор объектов слов. Слова являются листьями этого дерева.
Информация о возможных местах разделения слова на буквы храниться в слове, однако отдельные объекты для букв не выделяются. В каждом объекте дерева хранится информация об области, занимаемой соответствующим объектом на изображении. Данная структура легко может быть расширена для поддержки других уровней разбиения, например колонок, таблиц.
Выявленные фрагменты изображения подаются на вход классификатора, выходом которого является вектор возможности принадлежности изображения к классу той или иной буквы. В разработанном алгоритме используется классификатор составной архитектуры, организованный в виде дерева, листьями которого являются простые классификаторы, а внутренние узлы соответствуют операциям комбинирования результатов низлежащих уровней (рис. 3).

Рисунок 3. Архитектура классификатора.
Работа простого классификатора осуществляется в два шага (рис. 4). Сначала по исходному изображению вычисляются признаки. Значение каждого признака является функцией от яркостей некоторого подмножества пикселей изображения. В результате получается вектор значений признаков, который поступает на вход нейронной сети.
Каждый выход сети соответствует одной из букв алфавита, а получаемое на выходе значение рассматривается как уровень принадлежности буквы нечёткому множеству.

Рисунок 4. Простой классификатор.
Задачей алгоритма комбинирования является обобщение информации, поступающей в виде входных нечётких множеств и вычисление на их основе выходного нечёткого подмножества множества распознаваемых символов. В качестве алгоритмов комбинирования используются операции теории нечётких множеств (такие как t-нормы и s-нормы), выбор наиболее уверенного эксперта.
Результатом работы классификатора является нечёткое множество, полученное в результате комбинирования на самом верхнем уровне.
На последнем этапе принимается решение о наиболее правдоподобном варианте прочтения слова. Для этого используются уровни возможности прочтения отдельных букв, межбуквенной сегментации и частоты сочетаний букв в русском языке.
Для оценки эффективности разработанного алгоритма было проведено сравнение с двумя существующими системами OCR. Это бесплатная open-source система CuneiForm v12 и коммерческая система ABBYY FineReader 10 Professional Edition.
К сожалению, для оценки эффективности работы систем распознавания, обычно используются наборы символов, подготовленных иностранными специалистами, либо наборы, собранные авторами и не опубликованные в открытом доступе. Так, например, оценивая эффективность работы алгоритмов ABBYY FineReader автор использовал базы данных CEDAR, NIST, CENPARMI а также сканированные анкеты ЕГЭ. Поскольку данные базы содержат английские и/или рукописные символы, они не могут быть использованы для оценки эффективности выполнения НИР по теме «разработка алгоритма распознавания печатных кириллических символов».
Сравнение производилось на образцах с разрешением 96 dpi и 180 dpi. В сравнении участвовал текст, состоящий из 300 слов, набранных шрифтами Arial 14pt и Times New Roman 14pt. Текст разрешением 96 dpi был создан на компьютере непосредственно в виде графического файла. Для теста с разрешением 180 dpi текст был распечатан на лазерном принтере, а затем сканирован с указанным разрешением. Фрагмент использованного текста приведен на рис. 5.

Рисунок 5. Фрагмент текста, использованного для тестирования систем распознавания.
Результаты сравнения для 96 dpi представлены в таблице 1.

Таблица 1. Результаты распознавания текста разрешением 96 dpi.
Результаты сравнения для текста с разрешением 180 dpi представлены в таблице 2.

