
Распознавание текста или оптическое распознавание символов также называется распознаванием текста или извлечением текста. Методы распознавания текста на основе машинного обучения позволяют извлекать печатный или рукописный текст из изображений, таких как плакаты, уличные знаки и наклейки на продукты, а также из таких документов, как статьи, отчеты, формы и счета. Текст обычно извлекается в виде слов, строк и абзацев или текстовых блоков, что обеспечивает доступ к цифровой версии отсканированного текста. Это устраняет или значительно сокращает потребность в вводе данных вручную.
Как OCR связано с интеллектуальной обработкой документов (IDP)?
Интеллектуальная обработка документов (IDP) использует OCR в качестве базовой технологии для дополнительного извлечения структуры, связей, ключевых значений, сущностей и других аналитических сведений, ориентированных на документ, с помощью расширенной службы искусственного интеллекта на основе машинного обучения, такой как Распознаватель документов. Распознаватель документов включает оптимизированную для документов версию Read в качестве обработчика OCR, делегируя другим моделям для получения аналитических сведений более высокого уровня. Если вы извлекаете текст из отсканированных и цифровых документов, используйте Распознаватель документов чтение OCR.
Обработчик OCR
Модуль OCR для чтения майкрософт состоит из нескольких расширенных моделей на основе машинного обучения, поддерживающих глобальные языки. Это позволяет им извлекать печатный и рукописный текст, включая смешанные языки и стили письма. Чтение доступно как облачная служба и локальный контейнер для гибкого развертывания. В последней предварительной версии он также доступен в виде синхронного API для отдельных сценариев, не относящихся к документам, только для изображений, с повышением производительности, что упрощает реализацию пользовательского интерфейса с помощью OCR.
Выпуски OCR (чтение)
Выберите выпуск для чтения, который лучше всего соответствует вашим требованиям.
| Изображения: общие, в дикие образы | наклейки, уличные знаки и плакаты | предварительная версия Компьютерное зрение версии 4.0 | Оптимизировано для общих изображений, не относящихся к документам, с синхронным API с улучшенной производительностью, что упрощает внедрение OCR в сценарии взаимодействия с пользователем. |
| Документы: цифровые и отсканированные, включая изображения | книги, статьи и отчеты | Распознаватель документов | Оптимизировано для отсканированных текстов и цифровых документов с асинхронным API для автоматизации интеллектуальной обработки документов в большом масштабе. |
Сведения об общедоступной версии Компьютерное зрение версии 3.2
Ищете последнюю Компьютерное зрение общедоступной версии 3.2 для чтения? Обратите внимание, что все будущие улучшения OCR для чтения будут частью двух новых служб, перечисленных выше. Дальнейших обновлений Компьютерное зрение версии 3.2 не будет. Чтобы продолжить, ознакомьтесь с общими сведениями и кратким руководством по Компьютерное зрение версии 3.2.
Использование OCR
Попробуйте OCR с помощью Vision Studio. Затем перейдите по одной из ссылок на выпуск Read, который лучше всего соответствует вашим требованиям.
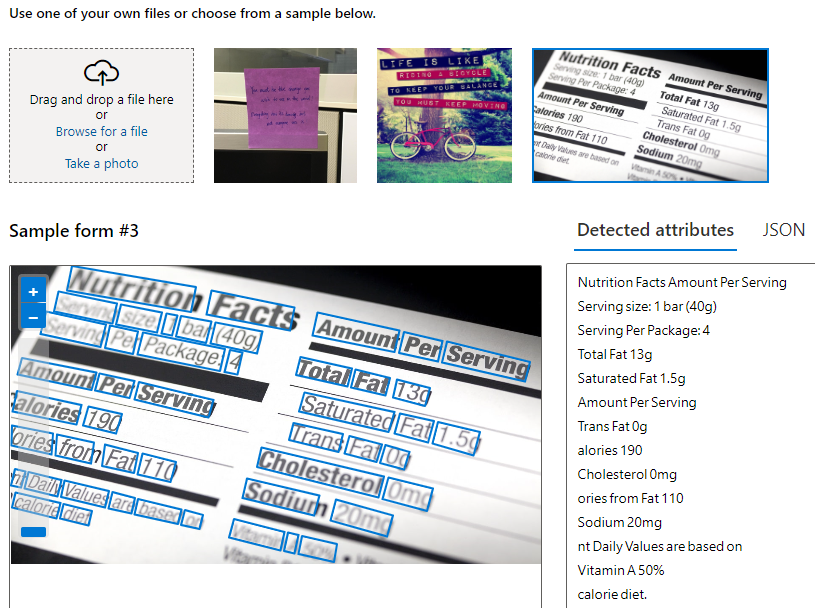
Языки, поддерживаемые OCR
Обе версии для чтения, доступные сегодня в Компьютерное зрение поддерживают несколько языков для печатного и рукописного текста. Распознавание текста для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латиницу, кириллицу, арабский и деванагари. Распознавание текста для рукописного текста включает поддержку английского, китайского (упрощенного), французского, немецкого, итальянского, японского, корейского, португальского и испанского языков.