Таблица 2. Результаты распознавания текста разрешением 180 dpi.
Лучшие результаты распознавания для 96 dpi можно объяснить тем, что текущая конфигурация системы была обучена на шрифтах Times New Roman 14pt и Arial 14pt при разрешающей способности 96 dpi. Можно ожидать улучшения результатов для этого текста при добавлении в систему простых классификаторов, обученных распознавать шрифты такого размера.
Суммарно, из 1200 слов было распознано:
• разработанным алгоритмом: 1180 слов (98,33%);
• системой с открытыми кодами CuneiForm: 597 слов (49,75%);
• коммерческой системой ABBYY FineReader: 1200 слов (100%).
Стоит отметить, что при низком разрешении, наличии большого числа шума Cuneiform не справляется с распознаванием текста, в то время как предложенный алгоритм распознает текст в таком качестве.
В целом, можно заключить, что хотя предложенный алгоритм уступает лучшему в данном классе коммерческому продукту фирмы Abbyy, он способен распознавать текст худшего качества, чем способна распознать система c открытыми исходными кодами CuneiForm.
Список использованной литературы.
Квасников В.П., Дзюбаненко А.В. Улучшение визуального качества цифрового изображения путем поэлементного преобразования // Авиационно-космическая техника и технология 2009 г., 8, стр. 200-204
Арлазаров В.Л., Куратов П.А., Славин О.А. Распознавание строк печатных текстов // Сб. трудов ИСА РАН «Методы и средства работы с документами». — М.: Эдиториал УРСС, 2000. — С. 31-51.
Проект СПбГУ Открытый код: распознавание текстовых изображений [Электронный ресурс] — Режим доступа: ocr.apmath.spbu.ru
Багрова И. А., Грицай А. А., Сорокин С. В., Пономарев С. А., Сытник Д. А. Выбор признаков для распознавания печатных кириллических символов // Вестник Тверского Государственного Университета 2010 г., 28, стр. 59-73
The concept of a linguistic variable and its application to approximate reasoning, Information Sciences, 8, 199-249; 9, 43-80.
Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13:2, 2006.
Панфилов С. А. Методы и программный комплекс моделирования алгоритмов управления нелинейными динамическими системами на основе мягких вычислений. Диссертация на соискание ученой степени кандидата технических наук. Тверь, 2005.
- нейронные сети
- OCR
- распознавание текстов
Источник: habr.com
Инструменты распознавания текстов и компьютерного перевода

Современный мир меняется и улучшается каждую минуту. Ещё недавно для того, чтобы почитать, мы были вынуждены покупать книги или ходить в библиотеку и брать книги там. А сейчас достаточно зайти в интернет, найти интересную книгу и читать её с компьютера, телефона или специального устройства – электронной книги. На этом уроке учащиеся узнают, как в интернет попали книги. Узнают, какие программы предназначены для распознавания документов, что называют компьютерными словарями, для чего предназначены программы-переводчики.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет.
Получите невероятные возможности

1. Откройте доступ ко всем видеоурокам комплекта.

2. Раздавайте видеоуроки в личные кабинеты ученикам.

3. Смотрите статистику просмотра видеоуроков учениками.
Получить доступ
Конспект урока «Инструменты распознавания текстов и компьютерного перевода»
Современный мир меняется и улучшается каждую минуту. Ещё недавно для того чтобы почитать мы были вынуждены покупать книги или ходить в библиотеку и брать книги там. А сейчас достаточно зайти в интернет, найти интересную книгу и читать её с компьютера, телефона или специального устройства – электронной книги.
А задумывались вы, как в интернет попали все эти книги. Можно предположить, что какой-то ответственный человек сидел и набирал тексты книг на компьютере.
Как вы думаете, сколько он потратил на это времени? Давайте попробуем подсчитать. Предположим, что наш человек очень опытный наборщик текстов и его скорость набора 180 знаков в минуту. Ему нужно ввести в компьютер текст романа «Война и мир».

Как вы уже догадались, данный способ перевода печатного текста на компьютер не эффективен и не практичен.
Гораздо быстрее и удобнее использовать специальный инструмент, такой как например сканер, который за считаные секунды переведёт любую бумажную информации в цифровую.

А когда же появился сканер? Давайте рассмотрим историю появления этого инструмента.
Можно сказать, что создание сканера началось со времён изобретения всем известного телеграфа. Был изобретён прибор, который передавал изображение на расстояния.

Но очень бурное развитие сканера началось в начале XX века, в те времена, когда был изобретён фототелеграф, как мы привыкли его называть – телефакс. В 1902 году, немецкий физик Артур Корн запатентовал технологию фотоэлектрического сканирования, получившую впоследствии название телефакс.

Передаваемое изображение закреплялось на прозрачном вращающемся барабане, луч света от лампы, перемещающейся вдоль оси барабана, проходил сквозь оригинал и через расположенные на оси барабана призму и объектив попадал на селеновый фотоприёмник.
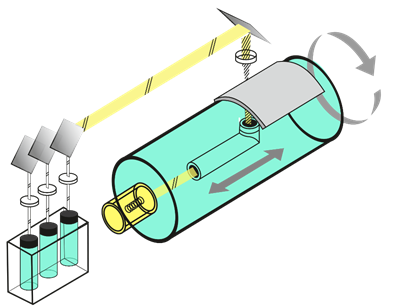
Эта технология до сих пор применяется в барабанных сканерах.