Общие функции OCR
Модель чтения OCR доступна в Компьютерное зрение и Распознаватель документов с общими базовыми возможностями при оптимизации для соответствующих сценариев. В следующем списке перечислены общие возможности:
- Извлечение печатного и рукописного текста на поддерживаемых языках
- Страницы, текстовые строки и слова с оценкой расположения и достоверности
- Поддержка смешанных языков, смешанный режим (печать и рукописный ввод)
- Функция доступна как контейнер Distroless Docker для локального развертывания
Использование облачных API OCR или развертывание локальной среды
Облачные API являются предпочтительным вариантом для большинства клиентов из-за простоты интеграции и быстрой производительности. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Для локального развертывания контейнер Docker для чтения позволяет развернуть общедоступные возможности OCR Компьютерное зрение версии 3.2 в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Конфиденциальность и безопасность данных OCR
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных. Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дальнейшие действия
- Распознавание текста для общих (недокументных) изображений: воспользуйтесь кратким руководством по REST API анализа изображений Компьютерное зрение 4.0 (предварительная версия).
- Распознавание текста для документов PDF, Office и HTML и изображений документов: начните с Распознаватель документов чтение.
- Ищете предыдущую общедоступную версию? Ознакомьтесь с краткими руководствами по пакету SDK для Компьютерное зрение 3.2 ga или REST API.
Источник: learn.microsoft.com
Как распознать текст с картинки, фото, PDF-файла: подборка полезных программ (OCR) и сервисов

Доброго дня!
Сегодня в заметке хочу коснуться одного «больного» офисного вопроса: «. вот у меня есть фото страницы книги/документа, как мне ее загнать в Word чтобы отредактировать текст. «. (его вариации могут чуть отличаться)
Основная «проблема» здесь в том, что на фотографии (скане) нет текста — там он представлен в виде графической картинки, или иными словами буквы на фото — это просто черные палочки, квадратики и кружки на белом фоне (обычный рисунок в виде букв)! Т.е. это не символы, их нельзя выделить, скопировать и вставить в Word!
Что делать? Сначала потребуется, чтобы «кто-то» преобразовал эти «палочки и кружочки» (т.е. буквы с картинки) в формат обычного текста, символов (эта операция назыв. по англ. OCR // optical character recognition // оптич. распознавание символов) . А вот уже потом текст можно перенести в Word и редактировать.
Собственно, о программах и сервисах, решающих эту задачу, и пойдет сегодня речь.
По теме!
1) Как отсканировать документ на компьютер с принтера (МФУ) — https://ocomp.info/kak-otskanirovat-dokument.html
2) Как отсканировать документ с помощью смартфона на Андроид — https://ocomp.info/skaniruem-dokumentyi-android.html
«Чем» распознать текст (OCR)
Софт для Windows
FineReader
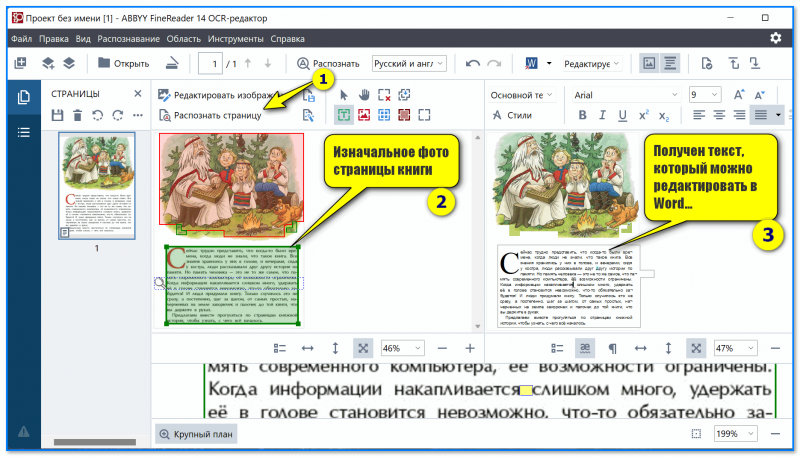
Пример работы с FineReader
Одна из лучших программ для распознавания текста с фотографий, сканов и PDF-файлов. Благодаря мощным алгоритмам (с автоматическим выделением областей) — процесс перевода «графики» в текст становится простым и легким!
Стоит отметить, что у FineReader почти нет конкурентов и заменить его очень сложно (особенно, если сканы для распознавания в плохом качестве или с редкими шрифтами).
- поддерживает все самые популярные языки (рус., англ., укр., немецкий, и пр.) и шрифты (даже отчасти рукописные);
- ручной и автоматический режимы работы;
- многостраничный режим (когда можно сразу же открыть 3 разных документа — и программа автоматически их обработает);
- встроенный редактор для исправления ошибок и корректировки текста;
- возможность передать распознанный текст в MS Word одним кликом мышки!
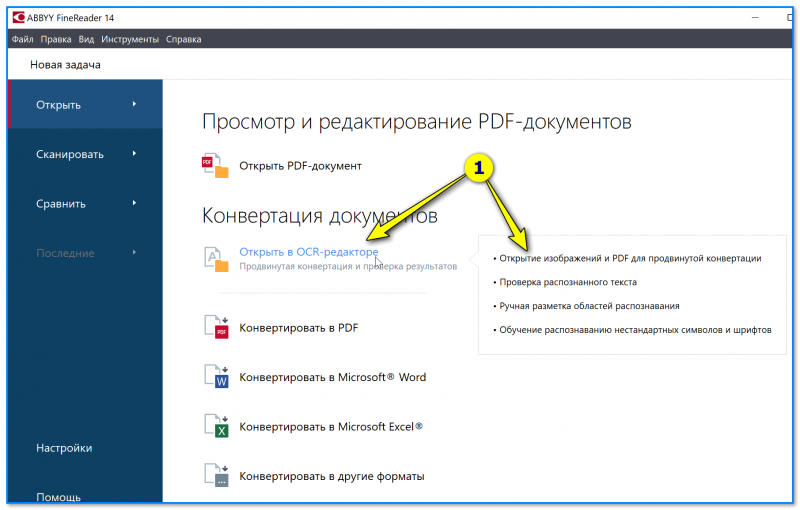
Открыть в OCR-редакторе — FineReader
Как пользоваться : достаточно открыть нужную фотографию или PDF-файл, а затем нажать кнопку «Распознать страницу» . Далее программа все сделает автоматически. См. скриншоты выше, стрелочками всё показано.
NAPS2
Компактная и простая программа для быстрого сканирования и распознавания документов. Отлично подходит для работы со сканерами и МФУ — можно сразу же с бумажного листа быстро «получить» документ Word с текстом для редактировки.
Кстати, в меню NAPS2 можно указать конкретно те языки, которыми вы будете пользоваться (чаще всего это русский и англ.). Прим. : программа поддерживает более 100 языков! См. скрин ниже.