После этого учёными было сделано, новое прорывное в будущее изобретение – был изобретён новый способ сканирования, который гордо носит название – планшетный.
Рассмотрим принцип действия планшетных сканеров.
Сканируемый объект кладётся на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается подвижная лампа, движение которой регулируется шаговым двигателем. Свет, отражённый от объекта, через систему зеркал попадает на чувствительную матрицу и передаётся в компьютер. За каждый шаг двигателя сканируется полоска объекта, все полоски потом объединяются программным обеспечением в общее изображение.
Данная конструкция имеет ряд преимуществ перед своими предками, основное из которых – это то, что сканер передаёт изображение в компьютер.
На сегодняшний день рынок компьютерной техники насчитывает огромное количество моделей сканеров.

Многие привыкли называть сканер – фотоаппарат, который фотографирует изображения.
Сканеры используются для ввода изображений на компьютер. С помощью сканера мы получаем на своём компьютере электронный снимок. Сканер иногда заменяет нам факс. Любой документ, любую фотографию мы можем отсканировать и передать по электронной почте.
Итак, отсканированный снимок попал в компьютер. Но дальше эту информацию нужно распознать, отредактировать и изменить. Для этого нам нужно воспользоваться специальной программой ABBYY FineReader.

Остановимся подробнее на работе такой программы:
1) В начале, вам необходимо отсканировать текст с помощью сканера. Для этого вы помещаете текст под крышку сканера, и в программе отдаёте команду Сканировать и распознать. Тем самым мы создаём цифровую копию исходного документа в формате графического изображения.
2) Затем программа анализирует структуру документа, выделяя на его страницах блоки текста, таблицы и картинки. Строки разбиваются на слова, а слова на буквы. Затем программа сравнивает найденные символы с шаблонами из своей памяти. Кроме того, в программу встроены словари, которые позволяют производить более точный анализ и распознавание и проверку распознанного текста. Проанализировав огромное количество вариантов, программа выдаёт окончательное решение пользователю распознанного текста.
3) И наконец, распознанный текст переносится в окно текстового редактора, например, Microsoft Word.
Однако, качество распознанного текста зависит от того как хорошо виден исходный текст. Отсканированный и распознанный текст обязательно нужно перечитать и отредактировать.
Современные технологии позволяют не использовать сканер, а вместо него воспользоваться фотоаппаратом или даже телефоном.
А теперь вспомните те далёкие годы, когда ещё не было печатных станков и нашим предкам приходилось вручную переписывать рукописи, чтобы они дошли до наших дней. Каким тяжёлым и важным был труд писарей, и как ценна была каждая книга.

Теперь разберёмся для чего предназначены компьютерные словари и программы-переводчики
Основная цель современных компьютерных технологий упрощать, улучшать жизнь человека, делать её комфортнее и динамичнее. Одним из таких удобств являются компьютерные словари и программы-переводчики, которые позволяют мгновенно найти нужное слово, перевести его и даже если нужно — прослушать произношение. Ещё совсем недавно это казалось невозможным. Люди, которые попадали за границу, должны были иметь при себе разговорник или карманный словарь, чтобы иметь возможность общаться с местными жителями.

Сегодня достаточно установить специальное приложение на телефон и общение проходит быстро и комфортно. Вы можете, как набрать на телефоне нужную фразу, так и произнести её, а приложение переведёт её на нужный язык.
Остановимся подробнее на программах переводчиках, установленных на компьютер.