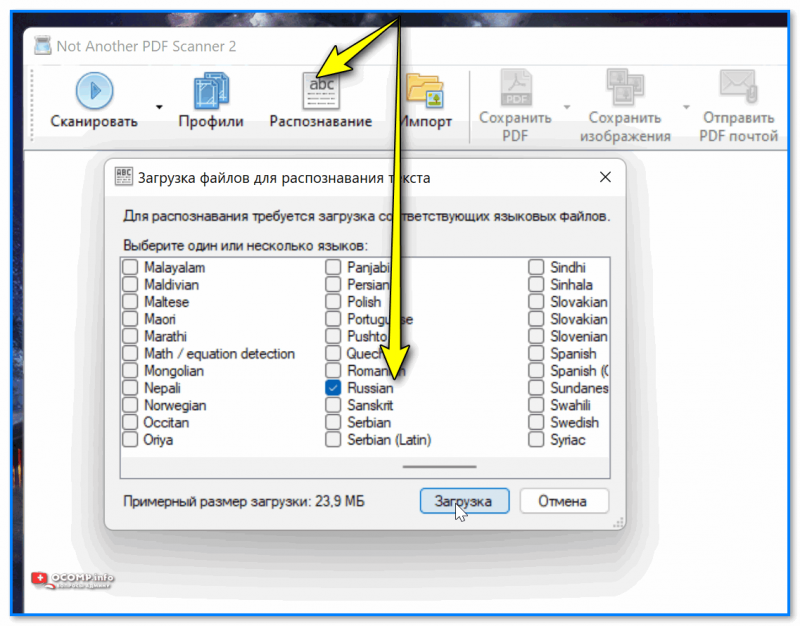
Загрузка русского (NAPS2)
Что по использованию : то здесь все просто. Сначала указываем языки, затем добавляем нужные файлы (JPG, TIFF, PNG, PDF и пр.), нажимаем кнопку распознать и сохраняем полученные страницы.
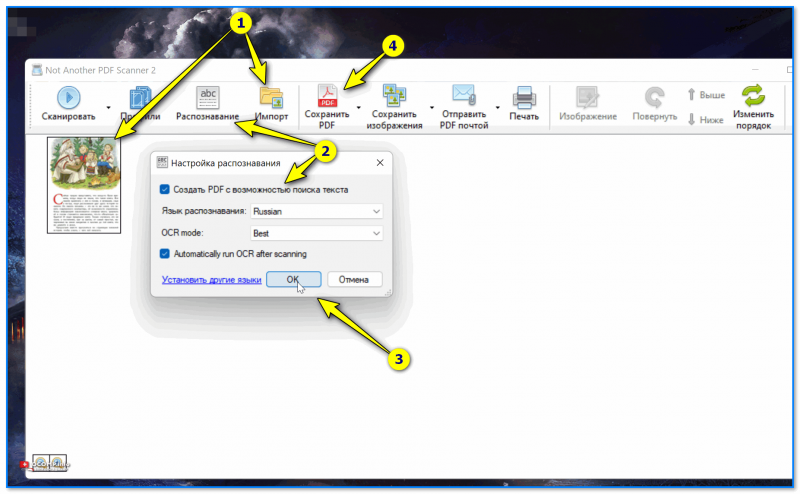
Пример работы со страничкой из книги — NAPS2
CuneiForm
Разработчик : Cognitive Technologies
Несмотря на то, что программа давно не обновлялась — русский и англ. текст она распознает довольно неплохо. Меню у нее выполнено в стиле минимализма (нет ничего лишнего): достаточно выбрать файл, указать параметры распознавания и приступить к операции. См. пример ниже.
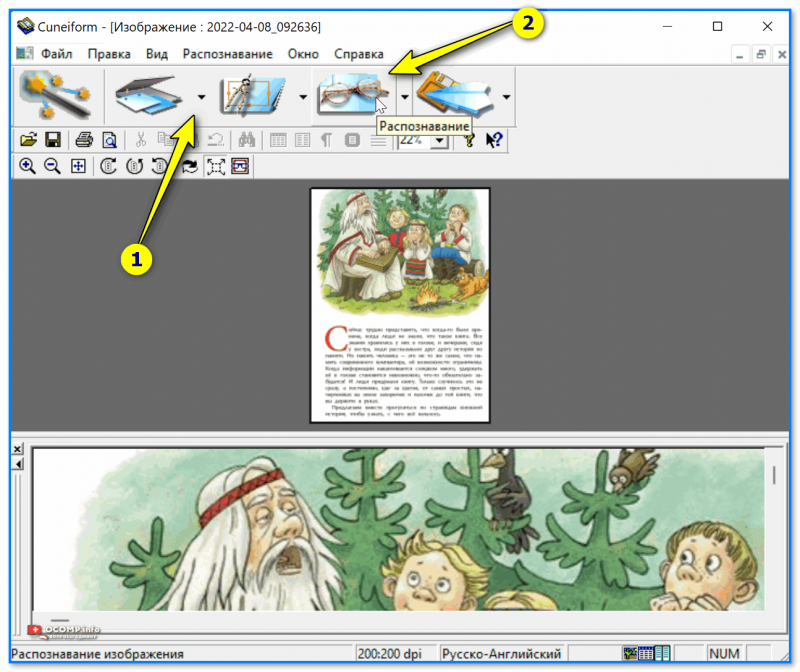
Cuneiform — пример работы со страничкой
- поддержка 20 языков;
- встроенный словарь для проверки документа;
- поддержка большинства печатных шрифтов;
- поддержка страниц, распечатанных на старых факсах, матричных принтерах и пр. устройствах (не все ПО такое может обработать!).
SimpleOCR
Примечание : см. в первую очередь на Classic версию (она бесплатна).
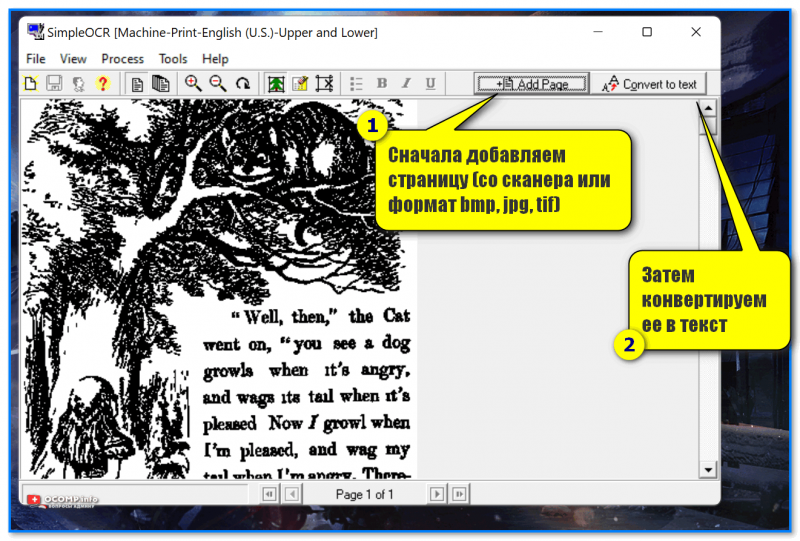
SimpleOCR — пример работы
SimpleOCR — крайне простая утилита для работы со сканерами (и документами, полученными с них). Позволяет преобразовать файлы BMP, TIF, JPG в текстовые форматы.
По умолчанию SimpleOCR умеет работать только с документами на англ., французском, немецком языками (русский придется до-устанавливать вручную!).
Также обратите внимание, что более расширенный функционал предоставляет платно.
На мой взгляд SimpleOCR может подойти, если вы активно работаете со сканами в хор. качестве с иностранным текстом (благо, что с ними она неплохо справляется!).
Scannitto Pro
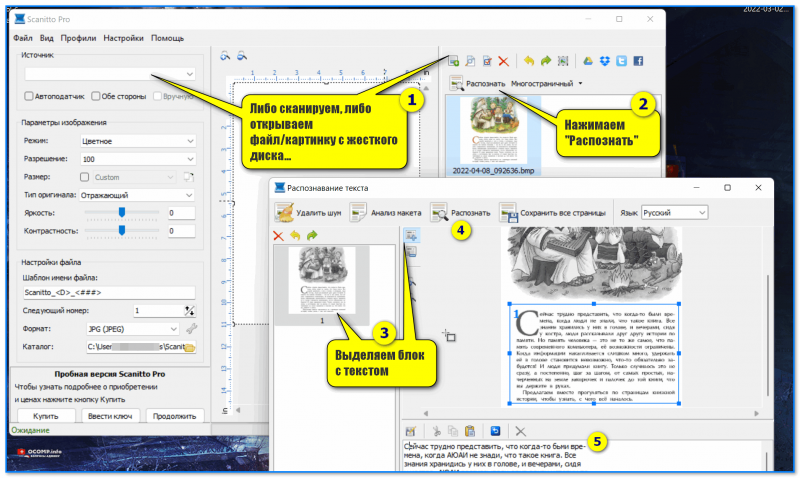
Пример работы с Scannitto Pro — распознавание странички текста
Scannitto Pro — эта программа больше подходит для получения сканов с МФУ и сканеров (и в этом плане здесь много опций: и повороты, и подрезки, и шаблоны. ). Однако, в ее арсенале функций есть и распознавание , причем, русский и англ. шрифты поддерживаются! (правда, опций здесь маловато. ).