Данные программы основаны на формальном знании языка – правил словообразования и правил построения предложения. Программа в начале анализирует текст на исходном языке, а затем конструирует этот текст на том языке, который необходим. Данные программы предназначены для перевода технической документации, деловых переписок и другие материалов, написанных на так называемым «сухом» языке. А вот перевод художественных текстов, эмоционально окрашенных, содержащих шутки, необычные сравнения может выполнить только человек.
Перейдём к практической части урока.
Давайте попробуем воспользоваться возможностями программы-переводчика Гугл и переведём английский язык следующий текст: «Информатика (от «информации» и «автоматика») — это наука о методах и процессах сбора, хранения, обработки, передачи, анализа и оценки информации с применением компьютерных технологий, обеспечивающих возможность её использования для принятия решений».
Затем полученный результат с помощью той же программы переведём на русский язык и сравним исходной текст и конечный результат.
Итак, откроем поисковую систему интернета Гугл. в поисковик запишем переводчик Гугл. В результатах поиска нажимаем на Открыть Google Переводчик.
Скопируем текст из текстового редактора и вставим в окно переводчика. В окошках исходный текст и перевод выберем необходимые языки.
Как видим наш текст мгновенно перевёлся на английский язык.
Теперь скопируем текст на английском языке и вставим его в окно Исходный текст.
Сравним исходный текст и переведённый.
«Информатика (от «информация» и «автоматика») — это наука о методах и процессах сбора, хранения, обработки, передачи, анализа и оценки информации с применением компьютерных технологий, обеспечивающих возможность её использования для принятия решений».
«КомпьютернАЯ наукА (от «информациЯ и «автоматика») — наука о методах и процессах сбора, хранения, обработки, передачи, анализа и оценки информации с использованием компьютерных технологий, ДЛЯ использоваНИЯ (использования 2 раза) ЕЁ (информации) для принятия решений (для тоже 2 раза)
Как видим в первом же слове отличия. Слово Информатика переводчик перевёл как Компьютерные науки.
Анализируя текст, мы видим, что переводчик переводит тексты не точно и может допускать ошибки.
То есть у программ есть свои достоинства и недостатки. В зависимости от задачи, одна особенность может и достоинством, и недостатком.
Достоинством программ является высокая скорость перевода. Всего несколько секунд, и Вы получаете перевод многостраничного текста.
Недостатком же можно назвать то, что программы-переводчики работают не точно. Они годятся для того, чтобы в общих чертах передать, о чём идёт речь, и допускают ошибки в переводе.
Пришло время подвести итоги урока.
Для ввода текстов в память компьютера с бумажных носителей используют сканеры и программы распознавания символов.
Возможности современных компьютеров по хранению больших массивов информации и осуществлению в них быстрого поиска положены в основу разработки компьютерных словарей и программ-переводчиков.
Компьютерные словари выполняют перевод отдельных слов и словосочетаний. Для перевода текстовых документов применяются программы-переводчики.
Источник: videouroki.net
В.10.электронные словари и переводчики, программы распознавания текста.