Суть работы сводится к следующему : сначала нужно добавить страничку, затем открыть доп. окно для распознавания, выделить синим цветом блок текста и произвести операцию. Далее текст нужно подредактировать (замечу, что ошибок здесь больше, чем у того же FineReader, а потому нужны качественные сканы!).
Важно : программа Scannitto Pro платная (это еще один недостаток)!
В остальном особых нареканий нет. Отлично подойдет тем, у кого возникли сложности с другим ПО, или кто занимается сканированием от случая к случаю.
Онлайн-сервисы (OCR)
Сервис поддерживает относительно небольшие файлы, размер которых не превышает 8 МБ. Доступные форматы: PDF, JPG, PNG, BMP и пр.
Что касается качества — то оно среднее (проигрывает FineReader, но лучше ряда др. софта и сервисов).
img2txt.com — сервис распознавания онлайн (скрин главной странички)
Этот сервис выигрывает у предыдущего поддержкой 15 Мб файлов, зато проигрывает по качеству распознавания (по крайней мере в отношении русских шрифтов).
Как пользоваться : достаточно выбрать файл на жестком диске, далее указать его язык и нажать кнопку «Convert» . После вы сможете загрузить doc-файл с распознанным текстом. Удобно?!
Onlineocr.net — скриншот главной страницы сайта
Этот сервис выгодно отличается тем, что может обрабатывать не только PDF-файлы и картинки, но и архивы со множеством файлов (согласитесь это удобнее?!). Да и качество распознавания весьма на хорошем уровне (для рус. и англ. текста перепроверял на своих документах).
Примечание : обратите внимание, что на сервисе обрабатывается лишь 20 страниц! Большие документы придется разбивать, прежде чем загружать их на этот сайт.
convertonlinefree.com — скриншот страницы сайта
Этот сервис хорош тем, что поддерживает десятки самых разных файлов + неплохое качество распознавания. Бесплатная версия, кстати, позволяет обработать лишь 10 страниц. Полученные результаты можно сохранить в Word, PDF, TXT-документы.
Примечание : полная поддержка русских шрифтов, большой ассортимент импортируемых файлов: PDF, JPG, BMP, GIF, JP2, JPEG, PBM, PCX, PGM, PNG, PPM, TGA, TIFF, WBMP.
Convertio — скриншот с сайта
Дополнения по теме заметки — приветствуются в комментариях!
За сим прощаюсь, всем удачи!
Источник: ocomp.info
Что такое OCR? Зачем нужно оптическое распознавание символов в современном мире мобильных технологий?
Говоря простым языком, OCR (optical character recognition, оптическое распознавание символов) – это процесс перевода текста на изображениях в текстовый формат. Основное применение технологии OCR находят в различных задачах, связанных с оцифровкой данных. Для отдельных подзадач OCR иногда используют названия наподобие “умное распознавание символов” (intelligent character recognition, ICR) или “распознавание визитных карточек” (business card recognition, BCR).

Первые системы оптического распознавания символов появились практически одновременно с первыми компьютерами. В 50-х годах прошлого столетия с помощью коммерческих OCR системы начали обрабатывать отчеты о продажах, набранные на печатной машинке, и переводили их в перфокарты. С тех пор OCR пережил много изменений, главным из которых стала замена применяемых в алгоритмах распознавания разнообразных классификаторов символов искусственными нейронными сетями (ИНС, ANN).
Вызовы современных OCR технологий
Сейчас технологиям распознавания брошен серьезный вызов, когда все чаще речь идет о распознавании изображений с камер мобильных устройств или обычных веб-камер. Это могут фотографии или кадры из видеопотока. Чтобы лучше понять сложность поставленной задачи, давайте начнем с примера. Изображение документа для распознавания можно получить разными способами, и мы выбрали три из них:
1) взяли Canon CanoScan LiDE 300, отсканировали документ с разрешением 300dpi и бинаризовали результат;
2) сфотографировали документ на iPhone 11 при комнатном освещении;
3) сняли видео веб-камерой и взяли из него один кадр.
Как видно на картинке, системы распознавания в наши дни должны быть устойчивы к самым разнообразным условиям съемки. Очевидно, качество изображений может существенно различаться.
| Binarized scan |  |
| Photo with iPhone 11 |  |
| Web camera video frame |  |
Вот так может выглядеть рабочий процесс системы оптического распознавания.

Большинство подходов начинаются с предобработки изображения, которая, как правило, включает бинаризацию изображение для упрощения последующей сегментации на символы. Алгоритм сегментации делит изображение строки на изображения отдельных символов, которые подаются классификатору. Иногда, для улучшения качества распознавания к результату классификации могут применяться алгоритмы постобработки.
В случае mobile optical character recognition или мобильного OCR (на Android, iOS или иных системах), или же распознавания на мобильном устройстве, возникают две трудности: ограничения на вычислительные мощности и неконтролируемые условия съемки. При работе с персональными документами, банковскими бумагами или, например, результатами теста на COVID-19 важно обеспечить максимум конфиденциальности и минимизировать риск утечки данных, так что распознавание “в облаке” сразу отпадает.
Распознавание непосредственно на устройстве накладывает ограничения на вычислительную сложность алгоритмов, ведь система должна работать быстро и энергоэффективно. С другой стороны, меньшие ограничения на условия съемки значительно расширяют диапазон возможных искажений. Появляются проективные искажения, смазывание, перепады яркости, блики и многое другое. Все это существенно влияет на этап предобработки.
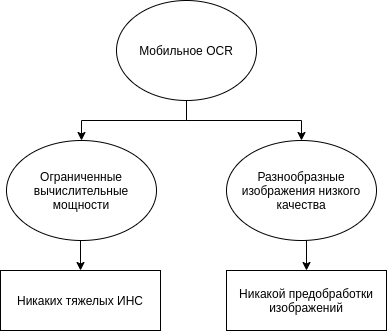
В результате при мобильном распознавании, с одной стороны, возникает множество ошибок у стандартных подходов к сегментации, а с другой – из-за ограничения на вычислительные ресурсы многие современные нейросетевые модели, например, рекуррентные сети (RNN) или LSTM-сети становятся неэффективными или же излишне ресурсозатратными. Таким образом, для успешного распознавания изображений, снятых на камеры мобильных устройств (работающих на Android или iOS), необходимо придумывать абсолютно новые алгоритмы и переосмысливать уже известные подходы.
Примером переосмысления старых подходов можно считать замену алгоритмов сегментации, основанных на обработке изображений, на сегментирующие нейронные сети, как это уже когда-то произошло с классификаторами. Наиболее многообещающей моделью для такие подходов представляется полносверточная сеть (fully convolutional network, FCN).

Замена отдельного изображения на видеопоток приводит к появлению концепции 4D OCR и новым возможностям распознавания, прежде всего, к алгоритмам межкадровой интеграции результатов распознавания. Более того, при обработке видео можно рассматривать процесс распознавания как anytime алгоритм, готовый в любой момент дать ответ. Выбор оптимального числа кадров можно осуществлять, решая задачу останова.
В каких процессах применяются системы оптического распознавания (OCR)
Давайте приведем несколько примеров. Все ниже перечисленные процессы можно улучшить и ускорить с помощью OCR системы.