Electronic dictionary (электронный переводной словарь) — переводной словарь на электронном носителе информации.
Функции переводных словарей
1.информативная-позволяет получить содержащуюся в словаре информацию
2.коммуникативная-предоставляет необходимые слова родного или чужого языка
3.нормативная-фиксирует значения и употребления слов способствуя унификации языка как средства общения
4.творческая-позволяют реализоваться лексикографическому таланту
5.развлекательная- см. ABBYY Lingvo X3 ME
Типы электронных переводных словарей
Словарь — электронный документ, воспроизводящий страницы традиционного бумажного словаря. Его функции ограничены, играет вспомогательную роль и неудобен в обращении.(Glossary Translation)
Словарь-программа, размещенный на компьютере пользователя. Как правило, электронные словари такого типа — это удобная и легко настраиваемая программная оболочка, работающая со словарными базами данных, имеющая настройки пользовательского интерфейса и позволяющая интеграцию с другими Windows-приложениями: MS Word и т.д.(Lingvo, TranslateIt!)
Сетевой словарь (программа перевода которого размещены на удаленных серверах) не требует наличия соответствующего программного обеспечения на персональном компьютере, но предполагают возможность работы в Интернете. ( Online Dictionary)
Словарь-форма на сайте, которая обращается к серверу. Каждый пользователь Интернета, имеющий свой собственный сайт, может разместить на нем On-line словарь и переводчик на Ваш сайт. Достаточно разместить на своем сайте формы On-line словаря и переводчика. С их помощью посетители сайта смогут переводить слова и целые предложения с русского на английский и обратно. (Lingvo Online)
Словарь-программа в мобильных устройствах (коммуникаторах, смартфонах). Имеют удобный интерфейс, быстрый перевод нужного слова, большое количество словарных статей при малом потреблении памяти, возможность установки нескольких словарей, возможность получать перевод слов, не выходя из других программ. ( Mobile Dictionary)
Словарь-устройство, в котором жестко прописывается программа, осуществляющая словарный перевод и дополнительные функции. Устройства оборудованы сенсорным экраном и могут управляться как с клавиатуры, так и специальным пером. У некоторых моделей имеется электронная записная книжка, которая позволяет вести записи на английском и русском языках и защищает паролем доступ к данным. Встроенный цифровой диктофон позволяет делать записи, предусмотрен обмен
Системы компьютерного перевода. Процесс глобализации мира приводит к необходимости частого обмена документами между людьми и организациями, находящимися в разных странах мира и говорящими на различных языках.
В этих условиях использование традиционной технологии перевода вручную тормозит развитие межнациональных контактов. Перевод многостраничной документации вручную требует длительного времени и высокой оплаты труда переводчиков. Перевод полученного по электронной почте письма или просматриваемой в браузере Web-страницы необходимо осуществлять срочно, и нет времени пригласить переводчика.
Системы компьютерного перевода позволяют решить эти проблемы. Они, с одной стороны, способны переводить многостраничные документы с высокой скоростью (одна страница в секунду), с другой стороны, переводить Web-страницы на лету, в режиме реального времени.
Системы компьютерного перевода осуществляют перевод текстов, основываясь на формальном знании: синтаксиса языка (правил построения предложений), правил словообразования и использовании словарей. Программа-переводчик сначала анализирует текст на одном языке, а затем конструирует этот текст на другом языке.
Современные системы компьютерного перевода позволяют достаточно качественно переводить техническую документацию, деловую переписку и другие специализированные тексты. Однако они не применимы для перевода художественных произведений, так как не способны адекватно переводить метафоры, аллегории и другие элементы художественного творчества человека.
Системы оптического распознавания символов. Системы оптического распознавания символов используются при создании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат.
Сначала с помощью сканера необходимо получить изображение страницы текста в графическом формате. Далее для получения документа в текстовом формате необходимо провести распознавание текста, т. е. преобразовать элементы графического изображения в последовательность текстовых символов.
Системы оптического распознавания символов сначала определяют структуру размещения текста на странице и разбивают его на отдельные области: колонки, таблицы, изображения и т. д. Далее выделенные текстовые фрагменты графического изображения страницы разделяются на изображения отдельных символов.
Для отсканированных документов типографского качества (достаточно крупный шрифт, отсутствие плохо напечатанных символов или исправлений) распознавание символов проводится путем их сравнения с растровыми шаблонами.
Растровое изображение каждого символа последовательно накладывается на растровые шаблоны символов, хранящиеся в памяти системы оптического распознавания. Результатом распознавания является символ, шаблон которого в наибольшей степени совпадает с изображением
При распознавании документов с низким качеством печати (машинописный текст, факс и т. д.) используется векторный метод распознавания символов. В распознаваемом изображении символа выделяются геометрические примитивы (отрезки, окружности и др.) и сравниваются с векторными шаблонами символов. В результате выбирается тот символ, для которого совокупность всех геометрических примитивов и их расположение больше всего соответствует распознаваемому символу.
Системы оптического распознавания символов являются самообучающимися (для каждого конкретного документа они создают соответствующий набор шаблонов символов), и поэтому скорость и качество распознавания многостраничного документа постепенно возрастают.
С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.
Статьи к прочтению:
- В 11. системы математических вычислений mathcad, mathlab. назначение, возможности, примеры применения.
- В12.системы подготовки презентаций. назначение, возможности. работа в ms powerpoint (или другой системе подготовки презентаций).
Переводчик на компьютер
Похожие статьи:
- Создание и редактирование электронных, текстовых служебных документов При подготовке текстовых документов на компьютере используются следующие основные группы операций. Операции ввода позволяют перевести исходный текст из…
- Инструкция по созданию электронной книги в программе book creator Создайте новую книгу в программе BookCreator. Дляэтого: · запустите приложение Book Creator; · нажмите знак «+» в нижней части экрана и выберите пункт…
Источник: csaa.ru