Платежи и переводы могут стать гораздо быстрее с добавлением распознавания банковской карты . Замена ручного ввода данных на сканирование QR, AZTEC, PDF 417 или другого типа штрихкода вместе с распознаванием карты поможет избежать раздражающих ошибок во введенных данных и улучшить впечатление конечного пользователя от банковского приложения, онлайн-магазина или даже оффлайн магазина.
При продаже билетов и регистрации на рейс пассажирам требуется вводить свои личные данные. Автоматическое сканирование МЧЗ (машиночитаемой зоны) или паспорта позволит сделать эти процессы более удобными для пользователей и минимизировать число ошибок в данных.
Удаленная идентификация клиента – популярная и крайне важная опция для многих задач, включая проверку возраста, онлайн-регистрацию, активацию сим-карты, бронирование номеров в отелях и предварительную запись на медицинские услуги. С ее помощью можно упростить жизнь пользователю, а также оптимизировать работу персонала и в результате избежать очередей в офисах, магазинах, фойе отелей и других местах скопления людей.
Отдельно стоит выделить банковские услуги, где применение OCR для распознавания документов и удостоверений личности является must-have функцией. В этой сфере любые ошибки в данных приводят к проблемам для клиентов, оставляя у них плохое впечатление от банка и влияя на решение о дальнейшем обслуживании. Встроенное распознавание ID карт, паспортов, водительских прав и других документов ускоряет процесс открытия счета новым клиентам, упрощает аутентификацию текущих клиентов и предоставляет возможности развития кросс-продаж.
А что об общедоступных OCR решениях?
В наше время существует много общедоступных open-source распознавателей текста. Такие решения могут быть очень полезны в образовательных целях или для учебного демонстрационного приложения. Однако они могут быть не просто бесполезны, а опасны для настоящих “боевых” коммерческих систем. При этом, их существенным недостатком окажется не только точность и скорость распознавания, но и уязвимость для внешних атак.
Атаки на нейронные сети – это популярная тема для научных исследований. Главные типы атак – отравление данных и атака уклонением с помощью состязательных примеров. При отравлении данных ошибки вводятся в сеть на этапе обучения. А при применении сети распознаватель может совершить специфические серьезные ошибки.
Единственный способ избежать такой атаки – быть уверенными в своих данных. А как можно быть уверенным в данных, которых вы никогда не видели? При атаке уклонением злоумышленник пытается заставить сеть дать неверный ответ. Иногда он даже может предопределить этот ответ.
Для открытых систем оптического распознавания текста и символов (OCR) такие примеры можно посчитать, так как эти системы общедоступны. Можно просто скачать модель и подобрать нужные примеры.
Теперь чуть больше об OCR сервисах Smart Engines
В Smart Engines мы разрабатываем OCR решения, которые могут работать с изображениям, фотографиями, сканами или видеопотоком в реальном времени. Условия съемки могут быть самыми разными – не нужно специально фокусировать камеру или же искать хорошо освещенное место. Наше ПО работает автономно на конечном устройстве, никуда не передает данные клиента, не хранит их и не требует интернет-соединения. При разработке нашего OCR модуля мы активно пользуемся генерацией искусственных данных и не используем предобученные модели. Таким образом, наше решение оказывается гораздо более устойчивым для внешних атак.
Программные продукты Smart Engines, в которых мы применяем собственные технологии OCR
– Smart ID Engine – SDK для сканирования более чем 2427 типов удостоверяющих личность документов со всего мира, напечатанных с использованием латиницы, кириллицы, арабицы и других письменностей;
– Smart Code Engine – решение для распознавания банковских карт, одномерных и двумерных штрихкодов, МЧЗ и других кодированных объектов;
– Smart Document Engine – система автоматического анализа и распознавания деловых документов, форм и анкет.
– Сканеры Smart Engines – программно-аппаратные комплексы для распознавания и проверки подлинности паспортов и дргуих удостоверений личности
Как работают наши OCR технологии в мобильных приложениях Android и iOS
Чтобы бесплатно попробовать наши продукты в действии, вы можете скачать демо приложение из App Store или Google Play.
Если же вы хотите узнать больше о научных разработках, стоящих за нашими продуктами, можете почитать разделы Наука и Блог на нашем сайте, наш блог на хабре или просто поискать нас в Google Scholar.
Источник: smartengines.ru